

Reasoning-LLM — это большие языковые модели, нацеленные на логическое рассуждение при решении сложных задач. В отличие от обычных LLM, которые часто выдавали ответы сразу, такие модели способны «думать» пошагово — как человек, анализируя задачу и выстраивая цепочку вывода.
Появление reasoning-LLM связано с тем, что традиционные LLM (например, GPT-4 или Llama 3.1) хотя и хорошо справляются с языковыми и энциклопедическими запросами, нередко ошибались в задачах, требующих сложных вычислений, планирования или логического вывода. В этой статье мы подробно разберем, как работают reasoning-LLM, их внутреннее устройство (Transformer, self-attention, механизмы «мышления»). А еще — рассмотрим передовые модели (OpenAI o1, DeepSeek R1 и Claude 3.7 Sonnet), факторы, влияющие на их точность, и дадим практические рекомендации по применению.
Принципы работы reasoning-LLM: как мыслят модели
Главное отличие reasoning-LLM — умение явно или неявно строить цепочки рассуждений перед тем, как дать окончательный ответ. Обычная языковая модель обучена предсказывать следующее слово на основе предыдущих, поэтому без специальных приемов может сразу выдавать вероятный ответ, не прописывая промежуточные шаги.
Reasoning-LLM же обучены тратить больше «умственного усилия» на задачу. Компания OpenAI прямо отмечает, что серия моделей o1 была разработана так, чтобы «тратить больше времени на обдумывание проблемы перед ответом, почти как человек», пробуя разные стратегии и исправляя ошибки. Иначе говоря, модель не торопится с выводом, а сначала генерирует последовательность шагов, анализирует их и лишь затем формулирует результат. Такой подход резко повышает качество на сложных задачах.
Кстати, такой подход работает и с обычными LLM. К примеру, простое добавление фразы «Давай подумаем пошагово» к запросу способно повысить долю правильных ответов модели на математическом тесте MultiArith с 17,7% до 78,7% – фактически, та же самая модель начинает решать задачу правильно, если побуждена мыслить вслух. Этот прием известен как Chain-of-Thought (цепочка мыслей), и он лежит в основе работы большинства reasoning-ориентированных моделей.
Отличие от обычных LLM
Обычные большие языковые модели обладают обширными знаниями и умениями генерировать связный текст, но у них ограничены способности к комплексной логике. Без специальных подсказок они могут допускать очевидные ошибки: например, неверно решать текстовые задачи по математике или путаться в количестве букв «с» в слове «искусство».
Причина в том, что базовая Transformer-архитектура склонна находить самое вероятное продолжение текста, а не обязательно следовать строгой логике, особенно если в обучающих данных было мало примеров явных рассуждений.
Reasoning-LLM отличаются тем, что их специально тренируют на решении сложных задач. В ходе обучения модель поощряется за правильные составные решения и учится раскладывать проблему на подзадачи. Таким образом, модели приобретают навыки, схожие с человеческим подходом к решению задач: понять условие, разбить на части, последовательно решить и проверить себя.
Еще одно важное отличие — прозрачность рассуждений. Некоторые reasoning-модели могут по запросу показывать свои рассуждения. В обычных же моделях этап рассуждения отсутствует. Возможность наблюдать размышления модели упрощает отладку и понимание ее ответа. Кроме того, reasoning-LLM обычно лучше справляются с задачами, требующими «мышления второго уровня» (system-2 в терминологии когнитивных наук). Под ними мы подразумеваем задачи на логический вывод, математические доказательства, планирование, тогда как обычные LLM сильны в задачах «первого уровня». Среди них — воспроизведение знаний, языковые задачи и обобщение информации.
Архитектура и внутренние механизмы reasoning-LLM
В этом тексте мы не будем супер-подробно рассматривать архитектуру трансформеров, поэтому пройдемся по верхам. Внутреннее устройство reasoning-LLM в целом основывается на той же архитектуре Transformer, что и у обычных LLM. Transformer характеризуется механизмом multi-head self-attention, который позволяет модели параллельно учитывать разные части входной последовательности при генерации каждого следующего токена. Иными словами, self-attention дает возможность взглянуть на все предложение целиком и определить, какие слова (токены) наиболее важны для текущего шага предсказания.
Это резко отличается от старых рекуррентных сетей, которые читали текст слева направо без такого глобального обзора. Благодаря self-attention модель «понимает» контекст и взаимосвязи в тексте. Например, при решении задачи self-attention поможет соотнести текущий шаг решения с условием, упомянутым несколькими предложениями выше, или учесть промежуточный вывод из предыдущего шага.
Кроме того, трансформеры обычно имеют большие полносвязные слои (FFN) после блоков внимания, механизмы позиционного кодирования (чтобы понимать порядок токенов) и прочие стандартные компоненты. Все эти элементы присутствуют и в reasoning-LLM, обеспечивая мощь обработки длинных контекстов и сложных зависимостей.
Важно отметить, что сами по себе механизмы Transformers не гарантируют, что модель будет мыслить логически. Они лишь создают основу. Ключевую роль играет то, как модель обучена и как она используется. Давайте подробнее рассмотрим специальные приемы и модификации, позволяющие Transformer-моделям проводить рассуждения.
Chain-of-thought и управление выводом
Главный внутренний механизм reasoning-LLM — генерация и использование цепочки мыслей (chain-of-thought, CoT). В некоторых случаях эта цепочка явная (модель выводит промежуточные шаги), в других — скрытая. Например, OpenAI o1 генерирует внутренне несколько этапов решения, прежде чем выдать ответ. Исследователи проанализировали работу o1 и выяснили, что модель фактически проходит примерно 6 шагов размышления при решении задачи.
- Анализ проблемы — модель переписывает задачу своими словами, выявляет ключевые условия.
- Декомпозиция на подзадачи — разбивает сложную задачу на более простые части.
- Систематическое решение — последовательно решает каждую часть, шаг за шагом.
- Альтернативные решения — при необходимости рассматривает разные подходы или проверяет несколько вариантов решения.
- Самопроверка — периодически проверяет, соответствует ли промежуточный результат условию, нет ли противоречий.
- Самокоррекция — если обнаружена ошибка или противоречие, модель возвращается и исправляет, прежде чем идти дальше.
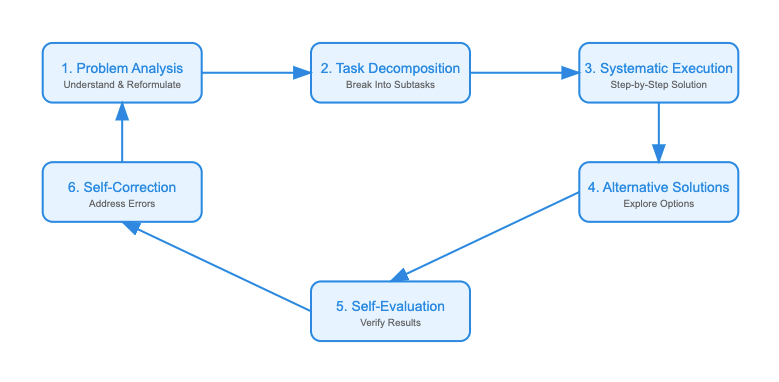
Типичные этапы внутреннего рассуждения LLM — от анализа задачи до самопроверки и коррекции ошибок. Модель может циклически возвращаться к ранним этапам, если во время проверки выявлены несоответствия.
Такой многоступенчатый процесс по сути встроен в архитектуру работы reasoning-модели. Реализуется он не добавлением новых модулей к Transformer, а специальным обучением и настройкой вывода. Модель обучена генерировать не просто ответ, а пару «решение + ответ». Цепочка рассуждений отделяется от основного ответа модели служебными токенами <think>…</think>.
Оптимизации reasoning-процессов
Чтобы модель могла эффективно рассуждать, одного механизма внимания мало — важна подготовка модели и окружения. Современные reasoning-LLM используют ряд оптимизаций.
1. Обучение с подкреплением (RLHF) на рассуждениях. И OpenAI o1, и DeepSeek R1 прошли через этапы RL, где модель вознаграждалась за правильные и логичные решения сложных задач.
Например, команда DeepSeek сначала обучила модель DeepSeek-R1-Zero чисто с помощью RL без какой-либо полуготовой разметки решений. Модель действительно научилась выдавать длинные цепочки рассуждений, выработав такие способности, как самопроверка и саморефлексия. Это подтверждает, что логические способности можно «вынудить» у LLM с помощью одного лишь подкрепления, даже без супервизии.
OpenAI o1, по заявленной информации, тоже обучали через RL: по сути, модель пыталась решать задачки, сравнивалась с эталоном и получала сигнал усилить те подходы, которые приводят к правильному ответу. Такой тренинг формирует у сети «внутреннюю привычку» рассуждать перед ответом.
2. Supervised fine-tuning (SFT) на решениях. Другой путь — обеспечить модель примерами правильных пошаговых решений. В ранних работах показано, что если в данных для тренировок есть решения с обоснованием, модель научится имитировать логическое обоснование.
Разработчики DeepSeek R1 после RL обнаружили у версии R1-Zero (в ней не использовали SFT) проблемы: лишнюю болтливость, повторения, не всегда читабельные ответ. Тогда они добавили стадию дообучения на подготовленных данных (cold-start data) и еще один этап RL с учетом предпочтений человека. Как итог — получили финальную модель DeepSeek R1. Этот микс SFT и RL позволил объединить сильные стороны подходов — и логичность решений, и читаемость/корректность ответа для пользователя. В целом, современные модели часто проходят сначала предварительное обучение на корпусе размеченных решений, а уже затем — RLHF для оттачивания.
3. Mixture of Experts (MoE). Другая архитектурная оптимизация — масштабирование параметров модели через Mixture-of-Experts. Это использовано в DeepSeek R1: модель состоит из множества экспертов (специализированных суб-моделей), что дает суммарно 671 миллиард параметров, из которых на каждый токен активно ~37 млрд (то есть не все эксперты задействуются одновременно). Такой подход позволяет существенно нарастить совокупную емкость модели без квадратичного роста вычислительных затрат, так как каждый токен обрабатывает лишь часть экспертов. Предполагается, что разные эксперты могут отвечать за разные типы задач или этапы рассуждений.
В результате DeepSeek-R1 достиг уровня OpenAI o1 по качеству на многих задачах, оставаясь достаточно экономичным по использованию вычислений. MoE — сложная в реализации технология, требующая распределенных вычислений, но она показывает, как архитектурные усовершенствования могут повысить способность модели к рассуждению, давая ей больше «мозгов», когда это нужно.
4. Увеличение контекстного окна. Рассуждения часто требуют помнить много информации: условие задачи, все промежуточные шаги, предыдущие попытки и т.д. Поэтому reasoning-LLM обычно имеют очень большой контекст.
Claude 3.7 Sonnet поддерживает контекст до 200 000 токенов (примерно 150 тыс. слов) – это позволяет ему удерживать целые книги или крупные проекты кода в памяти. DeepSeek R1 поддерживает 128k токенов ввода. Для сравнения, стандартный GPT-4 имеет максимум 32k. Большой контекст особенно полезен для reasoning, поскольку модель может «раздумывать» почти сколь угодно долго, не боясь выйти за пределы окна. Например, Claude в режиме Extended Thinking тратит до 128 тысяч токенов на размышление. Это значит, модель может последовательно анализировать очень сложную проблему, храня весь ход решения.
5. Модульные подсказки и планировщики. В некоторых приложениях reasoning-LLM выступает как планировщик, который генерирует общий план решения, а затем вызывает другие, более узкие модели или инструменты для выполнения шагов. Такая архитектура «модель-оркестратор» позволяет комбинировать интеллект reasoning-LLM с скоростью специализированных моделей.
К примеру, OpenAI в курсе Reasoning with o1 рассматривает прием, когда o1 разрабатывает план, а более дешевая модель o3-mini выполняет его части. Это сокращает стоимость, сохраняя качество решения. Хотя это скорее относится к использованию, упомянуть стоит: reasoning-LLM хорошо работают в паре с инструментами (калькуляторами, поиском) — они умеют формировать последовательность действий (по сути, код для себя), которая потом исполняется внешними средствами. Такая интеграция тоже частично закладывается при обучении: модели дают примеры взаимодействия с инструментами и поощряют правильное планирование их вызова.
Итого, архитектура reasoning-LLM — это симбиоз мощного Transformer (иногда массивно масштабированного), способного работать с огромным контекстом, и специальных методик обучения, которые прививают модели умение выстраивать и использовать цепочки рассуждений. Физически внутри таких моделей нет отдельного «модуля логики» — вся логика проявляется через обучение и правильный prompting, используя универсальные возможности Transformer. Тем не менее, результаты впечатляют: модели начинают демонстрировать качества, напоминающие человеческое решение задач.
Далее перейдем к обзору конкретных передовых представителей таких моделей и рассмотрим их особенности.
Передовые reasoning-LLM: OpenAI o1, DeepSeek R1, Claude 3.7 Sonnet
В 2024–2025 годах появилось несколько моделей, ставших в авангарде «революции рассуждений». Рассмотрим три из них:
- OpenAI o1 — проприетарную модель от OpenAI;
- DeepSeek R1 — открытую модель, которую создали исследователи в качестве альтернативы;
- Claude 3.7 Sonnet — флагманское решение от Anthropic.
- Мы проанализируем их характеристики, сильные и слабые стороны.
OpenAI o1: «мыслящий» потомок GPT-4
OpenAI o1 — это новая серия моделей, представленная в виде preview-версии в сентябре 2024. Она разработана специально для сложного рассуждения. По сути, o1 — ответ OpenAI на запрос решить задачи, с которыми не справлялся даже GPT-4. Модель доступна через ChatGPT (для Plus/Enterprise пользователей) и API.
По размерам o1 сравнима с топовыми LLM (точные параметры модели не раскрыты), но ее ключевая особенность — обучение с упором на chain-of-thought reasoning. Это дает впечатляющий скачок в ряде областей. Компания OpenAI сообщила, что на отборочном экзамене для Международной математической олимпиады (IMO) базовый GPT-4 решил лишь ~13% задач, тогда как модель o1 решила 83% задач. Разница колоссальная — о1 выходит на уровень хороших кандидатов в олимпийскую сборную по математике. Также кодинговые способности o1 оценивались на соревнованиях Codeforces: модель достигла 89% перцентиля, т. е. лучше большинства участников-людей.
Особенности и архитектура
Модель o1 построена на базе GPT-4o. Она сохранила все языковые способности GPT-4о, но получила новый тренировочный этап. Как заявлено OpenAI, при обучении o1 модели давали больше задач по науке, математике, коду и обучали методом подкрепления решать их глубже, а не наиболее коротким путем. В итоге модель научилась использовать так называемый test-time compute, т. е. увеличивать вычислительные усилия во время ответа, если задача сложная.
По сути, o1 может думать дольше, генерируя больше reasoning-токенов. Это отличается от обычных моделей, которые почти всегда отвечают за одну фазу генерации. Кроме того, o1 имеет модификации: выпущена облегченная версия o1-mini, которая на ~80% дешевле и быстрее, ориентирована на кодинг-задачи. Модель o1-mini позволяет использовать часть возможностей reasoning-модели там, где нужна экономия.
Производительность и ограничения
OpenAI o1 на момент создания статьи считается одной из сильнейших моделей в доказательстве теорем, решении олимпиадных задач, написании и отладке кода, а также в разборе научных вопросов. Она показала себя лучше GPT-4 в физике, химии, биологии на уровне задач PhD-вступительных экзаменов.
Однако у o1 есть и ограничения. Во-первых, из-за фокуса на сложных задачах модель может уступать в общих разговорах и в знании широкого контекста. OpenAI отмечала, что во многих повседневных запросах GPT-4o пока более способен, чем первая версия o1. Это объяснимо: o1 меньше специализировалась на диалогах, у нее отключены или не приоритезированы некоторые удобные функции (например, o1-preview изначально не поддерживала function calling, работу с изображениями и веб-браузинг). Фактически, o1 — это эксперт по рассуждениям, но не энциклопедист. Второе ограничение — скорость и стоимость.
В целом, сильные стороны o1 — это непревзойденная (на момент выхода модели) логика, способность решать задачи уровня олимпиад и конкурсов, отличные навыки написания/проверки кода, планирование комплексных процедур.
Слабые стороны: дороговизна и задержки, меньше знаний вне узких задач, отсутствуют некоторые мультимодальные возможности. Тем не менее, модель o1 получила широкое внимание сообщества как качественный прорыв. Ниже мы покажем пример использования модели o1, а пока перейдем к открытой альтернативе — DeepSeek R1.
DeepSeek R1: открытый «мыслящий» LLM
DeepSeek R1 — это одна из первых open-source reasoning-LLM, представленная в январе 2025 года. Ее разработали независимые исследователи проекта DeepSeek AI с целью сделать мощные рассуждающие модели доступными всем.
DeepSeek R1 заметна по двум причинам: во-первых, она добилась качества, сопоставимого с проприетарными моделями (в частности, заявлено соответствие OpenAI o1 по ключевым метрикам). Во-вторых, код и веса модели доступны всем — ее можно запустить локально или через API HuggingFace.
Архитектурно R1 очень интересна. Как уже упоминалось, это Mixture-of-Experts модель с суммарно 671 млрд параметров. При генерации каждого токена используются наиболее релевантные эксперты (около 37 млрд параметров). Такой подход позволил авторам объединить разные навыки в одной модели. Вероятно, часть экспертов специализируется на математике, часть — на коде, другая часть — на языке и т. д. Благодаря этому DeepSeek R1 показывает уверенные результаты во всех категориях задач – математика, логические ребусы, кодинг, работа с инструментами.
Обучение и возможности
DeepSeek R1 прошел уникальный путь обучения. Сначала базовую LLM (большого размера — вероятно, на основе Llama или Qwen) обучили через чистое RL без учителя, назвав результат R1-Zero. Уже эта модель продемонстрировала «эмерджентное» поведение рассуждения, а именно — умение генерировать очень длинные цепочки решений, предпринимать попытки самопроверки и рефлексии. Однако качество ответов оставляло желать лучшего: модель могла зациклиться или начать смешивать языки по ходу ответа. Тогда разработчики применили дополнительное обучение с учителем (видимо, на некотором объеме решений задач) и вторую фазу RL с учетом предпочтений человека.
Итог — модель DeepSeek R1, которая избавилась от главных проблем и стала более сбалансированной. Они также подготовили дистиллированные версии. Используя ответы большой R1, дообучили более мелкие модели на 1.5B, 7B, 14B, 32B и 70B параметров. Интересно, что DeepSeek-R1-Distill-Qwen-32B даже превзошла по ряду тестов проприетарную модель OpenAI o1-mini. Это показывает, что знание и логика R1 успешно передаются моделям поменьше, что крайне полезно для практики (можно задействовать 32B-модель, которая работает быстрее, но частично обладает разумом R1).
Возможности DeepSeek R1 сопоставимы с o1: она решает сложную арифметику, логические задачи, умеет писать код. В бенчмарках, например, на graduate-level reasoning (GPQA Diamond), R1 набрала 71,5% (против 75,7% у OpenAI o1), на соревновании AIME 2024 (математический конкурс школьников) — 79,8% (почти на уровне Claude 3.7 Extended, речь о которой пойдет дальше). На программном тесте SWE-bench (coding) R1 показала ~49,2% (почти как o1 ~48,9%), то есть обе модели выступают одинаково, хотя и уступают Claude 3.5 Sonnet в кодинге. Зато R1 почти догнала лидеров на математических задачах и достигла ~97,3% точности, тогда как o1 получила ~96,4%. Но они подтверждают: DeepSeek R1 действительно входит в число топ-моделей. А преимущество ее в том, что она открыта и дешевле в использовании.
Плюсы и минусы
К достоинствам DeepSeek R1 относится открытость и низкая стоимость. Модель выложена для скачивания, доступны API с куда меньшей ценой, чем у коммерческих конкурентов. Согласно сравнению, стоимость R1-подобных моделей — около $0.55 за миллион входных токенов и $2.19 за миллион выходных, тогда как у Claude 3.7 — $3 и $15 соответственно. Разница более чем в 6 раз. Это делает R1 привлекательной для внедрения в стартапах и исследованиях.
Второй плюс — большой контекст 128k токенов, что позволяет решать более масштабные задачи.
Третий — настраиваемость: сообщество уже начало тонкую настройку дистиллятов R1 под свои нужды, например, под другие языки или отдельные домены. Открытая лицензия этому не препятствует.
Из недостатков — отсутствие мультимодальности. DeepSeek R1 работает только с текстом. В отличие от Claude 3.7, она не умеет принимать изображения на вход.
MoE-модель крайне тяжела для разворачивания локально: потребуется серьезный кластер GPU, чтобы обслуживать 671B экспертов, поэтому пользователи чаще пользуются либо дистилляциями, либо облачными хостингами.
Еще есть нюансы, связанные с безопасностью и фильтрацией. Проприетарные модели проходят много этапов RLHF, чтобы отсеять нежелательные ответы. Про R1 пока таких подробностей меньше, а открытые модели могут быть более разговорчивыми на запрещенные темы.
Однако команда DeepSeek заявляет, что провела RL для согласования с человеческими предпочтениями, что подразумевает базовую контент-фильтрацию.
В целом, DeepSeek R1 — выдающийся пример того, что подходы, примененные в закрытых моделях (как o1), могут быть воспроизведены в «открытом мире». Это дает сообществу свободную reasoning-модель, которую можно изучать и улучшать далее.
Claude 3.7 Sonnet: гибридный подход от Anthropic
Claude 3.7 Sonnet — последняя флагманская модель от Anthropic. Выпущенная в конце февраля 2025, она известна как «первая гибридная модель рассуждений на рынке».
Под гибридностью понимается объединение в одном AI двух режимов: обычного быстрого ответа и развернутого пошагового размышления. Пользователь может переключаться — например, задать простой вопрос и получить ответ сразу (как от обычного Claude), либо активировать Extended Thinking и заставить модель рассуждать подробно.
Claude 3.7 Sonnet — коммерческая модель, доступная через интерфейс Claude.ai, API, а также на платформах Amazon Bedrock и Google Vertex AI. Бесплатный доступ позволяет пользоваться ею в ограниченном режиме (без extended-thinking) и с урезанным количеством сообщений. Полная функциональность открыта подписчикам Claude Pro и enterprise-API.
Архитектура и возможности
Claude 3.7 базируется на предыдущих Claude (модели семейства второго или третьего поколений). Точный размер не раскрыт, но это ориентировочно сотни миллиардов параметров.
Главное новшество — расширенное окно контекста до 200k токенов, что даже больше, чем у DeepSeek. Модель может обрабатывать огромные объемы данных: Anthropic декларирует, что Claude может читать и понимать целые кодовые базы, большие документы и т. д.
Также Claude 3.7 поддерживает изображения и является мультимодальным в отличие от o1 и R1. Ему можно предоставить картинку или PDF (через API) и задавать вопросы по ней. Такая функциональность роднит Claude 3.7 с GPT-4.
Уникальная фишка — Thinking Mode. В этом режиме Claude явно показывает свой ход рассуждений: печатает пронумерованные шаги или списком, а затем финальный ответ.
Anthropic сообщает, что Claude 3.7 Sonnet — «и обычная LLM, и модель рассуждений в одном лице». Пользователь волен решать, когда ему нужен быстрый ответ, а когда — глубокий анализ. В API для этого даже предусмотрен параметр «thinking-токены» — можно задать бюджет до 128k токенов, которые модель потратит на размышления. Это очень удобно: можно ограничить максимальную глубину, чтобы не тратить слишком много средств. Или, напротив, разрешить модели думать долго над критичной задачей.
Производительность
Claude 3.7 Sonnet на момент выхода побил многие рекорды. На бенчмарке SWE-bench Verified (решение реальных задач по программированию) он достиг 62,3% без специальных подсказок, а с использованием специального scaffold-промта — 70,3%. Это значительно выше, чем ~49% у OpenAI o1 и DeepSeek R1.
Иными словами, в задачах генерации кода Claude 3.7 стал новым лидером. На наборе TAU-bench (имитация работы AI-агента с внешними инструментами и веб-интерфейсами) Claude 3.7 тоже вышел вперед: например, в сценариях из ритейла он набрал 81,2%, тогда как OpenAI o1 —73,5%. В задачах авиационной отрасли 58,4% против 54,2% у o1. Эти тесты показывают, что Claude лучше планирует действия и использует API-инструменты, то есть пригоден для автоматизации некоторых бизнес-процессов.
На математических и логических задачах Claude 3.7 Extended достиг результатов на уровне лучших моделей: например, graduate-level reasoning — 84,8%, что чуть выше OpenAI o1 (78,0%) и вровень с моделью Grok 3 Beta (84,6%).
Сильные стороны Claude 3.7 Sonnet
- Гибкость режима работы. Пользователь может выбирать между быстрым ответом и глубоким анализом, что удобно в разных ситуациях. Это экономит время и деньги, давая возможность не «перегревать» модель там, где в этом нет нужды.
- Отличная производительность на практике. Claude 3.7 лидирует в генерации кода и почти не уступает никому в логических задачах, что подтверждается множеством метрик. Он особенно хорош для бизнес-применений: длинный контекст позволяет загрузить все данные, а сила рассуждений — принимать верные решения, следуя правилам.
- Большой контекст и мультимодальность. 200k токенов и поддержка изображений дают широкие возможности. Например, модель можно использовать для анализа большого PDF-документа с таблицами и картинками – она прочтет его целиком и ответит на вопросы.
- Интегрированность. Claude доступен на основных платформах облачных провайдеров, что упрощает внедрение. Кроме того, Anthropic активно сотрудничает с разработчиками (пример — интеграция Claude в продукты Notion, Quora и др).
Слабые стороны Claude 3.7 Sonnet
- Закрытость и стоимость. Как и OpenAI, Anthropic не раскрывает устройство модели и не предоставляет возможности тонкой настройки для сторонних. Использование API платное и довольно дорогое (в ~6 раз дороже, чем у DeepSeek R1 на токен). Для индивидуальных пользователей и исследователей Claude менее доступен.
- Ограничения бесплатного доступа. В бесплатном режиме Thinking Mode недоступен, что несколько снижает пользу для пользователей, которые не готовы платить за подписку.
- Скорость. Хотя Claude оптимизирован, использование 200k контекста или полных 128k «thinking tokens» может быть очень медленным. В количестве времени на рассуждение Claude 3.7 может уступать по времени o1 или другим моделям подобного типа.
Итог. Claude 3.7 Sonnet — очень сбалансированная и продвинутая reasoning-LLM, подходящая для широкого круга задач и обеспечивающая удобный контроль над процессом рассуждения.
Факторы, влияющие на точность reasoning-LLM
Качество обучения и объем данных. Как и для всех LLM, объем и разнообразие тренировочных данных сильно влияют на возможности reasoning-модели. Однако в случае reasoning-LLM важен не просто объем текстов, а наличие сложных задач и их решений в этих данных. Например, если модель в процессе обучения видела тысячи математических доказательств или пошаговых решений задач, она с большей вероятностью научится воспроизводить такой стиль мышления. Именно поэтому при создании моделей вроде o1 упор сделали на добавление в датасет научных и математических задач, программного кода, логических викторин и так далее. Чем богаче такой набор, тем более разносторонне модель сможет рассуждать.
Кроме того, сами по себе большие модели с сотнями миллиардов параметров обладают большим потенциалом. Исследователи обнаружили, что умение логически рассуждать является эмерджентным свойством, проявляющимся начиная с определенного масштаба модели. Например, небольшой 6-миллиардный LLM почти не выигрывает от chain-of-thought prompting, а вот модель >100 млрд уже значительно улучшает качество ответа. Это говорит о том, что для высокоточных reasoning-LLM почти всегда берут крупные архитектуры или объединение экспертов (как DeepSeek R1). Модель должна быть достаточно «умной», чтобы удерживать сложные зависимости — иначе ни приемы, ни fine-tuning не дадут нужного эффекта.
Промтинг. Один из самых важных факторов — это то, как мы задаем вопрос модели. Даже самая продвинутая reasoning-LLM может дать неверный ответ, если запрос двусмысленный или не просит обоснования, когда оно нужно. Правильно сформулированный промт способен раскрыть потенциал модели. Мы уже упоминали принцип «Let’s think step by step», который практически вдвое-втрое повышает точность на многих задачах. Это яркий пример: пользовательская инструкция явно включает модель в режим пошагового ответа.
Для reasoning-LLM подобные подсказки могут быть встроены неявно (например, в o1 модель сама инициирует chain-of-thought, даже если пользователь не просит). Но в большинстве случаев лучшая практика — указать на необходимость рассуждения. Можно использовать такие фразы, как «Покажи ход решения», «Объясни, как ты пришел к ответу», «Решай поэтапно» и т. д. Такие инструкции служат одновременно и проверкой: модель, расписывая решение, с меньшей вероятностью допустит грубую ошибку или пропустит важное условие.
Помимо chain-of-thought помогают и другие приемы prompt engineering. Например, few-shot prompting, чтобы показать модели 1-2 примера решения похожих задач, прежде чем дать новую. Модель по аналогии выстроит ответ. Или role prompting — чтобы задать роль: «Ты – эксперт-математик, рассуждающий строго и пошагово…» Это может подтянуть стиль ответа к более аналитическому. В целом, точность reasoning-LLM сильно зависит от качества инструкции: чем яснее запрос, тем выше шанс правильного решения.
Fine-tuning и дообучение. Если требуется повысить точность модели на определенном типе задач, помогает дообучение на задачах этого типа. Например, если компания хочет использовать reasoning-LLM для правовых заключений, можно дообучить (instruction-tune) модель на корпусе юридических кейсов с правильными рассуждениями. Это улучшит ее компетентность именно в правовой логике.
В сообществе уже применяют такой подход: открытые модели вроде Llama 2, Pythia и другие дообучают на размеченных решениях (в том числе используют данные chain-of-thought, сгенерированные крупными моделями). Эффект — улучшение точности на целевых тестах. DeepSeek R1-distill модели, по сути, являются результатом файнтюнинга меньших моделей на решениях большой R1. Они показали, что даже 7–32B модели могут выйти на уровень, близкий к 70B, если перенять ее цепочки рассуждений. Таким образом, файнтюнинг — весомый фактор. Когда мы даем модели больше правильных примеров логики, то повышаем вероятность, что она не собьется.
Параметры инференса: temperature, self-consistency. Методы генерации тоже влияют на точность на сложных задачах. Как правило, для логических задач лучше ставить temperature=0 (детерминированный вывод с прицелом на наиболее вероятный токен) — это снижает творческие отклонения и уменьшает случайные ошибки. Однако есть интересный прием — self-consistency: модель несколько раз генерирует решение при высокой temperature, а потом выбирает наиболее частый ответ.
Было показано, что такой метод повышает итоговую точность, так как устраняет ответы, которые получаются в единичных (возможно, ошибочных) цепочках. Модель как бы «голосует» различными мыслями. Этот подход требует больших вычислительных затрат, так как нужно сделать N итераций инференса, но для критичных задач улучшает надежность. Некоторые reasoning-LLM, возможно, уже частично реализуют нечто подобное внутри (например, o1 генерирует альтернативные решения на четвертом шаге и выбирает лучшее).
Инструменты и дополнительные проверки. Точность можно повысить, подключив модель к внешним инструментам: интерпретатору кода, поиску, базам знаний. Если модель может делать API-запросы (например, function calling в OpenAI или Chain-of-Thought с инструментами), она способна проверять факты и вычисления. На ее рассуждениях это сказывается положительно: снижается нагрузка на «смекалку» модели там, где можно просто посчитать или найти готовую информацию. Передовые reasoning-LLM умеют планировать такие действия. Пример — результаты TAU-bench у Claude, где он успешно использовал внешние инструменты.
Логические ошибки и их обработка. Даже лучшие reasoning-LLM пока не идеальны – они могут допускать ошибки в рассуждениях. Однако важен подход к этим ошибкам. Если модель обучена распознавать свои ошибки, общая точность выше. Мы видели, что o1 и другие внедряют шаг Self-Evaluation. Это значит, модель проверяет свои промежуточные ответы. Например, решая уравнение, она может подставить найденный корень обратно, чтобы убедиться, что уравнение верно. Такие проверки нередко прописываются явно при файнтюнинге или от модели требуют в промте («проверь, что ответ удовлетворяет всем условиям»). Таким образом, навык самопроверки — критичный фактор качества. Если модель сразу выдает ответ без оглядки, шанс ошибки выше, чем если она потратит пару лишних шагов на верификацию.
Обработка инструкций (Alignment). Настройки инструкций (например, RLHF, ориентированное на предпочтения пользователей) также оказывают влияние на точность reasoning-LLM, причем иногда это влияние может быть негативным. Например, слишком строгая фильтрация нежелательных ответов может привести к тому, что модель начинает отказываться отвечать даже на технически корректные вопросы, посчитав их «опасными» или «этически некорректными». С другой стороны, стремление угодить пользователю способно подтолкнуть модель к некритичному согласию с неверными или вводящими в заблуждение подсказками. Наилучшие reasoning-LLM стремятся балансировать между четким выполнением инструкций и сохранением объективной логики ответов.
Хорошим примером работы с такими настройками является подход компании Anthropic, которая специально занималась снижением процента неоправданных отказов модели Claude (количество таких отказов удалось уменьшить примерно на 45%). Благодаря этому модель стала менее осторожной, что повысило её способность решать задачи вместо того, чтобы просто отказываться от ответа. В то же время качественные модели стараются удерживать рамки логики и не поддаваться чрезмерному давлению со стороны пользователей. Таким образом, правильно настроенные alignment-параметры помогают существенно повысить общую точность reasoning-LLM.
Итак, совокупность факторов — объем знаний, специальные тренировки на логике, продуманные подсказки, алгоритмы генерации и интеграция инструментов — определяют, насколько успешной будет reasoning-модель в реальных задачах. Лучшие результаты достигаются, когда все эти аспекты учтены: модель большая и обучена на решении задач, пользователь правильно формулирует вопрос, а модель на этапе вывода проверяет себя и использует все возможности (внутренние и внешние), чтобы дать верный ответ.
Практические рекомендации по использованию reasoning-LLM
В заключение — несколько советов, как эффективно работать с reasoning-LLM, чтобы получить максимальную пользу от их возможностей:
Выбирайте модель под задачу. Если у вас простой вопрос, не требующий глубокого анализа, используйте обычные LLM (они дешевле и быстрее).
Reasoning-модели стоит привлекать для реально сложных проблем: многошаговые вычисления, генерирование алгоритмов, сложные вопросы, где нужен анализ. Например, в рамках ChatGPT Plus переключайтесь на Advanced Reasoning модель (o1) только когда уверены, что GPT-4 не справляется с требуемой логикой.
Ясно формулируйте запрос и просите рассуждение. Четко опишите проблему, укажите все данные. Добавьте фразу, побуждающую к размышлению: «Объясни свой ход решения» или «Решай по шагам». Это заставит даже менее склонную к рассуждению модель выдать цепочку, что повысит точность и прозрачность. Избегайте двусмысленности: модель может пойти по неверному пути, если вопрос нечеткий.
Используйте форматирование и разбиение проблемы. В длинных задачах полезно разбить ввод на части или пронумеровать шаги. Например: «1) Вот данные… 2) Требуется найти… 3) Обрати внимание на условие…». Модель с большей вероятностью структурирует ответ аналогично.
Вы также можете задать подзадачи последовательно: спросить сперва, что означает условие, потом попросить решить. Reasoning-LLM хорошо справляются с многоходовыми диалогами, где каждый следующий вопрос основывается на предыдущем ответе модели.
Ограничивайте «мышление» при необходимости. Если вы используете Claude 3.7, можно выставить thinking token limit, либо в явном виде указать: «Дай короткое объяснение и ответ». Хотя модели и склонны рассуждать, они следуют инструкциям, поэтому если нужна лаконичность, предупредите об этом. Аналогично в OpenAI o1, можно попросить: «Пожалуйста, только решение без лишних выкладок». Тогда модель выдаст более компактный результат (но все равно продуманно).
Проверяйте критичные ответы. Несмотря на высокий уровень reasoning-LLM, доверяйте, но проверяйте.
Если получен ответ на важный вопрос (например, медицинский расчет, финансовая модель) — стоит перепроверить логику. Можно сделать это двумя способами.
Первый — попросить саму модель проверить свое решение. Например: «Ты получил ответ X. Проверь, соответствует ли он исходным условиям и нет ли ошибок в расчетах». Модель еще раз прогонит свою цепочку и либо подтвердит, либо найдет изъян и исправит.
Второй способ — использовать другую модель или инструмент. Например, сгенерировать тот же запрос через другую модель (или другую температуру) и сравнить ответы; либо прямо скормить финальную формулу вычислителю. Reasoning-LLM обычно не обижаются на перепроверку — наоборот, иногда сами предупреждают, если не уверены в результате.
Используйте функцию self-consistency вручную. Если интерфейс позволяет, попробуйте задать один и тот же вопрос несколько раз (с разными начальными random seed) и собрать несколько решений. Затем посмотрите, к какому ответу модель пришла чаще. Это особенно полезно для задач, где возможны несколько подходов – модель может первое решение сделать неправильно, а второе – правильно. Сравнение и «голосование» между ними повышает вашу уверенность.
Применяйте дополнительные инструменты. Современные фреймворки (LangChain, LlamaIndex и др) позволяют оборачивать LLM в цепочки с инструментами. Если задача включает, скажем, поиск в базе знаний и логическое объединение фактов, настройте пайплайн, чтобы сначала модель формировала поисковый запрос, искала (через API) и после анализировала найденное. Reasoning-LLM в таких условиях раскроют потенциал полностью — они будут и рассуждать, и пользоваться актуальными данными. Например, DeepSeek R1 в связке с Wikipedia API могла бы ответить на сложный вопрос с проверкой фактов — сначала найти статью, затем логически обработать.
Следите за обновлениями моделей. Область развивается очень быстро. Появляются новые версии (Claude 4? OpenAI o2?), которые наверняка превзойдут текущие. Иногда обновления улучшают навыки рассуждений или расширяют контекст еще больше. Имеет смысл периодически тестировать новые модели на ваших задачах.
Также открытые решения типа DeepSeek будут совершенствоваться — возможно, через несколько месяцев появятся R2 или улучшенные дистилляты. Быть в курсе — значит, иметь возможность повысить качество ваших приложений.
Учитывайте затраты и latency. При внедрении reasoning-LLM в продукт важно балансировать между качеством и стоимостью. Например, можно реализовать логику: сперва попытаться ответить стандартной моделью (быстро и дешево), и только если уверен, что задача сложная — переключаться на reasoning-модель. Такой роутинг упоминается и OpenAI в рекомендациях (Reasoning with o1 – DeepLearning.AI).
Можно ограничивать глубину reasoning в настройках. Claude позволяет вручную задать флаг extended только когда пользователь запросил анализ. В OpenAI API можно самой программе решать, когда вызывать model=”o1″ (например, по ключевым словам в вопросе или если GPT-4 выражает неуверенность).
Используйте meta-prompting. Интересный прием для продвинутых пользователей: попросите саму модель улучшить ваш промпт. Например, вы дали задачу, и модель ответила, но не очень уверенно. Спросите: «Как переформулировать вопрос, чтобы тебе было проще его решить?» — модель может предложить уточнить данные или разбить вопрос. Либо напрямую: «Придумай, какие шаги нужны для решения, и составь инструкцию для себя же». Это хоть и загадочно выглядит, но порой помогает. O1, как отмечали сами разработчики, может выступать в роли мета-подсказчика для других моделей.
Следуя рекомендациям, вы сможете извлечь из reasoning-LLM максимум пользы. Эти модели открывают новые горизонты: теперь машина может не просто отвечать, но и думать. При грамотном использовании они становятся настоящими помощниками для инженеров, аналитиков и исследователей, позволяя решать задачи, которые раньше были неподъемны для ИИ.
Вместо заключения
Reasoning-LLM — яркий пример того, как качественные изменения в подходе приводят к прорыву. Мы рассмотрели три современные модели: OpenAI o1, DeepSeek R1, Claude 3.7 — каждая из них по-своему продвинула границы возможностей ИИ. OpenAI внедрила понятие «размышляющего» ИИ массово через ChatGPT, DeepSeek — показала, что открытое сообщество не отстанет и сможет воспроизвести эти достижения, а Anthropic — предложила удобный компромисс между скоростью и глубиной размышлений.
Однако важно помнить и о контроле: reasoning-LLM все еще могут делать ошибки или «уверенно заблуждаться». Человек должен оставаться в цикле, проверять критичные решения. В то же время прозрачность работы с цепочками мыслей у некоторых провайдеров этому очень помогает.
Будем следить за развитием reasoning-LLM. Вероятно, в ближайший год-два мы увидим еще более мощные версии. Но уже сейчас эти модели — ценный инструмент в арсенале IT-специалистов, способный значительно повысить продуктивность там, где требуется аналитическое мышление. Используя их грамотно, мы фактически получаем в команду виртуального эксперта, готового думать над задачей столько, сколько нужно, не уставая и не теряя внимательность. И это, без сомнения, одно из самых захватывающих направлений развития ИИ.





