

Не секрет, что ML‑модели требуют огромного количества данных. Информации не просто много, она организовывается в многообразные структуры, версионируется, употребляется разными моделями. Скорость обращения данных тоже критична, особенно для систем, взаимодействующих с пользователями в режиме реального времени.
При возросшей сложности не обойтись без специализированных инструментов, например Feature Store. Однако случается, что все решения на рынке не годятся по тем или иным причинам. Тогда приходится рассчитывать исключительно на свои силы.
Статья написана по мотивам выступления Юрия Классена, тимлида MLOps‑команды в «Купере» — одного из крупнейших онлайн-сервисов доставки из магазинов и ресторанов.
Предыстория
Для любой современной компании c большой базой клиентов предсказание спроса — уже не конкурентное преимущество, а необходимость. Рекомендательные системы в розничной торговле стали обычным явлением. В Купере машинное обучение используют повсеместно.
Использование ML‑практик во всей логистической цепочке, вплоть до сборщиков и курьеров, позволяет оптимизировать затраты и сделать наше предложение на рынке еще более привлекательным по цене.
Основные верхнеуровневые сущности, на которых строится обучение ML-моделей — это признаки (features). Чем их больше, тем существеннее требования к информационной системе. В какой-то момент становится очевидно, что без Feature Store дальнейшее развитие сложного ML-проекта оказывается под сомнением.
Feature Store — объединение лучших ML‑практик по работе с признаками (features), интерфейс между данными и использующими их моделями.
Без специального хранилища признаков на MLOps-инженеров наваливаются дополнительные рутинные задачи, а интерфейс, который видят перед собой пользователи, начинает серьезно подтормаживать. Команда Купера ощутила это на своем опыте.
Перед нашими подразделениями MLOps стоит много задач. Самое важное — работа над рекомендательной и поисковой системами. Проекты высоконагруженные, производят сотни и даже тысячи запросов в секунду и каждый день пополняют базу данных на десятки гигабайт.

Пока объем обучающих данных невелик, достаточно простых инструментов, а признаки можно хранить в памяти. По мере разрастания данных команда ожидаемо упирается в предел, а простые инструменты, как известно, не масштабируются.
Задача Купера состояла в том, чтобы добиться скорости обслуживания запросов, не превышающей 50 мс. Смягчить требования нельзя — пользователи увидят задержку. Архитектура Feature Store позволяет упорядочить и ускорить работу с признаками: данные отделены от ML-процессов, а роли участников четко определены и регламентированы.
Самый разумный шаг в подобном случае — поиск готового решения. Тогда вся работа сводится к сравнению предложений и более обстоятельному ознакомлению с «победителем» соревнования. Если бы все было так просто!
Поиск подходящего решения
Разумеется, MLOps‑команда Купера не первые, кто столкнулся с необходимостью выбора.
Готовых решений много, они прекрасны. Мы сравнили все, что присутствует на рынке — по разным критериям, обстоятельно. Пришли к неутешительному заключению: ни одно из исследованных нами решений не подходит — они или работают только за рубежом, или чреваты внезапным отказом.
Наша команда не верит в безвыходные ситуации и после долгих рассуждений решились: будем пробовать Feast.
Выбор Feast вполне оправдан. Основные причины в том, что выбранное хранилище признаков:
- имеет открытый исходный код;
- не является полноценной Data-платформой, а значит, не придется переделывать весь пайплайн;
- относительно легко интегрируется в устоявшиеся процессы;
- при необходимости позволит дорабатывать его самостоятельно.
Чтобы убедиться в правильности своего выбора и соответствии Feast требованиям, инженеры MLOps Купера начали с испытаний гипотезы в синтетических тестах. На локальной машине эмулировали нагрузку. Для хранения данных взяли Redis — резидентную СУБД, ориентированную на максимальную производительность при работе с «плоскими» данными. Хранилища признаков использовали только там, где без них было не обойтись. Redis, потребитель данных и серверы Feature Store находились в отдельных контейнерах с двумя CPU и 4 ГБ оперативной памяти. Все контейнеры запускались с помощью Docker Compose.
Вариантов работы с данными было немного. В самом простом случае потребитель обращается к Redis напрямую с помощью Feast SDK. В более сложном — работает с признаками через Feature Store Server, в качестве которого рассматривался Python Feature Server и Java Feature Sever.
Тестирование вариантов показало следующую взаимосвязь между количеством строк в запросе (ось X) и задержкой (ось Y). Линии на графиках отражают количество признаков в запросе: один (голубая), десять (зеленая) или сто (серая).
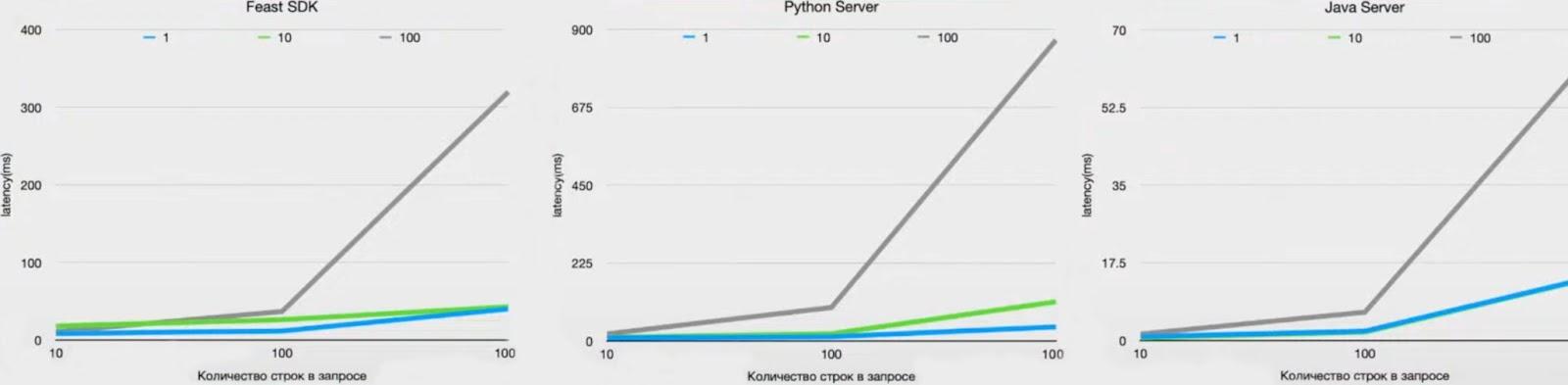
Отзывчивость Feast SDK не понравилась: 300 мс очень далеки от требуемых значений. Еще хуже, как ни странно, показал себя Python-сервер — он работает медленнее Feast SDK.
Инженеры предположили, что в коде нет серьезных ошибок — причина в скорости самого Python. Долго разбираться не стали и перешли на Java‑сервер, который также поставляется с Feast. С ним удалось получить искомые 50 мс для 100 признаков при обработке данных 1 000 пользователей. С такой производительностью хранилище можно внедрять.
Если вам интересна тема статьи, присоединяйтесь к нашему сообществу «MLечный путь» в Telegram. Там мы вместе обсуждаем проблемы и лучшие практики организации production ML-сервисов, а также делимся собственным опытом. А еще там раз в неделю выходят дайджесты по DataOps и MLOps.
Схема движения данных
Схема для работы с Feast была построена следующим образом.
- Описания признаков хранятся в GitLab как код — просто, понятно и соответствует рекомендациям того же Feast.
- CI/CD передает описание признаков в Registry, хранящемся на S3. На практике можно также использовать PostgreSQL.
- AirflowDAG по расписанию материализует признаки из S3 в Redis с помощью Bytewax и Spark — одних из немногих масштабируемых решений, которые предлагаются вне западных облаков.
- Конечные ML‑сервисы забирают признаки из Redis через Java Feature Store Server. Сервисы, для которых производительность не критична, работают напрямую с менее шустрым Feast SDK.
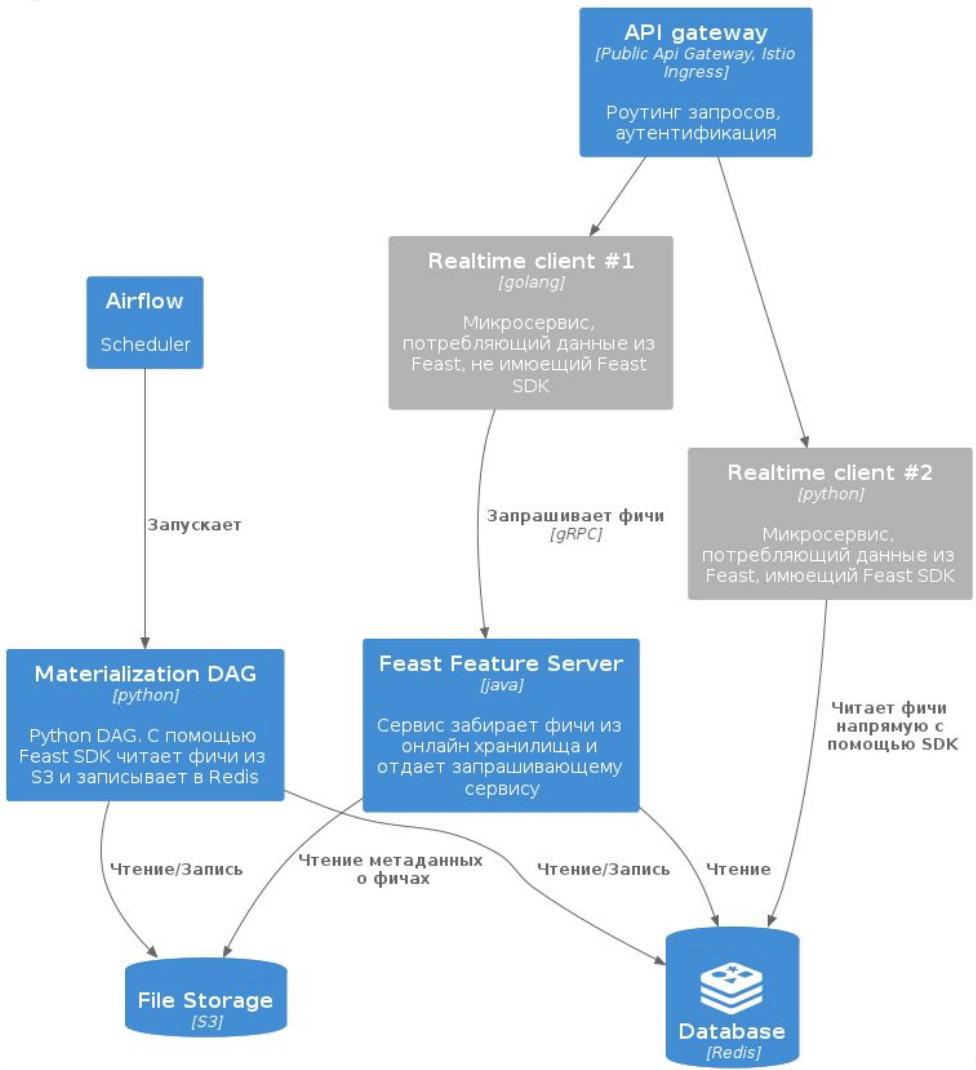
Получившуюся схему согласовали со специалистами по работе с большими данными и перешли к внедрению. Но, как это часто бывает, все пошло не так.
Угроза прекращения поддержки Feast
Едва начали трудиться над Feast, как его основной мейнтейнер Tecton отказался от дальнейшего сопровождения проекта. На какое-то время будущее Feast стало туманным.
Такой востребованный замысел, как Feast, обречен на успех. Ситуация оставалась неопределенной недолго. Через три месяца сформировалось сообщество энтузиастов, которые активно занялись дальнейшим развитием проекта под покровительством Linux Foundation.
Надо сказать, что возобновившаяся разработка Feast не выглядела такой уж беспроблемной. Новые мейнтейнеры представили первую версию плана дальнейшего развития, который внушал определенную тревогу. Сейчас можно с облегчением сказать, что опасения в значительной степени не подтвердились: с момента ухода Tecton появились уже две версии Feast.
Главный недостаток нового плана развития был в том, что он скорее походил на список желаний. Не обозначались сроки реализации той или иной функциональности. Не обсуждались пути достижения заявленных целей. Такая расплывчатость не позволяла сделать однозначные выводы о качестве, с которым будут воплощены предполагаемые решения.
Несмотря на все сомнения, команда «Купера» приняла риск. У нее достаточно знаний и необходимых ресурсов, чтобы дорабатывать Feast самостоятельно. Но они не предполагали, какого рода препятствия окажутся на этом пути.
Практически полное отсутствие документации
Материализация признаков, а именно загрузка их из S3 в Redis, не работает так, как заявлено в документации: возникают множественные ошибки, такие как отсутствие запрашиваемого ресурса и прочие. Попытки разобраться наталкиваются на то, что документация содержит совершенно неверную информацию, а указанные в документации примеры попросту не существуют.
Выяснение причин неработоспособности Feast привело к открытию трудностей более фундаментального характера. Все предлагаемые решения масштабируемые, но взаимодействуют только с западными облаками, для работы с которыми и создавались.
Привязка к проприетарным облачным сервисам
Те, у кого есть подписка на Google Snowflake или Amazon Red Shift вообще не заметят никаких сложностей — все заработает «из коробки». Всем остальным неизбежно придется дорабатывать Feast для совместимости с альтернативными облачными сервисами. За основу, скорее всего, придется брать Spark или другую подобную технологию. Главное, чтобы разработчикам она была хорошо известна.
В «Купере» так и сделали: адаптировали Spark так, чтобы использовать его с S3, а не Amazon. Но это было только начало.
Критические недостатки Java‑сервера
Java‑сервер позиционируется как «масштабируемое, высоконагруженное, готовое к промышленной эксплуатации» решение. Выяснилось, что это не совсем так. На слайде отражено примерное количество доработок, которые потребовалось привнести в код Java-сервера просто чтобы тот запустился.

Сверх того пришлось добавить поддержку сервера метрик, потому что Java Feature Server предоставлял очень мало отладочной информации. Во многих ситуациях было совершенно неясно, что происходит. Какая-либо система мониторинга также отсутствовала. Продуктивная работа при таких вводных невозможна, команде «Купера» пришлось совершенствовать и Java‑сервер.
Могло показаться, что привязанность к проприетарным облакам преодолена. Выяснилось, что не совсем.
Java‑сервер ориентирован на работу в Amazon Cloud. Если есть необходимость в использовании своего S3 — который живет в «Яндексе», Selectel или где‑то еще — нужно снова разбираться в исходном коде Java‑сервера и вносить изменения. В это трудно поверить, но Java‑сервер совершенно игнорирует переменные среды, которые отвечают за настройку доступа к S3.
Наконец, объемные работы по перепрограммированию Java‑сервера завершены, можно запускать тесты. Но снова неприятная неожиданность.
Трудности с производительностью
Итоговая производительность оказалась далека от той, что получилась в синтетических тестах. Расчет был на 50 мс для задержки при P99 (когда только для 1% запросов допускается выход за пределы ожидаемого значения). В действительности же величина задержки оказалась превышенной в 20 раз! Заметьте, замеры проводились при нагрузке всего 120 запросов в секунду.
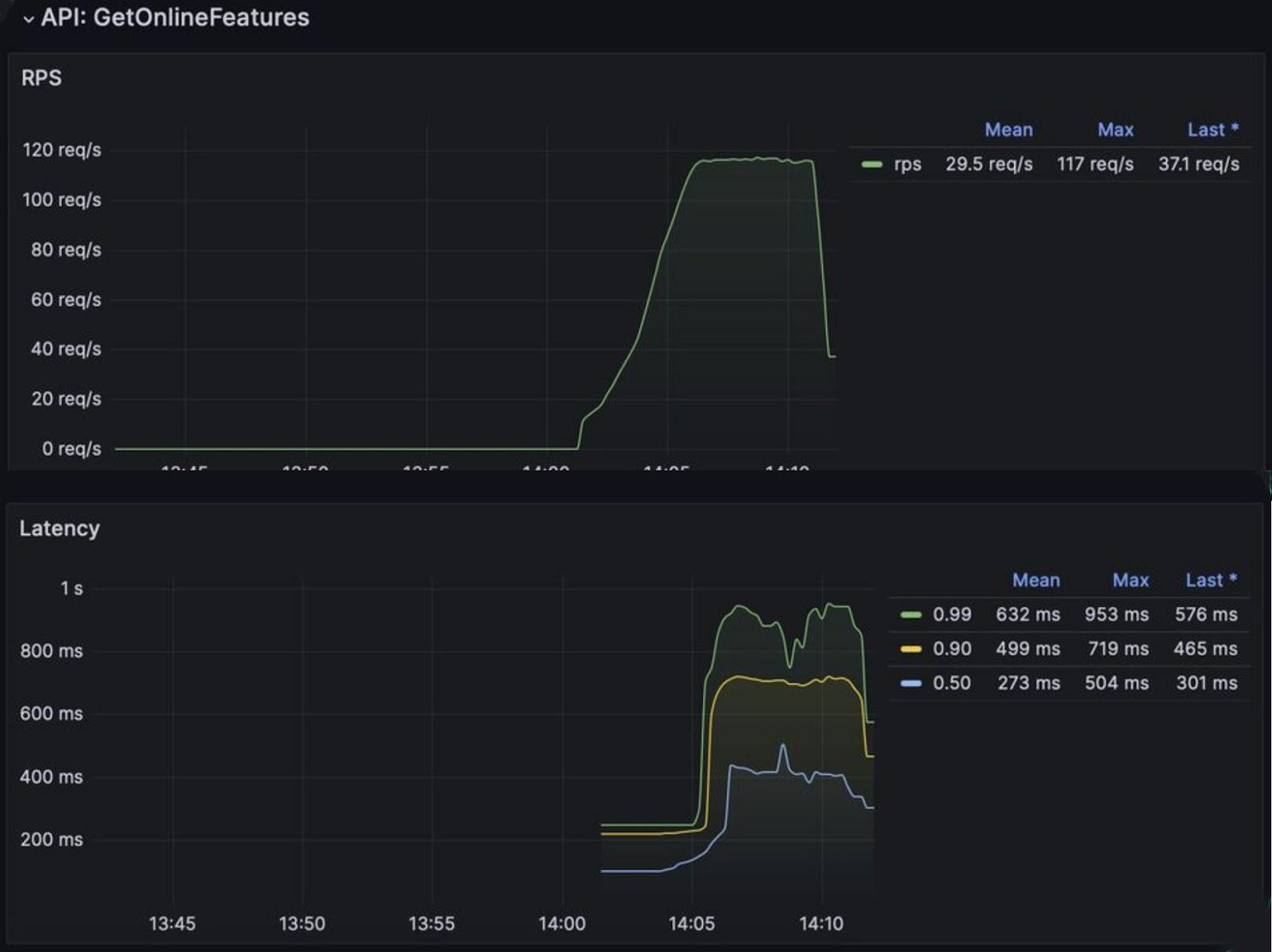
Впереди предстояла борьба за миллисекунды. Чтобы определить причину такого неудовлетворительного результата, потребовалось небольшое дополнительное исследование, которое и вывело на правильный путь. В качестве бэкенда использовался шардированный Redis.
Шардирование или шардинг — разбиение базы данных на части, каждая из которых размещается на отдельном узле внутри кластера, состоящего из одной или нескольких реплик. Такой архитектурный принцип позволяет легко производить горизонтальное масштабирование БД.
Выяснилось, что из‑за особенностей взаимодействия Feast с Redis много времени уходило на поиск хоста.
Оптимизировать в Java‑сервере обращения к Redis достаточно сложно — потребуется отдельный разработчик, который все свое время отдаст этой работе. Посвятить себя улучшению Java-сервера команда Купера не планировала, у нее другие задачи.
Поиск узких мест продолжился в потоках данных. Обнаружилось, что очень много времени уходит на сериализацию и десериализацию запросов. А вот здесь уже есть смысл заниматься поиском оптимизационного решения.
В испытательной схеме хранения данных на один признак приходился один ключ. Напрашивается вывод, что в условиях коммерческой эксплуатации такой подход себя не оправдает. Как правило, признаки используются совместно и объединяются в вектор, а потому правильнее опробовать схему, где сотня признаков передается совокупно, в едином массиве.
Быстрый синтетический тест показал десятикратный прирост производительности по сравнению с извлечением признаков поодиночке: 50 мс против 5−7 мс.
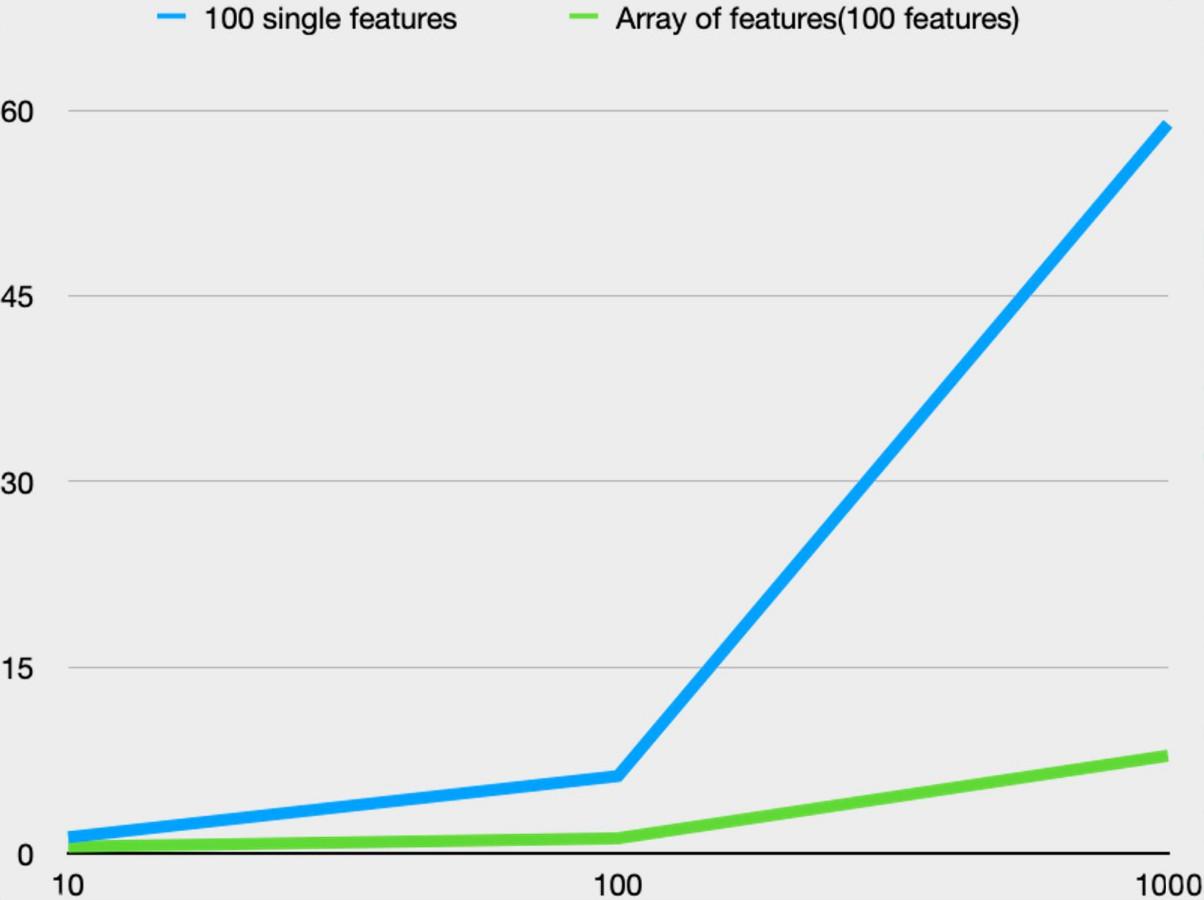
Улучшение существенное, но захотелось посмотреть, насколько результаты синтетических тестов будут соответствовать показателям в нагрузочном тестировании, приближенном к условиям эксплуатации.
Испытание не обрадовали: производительность возросла, но недостаточно. Задержка для P99 составила уже обнадеживающие 150 мс вместо первоначальных 1 000. Однако при 300 запросах в секунду по-прежнему не попадала в целевые значения.
MLOps Купера продолжили исследования и сосредоточились на поиске причин существенного расхождения между синтетическими тестами, на показания которых они опирались изначально, и реальным кейсом.
Загвоздка оказалась в том, что в синтетическом тесте обращение идет только к одной таблице. В действительности одной таблицей ограничиться невозможно. Если в нее собирать все признаки для разных сущностей, она займет слишком много места из‑за дублирования данных и лишних пустых значений.
Стала понятна причина недостаточной производительности: в одном запросе обращение осуществляется не ко всем таблицам с признаками одновременно, а по очереди. После проведения соответствующего теста, в котором обращение ко всем 14‑ти таблицам осуществлялась параллельно в разных запросах, удалось достичь приемлемой производительности.
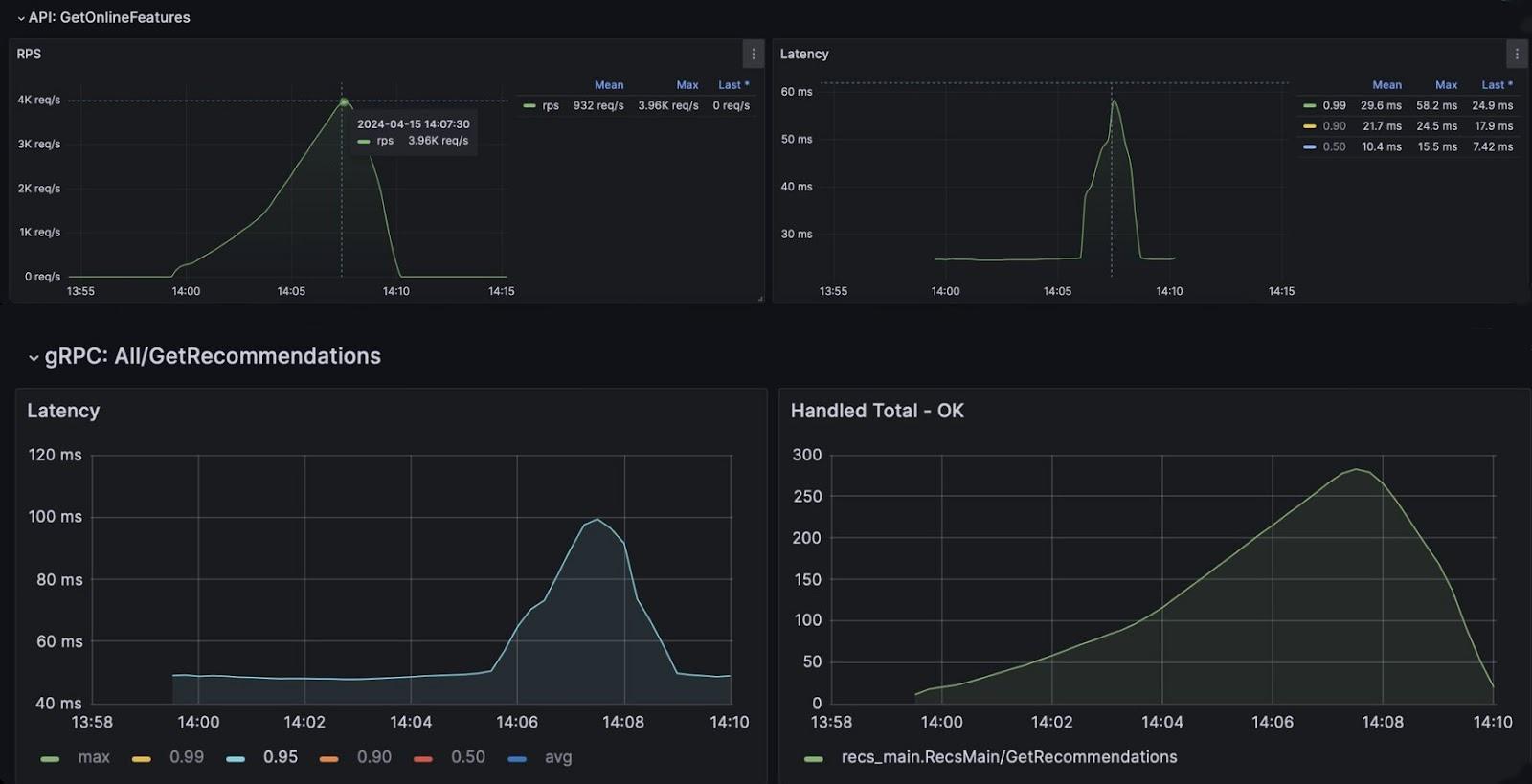
Допустимая нагрузка на Feature Store возросла с 300 до 4 000 запросов в секунду. Задержка составила не более 58 мс при достоверности P99. Для рекомендательной системы задержка стала не превышать 100 мс для P95 (в 95% случаев) и значительно возрастала только при нагрузке свыше 200 обращений в секунду.
Достигнутые показатели можно считать удовлетворительными, а значит, система готова к внедрению для коммерческого использования.
Выводы
Приходится признать — Feast на данный момент не является решением, готовым для production. Работать с инструментом можно, но тогда необходимо закладывать время и ресурсы на изучение его исходного кода, а также существенную доработку имеющейся функциональности. Кроме того, важно быть готовым к отсутствию документации приемлемого качества.
Резюмируя наш опыт и взвешивая все «за» и «против», допустимо сказать так: использовать Feast можно, но серебряной пулей для реализации Feature Store он, к сожалению, не является.
Несмотря на все найденные недостатки, его можно использовать как основу для создания собственной платформы. Опыт Купера показал, что Feast содержит очень много хорошо реализованных функциональных возможностей и нуждается лишь в относительно небольшом вмешательстве для адаптации к нестандартным техническим требованиям.





