Как настроить автоскейлинг инференса в Kubernetes
В инструкции расскажем, зачем нужен автоскейлинг GPU-ресурсов, как настроить масштабирование реплик в Kubernetes по трафику, а также как сделать свой высоконагруженный ChatGPT.
Нагрузка в ML Production
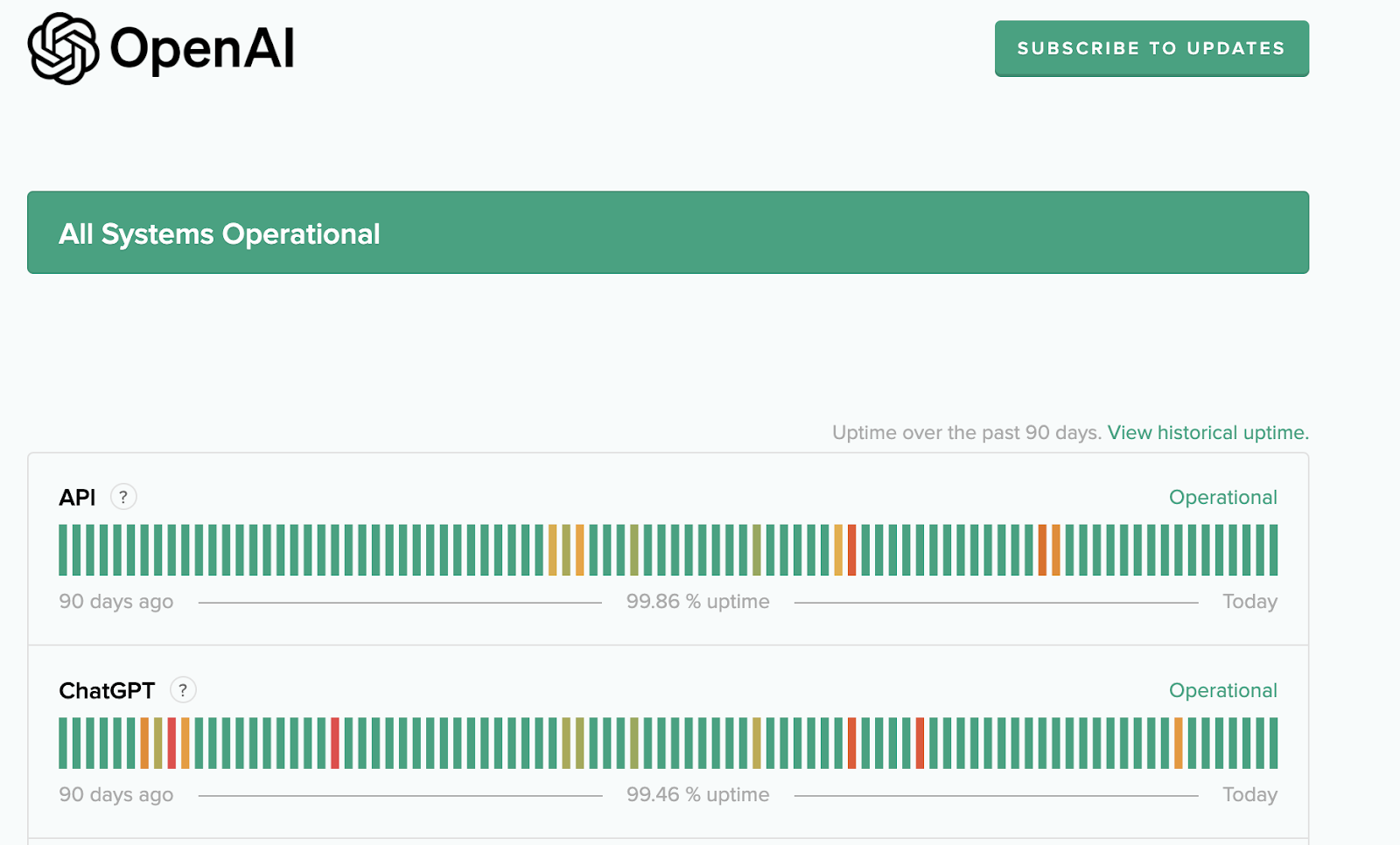
Лучше всего рассказывать про нагрузку ML- или инференс-сервисов на примере ChatGPT. Чтобы поддерживать свою инфраструктуру, OpenAI использует 3 617 серверов HGX A100. Это позволяет обеспечить MAU от 100 до 500 млн активных пользователей в месяц.
Если посмотреть на статистику последних 90 дней работы ChatGPT, можно увидеть, что даже такой IT-мастодонт не всегда справляется с входящим трафиком — обратите внимание на красные черты доступности сервиса:
Сам инференс почти не отличается от обычного веб-сервиса. Пользователь отправляет на эндпоинт запрос, затем модель делает предположение по нашему запросу и возвращает ответ в том же формате — например, в JSON. Чтобы справиться с большой нагрузкой, необходимо развернуть больше реплик. Для больших реплик нужно больше свободных ресурсов. Облако отлично подходит под такие системы, так как именно там есть свободные ресурсы под дополнительные входящие нагрузки (но конечно не во всех кейсах).
И вот мы хотим реализовать инференс-продакшн, да еще и с использованием GPU в облаке, например, на основе Selectel Managed Kubernetes (MKS). Давайте разберемся, с чем нам предстоит столкнуться.
Как работает автоскейлинг нод в K8s
Начальное состояние нашей системы — развернутый кластер Managed Kubernetes с одной нодой и GPU. На ноде крутится инференс-сервис, на который можно отправлять HTTP-запросы, например, как на модель gpt2.
За поддержку сервисов для работы с видеокартами отвечает GPU-оператор. Подробнее про него читайте в моей предыдущей статье.
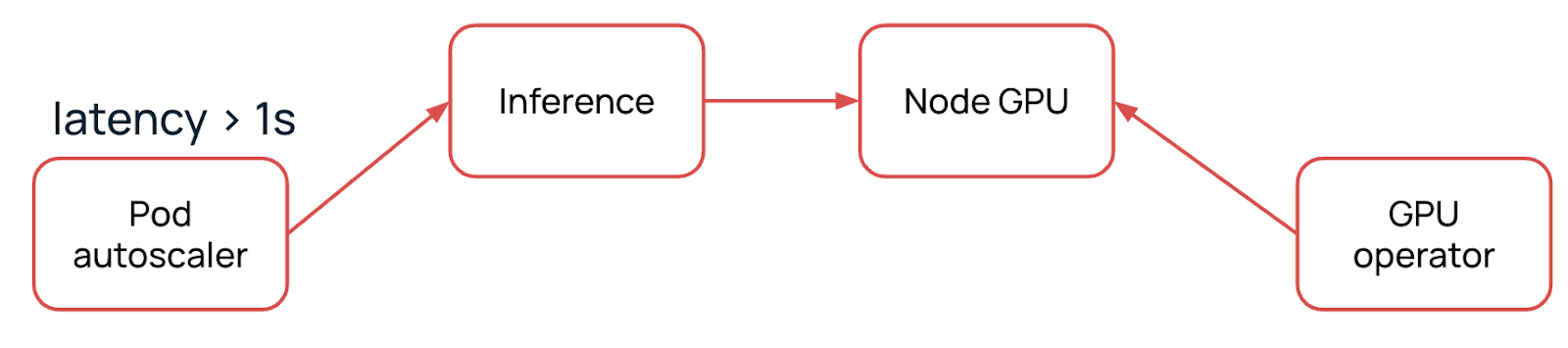
Далее мы подаем трафик на нашу реплику и замечаем, что клиенты стали получать ответы от инференса с задержкой больше одной секунды. Что происходит дальше с нашей системой? Рассмотрим подробнее.
Horizontal Pod Autoscaler
В дело вступает HPA (Horizontal Pod Autoscaler). Мы заранее заложили в него требование, что задержка запросов не должна превышать секунду. Как только это происходит, система разворачивает еще одну реплику нашего сервиса.
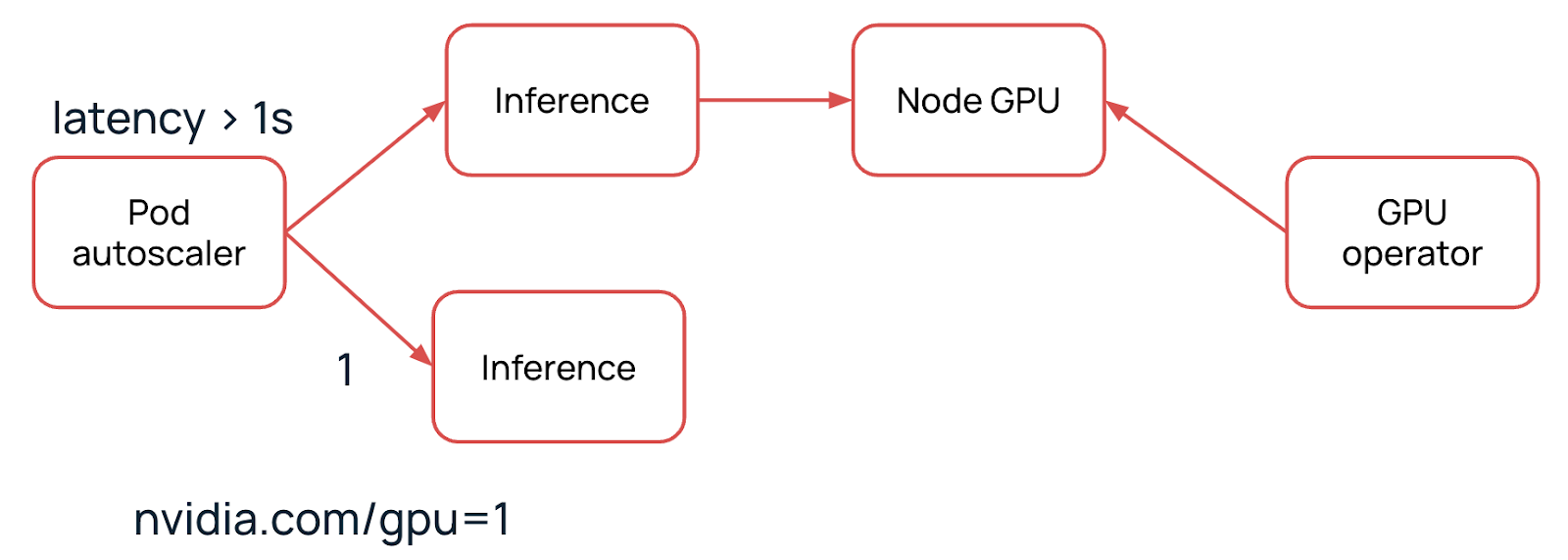
Когда новая реплика поднимается, то требует ресурс nvidia.com/gpu=1, который отвечает за наличие GPU на ноде. В данном случае у нас нет доступной ноды с этим ресурсом.
K8s autoscaler
В облаке Selectel для реализации автоскейлинга нод используем форк этого репозитория. Автоскейлер проверяет наличие ресурсов — CPU, RAM и т. д. — и смотрит за ресурсом nvidia.com/gpu, которого не хватает для новой реплики.
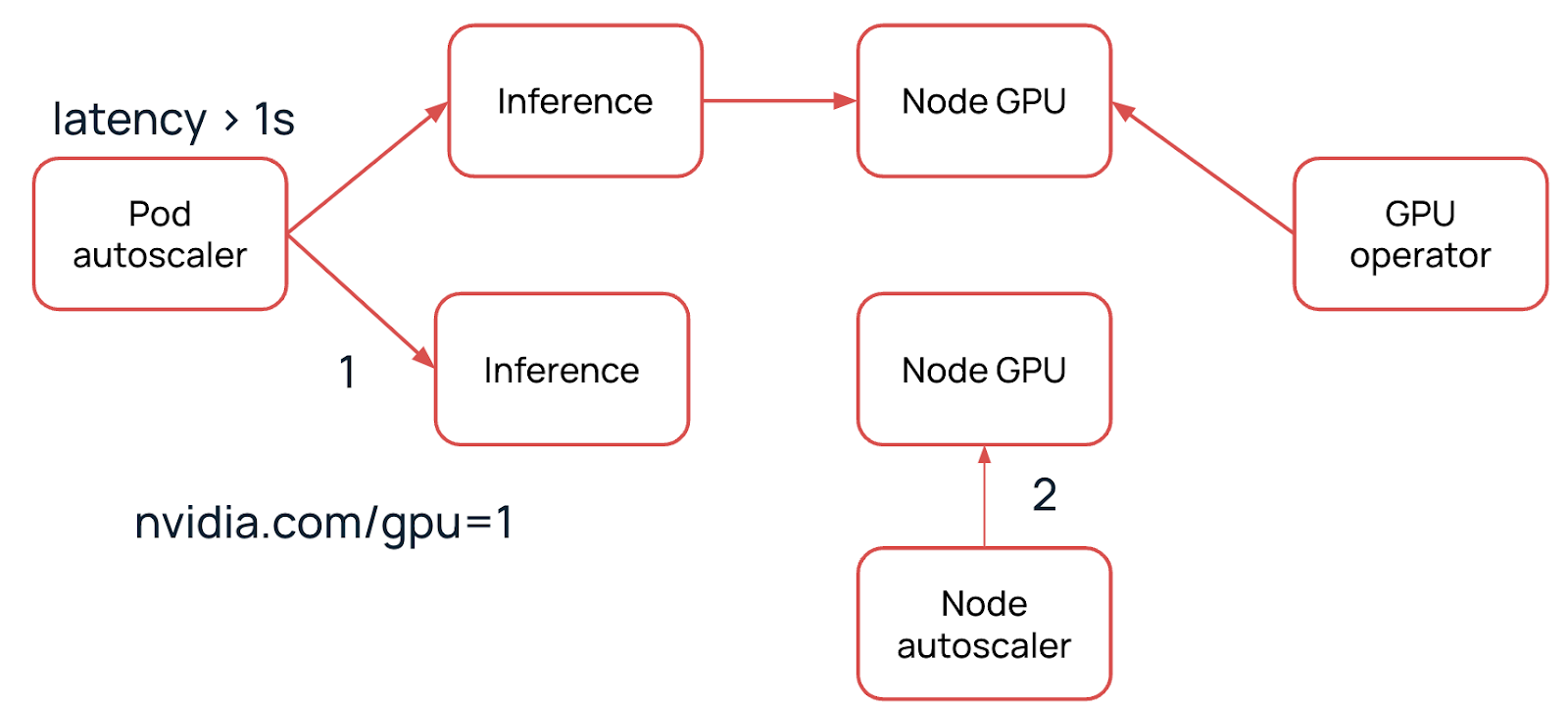
Автоскейлер поднимет ноду из базового образа в той группе, в которой разворачивается новая реплика. Время деплоя новой ноды зависит от размера выбранного флейвора, обычно до пяти минут. Далее начнется установка сервисов K8s.
Managed Kubernetes Services
На этом этапе на новую ноду ставятся необходимые для работы K8s-сервисы в виде systemd units: containerd, kubelet, mk-node-adm, mk-node-health. Это занимает до минуты.
GPU operator
Поскольку мы работаем с GPU, нам необходимо подготовить ноду. GPU-оператор устанавливает необходимые драйверы и тулкиты, настраивает плагин. Последнее как раз и выдает ресурс nvidia.com/gpu для нашей новой реплики.
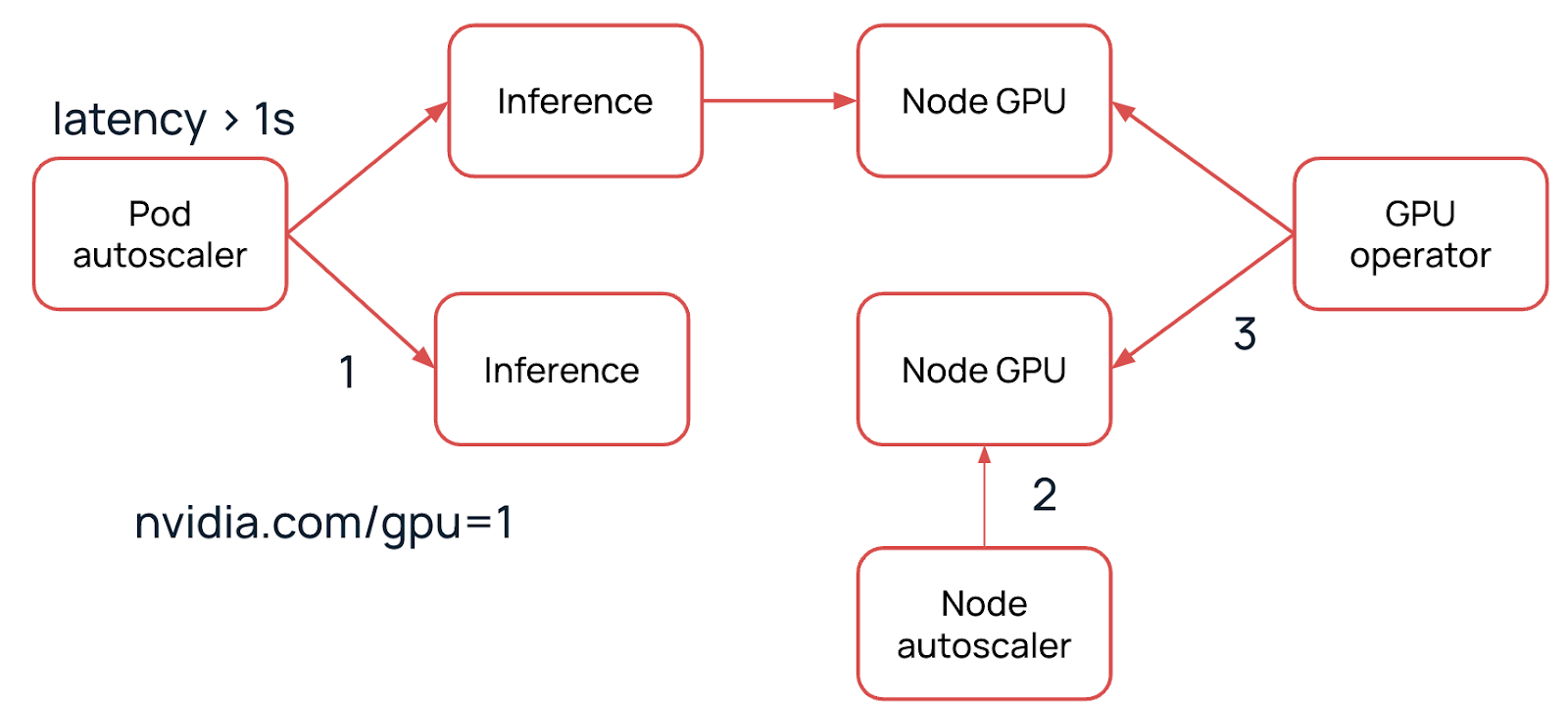
После установки всех драйверов нода готова — теперь на нее можно аллоцировать реплику. Это занимает примерно до трех минут.
Image pulling
Начинается пуллинг образа на новую ноду. Время зависит от размера образа, пропускной способности канала и вычислительной мощности доступной для экстрактинга образа на ноду.
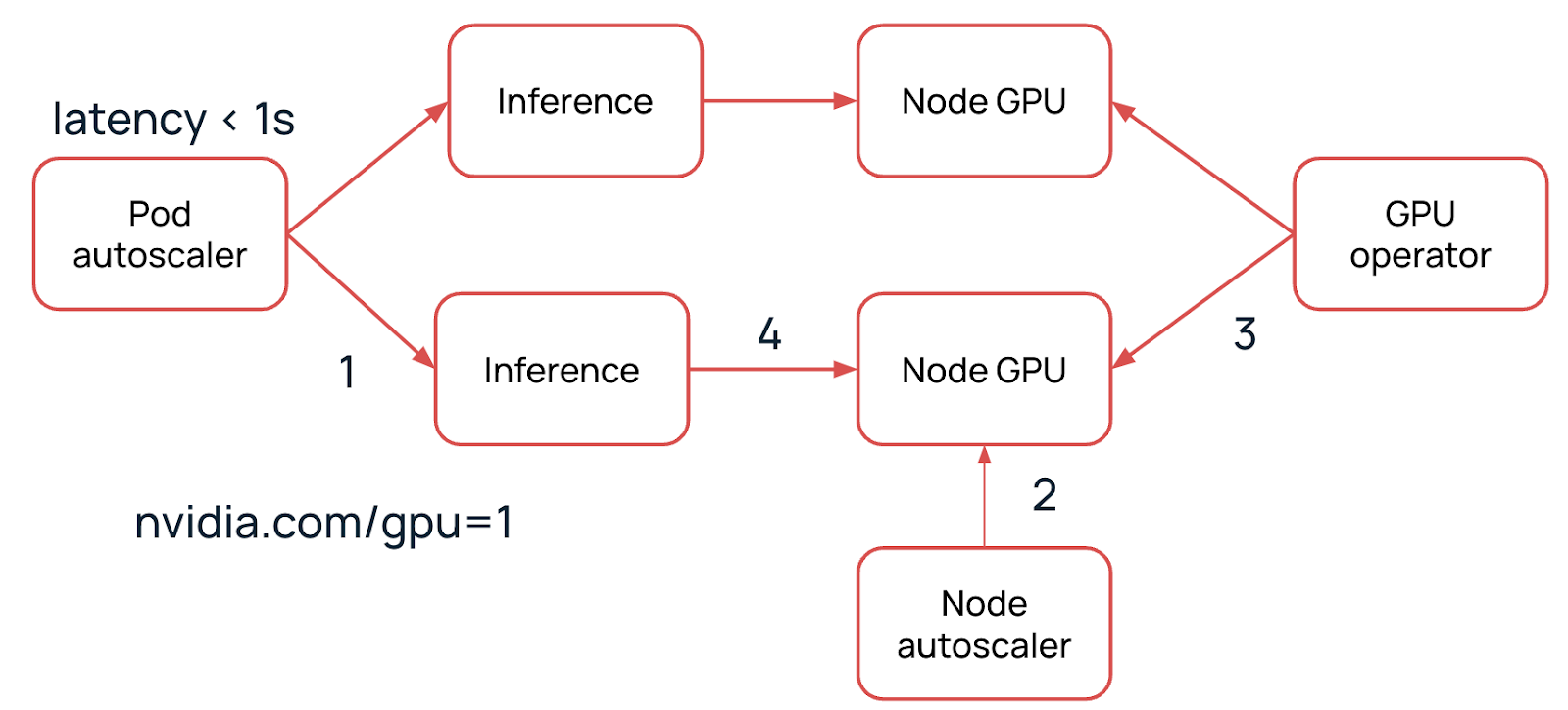
Для образа размером в 20 ГБ — а такие в ML бывают достаточно часто — время пуллинга займет порядка шести минут (с каналом 1 Гбит/с).
Теперь перейдем к практике и попробуем построить свой высоконагруженный инференс-сервис.
Автоскейлинг chatGPT2 на vLLM
Разберем пример, который я показывал на вебинаре. Весь код находится в репозитории, так что смело переиспользуйте наработки.
Какие компоненты нам понадобятся
Инфраструктура
В вебинаре я разворачивал кластер Managed Kubernetes с помощью Terraform. Если вы знакомы с этим инструментом, вам не составит труда использовать код из репозитория и развернуть кластер.
Мы же посмотрим, как через панель управления развернуть Managed Kubernetes в облаке с опцией автоскейлинга. В целом, это ничем не отличается от обычного флоу, поэтому покажу только особенности.
1. Создаем кластер и указываем дефолтные настройки:
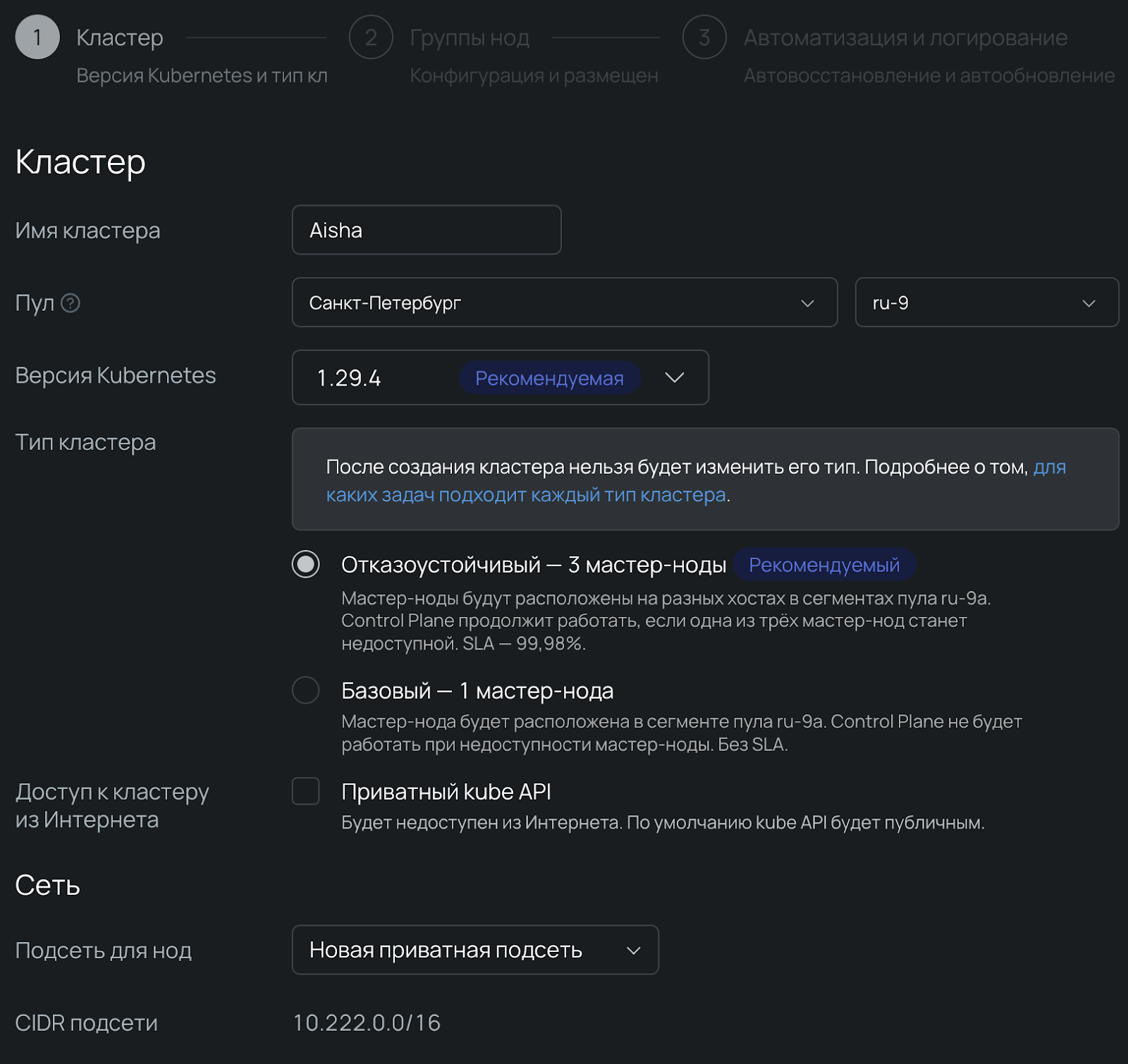
2. Указываем регион, версию K8s и отказоустойчивость кластера. При деплое выбираем группу нод и указываем автоскейлинг:
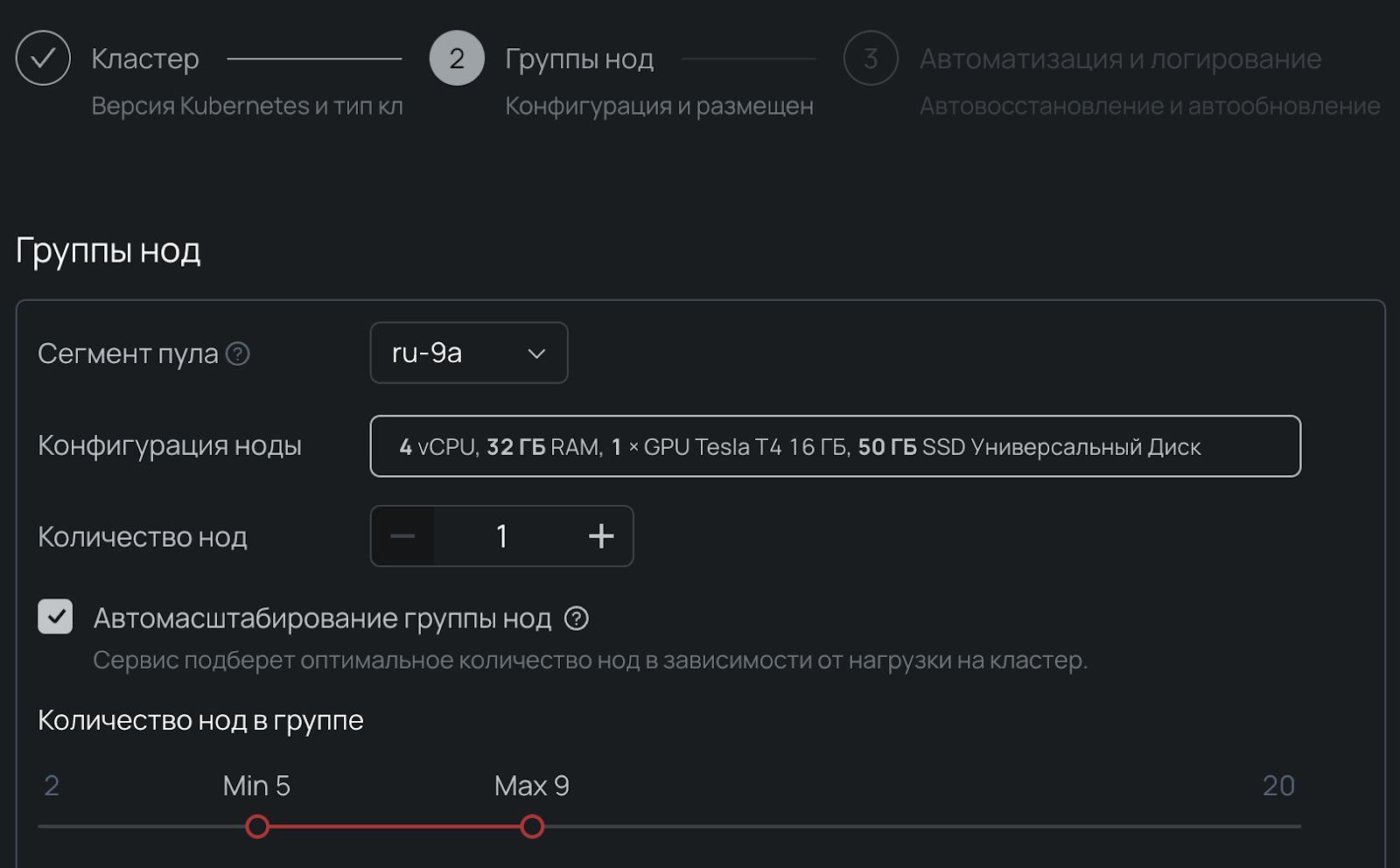
При включении опции Автомасштабирования можно выбрать от двух до 20 нод в одной группе. При этом через поддержку можно увеличить квоты персонально.
3. В конфигурации ноды выбираем флейвор с GPU, например Tesla T4:
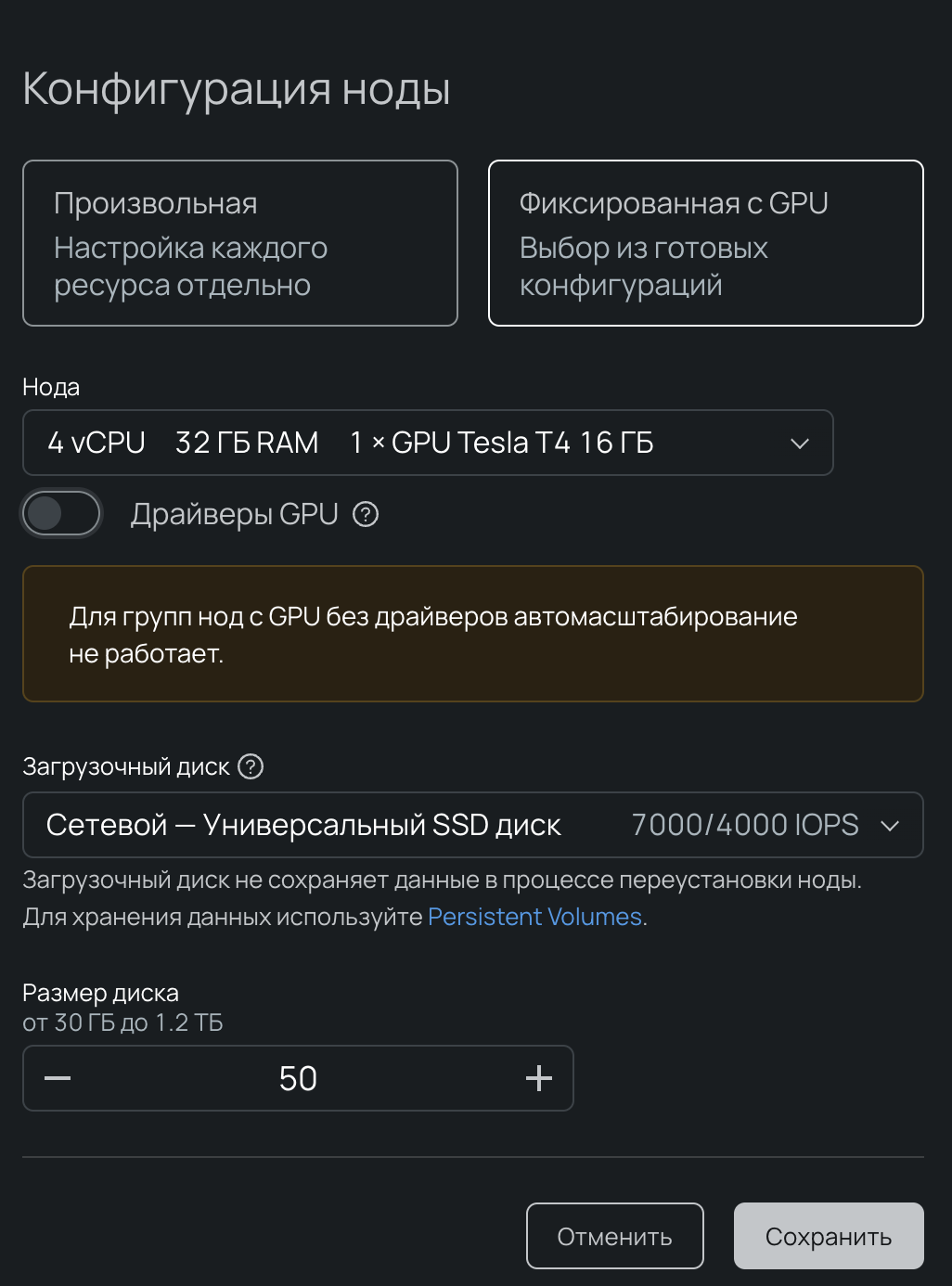
Также при выборе конфигурации ноды указываем опцию Установить ноду без драйверов GPU, чтобы самостоятельно поставить GPU-оператор.
Итак, наш кластер готов! Теперь установим необходимые сервисы.
Системные сервисы
gpu-operator
Подробно про этот Helm-чарт рассказывали в предыдущей статье. Сейчас он нужен для установки драйверов, тулкитов и лейблинга ресурсов на наших нодах.
1. Используем следующие значения для Helm-чарта:
driver: # поставит драйвер на ноду
enabled: true
version: "550.54.15" # версия устанавливаемого драйвера
toolkit: # перезапишит containerd config
enabled: true
devicePlugin: # разметит наши GPU ресурсы в лейбл nvidia.com/gpu
enabled: true
dcgmExporter: # нужен для экспорта метрик GPU в prometheus
enabled: true
2. Ставим gpu-operator с помощью следующей команды:
helm upgrade --install gpu-operator -n gpu-operator --create-namespace nvidia/gpu-operator -f gpu-operator/values.yaml
prometheus-stack
1. Стек сервисов нужен для Prometheus и Grafana, чтобы отслеживать наш трафик по дашбордам. Ставим чарт со следующими значениями:
prometheus:
prometheusSpec: # эти настройки нужны для автоматического подтягивания ServiceMonitor
podMonitorSelectorNilUsesHelmValues: false
probeSelectorNilUsesHelmValues: false
ruleSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
grafana: # дефолтные настройки графаны
grafana.ini:
analytics:
check_for_updates: true
grafana_net:
url: https://grafana.net
log:
mode: console
paths:
data: /var/lib/grafana/
logs: /var/log/grafana
plugins: /var/lib/grafana/plugins
provisioning: /etc/grafana/provisioning
helm upgrade --install prometheus-stack prometheus-community/kube-prometheus-stack -f prometheus-stack/values.yaml
2. Далее открываем Grafana через port forward и заходим в веб-интерфейс:
kubectl port-forward <service/grafana> 3000:3000 --namespace=<grafana-namespace>
prometheus-adapter
Нужен для преобразования метрик Prometheus в кастомные метрики K8s. Расскажем о нем подробнее чуть позже.
Манифесты нашего инференса
Для демонстрации работы инференса будем использовать фреймворк vLLM. Деплой моделей достаточно прост: достаточно указать название из списка доступных моделей, например Hugging Face. В нашем случае — gpt2, чтобы не тратить много времени на загрузку весов. Также vLLM хорош тем, что сразу под капотом имеет метрики инференса и Swagger для тестов.
Отправляем манифесты в одну папку vllm/ha. Деплоить их можно с помощью команды:
kubectl apply -f vllm/ha
Теперь рассмотрим каждый манифест.
vLLM deployment
Манифест деплоймента нашего ChatGPT 2:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: vllm-app
name: vllm
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: vllm-app
strategy:
type: Recreate
template:
metadata:
labels:
app: vllm-app
spec:
containers:
- command:
- python3
- -m
- vllm.entrypoints.openai.api_server
- --model
- gpt2
image: vllm/vllm-openai:latest
name: vllm-openai
ports:
- containerPort: 8000
protocol: TCP
resources:
limits:
nvidia.com/gpu: "1"
volumeMounts:
- mountPath: /root/.cache/huggingface
name: cache-volume
readinessProbe:
failureThreshold: 5
httpGet:
path: /health
port: 8000
scheme: HTTP
initialDelaySeconds: 40
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 1
livenessProbe:
failureThreshold: 5
httpGet:
path: /health
port: 8000
scheme: HTTP
initialDelaySeconds: 40
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 1
volumes:
- emptyDir: {}
name: cache-volume
Service load balancer
Для доступа из интернета к инференсу будем использовать балансировщик нагрузки Selectel. Достаточно задеплоить следующий манифест:
apiVersion: v1
kind: Service
metadata:
labels:
app: vllm-app
name: vllm-openai-svc
namespace: default
spec:
ports:
- port: 8000
protocol: TCP
targetPort: 8000
selector:
app: vllm-app
type: LoadBalancer
Service monitor
Нужен для сбора Prometheus-метрик с нашего инференса. После деплоя монитора в Prometheus система автоматически добавит новый таргет и начнет сбор данных.
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
serviceMonitorSelector: vllm-prometheus
name: vllm-prometheus
spec:
endpoints:
- interval: 10s
targetPort: 8000
path: /metrics
selector:
matchLabels:
app: "vllm-app"
HorizontalPodAutoscaler
Нужен для настройки автоскейлинга наших реплик. Указываем таргет в виде кастомной метрики и порог:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: vllm-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: vllm
minReplicas: 1
maxReplicas: 3
metrics:
- type: Pods
pods:
metric:
name: vllm_request_latency_seconds
target:
type: AverageValue
averageValue: 200m # 200ms задержки инференса
Думаю, многие могут задаться вопросом, что это за кастомная метрика K8s. Давайте разберем, как работает Prometheus-адаптер.
Делаем кастомные метрики с помощью Prometheus-адаптера
Зачем это нужно
Скейлинг происходит по метрикам K8s. Адаптер делает из метрик Prometheus кастомные метрики «куба» с помощью декларации API. Ранее я повторял это самостоятельно в статье про шеринг GPU. Prometheus-адаптер позволяет автоматизировать процесс через Helm-чарт.
Реализация
1. Используем следующие значения:
namespaceOverride: default
prometheus:
url: http://prometheus-stack-kube-prom-prometheus
port: 9090
rules:
custom:
- seriesQuery: 'vllm:e2e_request_latency_seconds_sum{namespace!="",pod!="",model_name="gpt2"}'
resources:
overrides:
namespace:
resource: "namespace"
pod:
resource: "pod"
name:
matches: "vllm:e2e_request_latency_seconds_sum"
as: "vllm_request_latency_seconds"
metricsQuery: 'rate(vllm:e2e_request_latency_seconds_sum{<<.LabelMatchers>>}[1m])/rate(vllm:e2e_request_latency_seconds_count{<<.LabelMatchers>>}[1m])'
2. Деплоим Helm-чарт с помощью такой команды:
helm upgrade --install prometheus-adapter prometheus-community/prometheus-adapter -f vllm/prometheus-adapter.yaml
Для составления кастомной метрики используется специальная формула metricsQuery. Принцип ее составления похож на выбор метрик в Prometheus с помощью promQL-запроса. Единственное, нужно дополнительно указать атрибут <<.LabelMatchers>>, по которому фильтруются метрики по подам и пространствам имен. Этой формулой мы создадим кастомную метрику vllm_request_latency_seconds, по которой HPA будет производить скейлинг.
Проверяем инференс
После деплоя манифестов мы можем зайти в Swagger и отправить запрос в модель. Swagger будет доступен по IP-адресу балансировщика нагрузки по порту 8000.
После всех манипуляций получим примерно такой ответ:
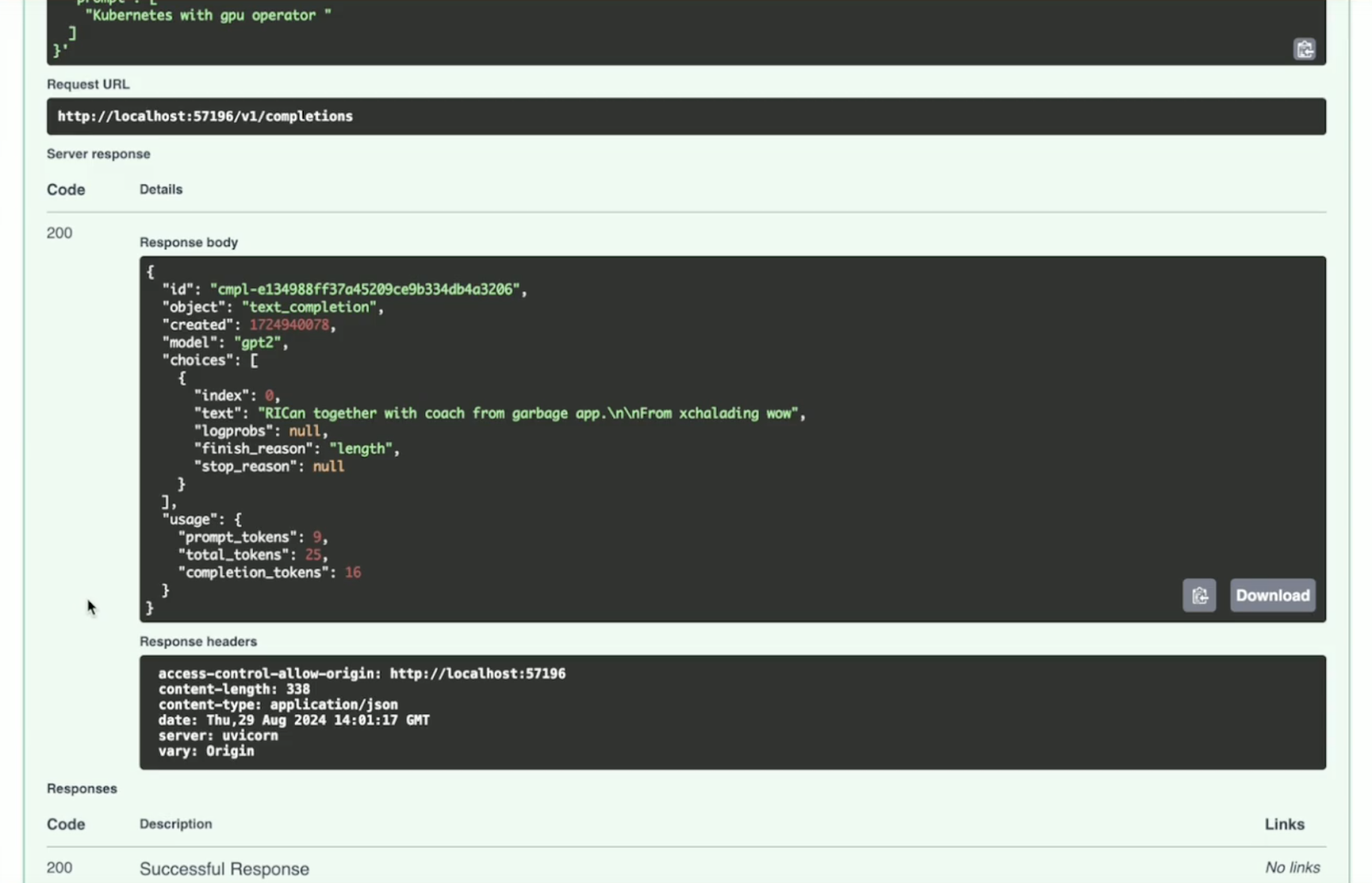
В результате у нас есть код 200 и ответ от gpt2 — не самый осознанный, как и модель, но инференс работает.
Подаем нагрузку
Для отслеживания трафика используем дашборд из официального репозитория vLLM.
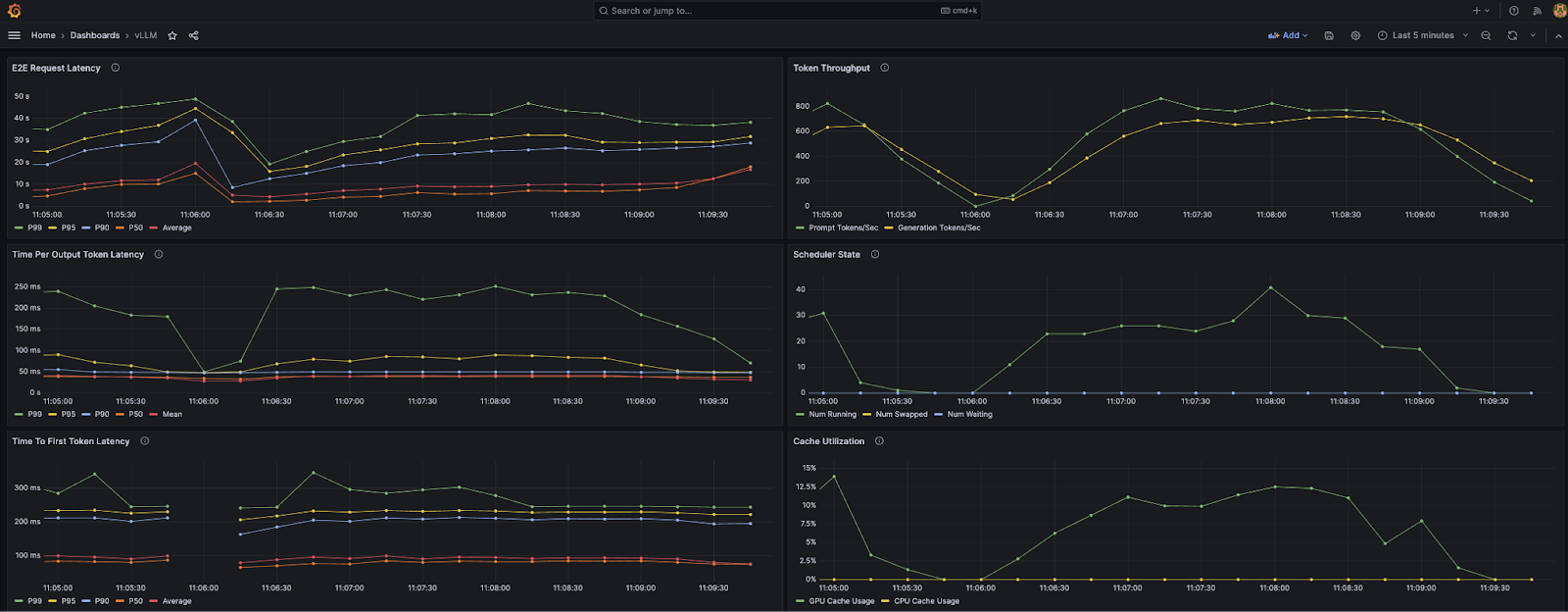
Нам нужен график E2E Request Latency, по нему будем отслеживать среднюю задержку запросов.
Нагрузку будем подавать с помощью инструмента gen ai perf client от NVIDIA. Его разработали на основе perf client специально для тестирования LLM.
Указываем <loadbalancer_ip> и количество конкурентных пользователей –concurrency. Если менять –concurrency от 50 до 100, то средняя задержка будет варьироваться от 200 до 400 мс.
docker run --net host -it -v /tmp:/workspace nvcr.io/nvidia/tritonserver:24.05-py3-sdk
genai-perf -m gpt2 --service-kind openai --endpoint v1/completions --concurrency 50 --url <loadbalancer_ip>:8000 --endpoint-type completions --num-prompts 100 --random-seed 123 --synthetic-input-tokens-mean 20 --synthetic-input-tokens-stddev 0 --tokenizer hf-internal-testing/llama-tokenizer --measurement-interval 1000 -p 100000
Сам GenAI генерирует запросы для gpt2 и сохраняет их в файле artifacts/gpt2-openai-completions-concurrency50/llm_inputs.json.
Спустя время мы сможем увидеть, как HPA поднимает новую реплику, которая будет требовать nvidia.com/gpu. Далее начинается магия автоскейлинга, которую описывали выше.
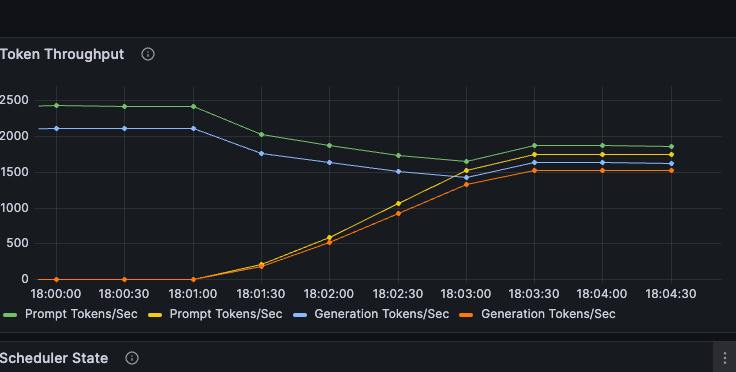
Как только поднялась новая нода, поставились драйверы и аллоцировалась на ноду реплика, смотрим, как в Grafana меняется трафик.
Вот пример графика, в котором после появления новой реплики генерация токенов в старой сократилось почти в два раза:
Заключение
В этой статье мы на практике посмотрели, как реализовать автоскейлинг инференса, из каких этапов он состоит и какие компоненты нужны. Но это еще не все. На вебинаре я получил список вопросов, постараюсь здесь на них ответить.
Что делать, если нет богатого парка GPU? Реализовать автоскейлинг можно и с одной GPU. Читайте в моей статье про шеринг GPU, MIG, Timeslicing и MPS.
Зачем использовать K8s для ML production, если можно развернуть большие виртуалки? K8s — это продакшн для любых сервисов, как и для инференсов. Он избавляет вас от проблем с оркестрацией, обеспечивает деплой без даунтаймов, менеджмент ресурсов и изоляцию сервисов.
Как предусмотреть АБ-тестирование инференсов? Мы используем canary-деплой наших инференс-сервисов. Сначала тестируем на определенном проценте трафика новую модель, затем пересылаем на нее уже полный трафик. Делаем это с помощью Istio. Полноценный АБ-тест таким образом не реализовать, так как нет контроля над определенной группой пользователя, но потестировать на нагрузку новую версию инференса можно.
Можно ли использовать в одном поде две и более видеокарты? Вы можете выбрать флейвор для ноды в нашем облаке, которое использует более двух видеокарт. NVIDIA device plugin отметит наличие более одного ресурса nvidia.com/gpu на ноде. Стоит помнить, что две видеокарты под может использовать только на ноде, в которой они аллоцированы. Нельзя использовать две видеокарты с разных нод.