Будущее серверной архитектуры


Привет! На связи Дима Шиченко, руководитель отдела разработки встроенных систем в Selectel. В истории развития и серверов, и настольных компьютеров материнская плата всегда оставалась центральным элементом. Именно она определяет не только совместимость компонентов, но и общую производительность, масштабируемость и энергоэффективность всей платформы.
Ее архитектура — не просто физическая основа для размещения процессора, памяти и подключения периферии. Это сложная логическая структура, на которой отразились эволюция вычислительных мощностей, технологические ограничения и требования рынка.
Разделение функций: северный и южный мост в классической архитектуре
На ранних этапах развития персональных компьютеров и серверов уровень интеграции полупроводниковых компонентов ограничивался технологическими возможностями производства. Процессоры того времени из-за технологических ограничений не могли вместить все необходимые контроллеры и интерфейсы.
На материнской плате приходилось предусматривать дополнительные микросхемы — чипсеты. Именно они обеспечивали взаимодействие между центральным вычислительным юнитом и остальными компонентами. Тогда и сформировалась классическая двухмостовая архитектура, которая на десятилетия определила развитие платформ x86.
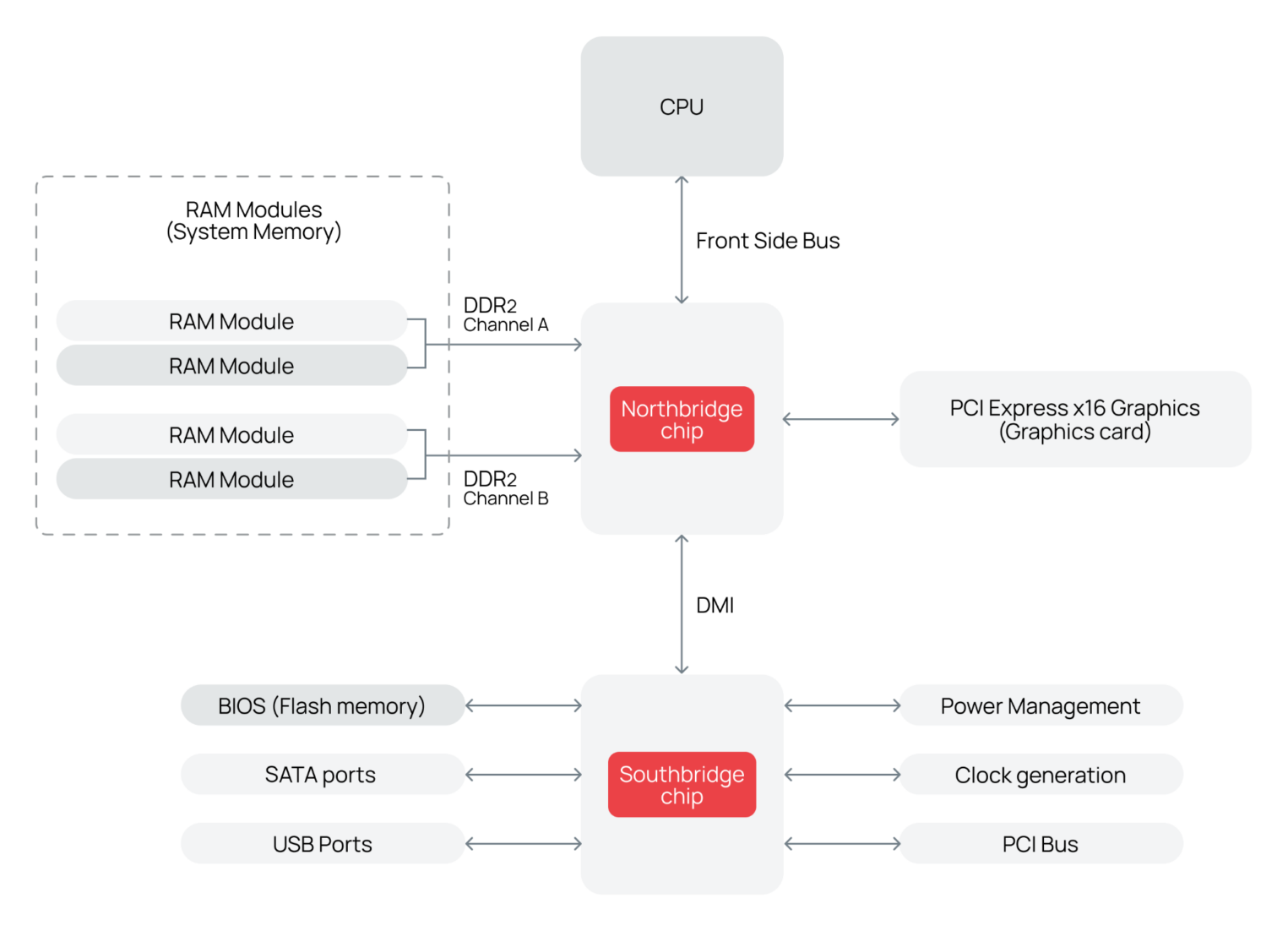
Северный мост (North Bridge) занимал на плате центральное положение, чтобы физически оказаться как можно ближе к процессору. Только так получится минимизировать задержки при обмене данными, ведь длина шины — критический параметр: чем она короче, тем меньше потери из‑за затухания сигнала и паразитных наводок, а значит, выше общая производительность. Северный мост же управляет самыми высокоскоростными подсистемами:
- контроллером памяти, который отвечает за обмен данными между CPU и DRAM;
- интерфейсом графического ускорителя, поддерживающим работу дискретных видеокарт через шины AGP или PCIe, а также управляющим встроенными графическими ядрами;
- высокоскоростными линиями PCIe — интерфейсом для подключения быстрых устройств, таких как SSD-накопители или сетевые адаптеры (в более поздних реализациях за распределение линий PCIe также отвечал северный мост).
За работу с высокочастотными сигналами северный мост часто называли, особенно в Intel, «контроллером памяти и графики» (Graphics and Memory Controller Hub, GMCH).
Южный мост (South Bridge), напротив, располагался на периферии платы и отвечал за управление низкоскоростными, но многочисленными интерфейсами ввода-вывода:
- SATA-контроллерами для подключения HDD и SSD;
- USB-портами различных поколений;
- Аудио- и сетевыми контроллерами;
- Управлением питанием, таймерами, RTC и другими вспомогательными функциями.
Такое разделение не было случайным, оно позволяло:
- оптимизировать трассировку печатной платы,
- соблюсти требования к целостности сигнала (signal integrity),
- минимизировать его потери и затухание.
Высокоскоростные пути от процессора к памяти и GPU требовали коротких дифференциальных пар. Низкоскоростные интерфейсы, напротив, допускали более длинные.
Дифференциальная пара — способ передачи высокоскоростных сигналов по двум близко расположенным проводникам. Сигналы идут одинаковой величины, но противоположной полярности — прямой и инверсной. Разность напряжений между ними и позволяет приемнику отфильтровывать помехи, а значит, повысить надежность и скорость передачи.
Путь к интеграции — исчезновение северного моста
С развитием полупроводниковых технологий — в частности, с переходом на техпроцессы 45 нм, 32 нм и далее — стало возможным размещать все больше функциональных блоков непосредственно внутри процессорного кристалла. Архитектура материнских плат начала необратимо меняться.
Первым крупным шагом стала интеграция контроллера памяти в ядро процессора. Опередив всех, эту концепцию внедрила AMD в архитектуре K8 (Athlon 64) еще в 2003 году. Ее примеру последовала и Intel, выпустив в 2008‑ом свою Nehalem. Прямое подключение CPU к RAM резко сократило задержки доступа, повысило пропускную способность и упростило топологию платы.
Следующим этапом была интеграция графического ядра iGPU непосредственно в кристалл CPU. В серверных архитектурах приоритет отдан плотности вычислений и пропускной способности памяти. Дискретная же графика долгое время оставалась избыточной и требовалась лишь для вывода в консоль. Интеграция iGPU позволила отказаться от дискретных видеокарт в базовых конфигурациях, что снизило и стоимость, и энергопотребление.
Особенно важно — внутрь процессора перешло управление PCIe‑линиями для подключения видеокарт, NVMe-накопителей и высокоскоростных сетевых контроллеров. Остальные, менее приоритетные линии, по‑прежнему маршрутизируются через единственный чипсет — PCH (Platform Controller Hub), ставший преемником южного моста и реализующий интерфейсы ввода‑вывода — SATA, USB, BIOS и другие. PCIe и PCH соединяются друг с другом DMI‑шиной (Direct Media Interface) у Intel и IFL (Infinity Fabric Link) у AMD.
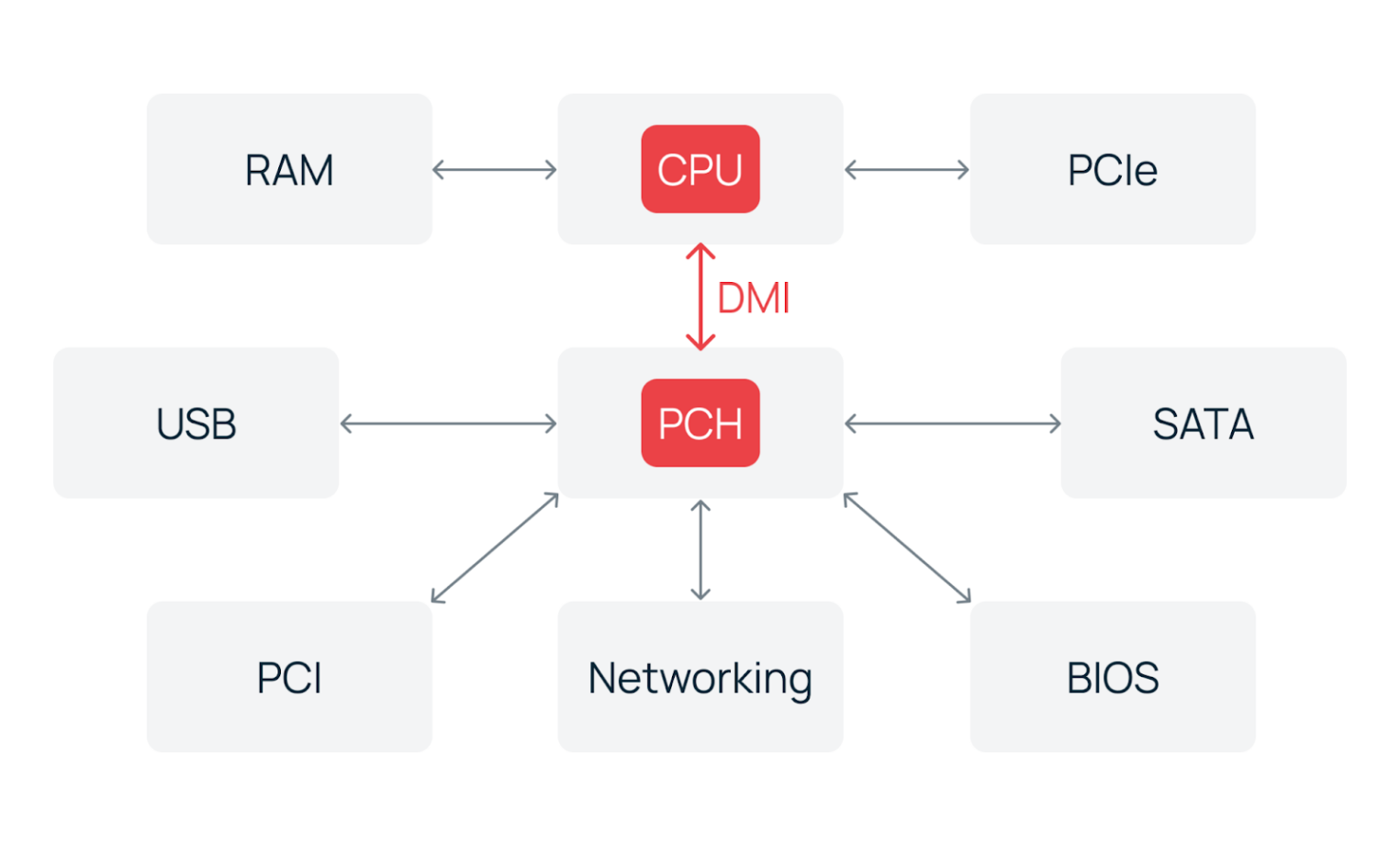
В результате всех изменений северный мост исчез полностью. На платформах Intel, начиная с поколения Sandy Bridge 2011 года, он целиком интегрирован в процессор. У AMD аналогичный переход произошел с архитектурой ZEN в 2017‑ом. В серверных сегментах двухчиповые компоновки сохранялись дольше — в силу требований к количеству линий PCIe и поддержке многопроцессорных конфигураций.
Тем не менее, логическое разделение функций сохранилось. Даже в современных процессорах можно обособить «северную» часть (ядра, кэш, контроллеры памяти, PCIe) и «южную» (интерфейсы ввода-вывода, управляемые чипсетом по высокоскоростному DMI или IFL).
Серверные материнские платы эволюция изменила радикально:
- упростилась топология — меньше чипов, меньше слоев PCB, снижение стоимости, повышение надежности;
- снизились задержки и энергопотребление — прямое подключение памяти и PCIe-устройств к CPU устраняет промежуточные звенья;
- централизовалось управление — чипсет превратился в «южный хаб», обеспечивающий подключение периферии, но уже не участвующий в критических путях данных.
CPU‑центричная система
В начале 2026 года вышли новейшие поколения серверных процессоров — Intel® Xeon® 6 (Granite Rapids и Sierra Forest) и AMD EPYC™ 9005 (Turin). С их появлением состоялся окончательный переход к парадигме, в которой PCH и аналоги утратили статус обязательного компонента материнской платы. Мы наблюдаем логическое завершение многолетнего пути интеграции, которое началось с исчезновения северного моста.
Подходы Intel и AMD различны в деталях, но приводят к единому результату. Вся критическая логика управления потоками данных теперь сосредоточена непосредственно в процессорном модуле.
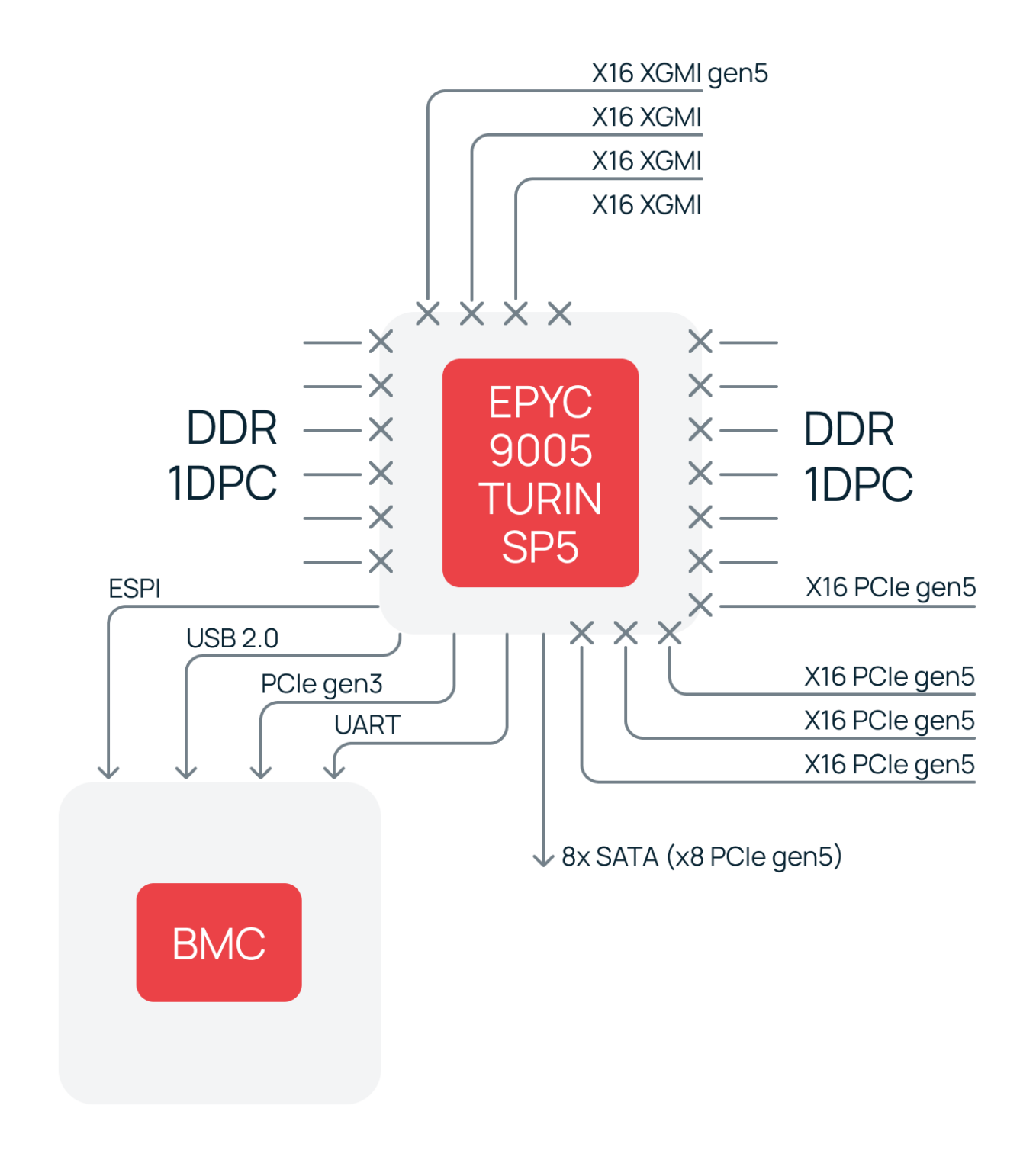
AMD подготовила фундамент для такой архитектуры заранее. Начиная с поколения Zen 2 (EPYC™ Rome) они оказались от классического внешнего чипсета. Вместо него интегрировали все функции южного моста в специализированный кристалл I/O Die внутри многочипового модуля MCM.
Во флагманском EPYC™ 9005 (Turin) эта концепция получила наивысшее развитие. Центральный I/O Die обеспечивает до 12 каналов памяти DDR5‑6400 и 128 линий PCIe 5.0 с потенциалом до 160 в двухпроцессорных системах. Кроме того, сохраняется встроенная поддержка таких интерфейсов, как SATA и CXL 2.0.
Получается, что для большинства серверных конфигураций внешний чипсет становится избыточным. Он теперь нужен лишь для увеличения количества портов, но не для базовой функциональности.
По такому принципу и мы разрабатывали наши серверные платформы нового поколения с процессором EPYC™ 9005. Ниже — функциональная схема материнской платы Selectel. Все критические ресурсы — память, расширение, сетевые интерфейсы — подключаются напрямую к процессору через его встроенные контроллеры.
В Intel действовали не менее решительно. В предыдущих поколениях, включая 4th Gen Xeon Scalable (Emerald Rapids), все еще использовался чипсет Emmitsburg PCH (Intel® C740 Series Chipsets). Однако с 5th Gen Intel® Xeon® Scalable и более нового Xeon 6 прогресс становится радикальнее.
Управление всеми ключевыми высокоскоростными подсистемами, такими как памятью и PCIe, интегрируется напрямую в кристалл. Второстепенные низкоскоростные интерфейсы — USB, SATA или Ethernet — могут иметь дискретные контроллеры на материнской плате. Однако их физический транспортный уровень — не что иное, как PCIe! Получается, что даже периферийные устройства логически подключены к CPU, а не к отдельному хабу ввода-вывода.
Такую концепцию видно и на примере нашей первой разработки — сервера Selectel на Intel® Xeon® 6. В частности, интерфейсы SAS и SATA реализованы отдельными контроллерами и соединены с процессором Gen 5 шиной PCIe. Также для USB и Ethernet на материнской плате предусмотрены дискретные контроллеры без привлечения северного моста.
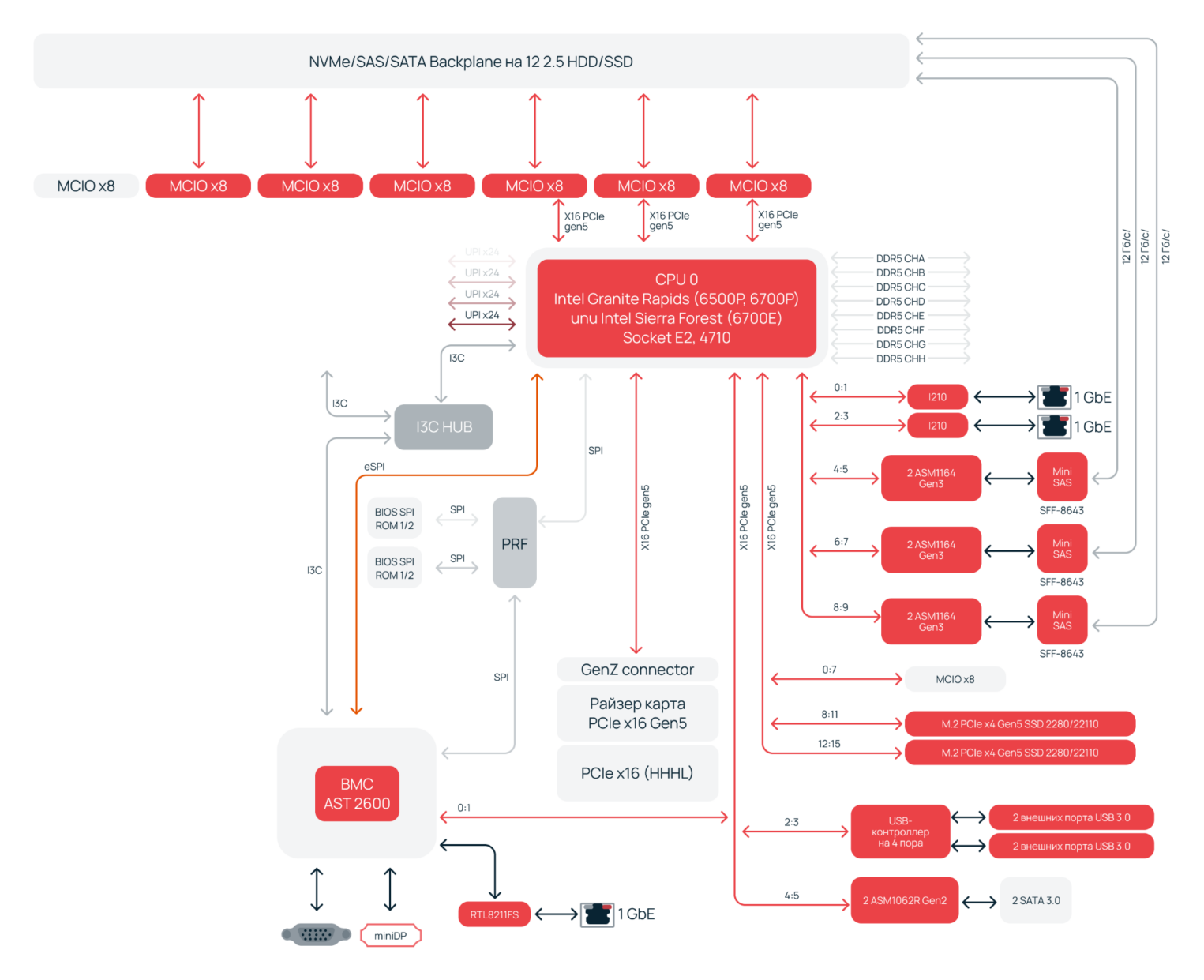
В итоге некогда сложная иерархическая структура, основанная на взаимодействии CPU, северного и южного мостов, свелась к минималистичной топологии. Есть процессор, его непосредственные связи с оперативной памятью и PCIe-устройствами, а также контроллер управления BMC. Материнская плата из активного участника обработки данных превратилась в высокоскоростную, но пассивную коммутационную среду. Ее роль теперь — передача сигналов и питание мощных, под 300−500 Вт, процессоров.
Фундаментальный сдвиг в архитектуре не только радикально упростил проектирование и снизил стоимость производства. Открылся путь к созданию еще более быстрых и энергоэффективных серверов, с плотной расстановкой компонентов. Такие требования критически важны для современных дата-центров с ориентацией на ИИ, облачные вычисления и высокопроизводительные задачи.
Эволюция, начавшаяся с разделения функций между мостами, завершилась их полным растворением в самом сердце вычислительной системы.
Будущее за дезагрегацией — модульными серверами и масштабируемой архитектурой
Эволюция материнской платы в начале XXI века пока идет по пути объединения функций в процессоре. Однако следующий этап — их целенаправленное вынесение за его пределы, но уже на ином технологическом уровне.
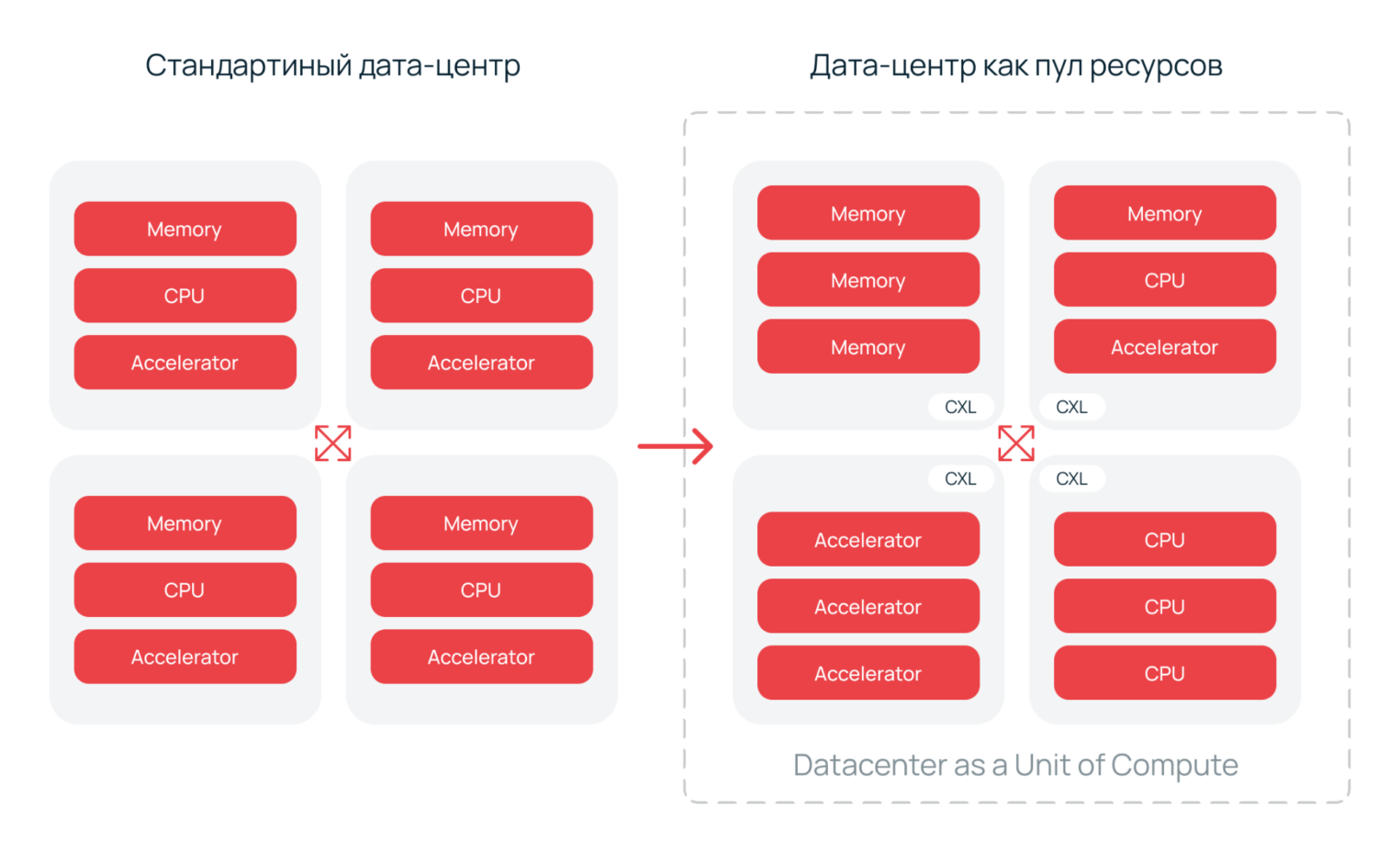
Концепция будущего сервера — не привязываться ни к физической плате, ни даже к единому корпусу. Вместо этого формируется динамическая, гибкая «вычислительная стена», в которой все ресурсы — процессоры, память, хранилище, ускорители — объединяются по принципу «plug-and-compute» с помощью высокоскоростных интерконнектов. Появляется возможность создавать пулы вычислительных мощностей, которые будут функционировать как целостный массив с параллельной обработкой данных.
Эта парадигма получила название Resource Disaggregation — разъединение ресурсов. Предполагается полный пересмотр роли материнской платы. Она перестает быть статичной основой для фиксированного набора компонентов, а превращается в универсальный коммутационный хаб, способный адаптироваться под меняющиеся рабочие нагрузки.
Блочная сборка суперкомпьютера
Сервер будущего будет собираться из «кирпичиков», как стена. Базовое шасси предоставит питание, охлаждение и магистральную коммутацию. Остальные ресурсы будут подключаться в виде отдельных блоков:
- вычислительных — CPU, GPU, FPGA;
- памяти — оперативной и постоянной;
- хранилища — NVMe SSD, SAS/SATA SSD, HDD;
- сетевой инфраструктуры — SmartNIC, DPU.
Все компоненты будут взаимодействовать через единый высокоскоростной интерфейс.
Какой? Пока не ясно.
Один из главных претендентов — Compute Express Link (CXL), протокол, обеспечивающий межкомпонентное соединение (interconnect) на уровне транзакций кэша и памяти. Его ключевая черта — высокая пропускная способность еи совместное адресное пространство (когерентность данных). Другими словами, CXL позволяет и процессору, и графическому ускорителю с минимальными задержками взаимодействовать с памятью за пределами собственной серверной стойки.
Наш сервер Selectel использует самые новые процессоры Xeon® 6 и уже поддерживает CXL 1.2 и 2.0. Технологию мы активно тестируем. Если вы хотите присоединиться к эксперименту, оставьте заявку на сайте.
На сегодняшний день развитие интерконнекта напоминает технологическое ралли. На сцену одновременно вышли несколько протоколов — каждый со своей философией и областью применения. Все они — CXL, UCIe, CCIX, Infinity Fabric — отвечают на один и тот же фундаментальный вызов современных вычислений. Однако пути их реализации принципиально различаются. Вопрос же звучит так: «Как преодолеть границы монолитного кристалла и превратить жестко связанные компоненты в динамически управляемые ресурсные пулы?»
Некоторые протоколы, такие как UCIe, действуют на микроуровне — внутри упаковки, связывая чиплеты на общей подложке. Они как бы растворяют границы самого процессора, превращая его из монолита в конгломерат специализированных кристаллов, объединенных когерентной шиной.
Другие, как CXL или CCIX, работают на макроуровне. Их стихия — серверная плата, стойка, а в перспективе — целый дата-центр. Именно они позволяют процессору «выглянуть» за пределы своего корпуса и адресовать память или ускоритель, физически расположенный в соседнем блоке, сохраняя при этом когерентность и низкую задержку.
Infinity Fabric от AMD занимает промежуточную нишу, обеспечивая масштабируемость от многочиповых модулей до многопроцессорных серверов.
Однако переход к дезагрегированной архитектуре сталкивается с рядом фундаментальных ограничений. Их корни — в физических и конструктивных особенностях существующих интерконнектов. Основа экосистемы CXL — шина PCIe. Та изначально не предназначалась для когерентного доступа к удаленным ресурсам. Ее последовательная природа накладывает три критических ограничения.
1. Латентность транзакций проявляется при работе с удаленными вычислительными пулами. Запуск задачи на процессоре или ускорителе за пределами локального узла требует не просто обмена данными, но и синхронизации: состояния кэшей, обработки прерываний и возврата результатов. Совокупная задержка легко превышает 5−10 мкс, что делает такой подход неприменимым для короткоживущих, низколатентных транзакций.
Эффективное использование удаленных вычислительных ресурсов становится возможным лишь при пакетной обработке или длительных задачах. В таких случаях накладные расходы на коммуникацию амортизируются объемом полезной работы.
2. Дальность передачи уменьшается из‑за физических ограничений среды. Высокоскоростные сериализаторы PCIe Gen5/6 (32 GT/s) подвержены критическому затуханию на пассивных медных трассах — свыше 25 дБ/м на частотах более 16 ГГц. В типовых реализациях без дополнительного усиления расстояние между узлами сокращается до 30−50 см. Преодоление барьера требует внедрения активных медных кабелей (ACC) или оптических трансиверов (AOC). Однако такие решения увеличивают энергопотребление на 3−5 Вт на линк и вносят дополнительные 20−50 нс латентности на этапе ретрансляции.
3. Масштабируемость когерентности — еще один критический барьер. Алгоритмы поддержания кэш-когерентности, такие как MESI, экспоненциально усложняются при расширении пула памяти. В топологиях «звезда» или «фат-три» (fat-tree) узкими местами становятся коммутаторы CXL — их буферы и таблицы трансляции адресов (TLB) ограничивает число одновременных транзакций. Дополнительную нагрузку создает рассылка сигналов инвалидации кэша — этот фоновый трафик поглощает полезную пропускную способность канала.
Итак. Текущие ограничения диктуют стратегию иерархической дезагрегации интерконнектов. На микроуровне протоколы вроде UCIe минимизируют латентность внутри упаковки. Задержка при установке соединения между чиплетами — не более 10 нс. При этом они формируют «когерентный остров» высокопроизводительных ресурсов. На макроуровне CXL и его наследники, включая концепцию CXL over optical fabric, обеспечивают эффективное объединение стоек, не претендуя на сверхнизкую латентность.
Такой подход подтверждает отсутствие универсального протокола для всех элементов системы — от кристалла до дата-центра. Будущее за многослойной архитектурой: каждый уровень интерконнекта оптимизирован под свой масштаб, а управление ресурсами перенесено в программную плоскость, которая скрывает физические компромиссы за абстракцией единой вычислительной среды.
Процессор как сменный модуль
Ключевой элемент концепции — сменный вычислительный модуль. Представьте материнскую плату с унифицированным разъемом или интерпоузером, совместимым с разными поколениями CPU и даже производителями. Такая кросс-платформенность достижима через зонную стандартизацию выводов: выделенные области сокета будут отвечать за конкретные функции — I/O (PCIe), DRAM, Power Management и другие.
Сразу же получаем несколько преимуществ:
- продление жизненного цикла — модернизация вычислительного ядра не потребует замены всей платы;
- гибкость конфигурации — возможность подбора CPU под конкретную нагрузку: от энергоэффективных моделей для фоновых процессов до многоядерных решений для HPC;
- оптимизация эксплуатации — упрощается ремонт и обслуживание в дата-центрах благодаря быстрой замене вычислительного узла.
Такие модули объединят в себе не только процессор, но и встроенные контроллеры памяти, PCIe и CXL, превращаясь в полностью независимые вычислительные единицы.
Selectel Server — это продукт, который должен не только соответствовать требованиям современного рынка, но и быть гибким в отношении потребностей клиентов. Поэтому недавно мы объявили о расширении линейки серверных решений и представили плату на базе AMD EPYC™ 9005 Turin.
Память и хранилище как сервис
Протоколы CXL.mem и CXL.io в стандарте CXL 2.0+ меняют архитектуру. Память и накопители больше не привязаны к конкретному CPU. Вместо жесткой сцепки компонентов создаются гибкие пулы ресурсов.
- Memory Pooling — несколько серверов совместно используют общий массив DRAM. Емкость динамически распределяется между виртуальными машинами или контейнерами, исключая простой и фрагментацию памяти.
- Storage Class Memory over Fabric — сверхбыстрые энергонезависимые накопители подключаются к шине памяти напрямую. Грань между RAM и хранилищем стирается. Открывается путь к новым моделям данных — например, In-memory DB с мгновенным восстановлением после сбоев.
Эти протоколы гарантируют три важных особенности.
- Кэш-когерентность — данные в удаленной памяти синхронизируются с кэшами процессоров автоматически. Исчезает необходимость программно управлять согласованностью.
- Допустимую латентность — задержки при обращении к пулу выше, чем к локальной DRAM, но ограничиваются сотней наносекунд. Для большинства прикладных задач (application layer) такая разница остается незаметной. Производительность обычно упирается во внутреннюю логику, сериализацию данных или сетевой стек. Переход к пулам памяти не вызывает значительной деградации скорости, при этом радикально повышается гибкость системы.
- Масштабируемость — такая архитектура позволяет практически безгранично наращивать объем памяти. Для пула можно выбирать модули с оптимальным балансом цены и плотности — от RDIMM до специализированных CXL-решений на базе LPDDR5X или энергоэффективной DDR5. Подобная гибкость особенно актуальна в условиях нестабильного рынка компонентов и растущего давления на TCO (Total Cost of Ownership) — вместо дорогой высокочастотной памяти в каждом узле разворачивается единый эффективный пул, разделяемый между несколькими вычислительными блоками.
- Прозрачность для ОС и приложений — современные гипервизоры и ядра операционных систем, например Linux с CXL 3.0, видят пул как обычный NUMA-узел или расширение локальной памяти. Изменения в коде приложений не требуются — значит внедрять технологию в существующую инфраструктуру можно уже сейчас.
Такая архитектура превращает серверную стойку в масштабируемый суперкомпьютер с динамическим распределением ресурсов — своего рода «железное облако». Дата-центр начинает функционировать как единый вычислительный организм.
- Гибкое расширение VM может запросить 1 ТБ RAM, даже если локальный узел ограничен 512 ГБ — недостающий объем будет выделен из общего пула в соседней стойке.
- Аналитика In-memory и системы реального времени обрабатывают гигантские датасеты целиком в памяти — при этом исключается деградация производительности из-за свопинга на диск.
- Обучение нейросетей требует колоссальных объемов памяти для хранения весов и активаций — система динамически выделяет ресурсы под эти задачи, заимствуя их у менее нагруженных узлов.
Эволюция архитектуры серверных плат — не просто хронология изменения компоновки чипов на ограниченной площади. Она отражает не только прогресс в электронике, но и фундаментальный сдвиг в самой природе вычислений. Происходит переход от жестко связанных монолитных систем к гибким, программно-определяемым и ресурсно-эффективным инфраструктурам.
Материнская плата как точка коммутации
Трансформация архитектуры — это не финал, а переход к новому этапу. С развитием CXL и концепции дезагрегации ресурсов классическая материнская плата исчезает. Сервер перестает быть ограничен рамками одного шасси. Процессоры, память и хранилище превращаются в независимые, но логически связанные ресурсы, формирующие динамическую вычислительную среду.
Memory pooling, процессоры в формате модулей hot-swap и блочная сборка «суперсерверов» — все подтверждают отказ от аппаратной статики в пользу программной гибкости. Мы также отталкиваемся от этих принципов при разработке наших программно-аппаратных продуктов.
Не просто наблюдаем за эволюцией индустрии, а проектируем собственные серверы, исходя из этой философии. В основе — три принципа: модульность, универсальность и полный цикл разработки. Так получается создавать платформы, где каждый компонент — от корпуса и бэкплейна до системы охлаждения — оптимизирован под конкретные задачи. С одной стороны, исчезает зависимость от жестких рамок готовых вендорских решений, с другой — появляется возможность гибко адаптировать «железо» под меняющиеся стандарты дезагрегации.

Разработка собственных материнских плат и сопутствующей инфраструктуры дает нам прямой контроль над топологией системы. Появляется гарантия максимальной эффективности передачи сигналов и реализуется поддержка новейших интерфейсов, таких как CXL, сразу после их появления. В результате наши клиенты получают серверы, которые изначально готовы к работе в концепции «вычислительного организма», где ресурсы масштабируются динамически и без лишних издержек.
Будущее серверной материнской платы — не в усложнении, а в «растворении». Она перестает быть центром системы и превращается в часть распределенной инфраструктуры, где границы между компонентами стираются, а эффективность определяет интеллект управления ресурсами. В этой реальности ключевую роль играет архитектура как сервис — именно она сформирует облик вычислительных систем следующего поколения, у которого будут измеримые преимущества:
- снижение TCO на 30−40% благодаря отказу от избыточного резервирования,
- мгновенное масштабирование ресурсов без остановки критически важных сервисов,
- минимальное время обслуживания за счет модульной замены компонентов,
- динамическое перераспределение мощностей между рабочими нагрузками в режиме реального времени.
Наши решения, спроектированные под стандарты дезагрегации (disaggregation) и управляемые единой программной платформой, подтверждают: переход от теории к практике происходит уже сейчас.





