

Привет! Я — Алексей Гончаров, основатель платформы Compressa.ai для разработки GenAI-решений на своих серверах. Все чаще мы с коллегами замечаем, что компаниям нравятся возможности ChatGPT, но далеко не каждая готова передавать данные во внешние АРІ и жертвовать своей безопасностью. В результате команды начинают внедрять open source-LLM, развернутые локально. Чтобы осуществить этот процесс, инженерам нужно выполнить две задачи.
- Сделать удобную «песочницу» для экспериментов, чтобы быстро проверять гипотезы для бизнеса.
- Эффективно масштабировать найденные кейсы внутри компании, по возможности снижая затраты на ресурсы.
Интересно, как построить быстрый и экономичный инференс LLM? В тексте поделюсь пошаговым гайдом и покажу полученные результаты. Добро пожаловать под кат!
Арендуйте готовую LLM-инфраструктуру от Compressa и Selectel, в облаке или на выделенных серверах. Ускоряйте цикл разработки и сокращайте издержки на генерацию токенов. Попробуйте бесплатно с двухнедельным тестом.
Проблемы у open source-LLM и их решение
Всего есть три ключевых фактора, из-за которых бизнесу сложно использовать модели на своем сервере: высокая стоимость, нехватка специалистов и низкое качество open source-LLM в прикладных задачах. Ниже расскажу о каждом подробнее.
Высокая стоимость ресурсов
Если команда хочет использовать LLM в продакшене с высокой нагрузкой или большим количеством пользователей, понадобится сервер как минимум с одной мощной GPU, например А100. Вот только подобное оборудование стоит дорого, и не каждый отдел или даже компания могут себе такое позволить.
А если для высокого качества ответов необходимо дообучение под разные бизнес-задачи? Тогда для запуска этого процесса понадобится целый кластер из GPU, а для хостинга каждый версии LLM — отдельный сервер. В результате расходы на вычислительные ресурсы увеличатся.
К примеру, стоимость NVIDIA A100 начинается от 800 тыс рублей за штуку. Также накладываются затраты на администрирование, обслуживание и другие расходы.
Мало экспертов
К сожалению, на рынке не так много специалистов, которые могут прийти в компанию и быстро развернуть локальную LLM. Они должны понимать, какая инфраструктура нужна под конкретные запросы компании, какие методы оптимизации стоит применять и как они влияют на работу модели. А также учитывать контекст использования LLM и приоритетные метрики в процессе настройки. Немногие обладают такими компетенциями.
Низкое качество ответов open source-LLM
Open source-LLM, особенно небольшого размера, часто показывают низкие результаты в специализированных задачах, поэтому использовать их для решения бизнес-проблем не получится. Улучшить результаты работы модели можно, если собрать подходящий датасет и правильно дообучить его под нужную задачу.
Инструменты
Чтобы решить эти проблемы, открытое сообщество активно развивает инструменты для снижения расходов на GPU. Первое — квантование. Преобразует модель в восемь, четыре и меньше бит, чтобы уменьшить объем памяти для запуска LLM. Второе — LoRA-адаптеры. Помогают быстрее и дешевле дообучать модели, а после — запускать их на одной видеокарте. Третье — фреймворки для инференса. Позволяют увеличивать производительность модели.
Как оптимизировать инференс LLM
Шаг 1. Выберите модель
Существует много открытых бенчмарков, которые помогают оценивать производительность. Однако их часто критикуют за переобучение моделей под определенные результаты. Закрытые, наоборот, предлагают более надежные данные, но доступ к ним ограничен.
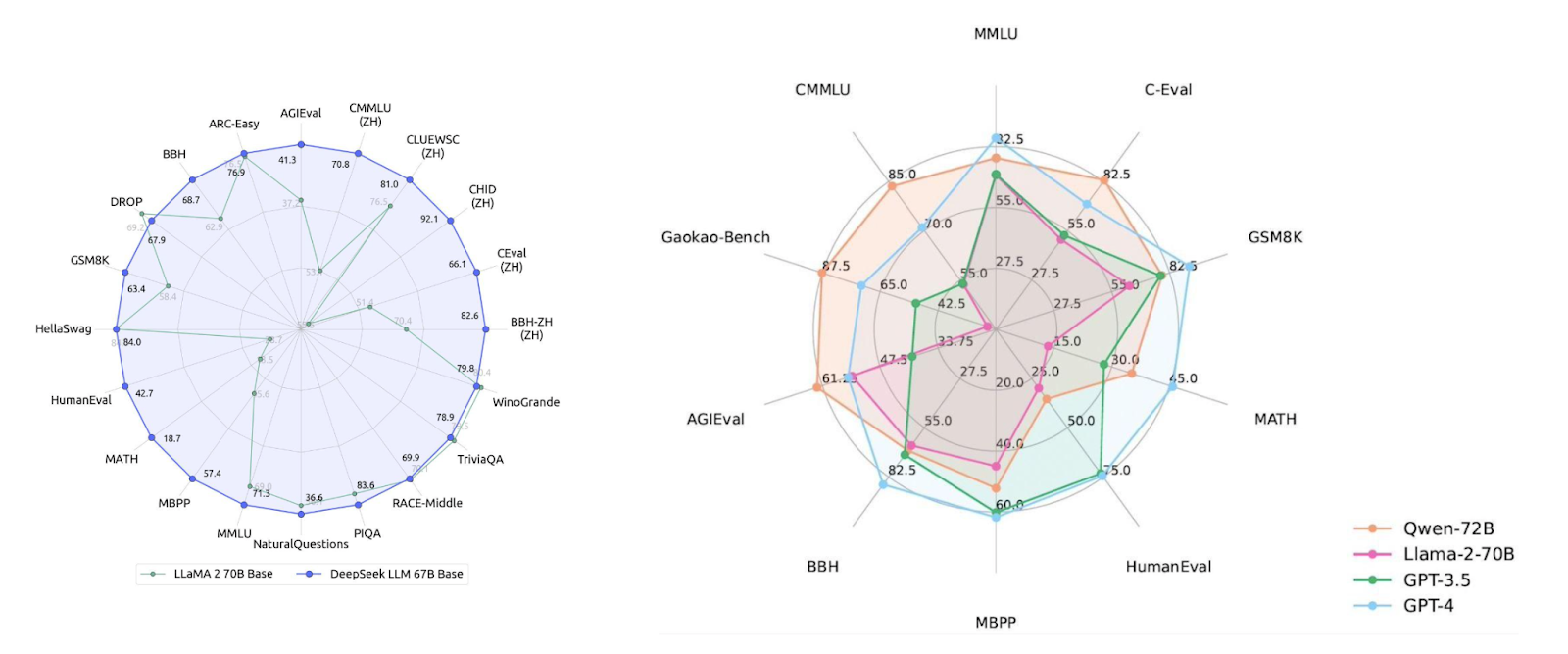
Чтобы подобрать нужное решение, есть два способа выбора модели. С одной стороны, изучаем бенчмарки и то, как модели на них запускались. С другой — даем субъективную оценку качества работы в каждом из сценариев.
При этом результаты на русском языке и бенчмарках, как правило, хуже, поэтому нужно внимательно оценивать ответы на своих задачах. Благо, есть такие open source-проекты, как saiga. По сути, это алгоритм «русификации», который применяется к известным моделям, таким как Mistral или Llama.
Шаг 2. Дообучите модель под нужную задачу
В работе с прикладными задачами Compressa.ai использует не полный fine-tune модели, а подход LoRa-адаптеров. Fine-tune — сложная, хоть и эффективная операция. Компании нужны ресурсы и экспертиза специалистов, чтобы случайно не поломать модель. LoRa-адаптеры не меняют вес изначальной модели, при этом корректируют ее ответы под нужную задачу, например, под вывод на русском языке.
Полностью дообученной модели может понадобиться отдельная видеокарта. Тогда как LoRA-адаптеры позволяют подключить сразу несколько на одной и динамично переключать их в процессе обработки запросов.
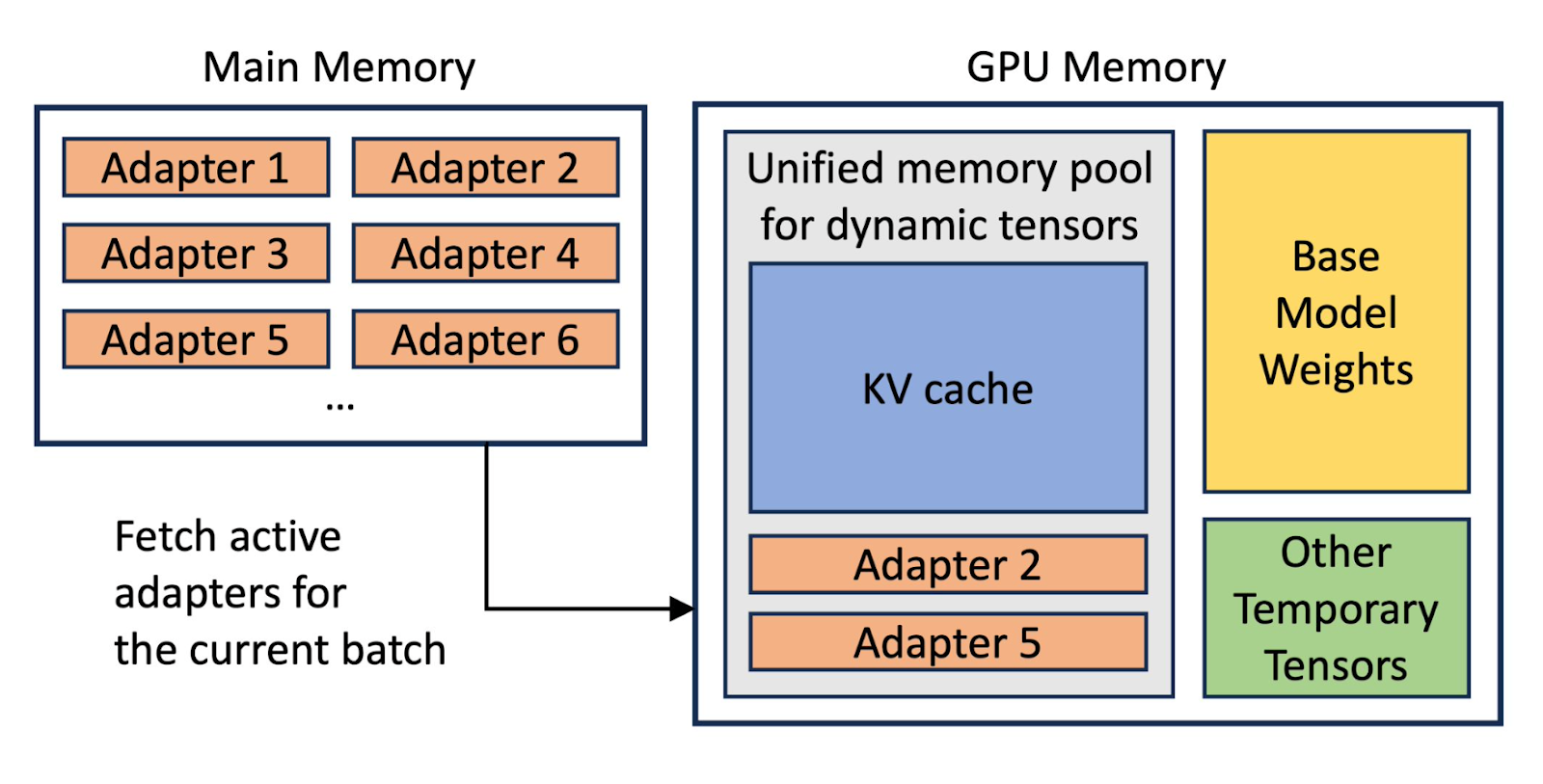
Безусловно, увеличение количества адаптеров на один GPU снижает общую производительность, поэтому нужно найти оптимальный баланс исходя из требуемой нагрузки и доступного вам железа. Возможно, часть адаптеров понадобится перенести на другую видеокарту.
Шаг 3. Используйте квантизацию
Научное сообщество каждый год изобретает новые методы квантизации моделей. Наиболее известные — GPTQ и AWQ, SmoothQuant, OmniQuant, AdaRound, SqueezeLLM и другие. Они позволяют уменьшать размер модели и требования к GPU, а также минимизировать потери в качестве у ответов.
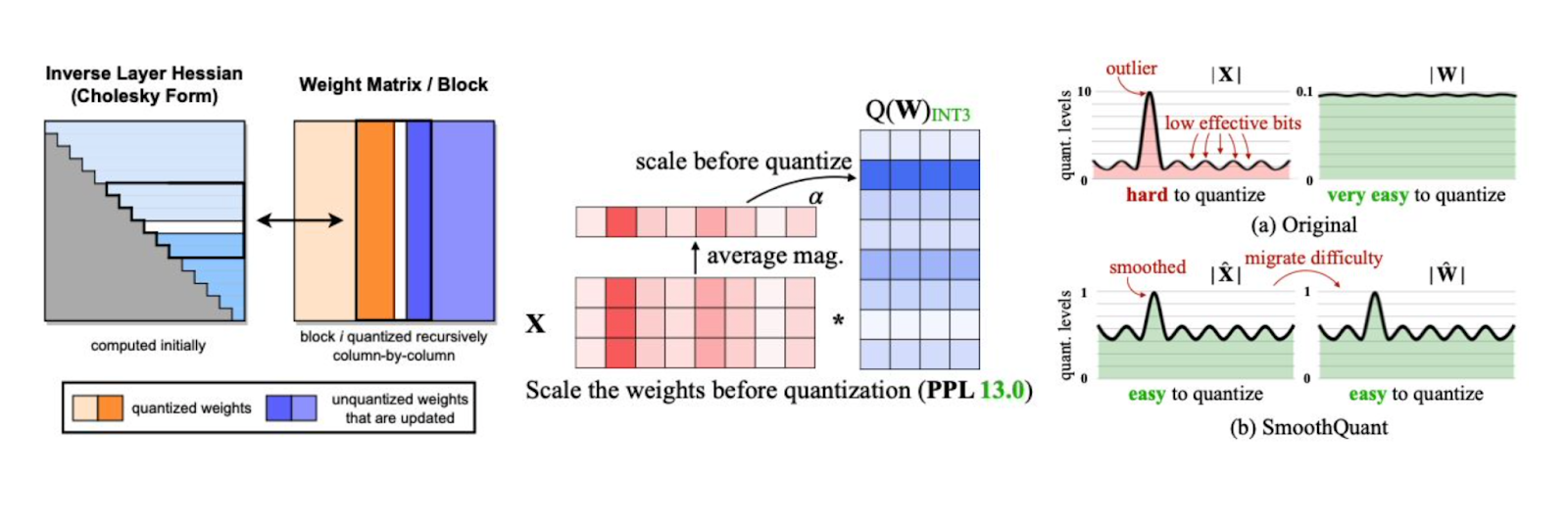
Итоговый эффект квантования отличается у разных методов. Но чтобы получить определенный результат, нужно связать эти методы со сценариями, в которых потом применяют модели.
Например, мы хотим сделать lossless-модель, но для ограниченного набора задач. Для этого используем специальные методы, которые сжимают часть модели, но практически не влияют на ее вес. В результате модель будет также работать в ограниченных сценариях, но сильно хуже — в остальных.
Есть и другой вариант — использовать более универсальные методы. Модель потеряет небольшой процент метрик, но будет более-менее стабильно работать по всем задачам. С точки зрения математики эти методы ортогональны — можно комбинировать между собой и получать новые результаты.
Шаг 4. Используйте фреймворки инференса
Есть разные фреймворки для инференса модели, среди них — Llama.cpp, LMDeploy, vLLM, TensorRT-LLM и другие. Многие из них появились из научных статей: исследователи описывали новые способы оптимизации для определенных операций в процессе генерации токенов. Например, vLLM вырос из paged attention-подхода — открытое комьюнити контрибьютило туда остальные методы ускорения.
Каждый из этих фреймворков поддерживает разный набор оптимизаций и разную скорость добавления новых фич. Выбор оптимального зависит от доступного железа, среднего количество токенов на вход и выход, приоритетных метрик для оптимизации и других особенностей. ML-инженеры Compressa постоянно тестируют разные фреймворки, чтобы понимать их слабые и сильные стороны. Дополнительно контрибьютят в некоторые из них.
Шаг 5. Избегайте инференса на А100
Если вы обрабатываете большой поток запросов каждый день и хотите запускать Llama 70B, вам точно потребуется несколько А100. Однако для некоторых сценариев подойдут сборки и на экономичных GPU. Рассмотрим их подробнее.
Небольшие модели
Обычно специалисты начинают эксперименты с самыми сильными и большими LLM, чтобы посмотреть на максимальное качество ответов, доступных для конкретного бизнес-сценария. Но для некоторых задач подойдут модели с небольшим объемом памяти, например Phi-3. Их можно дообучить и эффективно запустить даже на очень бюджетной GPU.
Распределенный инференс LLM
Если желаемая LLM не помещается в память бюджетной видеокарты, возможно, не стоит сразу переходить на дорогое железо. Вы можете подключить несколько недорогих GPU в общий кластер, чтобы увеличить общий объем доступной памяти. В такой системе есть издержки на передачу информации, поэтому оптимальное решение задачи зависит от требований к задержке и пропускной способности.
Результаты сборок
Допустим, мы уже разработали решение. Каких результатов можно ожидать? Есть два варианта развития событий.
- Если запускать модели на мощных GPU, пропускная способность увеличится в 10-70 раз по сравнению с HuggingFace и PyTorch. Потребуется намного меньше железа для обработки такого же потока запросов, поэтому можно сильно сократить расходы.
- Если пока нет доступа к дорогим видеокартам или масштабированию, можно использовать бюджетные RTX 2080. Пропускная способность, конечно, будет страдать по сравнению с А100, но все еще останется большой.

Кейс: LLM для поисковых задач
Один из наших заказчиков использует LLM для улучшения индексации документов в поисковой системе. Ему необходимо было обрабатывать большой поток документов с регулярными обновлениями. Производительность LLM стала сдерживающим фактором для масштабирования решения.
Чтобы решить проблему, мы оптимизировали пайплайн для индексирования документов на LLM с большим количеством обновлений. После внедрения нужных оптимизаций добились ускорения в 20 раз. Теперь система может проиндексировать 200 тыс страниц вместо десяти за один и тот же период. При этом затраты на ресурсы сократились с четырех A100 до всего одной видеокарты.
Статья написана по мотивам доклада Compressa.ai на конференции MLечный путь.




