

Связи между таблицами данных устанавливают логические отношения между хранимыми сущностями — например, пользователями, заказами и продуктами. Это упрощает структурирование данных и управление ими. Связи позволяют сократить дублирование информации и обеспечить ее целостность, а также эффективно объединять данные из разных таблиц. Обсудим отношения таблиц и про типы их соединений.
Реляционные базы данных
Существует несколько типов баз данных, но наиболее распространены из них реляционная и нереляционная.
Характеристики реляционной БД (SQL):
- данные хранятся в таблицах;
- таблицы связаны;
- использует SQL для запросов.
Популярные реляционные БД — MySQL, PostgreSQL и другие.
Предпочтительно, чтобы реляционная СУБД соответствовала набору требований ACID, которые являются стандартом для высоконадежных систем.
- Атомарность (от англ. atomicity) — гарантированная фиксация транзакций. Либо транзакция будет выполнена со всеми подоперациями, либо не будет выполнено ни одной.
- Согласованность (от англ. consistency) — каждая успешно завершенная транзакция фиксирует только допустимые результаты.
- Изоляция (от англ. isolation) — параллельно выполняемые транзакции не оказывают влияния на результат других транзакций.
- Устойчивость (от англ. durability) — гарантированное сохранение данных транзакции даже в случае сбоя системы.
- Эти требования обеспечивают предсказуемую и наиболее надежную работу СУБД.
Задачи, для которых подходят реляционные БД:
- хранение структурированных данных с четкой схемой: таблицы, связи, ключи;
- обработка транзакций, требующая строгого соблюдения ACID-свойств;
- работа с данными, где важна согласованность и предсказуемость;
- приложения с относительно фиксированной структурой данных: например, финансовые системы, CRM.
Нереляционная БД (NoSQL):
- хранение данных в разных форматах: документы, ключ-значение, графы, столбцы;
- отсутствие жесткой структуры данных;
- использование различных подходов для хранения и обработки данных в зависимости от типа базы данных;
популярные нереляционные БД — Redis, MongoDB и другие.
Задачи, для которых подходят нереляционные БД:
- обрабатывание больших объемов данных (Big Data), включая полу- и неструктурированные данные;
- хранение данных в распределенных системах с высоким уровнем масштабируемости;
- работа с данными, где структура может изменяться со временем: например, JSON-документы;
- приложения, где допускаются компромиссы между согласованностью и доступностью: рекомендательные системы, IoT, социальные сети.
Для большинства задач используют несколько таблиц, чтобы разделить данные по типам и избежать дублирования. Это соответствует правилам нормализации, которые помогают структурам баз данных быть упорядоченными и эффективными.
Нормализация данных
Первая нормальная форма:
- каждая ячейка таблицы может хранить только одно значение;
- в одном столбце все данные должны быть только одного типа;
- каждая запись в таблице должна быть уникальной.
Вторая нормальная форма:
- таблица должна соответствовать первой нормальной форме;
- в таблице должны отсутствовать частичные зависимости;
- каждая запись в таблице должна иметь первичный ключ (Primary Keys), по которому ее гарантированно можно отличить от любой другой.
Третья нормальная форма:
- таблица должна соответствовать второй нормальной форме;
- в таблице должны отсутствовать транзитивные зависимости, то есть зависимости одних неключевых столбцов от других.
Как организовываются связи
При нормализации данных необходимо также описать отношения между таблицами. Благодаря этим отношениям формируется связность баз данных и обеспечивается ее целостность. Связь — это соединение двух таблиц, которое отражает, как данные одной таблицы соотносятся с данными другой. С точки зрения реляционной модели, такие связи возникают через ключи.
- Первичные ключи (Primary Keys) — определяют уникальность каждой строки в таблице.
- Внешние ключи (Foreign Keys) — связывают строки одной таблицы со строками другой таблицы, указывая на первичные ключи.
Протестируйте облачные базы данных бесплатно
Отношения таблиц
Когда данные нормализованы, нужно понять, как связать таблицы. От правильного определения типов связи между таблицами зависит, насколько легко и эффективно будет работать система.
Отношения «один к одному» с обязательной связью
Все примеры будут, конечно же, с динозаврами.
Кейс использования: у каждого динозавра в компании должен быть персональный пропуск.
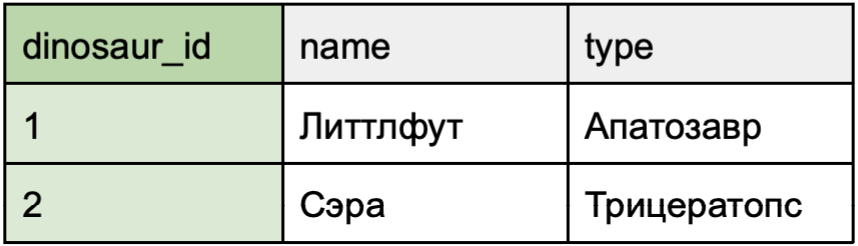

Отношения «один к одному» с необязательной связью
Кейс использования: у некоторых динозавров может быть специальное образование, но это необязательно. У всех, кроме Даки, есть специальное образование.
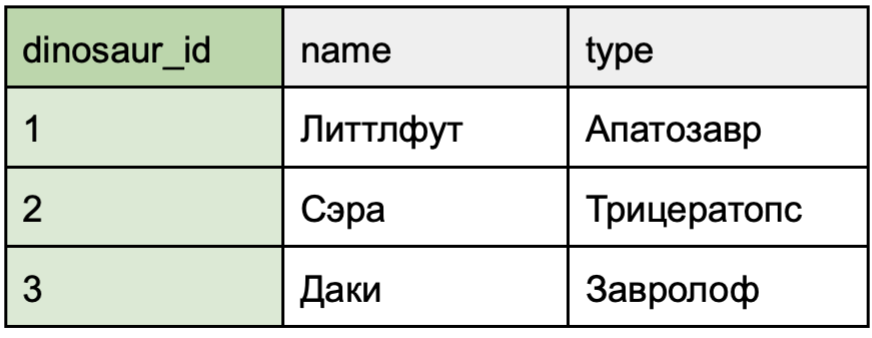

Отношения «один ко многим» с необязательной связью
Кейс использования: динозавр может писать статьи, но это не обязательно. Динозавр может отсутствовать в записях о написанных статьях.
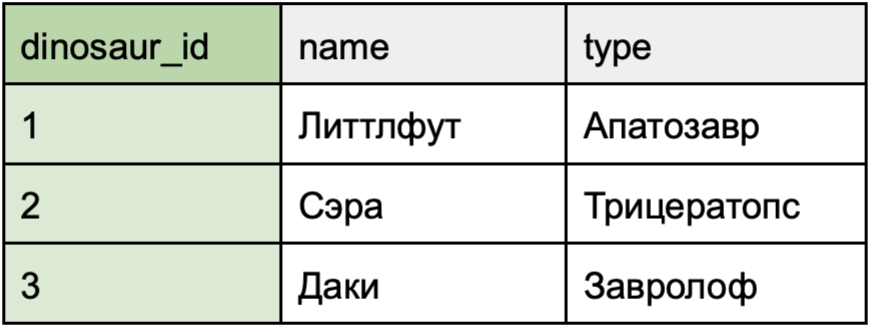

Отношения «один ко многим» с обязательной связью
Кейс использования: каждый динозавр обязательно должен быть частью хотя бы одного подразделения в компании.

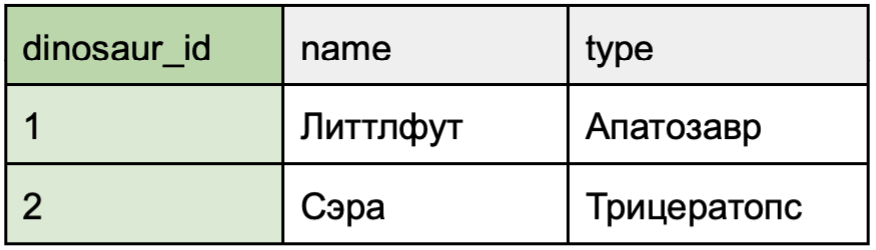
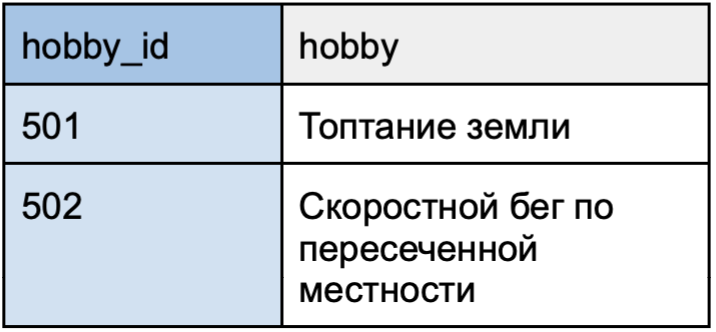
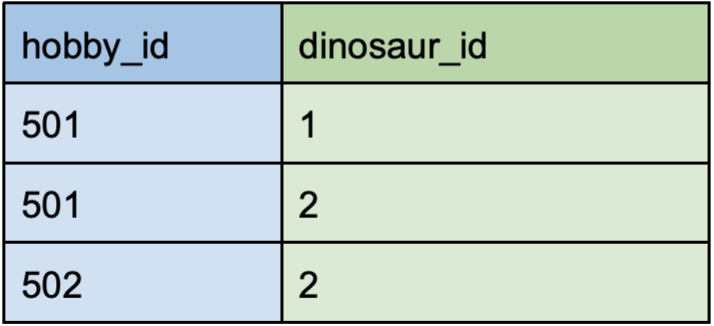
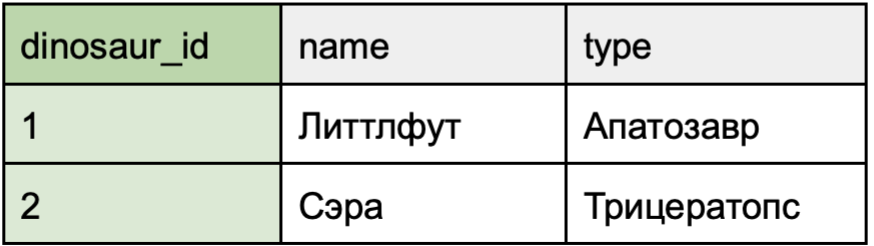
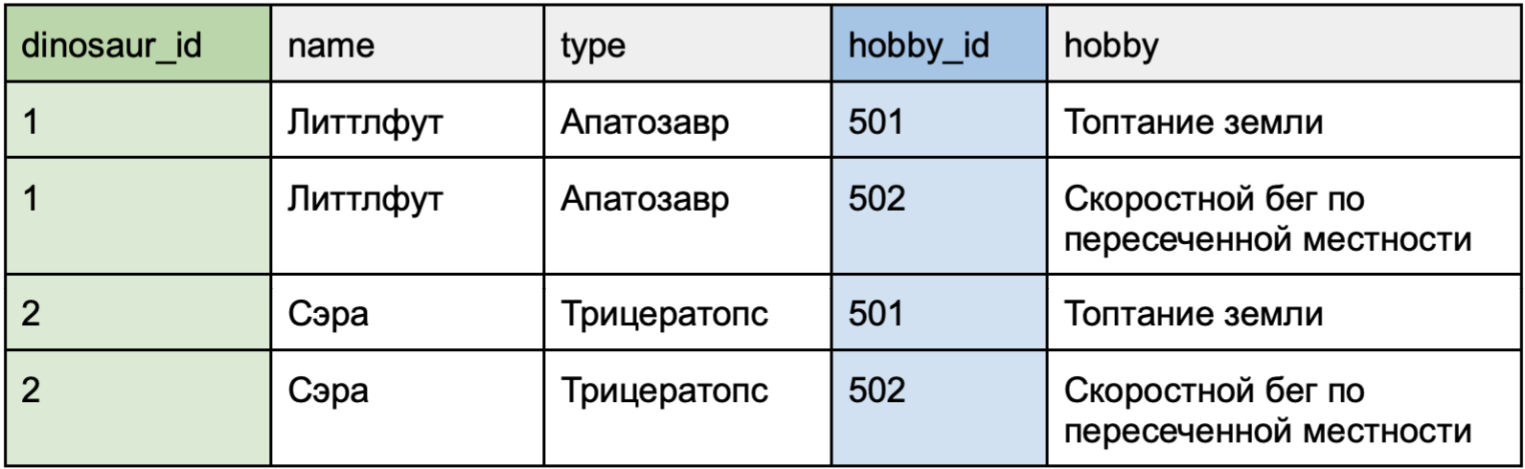
Отношение «многие ко многим»
Кейс использования: один динозавр может заниматься несколькими хобби, а одним хобби могут заниматься несколько динозавров.
Этот тип отношений реализуется через промежуточную таблицу — пример показан в таблице «Хобби».
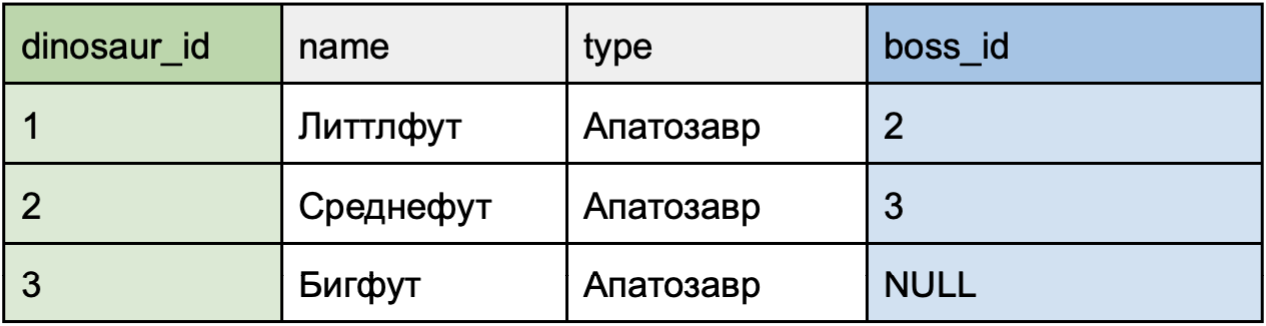
Связь таблицы с самой собой
Кейс использования: компания хранит информацию о динозаврах и их руководителях. Если руководителя нет (например, этот динозавр является владельцем компании), поле boss_id будет NULL.
Типы соединения баз данных (JOIN) в SQL
После того, как данные были нормализованы, а отношения выбраны, можно переходить к чтению таблиц. Для извлечения необходимых данных из таблиц используется SQL — язык структурированных запросов. Разберем ключевые операторы:
- SELECT — извлечение данных из таблиц;
- WHERE — фильтрация строк по условиям;
- ORDER BY — сортировка строк по колонке;
- GROUP BY — группировка строк на основе значений колонок;
- JOIN — объединение данных из нескольких таблиц;
- Тип объединения, например, Left / Right. Он определяет, каким образом объединятся таблицы. Для примера вернемся к динозаврам.
Левое внешнее (Left JOIN)
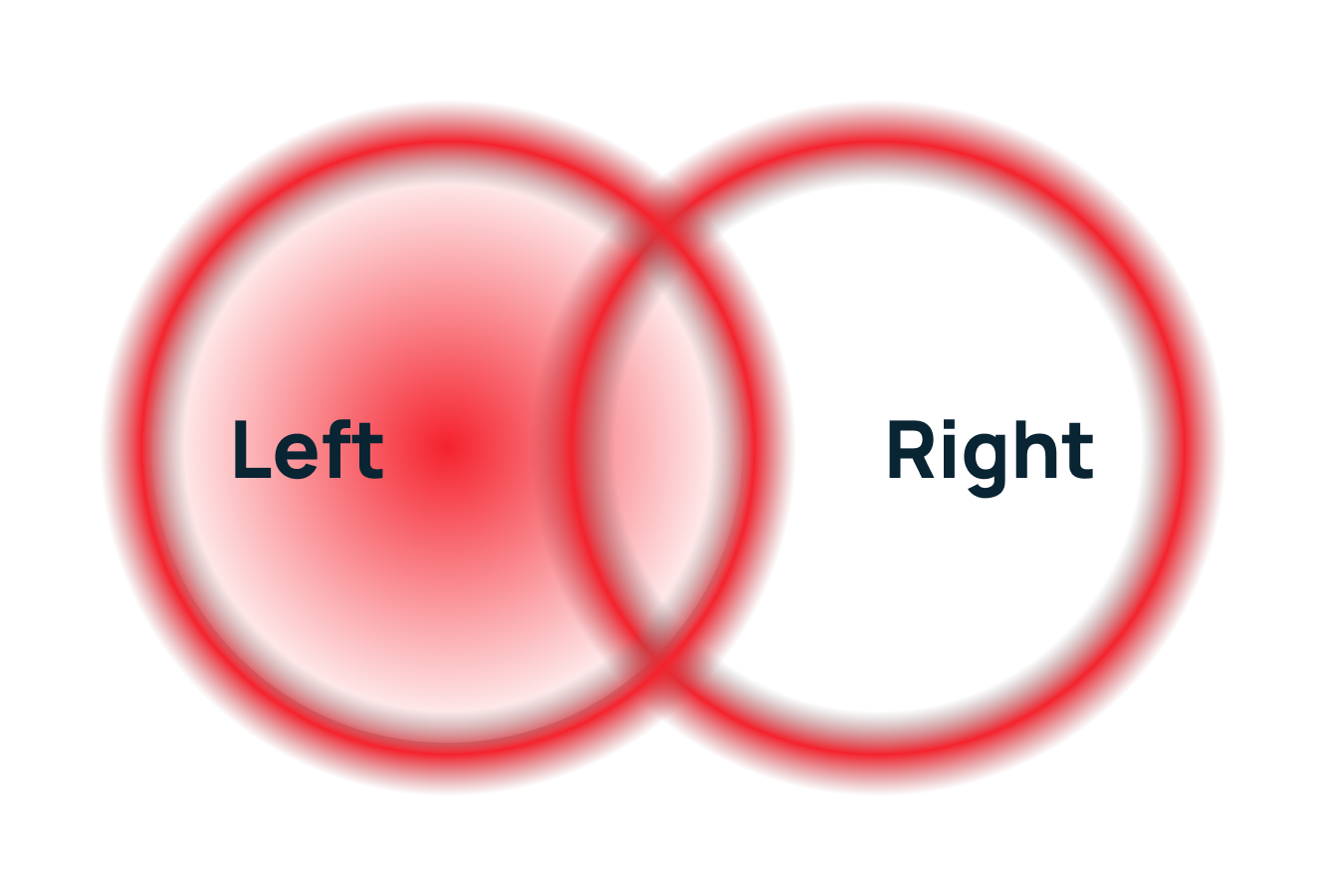
Что делает: возвращает все строки из левой таблицы и соответствующие строки из правой. Если совпадений нет, недостающие значения из правой таблицы заполняются NULL.
Задача: узнать, какие динозавры занимаются хобби, а какие — нет.
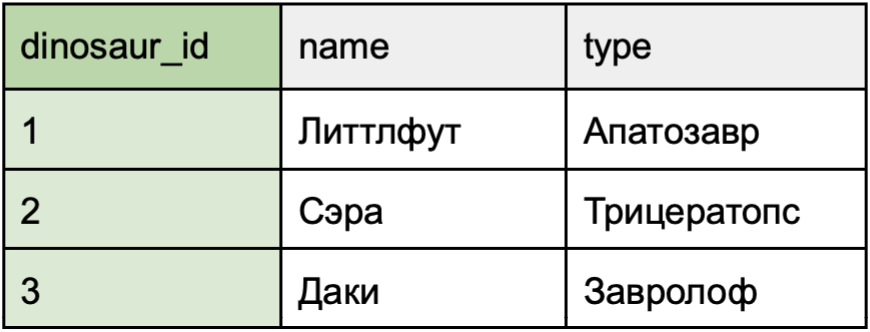
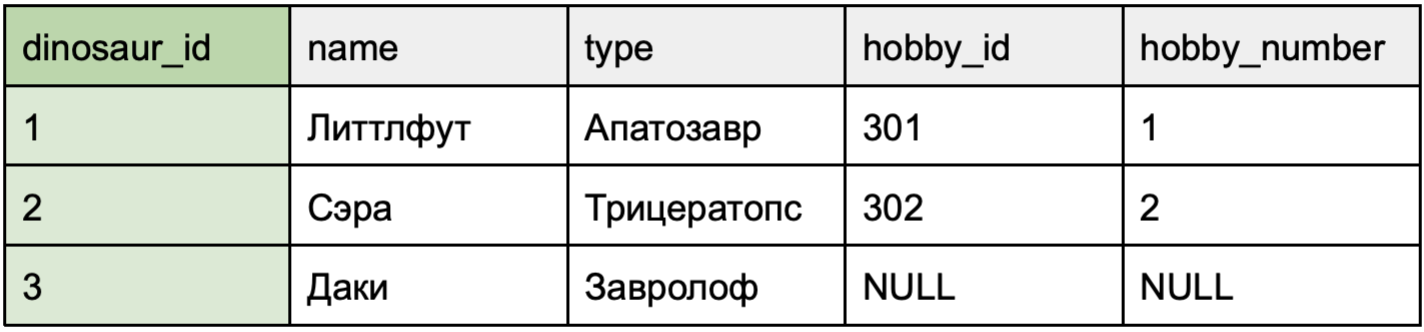
Представим, что таблица dinosaur расположена слева и будет объединена с таблицей hobby. Нам необходимо выбрать признак, по которому эти таблицы будут объединены. В данном случае, это dinosaur_id.

SELECT
d.dinosaur_id, -- dinosaur_id из таблицы "dinosaur"
d.name, -- name из таблицы "dinosaur"
d.type, -- type из таблицы "dinosaur"
h.hobby_id, -- hobby_id из таблицы "hobby"
h.hobby_number -- hobby_number из таблицы "hobby"
FROM
dinosaur d
LEFT JOIN
hobby h ON d.dinosaur_id = h.dinosaur_id; -- соединение по dinosaur_id
Объяснение: запрос возвращает всех динозавров из таблицы dinosaur, а также данные из таблицы hobby, если такие есть. Если для динозавра нет хобби, в столбцах hobby_id и hobby_number будут NULL.
Правое внешнее (Right JOIN)
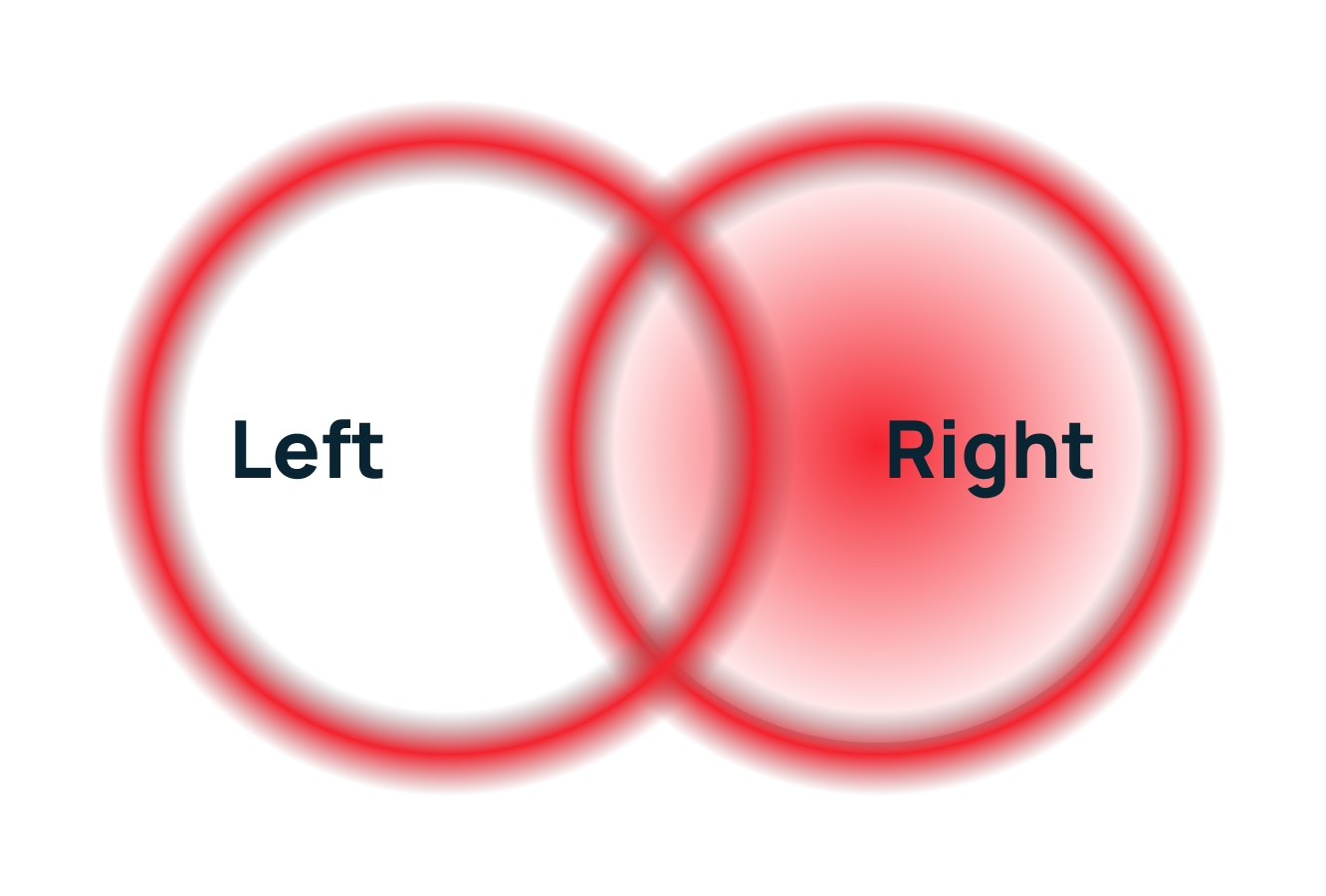
Что делает: возвращает все строки из правой таблицы и соответствующие строки из левой. Если совпадений нет, недостающие значения из левой таблицы заполняются NULL.
Задача остается той же, но в этот раз будем выводить только тех, кто занимается хобби.
Запрос Right JOIN используется редко, т.к. он зеркален Left JOIN.
Теперь необходимо объединить таблицу hobby с таблицей dinosaur также по dinosaur_id.
SELECT
d.dinosaur_id, -- dinosaur_id из таблицы "dinosaur"
h.hobby_id, -- hobby_id из таблицы "hobby"
h.hobby_number, -- hobby_number из таблицы "hobby"
d.name, -- name из таблицы "dinosaur"
d.type -- type из таблицы "dinosaur"
FROM
hobby h
RIGHT JOIN
dinosaur d ON h.dinosaur_id = d.dinosaur_id; -- соединение по dinosaur_id
Объяснение: запрос возвращает все записи из таблицы hobby и соответствующие данные из таблицы dinosaur. Если для хобби нет соответствующего динозавра, данные из таблицы dinosaur будут NULL, но так как таблица hobby уже ограничивает результат теми динозаврами, которые занимаются хобби, динозавры без хобби не попадут в результат.

Внутреннее (Inner JOIN)
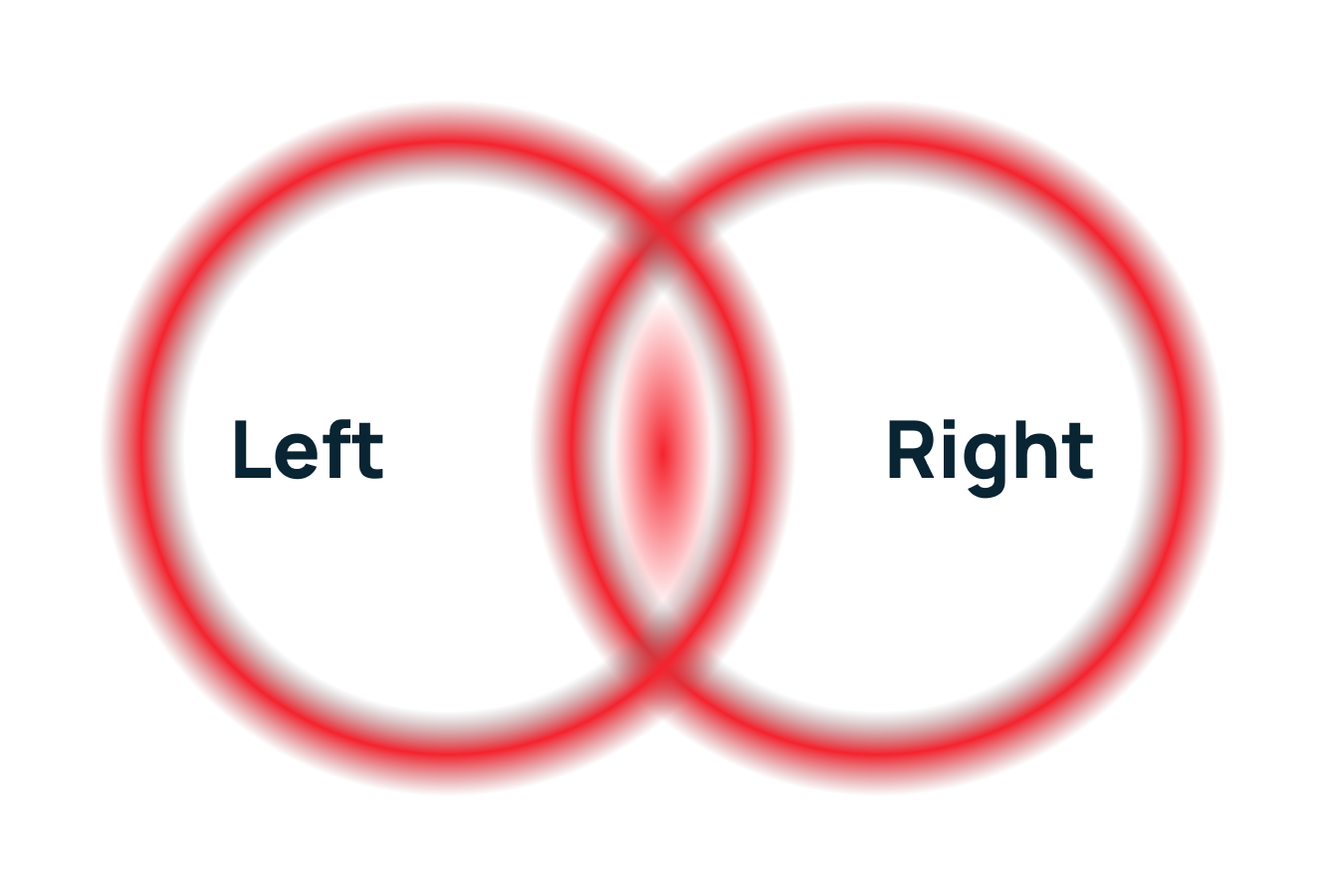
Что делает: возвращает только те строки, которые имеют совпадения в обеих таблицах по указанному условию.
Задача: узнать, у каких динозавров есть фотография.
Нам нужно объединить таблицы dinosaur и photo.

SELECT
d.dinosaur_id, -- dinosaur_id из таблицы "dinosaur"
p.passport_id, -- passport_id из таблицы "photo"
d.name, -- name из таблицы "dinosaur"
d.type, -- type из таблицы "dinosaur"
p.photo -- photo из таблицы "photo"
FROM
dinosaur d
INNER JOIN
photo p ON d.dinosaur_id = p.dinosaur_id; -- соединение по dinosaur_id
Объяснение: запрос возвращает только тех динозавров, у которых есть фото. Он объединяет таблицы dinosaur и photo, используя внутреннее соединение. Это означает, что в результат попадут только те записи, у которых есть совпадение в обеих таблицах.

Полное (Full JOIN)
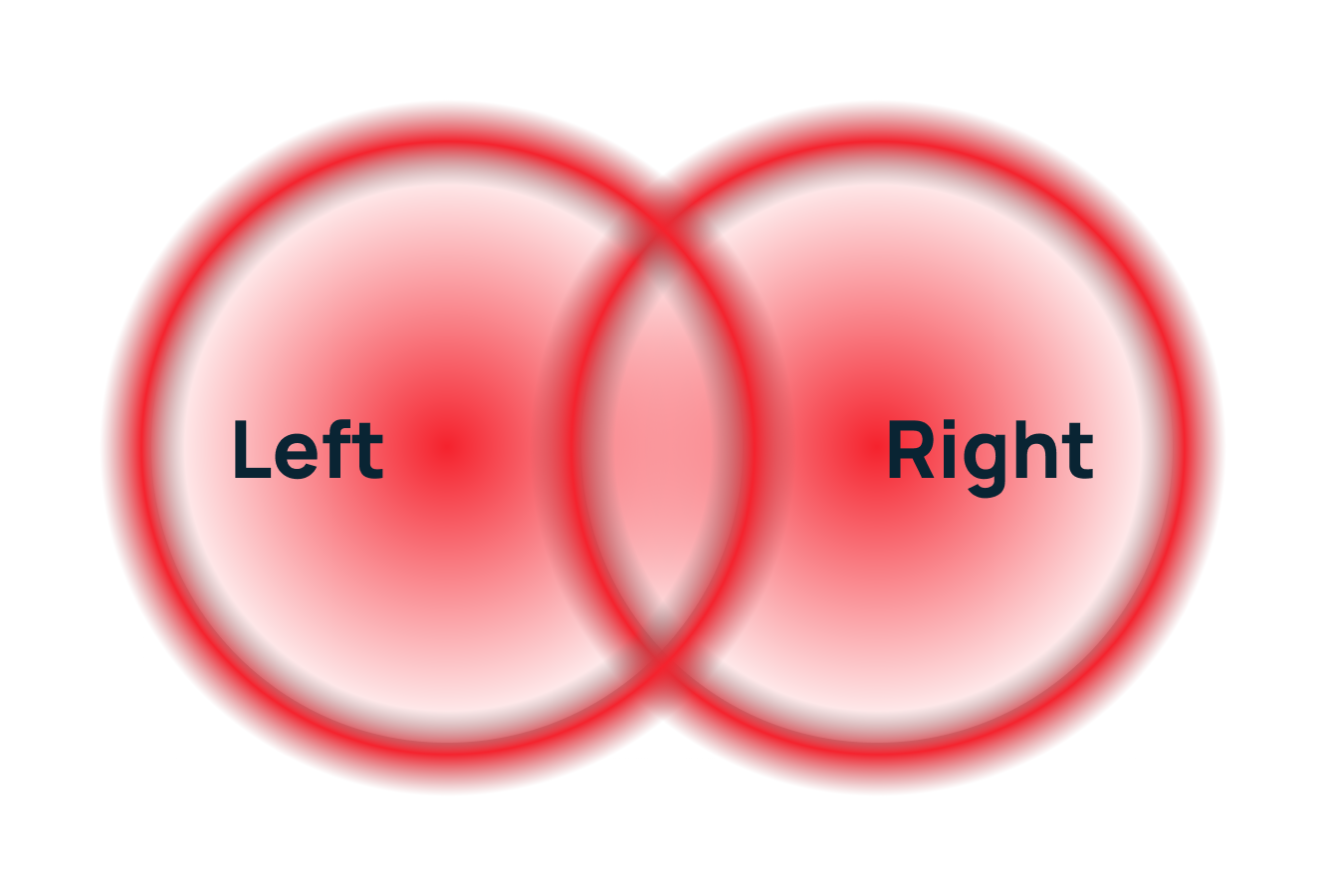
Что делает: возвращает все строки из обеих таблиц, заполняя NULL там, где нет совпадений.
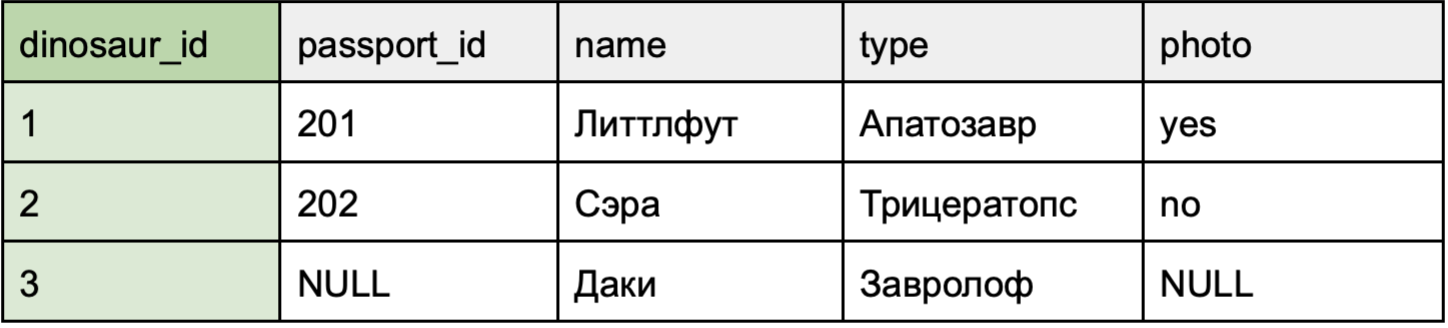
Задача та же: узнать, у каких динозавров есть фото.
Нам нужно объединить таблицы dinosaur и photo. При таком типе объединения в результате будут выведены все строки таблицы, даже те, у которых отсутствуют значения в каком-то из столбцов.
Важно: MySQL не поддерживает полный внешний JOIN, но для других СУБД, например, PostgreSQL, запрос будет следующим.
SELECT
d.dinosaur_id, -- dinosaur_id из таблицы "dinosaur"
p.passport_id, -- passport_id из таблицы "photo"
d.name, -- name из таблицы "dinosaur"
d.type, -- type из таблицы "dinosaur"
p.photo -- photo из таблицы "photo"
FROM
dinosaur d
FULL OUTER JOIN
photo p ON d.dinosaur_id = p.dinosaur_id; -- соединение по dinosaur_id
Объяснение: запрос возвращает все строки из обеих таблиц, даже если для некоторых динозавров нет фото или наоборот. В таких случаях значения будут NULL.
Перекрестное (Cross JOIN)
Что делает: выполняет декартово произведение таблиц, создавая всевозможные комбинации строк из обеих таблиц, путем соединения каждой строки из одной таблицы с каждой строкой из другой таблицы.
Задача: составить таблицу из всевозможных вариантов участия динозавров в хобби.

Важно: данный тип соединения используется редко на практике, т.к. результатом является достаточно большой объем данных.
SELECT
d.dinosaur_id, -- dinosaur_id из таблицы "dinosaur"
d.name, -- name из таблицы "dinosaur"
d.type, -- type из таблицы "dinosaur"
h.hobby_id, -- hobby_id из таблицы "hobby"
h.hobby -- hobby из таблицы "hobby"
FROM
dinosaur d
CROSS JOIN
hobby h; -- Декартово произведение таблиц "dinosaur" и "hobby"
Объяснение: запрос выполняет декартово произведение таблиц dinosaur и hobby, создавая все возможные комбинации строк из обеих таблиц. Результат будет содержать все варианты, где каждый динозавр связан с каждым хобби.
Целостность данных при соединении
Целостность данных в базах данных — это соответствие содержащейся в них информации определенным правилам. Например, если столбец предназначен для хранения номеров телефонов, значение не может содержать более 15 символов. Таким образом, попытка записи номера из 17 знаков будет отклонена.
Для реляционных баз данных выделяют четыре типа ограничений целостности:
- Определение допустимых значений для столбцов
Пример: age INT CHECK (age >= 18) — возраст должен быть 18 лет или старше.
2. Гарантия уникальности записей
Пример: id INT PRIMARY KEY — идентификатор должен быть уникальным для каждой записи.
3. Поддержка связи между таблицами
Пример: FOREIGN KEY (dinosaur_id) REFERENCES dinosaur(id) — значение dinosaur_id должно ссылаться на существующий id в таблице dinosaur.
4. Запрет дублирования значений
Пример: pass VARCHAR(255) UNIQUE — значение в поле пропуска должно быть уникальным.
Несмотря на то, что СУБД отклоняет данные, не соответствующие этим правилам, это не гарантирует, что данные отражают реальность. Например, если ввести номер телефона, состоящий из 11 знаков, он запишется в БД, но не обязательно будет являться действующим номером того, кто его внес. Таким образом, если данные достоверны, они всегда будут непротиворечивыми, но непротиворечивые данные не всегда достоверны.
Целостность данных при использовании JOIN в SQL называется ссылочной целостностью. Она гарантируется с помощью внешних ключей (FOREIGN KEY).
В чем преимущество использования облачных баз данных Selectel
В облачных базах данных Selectel используется подход Multi-AZ (автономные зоны). Благодаря такому подходу повышается отказоустойчивость баз данных, т.к. ноды каждого многонодного кластера, который размещен в пулах ru-1, ru-2, ru-3, ru-7, будут гарантированно распределены по изолированным друг от друга сегментам пула: a,b,c. Каждый сегмент оборудован своими вводами питания, ИБП, дизель-генератороной установкой, охлаждением, сетью и прочими системами жизнеобеспечения ЦОД.
Также облачная платформа Selectel и облачные базы данных соответствуют требованиям 152-ФЗ, PCI DSS, ISO 27001, ISO 27017, ISO 27018 и ГОСТ Р 57580, что гарантирует высокий уровень информационной безопасности, обеспечение надежной защиты данных и соответствие лучшим практикам.
Заключение
Связи в таблицах делают базы данных более организованными, масштабируемыми и удобными для работы. Они позволяют эффективно связывать информацию из разных таблиц и упростить процесс управление данными.





