

Специализированные процессоры ASIC для конкретных областей — один из способов «перезапустить» закон Мура и преодолеть ограничения универсальных CPU общего назначения. Сейчас это очень перспективная область развития микроэлектроники.
Собственные проекты есть у Google, Amazon и других компаний. Например, Google выпускает тензорные процессоры Google TPU, а в дата-центрах Amazon работают чипы AWS Graviton на ядре ARM.
Первые представляют собой ASIC для нейронных сетей, вторые — 64-битные ARM общего назначения для оптимизации соотношения цены и производительности в рабочих нагрузках, требующих больших вычислительных ресурсов.
Еще один класс универсальных ASIC, где в последнее время идут активные эксперименты, — это специализированные сопроцессоры для обработки данных (data processing unit, DPU), разновидность умных сетевых карт (SmartNIC). Вот некоторые представители этого вида: Nvidia BlueField 2, Fungible и Pensando DSC-25.
Что они из себя представляют? Для каких задач подходят? Давайте посмотрим.
Что такое SmartNIC
Обычные сетевые карты (NIC) построены на интегральной схеме специального назначения (ASIC), которая спроектирована на работу Ethernet-контроллером. Часто эти микросхемы проектируют для выполнения вторичных функций. Например, контроллеры Mellanox ConnectX также поддерживают высокоскоростной протокол Infiniband. Это отличные специализированные чипы, но их функциональность нельзя изменить.
В отличие от простых сетевых карт, SmartNIC допускает загрузку в контроллер дополнительного программного обеспечения уже самим пользователем, то есть после покупки аппаратного обеспечения. Это расширяет или изменяет функциональность ASIC. Процедура чем-то похожа на покупку смартфона и установку на него различных приложений.
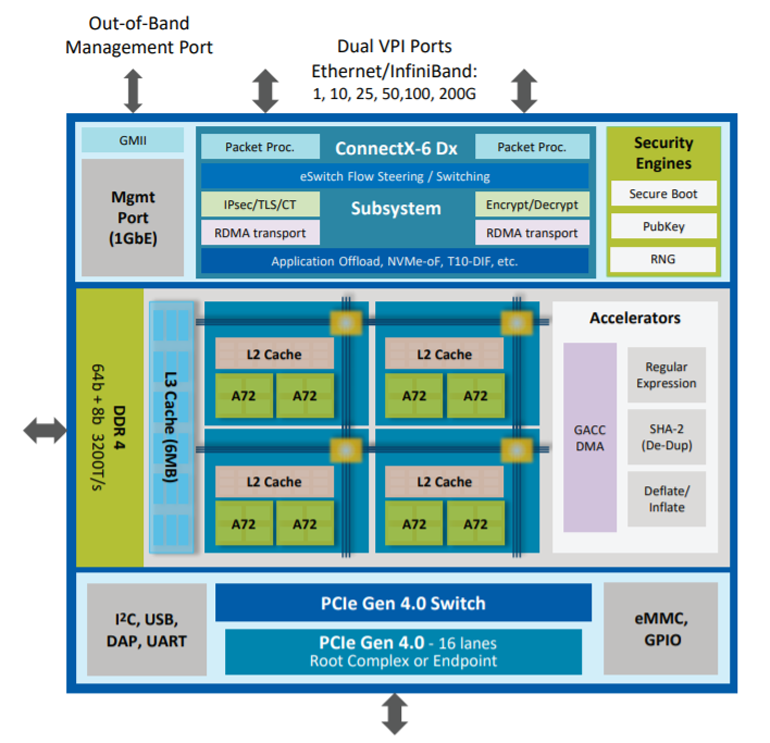
Чтобы такое стало возможным, SmartNIC требует повышенной вычислительной мощности и дополнительной памяти, по сравнению с обычными NIC. Речь идет о более мощных многоядерных ARM-процессорах, установке специализированных сетевых процессоров (flow processing cores, FPC) и программируемых пользователем вентильных матриц (FPGA).
На платах SmartNIC зачастую выделяют отдельное ядро ARM для уровня управления, некоторые платы допускают загрузку модифицированного ядра Linux. Эти специализированные ядра ARM распределяют нагрузку по остальным вычислительным модулям, собирают статистику и логи, отслеживают состояние SmartNIC. Непосредственно сетевой трафик через них не проходит.
Для каких задач подходят DPU
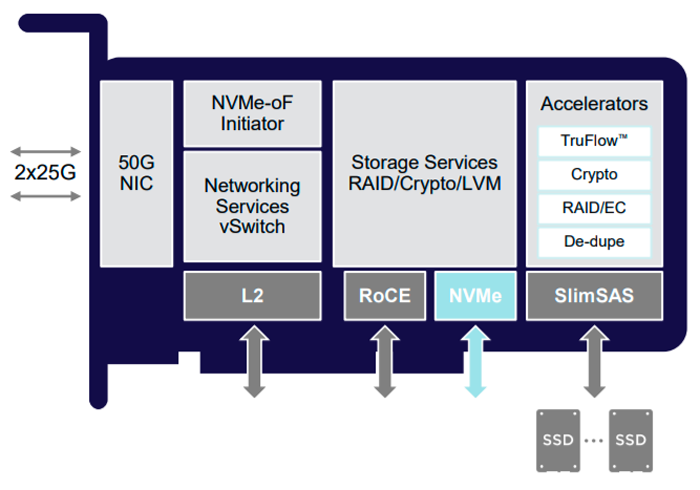
Сопроцессоры для обработки данных (DPU) — типичное расширение сетевых плат SmartNIC, к которым добавляют функциональность NVMe или NVMe over Fabrics (NVMe-oF). Такая плата позволяет разгрузить центральный процессор, забрав себе все задачи ввода-вывода.
Для примера можно рассмотреть устройство SmartNIC микроконтроллера Broadcom NetXtreme-S BCM58800. Он работает как программируемая сетевая карта и поддерживает (NVMe-oF).
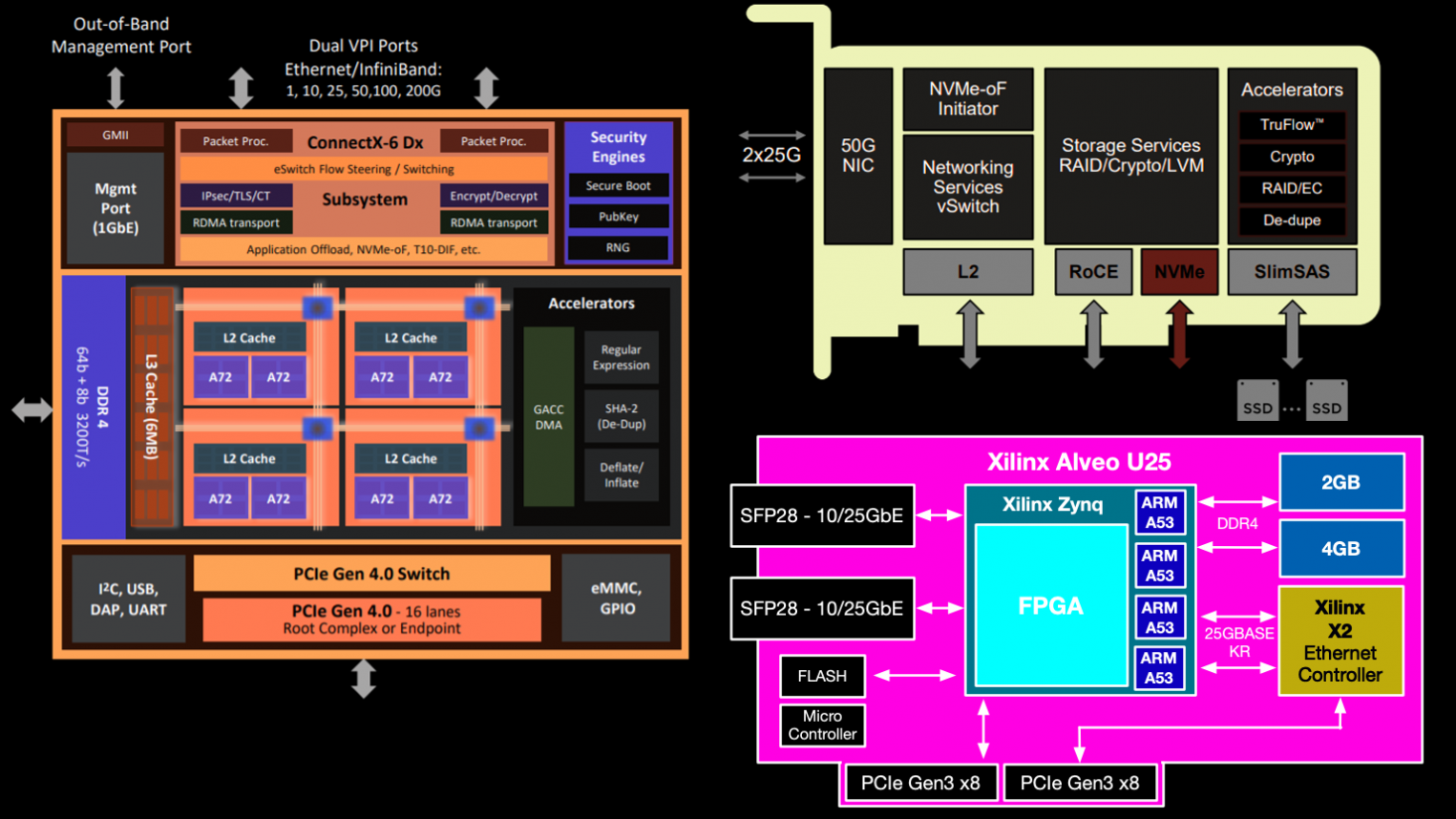
Архитектура карты Broadcom Stingray на базе микроконтроллера BCM58800
В Broadcom Stingray установлено восемь ядер ARM v8 A72 на частоте 3 ГГц, и это, возможно, самая высокая тактовая частота среди ARM на любых SmartNIC. Сетевая карта комплектуется до 16 ГБ памяти DDR4. На аппаратном уровне поддерживается шифрование на скорости до 90 Гбит/с и некоторые функции по обработке данных: дедупликация, удаляющее кодирование RAID 5 и RAID 6.
На схеме также отмечен ускоритель TruFlow. Это патентованная технология Broadcom для аппаратного ускорения сетевых операций, в том числе операций программного коммутатора Open vSwitch (OvS) и др.
Nvidia BlueField 2
Nvidia традиционно специализируется на производстве графических ускорителей, но в этом году она завершила покупку разработчика специализированных микросхем Mellanox за $7 млрд, так что теперь всерьез нацеливается на новую для себя сферу — рынок высокопроизводительных вычислений в ЦОД.
Mellanox — один из первопроходцев в разработке умных сетевых карт, и ведущим продуктом сейчас считается плата BlueField 2, которая позиционируется как Data Processing Unit (DPU).
Ключевые приложения DPU:
- Виртуальные и аппаратные облачные среды.
- Хранилища NVMe в виртуальных машинах.
- Приложения Network Function Virtualization (NFV).
- Приложения ИБ, такие как Deep Packet Inspection (DPI).
- Микросерверы для граничных вычислений.

Здесь реализован массив из восьми ядер ARM v8 A72, контроллер памяти DDR4 и двухпортовый сетевой адаптер Ethernet или InfiniBand (два на 100 Гбит/с или один 200 Гбит/с), плюс специализированные ASIC-блоки для ускорения различных функций: регулярных выражений, хэширования SHA-2 и др.
Pensando
Один из новых стартапов в области SmartNIC — компания Pensando, которая предлагает на рынке так называемые Distributed Services Card, это Pensando DSC-25 (для корпоративных серверов) и Pensando DSC-100 (для облачных провайдеров).

Основным продуктом считается Pensando DSC-25. Это карта с одним DPU-процессором P4 (Capri) для обработки данных, дополнительными ARM-ядрами и аппаратными ускорителями отдельных функций.
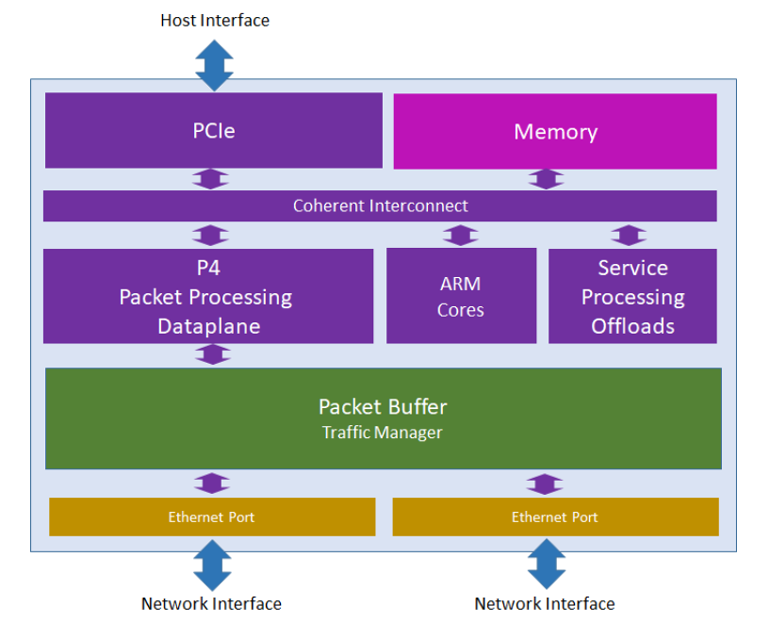
Основной процессор DPU и ARM-ядра через общую шину межсоединения подключены к контроллеру PCIe и массиву оперативной памяти (до 4 ГБ).
Отдельные аппаратные ускорители здесь называются Service Processing Offloads. Как и в карте Mellanox, они берут на себя шифрование, обработку дисковых операций и другие задачи.
Fungible
Еще один многообещающий стартап Fungible утверждает, что это именно он изобрел термин DPU в 2016 году. Компания заявляет о выпуске процессоров под названием F1 DPU, но фактическая архитектура этих чипов неизвестна. Fungible пока может продемонстрировать только общие схемы, как на иллюстрации выше.
Некоторые специалисты высказывают подозрение, что Fungible просто использует хайповый термин DPU для привлечения венчурных инвестиций. Кстати, на различных раундах в нее уже вложено $500 млн.
Что дальше?
Вокруг концепции DPU в последнее время много хайпа. В этом обзоре упомянуты не все компании, которые пытаются выйти на этот рынок (Intel, Xilinx и другие).
Факт в том, что концепция SmartNIC появилась уже давно, а крупные компании вроде Google и Amazon разработали и внедрили собственные внутренние решения. В то же время был сформирован рынок, который заполнили сторонние игроки.
Сейчас появляется второе поколение SmartNIC на основе FPGA. Технология программируемых пользователем вентильных матриц созрела до такой степени, что теперь может стать основополагающей технологией для SmartNIC. Десять лет назад рынок буквально наводнили графические ускорители — это была первая значительная волна в технологиях аппаратного ускорения.
Теперь, когда FPGA преодолели рубеж в три миллиона логических блоков, эти микросхемы тесно интегрируются с другими составными блоками для обработки сетевого трафика, памятью, системой хранения и вычислительными ядрами. Технологии SmartNIC и FPGA отлично дополняют друг друга.
На этом фоне можно ожидать вторую волну аппаратных ускорителей. И тогда к комплекту CPU + GPU добавится третий элемент — DPU. Сопроцессор для обработки данных освободит серверные процессоры от инфраструктурных задач.
Исследования показывают, что в сильно виртуализированных средах сетевые процессы, такие как транзакции OvS, могут занимать более 30% процессорного времени на хосте. Представьте, что дисковые операции, шифрование, DPI и сложная маршрутизация выполняются отдельным модулем. Это потенциально снимет значительную часть нагрузки с CPU.
Стартапы вроде Pensando и Fungible со своими инновациями столкнулись на рынке с технологическими лидерами, такими как Xilinx, Intel, Broadcom и Nvidia. Это технологическое соревнование, за которым всегда интересно наблюдать.



