
В статье рассказываем, что такое Data Warehouse, какие у этой технологии особенности и зачем ее используют компании.
Что такое Data Warehouse
Обычно данные в организациях хранятся «разрозненно». В бухгалтерии одна система хранения, в логистике и прочих отделах — другая. Желательно, чтобы эти системы хранения не пересекались — и в этом есть логика. Так, например, информация о финансовых поступлениях и налоговых отчислениях не будет доступна никому, кроме сотрудников отдела бухгалтерии.
Но эта «разрозненность» вызывает много вопросов. Например, как подготовить аналитику состояния компании за год? Как объединить данные из разных источников и информационных систем в одном месте? Ведь база данных (БД) склада хранит только информацию о складских запасах, а база отдела кадров — данные о сотрудниках. Как их очистить, структурировать и анализировать? На помощь приходит Data Warehouse.
Data Warehouse (DWH) — это хранилище, в которое из разных систем хранения собираются исторические данные компании. Это некая библиотека, в которой упорядочена и каталогизирован весь объем информации. Она может быть в основе, например, платформы обработки данных.
Признаки и особенности DWH:
- Аналитику не нужно запрашивать доступы к базам данных разных отделов. Все хранится в одном месте, при этом в DWH могут храниться агрегированные данные за десятки лет.
- Данные в хранилище добавляются, удаляются, очищаются, выгружаются. К этому хранилищу выполняются запросы, также с ним производятся другие манипуляции.
- При использовании систем бизнес-аналитики (BI) совместно с DWH у пользователей появляется возможность искать закономерности и взаимосвязи в данных, аналитически обрабатывать и визуализировать информацию. Аналитик изучает данные из хранилища, формирует отчет, подкрепляя статистической информацией, визуализирует.
Корпоративное хранилище данных, КХД
DWH называют хранилищем данных или корпоративным хранилищем данных (КХД). Это хранилище структурированных данных, с одной широкой или большим количеством отдельных таблиц.
DWH не только хранят данные, но и выполняют вычисления, так как аналитические — например, OLAP — запросы зачастую требуют много ресурсов. Например, представим гигантский ангар, заставленный полками вдоль и поперек, а полки — вещами в коробках, пакетах, пленке. Здание поделено на секции для канцтоваров, ГСМ, средств гигиены и прочего.
Если просто использовать ангар как склад — это будет простое хранилище. Но если добавить на все коробки штрих-коды, а на входе и выходе — лазерные сканеры для их считывания, то условный завхоз сможет отслеживать насколько заполнены стеллажи. Это полезно, если ему нужно прогнозировать, например, расход материалов — чтобы они не простаивали и не перегружали стеллажи. Такой прокачанный ангар — это хранилище данных, DWH.
Трехуровневая архитектура хранилища данных
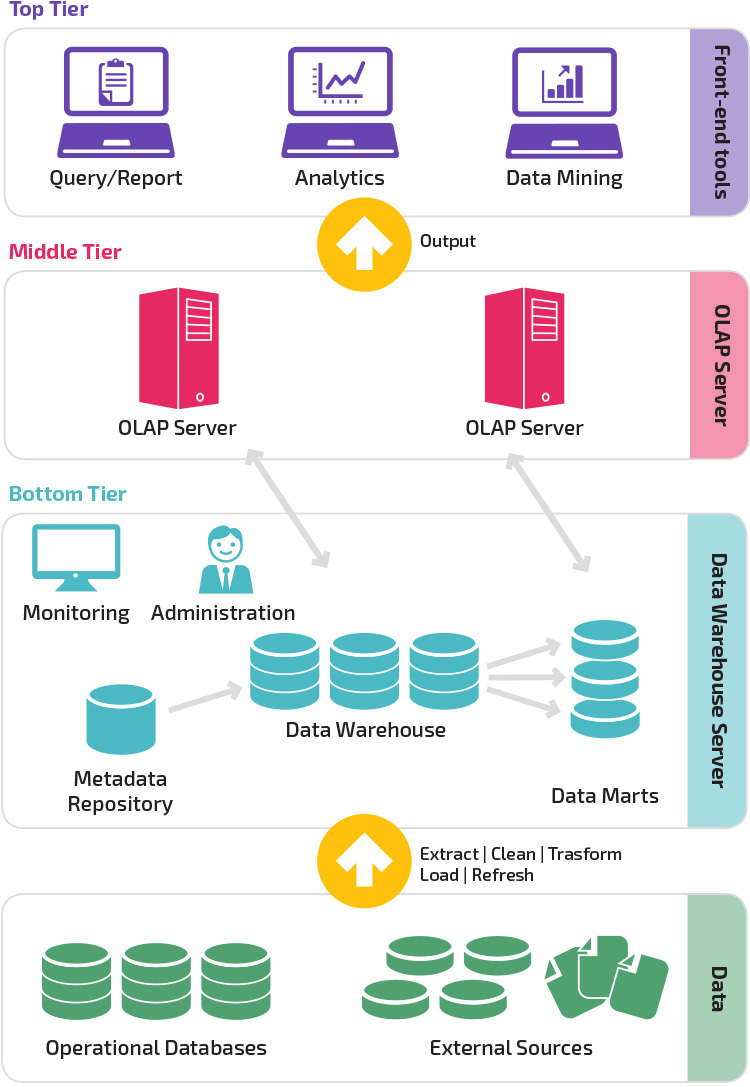
В традиционном виде часто архитектура хранилища данных состоит из трех уровней.
- Нижний уровень — база данных (или даже несколько), которые объединяют в себе данные из различных источников информации — например, из транзакционных СУБД или SaaS-сервисов.
- Средний уровень — сервисы и приложения, которые преобразуют данные в специальную структуру для анализа и сложных запросов (уровень моделирования, либо семантической слой). Это может быть сервер OLAP, например, который работает в качестве расширенной системы управления реляционными базами данных. И отображает операции над многомерными данными в стандартных реляционных операциях.
- Верхний уровень — инструменты для создания отчетов, визуализации и последующего анализа данных. Его также называют уровнем клиента.
Концептуально все понятно — рассмотрим DWH подробней, через призму LSA.
Полная архитектура хранилища данных
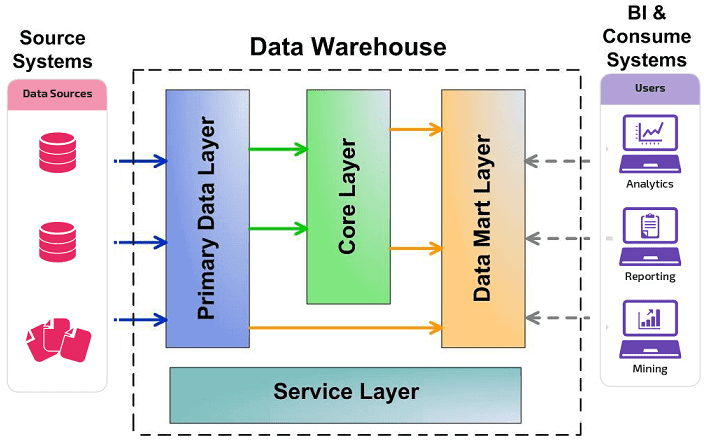
Одна из моделей проектирования Data Warehouse — «слоеный пирог», построенный по архитектуре LSA, Layered Scalable Architecture. Она реализует логическое деление структур с данными на несколько функциональных уровней:
- Стейджинг (Primary Data Layer) — уровень, на котором подгружаются данные из внешних источников. Например, из таблиц, ERP-системы или биллинговой системы.
- Ядро хранилища (Core Data Layer) — центральный уровень, который подгоняет данные к единым структурам и ключам. На этом слое обеспечивается целостность и качество данных.
- Аналитические витрины (Data Mart Layer) — слой, который преобразует данные к структурам, удобным для анализа и использования в BI-дашбордах и других аналитических системах.
- Сервисный слой (Service Layer) — уровень, на котором обеспечивается управление предыдущими слоями, мониторинг и диагностика ошибок.
Визуально LSA-архитектуру Data Warehouse можно представить так:
Проектирование хранилища данных: модели Кимбалла и Инмона
Существует две модели, описывающие то, как должны быть устроены хранилища данных. Их идейные вдохновители — Билл Инмон, «отец хранилищ данных», и Ральф Кимбалл, идейный лидер в области хранилищ многомерных данных.
Хранение данных по модели Инмона
По модели Инмона (Inmon) данные из источников должны поступать в хранилище после процесса ETL (Extract, Transformation, Load).
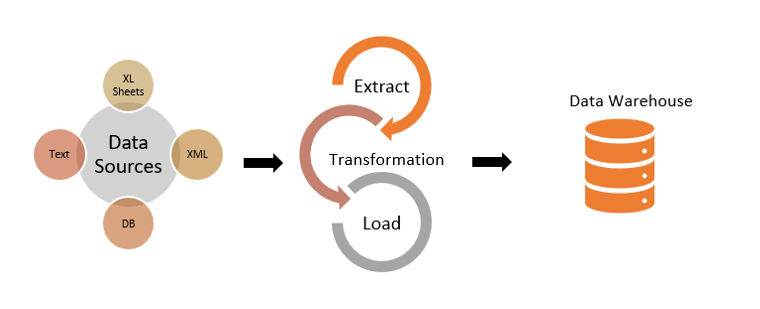
Хранение данных по модели Кимбалла
По модели Кимбалла (Kimball) после процесса ETL данные загружаются в витрины данных, а объединение витрин создает концептуальное (а не фактическое) хранилище данных.
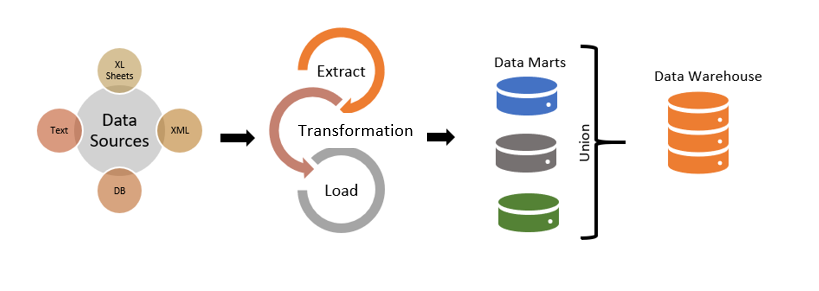
От выбора двух подходов будет зависеть исходный результат. Представим хранилище в виде картотеки — библиотечного шкафа с карточками, в котором хранятся данные.
- По Инмону мы сначала берем 10 карточек, выписываем из них самое важное на листочек и кладем в шкаф. Подобный подход используют в страховании. Сначала формируют общую картинку о всех застрахованных, собирают данные о доходе, возрасте, хронических болезнях, распространении определенных болезней в регионе, демографии, авариях на дорогах и пр. Все аспекты взаимосвязаны, поэтому сначала собираются все возможные данные, а после фильтруются и ложатся в основу модели.
- По Кимбаллу мы начинаем с нескольких ящиков (витрин данных), а потом решаем, что сложить в общий шкаф. Такой подход используют, например, в маркетинге: чтобы анализировать рекламные кампании не нужно знать абсолютно все, к метрикам нужно подходить выборочно.
При создании DWH также следует учитывать и специфику данных, взаимосвязи внутри групп данных, связи между ними, типы преобразования данных, частоту обновления, взаимосвязь между объектами хранилища, процессы передачи, резервного копирования, восстановления.
Архитектуры облачных хранилищ данных Amazon Redshift, Google BigQuery, Panoply
Последние несколько лет хранилища данных перемещаются в гипероблака вроде Amazon, Google, Microsoft Azure или облачные сервисы вроде Snowflake, Panoply и их аналоги. Агрегаторы постепенно прекращают придерживаться традиционной архитектуры DWH и создают собственные. Например, Amazon Redshift и Google BigQuery. В их основе — различные механизмы вроде MPP и Dremel. Подробнее о новых архитектурах облачных хранилищ можно почитать по ссылке.
Чем DWH отличается от базы данных, Data Lake и Data Mart
Базы данных и хранилища данных — это разные вещи
Многие базы данных — OLTP, рассчитаны на операционную нагрузку, поэтому они выполняют много небольших операций записи, изменения и удаления. В остальном, можно выделить следующие признаки для баз данных:
- информация в первую очередь хранится,
- информация от разных информационных систем компании хранится в разных БД (например, у службы поддержки и отдела логистики БД разные — никто не будет их объединять),
- обновления выполняют конечные пользователи с помощью специальных команд (SQL),
- существуют сложности с агрегированием данных.
С Data Warehouse ситуация другая, хранилище:
- объединяет массивы данных из различных источников — начиная от отдела продаж, заканчивая данными о транзакциях,
- обновляет операционные данные не в real-time, а с некоторой периодичностью — например, раз в час,
- консолидирует данные вместе,
- позволяет получать ответы на большие аналитические запросы (OLAP).
DWH — единый источник информации, основанный на структурированных и неструктурированных данных бизнеса. Инструмент, который используется для аналитики и обнаружения закономерностей и взаимосвязей в данных, которые появляются со временем.
Витрины данных и хранилища данных — разные вещи
Витрины нужны для того, чтобы предоставлять обработанные данные в BI- или отчетную систему, наряду с этим:
- витрины ограничены — подразделением или направлением бизнеса,
- они строятся из данных, которые запрашивают чаще других, поэтому витрины создавать легче и быстрее, чем хранилища,
- комплекс из нескольких витрин обычно ведет к потере целостности данных, потому что сложно обеспечить управление данными и контроль между витринами,
- доступ к историческим данным ограничен.
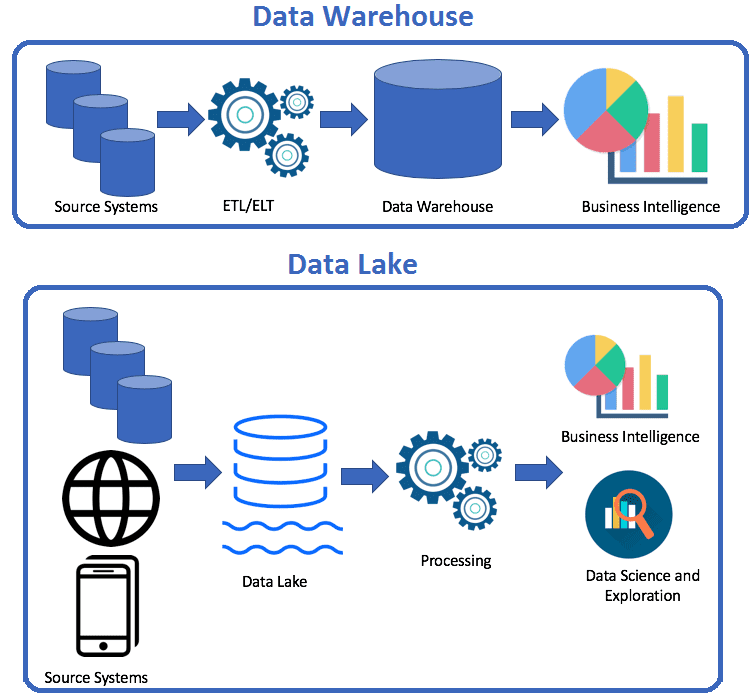
Озера данных и хранилища данных — не одно и то же
Они отличаются архитектурно и функционально.
DWH как инструмент для анализа данных
«Озера данных», или Data Lake, используют для хранения неформатированных, неструктурированных данных из большого количества внешних источников. Они могут строиться, например, на базе облачного хранилища (S3) и быть дешевле в работе. DWH же предназначены не только для хранения, но и для анализа данных.
Подробнее о разнице между Data Lake и Data Warehouse читайте по ссылке →
Для чего крупному бизнесу хранилище данных
Мы уже определили, что хранилище данных — это информационная система, предназначенная для подготовки отчетов и бизнес-анализа. Наряду с этим DWH помогает:
- безопасно хранить данные в одном месте из множества источников,
- создавать специальные отчеты и работать со сложными запросами,
- преобразовывать данные в стандартный формат даже из устаревших систем,
- очищать и удалять некачественную информации, обнаруживать повторяющиеся, поврежденные или неточные наборы данных,
- сократить общее время обработки для анализа и отчетности,
- хранить большое количество исторических данных.





