Тестируем 3 модели Qwen: сравнение производительности и примеры использования
Рассмотрим модель генерации речи, создадим изображения и проверим универсальный генератор.

Сегодня продолжаем обозревать модели китайской экосистемы Qwen от Alibaba. По частоте релизов она уже сопоставима с ChatGPT, а вот насколько модели конкурентоспособны по качеству — разберемся на практике.
Недавно мы уже проводили честный тест Qwen3 — проверяли, как она справляется с задачами на рассуждение, генерацией кода и работой с интерфейсами.
В тексте рассмотрим три решения.
- TTS-Flash — модель генерации речи, позиционируемая как инструмент для ультрареалистичного озвучивания. Заявлена поддержка русского языка и набор из нескольких голосов с разным тембром, темпом и интонацией.
- Image-Edit-2509 — модель генерации и редактирования изображений, которая ориентирована на точное понимание контекста и сохранение структуры объектов, в том числе с использованием ControlNet.
- Qwen Omni — универсальная мультимодальная модель для работы с текстом, аудио, изображениями и видео, а также для редактирования сгенерированного контента. Модель заявлена как хорошо понимающая русский язык, без промежуточных переводов.
Нейросеть в роли диктора
Сравнение начнем с модели генерации речи — Qwen TTS-Flash. Тестировать будем на русском языке: проверим дикцию, наличие артефактов, устойчивость к длинным текстам и корректность интонаций. Требования — почти как к профессиональному диктору. 🙂 Приступим.
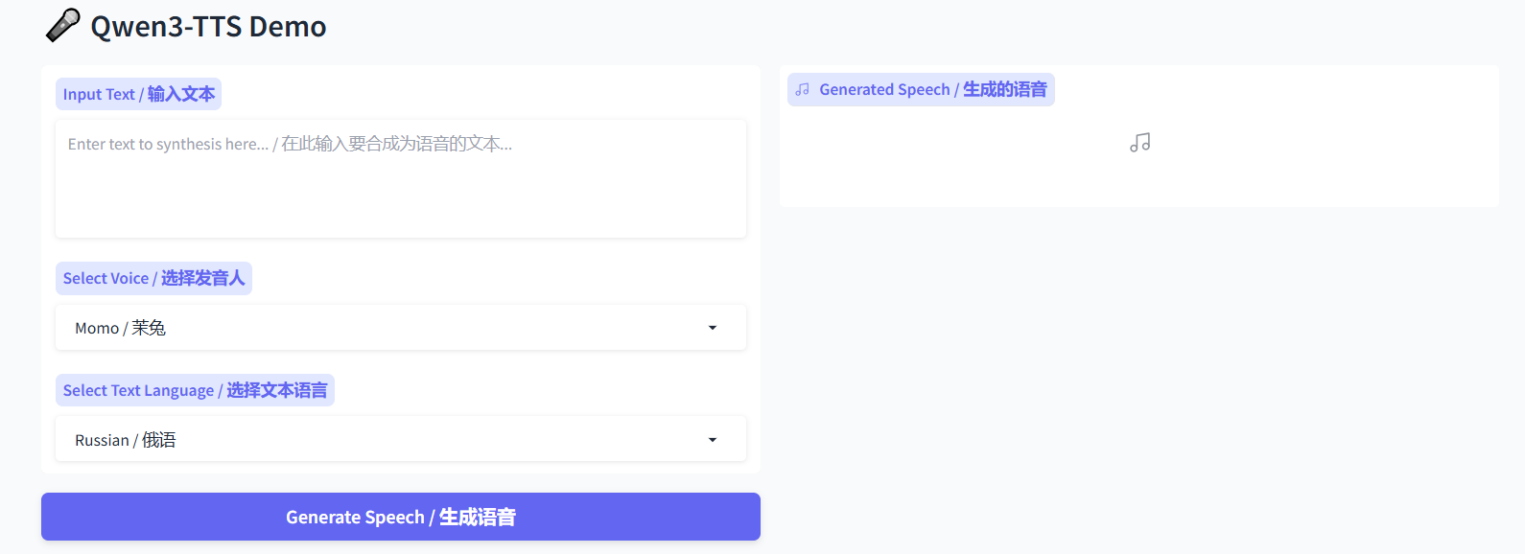
Интерфейс модели на Hugging Face.
При вводе текста выбираем один из 49 голосов (звучаний) — каждый отличается темпом речи, акцентом и интонацией. Также модель поддерживает 10 языков и автоопределение: например, при вводе текста на английском язык выбирается автоматически.
Первый тест: выносливость модели
Первая генерация была тестовой — важно было понять, насколько «человечно» звучит речь, как модель ведет себя при повторении одних и тех же слов, а также какой объем для модели максимальный.
Промт:
«Раз два три четыре пять», где слово «пять» повторяется максимальное количество раз.
Обработка текста заняла около 160 секунд. При этом модель сгенерировала более длинный аудиофайл, чем исходный текст на скриншоте. Хотя попытки напрямую подать большой текст приводили к ошибке генерации.
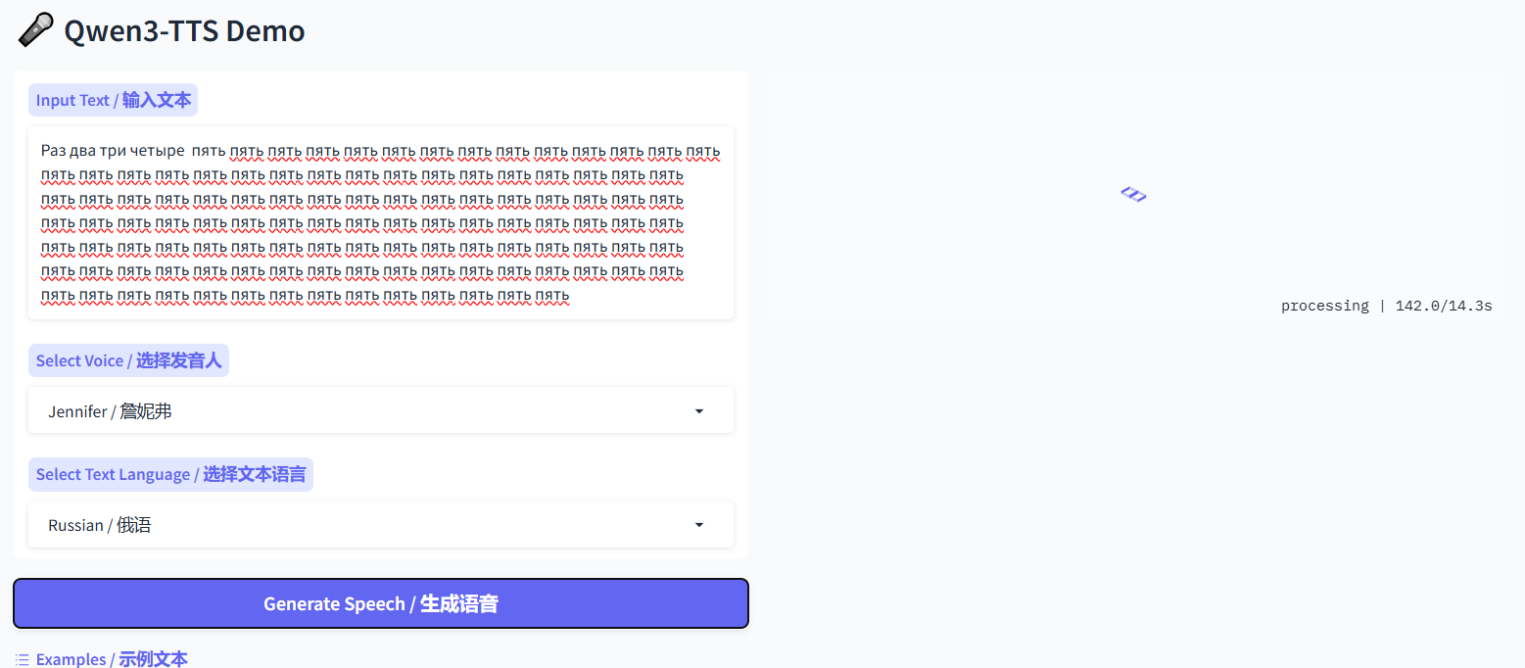
В итоге получилось почти восемь минут аудиодорожки.
Первые две минуты модель справляется без «заиканий» и артефактов, однако на третьей минуте речь становится прерывистой. На четвертой — появляется фоновый шум, а качество заметно падает и речь превращается в «кашу». Ближе к пятой минуте звук полностью искажается и начинает напоминать сирену. На тайминге в 5:13 создается эффект радиосигнала с очень сильными помехами, который сохраняется до конца записи.
Второй тест: чтение стихотворения
Все читали стишки Деду Морозу в детстве? Следующий тест будет как раз про это — нейросеть будет преобразовывать стих в аудио. Проверяем расстановку ударений, паузы и интонации.
В качестве промта используем отрывок из стихотворения Николая Некрасова «Крестьянские дети» («Однажды, в студеную зимнюю пору…»).
Промт:
«Однажды, в студеную зимнюю пору
Я из лесу вышел; был сильный мороз.
Гляжу, поднимается медленно в гору
Лошадка, везущая хворосту воз.
И шествуя важно, в спокойствии чинном,
Лошадку ведет под уздцы мужичок
В больших сапогах, в полушубке овчинном,
В больших рукавицах… а сам с ноготок!
“Здорово, парнище!” — “Ступай себе мимо!”
— “Уж больно ты грозен, как я погляжу!
Откуда дровишки?” — “Из лесу, вестимо;
Отец, слышишь, рубит, а я отвожу”.
(В лесу раздавался топор дровосека.)
“А что, у отца-то большая семья?”
— “Семья-то большая, да два человека
Всего мужиков-то: отец мой да я…”»
Модель не смогла обработать стихотворение целиком — генерация завершалась ошибкой без пояснений. В результате удалось получить около 49 секунд аудио.
Чтение в целом корректное, но с проблемами в интонации, дикции и ударениях. В некоторых местах звучит неестественно, местами — даже комично. Тем не менее, для текущего состояния модели результат впечатляет: при доработке интонационного блока ее уже можно рассматривать для чернового озвучивания.
Сравнение с коммерческими версиями
Сравнивать Qwen TTS будем с Resemble AI — ИИ-сервисом для озвучивания текста, который можно использовать для подкастов, озвучивания игр и фильмов, дубляжа. Также сервис позволяет редактировать и транскрибировать аудиофайлы. Есть возможность обучать модель на собственном голосе, но передавать такие данные сторонним сервисам я не рекомендую. Бесплатный лимит — до 2 000 слов, после чего сайт потребует оплату.
Цель сравнения — понять, сможет ли бесплатная модель конкурировать с платным сервисом без существенных ограничений, включая доступ пользователей из России.
Попробуем испытать нейросеть на дикцию. Промт тот же, что в первом тесте, но короче (лимит в 2 000 слов).
Промт:
«Раз два три четыре пять», где слово «пять» повторяется максимальное количество раз.
После прослушивания аудиофайла сложилось впечатление, что нейросеть начинает со стандартной скорости чтения, а затем постепенно ускоряется, искажая изначальный текст. Уже через десять секунд речь начинает «слипаться». Вдовесок получаем ограничение на время записи голоса, после чего сервис предлагает приобрести токены (как и на всех сайтах с платными нейросетями).
Возможно, платный «собрат» поразит нас своим чтением стиха, растопив сердца дикцией, интонацией, и выразительностью? Промт используем тот же, что раньше — отрывок стихотворения.
Но чуда не случилось: в файле получили неудовлетворительное по сравнению с Qwen чтение текста и те же ошибки в ударении: здорОво парнишЕ, чтение знака препинания «.». Да и в целом чтение не отличается выразительностью, звучит «не по-человечески» монотонно.
Также протестировали популярный сервис Crreo, но и его результат оставлял желать лучшего.
Выводы по TTS
При сравнении бесплатной модели Qwen TTS-Flash без ограничений по длительности с платными сервисами из коммерческого сегмента можно сделать простой вывод: решение от Qwen выглядит предпочтительнее.
Да, у модели есть проблемы с устойчивостью на длинных отрезках и с интонацией, но эти минусы компенсируются доступностью, возможностью локального развертывания и общей «живостью» звучания. В текущем виде TTS-Flash уже подходит для экспериментов, прототипов и некоммерческого использования.
Крупные коммерческие TTS-системы в сравнение не включались — многие из них недоступны на территории РФ.
Нейросеть в роли художника
Вторая модель на сегодня — для генерации изображений. Она доступна прямо в Qwen Chat. Цель теста — отследить прогресс модели: в начале года я уже тестировал Qwen на генерацию изображений и тогда результат выглядел сыроватым. Повторим те же промты и посмотрим, что изменилось.
Промт:
«Создай реалистичное историческое изображение. Сцена «Бостонского чаепития», произошедшего в порту Бостона, 16 декабря 1773 года. Группа колонистов, переодетых в индейцев, бросают ящики с чаем в воду. На заднем плане видны другие корабли, наблюдатели на берегу и городской пейзаж Бостона того времени. Обрати внимание на детализацию: одежда участников, выражения лиц, архитектура города и кораблей.»

Результат неожиданно порадовал. Сцена в целом соответствует запросу: композиция сохранена, ключевые элементы на местах, явных логических ошибок в расположении людей, кораблей и построек не заметил.
Без артефактов, конечно, не обошлось — встречаются «мультяшные» элементы, небоскребы на заднем фоне, странные детали вроде факела на сундуке или неестественные позы наблюдателей, которые стоят спиной к основной сцене. Но на фоне предыдущих результатов прогресс заметен. Несколько уточняющих промптов — и изображение уже можно довести до приличного состояния.
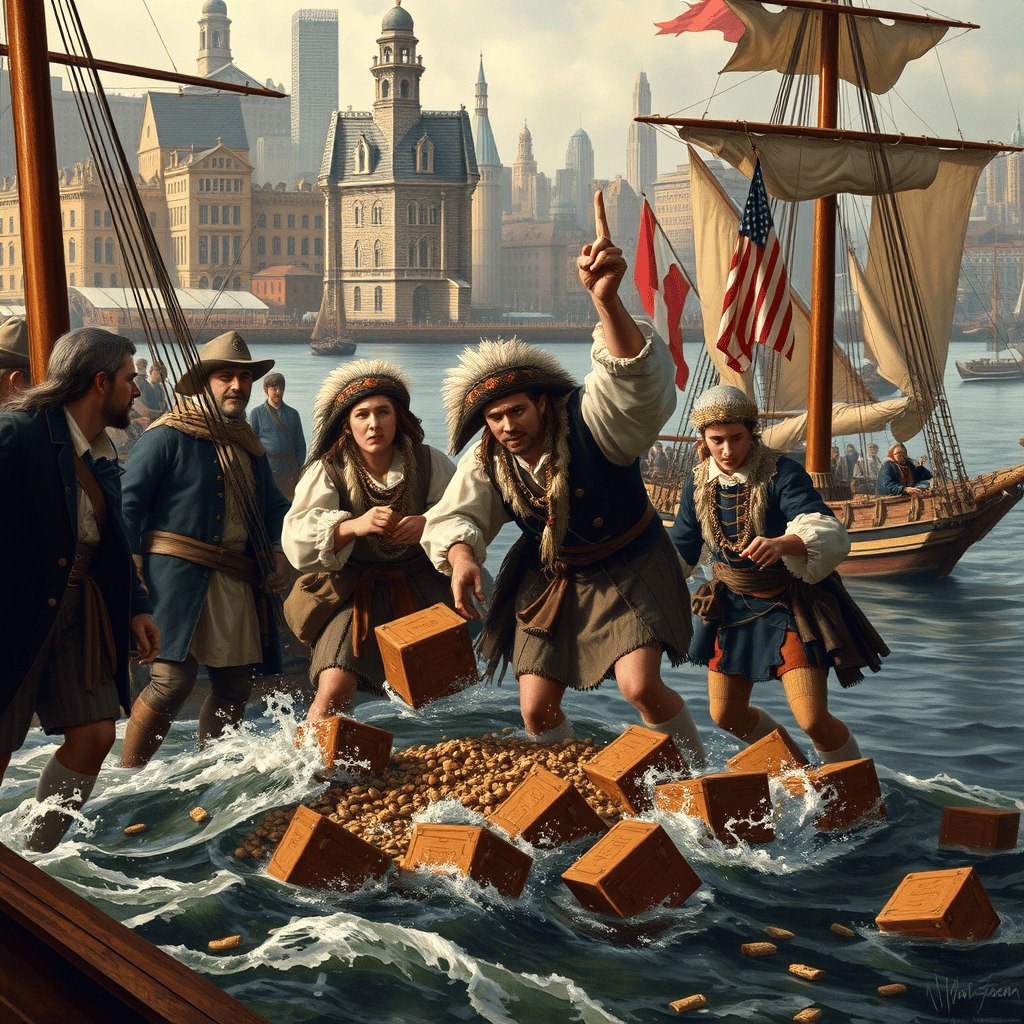
Первая сцена получилась немного мультяшной, поэтому следующий шаг — проверить, как модель справляется с требованием «строгой историчности» и высокой детализации.
Промт:
«Парусный линейный корабль Сантисима-Тринидад времен 18 века, огромный испанский корабль с сотнями пушек, идет по бурному морю. Сцена максимально детализированная. На палубах отчетливо видно команду матросов: кто-то у пушек, кто-то на такелаже, офицеры дают команды, моряки держатся за канаты под сильными порывами ветра. Видны открытые пушечные порты, тяжелые морские орудия, элементы корпуса, снасти, паруса, флаги. Погода штормовая: сильный ветер, дождь, темные волны, набегающие валы. На фоне вспышка яркой молнии, освещающая корабль. Атмосфера драматичная, напряженная, реалистичная. Ультра-детализация, кинематографический ракурс, реалистичное освещение, высокое качество.»

К сожалению, добиться исторической точности не удалось. Образ корабля получился эффектным, но скорее «собирательным»: пропорции, детали оснастки и общее устройство не соответствуют реальному «Сантисима-Тринидад».
При этом у Qwen есть полезные инструменты постобработки: изображение можно отредактировать, скрестить с другим или анимировать. Я попробовал создать видео на основе сгенерированного изображения, но результат оказался посредственным: анимация грубая, движения неестественные, целостность сцены быстро теряется. На текущем этапе Qwen явно не рассчитан на такой уровень задач.

Для сравнения, ChatGPT справился с аналогичным запросом заметно лучше — вплоть до корректного написания названия корабля и более аккуратной визуальной логики. Это тот уровень, до которого Qwen пока не дотягивает.

Нейросеть-универсал
Последняя модель в обзоре — Qwen3-Omni, также доступная через стандартный Qwen Chat. Это основная многомодальная языковая модель экосистемы. В ней можно включить «режим мышления» с бюджетом до 24 576 токенов.
Модель заявлена как универсальная: она работает с текстом, изображениями, аудио и видео, без деградации качества в отдельных модальностях. В рамках тестирования проверим скорость обработки запросов в режиме рассуждений, логические способности и качество генерации.
Первый тест — на логику
Для проверки логического мышления модель будет проходить тест Войнаровского (задачи про шмурдиков, мухропендий и тиалей). Условие — отвечать строго по существу, с явной цепочкой рассуждений.
Промт:
«Давай проведем тест на логику! Твоя задача — давать максимально логичные ответы.
отвечай только те пункты, которые я тебе выдам.
Шмурдик боится как мышей, так и тараканов.
a. шмурдик не боится тараканов
b. шмурдик боится мышей
c. шмурдик боится мышей больше, чем тараканов, но и тараканов боится тоже» и далее 29 подобных вопросов на логику с вариантами ответов.
При просмотре скрытых размышлений модель демонстрировала связную и последовательную логику рассуждений.

По итогам теста Qwen3-Omni набрала 27 правильных ответов из 30, что можно считать хорошим результатом.

На обдумывание всех вопросов модель потратила около двух минут — показатель вполне приемлемый для режима с расширенным бюджетом рассуждений. Однако при тестировании обнаружил особенность интерфейса: если в режиме мышления задать новый вопрос в том же чате, не сбрасывая контекст, модель воспринимает его как продолжение предыдущей задачи и строит рассуждения, опираясь на прошлый контекст. Для корректной работы требуется либо новый чат, либо явный сброс рассуждений.

Сравнение с ChatGPT
GPT-5 прошел тот же логический тест за 1 минуту 20 секунд, набрав 29 правильных ответов из 30. Как и Qwen, модель допустила ошибку в вопросе про бурдыльку.
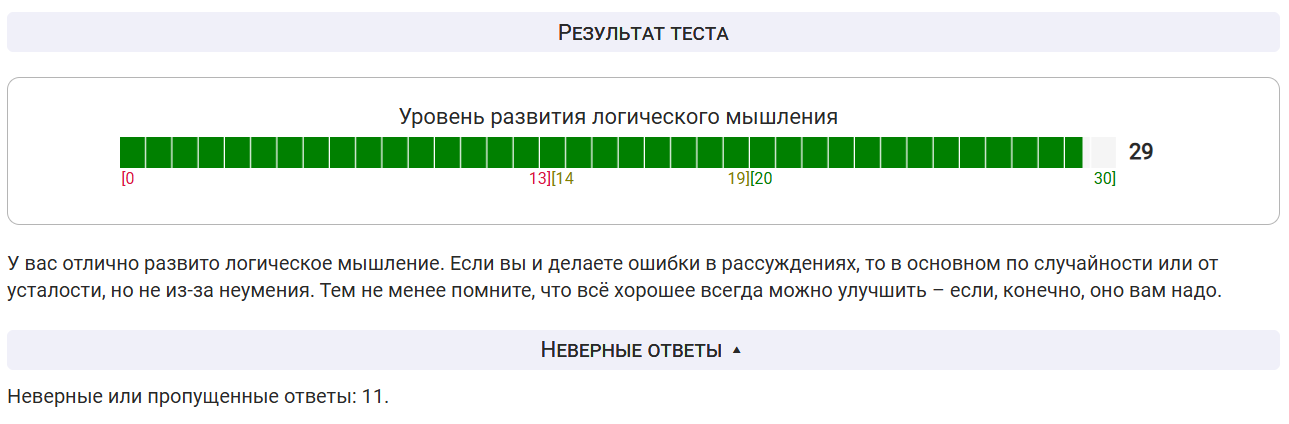
Результат у ChatGPT-5 немного лучше как по скорости, так и по числу верных ответов, однако разрыв нельзя назвать критичным.
Второй тест — анализ и генерация
Второй тест был направлен на способность модели анализировать крупное произведение и создавать структурированный текст.
Промт
«Проанализируй произведение война и мир, и составь краткую выжимку из тысячи предложений. каждое предложение должно быть уникальным, не менее 10 слов в предложении.»
Qwen3-Omni сгенерировала 1 000 формально корректных предложений, однако значительная часть из них повторялась по смыслу и структуре. В результате текст не воспринимается как связная краткая выжимка, несмотря на соблюдение формальных требований.

Поведение ChatGPT
ChatGPT-5 из-за ограничений на длину генерации предложил сформировать результат в виде файла.

Но при проверке выяснилось, что и в этом случае текст содержит заметные смысловые повторы.

После уточнения требования об уникальности предложений модель извинилась и выдала новый вариант. Повторы в нем встречались реже, предложения действительно были уникальными, но по уровню оригинальности формулировок и разнообразию идей результат все равно оказался ограниченным.

Какой можно сделать вывод
В целом даже модели высокого уровня пока слабо справляются с задачей генерации действительно качественного и уникального текста при жестких формальных требованиях. Однако прогресс очевиден, и развитие в этом направлении идет быстро.
TTS-Flash приятно удивила качеством генерации речи. Модель действительно создает реалистичное, «живое» звучание и в большинстве случаев корректно работает с русским языком. Это хороший инструмент для задач озвучивания, особенно с учетом бесплатного доступа и возможности локального развертывания. При этом иногда возникают сбои в генерации, которые на практике решаются повторным запуском или перезагрузкой страницы.
Image-Edit-2509 демонстрирует заметный прогресс по сравнению с предыдущими версиями, однако до фотореалистичной или исторически точной генерации ей пока далеко. Модель уверенно справляется с простыми сценами, но в сложных запросах по-прежнему склонна к мультяшному стилю и игнорирует требования к исторической достоверности.Qwen3-Omni оставила смешанное впечатление. В логических задачах и повседневных запросах модель работает быстро и уверенно, однако в сценариях сложной аналитической генерации она часто воспроизводит шаблонные и уже встречавшиеся формулировки, не создавая принципиально нового текста. Для таких задач я бы скорее отдал предпочтение флагманской модели — QwenMAX.




