Как быстро написать API на FastAPI с валидацией и базой данных
Разрабатываем приложение на FastAPI с использованием самого популярного стека и разворачиваем его на сервере.
Введение
В этой статье мы разработаем несложное приложение на FastAPI с использованием самого популярного стека на текущий момент, рассмотрим важные концепции работы с фреймворком, зададим базовую структуру проекта и развернем наше приложение на реальном сервере.
Подготовка окружения
Первым делом стоит создать виртуальное окружение для нашего проекта, в которое мы установим необходимые зависимости. В зависимости от операционной системы и способа установки Python может сработать одна из следующих команд:
python -m venv venv
python3 -m venv venv
py -m venv venv
Установка библиотек
Предлагаю сразу установить необходимые библиотеки с помощью следующей команды:
pip install fastapi uvicorn pydantic aiosqlite sqlalchemy
Если у вас возникли конфликты версий библиотек, обратитесь к их документации или к паку версий, использующемся в проекте:
aiosqlite==0.19.0
fastapi==0.109.0
pydantic==2.5.3
SQLAlchemy==2.0.25
uvicorn==0.25.0
Рассмотрим вкратце их предназначение.
- FastAPI — это популярный асинхронный фреймворк, позволяющий быстро писать API.
- Pydantic — это быстрая и обширная библиотека для валидации и сериализации данных. Она входит в список основных зависимостей FastAPI, так как они тесно связаны друг с другом.
- Uvicorn — библиотека, позволяющая запустить свой собственный веб-сервер.
- SQLAlchemy — самая известная библиотека для работы с реляционными базами данных через Python.
- Aiosqlite — асинхронный драйвер для работы легковесной базы данных SQLite, которую можно создать и распространять как обычный файл.
Первые наброски
Основной файл, через который будет запускаться наше приложение, — это main.py. Его нужно создать в корне той директории, где вы разрабатываете.
Проверим, что все работает корректно. Для этого создадим простейшее приложение на FastAPI с одним эндпоинтом (его также называют «ручкой» или «роутером»):
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def home():
return {"data": "Hello World"}
И запустим веб-сервер Uvicorn:
uvicorn main:app --reload
Обращаем внимание, что мы обязательно должны указать расположение переменной app для запуска приложения, а также флаг –reload, чтобы внесенные изменения тут же обновляли веб-сервер до последних версий кода.
Теперь, если перейти в браузере по адресу http://127.0.0.1:8000 или http://localhost:8000, мы увидим ответ веб-сервера: {“data”: “Hello World”}.
Работа Uvicorn в связке с FastAPI выглядит следующим образом:
- наш запрос поступает в Uvicorn;
- Uvicorn передает этот запрос в FastAPI;
- FastAPI запускает код, который мы написали, и возвращает ответ Uvicorn-у:
return {“data”: “Hello World”};
- Uvicorn возвращает ответ нам.
Если зайти по адресу http://localhost:8000/docs, то мы увидим удобный интерфейс для тестирования наших эндпоинтов.
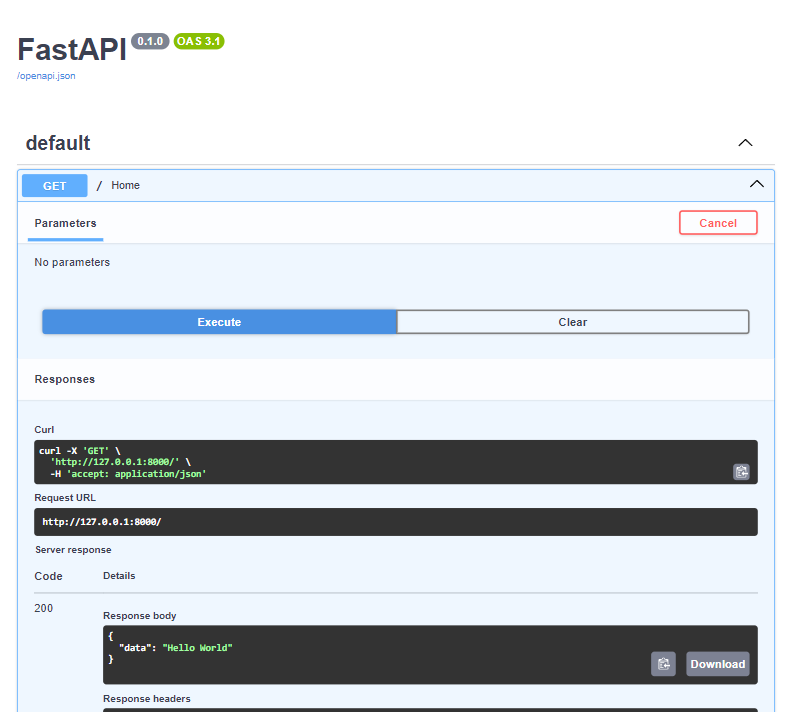
Если запустить наш запрос здесь, мы увидим тот же ответ: {“data”: “Hello World”}.
Валидация данных с Pydantic
Pydantic дает возможность валидировать данные через аннотации типов в Python. Давайте создадим простейшую схему для добавления новой задачи:
from pydantic import BaseModel
class STaskAdd(BaseModel):
name: str
description: str | None = None
@app.post("/")
async def add_task(task: STaskAdd):
return {"data": task}
В будущем нам пригодится схема для чтения задач из базы данных, у которой дополнительно будет параметр id (первичный ключ в таблице). Пропишем схему для чтения:
class STask(STaskAdd):
id: int
model_config = ConfigDict(from_attributes=True)
Обратите внимание, что мы наследуемся не от BaseModel, а от только что созданной схемы STaskAdd. В таком случае мы наследуем поля name и description и нам остается добавить только id. Мы также задаем атрибут model_config, о котором поговорим позже в разделе Репозиторий.
Сохраним файл, перейдем в документацию по адресу http://localhost:8000/docs:
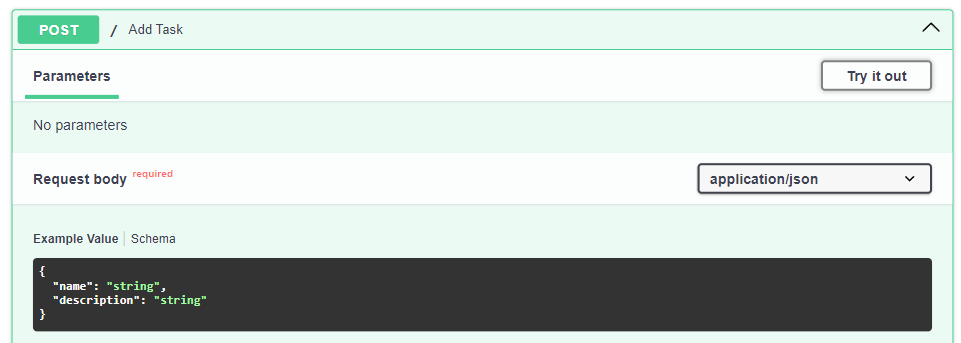
Ввод данных в эндпоинте.
Если нажать Try it out в правом верхнем углу, то нам предложат вручную отредактировать json, что не очень удобно. К тому же сложно понять, какие из полей являются обязательными. Чтобы улучшить опыт работы с документацией API, давайте изменим эндпоинт с добавлением задачи на следующее:
from fastapi import Depends
@app.post("/")
async def add_task(task: STaskAdd = Depends()):
return {"data": task}
В данной статье мы не будем разбирать особенности работы Depends, так как это продвинутая тема, требующая углубленного изучения. Сейчас достаточно убедиться, что вид эндпоинта в доке значительно улучшился.
Видим, что появилась понятная пометка для обязательного поля и его можно удобно заполнить в выделенной области:
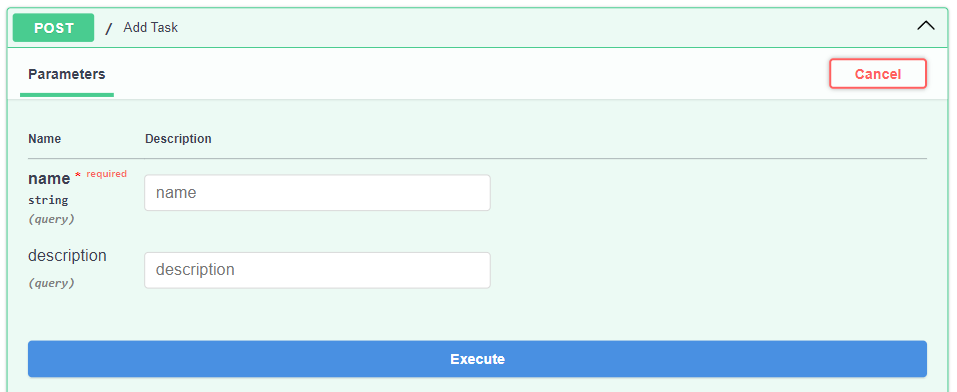
Работа с базой данных
SQLAlchemy — это мощная библиотека для работы с реляционными базами данных. Она учитывает максимальное количество особенностей и нюансов различных СУБД. Мы будем работать с асинхронной версией SQLAlchemy и базой данных SQLite. Для начала давайте создадим файл database.py рядом с файлом main.py и вставим следующий код:
from datetime import datetime
from sqlalchemy.ext.asyncio import async_sessionmaker, create_async_engine
engine = create_async_engine("sqlite+aiosqlite:///tasks.db")
new_session = async_sessionmaker(engine, expire_on_commit=False)
Здесь мы создаем асинхронное подключение, которое будет отвечать за отправку запросов в базу данных engine. Обратите внимание, что мы говорим SQLAlchemy, что будем использовать драйвер для асинхронного кода aiosqlite. После создания engine, с которым уже можно работать, мы дополнительно создаем фабрику сессий new_session. Сессия позволяет работать не с обычными списками и словарями, а с моделями данных, которые создаются через классы. Давайте создадим модель задач:
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column
class Model(DeclarativeBase):
pass
class TaskOrm(Model):
__tablename__ = "tasks"
id: Mapped[int] = mapped_column(primary_key=True)
name: Mapped[str]
description: Mapped[str | None]
Для создания моделей нам всегда нужен класс, от которого мы будем наследоваться. В нашем случае «родительским» классом является DeclarativeBase. Модель соответствует одной таблице в базе данных. Название таблицы мы задаем в атрибуте __tablename__. В базах данных каждая таблица обычно имеет столбец с уникальными значениями с названием id.
SQLAlchemy, как и Pydantic, использует аннотации типов для задания категорий столбцов. Модель TaskOrm полностью описывает таблицу внутри базы данных, задает первичные и внешние ключи, индексы, ограничения и т. п.
Чтобы таблица была создана внутри базы данных SQLite, необходимо добавить следующие функции в файл database.py:
async def create_tables():
async with engine.begin() as conn:
await conn.run_sync(Model.metadata.create_all)
async def delete_tables():
async with engine.begin() as conn:
await conn.run_sync(Model.metadata.drop_all)
Эти функции отвечают за создание и удаление таблиц в базе данных.
Давайте рассмотрим работу жизненного цикла приложения FastAPI и научимся создавать таблицу при запуске приложения и удалять при выключении. Для этого в файле main.py напишем функцию lifespan. При создании переменной app внутри FastAPI(…) зададим параметр lifespan со значением lifespan:
from contextlib import asynccontextmanager
from fastapi import FastAPI
from database import create_tables, delete_tables
@asynccontextmanager
async def lifespan(app: FastAPI):
await create_tables()
print("База готова")
yield
await delete_tables()
print("База очищена")
app = FastAPI(lifespan=lifespan)
Если у вас запущен Uvicorn с параметром –reload, то после сохранения файла main.py вы должны увидеть в терминале фразу «База готова». Это значит, что функция успешно запустила весь код до оператора yield. Код после него будет запущен при выключении Uvicorn, если вы нажмете комбинацию клавиш CTRL + C.
Запросы к базе данных
Для создания запросов к базе данных мы будем использовать SQLAlchemy Object Relational Mapper (объектно-реляционное отображение, ORM), который позволяет оперировать экземплярами классов как реальными строками из базы данных.
Создадим файл repository.py с простой функцией для добавления задачи:
from database import TaskOrm, new_session
async def add_task(data: dict) -> int:
async with new_session() as session:
new_task = TaskOrm(**data)
session.add(new_task)
await session.flush()
await session.commit()
return new_task.id
Функция использует фабрику сессий new_session и модель TaskOrm, чтобы добавить в таблицу tasks новую строку. Обратите внимание, что мы используем асинхронный контекстный менеджер async with new_session() as session, который позволяет автоматически закрывать сессию при выходе из менеджера, чтобы нам не приходилось каждый раз закрывать сессию вручную через session.close().
Строка new_task = TaskOrm(**data) создает новую строку, но пока хранит ее только внутри нашего FastAPI приложения — база данных еще ничего не знает про нее. Строка session.add(new_task) позволяет добавить новую строку в объект сессии, чтобы SQLAlchemy знала, какие изменения нужно будет отправлять в базу данных, однако по-прежнему мы ничего не сообщили базе данных о новой задаче.
Строка await session.flush() отправляет в базу данных SQL запрос вида INSERT INTO tasks (name, description) VALUES (‘Jack’, NULL) RETURNING id, но еще не завершает транзакцию, то есть изменения все еще не находятся внутри базы данных. Функция flush позволяет получить значение столбца id новой задачи, которое мы отдаем в конце функции.
Так как мы хотим, чтобы изменения оказались в базе данных, в конце мы пишем код await session.commit(), который оставляет/коммитит изменения в базе данных, завершая транзакцию.
Заметьте, что любой код, который не выполняется асинхронно, не взаимодействует с базой данных, а все асинхронные операции отправляют запросы в базу. Помните об этом, когда будете работать с объектом сессии.
После того, как мы добавим задачу, мы, скорее всего, захотим получить список всех задач. Для этого создадим еще одну функцию:
async def get_tasks():
async with new_session() as session:
query = select(TaskOrm)
result = await session.execute(query)
task_models = result.scalars().all()
return task_models
Здесь мы пишем простейший запрос типа SELECT, который отдаст нам все строки из базы данных. Учитывая, что мы просим выбрать все объекты класса TaskOrm, SQLAlchemy конвертирует ответ от базы данных к экземплярам модели TaskOrm. Обратите внимание, что полученный ответ result — это итератор, по которому нужно пройтись и выбрать все нужные результаты. Для этого мы вводим следующую команду:
result.scalars().all().
Больше про работу с SQLAlchemy можно узнать в этом плейлисте.
Паттерн «Репозиторий»
Обе функции обращаются к таблице tasks, поэтому будет логично объединить их в один класс. Такие классы, которые взаимодействуют с определенной таблицей и отвечают за функции добавления, изменения, выборки и удаления строк, называют репозиториями, так как они используют соответствующий паттерн.
Давайте создадим наш первый класс репозиторий, а заодно добавим конвертацию полученных данных в Pydantic-схемы:
from sqlalchemy import select
from database import TaskOrm, new_session
from schemas import STaskAdd, STask
class TaskRepository:
@classmethod
async def add_task(cls, task: STaskAdd) -> int:
async with new_session() as session:
data = task.model_dump()
new_task = TaskOrm(**data)
session.add(new_task)
await session.flush()
await session.commit()
return new_task.id
@classmethod
async def get_tasks(cls) -> list[STask]:
async with new_session() as session:
query = select(TaskOrm)
result = await session.execute(query)
task_models = result.scalars().all()
tasks = [STask.model_validate(task_model) for task_model in task_models]
return tasks
Теперь при добавлении задачи мы принимаем не случайный словарь, а Pydantic-схему, затем преобразуя ее в словарь при помощи data = task.model_dump(). Также, при отдаче всех задач мы предварительно конвертируем их в Pydantic-cхему STask.
Роутер
Остался последний шаг — создать роутер и добавить в него эндпоинты. Роутер — это сущность FastAPI, позволяющая создавать приложения с одним эндпоинтом не только в одном файле main.py, а во множестве. Таким образом, структура проекта будет легко читаема.
Создадим файл router.py и объявим в нем роутер для задач, «тасок»:
from fastapi import APIRouter
router = APIRouter(
prefix="/tasks",
tags=["Таски"],
)
Каждый эндпоинт будет иметь префикс /tasks, а также в документации по адресу /docs будет указан тег задачи. Теперь давайте добавим два эндпоинта: для добавления одной задачи и получения всех:
from repository import TaskRepository
from schemas import STask, STaskAdd, STaskId
@router.post("")
async def add_task(task: STaskAdd = Depends()) -> STaskId:
new_task_id = await TaskRepository.add_task(task)
return {"id": new_task_id}
@router.get("")
async def get_tasks() -> list[STask]:
tasks = await TaskRepository.get_tasks()
return tasks
Также давайте создадим отдельную схему STaskId, которая будет отображать возвращаемый ответ функции add_task:
class STaskId(BaseModel):
id: int
Чтобы включить данный роутер в наше приложение, достаточно в файле main.py импортировать файл router.py и добавить роутер с помощью метода include_router:
from router import router as tasks_router
app = FastAPI(lifespan=lifespan)
app.include_router(tasks_router)
В файле router.py мы используем созданный ранее репозиторий, аннотации типов и возвращаемый тип функций. Это позволяет нам добавить валидацию возвращаемых клиенту данных и улучшить документацию к API:
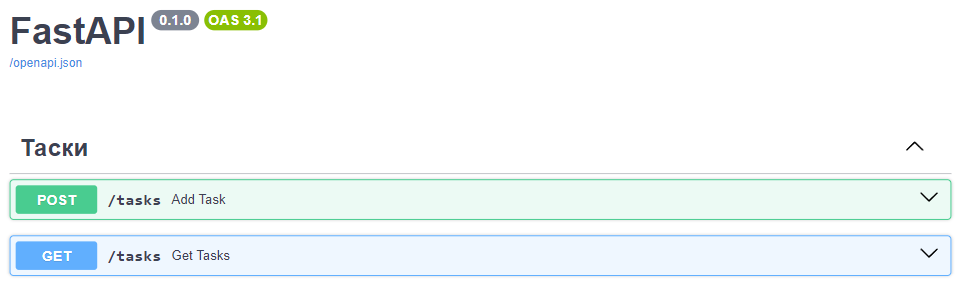
Так выглядит «ручка» GET /tasks:
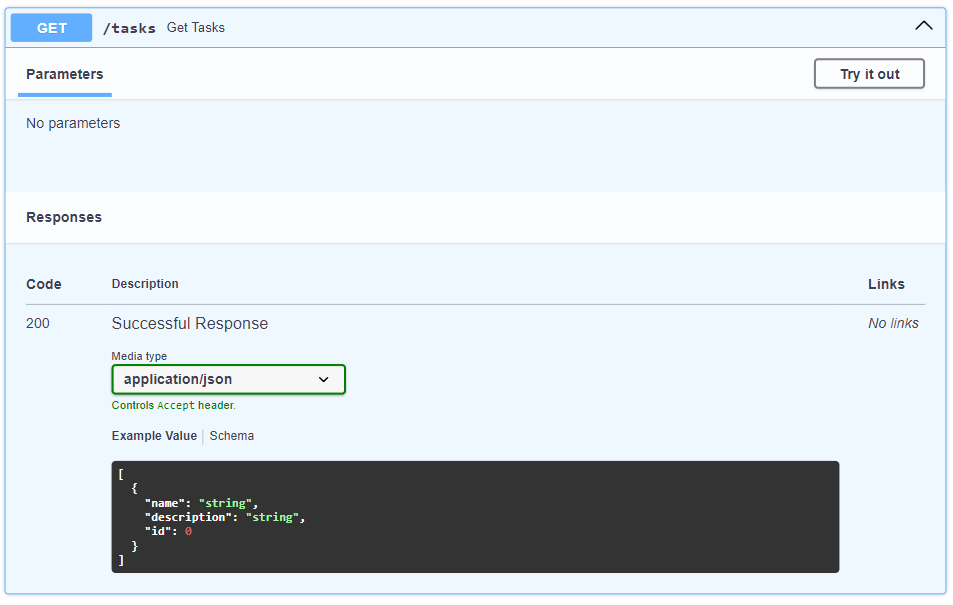
Готово! Мы задали базовую структуру проекта и теперь можем перейти на следующий этап — его развертыванию на реальном сервере.
Деплой проекта на облачный сервер
Подготовка
Перед началом давайте создадим файл со всеми зависимостями, которые используются в проекте. Делается это с помощью команды pip freeze > requirements.txt. У меня получился следующий файл:
aiosqlite==0.19.0
annotated-types==0.6.0
anyio==4.2.0
click==8.1.7
colorama==0.4.6
fastapi==0.109.0
greenlet==3.0.3
h11==0.14.0
idna==3.6
pydantic==2.5.3
pydantic_core==2.14.6
sniffio==1.3.0
SQLAlchemy==2.0.25
starlette==0.35.1
typing_extensions==4.9.0
uvicorn==0.25.0
Обычно развертывание приложений и сервисов на сервере происходит при помощи Docker. Для создания образа нашего приложения нам понадобится создать Dockerfile:
FROM python:3.11-slim
COPY . .
RUN pip install -r requirements.txt
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "80"]
Для запуска приложения нам нужно установить Python 3.11. Командой COPY перемещаем все файлы из текущего проекта в собираемый Docker-образ. Далее — устанавливаем все зависимости. В конце Dockerfile необходимо указать CMD и команду, которая будет запущена при старте контейнера. Напомню, что образ не запускает приложение, а лишь хранит информацию о всех папках и зависимостях, а вот контейнер — это запущенный образ.
Помимо Dockerfile добавим файл .dockerignore, чтобы в образе не оказалось папки с зависимостями самого Dockerfile:
venv
Dockerfile
Далее создадим файл .gitignore и GitHub-репозиторий:
__pycache__
venv
git init
git add .
git commit -m "initial commit"
git remote add origin REPO_URL
git push -u origin main
Загрузка проекта
Переходим в раздел Облачная платформа внутри панели управления и нажимаем Создать сервер:
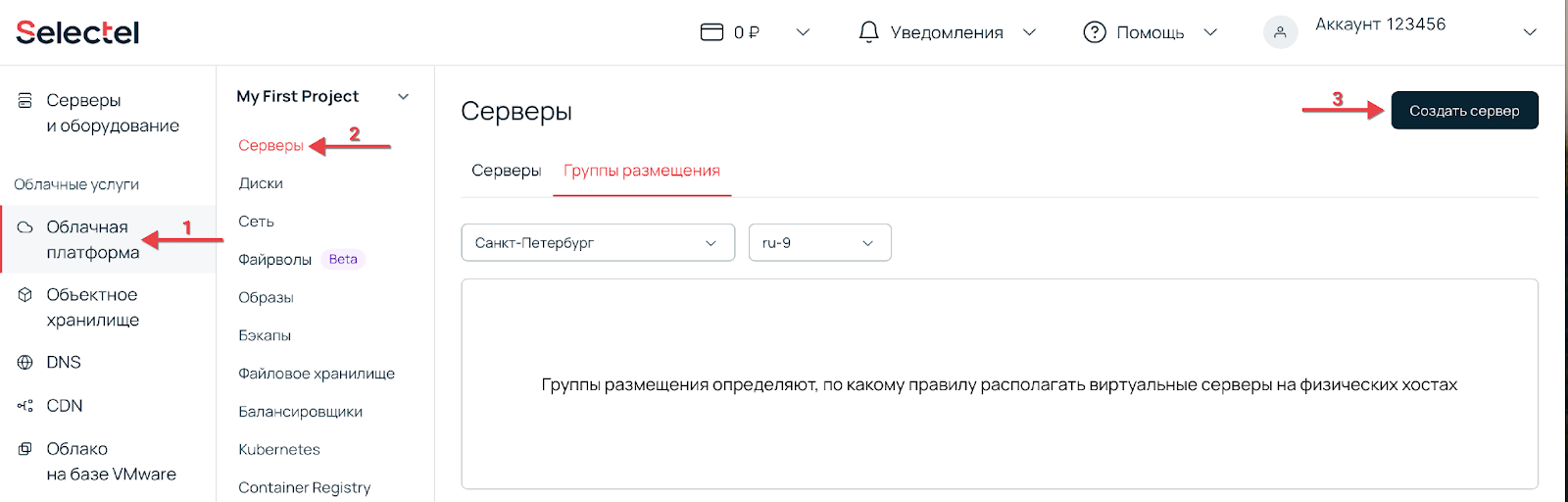
Для работы нашего приложения будет достаточно одного ядра vCPU с долей 10% и 512 МБ оперативной памяти.
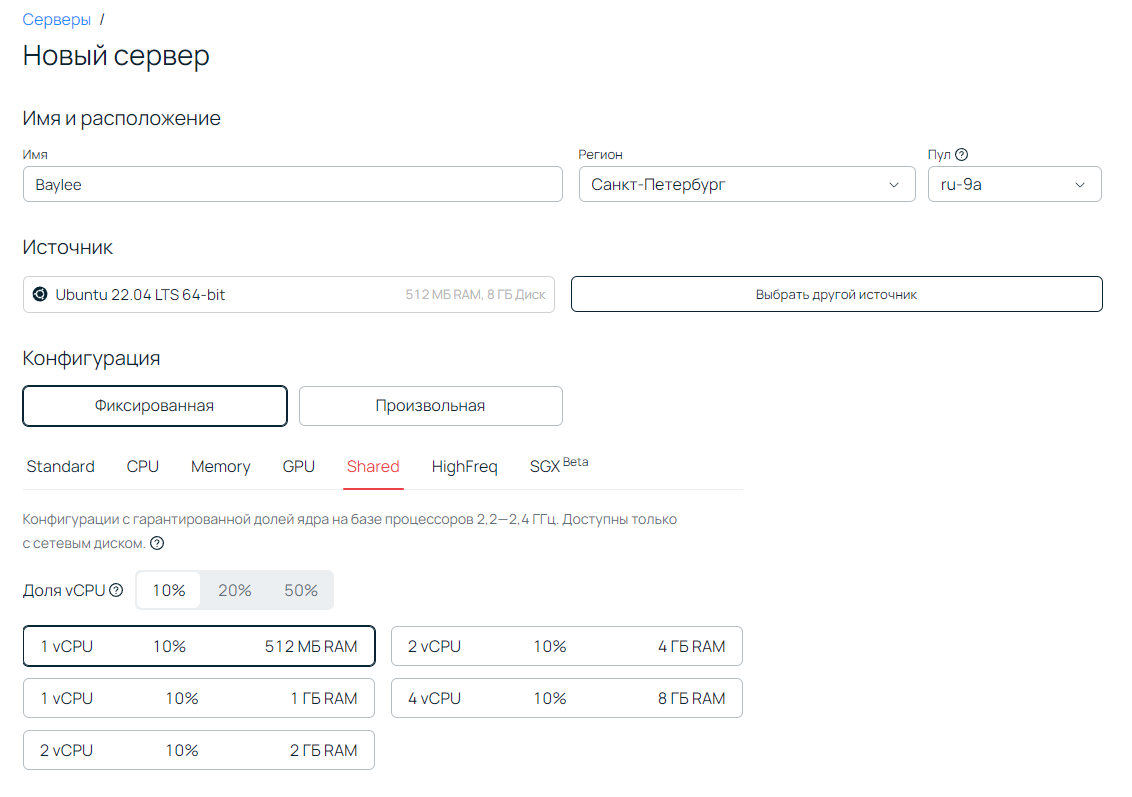
Стоимость аренды составит около 10 ₽/день. Сервер будет создан всего за минуту, после чего у вас появится доступ к консоли. Во вкладке Консоль видим логин пользователя и пароль — можем авторизоваться по SSH:
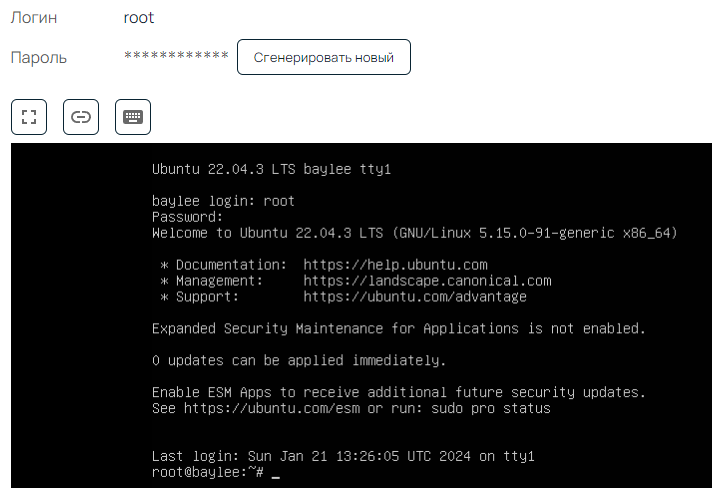
Отлично — сервер готов. Теперь можем перенести проект. Сперва установим необходимые зависимости: git и Docker. Инструкция взята с официального сайта:
sudo apt-get update
sudo apt-get install git
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
После установки git и Docker необходимо клонировать созданный ранее репозиторий:
git clone REPO_URL.git
Мы можем также использовать готовый репозиторий с помощью команды:
git clone https://github.com/artemonsh/fastapi_beginner_course.git
После клонирования проекта необходимо перейти в папку с проектом:
cd <название_папки>
И запустить команду для сборки образа fastapi_app и запуска контейнера на порту 80:
docker build . --tag fastapi_app && docker run -p 80:80 fastapi_app
Поздравляю! Теперь ваше приложение доступно по IP-адресу сервера, на него могут зайти другие пользователи и использовать ваши API.
Заключение
Мы научились реализовывать простейшее API на базе FastAPI, создавать базу и таблицы внутри нее при помощи SQLAlchemy, описывать схемы данных и валидировать их при помощи Pydantic. Полученные знания являются фундаментом для построения более сложных приложений.
Надеюсь, статья вдохновит вас на дальнейшие эксперименты и создание собственных проектов. Вы можете расширить функциональность, глубже погрузиться в возможности FastAPI и персонализировать приложение под ваши нужды.
Автор: Артем Шумейко, автор канала на YouTube.