

В фильме «Отряд самоубийц: Миссия навылет», когда персонажи Идриса Эльбы (Бладспот) и Джона Сины (Миротворец) знакомятся при участии Аманды Уоллер, звучит следующая фраза:
– Ты сказала, что у всех в отряде уникальные навыки, а он — это тот же я.
Казалось бы, при чем здесь базы данных? На самом деле, отношения между PostgreSQL и TimescaleDB напоминают эту пару героев. PostgreSQL — одна из самых популярных СУБД в мире. Вокруг решения давно существует комьюнити, а за годы в коммерческой разработке набралось достаточно документации. TimescaleDB, будучи расширением PostgreSQL, умеет многое из ее арсенала, но применяется более точечно. В основном в проектах, где нужно работать с временными рядами или собирать данные с IoT-устройств. В этом материале мы рассмотрим особенности работы TimescaleDB, а также покажем, как ее использует клиент Selectel — сервис DwarfByte.
(Не)Проблема выбора СУБД
Выбор СУБД под проект отличается от выбора фреймворка или оркестратора. Сделав ставку на условный Nomad, архитектор или техлид всегда (почти всегда) понимает, чего хочет достичь этим решением. Он понимает, что Kubernetes для проекта будет слишком сложным и большим, поэтому зачем?
Функциональность баз данных во многом похожа, поэтому при прочих архитектурных равных нет критической разницы между решениями. По этой причине в работе с БД на первые места выходит опыт команды с конкретным продуктом и преемственность. То есть возможность не накручивать дополнительную логику вокруг нового кластера, а масштабировать решение, которое уже есть в продакшене.
Есть проекты, которым приходится брать в отряд и Бладспота, и Миротворца, хотя, на первый взгляд, Идрис Эльба (и PostgreSQL) справился бы один. Но мы же говорим про коммерческие проекты, значит, нам по-настоящему важна скорость. Например, по сравнению с ванильным PostgreSQL TimescaleDB способен ускорить работу с данными в 2000 раз.
Среди других преимуществ стоит выделить:
- Встроенный toolkit со структурами данных для аналитических запросов «из коробки».
- Автоматическое партицирование.
- Встроенный механизм задач.
- Мультинодность.
Почему СУБД-напарник — оправданный шаг
- TimescaleDB оптимизирует хранение time series-данных: время вставки новых значений не увеличивается при увеличении количества данных.
- Не нужно переходить на другие решения, заточенные под time series-данные. Например, ClickHouse или QuestDB. До прямого сравнения мы еще доберемся.
- Работа в одном программном стеке. Можно хранить как временные ряды, так и другие типы данных на одной платформе. Для гипертаблиц это нормальная практика. Кроме этого, в одной СУБД можно использовать привычные расширения: pgbouncer, postgis, jsquery, pg_stat_statements.
На словах неплохо, а какие задачи решает TimescaleDB в реальных условиях? Давайте разбираться.
Как TimescaleDB используется на практике. Кейс компании DwarfByte
DwarfByte позволяет работать с AmoCRM при создании приложений с помощью привычного интерфейса взаимодействия PostgreSQL, вместо ограниченного стандартного REST API. Продукт позволяет строить аналитические отчеты, разрабатывать бизнес-процессы на основе данных AmoCRM.
Структура проекта выглядит так:
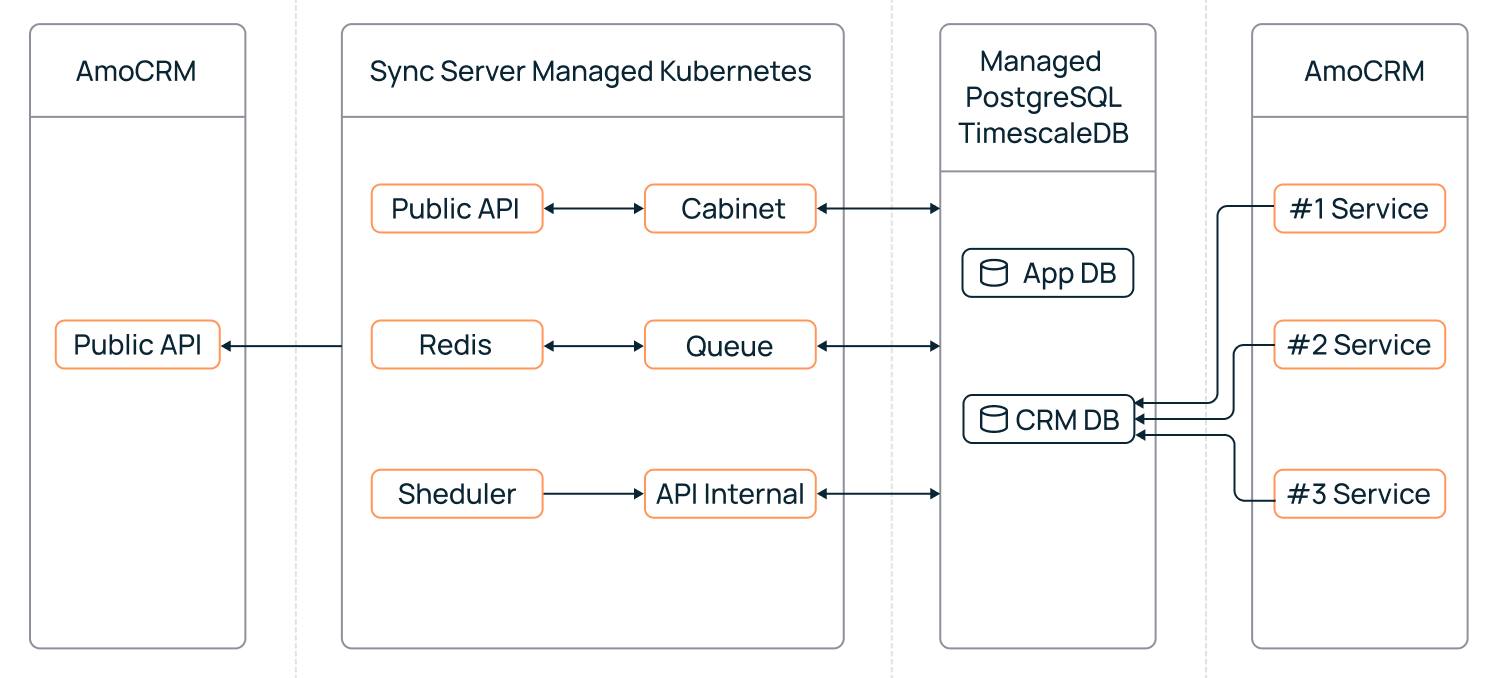
Объемы кластера определяются количеством данных в CRM. Как правило, не требуется много ресурсов для среднестатистического аккаунта. В данном примере используется только одна нода c 6 vCPU, 16 ГБ RAM, при объеме данных в 90 ГБ. Несмотря на то, что кластер включает в себя только мастер-ноду, из-за особенности интеграции AmoCRM выступает в роли еще одного мастера, и система не теряет в отказоустойчивости. Целостность данных в AmoCRM обеспечивает сам поставщик решения, а PostgreSQL-кластер нужен для упрощенного взаимодействия и ускоренной работы.
Система фиксирует все пользовательские и системные действия, которые обрабатываются приложением и синхронизируются в PostgreSQL-кластер. В кластере выделен отдельный сегмент для хранения time series-данных, чем занимается TimescaleDB. Главное преимущество — гипертаблицы. Они позволяют ускорить доступ к данным, настроить партицирование, сжатие «холодных» данных. Кроме этого, TimescaleDB решает задачи по удалению и «утилизации» неактуальных данных благодаря retention policy.
Одна из сущностей, данные которой хранятся в гипертаблице, — это события (events). Например, действие с карточкой клиента, постановка задачи в сделке, выполнение этой задачи и т. д. События становятся триггерами для различных бизнес-процессов. Доступ к старым событиям нам нужен нечасто, поэтому эти данные мы можем сжать и физически отправить на другой диск. Благодаря этому не пострадает скорость записи и чтения новых данных, и будет быстрее, чем на обычном PostgreSQL.
Помимо облачной базы данных, DwarfByte использует кластер Managed Kubernetes для деплоя сервера синхронизации.
Что делать с time series-данными
Эти данные можно использовать по-разному, ниже перечислены несколько примеров:
- Продуктовая аналитика. Данные помогают строить гипотезы и инвестировать ресурсы в фичи и решения, которые действительно улучшают сервис.
- Маркетинг. На основе своих действий клиенты получают наиболее выгодные предложения и видят актуальные офферы.
- Информационная безопасность. Можно настроить слежение за изменениями в данных AmoCRM.
- Customer Care. Отслеживается активность клиентов, чтобы коммуницировать с ними в рамках продуктовых сценариев.
Почему выбрали TimescaleDB
«Мы знали, что на рынке есть несколько подобных решений, но решили использовать TimescaleDB, чтобы работать с данными в одном стеке. Основная база данных продукта — PostgreSQL, мы решили, что правильнее будет не выходить за рамки экосистемы и не ошиблись. А также это решение оказалось быстрее остальных».
Филипп Потеряев, техлид DwarfByte
TimescaleDB vs ClickHouse
В материалах про СУБД, которые работают с time series-данными, часто можно встретить упоминания ClickHouse. Разберем, насколько справедливо сравнивать это решение с TimescaleDB при всем внешнем сходстве.
Функциональность Clickhouse действительно во многом перекликается с возможностями TimescaleDB, хотя архитектурно базы данных имеют принципиальные отличия. Самое важное и то, что поможет сделать правильный выбор СУБД под проект, — тип рабочей нагрузки.
Специфика ClickHouse — в работе с OLAP-нагрузками. Они действительно похожи на time series, но предполагают работу с потоковыми событиями. Например, обработку данных рекламных сетей или онлайн-игры.
Кроме этого, Clickhouse относится к колоночным решениям, что при работе с массивами данных помогает читать нужные данные на порядок быстрее, чем при строчном построении (TimescaleDB). Отсюда принципиальная разница запросов и производительности.
Строковые СУБД
Классический способ построения таблиц, в котором идет поочередный перебор данных.
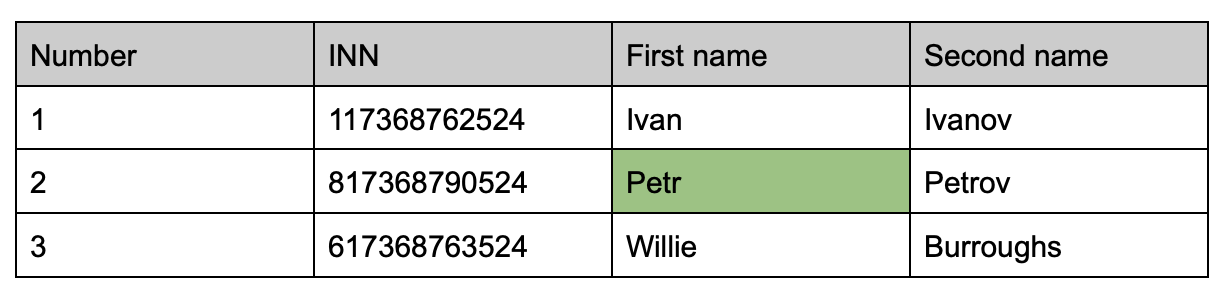
Чтобы добраться до нужной ячейки c записью Petr, нужно:
- Написать запрос и перейти на первую строку (строки обязательно читаются полностью): Select * From table Where first name = Petr.
- Найти колонку с названием Number и определить значение.
- Сравнить, подходит ли строка запросу.
- Если все ок, СУБД проверит значение колонки для каждой строки. Только таким способом можно проверить необходимость для запроса.
Звучит, как что-то надежное, но не очень быстрое. У нас есть плотная цепочка данных и гарантия, что ничего не потеряется, но перебирать каждый раз всю таблицу бывает неудобно, поэтому есть альтернативные решения.
Колоночные СУБД
Каждая колонка — это отдельная таблица из одного столбца, который хранит только свои значения. Чтобы найти нужную ячейку, достаточно обратиться к колонке First name. Ключевой принцип — использовать только колонки, которые участвуют в запросе.
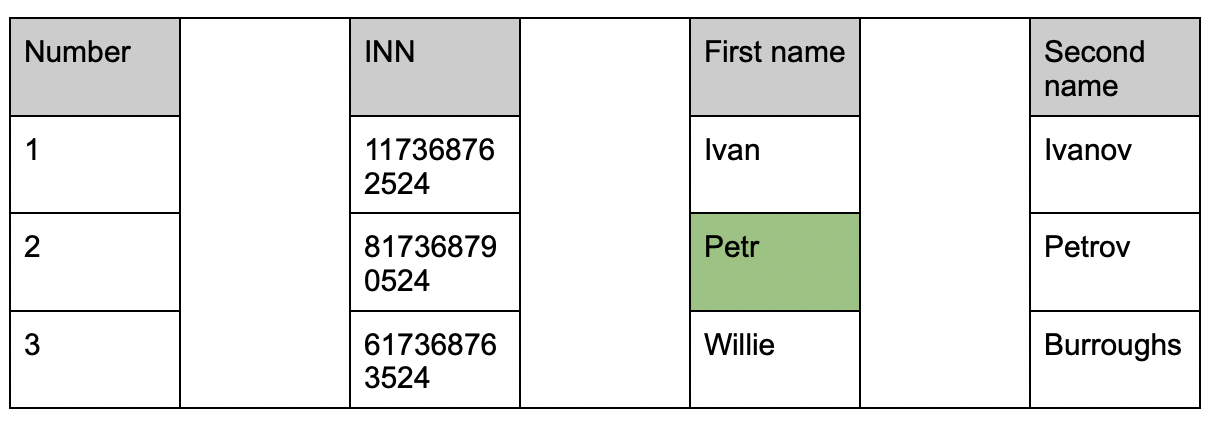
Кроме этого, данные в таких таблицах можно сортировать. Например, значения в таблице сейчас представлены в порядке возрастания в столбце Number. Это качество также оптимизирует запросы с участием нескольких колонок. Иногда такой подход стреляет себе в ногу неочевидным синтаксисом, поэтому знаний привычного SQL будет мало.
Между колонками нет физической связи, они — отдельные файлы на диске. Это позволяет увеличить эффективность работы при чтении с диска. В случае ClickHouse есть еще несколько преимуществ, которые позволяют использовать решение для эффективной работы с большими массивами данных:
- Есть опция сэмплирования. С ее помощью можно запустить быструю проверку только на каком-то конкретном сегменте, поэтому не нужно перебирать все данные.
- Каждая колонка хранится как отдельный файл, поэтому базу проще сжимать.
- Высокая производительность благодаря более коротким запросам относительно строчных СУБД.
Почему ClickHouse подходит не всем
Если сравнивать скорость работы ClickHouse с «классическими» решениями, то для получения 100 млн записей СУБД потребуется одна секунда, а MySQL справится с аналогичной задачей за 823,64 сек. Пока выглядит так, будто в ClickHouse нет слабых сторон, но так не бывает.
ClickHouse создавался для работы со сквозной аналитикой, чтобы изучать метрики, быстро выгружать отчеты и одновременно учитывать сотни атрибутов. Для таких задач не принципиальна целостность данных, поэтому СУБД работает только в режиме асинхронной репликации, хотя на практике это часто выглядит как потеря данных.
| Опции | ClickHouse | TimescaleDB |
| Транзакции | – | + |
| Хранимые процедуры | – | + |
| Управление индексами | Первичные, вторичные | + |
| Подзапросы | – | + |
| Триггеры | – | + |
| Функции, определяемые пользователями | – | + |
Это не значит, что ClickHouse работает хуже, просто его архитектура заточена под другие задачи.
Отсутствие транзакций и асинхронная репликация влияют на другие процессы. То есть сервер не может атомарно обновлять несколько таблиц одновременно. Если что-то сломается во время многокомпонентной вставки в таблицу с материализованными представлениями, то получим неконсистентное состояние данных. Единственный способ обеспечить согласованное резервное копирование — остановить все записи в базу данных.
Далее приводятся цифры по результатам бенчмарка Time Series Benchmark Suite.
Производительность вставки
При пакетной обработке строк от 5 000 до 15 000 строк на вставку обе базы данных демонстрируют высокую скорость, причем ClickHouse работает заметно лучше:
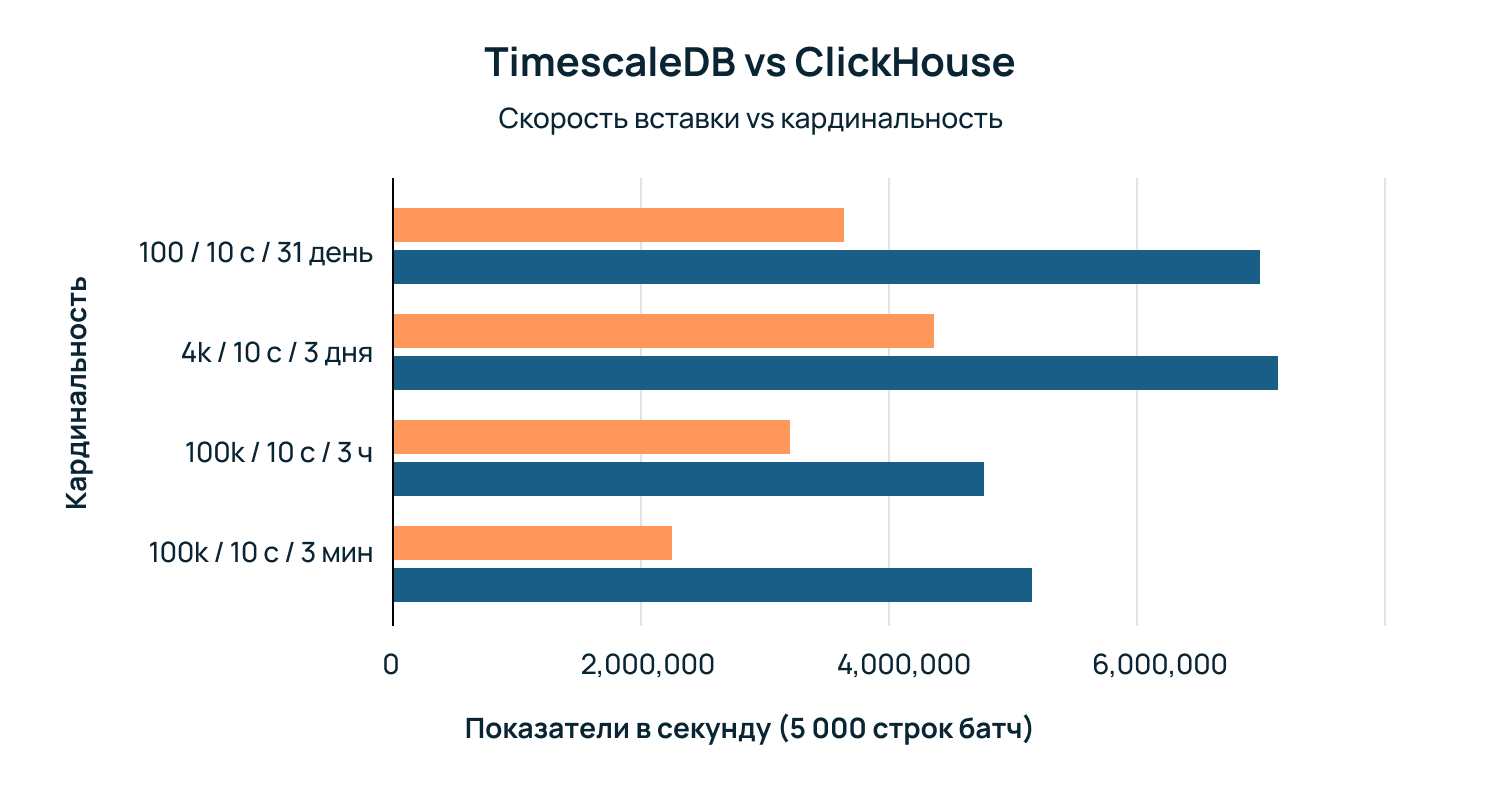
Однако при меньшем размере пакета результаты оказываются противоположными по двум параметрам: скорости вставки и потреблению пространства на диске. При больших объемах партий (5 000 строк/пакет) ClickHouse потребляет ~16 ГБ диска, а TimescaleDB ~19 ГБ (оба показателя до сжатия).
При меньших размерах партий TimescaleDB не только сохраняет стабильную скорость вставки, которая выше, чем у ClickHouse, в диапазоне 100-300 строк/пакет, но и потребляет в 2,7 раза больше пространства дисков, чем ClickHouse. Этого следовало ожидать из-за особенностей архитектурного дизайна каждой базы данных, но все равно интересно посмотреть.
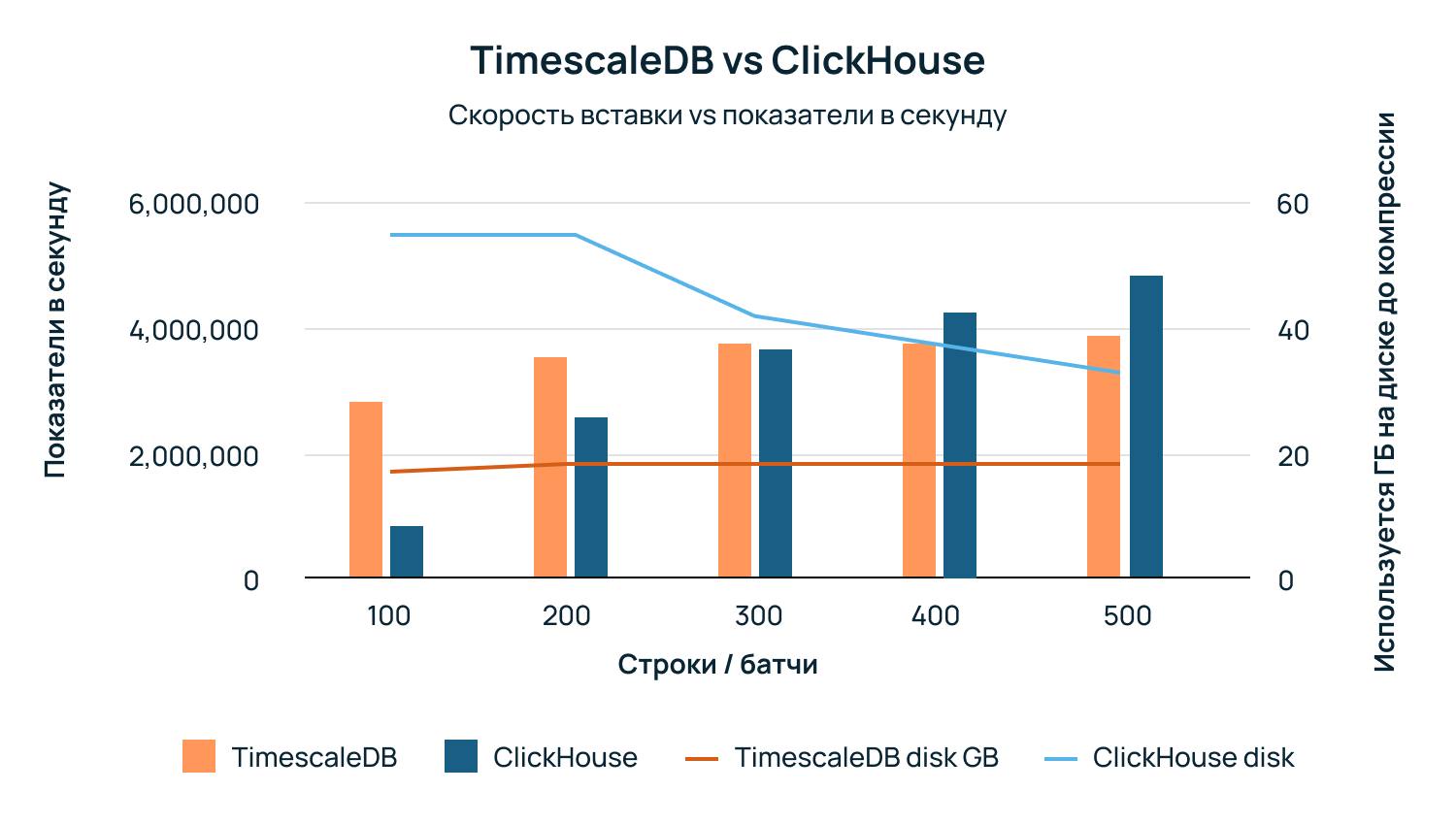
Сравнение производительности: Timescale превосходит ClickHouse при меньших размерах партий и использует в 2,7 раза меньше дискового пространства.
Производительность запросов
Для тестирования производительности запросов использовался «стандартный» набор данных, который запрашивает данные для 4 000 хостов за трехдневный период и содержит в общей сложности 100 млн. строк. Такое количество строк и кардинальность данных хорошо подходят в качестве репрезентативного набора данных для проведения эталонных тестов, поскольку позволяют выполнять множество циклов ввода и запросов по каждой базе данных в течение нескольких часов.
Основываясь на репутации ClickHouse как быстрой OLAP-базы данных, ожидалось, что решение превзойдет TimescaleDB почти по всем запросам в бенчмарке.
В режиме TimescaleDB без сжатия ClickHouse действительно вышел в лидеры.
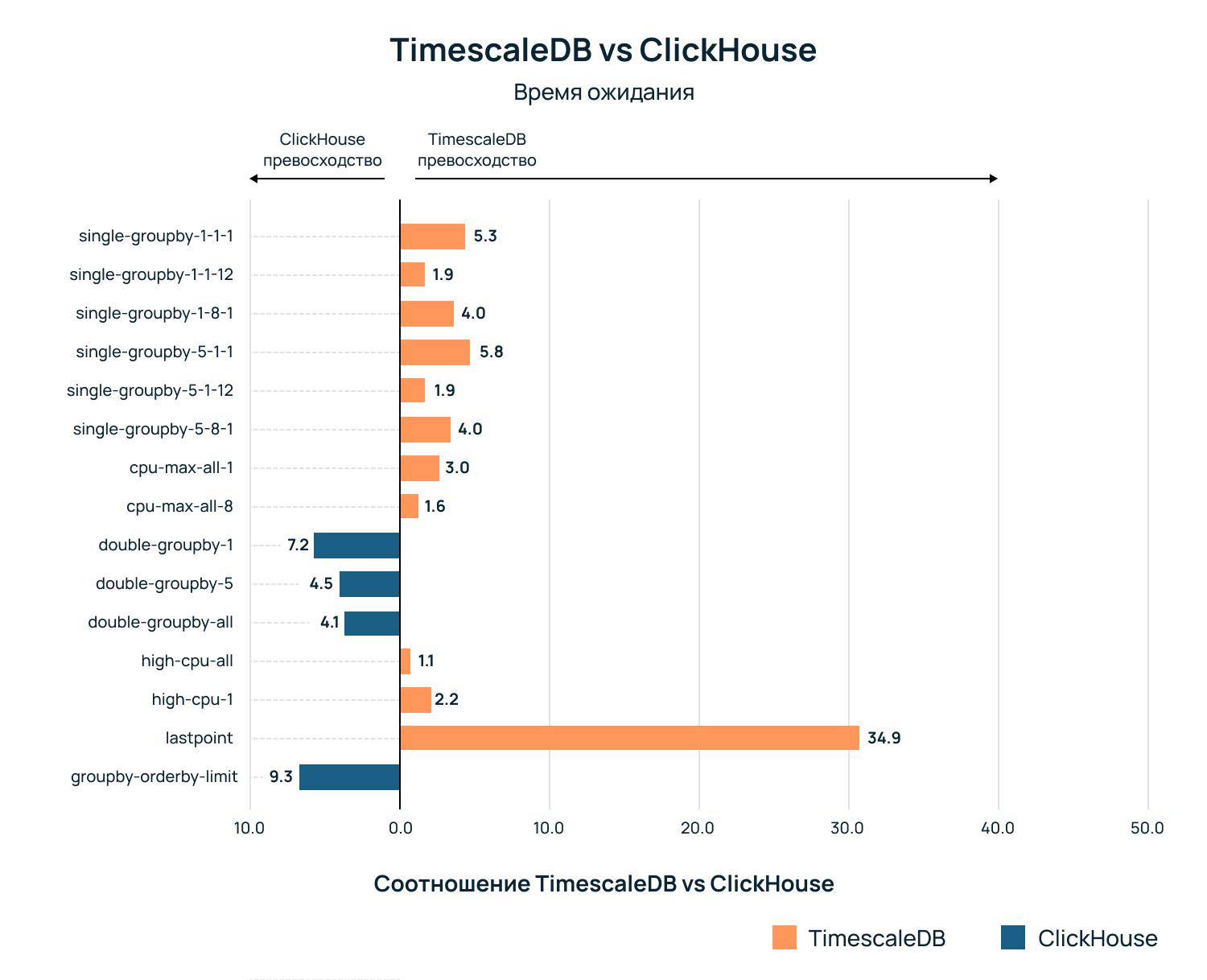
Но, если включить сжатие в TimescaleDB, что является рекомендуемым подходом, обнаруживается обратный эффект: TimescaleDB превзошла ClickHouse практически по всем запросам.
Предварительные итоги
Возможно, сравнивать строковые и колоночные СУБД изначально не самый честный спор. В современных проектах, где все больше внимания уделяется аналитике событий и поведению пользователей, граница между time series и OLAP-нагрузкой уже не такая очевидная.
Если проект предполагает аналитику приложений в App Store и Google Play, ClickHouse будет наиболее релевантным решением. СУБД действительно хорошо работает с большими массивами данных, но в ряде других задач (например, работа с транзакциями) уже не демонстрирует гибкость PostgreSQL и патча TimescaleDB.
TimescaleDB vs QuestDB
На месте QuestDB мог быть InfluxDB или OpenTSDB — не принципиально. После раунда против ClickHouse важно сравнить TimescaleDB с кем-то одного калибра и одного типа нагрузки. Как и другие time series-ориентированные СУБД, решение применяется в блокчейне, аналитике, онлайн-играх и интернете вещей.
С одной стороны, у QuestDB есть «специализация» — крупный финтех и трейдинговые платформы. В этом секторе быстродействие является ключевым параметром, поэтому решают даже миллисекунды. Основная причина, почему выбрана именно эта БД — наличие приличной документации. С другой стороны, решение часто применяется для работ с IoT, например, для интеграции с фитнес-устройствами.
Особенности QuestDB
База данных относится к колоночному типу и может работать с высокой степенью параллелизма, обрабатывая столбцы параллельно всеми доступными потоками. Для любого запроса, основанного на временных метках, QuestDB поднимает в памяти только последнюю версию данных в ячейке. Таким образом, выполнение запросов не замедляется по мере поступления данных.
Для ускорения запросов QuestDB использует современное оборудование с SIMD-инструкциями, агрегируя несколько строк одновременно. Команда инженеров создала JIT-компилятор, предназначенный для распараллеливания фильтров запросов во время их выполнения.
Совместимость
QuestDB поддерживает линейный протокол InfluxDB, проводной протокол PostgreSQL, REST API и загрузку данных в формате CSV. Пользователи, привыкшие к другим базам данных временных рядов, могут перенести свои существующие приложения без допиливания, а также могут выбрать один из протоколов ввода данных в зависимости от своих задач.
Другим интересным компонентом QuestDB является поддержка линейного протокола InfluxDB и проводного протокола PostgreSQL. Для существующих пользователей InfluxDB можно настроить Telegraf так, чтобы он указывал на адрес и порт QuestDB.
Пользователи PostgreSQL могут использовать свои клиентские библиотеки или JDBC для записи данных в QuestDB. Независимо от способа ввода данных, запросы к ним можно выполнять с помощью стандартного SQL, за вычетом некоторых исключений, перечисленных на справочной странице API.
Производительность
Несмотря на поддержку нескольких механизмов ввода данных, в QuestDB в качестве языка запросов используется SQL, поэтому нет необходимости изучать специфический диалект, как с ClickHouse. Существуют также расширения SQL, ориентированные на работу с временными рядами, что упрощает задачу.
QuestDB демонстрирует скорость обработки данных до 4,3 млн. строк в секунду. Этот показатель был рассчитан с помощью бенчмарка TSBS, который в настоящее время поддерживается компанией TimescaleDB. Выбранный экземпляр имел 32 ГБ CPU и 64 ГБ RAM, а также быстрый SSD-диск (NVMe). Быстрые диски позволяют лучше справляться с записью, связанной с вводом-выводом при одновременном поступлении большого количества неупорядоченных данных. В большинстве случаев для получения достаточной производительности можно использовать более медленные диски, например, тома AWS EBS.
Что касается скорости, то QuestDB — действительно любопытное решение. По данным разработчиков, БД значительно опережает ClickHouse и TimescaleDB.
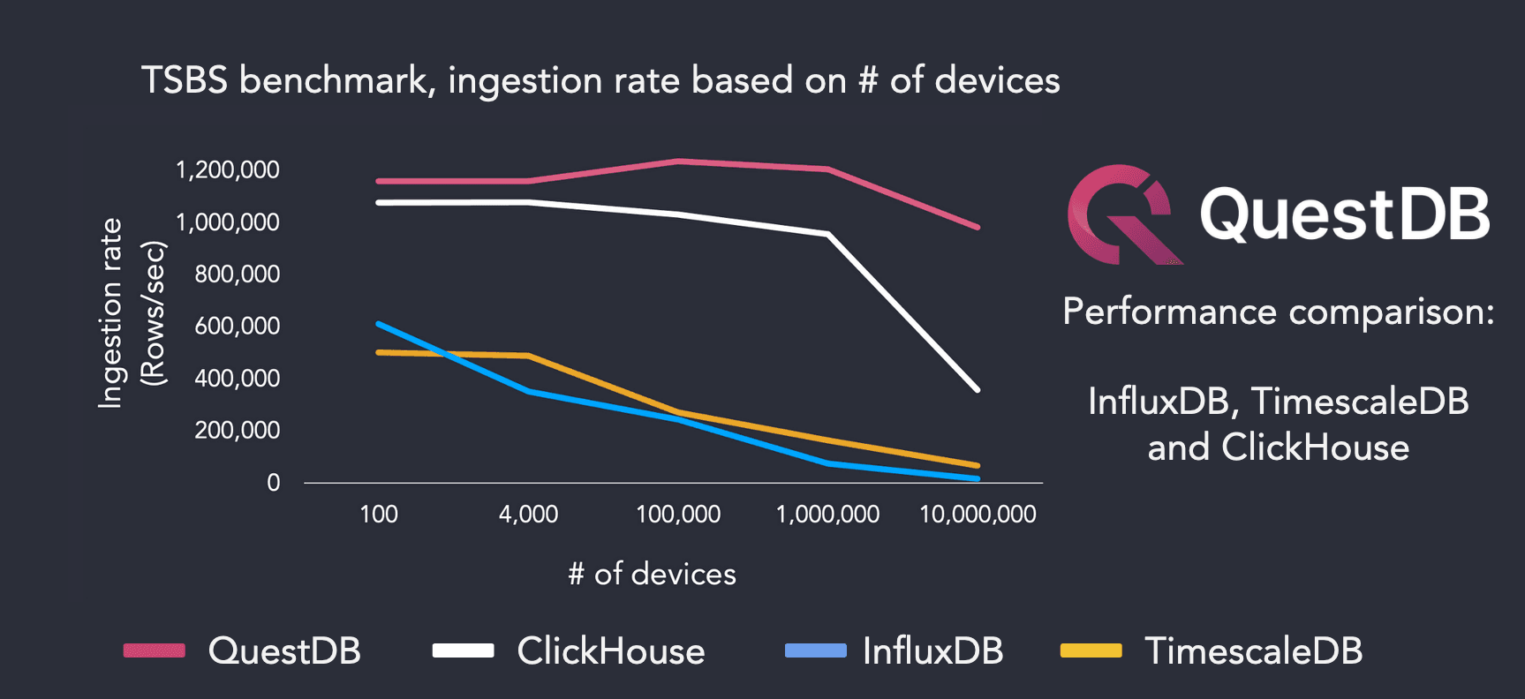
Как QuestDB удается так быстро получать данные такого типа? Дело в кардинальности данных.
Когда БД получает данные по линейному протоколу InfluxDB, теги сообщений хранятся в виде символьных типов. Этот символьный тип используется для эффективного хранения повторяющихся строковых значений, что позволяет группировать похожие записи.
Столбцы такого типа индексируются, поэтому запросы к таблицам по символам выполняются быстрее и эффективнее. Кроме того, БД умеет распараллеливать операции hashmap над индексированными столбцами и используем SIMD для выполнения большого количества тяжелых операций во всем SQL-движке. Так она по возможности параллельно выполняет процедуры, связанные с индексами и поиском в hashmap.
В такой ситуации мы можем говорить больше о том, что решение хорошо справляется с данными, в которых не нужно поддерживать историчность, а только обновлять.
Подробнее о тестах производительности QuestDB можно почитать здесь.
Почти итоги
У QuestDB есть ряд преимуществ, но и сложностей в работе с этой БД достаточно. Например, решение плохо подходит для больших отказоустойчивых систем из-за отсутствия репликации.
Плюсы:
- возможность встраивать базу данных в приложение на JVM и С++,
- расширения функций базы данных на любом языке для JVM, подключаются без перекомпиляции ядра базы с помощью ServiceLoader,
- быстрое получение данных,
- более высокая производительность при использовании меньшего количества ресурсов,
- поддержка протокола InfluxDB и PostgreSQL,
- выполнение запросов с помощью стандартного SQL,
- оптимизация запросов с помощью SIMD.
Минусы:
- небольшое сообщество,
- меньшее количество доступных интеграций,
- есть проблема с отсутствием контроля файлов журнала,
- не хватает математических функций (но уже в разработке),
- мало провайдеров, которые поддерживают БД как облачную услугу,
- репликация пока на стадии разработки.
Пока сфера использования QuestDB достаточно ограничена. Решение может быть полезно в следующих сценариях:
- При разработке FinTech-продуктов на JVM с низкой задержкой.
- Когда необходимо решение для аналитики данных в оперативной памяти.
- В качестве замены kdb+ из-за доступности лицензий.
- Если проект работает на JVM и вам нужна встроенная база данных для сохранения метрик или данных приложения, которые только добавляются и не обновляются.
QuestDB — достаточно быстрая БД, но пока ей не хватает поддержки комьюнити и ряда возможностей для масштабирования. TimescaleDB уже прошел этот путь и обзавелся множеством кейсов практического использования. Один из таких — от компании DwarfByte — мы рассмотрели в начале материала.
Заключение
TimescaleDB показывает высокие результаты производительности как в своем весе, так и среди колоночных СУБД. Кроме этого, решение может использовать экосистему PostgreSQL, что снижает порог входа и не вынуждает учить диалекты SQL. Область применения СУБД достаточно обширная, но для работы с нагруженными аналитическими системами лучше использовать более узкое, но не менее производительное решение типа ClickHouse.




