Как веб-разработчику прокачать SEO с помощью кода и здравого смысла
Разбираем технические детали верстки веб-страниц, оптимизированных под поисковые движки.

SEO, или поисковая оптимизация, обычно ассоциируется только с производством контента, а роль веб-разработчиков в ней часто недооценивают. Однако именно они знают, как сделать красиво, функционально и так, чтобы целевая страница попадала в топ выдачи.
Интересными лайфхаками на тему SEO-оптимизации с нами поделился наш давний партнер и фулстек-разработчик Ulbi TV.
Кратко о SEO
SEO (search engine optimization, или поисковая оптимизация) — это оптимизация сайта для повышения его позиции в поисковой выдаче по запросам пользователей.
Когда мы делаем запрос в Google или другой поисковой системе, она стремится показать максимально релевантные страницы. То есть задача поисковика — из всего множества сайтов, в которых упоминаются ключевые слова, отдать нам самые подходящие.
Поисковики отбирают страницы по множеству факторов и ранжируют результаты в соответствии с ними. Очевидно, владельцы сайтов хотят оказаться как можно выше в поисковой выдаче. При этом все поисковики работают по-разному: по одному и тому же запросу Google и Яндекс могут выдать разную подборку страниц.
Основной фактор, который влияет на ранжирование, — контент. Но есть технические детали, над которыми работают SEO-специалисты, оптимизируя сайты под разные поисковые движки.
Как поисковики собирают информацию о веб-страницах, чтобы в дальнейшем ранжировать их по релевантности? Представим сайт в виде паутины: каждая ниточка — это ссылка, по которой можно попасть с одной страницы на другую. По этой паутине ползают пауки — краулеры. Они заходят на страницы, анализируют их, изучают контент, заголовки, настройки и прочее. Краулер зашел на страницу, что-то о ней записал, куда-то эту запись сохранил — он проиндексировал страницу.
В результате такой индексации формируются огромные справочники, в которых поисковые движки могут быстро найти нужную информацию, чтобы затем ранжировать сайты по релевантности и выдать их пользователю.
Роль семантики в SEO
Чтобы показать SEO с позиции веб-разработчика, сверстаем простой сайт.
1. Создаем файл index.html
В нем проделываем базовые вещи: указываем язык, кодировку и вьюпорт, который отвечает за отображение страницы на разных устройствах.
2. Указываем метатеги
Title. Это заголовок нашей страницы, один из самых важных параметров. Он отображается на странице с результатами поисковой выдачи и на вкладке с открытой страницей. В заголовок помещаем как можно больше ключевых слов. Его текст должен быть осознанным, а сам метатег — уникальным на каждой странице. Не забываем, что заголовок страницы значительно влияет на ее позицию в поисковой выдаче.
<title>Книга по JavaScript. Обучение с нуля</title>
Description. Это описание страницы. Оно может быть любым, но в него стоит добавить максимально много ключевых слов. Описание находится под заголовком в поисковой выдаче.
<meta name="description" content="Эта книга научит вас с нуля программированию на JavaScript ....">
3. Делаем семантическую верстку
Поисковые роботы, которые будут парсить нашу страницу, обязательно будут учитывать ее семантику. Ничего не мешает нам сверстать сайт на div-блоках, навешать нужные классы, якоря вроде onclick и так далее — это будет работать и красиво выглядеть. Однако с точки зрения удобства использования, доступности и семантики это неверно.
Существует так называемая семантическая верстка, когда для каждого блока страницы (секции, хедера, артикла, навигации, футера) используются семантически правильные теги. Например, если вы используете кнопку, то пусть это будет не </div> или </span> с классом button, а прямо тег </button>. Тогда на странице по умолчанию кнопка будет работать не только по клику мышкой, но и через нажатие клавиши Enter. Кстати, доступность страницы для людей с ограниченными возможностями тоже влияет на ее ранжирование.
То же касается и остальных элементов HTML. Соответствующие теги используем для ссылок (а для внешних ссылок — target=”_blank”, чтобы ссылка открывалась в новом окне), списков, подзаголовков и прочего. Еще раз: с точки зрения внешнего вида тот же подзаголовок можно сделать с помощью div-блока с тегом header — пользователь будет воспринимать такой элемент именно как заголовок или подзаголовок. Но с точки зрения семантики (и, как следствие, SEO) это не оптимальный подход. Кстати, основной текст страницы тоже пишем не в div-блоках, а в параграфах.
А вот закрытые для пользователей страницы, например с админкой, в SEO не нуждаются и даже индексироваться поисковиками не должны (дальше мы разберемся, как отключить индексацию отдельных страниц). На таких страницах как раз можно по-быстрому сверстать все в div-блоках.
Open Graph и красивые ссылки
Open Graph, или OG, — протокол разметки, который позволяет делать ссылки привлекательными и понятными. Придумали это разработчики из Facebook, а сейчас поддержка Open Graph имеется практически во всех соцсетях.
Например, ссылка без Open Graph в соцсетях будет просто кликабельным текстом. А ссылка с Open Graph отправляется вместе с заголовком, описанием и картинкой:
Нужно это не просто для красоты: хотя применение Open Graph напрямую не влияет на поисковую выдачу, оно улучшает отображение ссылок в соцсетях и дает пользователю дополнительную информацию о странице, на которую ведет линк.
Добавление Open Graph начинаем с заполнения метатегов. Основных их пять: тип, url, заголовок, описание и изображение. В коде все это выглядит так:
<meta property="og:type" content="website">
<meta property="og:url" content="https://ya.ru">
<meta property="og:title" content="Это og дескрипшн">
<meta property="og:description" content="это og дескрипшн">
<meta property="og:image" content="https://ir.ozone.ru/s3/multimedia-d/wc1000/6029228593.jpg">
Если хотите увидеть OG-разметку на любом сайте, зайдите на страницу, выберите в контекстном меню опцию Просмотреть код, в поиске по странице введите «og». На крупных сайтах, особенно маркетплейсах, вы точно найдете теги og:title, og:description, og:image, og:url и прочее. Бывает интересно походить по разным сайтам и посмотреть, как там заполнены теги: иногда можно извлечь для себя что-то полезное.
В итоге наш простой HTML будет выглядеть вот так:
<!doctype html>
<html lang="ru">
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Книга по JavaScript. Обучение с нуля</title>
<meta name="description" content="Эта книга научит вас с нуля программированию на JavaScript ....">
<meta name="keywords" content="JS, JavaScript, Обучение JS">
<meta property="og:type" content="website">
<meta property="og:url" content="https://ya.ru">
<meta property="og:title" content="Это og дескрипшн">
<meta property="og:description" content="это og дескрипшн">
<meta property="og:image" content="https://ir.ozone.ru/s3/multimedia-d/wc1000/6029228593.jpg">
<!-- <meta name="robots" content="index">-->
<!-- <meta name="robots" content="index, nofollow">-->
<!-- <meta name="robots" content="noindex">-->
<!-- <meta name="robots" content="follow">-->
<!-- <meta name="robots" content="nofollow">-->
<!-- <meta name="robots" content="all">-->
<!-- <meta name="googlebot" content="index">-->
<!-- <meta name="yandex" content="noindex">-->
</head>
<body>
<img src="" alt="надо заполнять" srcset="400x400.png 500w, 700x700.png 800w">
<h1>
Hello world
</h1>
<!--<h2></h2>-->
<!--<h3></h3> именно заголовки-->
<!--<p class="header5">-->
<!--</p>-->
<!--<ul>-->
<!-- <li>1</li>-->
<!-- <li>2</li>-->
<!-- <li>3</li>-->
<!--</ul>-->
<!--<header>-->
<!-- <div class="button"></div>-->
<!-- <button></button>-->
<!--</header>-->
<!--<article></article>-->
<!--<section></section>-->
<!--<nav></nav>-->
<!--<footer></footer>-->
<!--<a href="ya.ru" target="_blank"></a>-->
<!--<p>текст в параграфы</p>-->
</body>
</html>
Деплой HTML-кода на облачный сервер
Итак, мы создали HTML-документ по всем правилам семантической верстки и применили OG-разметку. Теперь задеплоим его на облачный сервер. Можно собрать минимальную конфигурацию за 30 рублей в день, потому что сейчас большие мощности нам не нужны.
Идем в панель управления и переходим в раздел Облачная платформа.
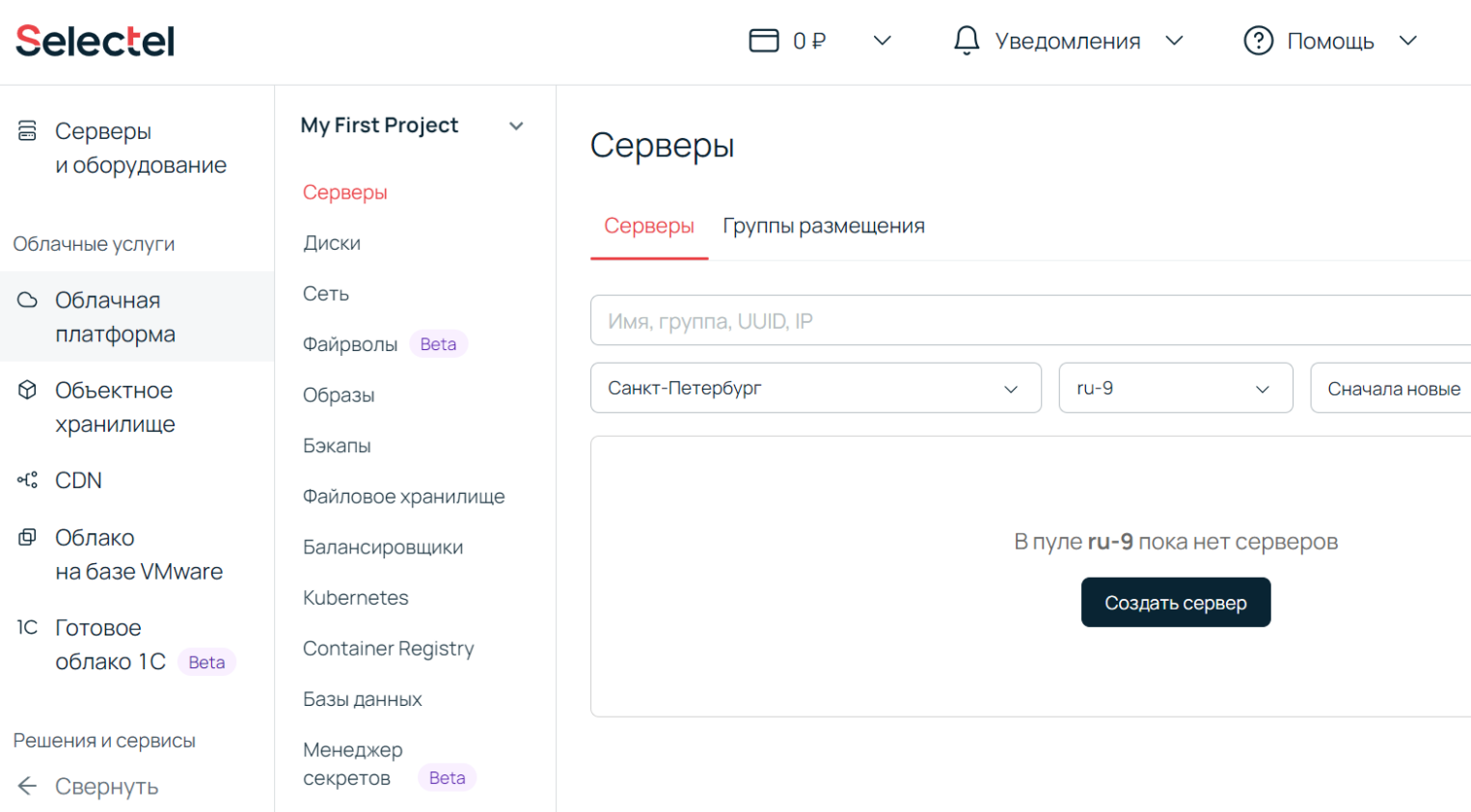
Здесь создаем сервер произвольной конфигурации. Для простого HTML мы можем обойтись одним ядром vCPU, 512 МБ оперативной памяти и 8 ГБ места на SSD:
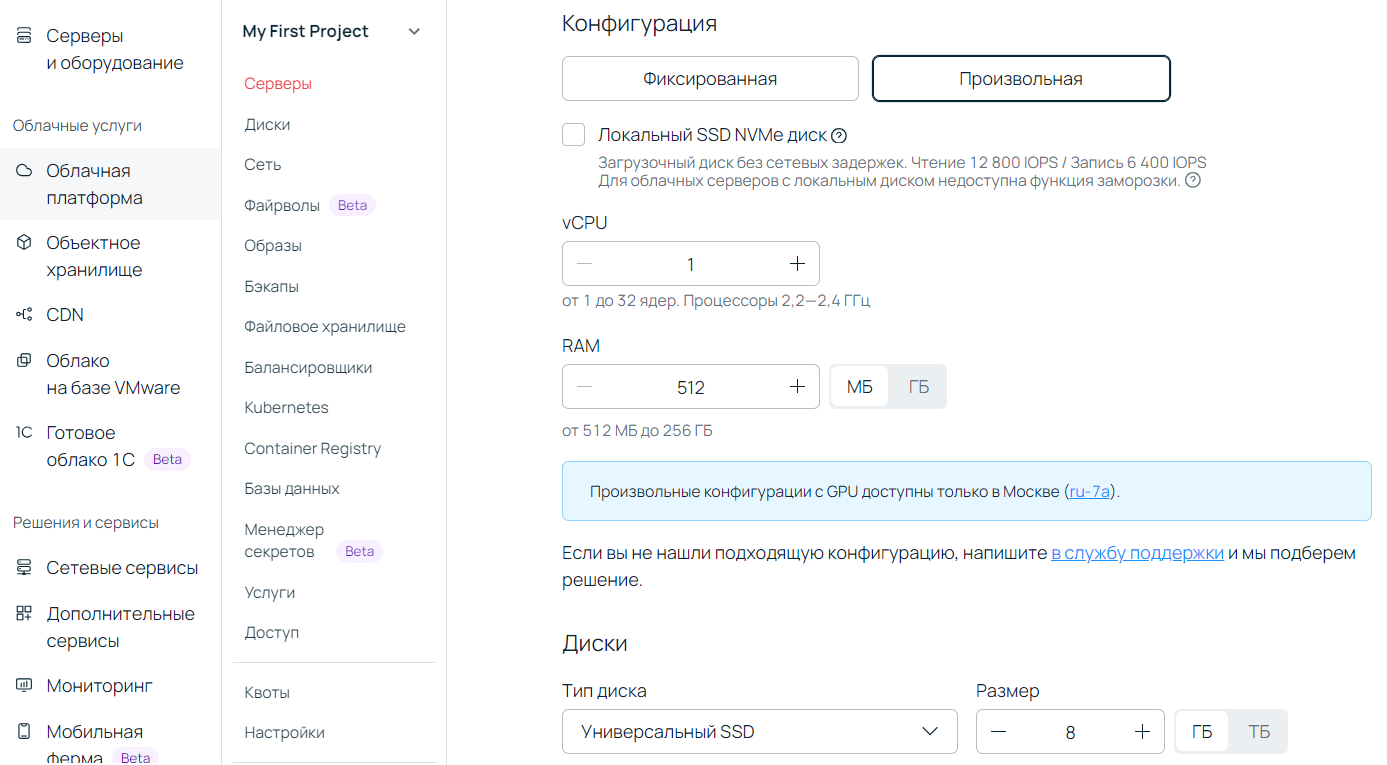
Создаем сервер и подключаемся к серверу по SSH — отлично, осталось подготовить веб-сервер.
1. Чтобы устанавливать только актуальные пакеты, обновляем репозиторий:
sudo apt update
2. Устанавливаем Nginx, чтобы раздавать наш index.html:
sudo apt install nginx
3. В папке sites enabled устанавливаем Vim, чтобы редактировать текстовые файлы:
/etc/nginx/sites-enabled# apt install vim
4. Находим root — это место, где будет храниться HTML-файл. В нашем случае это папка var/www/html. Идем туда и создаем index.html:
vim index.html
5. Копируем в открывшийся текстовый редактор наш HTML-код, выходим из Vim.
6. Перезапускаем Nginx:
sudo service nginx restart
Чтобы убедиться, что все работает, вставляем в адресную строку браузера публичный IP-адрес облачного сервера. Видим заветную строку «Hello world», все работает.
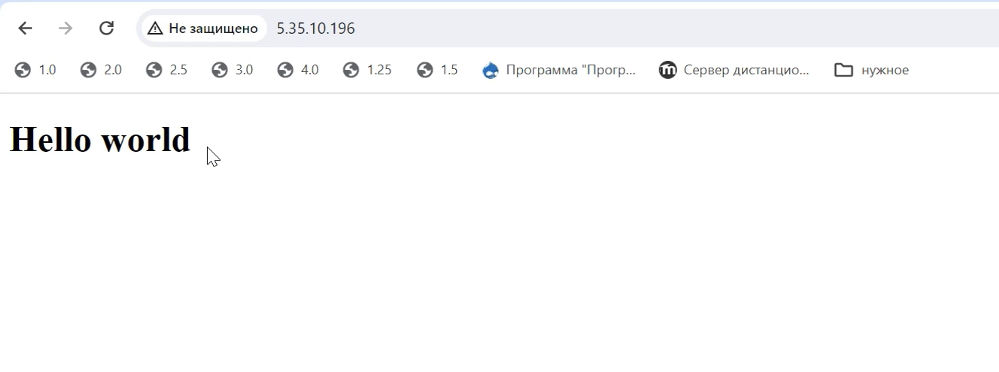
Но IP-адреса все же недостаточно: если мы вставим его, например, в Telegram, мессенджер его никак не обработает, потому что это не ссылка.

Чтобы получить ссылку, нужен домен. Мы берем готовый от Ulbi TV, но вообще получить новый домен можно на любом регистраторе.
Указываем для домена IP-адрес нашего сервера, чтобы связать их. DNS-серверу потребуется какое-то время, чтобы все обработать — от 2 часов до суток. И вот, домен уже выдает «Hello world».
Теперь самое интересное. Скидываем эту ссылку в соцсети и видим, как красиво туда подтянулась наша OG-разметка:
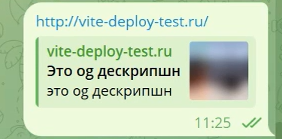
Работа со ссылками в контексте SEO
Человекопонятные ссылки
Когда вы видите ссылку https://cars.qq/auto/123/model/456, что вы можете предположить о содержании страницы, на которую она ведет? Из домена очевидно, что это что-то о машинах, и на этом все. А когда вам присылают ссылку https://cars.qq/auto/bmw/model/m5, вы сходу понимаете, что она ведет на страницу, связанную с BMW М5: это какая-то статья или объявление о продаже автомобиля. Этот url понятен человеку, там нет никаких идентификаторов или непонятных чисел.
Вот еще пара примеров из интернета. Ссылки слева — неинформативные, включающие index.php, category и цифры. Ссылки справа — осмысленные и легкочитаемые. Кстати, ключевые слова в ссылках тоже помогают в ранжировании страницы.

Числовой идентификатор в линках вполне уместен. Например, в ссылке на страницу сайта объявлений он точно будет. Но при этом первая часть ссылки все равно должна быть «человекопонятной», и только во второй ее половине, которая почти не влияет на ранжирование, появится уникальный идентификатор с набором цифр и букв. «Человекопонятностью» ссылок не стоит пренебрегать, если хотите выводить свои страницы в топ поисковой выдачи.
Канонические ссылки
Представим, что у нас есть две ссылки, которые ведут на одну и ту же страницу: исходный прямой url и тот, что сформировался при работе с категориями или фильтрами. Получается, у нас есть дубликат ссылки — это плохо. По сути, это мусорный контент, который тратит краулинговый бюджет и конкурирует с исходным линком при индексации поисковиками.
Чтобы этого избежать, указываем каноническую ссылку — индексироваться будет только она, а остальные перестанут восприниматься как дубликаты. Для этого идем в блок header HTML-документа и указываем линк, в котором rel=”canonical”, а в href размещаем прямую ссылку на страницу. Вот так это выглядит в коде со страницы Хабра:
<link data-vue-meta="ssr" href="https://habr.com/ru/companies/selectel/articles/788694/" rel="canonical" data-vmid="canonical">
Чтобы канонические ссылки всегда имели унифицированный вид, используются базовые редиректы. Их можно настроить на уровне Nginx-конфига. Редиректы автоматически перенаправляют пользователей со страницы с www в адресе на страницу без www, с http — на https (http вообще нигде не должен фигурировать), со страниц без / в конце адреса — на страницы с / в конце.
Другие важные особенности SEO
Теперь разберем несколько важных нюансов, которые помогут более тонко настроить индексацию страниц, а также улучшить пользовательский опыт.
Контроль поисковых движков
Метатег robots
При индексации поисковые роботы действуют по определенным алгоритмам, которые нас не всегда устраивают. Мы можем запретить роботам некоторые действия.
В HTML-документе указываем метатег <meta name=”robots” content=”index”>. Содержание его контентной части определяет действия робота. Запись index — значение по умолчанию, при нем робот будет индексировать страницу. Если указать “noindex”, страница индексироваться не будет.
То же работает и с другими контентными значениями:
- follow разрешает роботу ходить по ссылкам, nofollow — запрещает;
- archive — показывать ссылку на сохраненную копию в результатах поиска, noarchive — не показывать;
- noyaca — не использовать сформированное автоматически описание;
- all — использовать директивы index и follow;
- none — использовать директивы noindex и nofollow.
С помощью метатега robots можно запретить индексировать страницу в Яндексе, но сохранить индексацию для Google:
<meta name="googlebot" content="index">
<meta name="yandex" content="noindex">
Разрешающие директивы имеют приоритет над запрещающими: если не прописывать метатег noindex, страница и ссылки по умолчанию будут индексироваться всеми поисковиками. Метатеги нужны только тогда, когда мы хотим что-то запретить.
Файл robots.txt
Этот файл нужен, чтобы разрешить или запретить индексирование разделов или страниц сайта для разных роботов. Хотим исключить какую-то страницу сайта из индексации для всех поисковиков — без проблем. То же самое, если хотим сделать, чтобы какая-то страница индексировалась Яндексом, но не индексировалась системой Google.
Вот так мы запрещаем поисковику Google индексировать страницу с контактами:
User-agent: Googlebot
disallow: /contacts
А так, поставив *, запрещаем Яндексу индексировать все страницы раздела с админкой:
User-agent: Yandex
disallow: /admin/*
Из важного: этот файл должен находиться в корне проекта, чтобы робот смог до него достучаться, и быть не более 500 КБ.Посмотреть содержимое файла robots.txt для любого сайта просто: достаточно к ссылке на главную страницу добавить robots.txt после /. Например, содержимое файла для сайта Selectel смотрим здесь: https://selectel.ru/robots.txt.
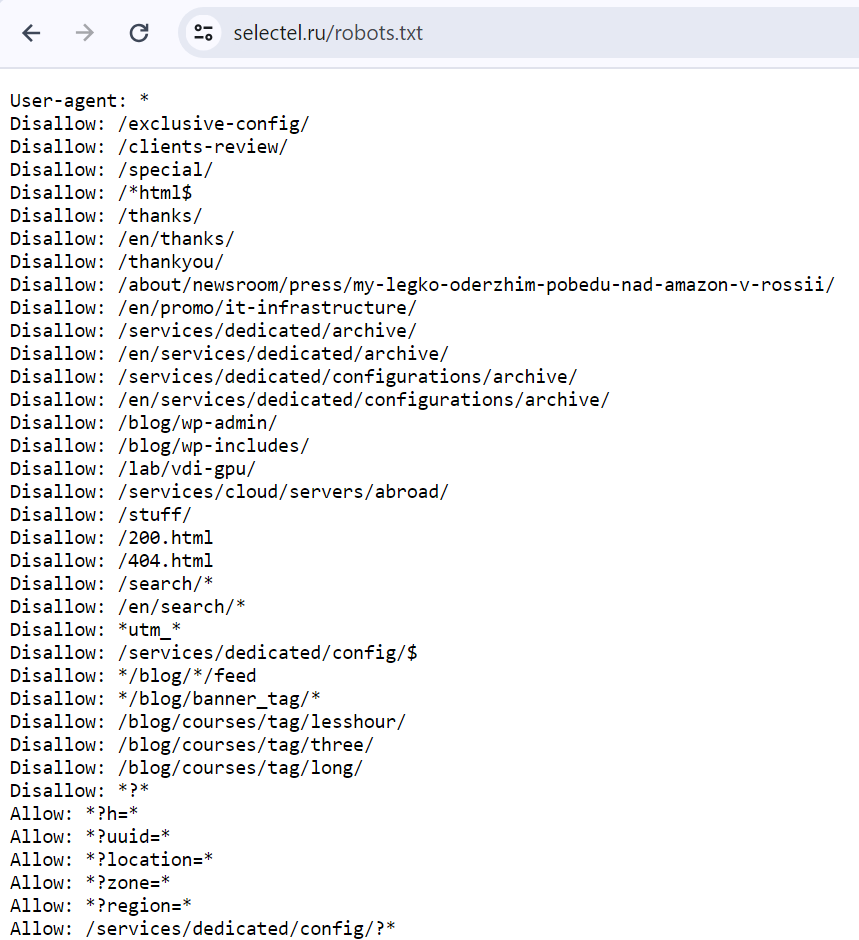
Все, что не запрещено, считаем разрешенным.
В конце документа есть ссылки, ведущие на sitemap.

Sitemap, или карта сайта, — это XML-документ, в котором указывается актуальная структура сайта со всеми ссылками и датами, когда эти ссылки изменялись. Здесь для каждой страницы можно задать четыре свойства: адрес самой страницы (тег <loc></loc>), дата последнего обновления (<lastmod></lastmod>), частота изменения страницы (<changefreq></changefreq>) и приоритет (<priority></priority>). Например, если вы хотите, чтобы какие-то страницы индексировались лучше других, для каждой их них можно установить приоритет индексации от 0 до 1 с шагом 0,1.
Sitemap строится из канонических ссылок и имеет ограничение по размеру в 50 МБ. Если страниц и ссылок так много, что 50 МБ не хватает, или вы хотите создать большую древовидную структуру, то внутри базового sitemap можно разместить ссылки на другие файлы sitemap. Чтобы индексатор узнал о том, что у вас есть эта карта сайта, указываем в robots.txt ссылку на sitemapindex.xml (как на скрине выше).
Важно понимать, что sitemap не нужен, если сайт содержит всего пару десятков страниц. Это необходимо только для сайтов с большой сложной структурой ссылок и страниц, когда требуется гарантированно проиндексировать нужные канонические ссылки и исключить из индексации некоторые страницы. Огромный XML-файл не заполняется руками. Это делается автоматически: с помощью скрипта или генератора.
Поддержка мобильных устройств
Есть такая технология — AMP, или Accelerated Mobile Pages. Проще говоря, она позволяет разрабатывать быстрые версии страниц для мобильных устройств. При этом Google лучше ранжирует такие страницы.
Естественно, эта технология, как и в целом оптимизация сайта под мобильные устройства, нужна не всем. Скажем, Хабр очевидно заточен под десктопных пользователей, а на какой-нибудь маркетплейс или сайт с объявлениями, наоборот, почти все заходят со смартфонов.
Как именно работает AMP, можно почитать в документации. В контексте SEO самое важное, что Google при индексации и ранжировании результатов отдает предпочтение именно быстрым AMP-страницам. Он определяет их по специальным тегам, которые добавляются при разработке.
Микроразметка
Микроразметка с точки зрения пользователя — это дополнительная информация под ссылкой в поисковой выдаче. Здесь могут отображаться цены на товары, расписание сеансов в кино или театре, хлебные крошки и так далее. Во всех случаях смысл микроразметки в том, чтобы дать пользователю дополнительную полезную информацию прямо на странице с результатами поиска.
Микроразметка пишется достаточно легко, подробная и понятная инструкция лежит здесь. Благодаря микроразметке можно вынести в результаты поиска наиболее важную для пользователя информацию: контакты, расписания, цены и прочее. Убедиться, что разметка сделана правильно, можно с помощью валидатора.
Проверка поисковой оптимизации
Метрики
Есть три наиболее важные метрики с технической точки зрения.
- LCP (Largest Contentful Paint) — время, за которое загрузился самый большой видимый элемент страницы. Хороший показатель — не более 4 секунд, отличный — не более 2,5 секунд. Очевидно, если весь бандл и фронтенд весят 200 КБ, они загрузятся быстро. Если же бандл не оптимизирован, весит 5 МБ и все подгружается одним цельным куском, на загрузку страницы может уйти секунд 10, а в случае с нестабильным интернетом — еще больше.
- FID (First Input Delay) — время до первой интерактивности. Другими словами, это время с момента загрузки страницы до появления у пользователя возможности взаимодействовать с ней: вводить текст, нажимать кнопки, переходить по ссылкам и так далее. Если FID укладывается в 0,3 секунды, все хорошо. Если нет, над сайтом стоит поработать. FID значительно меньше LCP, потому что какие-то элементы страницы могут подгружаться медленно или асинхронно и, пока они не загрузились, пользователь уже может взаимодействовать с другими элементами.
- CLS (Cumulative Layout Shift) — метрика, которая отвечает за визуальную стабильность. Сталкивались с ситуацией, когда хотите нажать на какую-нибудь кнопку, а тут «Бах!» — где-то сверху подгружается еще один блок, кнопка смещается вниз, и вы нажимаете на что-то не то? Это пример визуально нестабильной страницы, и такого, конечно, быть не должно. Даже если элементы страницы подгружаются асинхронно, до полной загрузки вместо них должна быть заглушка, чтобы верстка не съезжала и пользователи не испытывали дискомфорта. CLS измеряется в баллах, показатель не должен превышать 0,25.
Для измерения метрик удобно использовать сервис Page Speed Insights от Google. Разумеется, кроме LCP, FID и CLS здесь можно посмотреть огромное количество других параметров, связанных с производительностью, доступностью, безопасностью и так далее. Удобно, что можно измерять параметры и для десктопной, и для мобильной версии сайта.
В браузере есть похожий встроенный инструмент — Lighthouse, на основе которого и сделан Page Speed Insights. Принцип работы прост: переходим на нужную страницу, нажимаем F12 и выбираем вкладку Lighthouse. Задаем нужные настройки, нажимаем Analyze page load, ждем и получаем результат анализа. В целом, все практически то же самое, что в Page Speed Insights, хотя по отдельным метрикам показатели могут незначительно различаться.
Валидность HTML
Сайты с невалидным HTML-кодом гораздо хуже индексируются поисковиками, медленнее загружаются, а иногда и вовсе объявляются опасными. Проверить валидность можно с помощью классического W3-валидатора, в котором достаточно указать адрес нашей страницы.
В нашем случае HTML-документ небольшой и проверять его даже не так интересно, как полноценный сайт. Валидатор выдает одно предупреждение на вьюпорт, и на этом все. В реальности, когда речь идет о настоящем большом сайте, ошибок может быть очень много и они часто бывают незаметны. Например, незакрытый div — очень популярная история, которая не влияет на пользовательский опыт, но негативно сказывается на индексации сайта поисковиками.
Валидаторы хорошо справляются с поиском ошибок в верстке, поэтому пренебрегать ими не стоит. Чем больше ошибок останутся незамеченными, тем более подозрительной будут считать страницу поисковики, понижая ее приоритет в выдаче.
Краулинговый бюджет
Количество страниц, которые может обойти поисковый робот, ограничено. При этом практически на любом сайте есть страницы, которые вообще не должны индексироваться: админские разделы, дубликаты и прочее. Их стоит исключить из индексации, чтобы повысить другие страницы сайта в ранжировании поисковой выдачи.
Важно понимать, что заниматься этой работой стоит тогда, когда вы боретесь за десятые и сотые доли процента SEO. Это актуально, например, для маркетплейсов-гигантов. Если у вас небольшой сайт, лучше отложить оптимизацию краулингового бюджета и заняться более актуальными вопросами: улучшить качество контента, поработать с ключевыми словами, настроить Open Graph и так далее.
Заключение
Ключевым фактором SEO остается контент. Тем не менее, технические детали также важны: семантика, валидный HTML, канонические ссылки, ключевые слова в линках, AMP и так далее — все это помогает поднять страницу в результатах поисковой выдачи.




