

Итак, вы внедрили ИИ в свой сервис и решили ехать в продакшен, где у вас много пользователей. Закономерно возникает вопрос — а на чем запустить инференс, чтобы и пользователи были довольны скоростью работы, и бизнес не разорился.
Привет! На связи Никита, системный архитектор в Selectel. Сегодня я проведу для вас небольшой эксперимент: возьму HGX™ B300 и разверну на нем DeepSeek, Qwen и MiniMax. Зачем? Чтобы протестировать систему на разных задачах, посмотреть получившиеся бенчмарки и сделать выводы о почти топовом серверном GPU от NVIDIA. Заодно кратко вспомним, что получилось, когда мы пытались запустить бюджетный инференс LLM только на CPU. Прошу под кат.
Узкое место инференса — VRAM: ее объем и пропускная способность. Какими быстрыми бы ни были графические процессоры, скорость доступа к видеопамяти все равно жестко ограничивает общую производительность.
NVIDIA активно продвигает новый формат данных NVFP4 для уменьшения размера моделей и ускорения инференса. Ключевой механизм «внимания» (Attention), который отвечает за выделение наиболее важных частей входных данных, постоянно совершенствуется. Все ради экономии вычислительных ресурсов.
Например, для сокращения объема KV-кэша — памяти, хранящей контекст текущего диалога, — все чаще используются алгоритмы разреженного внимания (Sparse Attention) и разностороннего отложенного внимания (MLA, Multi-Head Latent Attention). Параллельно появляются новые методы сжатия контекста. Так, Google недавно опубликовала статью о Turbo Quant — новом виде квантизации KV-кэша, который снижает потребление памяти в 4−8 раз.
Кстати, в прошлой статье про инференс на CPU я затрагивал тему квантизации как способа снизить системные требования при запуске на недорогом железе с небольшой нагрузкой.
Что такое B300
Недавно мы добавили новую конфигурацию выделенных серверов — GL8-B300-HGX-25GE, специально для сверхтребовательных AI-задач.
Сервер HGX™ B300 — флагманская конфигурация NVIDIA для дата-центров. На борту — восемь карт NVIDIA® B300, машина идеально подходит как для обучения, так и для инференса.
Суммарно в системе 2,3 ТБ VRAM, а производительность — 192 петафлопс в режиме FP4. Это крайне существенное уточнение: чип B300 базируется на архитектуре Blackwell. Помимо привычных для инференса BF16 и FP8, она обеспечивает аппаратную поддержку стандарта NVFP4.
Немного о форматах представления чисел с плавающей запятой для машинного обучения и квантования нейросетей.
BF16 — это, можно сказать, стандартный формат для современных моделей. Его 16‑битной точности хватает как для дообучения открытых весов, так и для последующей квантизации до меньших размерностей.
Стандарт FP8 еще компактнее — всего 8 бит. Однако его разрешения уже недостаточно для некоторых частей нейросети. По этой причине в таком виде обычно сохраняют лишь те слои, работа которых не ухудшается при снижении точности. Показательный пример — архитектура DeepSeek. Ее параметры преимущественно переведены в FP8, и только критически важные элементы оставлены в BF16.
NVFP4 предназначен для еще более глубокой квантизации весов по сравнению с FP8. NVIDIA заявляет, что качество инференса при этом снижается незначительно — в пределах 1% относительно FP8, — при этом размер модели сокращается почти вдвое.
На первый взгляд это кажется странным, ведь в NVFP4 — всего 4 бита на параметр. Вроде бы очень мало, но не все так просто. NVFP4 опирается на блочное хранение: наличие масштабных коэффициентов и базовых переменных позволяет прямо в процессе вычислений восстанавливать содержимое блока до точности FP8. То есть веса упаковываются в структуру, содержащую всю необходимую информацию для повышения точности до уровня FP8 или BF16.
Инновационной эту идею назвать нельзя: форматы MXFP и GGUF устроены похожим образом и предлагают сопоставимую точность.
Зачем прилагается столько усилий? Перевод модели в FP8 ускоряет инференс почти вдвое относительно BF16. В свою очередь, NVFP4 дает прирост производительности еще в 1,8 раза по отношению к FP8 — то есть работает почти в 4 раза быстрее базового BF16. Выгода налицо.
Внедряя поддержку NVFP4 на аппаратном уровне, NVIDIA подтверждает: квантизация — это эффективный инструмент. Он позволяет существенно повысить скорость генерации без серьезного ущерба для точности модели.
Хватит теории, перейдем к практике. Давайте посмотрим, на что способен HGXTM B300 в задачах инференса. Запустим на нем несколько массивных моделей и посмотрим на бенчмарки. Заодно сравним FP8 и NVFP4: действительно ли пропускная способность вырастает в два раза при переходе на новый стандарт, как утверждает NVIDIA?
Немного о терминологии
Далее встретятся специфические, но важные для понимания термины. Проясним их значение.
Сам инференс разбивается на две основные стадии.
1. Prefill — на этом этапе обрабатываются входные данные: текстовые запросы, загруженные документы, изображения и тому подобное. Процесс дорогой — узким местом становится количество вычислительных блоков GPU. Скорость же памяти обычно отходит на второй план.
2. Decode — отвечает за генерацию результатов: итогового ответа, файла с кодом или инструкции для AI-агента. Производительность на этом шаге упирается в пропускную способность видеопамяти (а не в объем, как многие ошибочно думают). Чем быстрее VRAM графического ускорителя, тем стремительнее идет процесс.
Механизм внимания (Attention) — ключевой. Именно благодаря ему пришла популярность к большим моделям. Он определяет, как алгоритм рассматривает каждый токен на входе и выходе, соотносит их друг с другом, оценивает значимость для общего смысла. Вокруг оптимизации этого процесса ведется активная работа. Один из новых подходов — разреженное внимание (Sparse Attention), который заметно ускоряет обработку данных на этапе prefill.
На каких моделях испытывали
HGXTM B300 позволяет запустить любую модель из доступных. Вот только не все они, как оказалось, работают на инференс-серверах — особенно совсем новые.
Для исследования я взял инференс‑сервер vLLM — самый стабильный и работоспособный, на мой взгляд, из тех, что подходили для запуска на B300.
Скажем, sglang на многих моделях не показал стабильной работы и падал под нагрузкой, а llama.cpp серьезно отстает в скорости prefill. Брать их для B300 попросту невыгодно.
Итак, что тестировалось и почему.
- DeepSeek R1 — он хорошо поддерживается в vLLM. Хоть модель уже не новая, но зато производительная и служит хорошей базой для сравнения.
- DeepSeek V3.2 — на момент развертывания была самой новой версией, с механизмом разреженного внимания. На больших контекстах должна работать быстрее, чем R1.
- Minimax M2.5 — мой личный выбор. Модель не очень известна, но субъективно очень хорошо показывает себя в кодинге, что удивительно для ее размера — всего 229 млрд параметров!
- Qwen 3.5 397B — новая модель от Alibaba. Для некоторых внутренних задач мы пользуемся ее прошлой версией — 235B, а к этой еще присматриваемся.
Что не попало в тесты.
- Kimi K2 — самая большая модель. С удовольствием добавил бы ее к сравнению, но на момент экспериментов мой HGX еще стоял без штатных дисков, а на тех, что были под рукой, не хватало места. Было критически мало времени и на подключение подходящих накопителей его уже попросту не оставалось. Жаль, конечно.
- GLM 5 — не удалось запустить на vLLM. Точнее, запустить‑то удалось, но подобрать параметры, на которых модель не выдает мусор вместо внятного ответа, не получилось. Надеюсь, в новых версиях vLLM GLM-5 заработает без проблем.
Бенчмарк получен на версии vLLM 0.16.0.
Как подготовить к работе B300
DGX™ — готовое решение от самой NVIDIA, а HGX™ — это модульная платформа для сборки собственных вычислительных узлов. В нашем случае сервер построен на базе HGX™, но программно полностью совместим с DGX™.
Также NVIDIA везде в инструкциях по установке говорит исключительно о DGX™, хотя они в полной мере применимы и для платформ HGX™.
Вместе с DGX B300 NVIDIA предлагает покупать свою закрытую операционную систему — DGX OS. Внутри — обычная Ubuntu 24.04, но с добавлением некоторых компонент для пользователей из крупных компаний. Я не вижу смысла в ее установке, тем более NVIDIA разместила репозитории, из которых ставятся все необходимые для работы компоненты.
Важный момент: мы еще не успели подготовить автоустановку образа на HGX™ B300, поэтому действовать пока приходится вручную. Основные шаги следующие.
- Заказывается конфигурация в панели управления.
- В службе поддержки создается тикет с просьбой подключить флэшку с Ubuntu 24.04 к серверу HGX™ B300.
- После получения доступа к консоли в панели управления, устанавливается ОС и все необходимое ПО.
Процесс проходит без каких‑либо особенностей. Ubuntu безошибочно определяет диски и сетевые интерфейсы, для которых понадобится только вручную прописать настройки, так как автоматическая выдача через cloud init пока не работает.
Установив ОС, переходим к ПО — драйверам, библиотекам и подобным компонентам.
Настройка после установки ОС
Перво‑наперво обязательно обновляем систему и перезагружаемся. Если свежее ядро подтянется в процессе установки пакетов, могут возникнуть проблемы.
sudo apt update
sudo apt upgrade
sudo reboot
Подключаем репозитории NVIDIA, содержащие пакеты для HGX. При их установке выполняется множество скриптов автоматизации — очень удобно.
curl https://repo.download.nvidia.com/baseos/ubuntu/noble/x86_64/HGX-repo-files.tgz | sudo tar xzf - -C /
sudo apt update
Устанавливаем основные пакеты nvidia‑*.
sudo apt install -y nvidia-system-core nvidia-system-utils nvidia-system-extra linux-tools-generic nvidia-peermem-loader
Теперь можно поставить драйверы и сопутствующие пакеты.
sudo apt install -y nvidia-driver-590-open libnvidia-nscq nvidia-modprobe nvidia-fabricmanager datacenter-gpu-manager-4-cuda13 nv-persistence-mode nvlsm libnvsdm
Пакет nvidia-fabric-manager почему‑то не настроен до конца. Некоторые действия придется сделать вручную, иначе не заработает NVLink и CUDA в целом.
sudo apt install -y infiniband-diags
sudo modprobe ib_umad
sudo systemctl start nvidia-fabricmanager
Проверяем состояние менеджера — он должен уже запуститься и быть активен:
sudo systemctl status nvidia-fabricmanager
В ответ должны появиться подобные сообщения:
Mar 30 15:33:06 b300 nv-fabricmanager[53440]: NodeId 0 partition id 57082 is activated.
Mar 30 15:33:06 b300 nv-fabricmanager[53440]: Successfully configured all the available GPUs and NVSwitches to route NVLink traffic. NVLink Peer-to-Peer support will be enabled once the GPUs are successfully registered with the NVLink fabric.Если они не наблюдаются, значит fabricmanager лежит из‑за того, что мы что‑то упустили на предыдущих шагах.
Идем дальше. Теперь можно проверить топологию сети и состояние NVLink.
nvidia-smi topo -m
nvidia-smi topo -p2p r
nvidia-smi nvlink -s
Итак, линки есть и топология настроена. Добавляем загруженный ранее ib_umad в ядро, иначе после перезагрузки fabricmanager опять придется запускать вручную.
sudo update-initramfs -u
На этом этапе стоит перезагрузиться. Убедимся, что все модули стартуют и не возникает никаких ошибок.
nvidia-smi
sudo systemctl status nvidia-fabricmanager
После этих несложных шагов HGX готов к работе. Осталось только определиться, как запускать его. Для vLLM все зависимости уже подтянуты. Если предполагается использование контейнера, то потребуется еще пара команд для настройки среды.
sudo nvidia-ctk runtime configure
sudo systemctl restart docker
Можно подтягивать контейнер vLLM (во время написания статьи появилась уже версия 0.20.0). Брать надо обязательно с поддержкой CUDA 13.0, иначе не получится использовать NVFP4.
docker pull vllm/vllm-openai:v0.16.0-cu130
С настройками покончено, переходим к испытаниям.
Бенчмарки
Модели запускались в режиме онлайн-инференса. Бенчмарки были получены путем вызовов эндпоинтов OpenAI API через vllm bench — так ближе к реальной нагрузке.
Все модели я испытывал на двух одинаковых сценариях.
- Входной текст — 1 000, 2 000, 4 000, 8 000, 16 000 токенов. Проверялась производительность prefill при очень маленьком decode.
- Выходной текст — 1 000, 2 000, 4 000 токенов. Измерялась производительность decode — теперь уже при минимальном prefill.
Во время тестирования варьировалось количество одновременно поступающих запросов, тем самым имитировалась нагрузка для разного числа одновременно работающих условных пользователей. Профили одновременной нагрузки (Concurrency) — 4, 16, 64, 256.
Для prefill увидим на графиках сколько токенов в секунду выдает весь HGX и как долго каждый пользователь ждет до появления первого токена ответа (TTFT, Time to First Token). Пропускная способность позволяет сравнить производительность моделей между собой. Время до первого токена отражает субъективный комфорт условного пользователя при заданном профиле нагрузки.
Для decode графики показывают как общую производительность при выдаче (весь HGX), так и приходящуюся на одного пользователя. Единицы измерения — также количество токенов в секунду (или TPS, Tokens per Second). Измеренные показатели, как и в случае prefill, пригодятся для сравнения с другими системами, в том числе по комфортной отзывчивости для пользователя.
Начнем с заслуженного пенсионера ИИ‑индустрии. Его, наверное, скоро отправят на покой, но пока он еще ого‑го как пашет.
Deepseek R1 в NVFP4
Модель запущена «просто и без изысков» — как и предлагается в рецептах для vLLM и блогах vllm.ai.
В HGX™ — восемь штук B300. Модель квантизации — NVFP4. Значит, экземпляр модели умещается в две карты, всего на одном сервере можно разместить четыре экземпляра.
При наличии NVLink/NVSwitch предпочтительнее тензорный параллелизм, а не пайплайновый, поэтому запускаем с такими параметрами:
vllm serve -tp 2 -dp 4
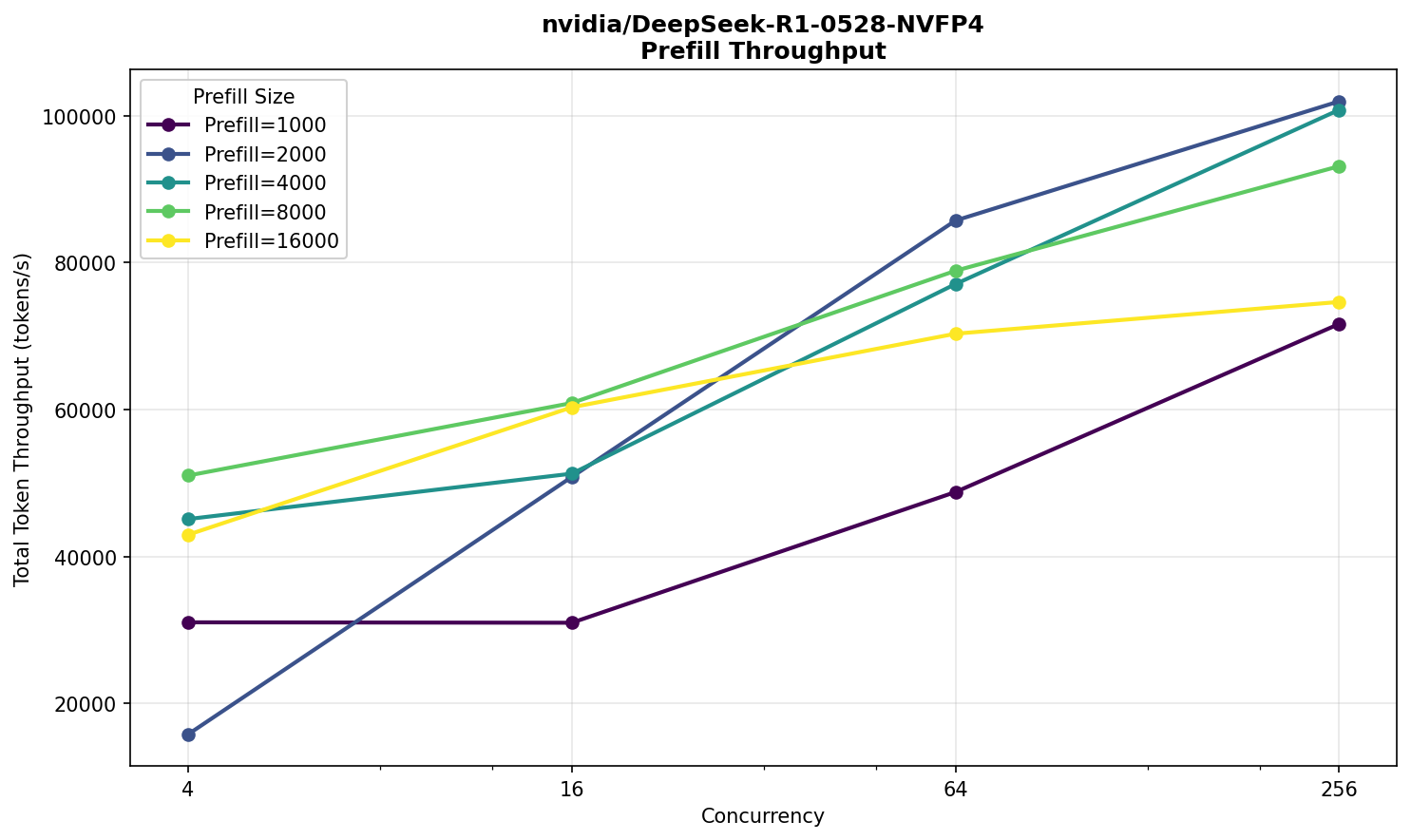
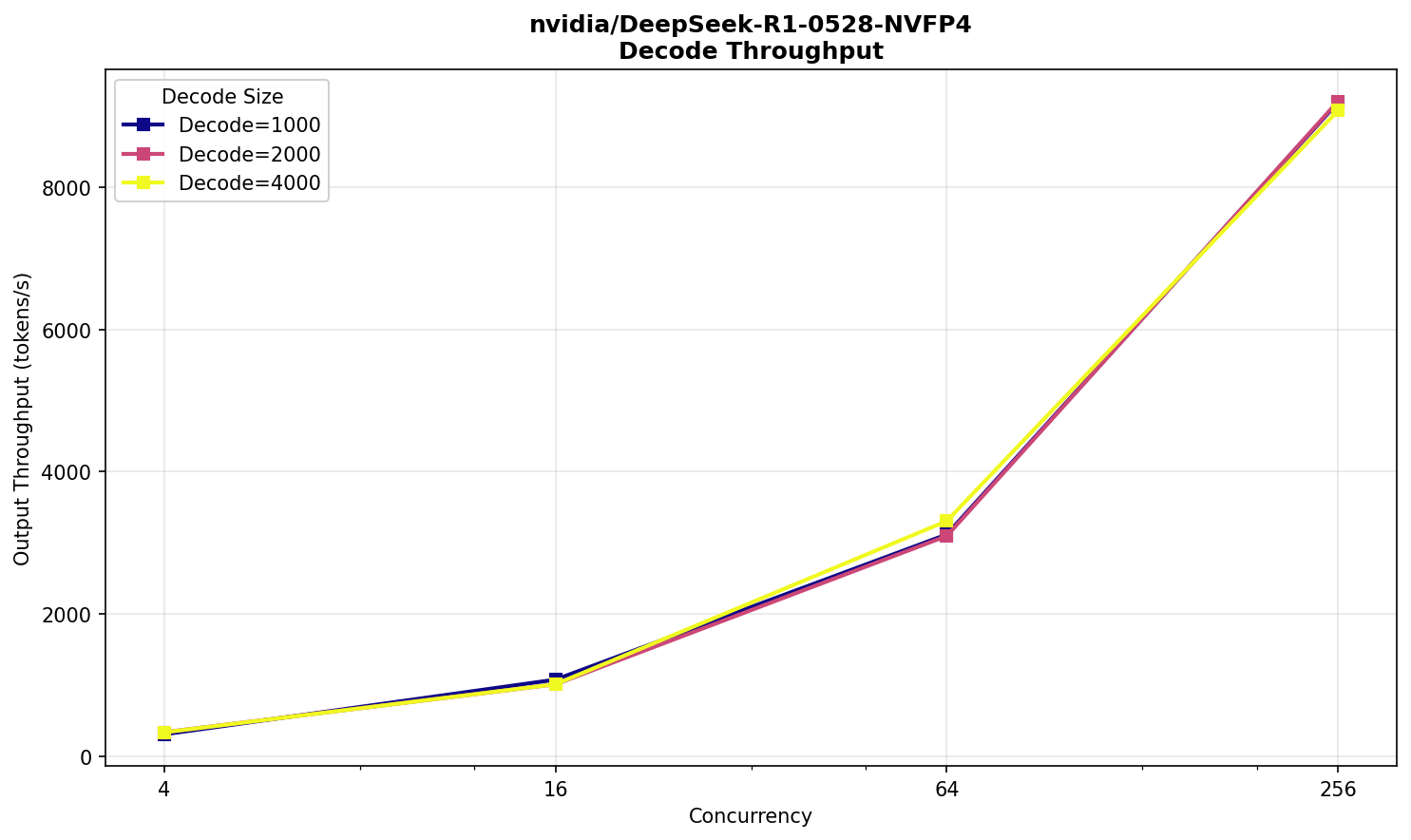
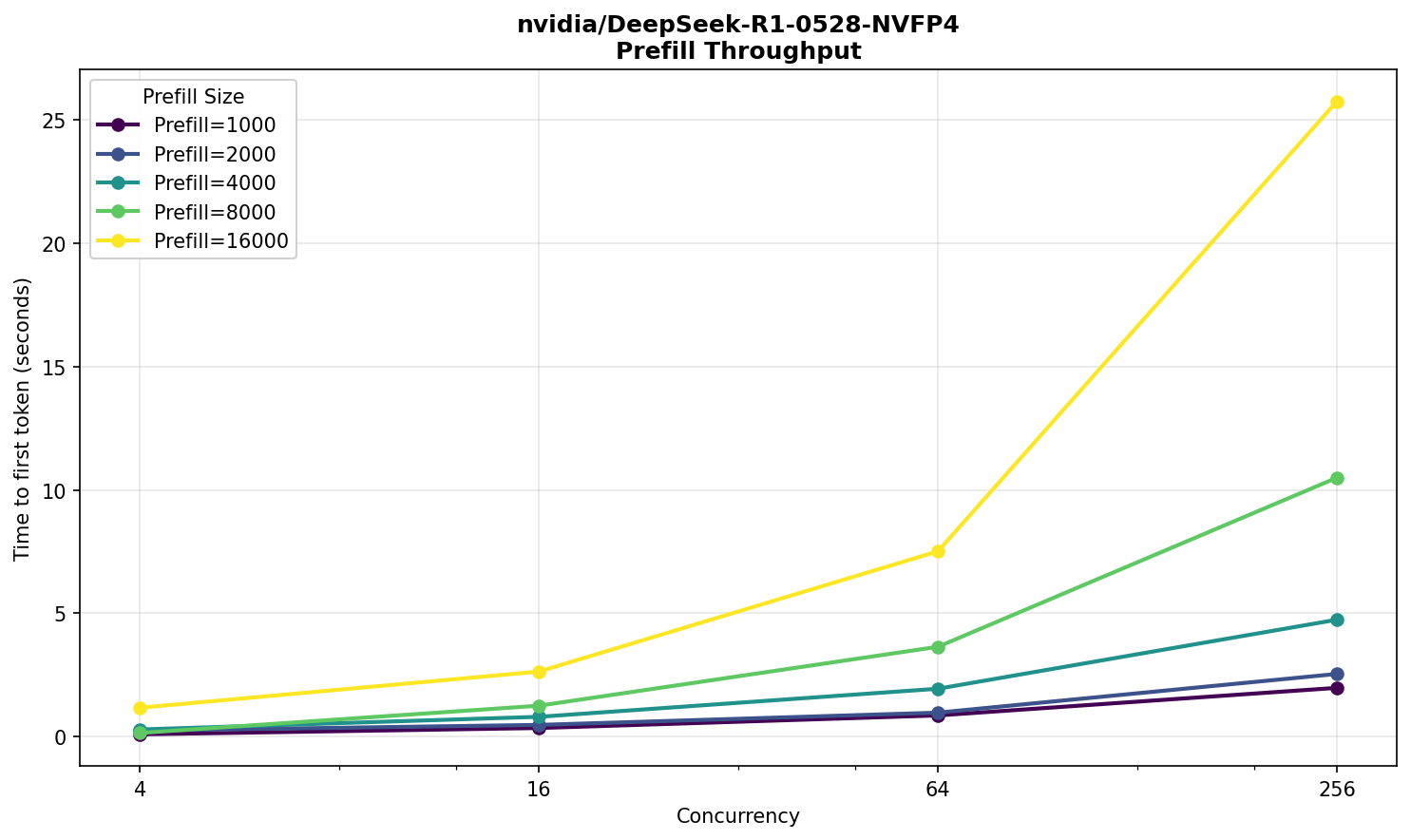
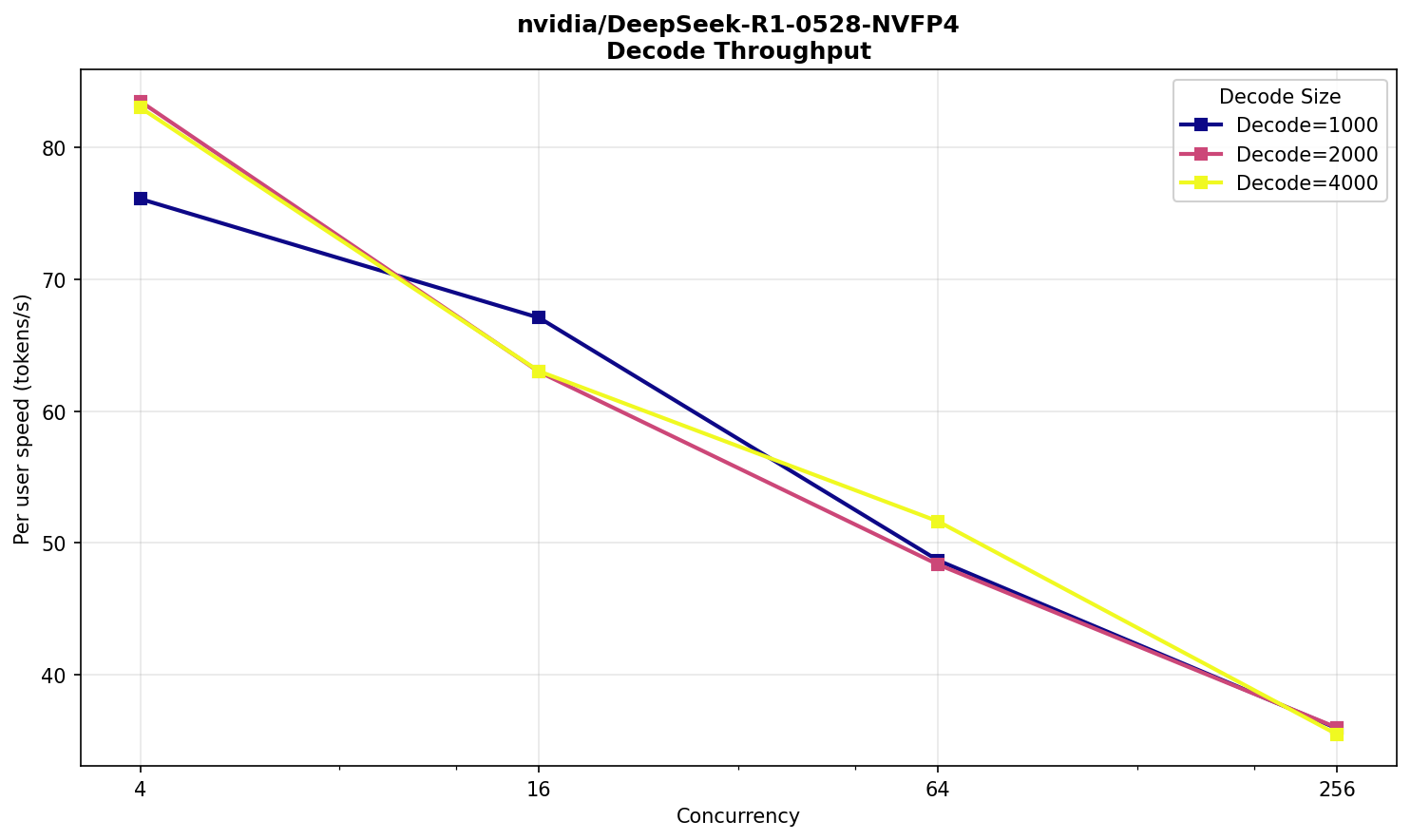
В самом нагруженном сценарии модель начинает выдавать ответ через полминуты со вполне комфортной скоростью 30 TPS — вполне приемлемо для большого текста на входе и 256‑ти одновременно выполняющихся запросов. Похожую работоспособность можно наблюдать на публичном Deepseek R1.
Заметно довольно быстрое снижение производительности prefill по мере увеличения размера входного текста, что для R1 вполне нормально.
Запомним полученные характеристики и сравним их с результатами следующего испытуемого — Deepseek V3.2.
Deepseek V3.2 в NVFP4
Архитектура этой модели несколько отличается от R1. Так как в V3.2 применяется разреженное внимание, то теоретически мы должны увидеть лучшую способность справляться с большими входными текстами.
После написания статьи вышла новая V4, но сервер к этому моменту уже пришлось вернуть.
Запускается также как и R1, на tp 2 и dp 4:
vllm serve -tp 2 -dp 4
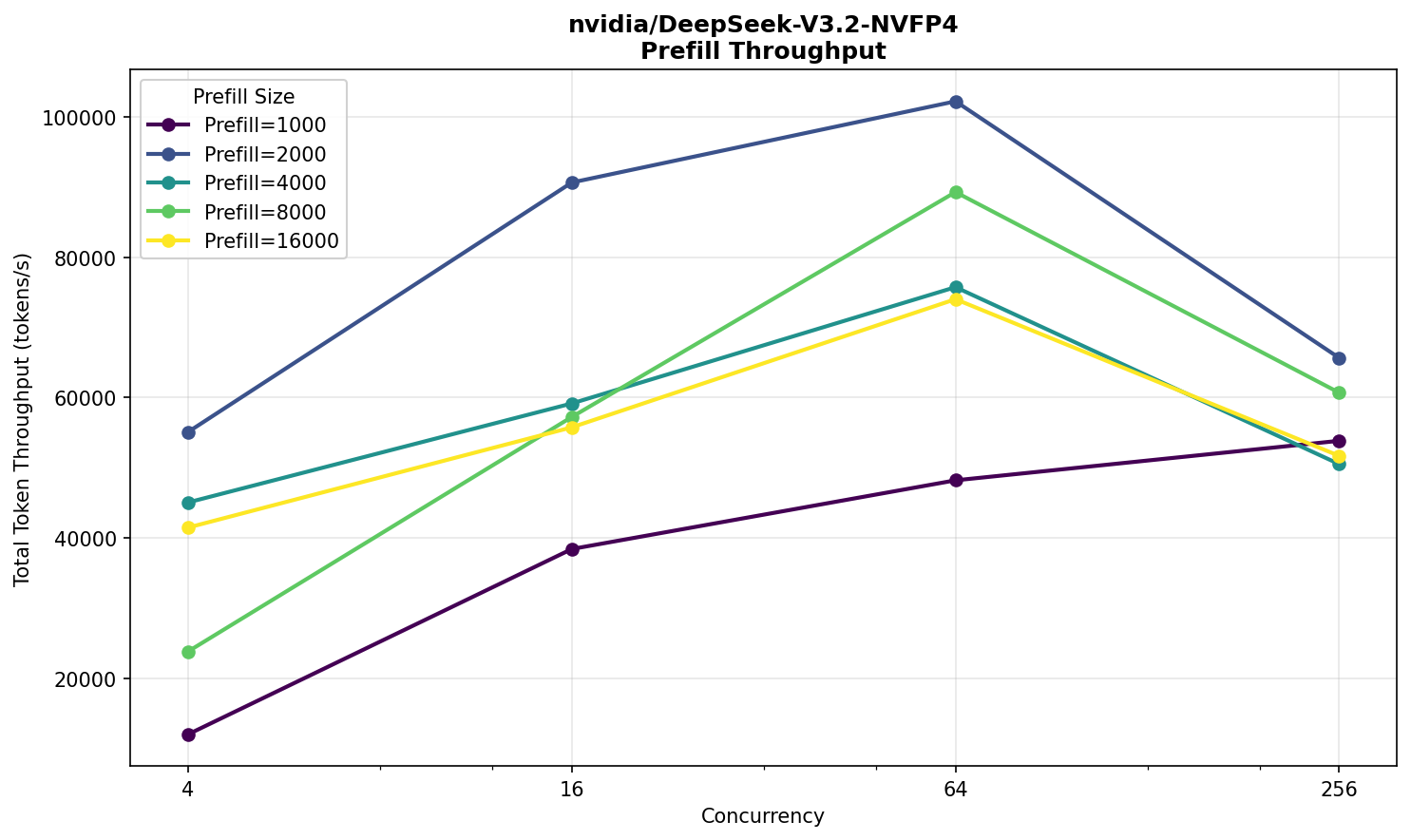
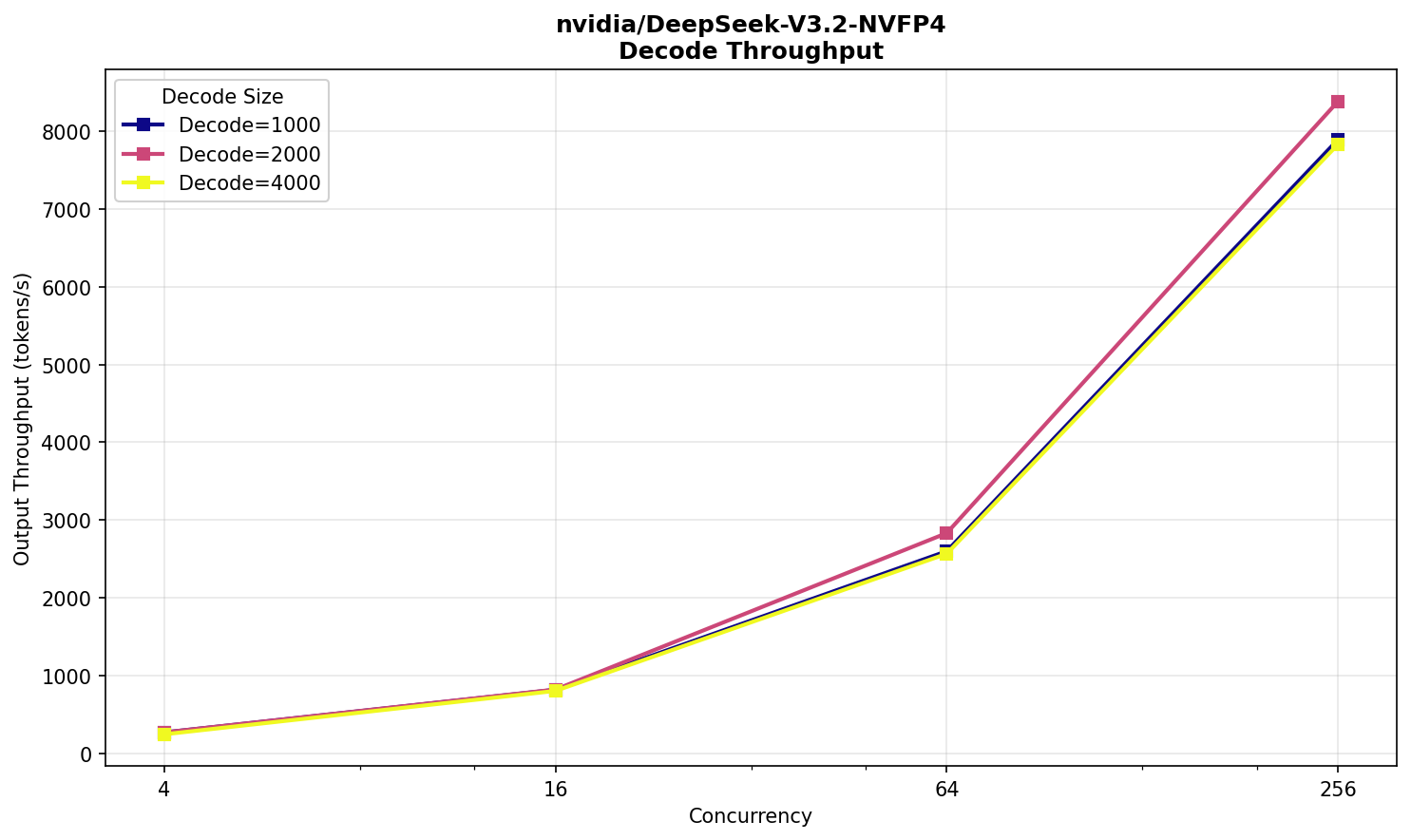
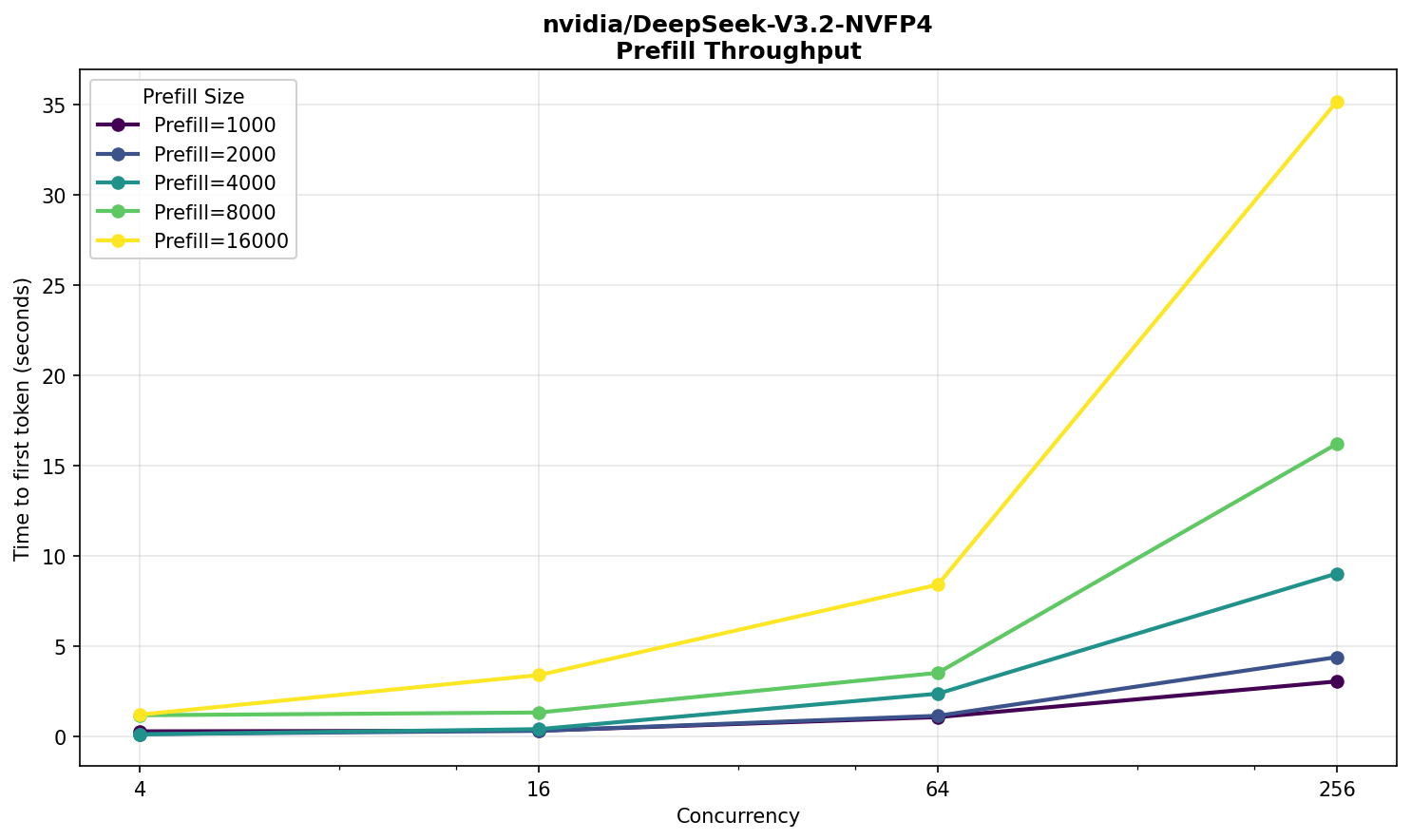
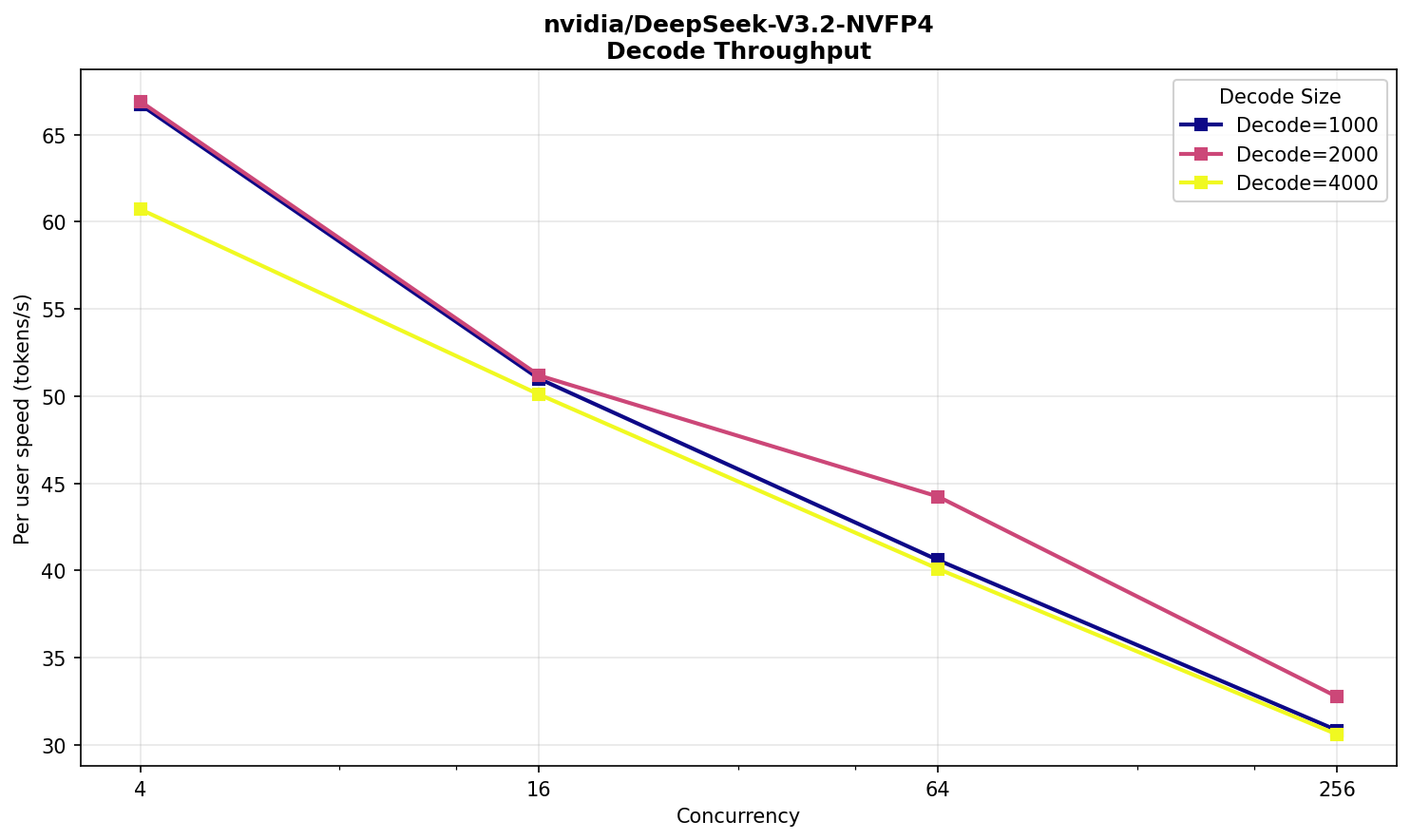
Значения все еще в комфортной для пользователей зоне. При 256‑ти одновременных запросах, ответы начинают выдаваться через 35 секунд со скоростью, сопоставимой с R1.
Примечательно, что не наблюдается заметного прироста производительности на входных текстах, вплоть до 16 000, и работает V3.2 NVFP4 даже немного медленнее R1. Возможно, преимущество V3.2 будет заметно на значительно бо́льших размерах входных текстов.
Общее же небольшое отставание от R1 скорее всего объясняется неоптимальной реализацией — все‑таки поддержку V3.2 добавили недавно, а R1 уже больше года в кодовой базе vLLM. Сравнить же напрямую со свежайшей V4 не получится: модели отличаются и по размеру, и по архитектуре.
Deepseek V3.2 FP8
Возьмем тот же V3.2, но оригинальный — от команды DeepSeek. Он публикуется в формате FP8, и будет интересно сравнить с FP4.
Такую модель на две карты уже не поместишь — нужно четыре. Соответственно, HGX™ возьмет на борт два экземпляра, а конфигурация запуска теперь выглядит так:
vllm serve -tp 4 -dp 2
Предполагал, что эффект на производительность будет не в пользу FP8‑варианта. Что ж, посмотрим что вышло.
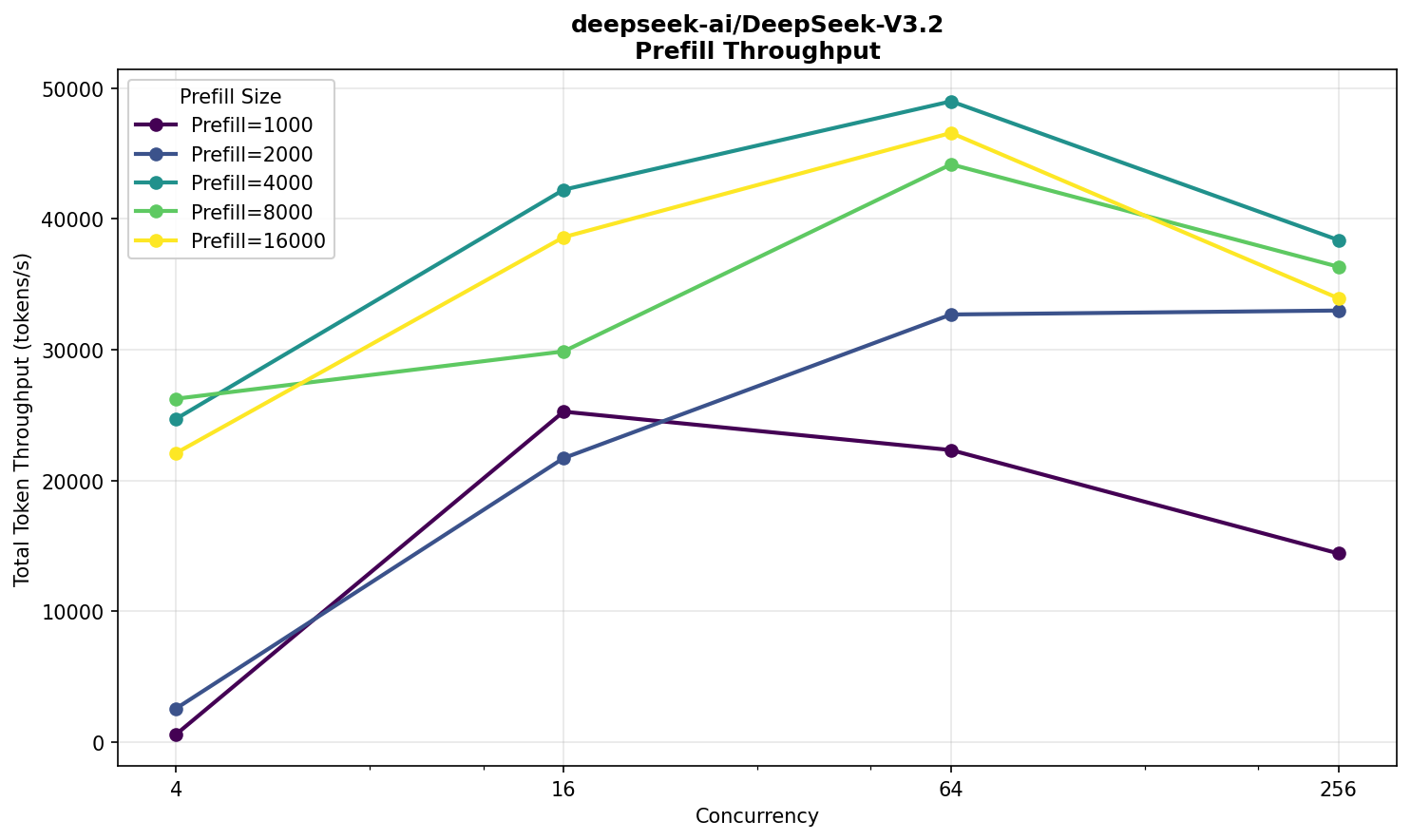
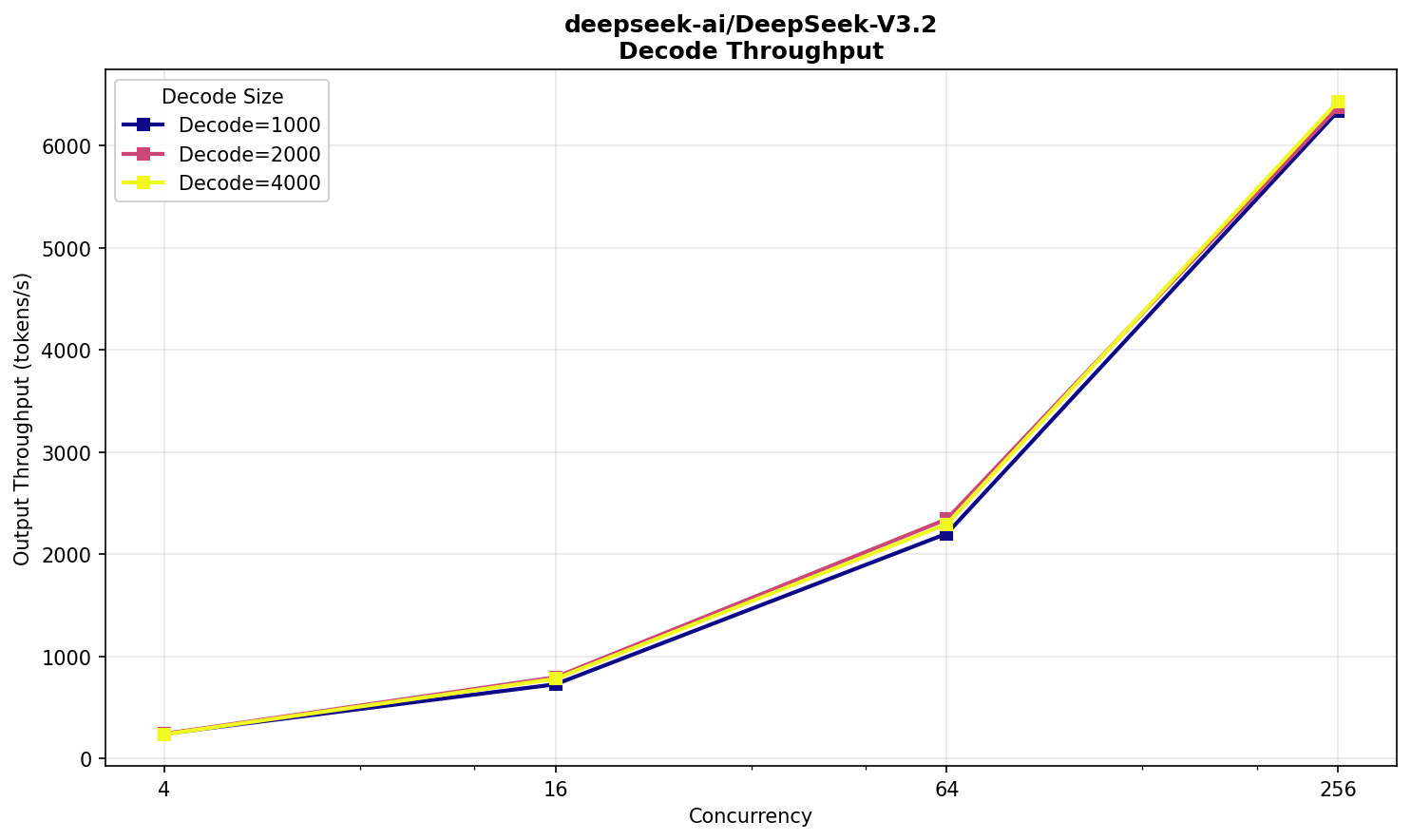
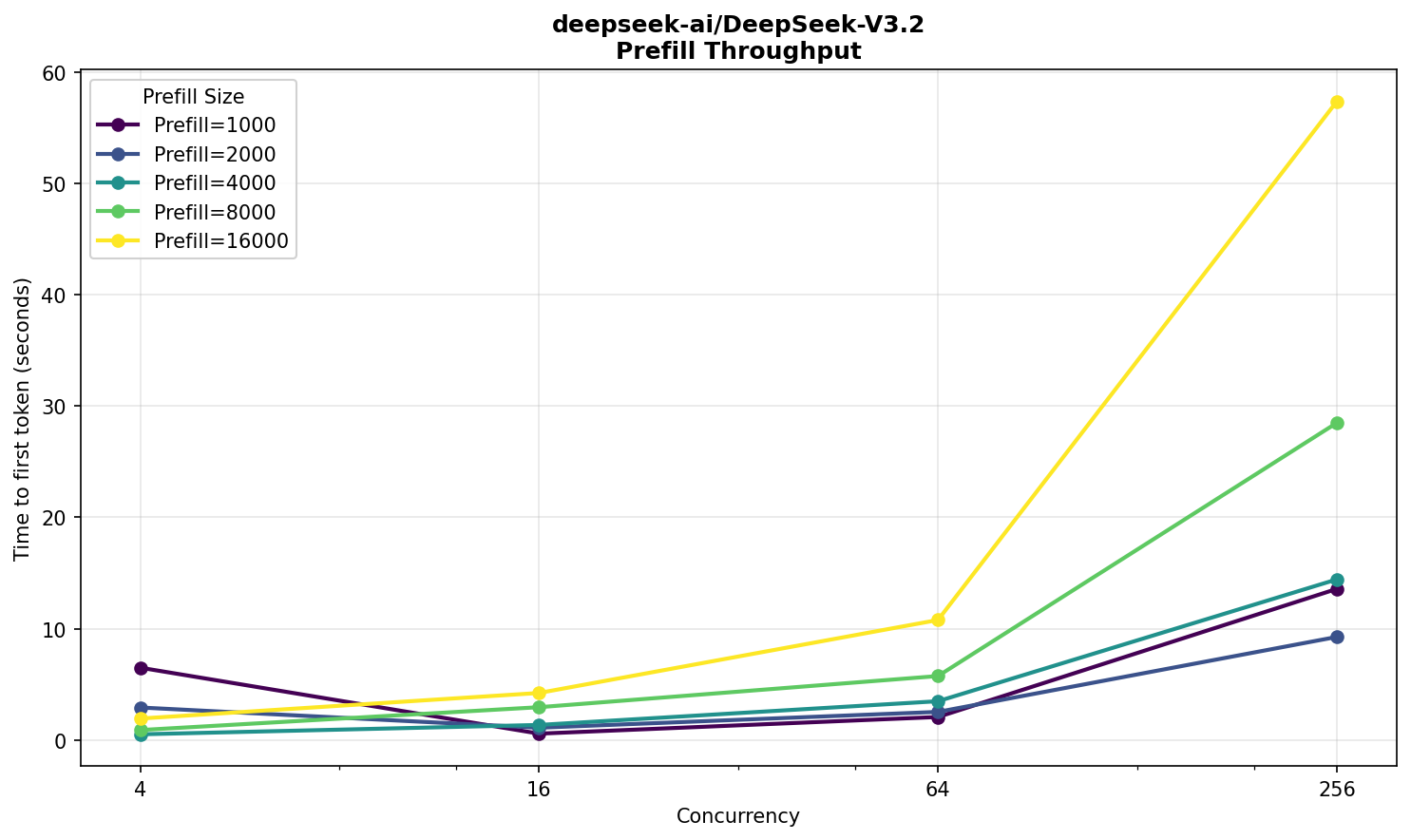
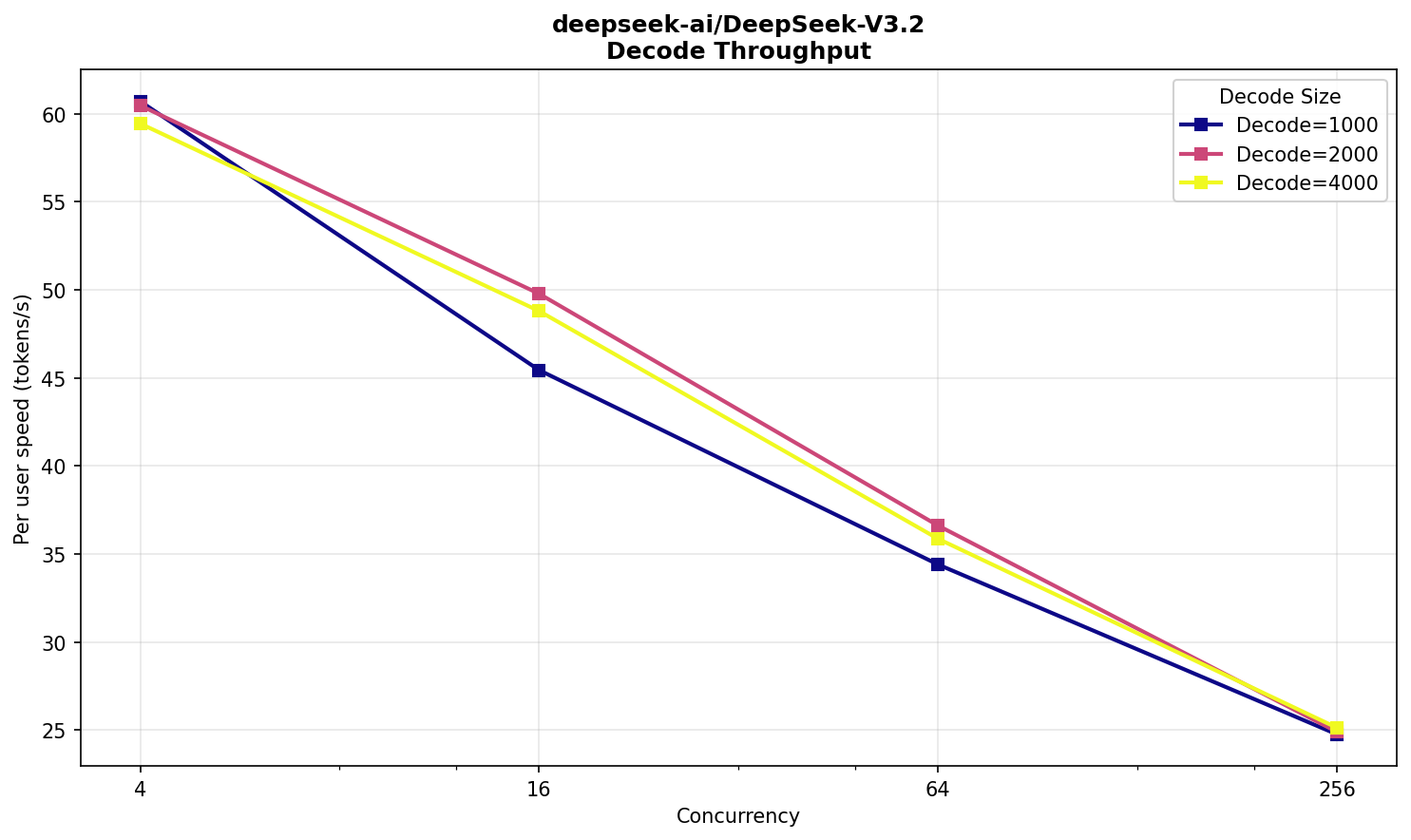
Отзывчивость все еще в комфортной зоне, хотя ожидание для 16 000 токенов — уже минута, что довольно долго. Скорость — 25 TPS.
По prefill разница с NVFP4 двукратная, что ожидаемо — модель ровно в два раза меньше. По decode тоже есть отличие, но уже не в два раза.
Посмотрим на полученные характеристики трех моделей вместе, в сравнительной диаграмме — так будет нагляднее.
Сравнение всех DeepSeek
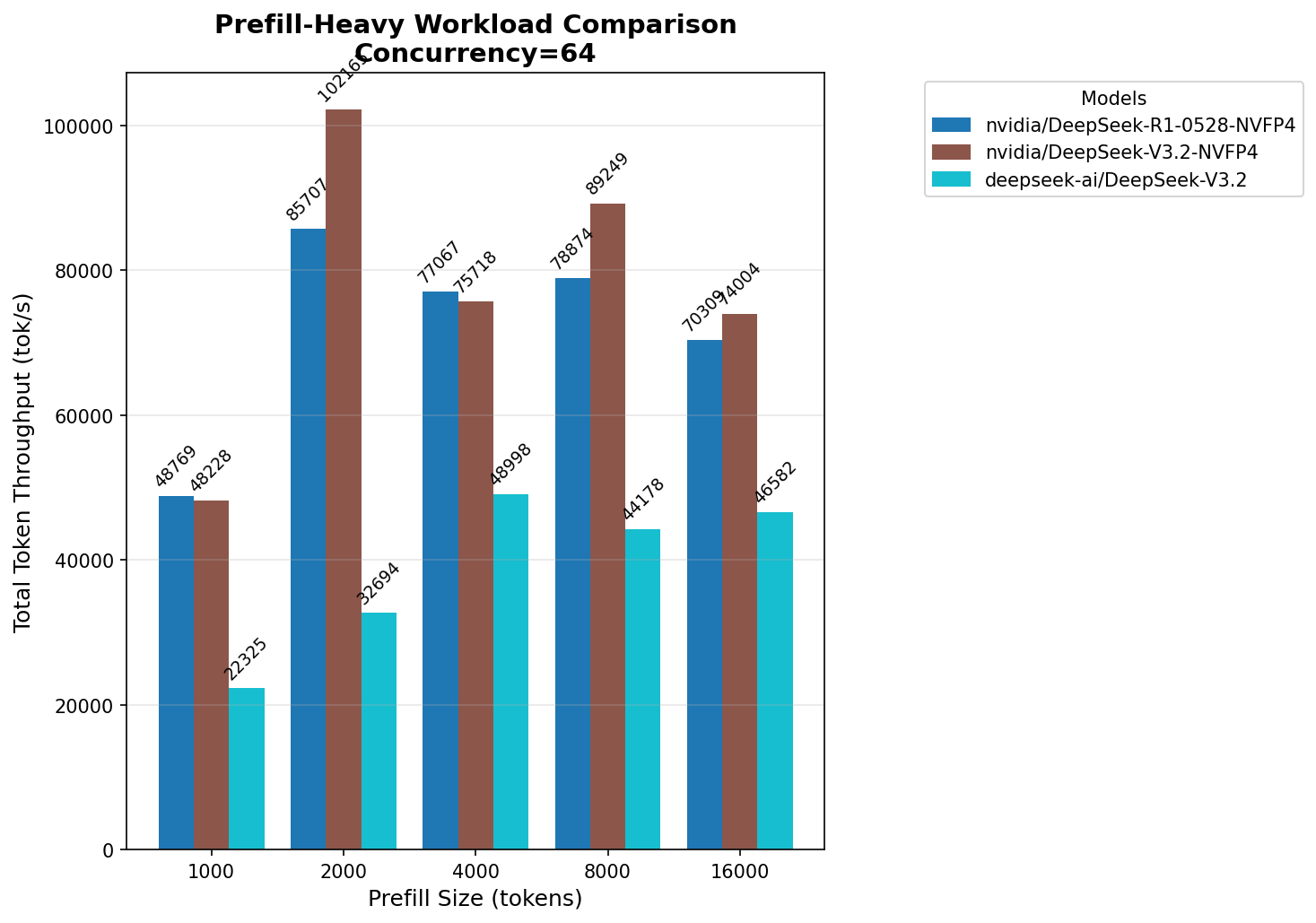
На prefill разница между R1 и V3.2 незначительна. Зато между V3.2 NVFP4 и FP8 очень существенная, на некоторых размерностях prefill — в два‑три раза.
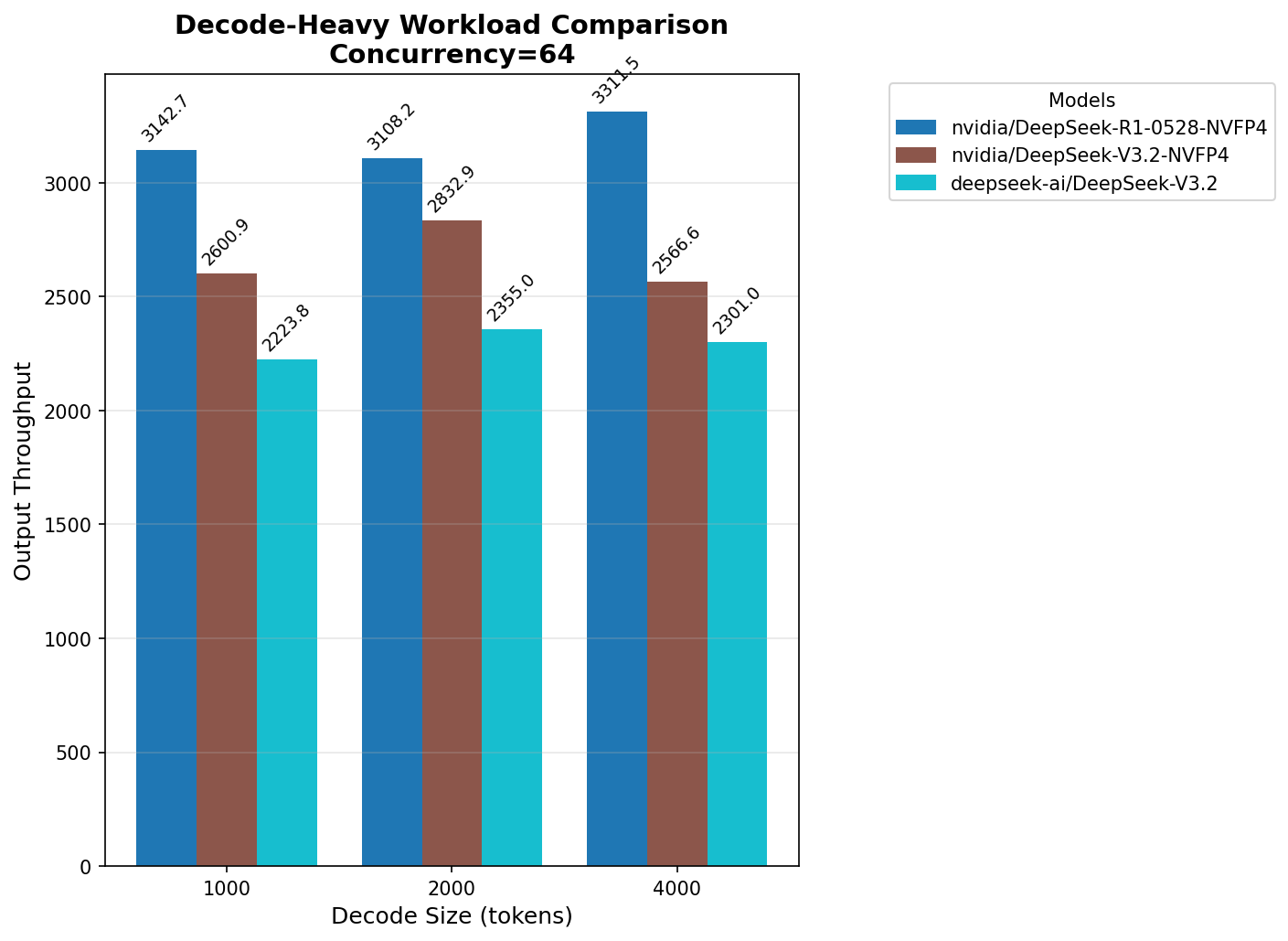
На decode разница есть, но уже не кратная. Во что-то сервер упирается, но во что именно — не ясно. Пока я искал ответ, пришла пора отдавать HGX (очередь из желающих образовалась очень быстро). Очень интересно узнать причину, буду рад прочитать предположения в комментариях.
Переходим к другим моделям.
Minimax M2.5
В этой модели всего 229 млрд параметров, поэтому она прекрасно умещается в один B300. Соответственно, на целом HGX™ — восемь экземпляров, по одному на карту, что исключает любые возможные проблемы производительности, связанные с распределением вычислений по модулям.
Каких-то сюрпризов на графиках нет. Есть подозрительный выброс TTFT на concurrency 16. Возможно, он вызван недостаточным прогревом инференс‑сервера.
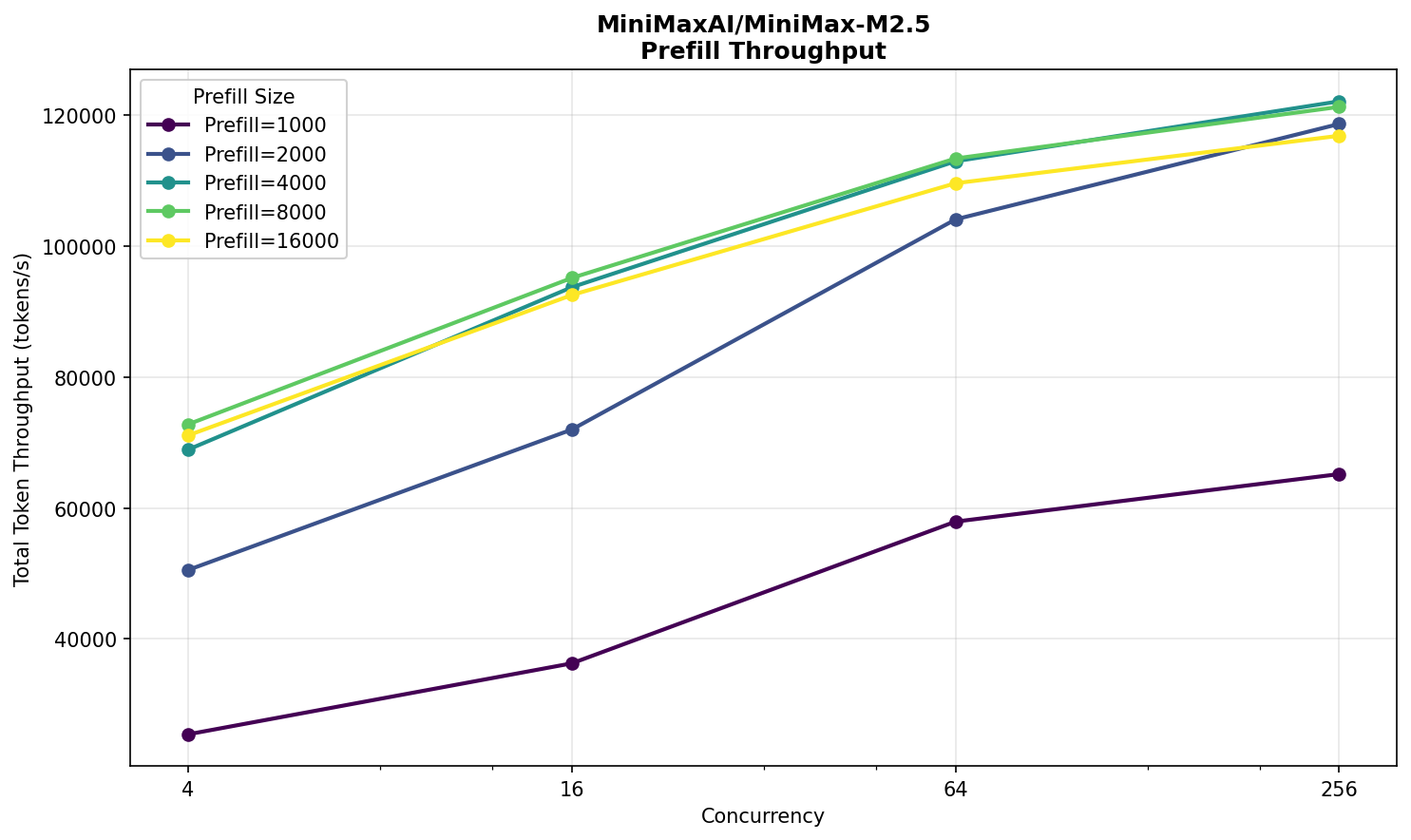
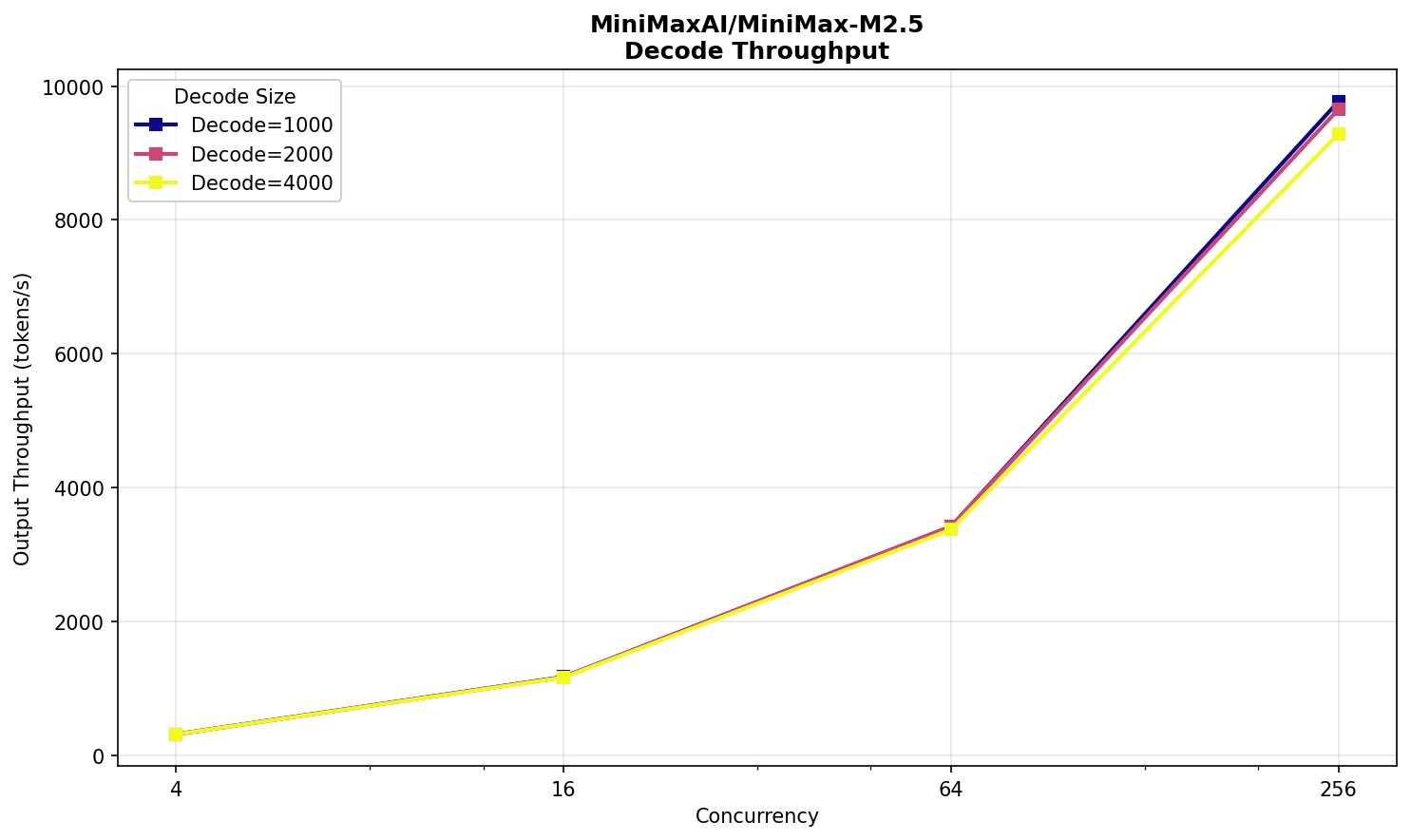
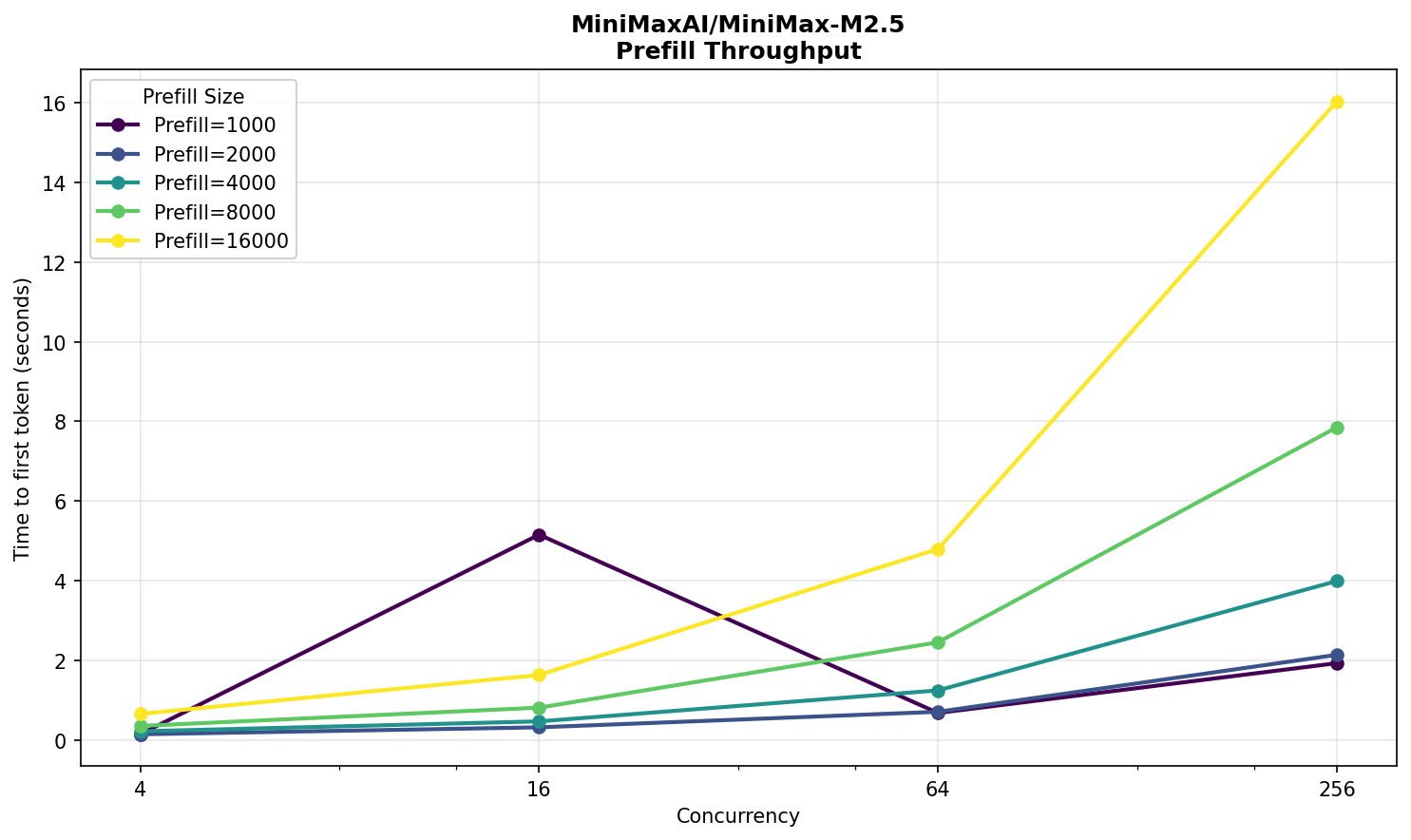
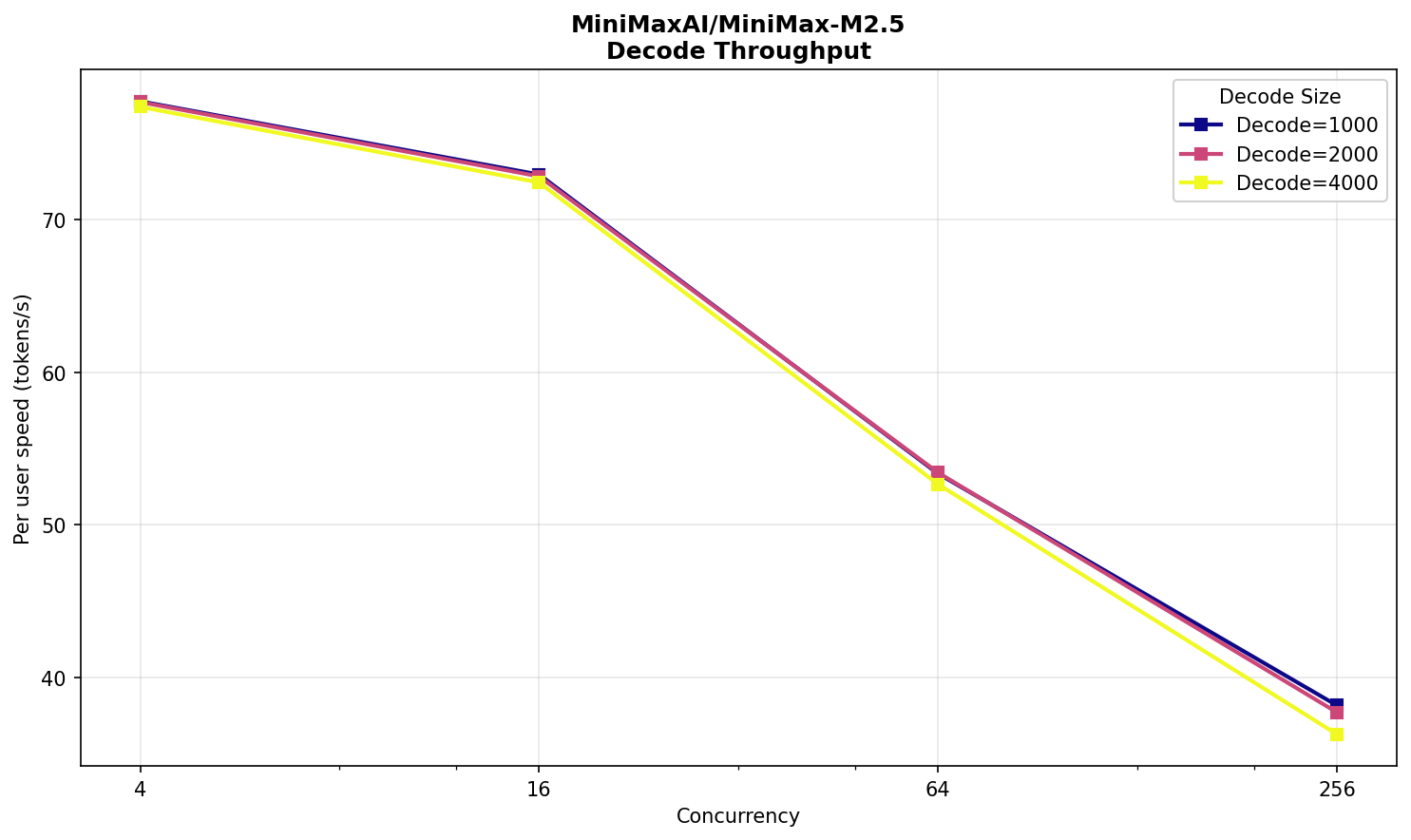
В целом, результат нельзя назвать выдающимся. Модель значительно меньше DeepSeek — почти в целых три раза! — но производительность выше ненамного. Да, на prefill разница существенная, но на decode ее совсем не видно. Заметим, что у Minimax 10 млрд активных параметров, а у Deepseek — 37 млрд. Здесь как будто есть простор для оптимизации в vLLM.
Варианта NVFP4 от NVIDIA нет, а неофициальные я не проверял — нет уверенности, что они правильно конвертированы.
Qwen 3.5 397B NVFP4
Интересная модель, тем более что есть официальная квантизация от NVIDIA. Помещается в две карты, всего получится разместить четыре экземпляра. Каких-то особых параметров запуска не требуется, все настройки — по умолчанию.
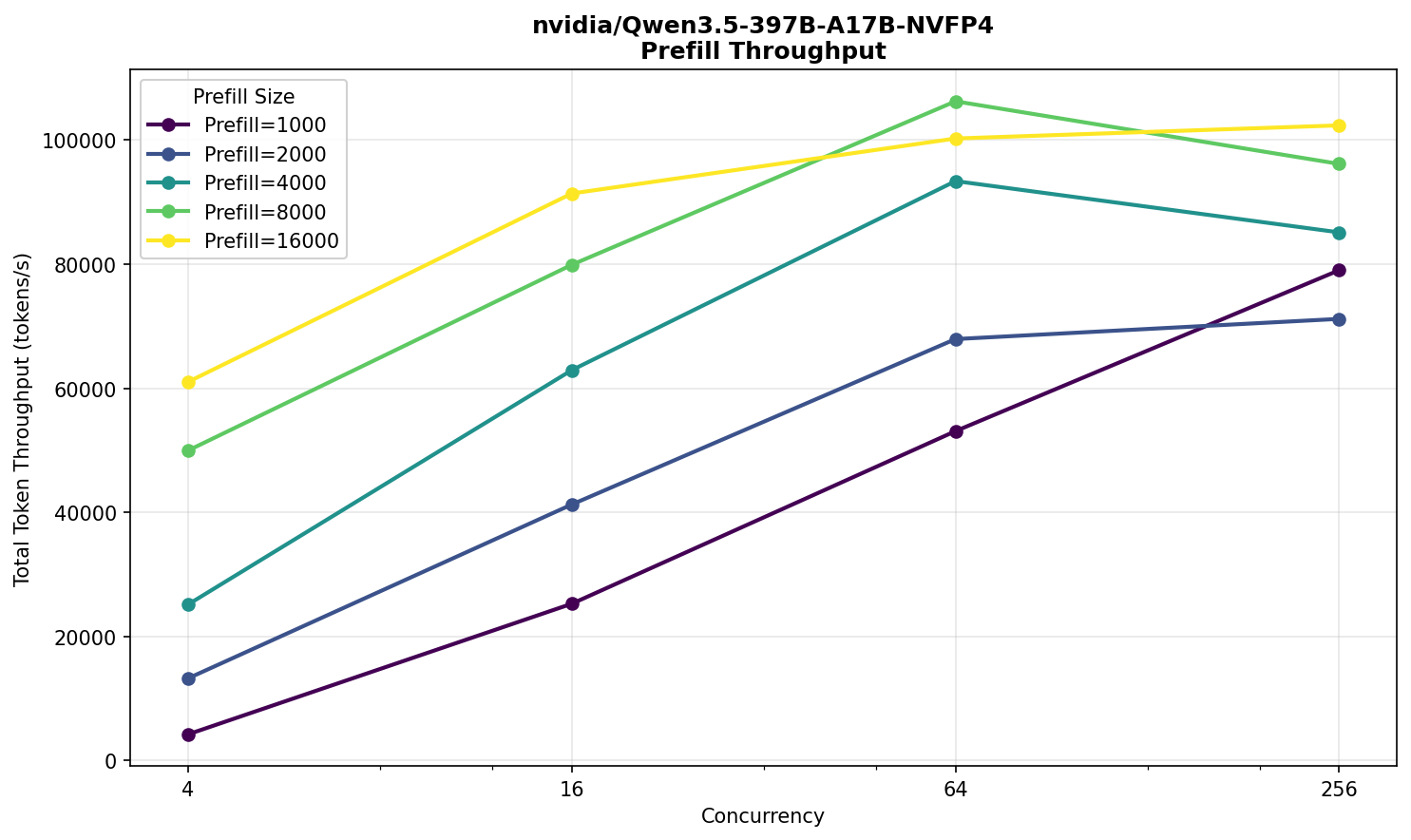
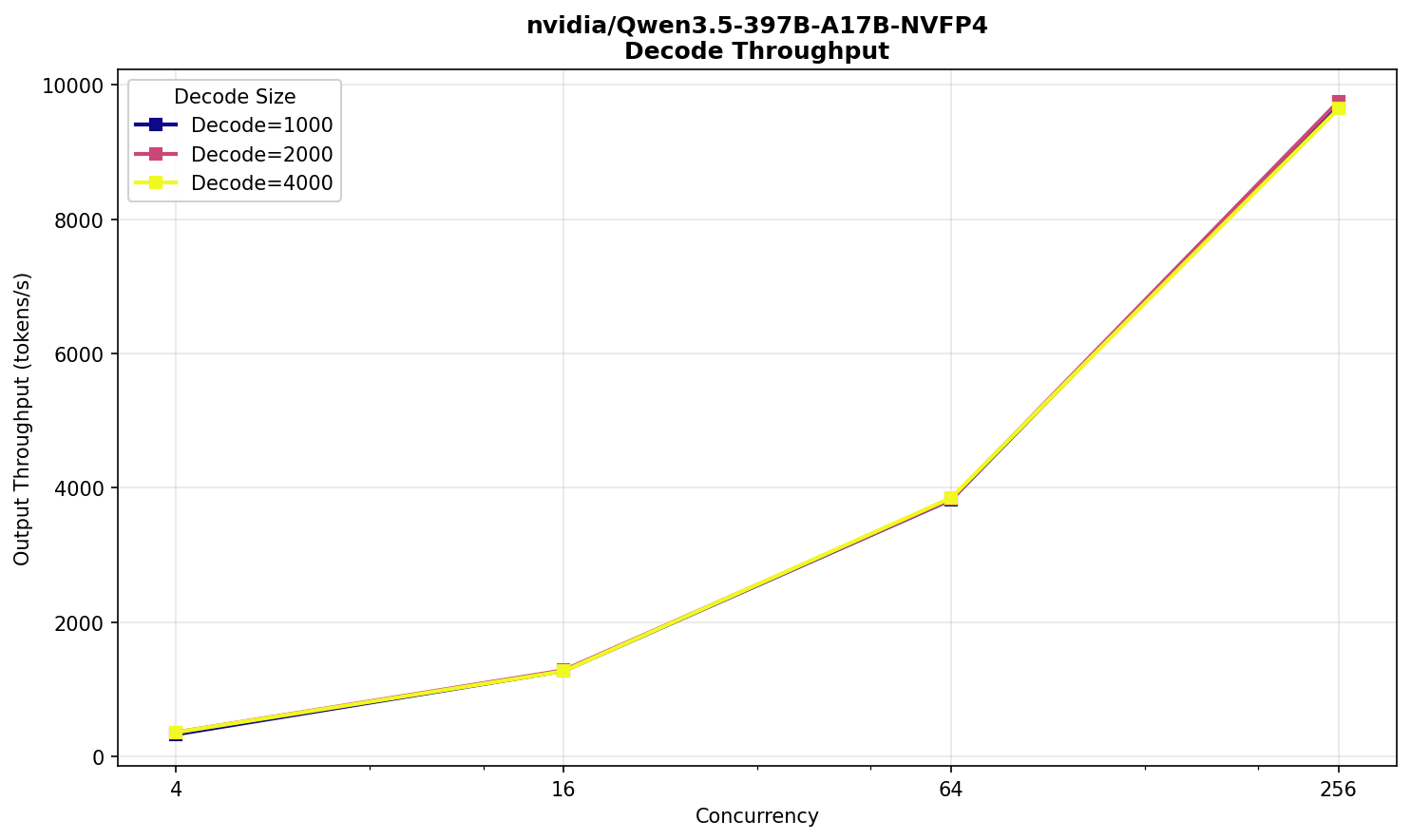
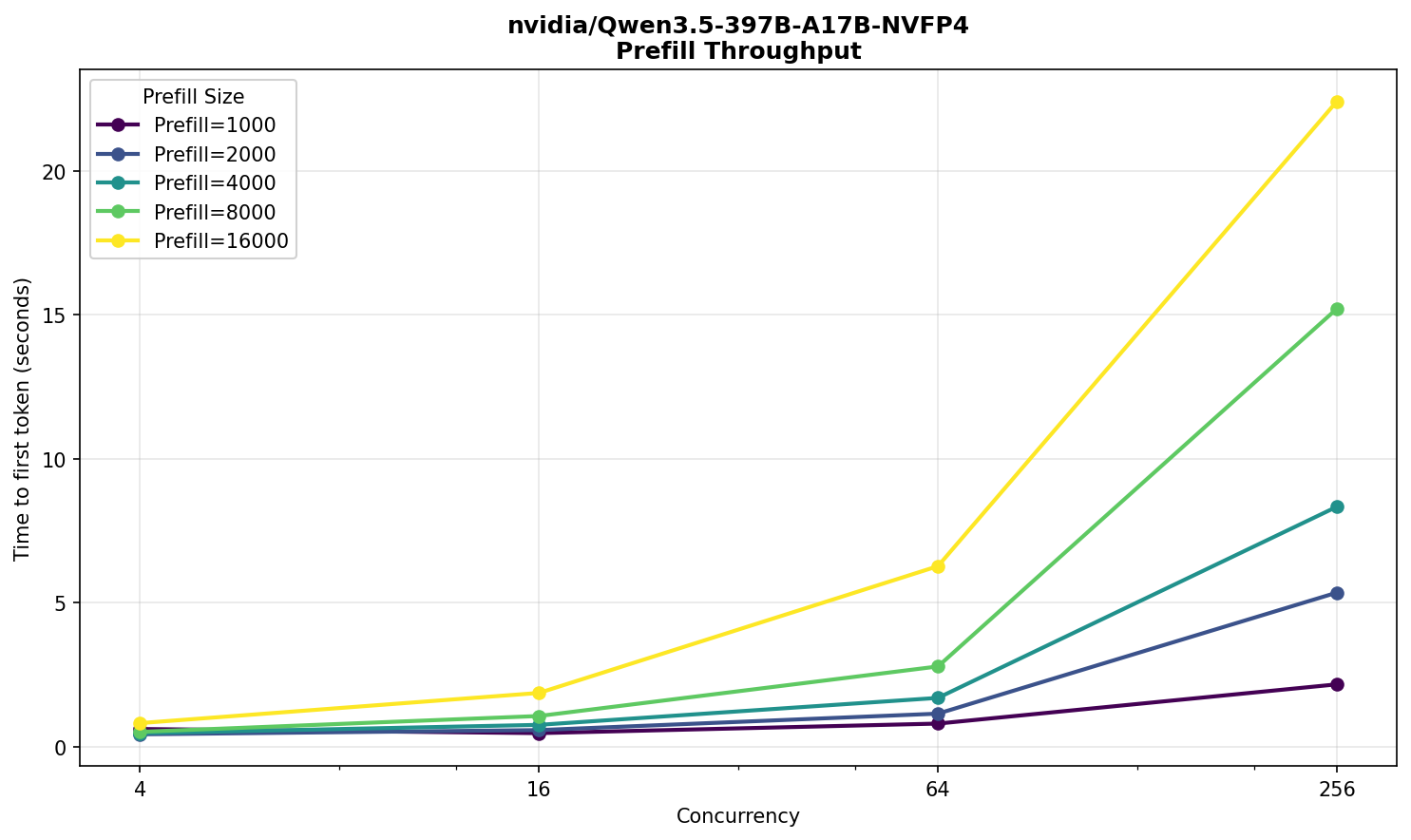
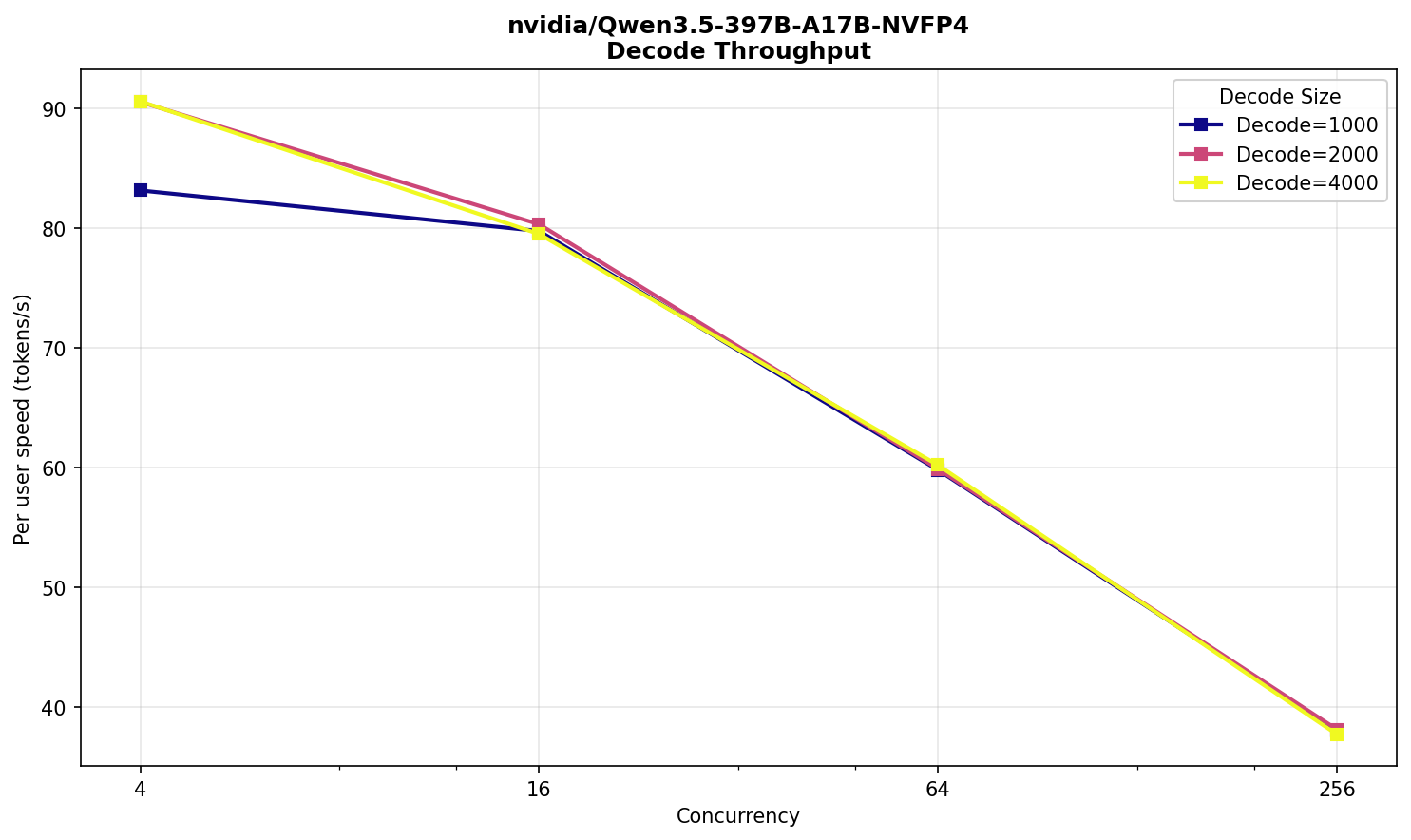
Никаких сюрпризов и аномалий не наблюдается. Производительность ожидаемо немного выше DeepSeek и, примерно, соответствует размеру модели в 397 млрд параметров.
Ожидание пользователя на 16 тыс входных токенов при 256 одновременных запросах — около 25 секунд, скорость — 38 TPS.
Qwen 3.5 умеет распознавать изображения, а значит для инференса модель становится еще интереснее.
Оценка производительности
Давайте посмотрим на быстродействие всех моделей на общей диаграмме, а затем попробуем прикинуть: сколько же пользователей сможет обслужить HGX™ B300 для каждой из них.
Для сравнения возьмем конкурентность 64, на которой и большинство моделей показывают себя лучше всего, и комфорт использования выше, чем на максимальной нагрузке.
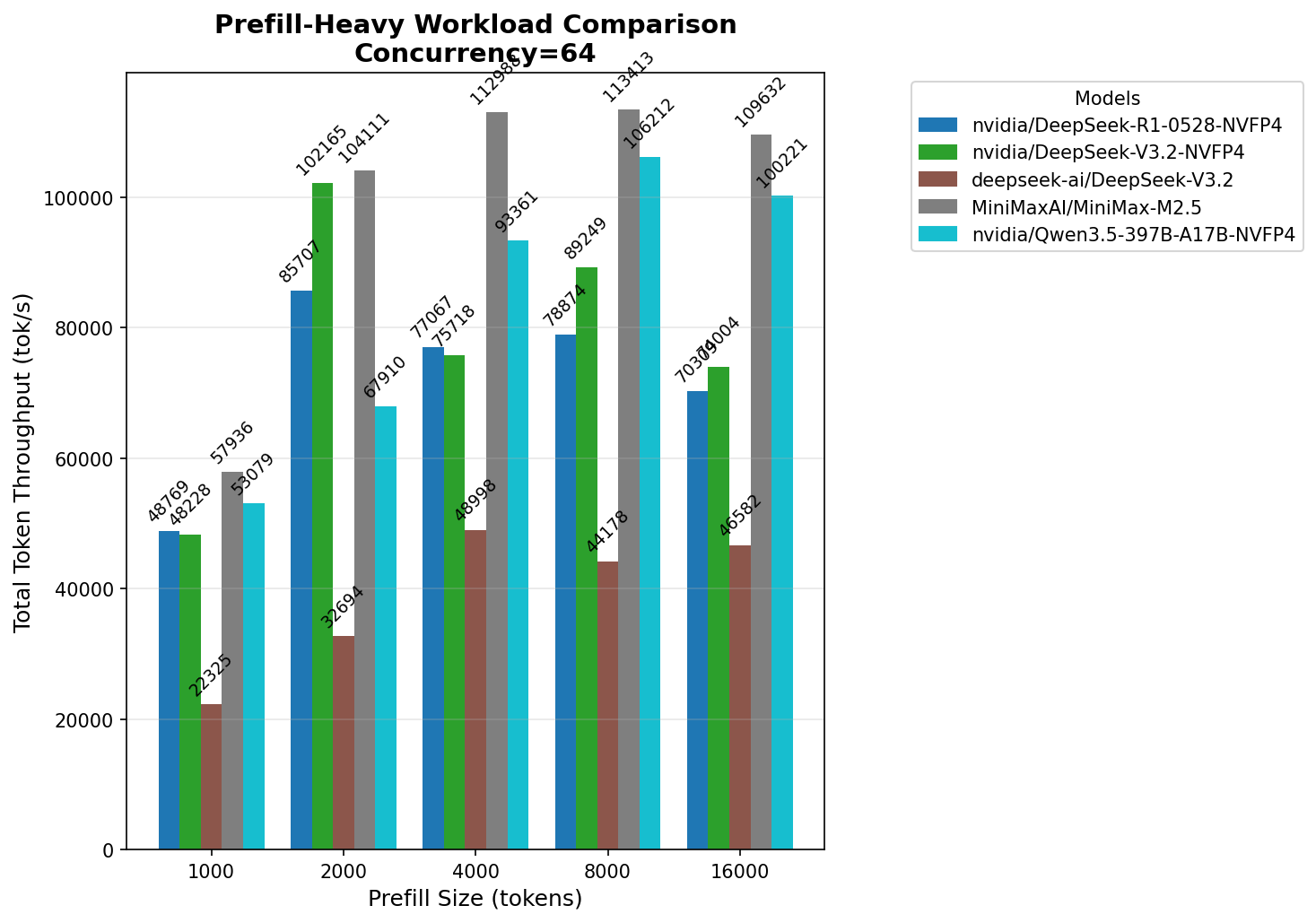
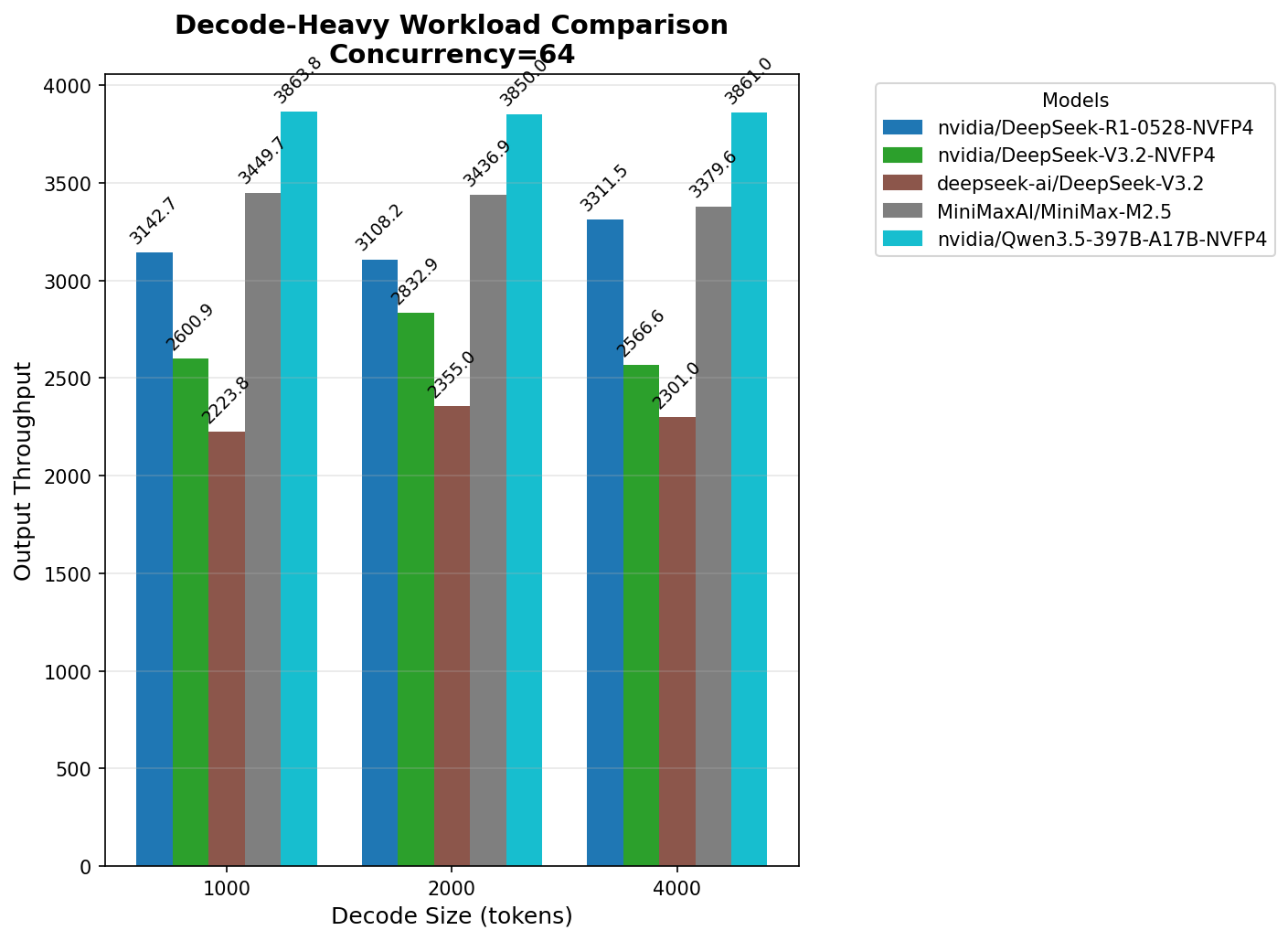
Что же мы видим?
1. NVFP4 может ускорять инференс на prefill и удешевляет токен входного текста в 2−3 раза.
2. На decode‑стадии в NVFP4 есть незначительная разница в производительности на одной и той же модели. Причин для объяснения может быть много, вот только некоторые:
- неоптимизированный код инференс‑сервера,
- разные бэкенды для NVFP4 и FP8 — реализации отличаются кардинально,
- совмещение prefill и decode,
- конкуренция за память.
Нужно доискиваться до причины такого поведения.
Некоторые модели могут иметь неоптимальную реализацию. Minimax M2.5 запускался без накладных расходов на распределение по картам, так как он небольшой и влезает в VRAM одного B300. Однако, для его размера и числа активных параметров я ожидал большей производительности, особенно на decode.
А что с числом пользователей?
Здесь все сильно зависит от вашего сервиса, на который будет работать инференс. Поэтому проще накопить небольшую статистику и подсчитать число настоящих запросов, которое обрабатывает HGX‑сервер для определенной модели.
Предварительно можно прикинуть, исходя из результатов наших синтетических тестов. Понятно, что оценка будет приблизительная — реальные запросы отличаются в размере и не всегда хорошо собираются в батчи для эффективного инференса.
Методика расчета следующая.
- Делим число токенов в секунду из диаграммы выше на размер запроса — prefill size или decode size.
- Умножаем полученное значение на время в секундах за интересующий период — например, 86 400, если расчет производится для суток.
Например, Qwen 3.5 на стадии decode выдает 3863 TPS, размер ответа — 1000 токенов, то есть, в среднем, получается почти четыре ответа в секунду. Формирование каждого из них не мгновенно — требуется около полминуты. При одновременной обработке 64 запросов, выходят те же, примерно, четыре ответа в секунду.
Оценки для генерации ответов с размером decode в 1000 токенов, запросов в сутки:
- Qwen 3.5 397B NVFP4 — 330 тыс,
- Deepseek V3.2 NVFP4 — 225 тыс.
Входящие обрабатываются намного быстрее, и пропускная способность системы выше. Оценим для входящего запроса на 4000 токенов, в запросах в сутки:
- Qwen 3.5 397B NVFP4 — 2 млн;
- Deepseek V3.2 NVFP4 — 1,6 млн.
Много это или мало — решать вам.
Внедрение совсем свежих релизов может сопровождаться программными сложностями, поэтому перед запуском в продакшен требуется тщательное тестирование.
Сервер на базе B300 легко тянет самые новые и масштабные нейросети, стабильно обрабатывает огромный поток параллельных запросов с минимальной задержкой и высокой скоростью генерации.
Не возникает никаких вопросов к работе с тяжеловесами, вроде Qwen 3.5 или семейства DeepSeek R1/V3.2. Поддержка формата NVFP4 и колоссальный запас VRAM — идеальный инструмент для инференса.





