

Kafka – стильная, модная, молодежная технология, которую разработала в 2011 году компания LinkedIn и значительно усовершенствовал Apache Software Foundation. Представляет собой надежный, масштабируемый и устойчивый инструмент для обработки и передачи данных в режиме реального времени — шину данных.
Я Саша, менеджер продукта в команде облачных БД. В статье расскажу про сильные стороны Kafka и задачи, в которых она раскрывается по максимуму. А также напишу быстрое приложение на базе Kafka-as-a-service, которую мы недавно запустили в Selectel.
Введение
Считается, что одна из основных задач шины данных — передача данных из системы источника в целевую систему. Но когда у нас один консьюмер и один продюсер, все просто — кажется, шина не нужна. Теперь представим, что у нас 4 консьюмера и 6 продюсеров (а уже завтра может стать больше)?
Нам придется реализовать 24 интеграции! И каждая потребует протокола взаимодействия, формата данных и валидации по схеме. Также нам необходимо выполнить нефункциональные требования, такие как:
- надежность и гарантия доставки,
- подключение новых сервисов,
- интеграция разных стеков.
Задача уже не кажется простой, но Kafka может с ней справиться и сделает это лучше похожих инструментов. Рассмотрим, за счет каких отличий от классических БД у нее это получится.
Отличия от классических баз данных
У Apache Kafka несколько принципиальных отличий от традиционных баз данных типа MySQL или PostgreSQL. Это обусловлено задачей, для которой она проектировалась, а именно — шардированная, отказоустойчивая потоковая обработка большого количества данных в реальном времени.
Среди ключевых отличий:
- Ориентация на потоковую обработку данных. Традиционные базы данных часто ориентированы на хранение структурированных данных. Apache Kafka, в свою очередь, создавалась специально для обработки непрерывных потоков данных в реальном времени.
- Сохранение данных как событий. Kafka не поддерживает полнотекстовый поиск или выполнение сложных запросов на месте, что отличает решение от традиционных БД. Вместо этого она сохраняет события и данные в своих топиках для последующей обработки.
- Сообщения вместо записей. В Kafka данные организованы в виде сообщений, а не записей, как в реляционных базах данных. Эти сообщения могут быть как структурированными данными, так и неструктурированными событиями.
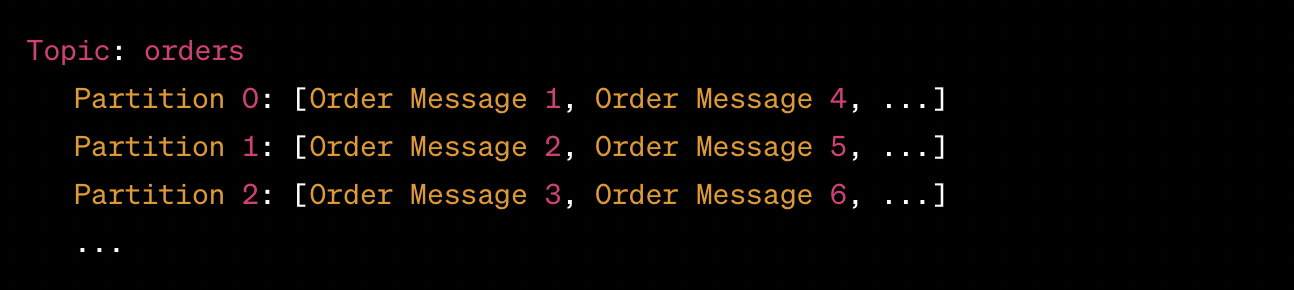
- Доставка сообщений. Одно из ключевых отличий Kafka — доставка и сохранение порядка сообщений. Это особенно важно для приложений, требующих надежности и согласованности данных.
C порядком сообщений все не так просто и возможны ситуации, приводящие к неожиданному порядку сообщений. Но их можно исправить на стороне потребителя путем правильной обработки времени события. Иными словами, Kafka не гарантирует порядок сообщений в отличие от того же, RabbitMQ.
- Отказоустойчивость и масштабируемость. Kafka проектировалась на принципах горизонтального масштабирования. Это позволяет добавлять новые брокеры и партиции для обработки больших объемов данных, обеспечивать репликацию и отказоустойчивость немного «нативнее», чем в классических СУБД. Kafka в новых версиях из коробки предоставляет механизм репликации данных и управления фейловером брокеров.
Отличие от классических брокеров сообщений
Иногда можно услышать, что Kafka — это просто очередь или брокер сообщений, очередной аналог RabbitMQ. Да Apache Kafka можно использовать в качестве такой очереди, но прямым аналогом «кролику» называть ее некорректно. Рассмотрим разницу между двумя решениями.
Архитектура и использование
- Kafka ориентирована на обработку потоков данных и является распределенной системой потоковой обработки. Подходит для сценариев, где данные передаются между компонентами в виде непрерывных потоков событий, а также для аналитики в реальном времени (больше похожа на шину, чем на очередь).
- RabbitMQ — это брокер сообщений, который реализует паттерн «очереди». Он предоставляет механизм для отправки, обработки и хранения сообщений в виде очередей. RabbitMQ хорошо подходит для сценариев, где необходимо гарантировать доставку сообщений в определенном порядке и обеспечить независимость компонентов друг от друга.
Сохранение сообщений
- Kafka сохраняет сообщения на определенное время (или скорее на любое время в объеме, на который хватит размера хранилища). Это позволяет обрабатывать и анализировать данные в любой момент времени, даже после их передачи.
- RabbitMQ хранит сообщения в очередях до тех пор, пока получатель их не обработает и подтвердит. После сообщение удаляется.
Сложность настройки
- Kafka может быть сложна в настройке из-за распределенной архитектуры и конфигураций. Решение обеспечивает более высокую масштабируемость и отказоустойчивость, но требует более глубокой экспертизы провайдера услуги и понимания нюансов работы технологии.
- RabbitMQ значительно проще в настройке и понимании, особенно для начинающих пользователей. БД хорошо подходит для небольших, тестовых проектов, SLA которых описывается командой — docker run.
Производительность
- Kafka обеспечивает высокую производительность и низкую задержку благодаря оптимизированной структуре хранения и обработки потоков данных. Такая услуга представляет собой серьезное enterprise-решение.
- Считается, что RabbitMQ имеет более низкую производительность и отказоустойчивость по сравнению с Kafka, особенно при больших объемах сообщений. С другой стороны, Rabbit обеспечивает меньшее латенси при доставке сообщений, другими словами — переварит меньше, зато быстрее.
Дисклеймер: сравнение выше не претендует на звание серьезного, инженерного бенчмарка под любой кейс и профиль нагрузки. Это скорее тезисный набросок основных отличий инструментов.
Бонус Kafka — в том, что она позволяет не только хранить, но и обрабатывать полученные данные в реальном времени, разделяя user data на разные топики. Для этого используются библиотеки Kafka streams, Apache flink.
Вывод: Apache Kafka отличается от всех остальных способов хранения данных и выделяется как платформа для обработки потоков данных в реальном времени. Простыми словами — шина данных.
Когда стоит использовать Kafka
Эта технология хорошо подходит для следующих технических задач.
Агрегация событий или логов — например, clickstream. Допустим, нужно отделить данные, полученные с ботов, от данных, полученных с людей. В дальнейшем такие очищенные данные используются в системах ML, аналитики, репортинга и визуализации.
IoT-приложение для сенсоров. Разработка приложения для мониторинга данных с IoT-устройств, таких как сенсоры в зданиях или устройства в производстве. Сенсоры могут передавать данные через Kafka-as-a-Service, а ваше приложение будет анализировать и реагировать на эти данные.
Доставка событий многим потребителям. Генерируется событие в одном месте, а обрабатывается сразу несколькими системами без реализации дополнительной логики обработки на уровне приложения.
Система уведомлений и событий. Система уведомлений, которая будет использовать Kafka для доставки сообщений о событиях, таких как новые заказы, обновления статусов и т.д. Клиенты могут подписаться на определенные темы событий и получать уведомления в реальном времени. Это бывает очень полезно в интеграции с CRM/ERP системами.
Обработка огромных данных. Задача вполне возможна благодаря архитектуре Kafka. Она использует партицирование и распределение данных между брокерами, что позволяет масштабировать систему горизонтально для обработки растущего потока данных, а библиотеки kafka streams, Apache flink могут помочь обрабатывать данные на лету.
Платформа для совместной работы и обсуждения. приложение, которое позволит пользователям обмениваться сообщениями и обсуждать проекты, идеи и задачи. Используйте Kafka для обеспечения мгновенной доставки сообщений и создания персонализированных потоков обсуждения.
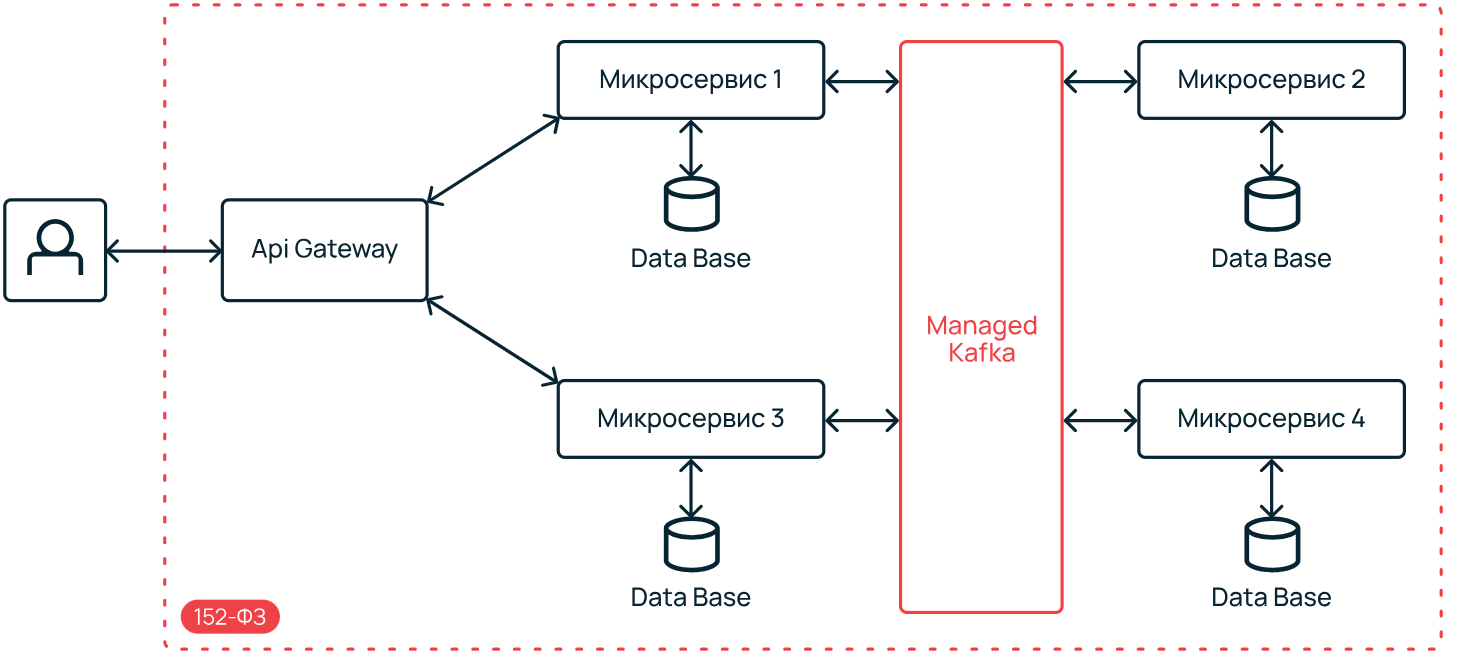
Проектирование event-driven системы. Apache Kafka идеально подходит для написания приложения с применением event-driven архитектуры. Обеспечивает надежную и масштабируемую платформу для передачи, сохранения и обработки событий:
- В Kafka складываются основные события системы, а микросервисы обновляют из нее локальные базы данных.
- Решение используется как источник истины, в том числе для обеспечения отказоустойчивости и надежности в таких архитектурах.
- Kafka использует понятие партиций для разделения данных. Это позволяет обработать события параллельно и распределить нагрузку между разными частями системы.
- Kafka позволяет анализировать данные в реальном времени, что полезно для мгновенной реакции на события, обнаружения аномалий, реализации персонализированных рекомендаций и других сценариев.
Stream-processing и CDC. Как промежуточное хранилище для перекладывание данных из одной системы в другую.
Вывод: Apache Kafka подходит для организаций, которые стремятся оптимизировать свои процессы обработки данных в условиях высокой нагрузки и требований к надежности. Решение может быть незаменимо для ситуаций, где оперативная обработка транзакций и мониторинг рисков критически важны. Также Kafka подойдет для предприятий в сфере интернета вещей (IoT), где потоки данных от большого количества устройств требуют непрерывной обработки и анализа.
Когда не стоит использовать Kafka
Я не сторонник использовать технологии только потому, что они модные, стильные и молодежные. Убежден, что для абсолютного большинства задач в разработке достаточно старой доброй PostgreSQL, о чем недавно писал мой коллега. Поэтому приведу примеры, когда точно не стоит использовать Kafka:
- Необходима тривиальная база данных для сайта — например, для хранения данных в CMS типа WordPress достаточно будет MySQL.
- Чтение подряд и большими порциями не нужно.
- Нужна настройка каждого сообщения индивидуально.
- Нужны очереди, поддерживающие сложные схемы обработки сообщений (request/reply) — в таком случае лучше использовать готовое решение типа RabbitMQ (у Kafka просто нет такой функциональности из коробки).
Вывод: для небольших и простых проектов без требований к обработке данных в реальном времени Apache Kafka будет избыточной. Не усложняйте и используйте классическую базу данных или очередь.
Пример простого приложения на Python для чтения и записи в Kafka
Давайте посмотрим на Kafka поближе и напишем небольшое приложение для быстрой демонстрации работы с шиной данных.
Так как мы хотим упростить знакомство, воспользуемся готовым сервисом Kafka в Selectel:
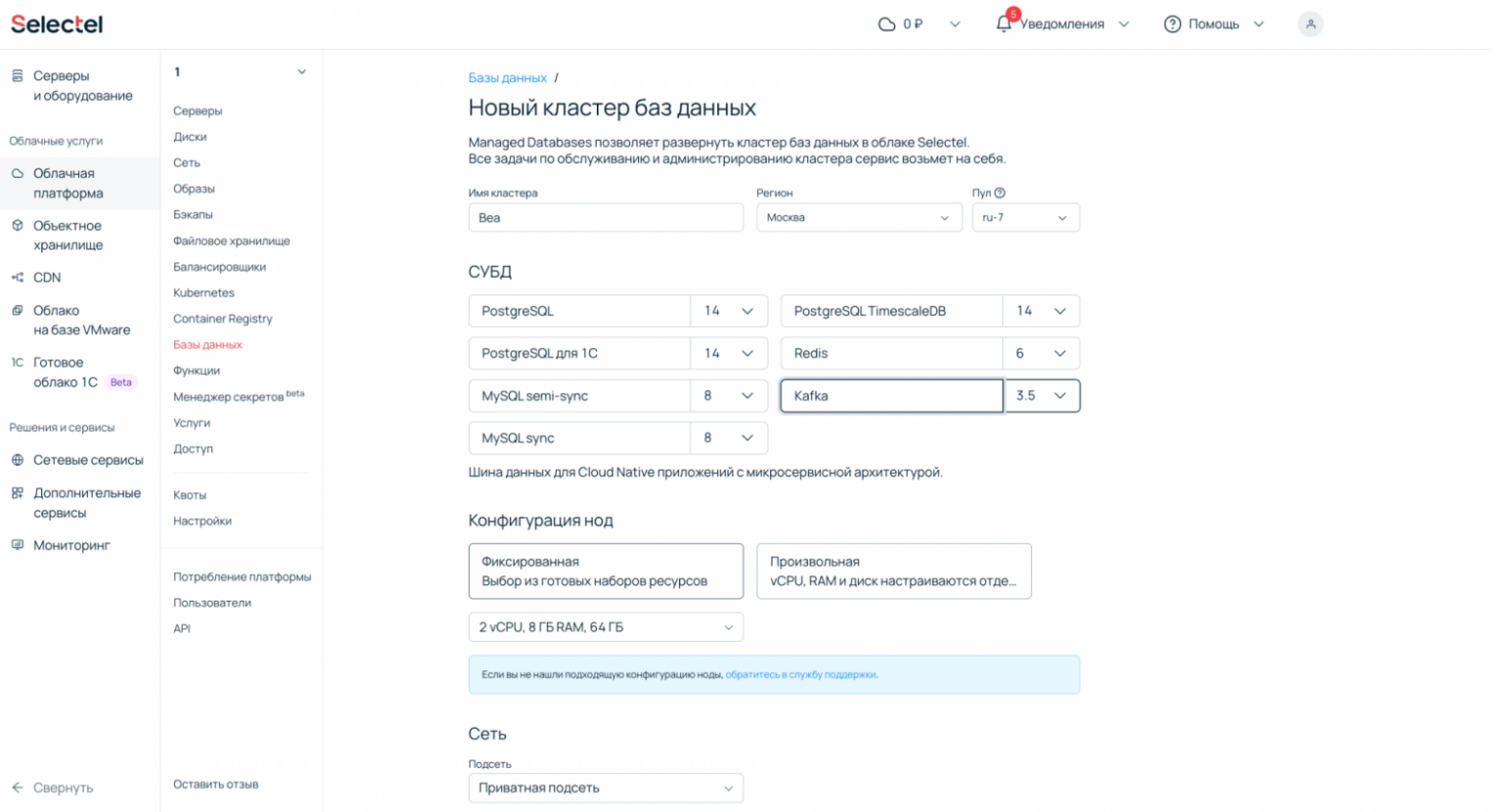
- Заходим в панель управления → раздел Облачная платформа → Базы данных.
- Заказываем услугу Kafka-as-a-service, выбираем любую удобную нам конфигурацию и регион.
- После создания кластера нужно скачать SSL-сертификат, он понадобится нам для подключения. Дополнительную информацию и примеры можно посмотреть в документации или на вкладке Подключения в услуге. Заходим в консоль на локальном ПК и выполняем команду:
mkdir -p ~/.kafka/ wget https://storage.dbaas.selcloud.ru/CA.pem -O ~/.kafka/root.crt chmod 0600 ~/.kafka/root.crt
- Возвращаемся в панель управления Selectel (Облачная платформа → Базы данных), на вкладку Топики в Kafka и создаем первый топик. Количество разделов можно оставить по умолчанию, для нашего примера этот параметр не принципиален:
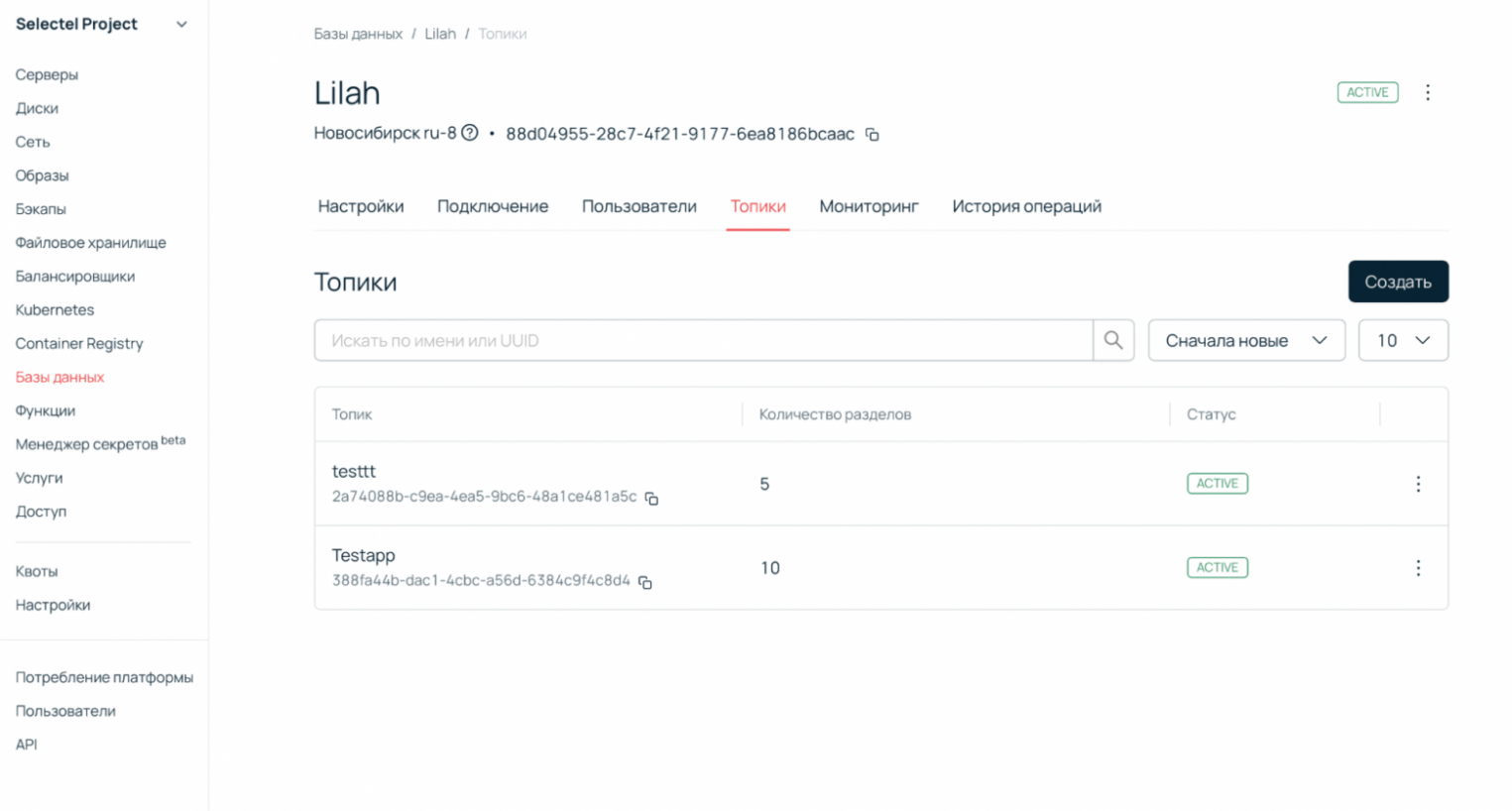
- Создаем пользователя и определяем ему доступ к интересующему нас топику. В примере мы даем сразу доступ на запись и чтение, однако вы можете разделять эти права так, как вам потребуется.
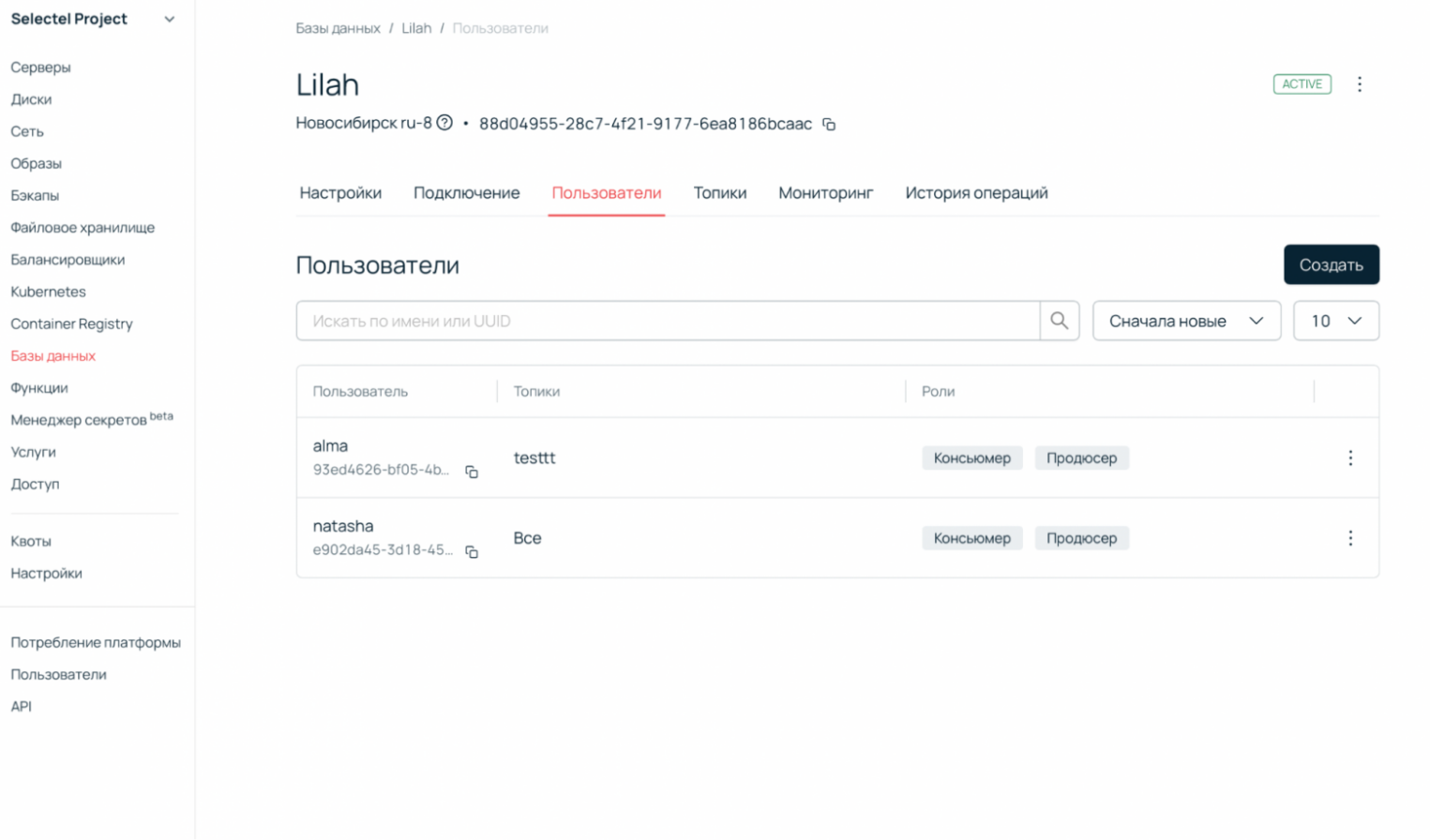
Инфраструктура готова, теперь переходим к написанию кода.
Задача первого сервиса будет тривиальной: постить в Kafka сообщение в формате JSON каждые 10 секунд. Я заказал Kafka-as-a-service c публичным адресом, поэтому писать программу буду прямо на своем ноутбуке с выходом в интернет. Вы можете использовать для этого любую другую архитектуру, главное обеспечить сетевую связность до кластера Kafka.
Писать будем на Python, так что нам понадобится скачать библиотеку kafka-python. Снова заходим в консоль ноутбука и выполняем команду (она может отличаться в зависимости от вашей ОС, за подробностями обращайтесь в документацию):
pip install kafka-python
Код первого сервиса — producer:
import json
import time
from kafka import KafkaProducer, KafkaConsumer
from kafka.errors import KafkaError
# Настройки для подключения к Kafka
bootstrap_servers = ':9093' # тут нужно указать адрес Kafka
topic = 'testtt' # тут нужно указать топик
username = 'natasha'
password = ''# тут нужно указать пароль
ssl_cafile = '/Users/alex/.kafka/root.crt' # Путь к CA сертификату
ssl_certfile = '/Users/alex/.kafka/root.crt' # Путь к вашему клиентскому сертификату
# Пример данных о погоде (в реальности это может быть получено из API)
weather_data = {
"city": "SPb",
"temperature": 42,
"condition": "baby's on Fire!"
}
# Преобразование данных о погоде в JSON
weather_json = json.dumps(weather_data)
# Создание Kafka-продюсера с аутентификацией и SSL
producer = KafkaProducer(
bootstrap_servers=bootstrap_servers,
security_protocol='SASL_SSL',
sasl_mechanism='SCRAM-SHA-512',
sasl_plain_username=username,
sasl_plain_password=password,
ssl_cafile=ssl_cafile,
ssl_certfile=ssl_certfile,
)
print(producer.config['api_version'])
# Отправка данных о погоде в тему Kafka
while True:
try:
future = producer.send(topic, value=weather_json.encode())
record_metadata = future.get(timeout=10)
except KafkaError as e:
print(f"Failed to send data: {e}")
time.sleep(10)
Перейдем к другому сервису. Его задача снова простая — читать эти сообщения. В примере мы используем параметр enable_auto_commit, для того чтобы сообщения можно было легко перечитать сначала.
Код второго сервиса — consumer:
import json
from kafka import KafkaProducer, KafkaConsumer
# Настройки для подключения к Kafka
bootstrap_servers = ':9093' # тут нужно указать адрес Kafka
topic = 'testtt' # тут нужно указать топик
username = 'natasha'
password = ''# тут нужно указать пароль
ssl_cafile = '/Users/alex/.kafka/root.crt' # Путь к CA сертификату
ssl_certfile = '/Users/alex/.kafka/root.crt' # Путь к вашему клиентскому сертификату
# Создание Kafka-консьюмера с аутентификацией и SSL
consumer = KafkaConsumer(
topic,
bootstrap_servers=bootstrap_servers,
group_id='my-group',
security_protocol='SASL_SSL',
sasl_mechanism='SCRAM-SHA-512',
sasl_plain_username=username,
sasl_plain_password=password,
ssl_cafile=ssl_cafile,
ssl_certfile=ssl_certfile,
auto_offset_reset='none',
enable_auto_commit=False
)
# Чтение данных о погоде из темы Kafka
for message in consumer:
received_data = json.loads(message.value.decode())
print("Received weather data:")
print("City:", received_data["city"])
print("Temperature:", received_data["temperature"])
print("Condition:", received_data["condition"])
print("-----------------------")
# Закрываем консьюмера
consumer.close()
Запускаем оба сервиса и смотрим результат работы второго:
.../consumer.py
-----------------------
Received weather data:
City: SPb
Temperature: 42
Condition: baby's on Fire!
-----------------------
Received weather data:
City: SPb
Temperature: 42
Condition:baby's on Fire!
-----------------------
Received weather data:
City: SPb
Temperature: 42
Condition: baby's on Fire!
-----------------------
...
В рамках примера мы не рассмотрели несколько важных нюансов Kafka — партиции и оффсет.
Партиции — это фундаментальный механизм хранения данных в Apache Kafka. Каждый топик в Kafka разделен на одну или несколько партиций. Каждая партиция — это упорядоченная и неизменяемая последовательность сообщений, которая хранит данные.
При отправке сообщения в Kafka вы можете указать ключ и определить, в какую партицию отправить сообщение. Это позволяет управлять упорядоченностью данных с одним ключом и предотвращать изменение порядка обработки.
# Настройки для подключения к Kafka
bootstrap_servers = 'kafka_address:port'
topic = 'weather_data'
partition = 1 # Номер партиции, в которую отправляем сообщение
username = 'your_username'
password = 'your_password'
ssl_cafile = '/path/to/ca.crt'
ssl_certfile = '/path/to/client.crt'
ssl_keyfile = '/path/to/client.key'
# Содазание экземпляра продюсера не отличается от примеров выше
Для чтения можно реализовать функцию, в которой консьюмеры подпишутся на определенные партиции топика, чтобы обрабатывать данные параллельно. Вы можете регулировать количество консьюмеров и партиций для достижения оптимального баланса между скоростью и обработкой.
# Создание Kafka-консьюмера с аутентификацией и SSL
consumer = KafkaConsumer(
topic,
bootstrap_servers=bootstrap_servers,
security_protocol='SASL_SSL',
sasl_mechanism='SCRAM-SHA-512',
sasl_plain_username=username,
sasl_plain_password=password,
ssl_cafile=ssl_cafile,
ssl_certfile=ssl_certfile,
auto_offset_reset='earliest',
group_id=None # Отключаем группу потребителей для параллельной обработки
)
# Функция для обработки сообщений
def process_messages():
for message in consumer:
print(f"Consumer in partition {message.partition} received message: {message.value.decode()}")
# Запуск потоков для параллельной обработки
threads = []
for _ in range(3): # Пример: запустить 3 потока
thread = threading.Thread(target=process_messages)
threads.append(thread)
thread.start()
# Ожидание завершения всех потоков
for thread in threads:
thread.join()
Каждая партиция может иметь несколько реплик, которые распределяют данные для обеспечения отказоустойчивости. Репликация позволяет сохранить данные, даже если один из брокеров выходит из строя.
Оффсеты в Kafka — это позиции в партициях, указывающие на конкретные места в потоке сообщений. Оффсеты используются для отслеживания прогресса консьюмеров при чтении данных из топиков.
Оффсеты позволяют консьюмерам запоминать, до какого момента они уже прочитали данные. При перезапуске или сбое консьюмер сможет продолжить чтение с места, где он остановился, а не с начала.
Если консьюмер прочитал сообщение и успешно обработал его, он может сохранить оффсет после успешной обработки. Если впоследствии возникнут ошибки, консьюмер сможет использовать оффсет, чтобы перечитать это сообщение и обработать его повторно.
Оффсеты позволяют отслеживать прогресс консьюмеров в реальном времени. Это важно для мониторинга и контроля обработки данных.
Пример работы с оффсетом:
# Функция для обработки сообщений
def process_messages():
for message in consumer:
print(f"Received message: {message.value.decode()}")
# Получение и сохранение оффсета
topic_partition = (message.topic, message.partition)
offset = message.offset
print(f"Offset for {topic_partition}: {offset}")
# Запуск функции для обработки сообщений
process_messages()
Для работы с Kafka в примерах я использовал библиотеку kafka-python, однако хотел бы отметить еще одну библиотеку — confluent-kafka. Если вам интересны примеры ее работы, пишите в комментариях — я обязательно напишу отдельную статью про примеры работы с confluent-kafka.
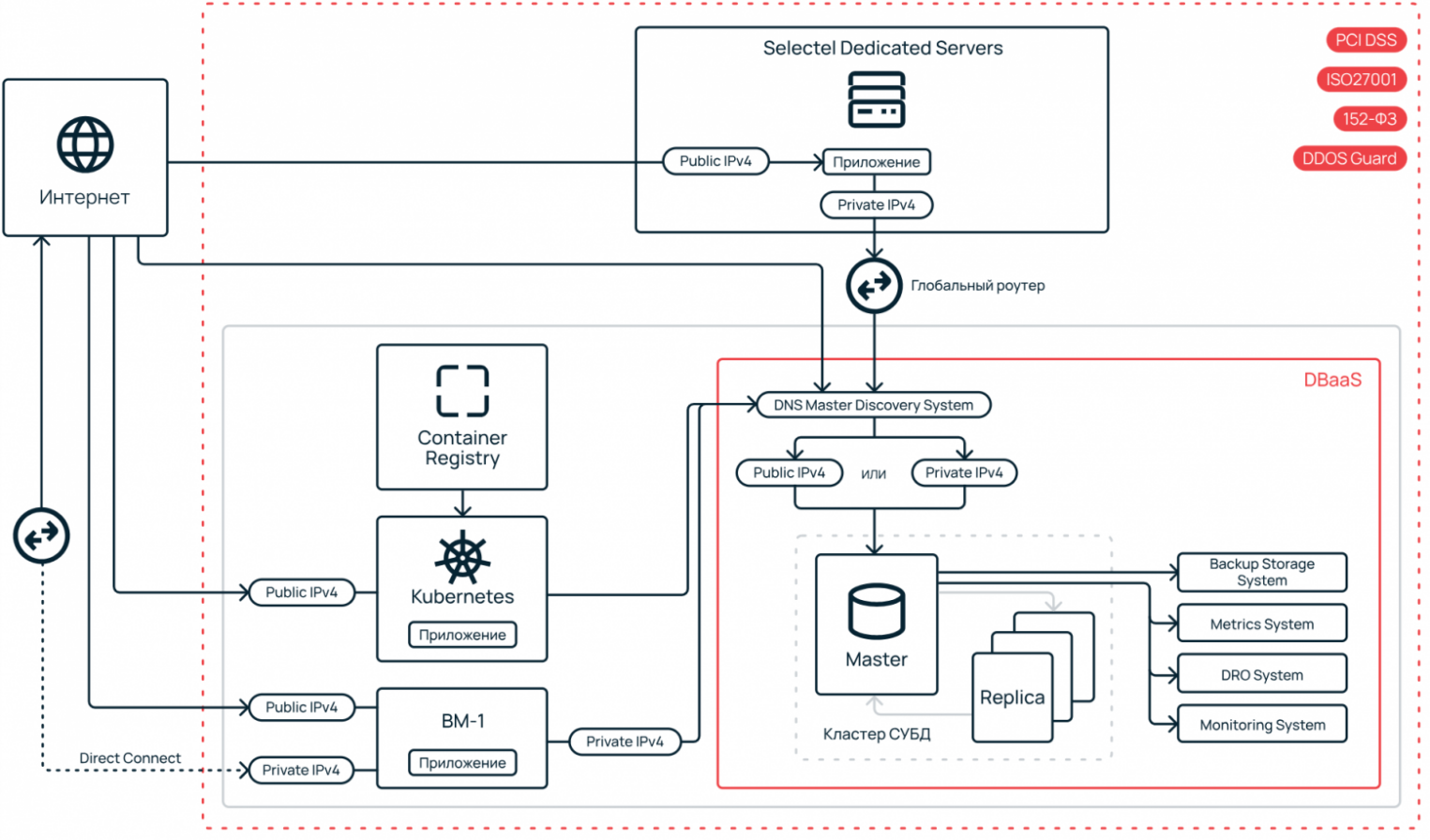
Обслуживание кластеров Apache Kafka
В примере выше я использовал готовый кластер Kafka-as-a-service. Это связано с тем, что внедрение Kafka может быть связано с рядом технических сложностей, требующих внимательного и компетентного инженерного подхода.
Кластер Apache Kafka состоит из двух ключевых компонентов:
- Брокеры представляют собой серверы, на которых запускается экземпляр Kafka в режиме «брокер». Такой сервер отвечает за хранение данных (топиков, партиций и сообщений) и обработку запросов клиентов. Брокеры образуют собой ядро кластера Kafka. Их количество варьируется в зависимости от профиля нагрузки и потребностей в репликации и шардировании.
- Контроллеры представляют собой серверы, на которых запускается экземпляр Kafka в режиме «контроллер». Контроллеры хранят метаданные, информацию о брокерах и синхронизируют их состояние. Обычно используется три контроллера на кластер Kafka, каждый из которых находится в разной зоне доступности для повышения отказоустойчивости всего кластера.
В процессе установки этих составляющих могут возникнуть проблемы, связанные с конфигурацией зависимостей, требований к аппаратному обеспечению, настроек сетевой связанности и, конечно, определением оптимальных параметров балансировки нагрузки, шардирования и производительности кластера.
В предыдущих версиях Kafka (до 2.8) в качестве контроллера использовался ZooKeeper. Он выполнял роль базы для хранения метаданных о состоянии узлов кластера и расположении сообщений, позволял организовать репликацию, отказоустойчивость и шардирование. В новой версии можно обойтись без ZooKeeper. Теперь эту работу выполняет сервер Kafka в режиме контроллера. Он реализует новый механизм управления метаданными, известный как KRaft. Если вы планируете установку новой версии Kafka, то можете использовать этот механизм управления, чтобы избежать зависимости от отдельной службы ZooKeeper.
Помимо проблем установки и настройки Kafka, отмечу еще ряд трудностей:
- Отдельный инженерный вызов — приведение инфраструктуры к соответствию требованиям 152-ФЗ, PCI DSS или ISO 27001.
- Дальнейшая эксплуатацию кластера и экспоненциальный рост объемов данных могут потребовать масштабирования и наличия свободных ресурсов в горячем резерве.
- Организация системы резервного копирования и мониторинга состояния кластера потребует внедрения новых инструментов и развития новых компетенций.
Чтобы упростить работу с Kafka, мы в Selectel берем на себя работу, связанную с администрированием инфраструктуры, и ответственность за пул задач, с которым можно познакомиться ниже:
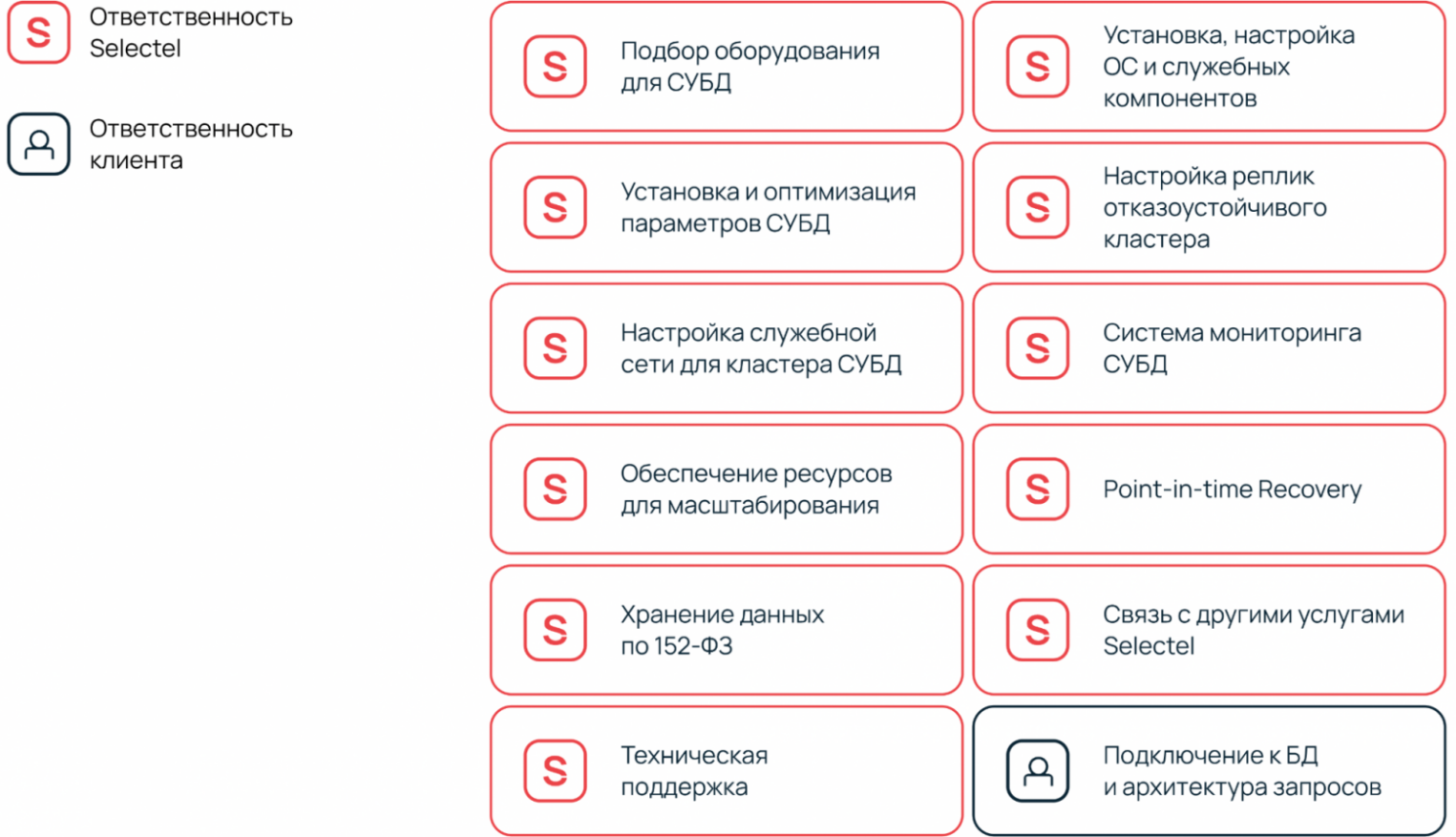
Сценарии использования Kafka как сервис
Рассмотрим несколько типовых бизнес-сценариев использования Managed Kafka в информационных системах:
- Компания разрабатывает приложения в cloud-native подходе: Kafka как сервис позволит ускорить разработку и доставку приложения для пользователей.
- Компании нужен горячий резерв высокопроизводительного оборудования, чтобы быстро масштабироваться при изменяющейся нагрузке.
- Компания хочет сократить стартовые затраты на инфраструктуру и оборудование или перенести ее на OPEX-модель.
- Компании нужна инфраструктура, которая использует лучшие практики безопасности и соответствует 152-ФЗ, PCI DSS, ISO 27001.
- Команда хочет ускорить исследования новых решений, проверку гипотез и тестирование приложений.
Отдельно выделю сценарий использования Kafka-as-a-service для stateful-приложений совместно с Managed Kubernetes для stateless-приложений. Такое сочетание серьезно ускорит time-to-market и снизит капитальные затраты на инфраструктуру для небольших команд.
Известные в мире примеры использования
Возможно, самый яркий пример использования Kafka — газета The NY Times, которая все статьи и правки за последние 160 лет хранит в Kafka. Однако рассмотрим еще несколько чуть менее известных примеров того, как крупные компании успешно используют эту технологию для обработки данных в реальном времени и повышают эффективности бизнес-процессов.
- LinkedIn, социальная сеть для профессионалов, разработала и внедрила Apache Kafka для обработки и передачи событий, в числе которых уведомления о новых связях, сообщения и действия пользователей. Это помогло им обеспечить реактивность и оперативность взаимодействия между пользователями.
- Netflix использует Apache Kafka для стриминга и обработки данных в реальном времени. Они создали платформу для сбора метрик, мониторинга, анализа и управления своими многомиллионными потоками данных, что помогает им предоставлять персонализированный контент и улучшать опыт пользователей.
- Uber использует Apache Kafka для обработки событий, связанных с заказами, платежами и другими операциями на платформе. Kafka помогает обеспечивать надежную и масштабируемую обработку данных в реальном времени, что необходимо для бесперебойной работы такой сложной системы.
- Airbnb применяет Apache Kafka для обработки и передачи потоков данных, связанных с бронированиями, отзывами и другой активностью на платформе. Это помогает им анализировать данные, улучшать рекомендации и предоставлять наилучший опыт пользователям.
- Twitter использует Apache Kafka для обработки потоков твитов и событий. Kafka позволяет сервису эффективно справляться с огромными объемами данных, обеспечивая оперативную доставку и анализ твитов в реальном времени.
- Walmart, крупнейшая розничная сеть в мире, использует Apache Kafka для обработки данных о продажах, инвентаре и покупательском поведении. Это помогает им улучшать управление запасами, анализировать тренды и оптимизировать процессы.
Кто еще:
- Различные банковские организации активно используют Apache Kafka для обработки банковских транзакций и мониторинга финансовых операций. Это помогает им оперативно реагировать на изменения в рыночных условиях и предоставлять финансовые услуги на высоком уровне.
- Глобальные поисковики используют Kafka для обработки поисковых запросов, сбора данных о поведении пользователей и анализа трафика на своих платформах. Это позволяет им улучшать качество своих продуктов и предоставлять более релевантный контент.
- Сервисы музыкального и видео стриминга используют Kafka для реализации подбора рекомендаций. Они анализируют данные в потоке, в истории прослушанных треков и, сопоставляя их с подобными событиями в соседних топиках, выдают пользователю рекомендации.
Заключение
Итак, мы рассмотрели особенности Apache Kafka, ее функциональность как элемента инфраструктуры. Также быстро создали небольшое приложение на базе managed-решения.
С помощью Managed Kafka вы можете значительно сократите время и ресурсы, которое потратите на самостоятельное развертывание. А мы со своей стороны позаботимся о настройках, надежности и поддержании инфраструктуры.





