

За последние годы инструменты на базе генеративного ИИ стали заметной частью работы с изображениями. В Adobe Photoshop появились функции вроде Generative Fill, упрощающие редактирование сцен и объектов без ручного маскирования.
В этом контексте интерес представляет семейство моделей Qwen от Alibaba, а именно Qwen-Image-Layered — модель, предназначенная для разбиения изображений на отдельные семантические слои. Такой подход потенциально может упростить работу с иллюстрациями и фотографиями, но на практике имеет ряд ограничений, которые важно учитывать.
Многослойность в Qwen
Тестирование на иллюстрации
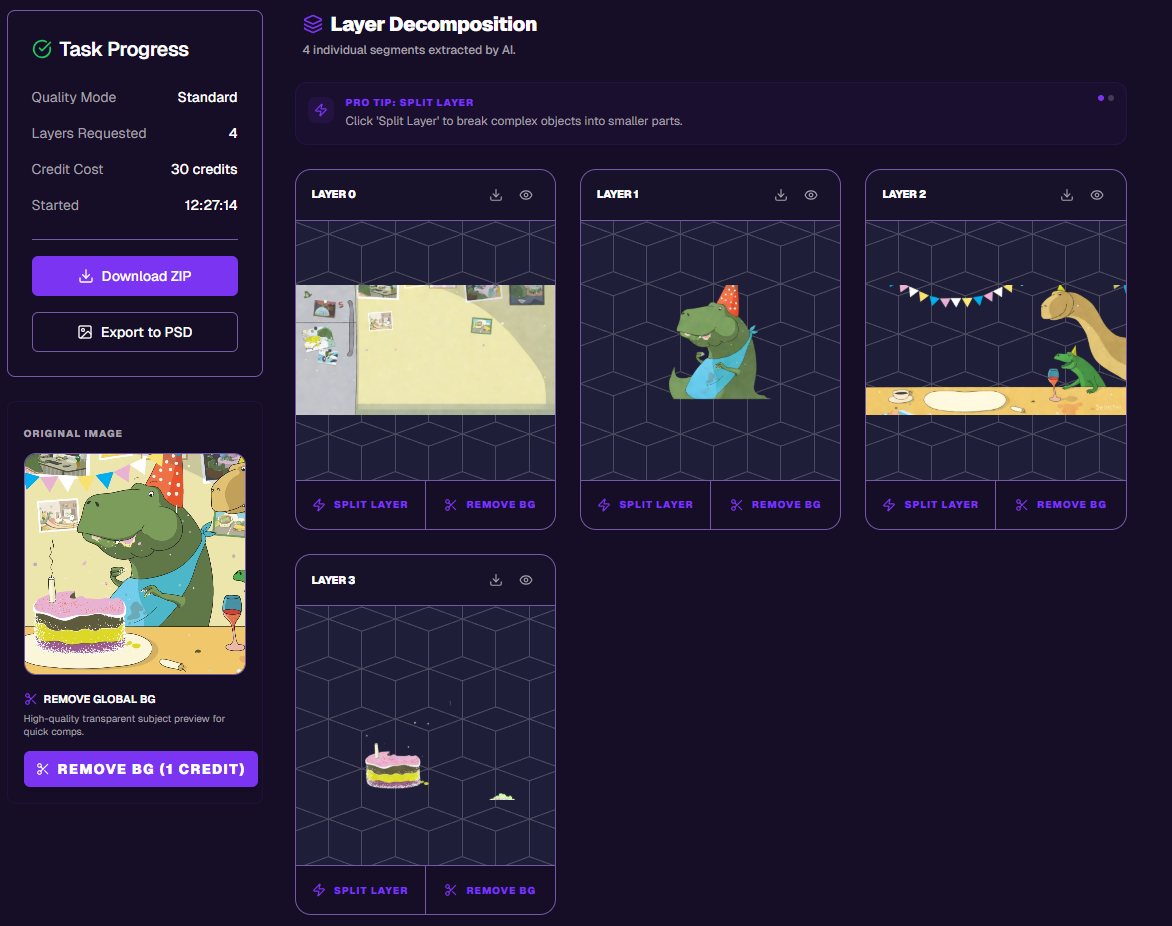
В качестве первого примера возьмем детализированную иллюстрацию с большим количеством мелких элементов, острых форм и пересечений объектов. Такие изображения обычно сложнее для автоматической сегментации, чем условно «плакатные» сцены с простыми формами и однородным фоном.

Модель разобрала картинку на четыре слоя, но их количество можно настраивать вплоть до десяти:

Первый слой (фон).



В целом модель справилась неплохо: фон с мишурой корректно вынесен в отдельный слой, основные объекты отделены друг от друга, а мелкие детали в большинстве случаев сохранены. При этом несколько треугольников мишуры с фона задублировались между слоями, что усложняет дальнейшее редактирование. Но плюс в карму модели за то, что она очистила лапы Тирекса от торта и даже поместила отпечатки в отдельный слой с тортом.
Само разбиение — лишь половина задачи. Для полноценного редактирования важно уметь менять содержимое каждого слоя или генерировать замену с сохранением стиля. Для этого в экосистеме Qwen существует отдельный инструмент — Qwen Image Edit, однако на текущий момент он не интегрирован напрямую в Layered.
Мы уже тестировали Qwen Image Edit в отдельном материале, где заодно рассмотрели модель для генерации речи TTS-Flash и универсальную мультимодальную модель Qwen Omni.
Тестирование на фотографии
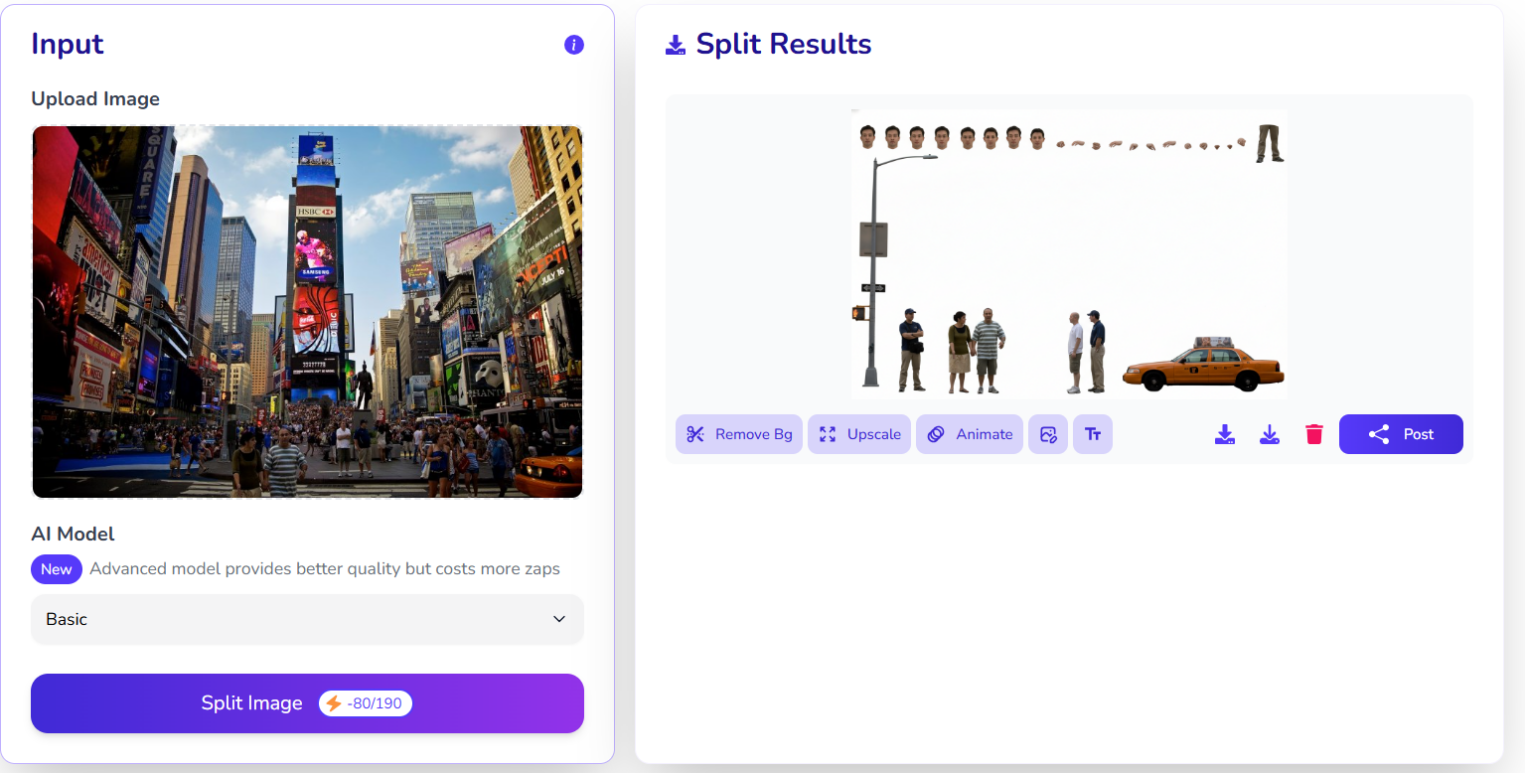
Для второго сценария была выбрана фотография Таймс-сквер в Нью-Йорке — сцена с большим количеством мелких деталей, пересечений объектов и разнородными слоями. Такой тип изображений традиционно сложен для автоматической семантической сегментации.

В результате модель также сформировала четыре слоя:



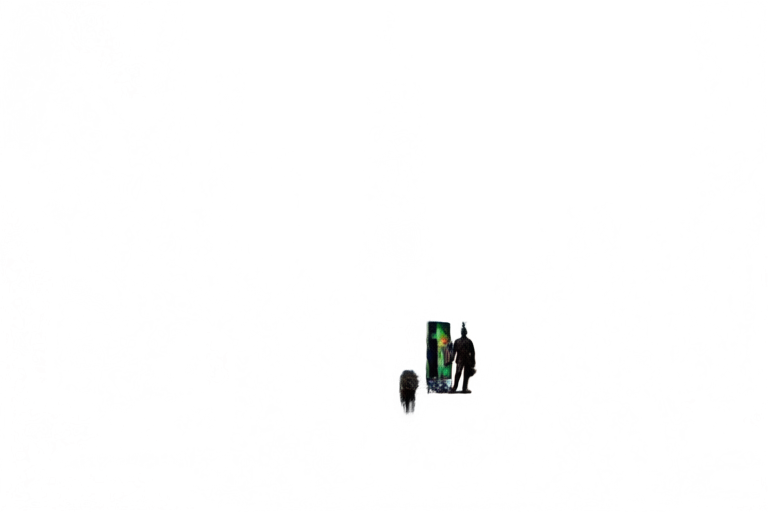
Получившиеся слои слабо соответствуют логической структуре сцены. Модель не удерживает целостность объектов: например, людей, идущих вместе, она разносит по разным слоям. В таком виде результат сложно использовать для последующего редактирования — слои не отражают ни смысловые группы, ни пространственные связи между объектами.
По итогам тестирования можно сделать вывод, что Qwen-Image-Layered неплохо справляется с разбиением относительно простых иллюстраций, но демонстрирует существенные ограничения при работе с фотографиями сложных сцен. Дополнительное ограничение — отсутствие прямой интеграции Qwen Image Edit в Layered. Для генерации или замены объектов приходится сначала работать в Image Edit, а затем вручную переносить результат в Layered, что усложняет рабочий процесс и нарушает целостность контекста.
Возможные аналоги
Насколько уникален подход Qwen-Image-Layered и есть ли у него прямые конкуренты? Среди доступных решений удалось найти лишь несколько веб-сервисов с ограниченным бесплатным доступом, которые позволяют автоматически разбивать изображение на слои. Протестируем их на тех же примерах, что и Qwen.
Foundation Models Catalog — сервис для запуска и управления LLM в облаке Selectel. Выберите модель, конфигурацию и получите готовый endpoint для работы с ней. На борту уже есть преднастроенные модели Qwen, OpenAI, DeepSeek и Mistral AI. Сейчас доступ к сервису предоставляется в первую очередь юридическим лицам по запросу. В дальнейшем сервис станет доступен для всех пользователей.
Image to Layers
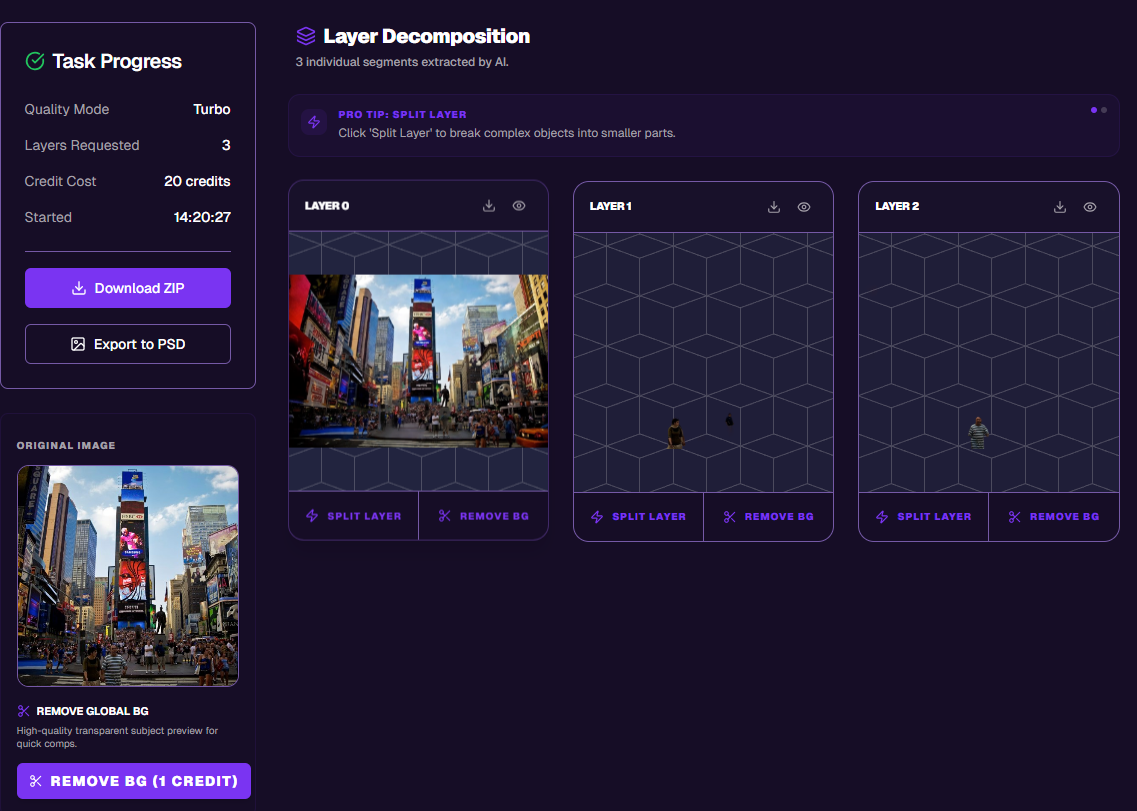
Первый сервис — Image to Layers — представляет собой веб-инструмент для автоматического разбиения фотографий и изображений на слои. Среди ключевых особенностей — возможность дополнительно дробить полученные слои и автоматическое заполнение скрытых участков фона при разделении, что снижает количество артефактов.




При тестировании на иллюстрации результат оказался сопоставимым, а в отдельных моментах — даже более аккуратным. Треугольные элементы мишуры были корректно отделены без заметных артефактов. При этом часть мелких деталей, таких как конфетти и брови персонажей, оказалась ошибочно вынесена в отдельный слой.
В целом качество генерации можно оценить немного выше по сравнению с результатом от Qwen. Но небольшой спойлер: с разделением фотографии эта модель не справилась.

Первый слой, который на первый взгляд не многим отличается от исходника.
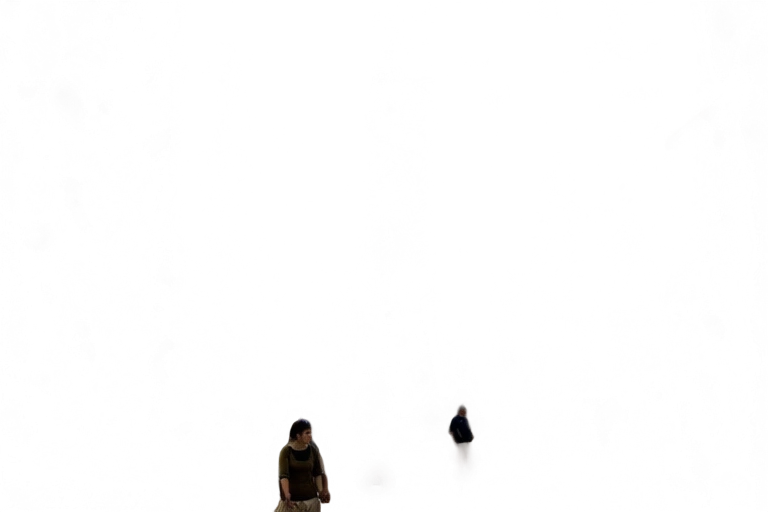

При работе с фотографией сервис продемонстрировал примерно те же ограничения. Алгоритм не сохраняет семантическую целостность объектов: людей, идущих вместе, он разделяет на разные слои, что делает результат малопригодным для дальнейшего редактирования сложных сцен.
AI Layer Splitter от KomikoAI
Второй инструмент для тестов — AI Layer Splitter (KomikoAI). Сервис позиционирует себя как универсальную платформу для генерации картинок, их анимации, раскрашивании, редактировании и разделении на слои. Доступ к функциям ограничен системой кредитов с возможностью оформления подписки.
Сервис KomikoAI отображает результаты генераций других пользователей, среди которых встречается контент, не соответствующий требованиям законодательства Российской Федерации. В рамках статьи инструмент рассматривается исключительно с технической точки зрения, без оценки или распространения пользовательских материалов.
Для теста была загружена та же иллюстрация, при этом использовалась расширенная модель, потребляющая большее количество кредитов.
Результат разбиения выглядит пугающе: «черты» персонажей были искажены, а задние лапы и нижняя часть туловища Тирекса были сгенерированы без спроса. Но в остальном модель справилась хорошо и фон вырезан — подставляй какой хочешь. Конфетти удалены — модель немного упростила себе жизнь и не стала вырезать их в отдельные слои. Сложные фигуры отделены хорошо. В сумме было получено около 20 слоев, что удобно для дальнейшего ручного редактирования и компоновки сцены.

Однако при тестировании на фотографии сервис столкнулся с теми же ограничениями, что и ранее рассмотренные решения. Вместо осмысленного разбиения сцены на логические слои результат представлял собой набор «лего-человечков», не отражающих семантическую структуру изображения. Как и в предыдущих случаях, инструмент не продемонстрировал устойчивой сегментации сложной городской сцены. Но и небольшой прогресс есть: семейная пара здесь выделена как один элемент!
Модель не перестает пугать своими генерациями, на этот раз слоев мы вообще не получили, а получили набор лего-человечков. С задачей разбиения фотографии и эта модель не справилась. Но хоть тут семейная пара была вместе! Это прогресс.

Заключение
Инструменты для автоматического разбиения изображений на слои пока остаются на ранней стадии развития. В ходе тестирования были заметны артефакты, несогласованность слоев и отсутствие устойчивой логики сегментации в ряде сценариев. Особенно слабо все рассмотренные решения справляются с разбиением реальных фотографий сложных сцен.
Qwen-Image-Layered демонстрирует приемлемые результаты при работе с иллюстрациями и простыми композициями. Несмотря на ограничения, его преимущество заключается в бесплатной доступности и возможности использовать в связке с Qwen Image Edit для генерации и замены отдельных элементов. Это делает его наиболее практичным вариантом среди протестированных инструментов.
Коммерческие веб-сервисы в ряде случаев показывают более аккуратное разбиение иллюстраций на отдельные элементы, однако они также не справляются с фотографиями и накладывают ограничения в виде кредитной системы и подписок.
В целом направление автоматической декомпозиции изображений выглядит перспективным и потенциально полезным для дизайнеров и разработчиков. Однако до уровня удобства и точности, который сегодня предлагает Photoshop с ручным и полуавтоматическим редактированием, таким моделям пока далеко.



