
22 февраля 2024 года StabilityAI анонсировали новое поколение Stable Diffusion. Спустя четыре месяца, 12 июня, вышла «Сommunity-версия» Stable Diffusion 3 Medium. Нам обещают хорошую оптимизацию для домашних компьютеров, улучшенное восприятие запросов и бонусом новую лицензию. На примере множества картинок сравним локальные «чистые» модели SD и «закрытые» сервисы с Stable Diffusion 3.
Новое лицензионное соглашение
Stable Diffusion долгое время радовала своей открытостью. Каждый пользователь мог развернуть модель локально, дообучить разными способами и использовать результат по своему желанию. В том числе в коммерческих целях — лицензия CreativeML Open RAIL++-M это позволяет.
К сожалению, Stable Diffusion 3 вышла под другой лицензией с тремя уровнями использования.
- Некоммерческая. Лицензия бесплатна и дает доступ к API StabilityAI, в том числе к SDXL Turbo.
- Creator License. Стоимость — 20 $/мес, региональных цен нет. Включает в себя 6 000 генераций в Stable Diffusion 3 Medium и право использовать их в коммерческих целях. Но есть и ограничения — у проекта должен быть годовой доход меньше миллиона долларов и менее миллиона активных пользователей в месяц.
- Enterprise License. На индивидуальных условиях для крупных компаний.
Отдельно стоит отметить, что Creator License дает бесплатные генерации только для Medium-версии, которую можно развернуть локально. Закрытую Large-версию нужно оплачивать отдельно с примерным тарифом 0,07 $ за изображение. При этом на странице модели на Hugging Face указано, что локальная Medium-версия недоступна для коммерческого использования.
Для сравнения, Midjourney предоставляет 200 изображений за 10 $ (0,05 $ за изображение) или 900 изображений за 30 $ (0,03 $ за изображение). При этом тариф за 30 $ отличается наличием безлимитных генераций с пониженным приоритетом.
Визуальное сравнение
Для сравнения поколений используем как локальные модели, так и официальное API StabilityAI. Пробежимся по первым.
- v1-5-pruned.safetensors — версия 1.5, октябрь 2022.
- v2-1_768-ema-pruned.safetensors — версия 2.1, декабрь 2022.
- sd_xl_base_1.0.safetensors — версия SDXL 1.0, июль 2023.
- sd3_medium_incl_clips.safetensors — версия 3 Medium, июнь 2024. Для скачивания нужно зарегистрироваться на Hugging Face и заполнить форму.
Локальные модели запускаются через ComfyUI. Это обусловлено тем, что на момент написания статьи интерфейс от AUTOMATIC1111 не поддерживает третье поколение моделей. Старые версии запускаются со стандартной схемой (workflow) ComfyUI, а SD3 — с отдельной. Модели, доступные через StabilityAI API — Stable Diffusion 3 Medium и Stable Diffusion 3 Large.
Текст посвящен Stable Diffusion, однако есть множество конкурентов, которые стараются не отставать. Добавим несколько сторонних моделей:
- Midjourney v6,
- DALL-E 3 (через ChatGPT),
- Ideogram 1.0,
- Kandinsky 3.1 (запросы переводятся на русский язык дословно),
- PixArt Sigma 1024px (локальная модель, но использовали демо на HuggingFace).
Для взаимодействия с «внешними» Stable Diffusion используется Python-скрипт из документации.
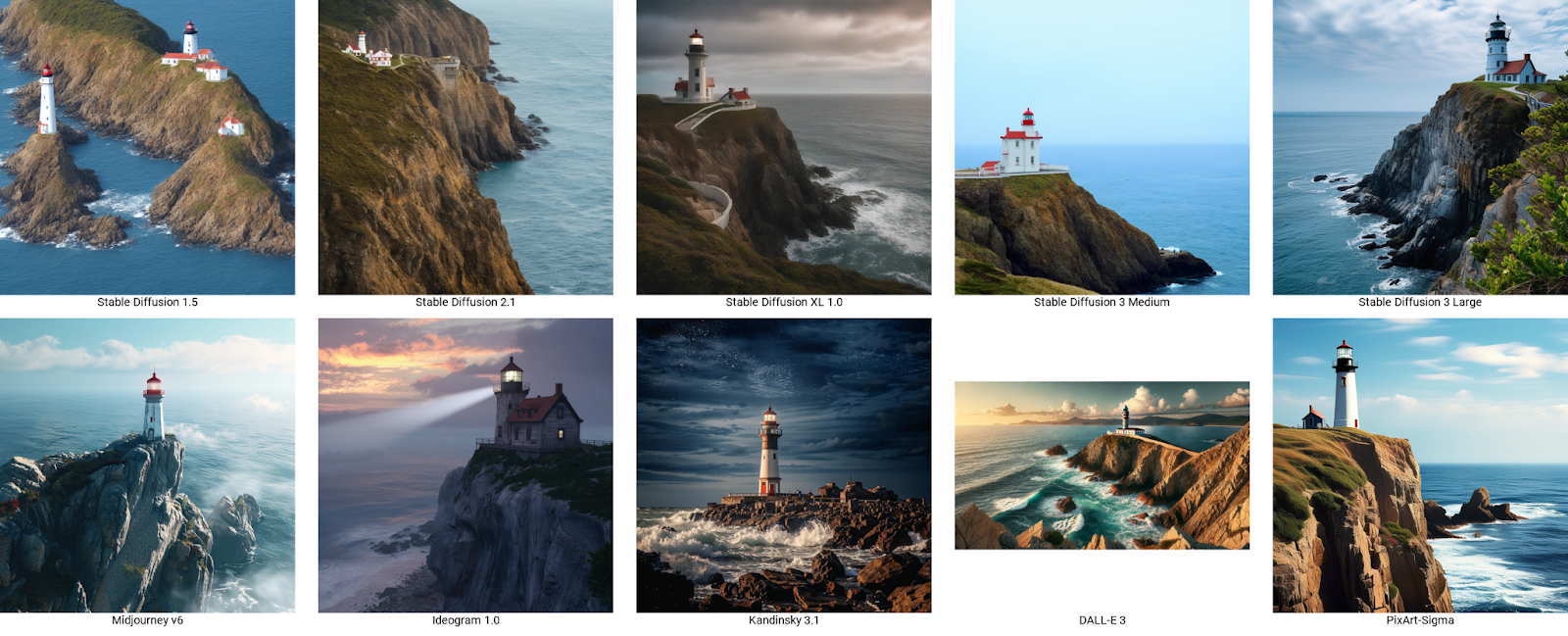
Первый запрос я нашел в документации API. Абстрактные пейзажи — это хороший старт. Medium, на мой взгляд, рисует «плоские» картинки, а вот Large выдает интересный результат. DALL-E самостоятельно выделилась не квадратным изображением. Пейзажи сразу были хороши, поэтому перейдем к генерации людей.

Сложно сказать, что «чистая» Stable Diffusion ранних версий рисовала людей хорошо, но SDXL укрепляла надежду в светлое будущее красивой анатомии. SD3 в текущем варианте разрушила эти надежды. В сообществе на Reddit высказывают мысли, что плохая генерация анатомии может быть следствием цензуры модели. Впрочем, на civitai уже можно найти рефайнеры для SD3.
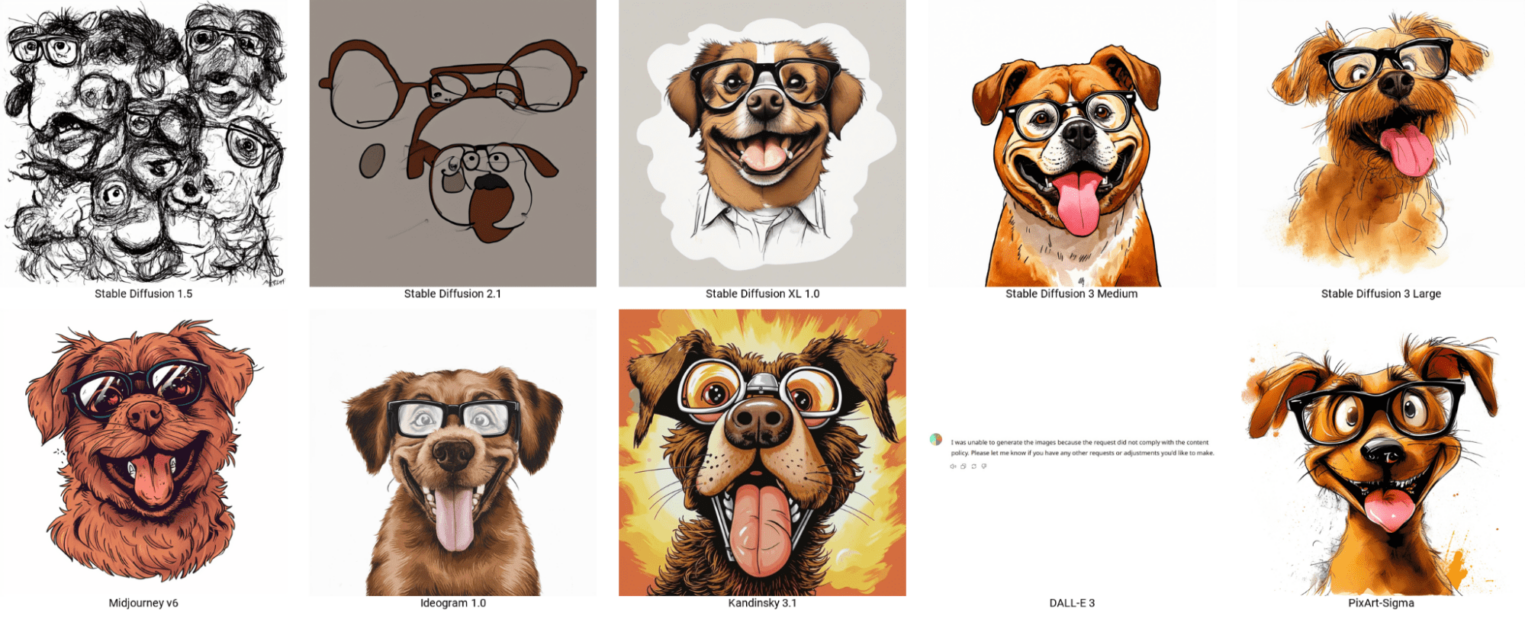
Рисунки животных генерируются отлично, на детальные описания нейросети реагируют хорошо. Исключение — DALL-E, которая ответила, что запрос нарушает контентную политику.
Длинные запросы могут путать генерацию. Однако еще больше путают максимально краткие и сухие запросы. Например, «ложка».

Обычная ложка запутала только SD1.5, Kandinsky 3.1 и PixArt. Остальные справились успешно. Посредник в общении с DALL-E, ChatGPT, пыталась выяснять что именно нужно нарисовать. В итоге ответ «просто ложка» привел к желаемому результату.
В прошлом обзоре на Midjourney я отмечал, что генерация текста значительно улучшилась. Посмотрим, есть ли такая тенденция у SD.

С текстами все относительно хорошо, хотя дополнительные детали наводят на вопросы. Почему ideogram нарисовал молодую девушку? Почему Kandinsky нарисовал «best grandma», если его попросили «лучшая бабуля»? Чьи колени на фоне у Midjourney? Эти вопросы останутся без ответа.
Осталось еще одно испытание — отрицание в запросе.

Вот так попросишь бургер без огурцов, а в восьми случаях из десяти они есть. И это не значит, что в двух оставшихся пожелание исполнено — в них что-то не так с бургером в целом. Но ведь есть негативный промпт? Да, промпт-инжиниринг никто не отменял, но этот запрос очень человечный.
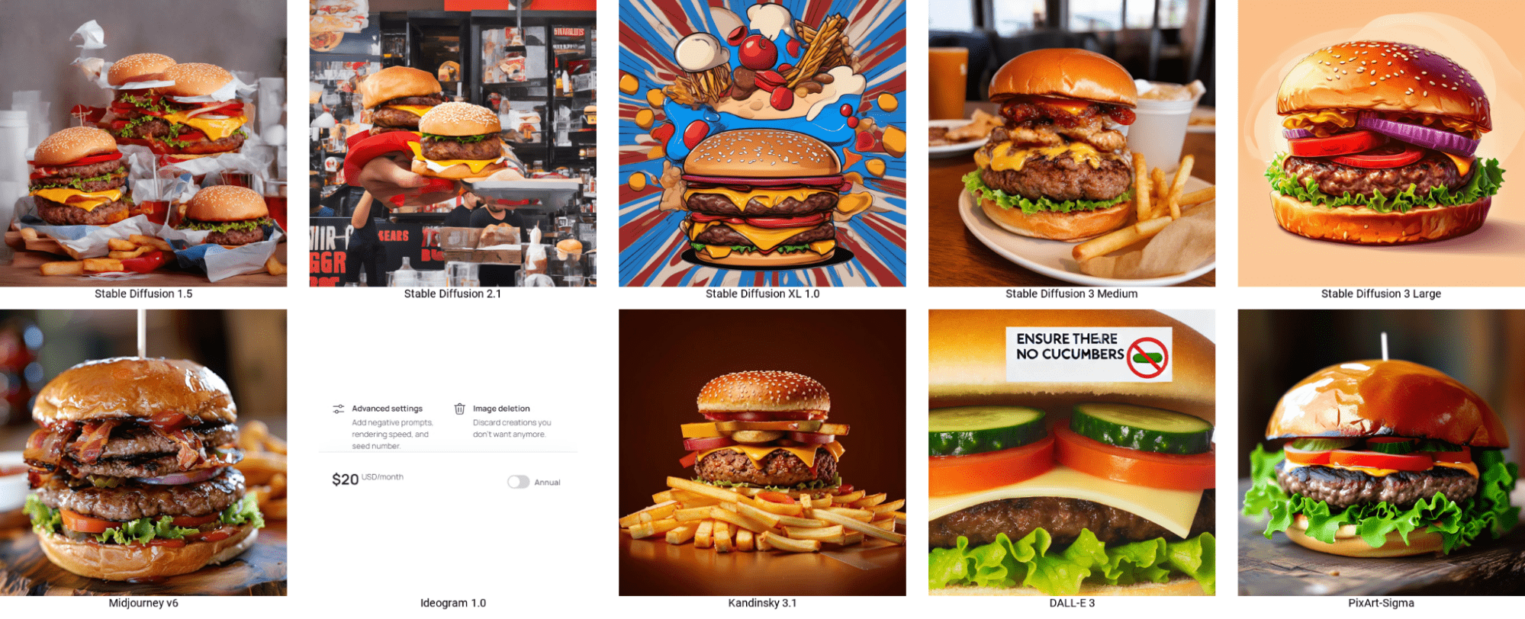
Да, так гораздо лучше, но не все нейронные сети принимают такой вид бургеров.
В конце визуальной части небольшой бонус: картинки из официальных промптов SD3 Medium, запрошенные во всех нейросетях.



Все изображения, использованные в статье, доступны в архиве.
Сравнение производительности
Критерии «красивее», «фотореалистичнее» и «лучше понимает запрос» — субъективные метрики, которые сильно зависят от стиля, личных предпочтений человека и умения составлять запросы. Однако нам обещали производительность, которую мы можем измерить.
Для запуска локальных моделей используется следующая аппаратная конфигурация:
- Intel i5-10500,
- 32 GB RAM,
- RTX 3060,
- SSD,
- Windows 10.
Какие параметры измеряем? Во-первых, объем занимаемой VRAM. Замеряется мониторингом ОС (диспетчером задач). Во-вторых, среднее время генерации изображения размером 1024×1024. Отображается в логах ComfyUI для каждого запроса.
Для разных моделей используется одинаковая конфигурация запроса.
- Запрос — a female character with long, flowing hair that appears to be made of ethereal, swirling patterns resembling the Northern Lights or Aurora Borealis. The background is dominated by deep blues and purples, creating a mysterious and dramatic atmosphere. The character’s face is serene, with pale skin and striking features. She wears a dark-colored outfit with subtle patterns. The overall style of the artwork is reminiscent of fantasy or supernatural genres.
- Негативный запрос: <пусто>.
- Шагов: 20.
- Сэмплер: dpmpp_2m.
| Модель | Объем выделенной VRAM, ГБ | Среднее время генерации изображения размером 1024×1024, с |
| Stable Diffusion 1.5 | 2.6 | 9.97 |
| Stable Diffusion 2.1 | 2.7 | 7.44 |
| Stable Diffusion XL 1.0 | 4.4 | 12.00 |
| Stable Diffusion 3 Medium (стандартный workflow) | 4.4 | 14.15 |
| Stable Diffusion 3 Medium(специальный wokflow) | 4.5 | 19.12 |
При сравнении «в лоб» оптимизация не видна. Видеопамяти актуальная модель требует не меньше, а времени занимает больше. Может быть есть возможность запускать модель на видеокартах с малым объемом оперативной памяти, но мне это останется неизвестным.
Заключение
Сообщества и различные социальные сети подогревают недовольство новой моделью за ее непонимание человеческой анатомии. Также новая лицензия и закрытость Large-модели могут огорчить профессиональных пользователей Stable Diffusion.
Стоит ли переходить на Stable Diffusion 3? Кажется, что сейчас это нерационально: оригинальная модель получила ограничения, а дообученных моделей еще нет. Остается только следить за развитием событий.




