Самые популярные расширения PostgreSQL
Обзор расширений, которые встречаются чаще всего. Зачем они нужны, чем помогают в реальных проектах и какие могут быть ограничения.

PostgreSQL поддерживает не только встроенные инструменты, но и дополнительную для пользователя функциональность. Существует огромное количество расширений, каждое из которых помогает решать конкретные задачи пользователей. С их помощью можно адаптировать базу данных под собственные нужды и упростить работу с данными.
Зачем PostgreSQL расширения
Стандартная сборка PostgreSQL предоставляет надежный и функциональный механизм реляционной СУБД, но не охватывает все возможные сценарии использования. Рассмотрим наиболее распространенные из них.
Расширенная аналитика и машинное обучение
СУБД не предназначена для выполнения сложной аналитики и задач машинного обучения. Она поддерживает базовые агрегаты и оконные функции, но не включает инструменты для статистического моделирования, регрессии, кластеризации или работы с матрицами и векторами.
Управление данными больших объемов (Big Data)
PostgreSQL — это классическая СУБД. Основные ограничения связаны с невозможностью масштабирования по горизонтали «из коробки» (т. е. нет поддержки шардирования), а также с ограничениями на хранение, обработку и скорость доступа к данным в многопоточных и многосерверных средах.
Последние связаны с тем, что у PostgreSQL есть особенности работы с CPU, которые важны при стартовом выборе конфигурации кластера. СУБД однопоточная на уровне выполнения запроса, то есть один SQL-запрос = один процесс = одно ядро. Это значит, что масштабирование происходит по количеству параллельных запросов, а не внутри одного запроса. Отсюда следует, что высокочастотные ядра (CPU линейки HighFreq) могут быть особенно полезны в нагрузке, где важна минимальная латенси одиночных запросов.
Специализированные типы данных и функции
СУБД не поддерживает специализированные типы данных и операций. Например, в ней отсутствуют встроенные геоданные и функции для пространственного анализа, иерархические структуры, расширенные XML-функции (XPath, XSLT), типы для временных рядов и другие операции.
Интеграция с определенными платформами или сервисами
PostgreSQL не поддерживает нативное подключение к другим источникам данных. Чтобы получить доступ к внешним базам, применяются FDW (Foreign Data Wrappers) — расширения, реализующие SQL/MED (Management of External Data).
Сложная оптимизация производительности
Для работы с высокими нагрузками и сложными запросами возможностей PostgreSQL недостаточно. В таких случаях используются расширения. Например, pg_stat_statements и auto_explain помогают выявить и проанализировать тяжелые запросы, hypopg — оценить эффективность гипотетических индексов без их создания, а pg_hint_plan — управлять планом выполнения вручную.
Какие расширения популярны
pg_repack
Это расширение для PostgreSQL, которое помогает бороться с «раздуванием таблиц», которое в свою очередь является следствием поддержки MVCC. Расширение удаляет мертвые строки, оставшиеся после DELETE и UPDATE. Это позволяет дефрагментировать и компактно переписать таблицу или индекс без блокировки таблицы, в отличие от VACUUM FULL.
- Создает временную «чистую» таблицу‑копию и индексы.
- Копирует в нее все актуальные данные.
- Следит за всеми изменениями в оригинальной таблице .
- Догоняет изменения, произошедшие в исходной таблице.
- Переключает имена таблиц за доли секунды.
- Удаляет старый bloat‑файл.
Его выбираю потому что он упрощает эксплуатацию кластеров, позволяя уменьшать размер данных на диске без простоя для приложения. Подробнее об этом расширении рассказывали в этой статье.
PostGIS
Расширение предназначено для работы с геоданными.
Почему его выбирают
- Поддерживает пространственные индексы R-Tree/GiST и функции обработки геоданных.
- Оперирует такими геометрическими объектами, как точка, линия, полигон, мультиточка, мультилиния, мультиполигон и геометрическая коллекция. Они определены в формате Well Known Text Open GIS (с расширениями XYZ, XYM, XYZM).
- В PostGIS входят другие экстеншены по работе с геокодингом: address_standardizer; address_standardizer_data_us; postgis_tiger_geocoder, postgis_topology.
- Позволяет создавать запросы, совмещающие тесты на попадание объекта в охват и заданный радиус.
pgcrypto
Расширение предоставляет криптографические функции для PostgreSQL. Подробнее о pgcrypto можно узнать в Академии Selectel.
Почему его выбирают
- Поддерживает популярные и надежные криптографические алгоритмы — например, SHA, MD5, AES.
- Позволяет выполнять шифрование и хеширование данных без внешних сервисов.
- Повышает безопасность за счет хранения и обработки чувствительных данных внутри СУБД.
jsquery
Расширение выполняет полнотекстовый поиск и запросы по JSON-данным в PostgreSQL. Почитать о нем подробнее можно в этой статье.

Почему его выбирают
- Эффективная индексация и поиск по сложным JSON-структурам.
- Поддерживает гибкие запросы к вложенным полям и массивам JSON.
- Ускоряет полнотекстовый поиск внутри JSON благодаря специализированным индексам.
- Упрощает работу с динамическими и полуструктурированными данными без потери производительности.
TimescaleDB
Расширение позволяет хранить временные ряды (time series-данные) и управлять ими.
В облачных базах данных Selectel расширение представлено отдельным типом БД для PostgreSQL (в качестве расширения TimescaleDB не добавляется). К созданной базе можно подключать дополнительные экстеншены. Например, расширения pg_stat_statements или postgres_fdw, которые мы рассмотрим отдельно.

Почему его выбирают
- Оптимизирует хранение time series-данных: время вставки новых значений не увеличивается при увеличении количества данных.
- Не нужно переходить на сторонние решения, заточенные под time series-данные, — ClickHouse, InfluxDB и другие.
- Работа в одном программном стеке. Можно хранить как временные ряды, так и другие типы данных на одной платформе.
pg_stat_statements
Расширение собирает статистику по работе всех баз данных: какие запросы, какое время выполнялись, есть ли запросы, тормозящие работу, и т.д.
Почему его выбирают
- Позволяет выследить запрос, который снижает производительность базы данных, и оптимизировать его.
Клиентам облачных баз данных Selectel экстеншен подключается по умолчанию.
postgres_fdw
Расширение позволяет обращаться к внешним СУБД, файлам и веб-сервисам.

Почему его выбирают
- Позволяет получать данные из нескольких БД без сторонних инструментов.
- Пригодится для шардинга, где нужно поделить одну большую базу данных на несколько инстансов в вертикальной или горизонтальной логике.
- Поможет провести бесшовную миграцию с одной базы данных на другую или объединить несколько БД.
- Готовые FDW (foreign-data wrappers) есть у MySQL, Redis, MongoDB, ClickHouse, Kafka и других СУБД.
btree_gist
Расширение позволяет работать сразу с двумя индексами PostgreSQL — btree и GiST.
Почему его выбирают
- Подходит для типов данных, где не работает жесткая семантика сравнения — «больше», «меньше» или «равно», характерная для btree.
- Предоставляет оператор «не равно» и оператор расстояния для поиска ближайших соседей с использованием индексов GiST.
- Полезно для баз данных, где часть полей индексируется только с GiST, а другая — представляет собой простые типы данных.
pgvector
Это расширение, простой способ добавить векторный поиск туда, где уже есть PostgreSQL, и понять необходимость новой функциональности в вашем проекте.
Его выбирают для:
- MVP или AI-стартапов,
- простых AI-интеграций,
- нетребовательных внутренних AI-систем,
- AI pet-проектов.
Подробнее о нюансах работы расширения рассказывали в этой статье.
Ознакомиться со списком всех расширений для PostgreSQL в Selectel можно в документации.
Как развернуть PostgreSQL в облаке
Хотя расширения существенно увеличивают функционал СУБД, успешная работа с базой данных во многом зависит от правильного выбора инфраструктуры. Размещение PostgreSQL в облаке предоставляет дополнительные преимущества — масштабируемость, высокую доступность, автоматизацию резервного копирования и управления, а также гибкость настройки ресурсов под нагрузку.
Вы можете развернуть PostgreSQL в облаке Selectel. Для этого достаточно создать кластер в несколько кликов. Наши администраторы позаботятся о настройках, надежности, резервном копировании и поддержке вашей инфраструктуры.
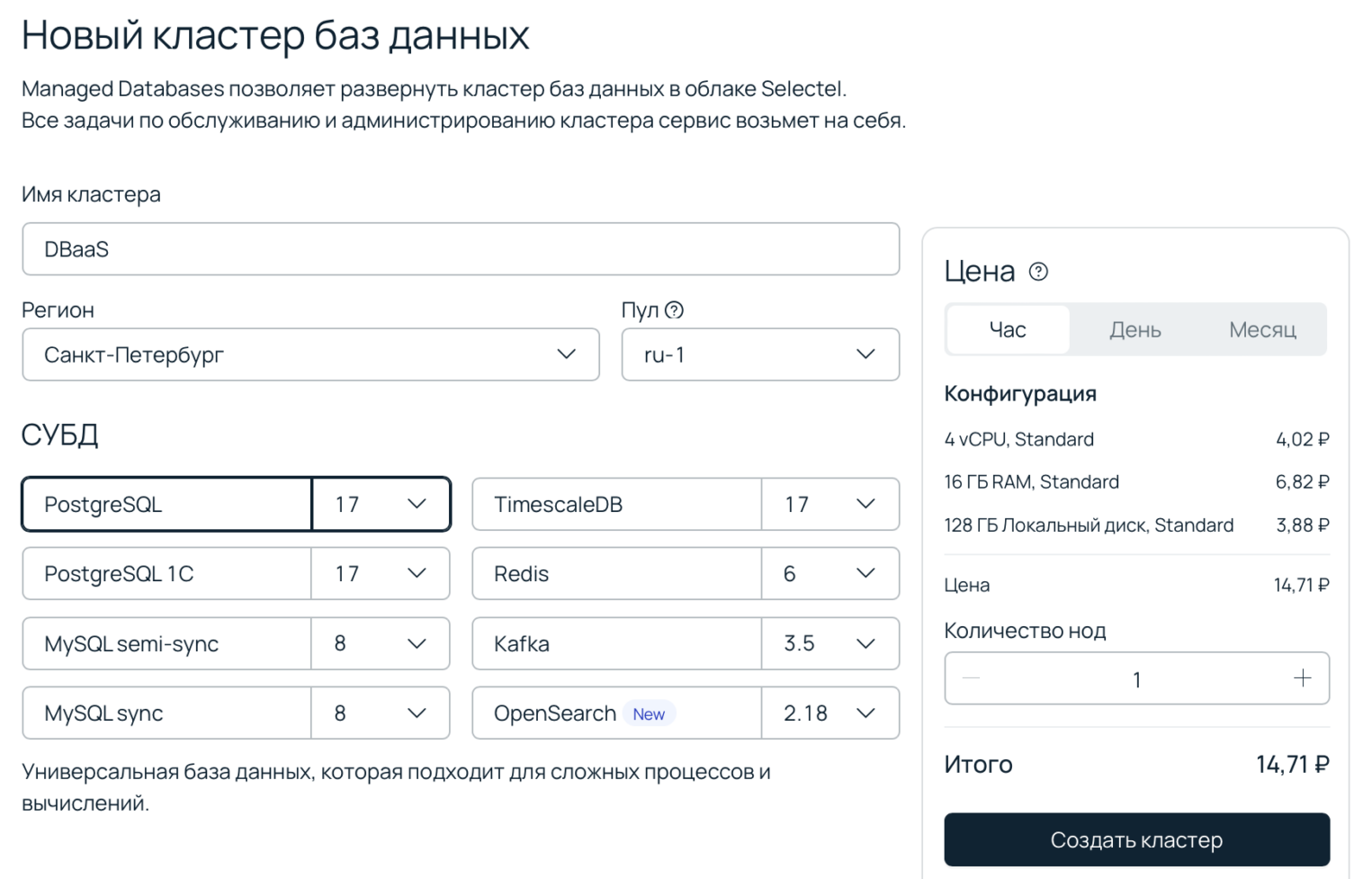
Шаг 1. Создание кластера
В панели управления перейдите в раздел Продукты → Облачные базы данных. Нажмите Создать кластер. Введите имя кластера, выберите пул и версию PostgreSQL. После создания версию будет нельзя изменить.
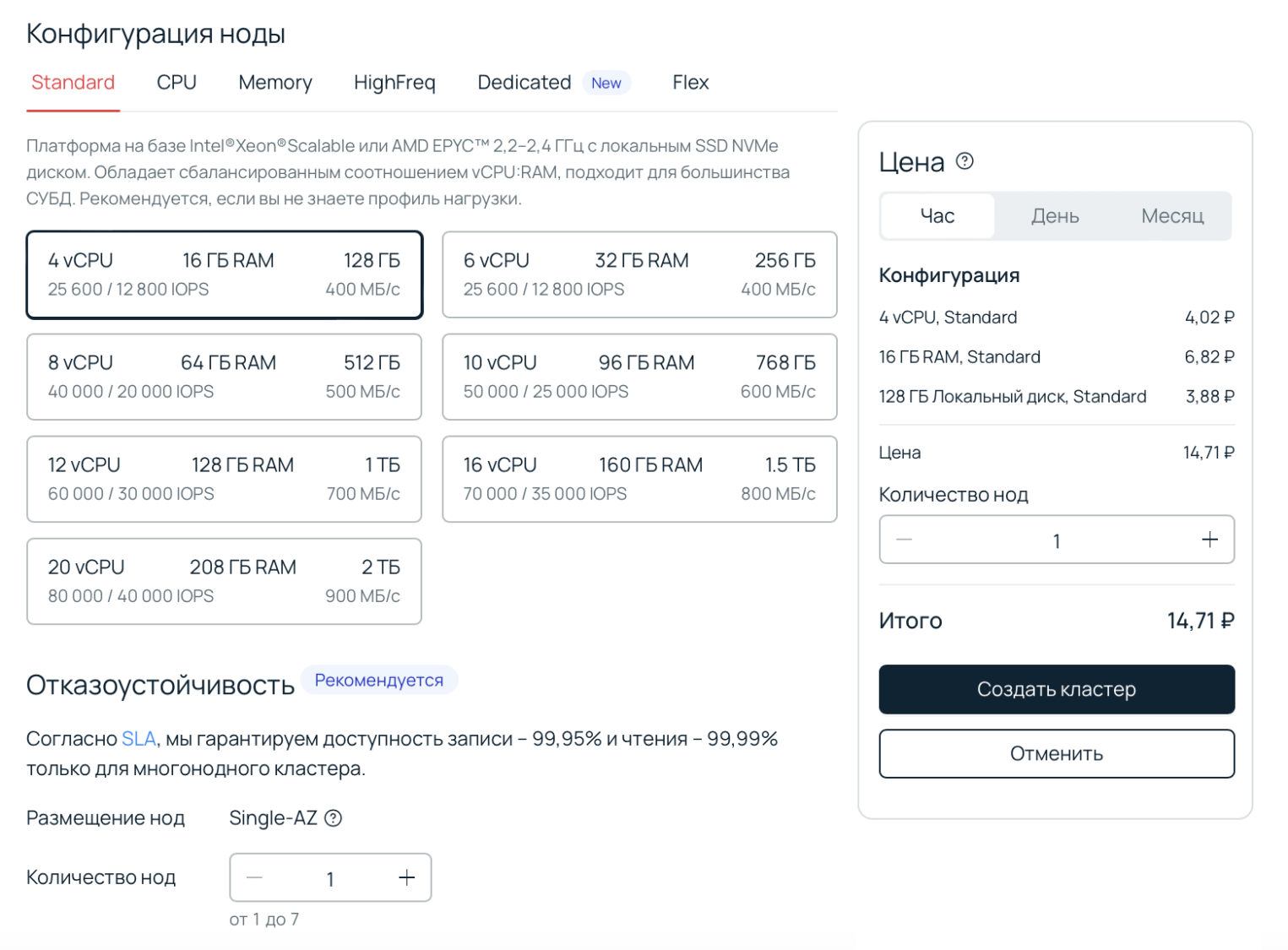
Шаг 2. Настройка кластера
В зависимости от профиля нагрузки выберите конфигурацию нод.
- Фиксированная — конфигурация с разным соотношением виртуальных процессорных ядер, оперативной памяти и локального диска до 34 vCPU, 448 ГБ RAM и 13,9 ТБ диска;
- Произвольная — свободный выбор соотношения ресурсов до 32 vCPU, 256 ГБ RAM и 2 ТБ локального или 10 ТБ сетевого диска.
Опционально: отметьте чекбокс Добавить реплики и укажите количество реплик. Реплики повышают отказоустойчивость кластера.
Шаг 3. Настройка сети
Далее выберите тип подсети, к которой будет подключен кластер — приватную или публичную. В приватных подсетях PostgreSQL можно подключить публичный адрес.
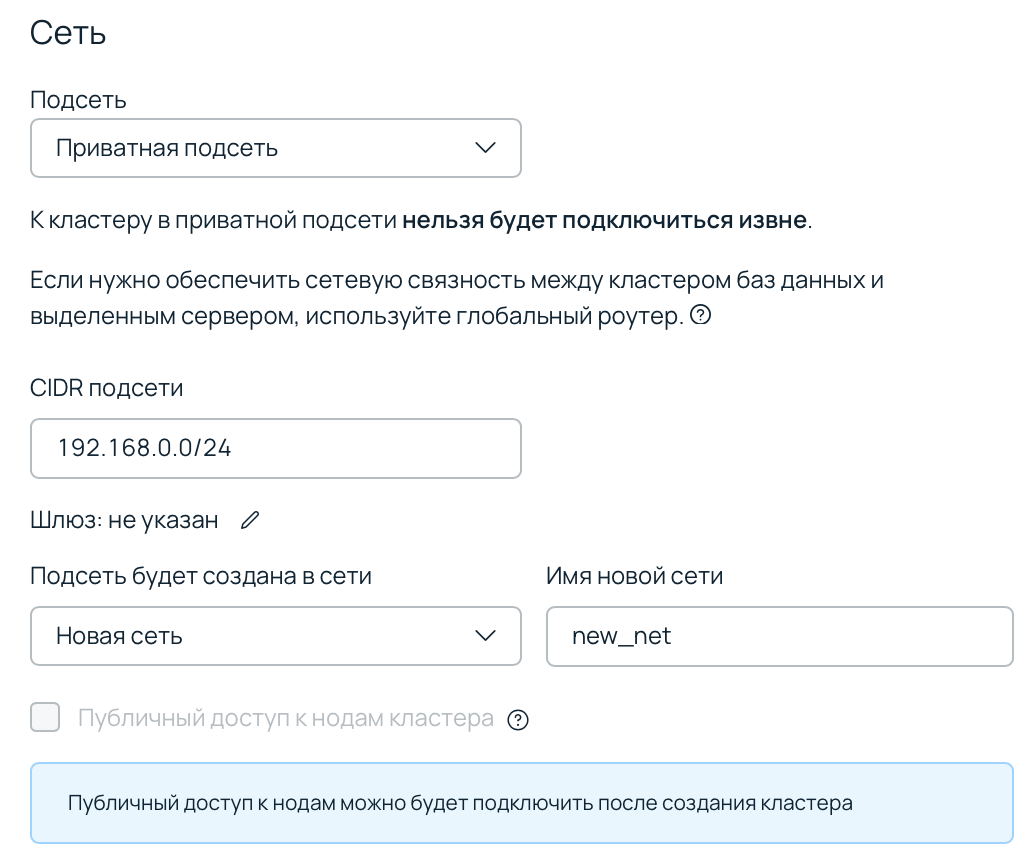
Убедитесь, что количество адресов в подсети не меньше количества нод в кластере. Если после создания кластера вы планируете увеличить количество реплик, то выберите подсеть, в которой есть запас свободных адресов.
После создания кластера сеть нельзя изменить. Вы можете ограничить список адресов, с которых будет разрешен доступ в кластер баз данных.
Шаг 3. Настройка пулера соединений
Выберите режим пулера соединений и размер пула. Транзакции с несколькими операторами запрещены.
- transaction — соединение назначено на клиента на время транзакции.
- session — соединение назначено, пока клиент подключен.
- statement — соединение назначено, пока не завершится запрос.

Опционально: вы можете изменить настройки СУБД. Рекомендуем менять значения настроек только при необходимости — неправильно подобранные значения могут снизить производительность кластера.
Нажмите Создать кластер баз данных. Кластер будет готов к работе, когда перейдет в статус ACTIVE.
Шаг 4. Создание базы данных
Если у вас уже есть PostgreSQL, данные из которой вы хотите перенести в облачные базы данных Selectel, то можете использовать для переноса логическую репликацию или логический дамп. Подробнее в инструкции Миграция баз данных PostgreSQL в облачные базы данных в нашей документации.
В панели управления перейдите в раздел Продукты → Облачные базы данных. Откройте вкладку Активные, затем страницу кластера → вкладка Базы данных. Нажмите Создать базу данных. Укажите имя и выберите пользователя-владельца базы данных.
Далее введите локаль набора символов (LC_CTYPE) — отвечает за классификацию символов и различия в их регистре. Затем введите локаль сортировки (LC_COLLATE) — определяет настройки сравнения строк и символов, а также влияет на сортировку. Нажмите Создать. Подробнее о локалях — в документации PostgreSQL.
Благодаря расширениям PostgreSQL и облачной инфраструктуры Selectel вы получаете оптимальное решение для работы с базами данных, которое легко адаптируется под рост нагрузки и сложности задач.





