

В конце года приложения все чаще подводят итоги пользовательской активности. Они показывают, сколько времени вы провели внутри сервиса, какие кнопочки нажимали чаще и на что вообще ушла жизнь. Один из самых удачных примеров — музыкальные сервисы. Там наглядно показано, сколько времени вы были панком и слушали рок, а сколько грустили под меланхоличный инди, кто для вас стал любимчиком и какой трек стал главным за год.
Подобные рекапы хорошо заходят, потому что дают возможность взглянуть на себя со стороны. Это некий способ осмыслить прошедший год, где-то улыбнуться, а где-то — испытать испанский стыд.
Можете ознакомиться с материалом в формате видео на канале Winderton.
Глобальные отчеты индустрии и их ограничения
Прежде чем переходить к реализации, есть смысл посмотреть на общие итоги года в индустрии и понять, в каком контексте вообще существует такой запрос.
Рекап (recap) — это итоговая выжимка по всей вашей активности за год в одном месте.
Компании ежегодно публикуют собственные отчеты об индустрии. Такие рекапы выпускают, например, JetBrains и GitHub. Эти данные обобщенные: они не рассказывают о конкретных разработчиках, но хорошо показывают картину в целом.
Из подобных отчетов можно узнать, на чем люди пишут код, какие темы доминируют в профессиональном поле, сколько человек приходит в программирование и как распределяются зарплаты по регионам. По сути, такие материалы предлагают разработчику сравнить себя с рынком и понять свое положение относительно индустрии.

Помимо скучноватых цифр вроде «Примерно один человек в секунду присоединялся к GitHub в 2025 году», «Меньше 1% — это проекты на C», «TypeScript и Python — топ-языки», «80 000 человек используют Copilot» и прочего, есть еще и определенный анализ.
Поэтому давайте сместим фокус: прежде чем собирать собственный рекап, освежим в памяти, чем вообще жил айтишный мир IT в 2025 году — так будет проще понять, какие тренды задели нас лично, а какие прошли мимо.
Рост числа разработчиков и изменение реальности
GitHub отдельно подчеркивает, что 2025 год стал для платформы самым крупным за все время по приросту пользователей и репозиториев. Это важная точка для понимания текущей ситуации.
К примеру, десять лет назад все было иначе и казалось проще. Разработчиков было меньше, экосистема была компактнее, а вход в профессию казался более прямолинейным.
А еще говорят, что раньше разработчики все делали сами: читали книги, глубоко разбирались в технологиях и писали код, который до сих пор стабильно работает. Сегодня же, наоборот, новое поколение называют более слабым, утверждая, работа совместно с ИИ в перспективе может привести к проблемам.
Однозначного ответа на этот вопрос нет. Скорее всего, станет понятно, кто был прав, только через пять–десять лет. Но есть более практическая и уже ощутимая проблема.
Конкуренция и рынок труда
Из-за резкого роста числа разработчиков поиск работы стал сложнее. Причем это касается не только новичков — высокая конкуренция ощущается даже среди специалистов со стажем. Все чаще в профессиональной среде появляется контент, в котором специалисты с коммерческим опытом рассказывают, что не могут найти работу.
Если мы взглянем, что происходит в IT-секторе на том же hh, то увидим минимум двойной рост от того, что было даже год назад. Людей в IT колоссальное количество.
С появлением ИИ казалось, что автоматизация должна сократить число разработчиков. На практике произошло обратное. Если мы посмотрим рекап от GitHub, то во всех странах, включая нашу, прирост разработчиков примерно один и тот же в процентном отношении.
Это говорит о том, что стадия паники позади. Сейчас гораздо меньше людей комплейнят по поводу «нас всех заменят» — это уже пройденный этап. Порог входа в программирование снизился, но при этом порог входа именно в работу стал выше.
Возврат к исходной идее профессии
В каком-то смысле профессия вернулась к своим истокам. Изначально программист — это человек, который умеет разбираться в сложных системах. Речь не о том, что если кого-то не берут на работу, значит он «плохой» разработчик. Скорее, теперь нужно знать немного больше.
По сути, все как раньше: плюс-минус много платят, миллиард инвестиций, все развивается и много работы. Но сегодня недостаточно знать только основы ООП, стандартную библиотеку и один фреймворк. От разработчика ожидают понимания базового computer science, принципов DevOps, работы серверов и инфраструктуры.
Если посмотреть на индустриальную статистику, становится очевидно, что основная часть разработки сегодня сосредоточена вокруг серверной части, инфраструктуры и облаков. Веб, мобильные приложения, разработка игр и даже системное программирование в итоге сходятся на серверной стороне.
Поэтому чем бы вы ни занимались и на чем бы ни писали, вы должны знать, как это работает — хотя бы примерно. Раньше все дороги вели в Рим, сейчас все дороги ведут в server-side. А возможность быть узким специалистом, не выходя за пределы своего домена, — редкость.
Идея персонального рекапа
На этом фоне идея персонального рекапа становится особенно актуальной. Настоящую ценность несет не абстрактный отчет о рынке, а честный взгляд на собственную активность. Что именно я делал весь год? Над чем работал? Какие технологии реально использовал?
Я решил попробовать собрать такой рекап самостоятельно, опираясь на реальные данные. Данные будем брать из GitHub — платформа предоставляет достаточно информации в открытом виде: профиль пользователя, репозитории, активность, используемые языки.
Задача языковой модели в этом процессе — не заменить анализ, а интерпретировать собранные данные и превратить их в связный текстовый итог.
Архитектура решения
В качестве интерфейса был выбран Telegram-бот. Это простой и удобный способ взаимодействия — без необходимости разрабатывать полноценный веб-интерфейс. Пользователь передает имя GitHub-аккаунта, а бот возвращает готовый рекап.
Выбор инструментов для меня здесь был очевиден. Я не самый большой фанат экосистемы JavaScript, поэтому остановился на Python. Его главное преимущество в том, что он позволяет моментально «накидать» рабочий вариант, да и порог входа практически нулевой — этот язык понимают все.
В этой задаче Python выступает как универсальный связующий слой. Логика проста: мы берем запрос из Telegram, идем в GitHub и через открытый API вынимаем оттуда вообще все, до чего можем дотянуться. Весь этот массив сырых данных вместе с промтом мы просто закидываем в LLM.

Модель пропускает через себя информацию и возвращает обратно в чат структурированный отчет, адаптированный под конкретного представителя IT-сферы. Текстовый рекап возвращается пользователю через Telegram.
Развертывание проекта: шаг за шагом
Чтобы зарегистрироваться Telegram-бота, идем в Telegram к @BotFather, регистрируем бота и получаем токен. Это наш ключ — именно через него бэкенд будет общаться с API мессенджера.
Шаг 1. Настройка окружения
Проверяем наличие Python и пакетного менеджера pip. Ставим библиотеку для работы с ботом:
sudo apt install phython3
sudo apt install phython3-pip -y
pip install python-telegram-bot --uprgradeТеперь можно запускать первый тестовый образец с сайта разработчиков, чтобы убедиться, что все работает.
from telegram import Update
from telegram.ext import ApplicationBuilder, CommandHandler, MessageHandler, ContextTypes, filters
async def hello(update: Update, context: ContextTypes.DEFAULT_TYPE)-> None:
await update.message.reply_text(f`Hello {update.effictive_user.first_name}`)
#В строке ниже вставьте токен, полученный от BotFather. Постарайтесь его не потерять, не забыть и не засветить в интернете.
app = ApplicationBuilder().token("YOUR TOKEN HERE").build()
app.add_handler(CommandHandler("hello", hello))
app.run_polling()
Для простоты примера мы оставили токен в коде, но в реальных проектах это — плохая практика. Никогда не оставляйте секретные ключи в открытом виде в исходниках, чтобы они не попали в публичный доступ. В целях безопасности всегда используйте переменные окружения.
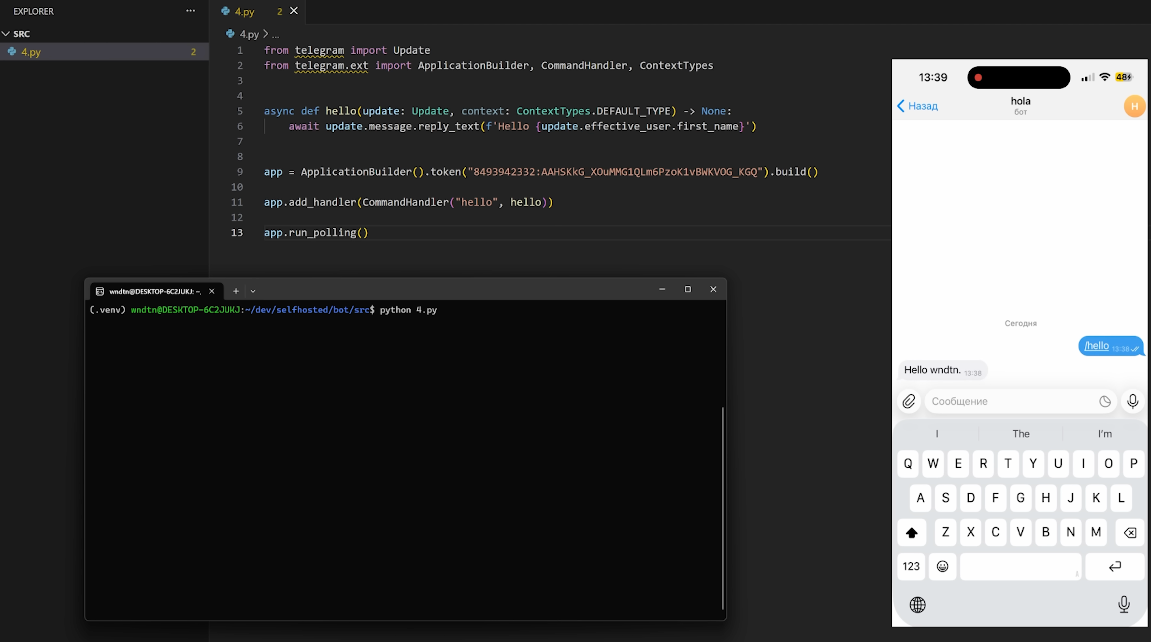
Шаг 2. Оживляем бота
Первым делом учим бота реагировать на сообщения. Добавляем простую функцию, для получения текста, который отправляют пользователи.. Теперь код выглядит так:
from telegram import Update
from telegram.ext import ApplicationBuilder, CommandHandler, MessageHandler, ContextTypes, filters
async def start(update: Update, context: ContextTypes.DEFAULT_TYPE):
await update.message.reply_text("Send something")
async def handle(update: Update, context: ContextTypes.DEFAULT_TYPE):
text = (update.message.text or "").strip()
if not text:
return
await update.message.reply_text("You sent: {text}")
def main():
app = ApplicationBuilder().token(os.environ["TELEGRAM_BOT_TOKEN"]).build()
app.add_handler(CommandHandler("start", start))
app.add_handler(MessageHandler(filters.TEXT & ~filters.COMMAND, handle))
app.run_polling()
if __name__ == "__main__":
main()
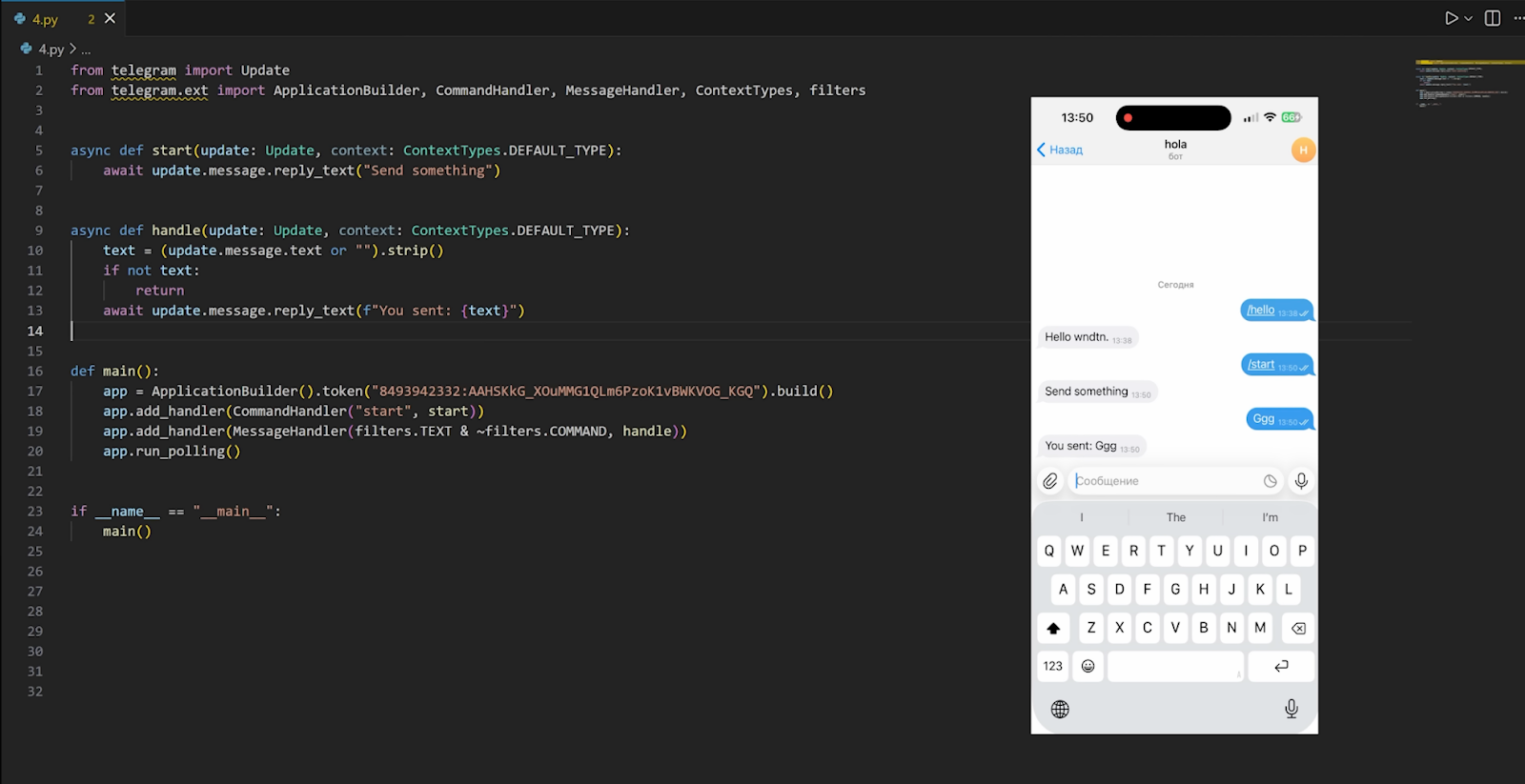
Шаг 3. Интеграция с GitHub API
Наша цель — собрать из профиля пользователя все, что можно: репозитории, звезды, активность. Логика такая: мы пишем боту имя пользователя в GitHub, а он идет в публичный API сервиса.
Пишем функцию для отправки запросов, которая принимает нужный эндпоинт в качестве аргумента. На этом этапе критично правильно обработать ответы:
- 404 — если юзера не существует;
- 403 — если превышение лимитов (это самое важное).
#идем на github, без авторизации(он позволяет)
def github(path: str, params=None):
r = requests.get(
API + path,
params=params,
headers={"Accept": "application/vnd.github+json", "User-Agent": "recap-bot"},
timeout=20,
)
if r.status_code == 404:
return None
if r.status_code == 403:
raise RuntimeError("Rate limit")
r.raise_for_status()
return r.json()
У GitHub основной лимит скорости для неаутентификированных запросов составляет 60 запросов в час. И чтобы их расширить, нужно авторизоваться (использовать персональный токен), иначе API быстро нас заблокирует.
Скорее всего, в процессе тестов мы быстро упремся в потолок. Как только лимит кончится — словим ошибку, так что этот момент мы предусмотрели в коде выше.
Шаг 4. Подготовка данных для LLM
В итоге мы должны получить массив данных, который потом отправим в нейросеть. Промт для LLM будет лежать прямо в коде, а функция сбора данных с GitHub станет для него «топливом».
Затем в обработчик (handler) бота закидываем имя пользователя из чата и через нашу функцию пробуем достать базу — например, список репозиториев и количество фолловеров. Даже если подписчиков ноль — не страшно, нам важно проверить, что связка работает.
async def handle(update: Update, context: ContextTypes.DEFAULT_TYPE):
query = (update.message.text or "").strip()
if not username:
return
user = github(f”/users/{username}”)
await update.message.reply_text(f"{user['login']} - public repos: {user['public_repos]}', folloiwers: user['followers']}”
)
Накидываем базовую обработку ошибок, чтобы бот не падал, если пользователь ввел имя несуществующего аккаунта.
try:
user = github (f”/users/{username}”)
except Exception as e:
await update.message.reply_text(f"Error: {e}")
return
if not username:
await update.message.reply_text(f"{user['login']} - public repos: {user['public_repos]}', folloiwers: user['followers']}”
)
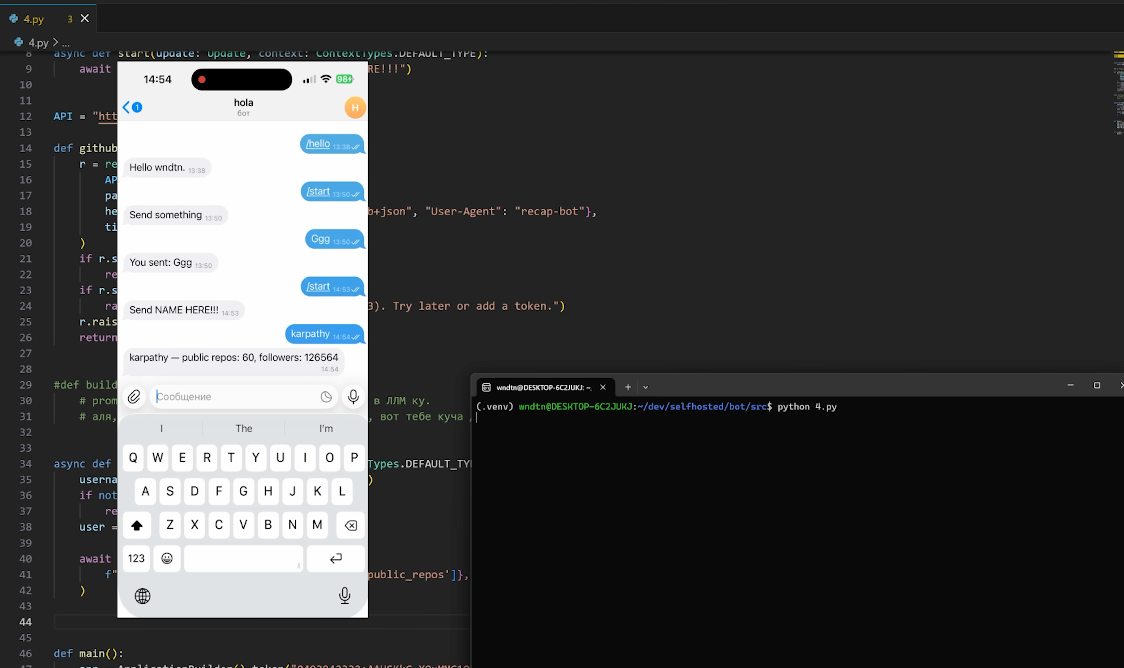
Шаг 5. Собираем рекап
Пишем функцию, которая аккумулирует всю информацию. Вытаскиваем профиль и список репозиториев. Тут важно подстраховаться: если репозиториев нет или пришел пустой ответ, возвращаем пустой список, иначе все крашнется на первой же итерации.
Чтобы статистика была честной, добавим фильтры:
- убираем форки — оставим только авторские проекты, чтобы было репрезентативнее;
- считаем языки — посмотрим, на чем человек кодит чаще всего.
def build_prompt(username: str) -> str:
username = github(f”/users/{username}”)
if not s:
return ""
repos = github(f"/users/{username}/repos", params={"per_page": 100, "sort": "updated"}) or []
repos = [r for r in repos if not r.get("fork", False)]
langs = Counter()
for r in repos:
lang = r.get("language")
if lang:
langs[lang] += 1
top_langs = ", ".join(f"{lang}: {count}" for lang, count in langs.most_common(5)) or "no data"
Шаг 6. Промты
На выходе из функции получаем структурированную выжимку, которую будем скармливать нейронке.
Я не профессиональный промт-инженер, поэтому пришлось немного помучить GPT, чтобы составить адекватную инструкцию.
def build_prompt(username: str) -> str:
s = get_stats(username)
if not s:
return ""
return (
"Роль: ты — Senior C++ инженер и ревьюер open-source профилей.\n"
"Задача: сделать эффектный, но честный 'GitHub Profile Recap' СТРОГО по данным ниже.\n"
"ЖЕЛЕЗНЫЕ ПРАВИЛА:\n"
"1) Нельзя придумывать факты, репозитории, компании, достижения, коммиты, звёзды, сроки.\n"
"2) Можно делать осторожные выводы только из чисел/языков (формулировки: 'похоже', 'вероятно', 'выглядит как').\n"
"3) Никакой динамики/роста/падения/трендов — у нас нет истории.\n"
"4) Проценты — это доля репозиториев по primary language (поле GitHub 'language'), не строки кода.\n"
"5) Если данных нет — так и пиши: 'нет данных'.\n\n"
"СТИЛЬ:\n"
"- Русский язык, уверенный тон, чуть-чуть юмора как у сеньора на код-ревью (без токсичности).\n"
"- Максимум конкретики: в каждом пункте минимум 1 число или язык из данных.\n"
"- Пиши так, чтобы выглядело как мини-отчет/паспорт профиля.\n\n"
"ФОРМАТ ОТВЕТА (строго соблюдать):\n"
"1) Заголовок: одна строка, ярко, но без выдумок.\n"
"2) Блок 'Паспорт профиля' (4 строки):\n"
" - 👤 Username: ...\n"
" - 🧩 Public repos: ...\n"
" - 👀 Followers: ...\n"
" - 🧪 Non-fork analyzed: ...\n"
"3) 'Языковой профиль' (2–4 строки):\n"
" - Топ-5 языков с количеством репозиториев.\n"
" - Если можно, добавь доли в % (от analyzed repos, округли до целых).\n"
"4) '5 наблюдений' — ровно 5 пунктов, каждый начинается с эмодзи и содержит конкретику.\n"
" Примеры тональности: 'Пахнет фокусом на ...', 'Портфель выглядит как ...'.\n"
"5) 'Итог' — 3–4 предложения: что это говорит о профиле, без фантазий.\n"
"6) Последняя строка-дисклеймер: 'P.S. GitHub-статы ≠ скилл, но сигнал дают.'\n\n"
"ДАННЫЕ:\n"
f"Username: {s['login']}\n"
f"Public repos (GitHub profile): {s['public_repos_total']}\n"
f"Non-fork repos analyzed (max 100): {s['repos_analyzed']}\n"
f"Followers: {s['followers']}\n"
f"Top languages (repo primary language): {s['top_langs']}\n"
)
В итоге получился хороший шаблон, куда мы просто подставляем данные о пользователе. Теперь все это добро нужно отправить в LLM, но ее сначала надо где-то развернуть.
Разворачиваем свою LLM через vLLM
Выбор моделей сейчас огромный, все упирается только в мощности вашего железа. Чтобы не гадать, хватит ли мощностей видеокарты для запуска, будем использовать vLLM. Это движок, который позволяет поднять инференс практически любой открытой модели прямо на вашей видеокарте.
Как это работает? У vLLM есть доступ к хабу моделей (Hugging Face), откуда он их и вытягивает. Мы говорим движку: «Разверни нам на видеокарте Qwen на 3 миллиарда параметров».
(.venv) wndtn@DESKTOP-6C2JUKJ:~/dev/selfhosted/bot/src$ vllm serve Qwen/Qwen2.5-3B-Instruct\
--host 127.0.0.1 --port 8000
--dtype float16 \
--gpu-memory-utilization 0.85 \
--max-model-len 4096
За пару минут инференс развернется, и в него уже можно будет что-то закидывать. Когда модель готова, пора отправлять туда наш промт с данными из GitHub. Дальше пишем функцию для связи бота с развернутой нейронкой.
vLLM дает OpenAI-совместимый API. Это значит, что нам не нужно изобретать велосипед — достаточно использовать стандартный формат запросов и ответов, к которому все привыкли. Можно, конечно, слать обычные HTTP-запросы напрямую, но через готовый стандарт кода будет меньше, а профит тот же.
Тут немного рвется шаблон по поводу того, что есть бэкенд, а что фронтенд. Код бота ближе к бэкенду: он не рендерит UI сам, но предоставляет его нам в Telegram. Считайте, что это целое приложение, где все внутри.
Мы развернули на своем железе LLM, ботом достаем данные из GitHub, закидываем их в нейронку, а она выдает мысли по нашей активности на основе промта, который мы захардкодили.
Идем дальше по коду: прописываем адрес, по которому будем обращаться к модели. По регламенту OpenAI API там должен лежать ключ или токен, но так как мы хостим все сами, у нас его нет. Но передать нужно хоть что-то, любую строку, иначе не заработает.
#обращаемся к нашей llm и говорим, как мы с ней взаимодействуем
def ask_llm(text: str) -> str:
client = OpenAI(
base_url=os.environ["OPENAI_URL"],
api_key=os.environ.get("OPENAI_API_KEY", "yoass"),
)
resp = client.chat.completions.create(
model=os.environ["MODEL_NAME"],
messages=[{"role": "user", "content": text}],
max_tokens=400,
temperature=0.8,
)
return resp.choices[0].message.content
Указываем нашу модель Qwen и роль — я всегда пишу просто user. Также выставляем лимит ответа в токенах и настраиваем, насколько разнообразно будет отвечать модель. Ставим 0,7: единица позволяет ей слишком много, а на нуле она будет слишком глупая. В этом и плюс self-hosted LLM — вы полностью контролируете все взаимодействие через такие настройки.
В конце добавляем функцию, которая склеит все воедино: сбор данных, промт и ответ нейронки. И правим функцию `handle` под новую логику, просто подставив вызовы всех наших новых функций.
def recap(username: str) -> str:\
prompt = build_prompt(username)
if not prompt:
return “User not found”
return ask_llm(prompt)
Все, можно запускать.
Тут можно пойти еще дальше: подтянуть логику и промт. Хочется результат поинтереснее, но мой комп не потянет ничего умнее модели на 3 млрд параметров. Поэтому давайте перенесем тесты в реальные условия и развернем инференс на нормальном железе в облаке.
Развернем LLM в облаке
Весь наш код (бэкенд и фронтенд бота) оставляем локально, а вот тяжелую LLM вынесем туда, где видеопамяти в десятки раз больше.
В cloud-computing для таких задач полно ресурсов. У Selectel, например, огромный выбор для self-host развертывания. Самый ходовой вариант — Linux + CUDA, так что создаем машину с видеокартой на Ubuntu. Дистрибутив уже стоит такой, который сразу раскроет потенциал карты.
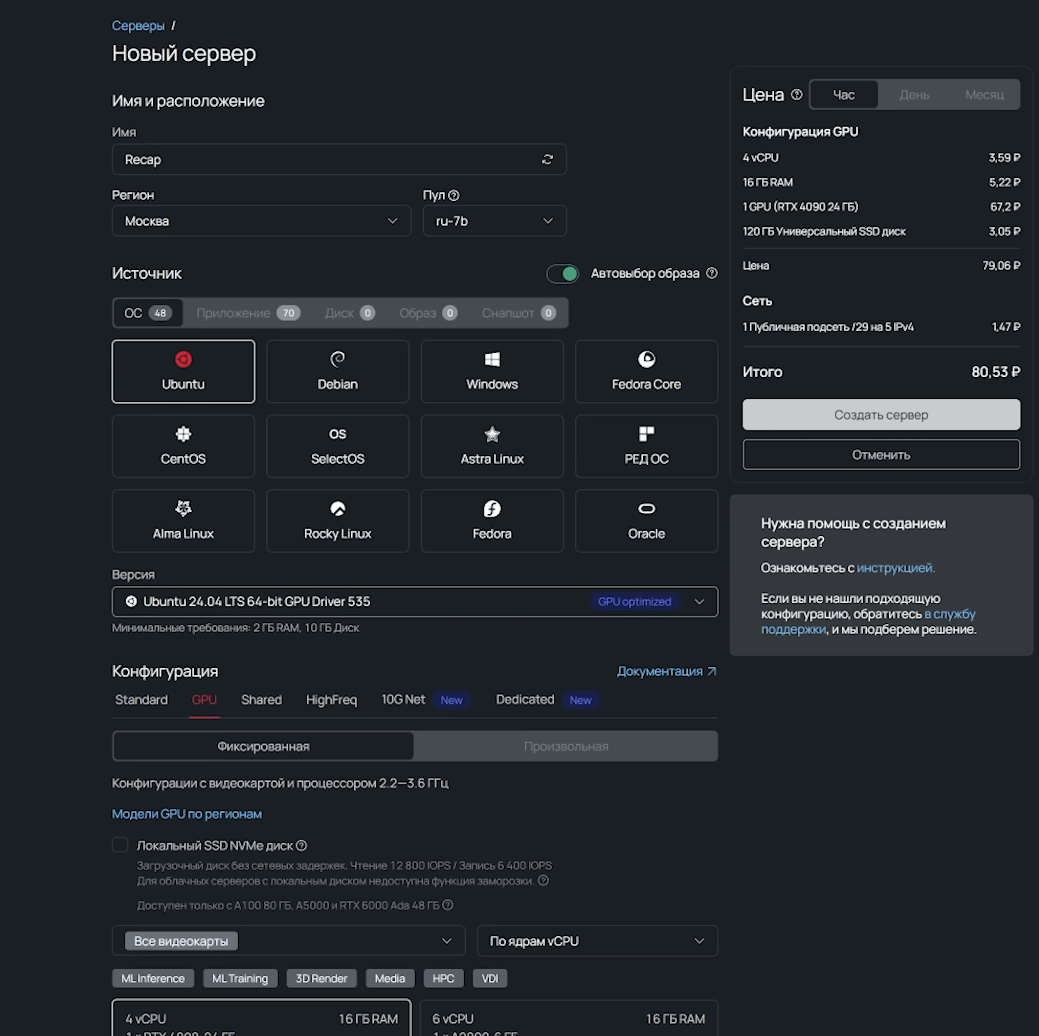
На сервере делаем базовые две базовые команды:
sudo apt update
sudo apt upgradeПервая команда обновляет списки доступных пакетов. При этом она не устанавливает новые программы, а просто проверяет сервер на наличие обновлений, чтобы компьютер знал: «Ага, есть свежая версия софта». Вторая команда обновляет сами пакеты до последней версии. Она берет информацию от первой команды, скачивает фактуальные файлы и устанавливает их в систему.
Дальше накатываем vLLM и другие детали — это разовое действие, после которого можно запускаться.
Сначала я думал о карте 4090, но зачем мелочиться, если есть A100? Тем более NVIDIA обещает на ней беспрецедентный перформанс для ИИ, и это как раз под нашу задачу.
Локально у нас крутилась слабенькая модель на 3 млрд параметров, а в облаке мы сразу запускаем на 70B. В коде бота просто правим адрес на IP облачного сервера. Посмотреть IP своей виртуальной машины можно в панели управления во вкладке «Конфигурация».
TELEGRAM_BOT_TOKEN=qwerty12345
OPENAI_URL=http://localhost/v1#или IP удаленного сервера:8000
OPENAI_API_KEY=whateveryoulike
MODEL_NAME=qwen-72b-awq #72миллиарда
#MODEL_NAME=Qwen/Qwen2.5-3B-Instruct #3миллиардаПоднимаем модель, запускаем бота и сравниваем: 3 млрд параметров предсказуемо проигрывают этому чуду. Адекватность и сочность ответов на другом уровне. С нормальным железом и промт можно улучшить, и нейронка начинает толково шутить, и давать грамотные советы по коду.
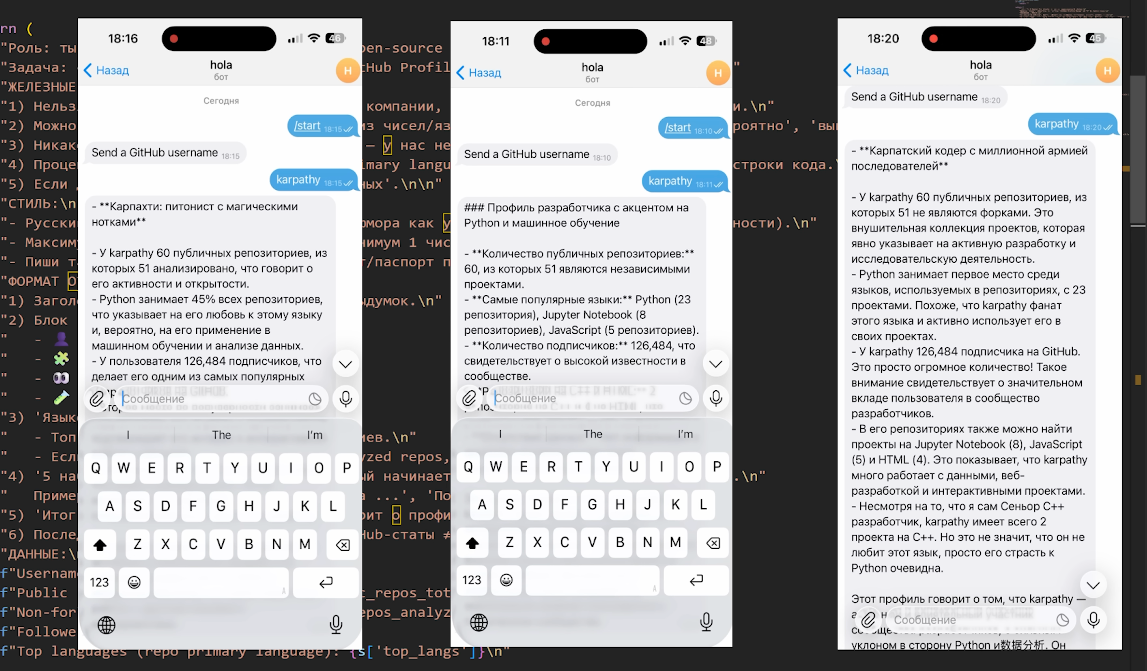
Заключение
В результате получается персональный рекап разработчика, основанный на реальных данных GitHub и интерпретированный self-hosted языковой моделью. Эксперимент показал не только способ подведения итогов года, но и то, как сегодня выглядит современная разработка: от API и бэкенда до инфраструктуры, облаков и собственных LLM.
Финальный код с актуальной логикой: переписан под новую структуру и включает вызовы всех новых компонентов.
import os
import asyncio
from collections import Counter
import requests
from dotenv import load_dotenv
from openai import OpenAI
from telegram import Update
from telegram.ext import ApplicationBuilder, CommandHandler, MessageHandler, ContextTypes, filters
load_dotenv()
API = “https://api.github.com”
#прыгаем на github, без авторизации(он позволяет)
def github(path: str, params=None):
r = requests.get(
API + path,
params=params,
headers={“Accept”: “application/vnd.github+json”, “User-Agent”: “recap-bot”},
timeout=20,
)
if r.status_code == 404:
return None
if r.status_code == 403:
raise RuntimeError(“Rate limit”)
r.raise_for_status()
return r.json()
#вытасикаем то что хотим из профиля на github
def get_stats(username: str):
user = github(f”/users/{username}”)
if not user:
return None
repos = github(f”/users/{username}/repos”, params={“per_page”: 100, “sort”: “updated”}) or []
repos = [r for r in repos if not r.get(“fork”, False)]
langs = Counter()
for r in repos:
lang = r.get(“language”)
if lang:
langs[lang] += 1
top_langs = “, “.join(f”{lang}: {count}” for lang, count in langs.most_common(5)) or “no data”
return {
“login”: user.get(“login”, username),
“followers”: int(user.get(“followers”, 0) or 0),
“public_repos_total”: int(user.get(“public_repos”, len(repos)) or 0),
“repos_analyzed”: len(repos),
“top_langs”: top_langs,
}
#В зависимости от промта, результаты могут быть хуже или лучше.
def build_prompt(username: str) -> str:
s = get_stats(username)
if not s:
return “”
return (
“Роль: ты — Senior C++ инженер и ревьюер open-source профилей.\n”
“Задача: сделать эффектный, но честный ‘GitHub Profile Recap’ СТРОГО по данным ниже.\n”
“ЖЕЛЕЗНЫЕ ПРАВИЛА:\n”
“1) Нельзя придумывать факты, репозитории, компании, достижения, коммиты, звезды, сроки.\n”
“2) Можно делать осторожные выводы только из чисел/языков (формулировки: ‘похоже’, ‘вероятно’, ‘выглядит как’).\n”
“3) Никакой динамики/роста/падения/трендов — у нас нет истории.\n”
“4) Проценты — это доля репозиториев по primary language (поле GitHub ‘language’), не строки кода.\n”
“5) Если данных нет — так и пиши: ‘нет данных’.\n\n”
“СТИЛЬ:\n”
“- Русский язык, уверенный тон, чуть-чуть юмора как у сеньора на код-ревью (без токсичности).\n”
“- Максимум конкретики: в каждом пункте минимум 1 число или язык из данных.\n”
“- Пиши так, чтобы выглядело как мини-отчет/паспорт профиля.\n\n”
“ФОРМАТ ОТВЕТА (строго соблюдать):\n”
“1) Заголовок: одна строка, ярко, но без выдумок.\n”
“2) Блок ‘Паспорт профиля’ (4 строки):\n”
” – 👤 Username: …\n”
” – 🧩 Public repos: …\n”
” – 👀 Followers: …\n”
” – 🧪 Non-fork analyzed: …\n”
“3) ‘Языковой профиль’ (2–4 строки):\n”
” – Топ-5 языков с количеством репозиториев.\n”
” – Если можно, добавь доли в % (от analyzed repos, округли до целых).\n”
“4) ‘5 наблюдений’ — ровно 5 пунктов, каждый начинается с эмодзи и содержит конкретику.\n”
” Примеры тональности: ‘Пахнет фокусом на …’, ‘Портфель выглядит как …’.\n”
“5) ‘Итог’ — 3–4 предложения: что это говорит о профиле, без фантазий.\n”
“6) Последняя строка-дисклеймер: ‘P.S. GitHub-статы ≠ скилл, но сигнал дают.’\n\n”
“ДАННЫЕ:\n”
f”Username: {s[‘login’]}\n”
f”Public repos (GitHub profile): {s[‘public_repos_total’]}\n”
f”Non-fork repos analyzed (max 100): {s[‘repos_analyzed’]}\n”
f”Followers: {s[‘followers’]}\n”
f”Top languages (repo primary language): {s[‘top_langs’]}\n”
)
#тут тоже самое как и с первым промтом, только это уже сравнение 2х профилей людей с github
def build_compare_prompt(u1: str, u2: str) -> str:
a = get_stats(u1)
b = get_stats(u2)
if not a or not b:
return “”
return (
“Роль: ты — Senior C++ инженер и ведущий шуточного ‘GitHub-рингa’.\n”
“Задача: сравнить два GitHub профиля СТРОГО по данным ниже и выдать эффектный, но честный итог.\n\n”
“ЖЕЛЕЗНЫЕ ПРАВИЛА:\n”
“1) НЕЛЬЗЯ придумывать факты: коммиты, звезды, PR, issues, компании, сроки, ‘рост’, активность во времени.\n”
“2) НЕЛЬЗЯ говорить кто ‘лучше программист’ вообще. Только выводы по этим метрикам.\n”
“3) МОЖНО: осторожные выводы по числам/языкам (формулировки: ‘выглядит’, ‘похоже’, ‘по метрикам’).\n”
“4) Проценты — только доля репозиториев по primary language среди analyzed repos.\n”
“5) Тон: легкий, немного юмора, без токсичности/оскорблений.\n”
“6) Если каких-то данных нет — ‘нет данных’.\n\n”
“ФОРМАТ ОТВЕТА (строго соблюдать):\n”
“1) Заголовок: одна строка в стиле ‘A vs B — GitHub recap battle’.\n”
“2) Блок ‘Табло’ (6 строк):\n”
” – 🅰️ A: <login>\n”
” – 🅱️ B: <login>\n”
” – 👀 Followers: A=<n> | B=<n>\n”
” – 📦 Public repos (total): A=<n> | B=<n>\n”
” – 🧪 Non-fork analyzed: A=<n> | B=<n>\n”
” – 🧩 Top languages: A=<…> | B=<…>\n”
“3) Блок ‘Раунд 1 — Охват’ (2 пункта):\n”
” – ✅ Пункт в пользу того, у кого больше followers (или честная ничья).\n”
” – ✅ Пункт в пользу того, у кого больше public repos (или честная ничья).\n”
“4) Блок ‘Раунд 2 — Портфель’ (2 пункта):\n”
” – ✅ Пункт в пользу того, у кого больше analyzed non-fork repos (или честная ничья).\n”
” – ✅ Пункт по языкам: сравни топ-языки (пересечения/разнообразие), но без фантазий.\n”
“5) Блок ‘Вердикт’ — 1 предложение: игриво кто выглядит более open-source/публичным по метрикам и почему.\n”
“6) Блок ‘Дисклеймер’ — 1 предложение: ‘GitHub-статы ≠ скилл’.\n\n”
“ДАННЫЕ (ТОЛЬКО ОНИ):\n”
f”User A: {a[‘login’]}\n”
f”- Followers: {a[‘followers’]}\n”
f”- Public repos (total): {a[‘public_repos_total’]}\n”
f”- Non-fork repos analyzed: {a[‘repos_analyzed’]}\n”
f”- Top languages (repo primary language): {a[‘top_langs’]}\n\n”
f”User B: {b[‘login’]}\n”
f”- Followers: {b[‘followers’]}\n”
f”- Public repos (total): {b[‘public_repos_total’]}\n”
f”- Non-fork repos analyzed: {b[‘repos_analyzed’]}\n”
f”- Top languages (repo primary language): {b[‘top_langs’]}\n”
)
#обращаемся к нашей llm и говорим, как мы с ней взаимодействуем
def recap(prompt: str) -> str:
client = OpenAI(
base_url=os.environ[“OPENAI_URL”],
api_key=os.environ.get(“OPENAI_API_KEY”, “yoass”),
)
resp = client.chat.completions.create(
model=os.environ[“MODEL_NAME”],
messages=[{“role”: “user”, “content”: prompt}],
max_tokens=400,
temperature=0.8,
)
return resp.choices[0].message.content
#склеивающая функция, это можно просто положить в main
def recap_one(username: str) -> str:
prompt = build_prompt(username)
if not prompt:
return “User not found. Send a GitHub username like: karpathy”
return recap(prompt)
#логика сравнения профилей
def recap_vs(text: str) -> str:
t = (text or “”).strip()
if ” vs ” in t:
u1, u2 = [x.strip() for x in t.split(” vs “, 1)]
elif “,” in t:
u1, u2 = [x.strip() for x in t.split(“,”, 1)]
else:
return “”
if not u1 or not u2:
return “”
prompt = build_compare_prompt(u1, u2)
if not prompt:
return “One of the users was not found”
return recap(prompt)
#приветственное сообщение
async def start(update: Update, context: ContextTypes.DEFAULT_TYPE):
await update.message.reply_text(
“Send a GitHub username [user] or compare: torvalds vs karpathy”
)
#обработка, по сути тоже склеивающая функция, чтобы сильно не захламлять код
async def handle(update: Update, context: ContextTypes.DEFAULT_TYPE):
query = (update.message.text or “”).strip()
if not query:
return
await update.message.reply_text(“Working…”)
def run():
out = recap_vs(query)
if out:
return out
return recap_one(query)
try:
out = await asyncio.to_thread(run)
except Exception as e:
await update.message.reply_text(f”Error: {e}”)
return
await update.message.reply_text(out)
#старт программы
def main():
app = ApplicationBuilder().token(os.environ[“TELEGRAM_BOT_TOKEN”]).build()
app.add_handler(CommandHandler(“start”, start))
app.add_handler(MessageHandler(filters.TEXT & ~filters.COMMAND, handle))
app.run_polling()
if __name__ == “__main__”:
main()




