
Привет! Я Владимир Иванов, системный администратор выделенных серверов в Selectel. Мы довольно часто экспериментируем с подходами, процессами и решениями. В одном из экспериментов добрались до Ceph: сделали тренажер, в котором можно «потыкать» основной функционал хранилища, проверить гипотезы, что-то сломать/починить, не собирая при этом железный кластер. В случае фейла этот тренажер можно развернуть заново в пару консольных команд. Так и появилась идея написать эту статью.
Ceph — программно определяемая система хранения данных (SDS, Software Defined Storage). Если коротко, он объединяет несколько дисков обычной сетью, лучше от 10 GbE. Хранилище устойчиво к выходу из строя отдельных дисков, серверов, стоек или даже дата-центров. В отличие от большинства вендорных СХД, Ceph разворачивается почти на любом железе и поддерживает несколько протоколов доступа к данным: объектный, файловый и блочный. В рамках статьи я рассмотрю последний из них.
При подготовке этой статьи я исхожу из того, что вы знакомы с общепринятыми терминами и сокращениями. Архитектура хранилища Ceph подробно описана в документации, на Хабре есть статья с картинками, а у СЛЁРМ — классный курс.
Nomad — это планировщик для ваших приложений. Ближайший аналог — Kubernetes. В Nomad значительно легче вкатиться: он прост в установке и подготовке к работе. Разработчики, компания Hashicorp, поддерживают автоматическую интеграцию основных инструментов экосистемы между собой: Nomad, Consul, Vault и Terraform. Если у вас есть опыт работы с любым из этих инструментов, разобраться с синтаксисом заданий не составит большого труда.
Зачем подключать Ceph к Nomad
Nomad может работать с приложениями, контейнерами и виртуальными машинами в любом масштабе. А чтобы масштаб действительно был любым, нам необходимо перемещать наше приложение между хостами оркестратора. Тут-то и понадобится Ceph — благодаря ему хранилище можно перемещать вместе с приложением и не зависеть от локальных ресурсов хоста.
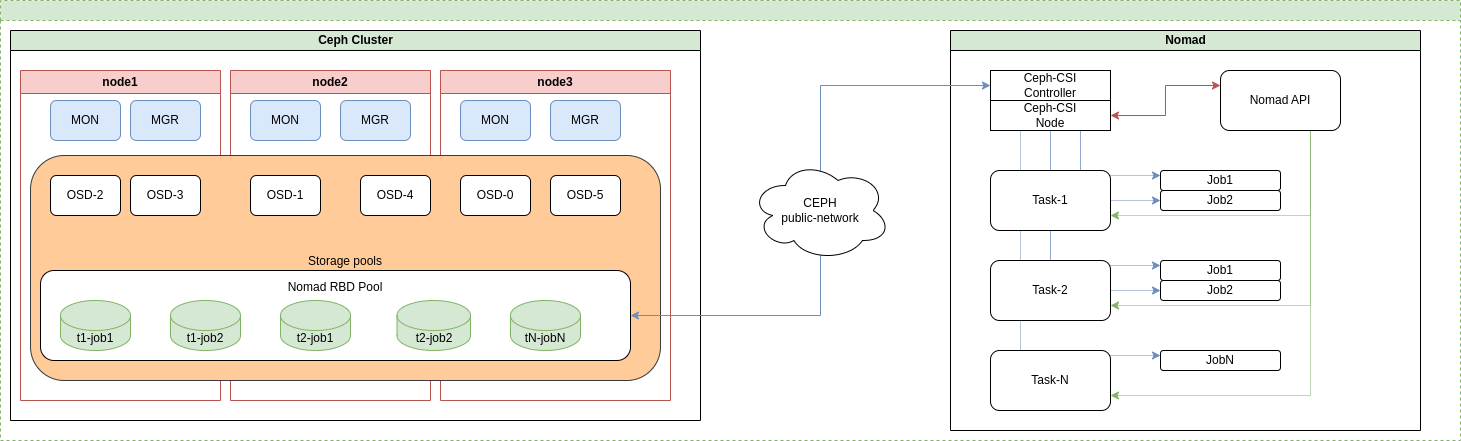
Вместо Nomad может быть K8s, выделенный сервер или платформа виртуализации. Отличаться будет только интерфейс предоставления блочного доступа к данным: CSI, RBD, iSCSI или NVME-OF. Nomad использует CSI Driver (Container Storage Interface Driver). Это унифицированный интерфейс, в котором описано взаимодействие между Nomad и системой хранения.
Ceph-CSI состоит из двух компонентов:
- Ceph-CSI Controller — работает непосредственно с Ceph, создает и удаляет тома, назначает права доступа и т. д.;
- Ceph-CSI Node — запускается на каждом узле и монтирует выделенные для задачи тома.
При подготовке этой статьи мы реализовали ChefCookbook, который автоматизирует деплой кластера Ceph и в несколько команд настраивает виртуальное окружение test-kitchen. С его помощью можно развернуть тестовый кластер у себя на ноутбуке в пару консольных команд. При запуске стенда развернем четыре виртуальные машины: три под кластер Ceph и одну для клиента кластера. У нас этим клиентом будет Nomad. Инструкция по настройке «тренажера» описана в репозитории.
Подготовка стенда
Вкратце, все сводится к установке необходимых зависимостей и запуску test-kitchen:
# Деплой локального кластера
:~$ kitchen converge
# Логинимся на первую ноду кластера
:~$ kitchen login node1
# Разбираем кластер, удаляем данные виртуальных машин
:~$ kitchen destroy
Если все прошло удачно, мы сможем залогиниться на ноду и посмотреть состояние нашего кластера:
vagrant@node1:~# ceph -s
cluster:
id: 6ba7d13c-642b-11ee-b8b2-c70be95e3c50
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 3 daemons, quorum node1,node2,node3 (age 28m)
mgr: node1.cauksk(active, since 44m), standbys: node2.ecffgz
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
# Если вы не меняли адресацию в файле kitchen.yml Ceph Dashboard будет доступна с вашего локального хоста.
Ceph Dashboard - https://192.168.56.6:8443/ или https://192.168.56.5:8443/ (в зависимости от того, где работает сервис mgr)
Креды по умолчанию: login - ceph-admin, pass - pa$$w0rd
Из вывода выше мы видим, что кластер развернут и состоит из:
- трех сервисов мониторов (mon), которые поддерживают кворум между собой;
- двух сервисов менеджеров, один активен, второй «на подхвате»;
- ноля сервисов OSD.
Данных в кластере нет, никакие сервисные флаги не установлены. А отсутствие сервисов OSD — причина, по которой кластер находится в состоянии warning.
Добавление OSD
Сервисы Ceph крутятся в контейнерах под управлением systemd. У хранилища есть инструмент ceph orch, с помощью которого можно настраивать практически все сервисы кластера, чем мы и займемся. В принципе, добавление OSD можно автоматизировать в рамках рецептов кукбука, но я намеренно этого не делаю, чтобы мы могли все потрогать и покрутить своими руками.
Кластер состоит из трех нод, у каждой помимо системного есть по два дополнительных диска. Мы можем инициализировать сервисы OSD на всех из них, выбрать некоторые из конкретных узлов или передать спецификацию YAML, указав в ней правило добавления дисков.
Мы используем все свободные диски кластера под сервисы OSD, потому что так быстрее, но в производственной среде стоит подумать, какие из них и по каким правилам будем добавлять в кластер. Так же инструмент ceph orch позволяет разворачивать и другие сервисы Ceph.
# Вывести все диски кластера
root@node1:~# ceph orch device ls
HOST PATH TYPE DEVICE ID SIZE AVAILABLE REFRESHED REJECT REASONS
node1 /dev/sdb hdd VBOX_HARDDISK_VBaa3afe84-dcde44b9 6000M Yes 18m ago
node1 /dev/sdc hdd VBOX_HARDDISK_VB6cfb6cfd-cbfff2b2 6000M Yes 18m ago
node2 /dev/sdb hdd VBOX_HARDDISK_VB9a0de133-d4c47481 6000M Yes 2m ago
node2 /dev/sdc hdd VBOX_HARDDISK_VB17ff3e6d-ff3a778d 6000M Yes 2m ago
node3 /dev/sdb hdd VBOX_HARDDISK_VBef988c66-7de380c8 6000M Yes 24s ago
node3 /dev/sdc hdd VBOX_HARDDISK_VBb42afeb2-1643e145 6000M Yes 24s ago
# Развернуть сервисы OSD на всех доступных дисках
root@node1:~# ceph orch apply osd --all-available-devices
Scheduled osd.all-available-devices update...
# Посмотреть состояние сервисов osd
root@node1:~# ceph orch ps --daemon_type osd
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID
osd.0 node3 running (1m) 1m ago 1m 26.9M 4096M 18.2.2 7b46ae09e5dc c20a9a449e32
osd.1 node2 running (1m) 1m ago 1m 35.5M 4096M 18.2.2 7b46ae09e5dc d6a3d414084b
osd.2 node1 running (1m) 1m ago 1m 23.8M 4096M 18.2.2 7b46ae09e5dc baae22c434b9
osd.3 node3 running (1m) 1m ago 1m 28.5M 4096M 18.2.2 7b46ae09e5dc 5cb04e5d04b4
osd.4 node2 running (1m) 1m ago 1m 27.6M 4096M 18.2.2 7b46ae09e5dc c2ad3d47caf5
osd.5 node1 running (1m) 1m ago 1m 24.8M 4096M 18.2.2 7b46ae09e5dc 0c1ae30543fc
Создание и настройка пула хранения
Чтобы создать и настроить пул хранения, необходимо указать его имя, тип, политику размещения данных в кластере и связать с приложением.
Начнем с настройки политик. С их помощью мы можем, например, настроить распределение пулов на разных типах носителей, тем самым определить их производительность. В нашем кластере отсутствуют устройства SSD, поэтому переопределим класс некоторых дисков. Данная операция может потребоваться и на боевом кластере, если ваши SSD прячутся за HBA-контроллером и определяются ОС как HDD.
root@node1:~# ceph osd crush rm-device-class osd.2 osd.1 osd.0
done removing class of osd(s): 0,1,2
root@node1:~# ceph osd crush set-device-class ssd osd.2 osd.1 osd.0
set osd(s) 0,1,2 to class 'ssd'
root@node1:~# ceph osd df tree
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS TYPE NAME
-1 0.03415 - 35 GiB 266 MiB 3.8 MiB 0 B 262 MiB 35 GiB 0.74 1.00 - root default
-7 0.01138 - 12 GiB 89 MiB 1.3 MiB 0 B 88 MiB 12 GiB 0.74 1.00 - host node1
5 hdd 0.00569 1.00000 5.9 GiB 62 MiB 948 KiB 0 B 61 MiB 5.8 GiB 1.04 1.40 1 up osd.5
2 ssd 0.00569 1.00000 5.9 GiB 26 MiB 368 KiB 0 B 26 MiB 5.8 GiB 0.44 0.60 0 up osd.2
-3 0.01138 - 12 GiB 89 MiB 1.3 MiB 0 B 88 MiB 12 GiB 0.74 1.00 - host node2
4 hdd 0.00569 1.00000 5.9 GiB 62 MiB 948 KiB 0 B 61 MiB 5.8 GiB 1.04 1.40 1 up osd.4
1 ssd 0.00569 1.00000 5.9 GiB 26 MiB 356 KiB 0 B 26 MiB 5.8 GiB 0.44 0.60 0 up osd.1
-5 0.01138 - 12 GiB 89 MiB 1.3 MiB 0 B 88 MiB 12 GiB 0.74 1.00 - host node3
3 hdd 0.00569 1.00000 5.9 GiB 62 MiB 936 KiB 0 B 61 MiB 5.8 GiB 1.04 1.40 1 up osd.3
0 ssd 0.00569 1.00000 5.9 GiB 26 MiB 356 KiB 0 B 26 MiB 5.8 GiB 0.44 0.60 0 up osd.0
TOTAL 35 GiB 266 MiB 3.8 MiB 0 B 262 MiB 35 GiB 0.74
MIN/MAX VAR: 0.60/1.40 STDDEV: 0.30
В листинге выше видно, что OSD. [0-2] находятся на разных узлах в дереве с корнем default. Кстати, с помощью политик можно создавать несколько корней и за счет этого хранить данные в одном кластере, но на разных хостах, стойках или дата-центрах. Ниже создадим пул данных и применим к нему политику размещения «только на SSD», а далее укажем, что данный пул будем использовать под RBD-образы.
Создаем политику для реплицированных пулов с именем replicated_ssd. Данные будут иметь домен отказа host, а размещаться — на SSD.
root@node1:~# ceph osd crush rule create-replicated replicated_ssd default host ssd
Посмотреть настройки политик можно этой командой:
root@node1:~# ceph osd crush rule dump
Создаем реплицированный пул nomad, «нарезанный» на 32 кусочка (PG, или placement group).
root@node1:~# ceph osd pool create nomad 32 32 replicated
pool 'nomad' created
Назначаем пулу crush правило SIC. Эту настройку необходимо выполнить до того, как залили пул клиентскими данными, иначе подобные действия приведут к их перемещению внутри кластера, что снизит производительность для клиентов.
root@node1:~# ceph osd pool set nomad crush_rule replicated_ssd
set pool 2 crush_rule to replicated_ssd
Указываем, что данный пул будет использоваться под блочные устройства (RBD):
root@node1:~# ceph osd pool application enable nomad rbd
enabled application 'rbd' on pool 'nomad'
Смотрим на дерево кластера. Видно, что OSD.[0-2] содержат по 32 PG:
root@node1:~# ceph osd df tree
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS TYPE NAME
-1 0.03415 - 35 GiB 267 MiB 4.3 MiB 0 B 262 MiB 35 GiB 0.74 1.00 - root default
-7 0.01138 - 12 GiB 89 MiB 1.4 MiB 0 B 88 MiB 12 GiB 0.74 1.00 - host node1
5 hdd 0.00569 1.00000 5.9 GiB 62 MiB 1020 KiB 0 B 61 MiB 5.8 GiB 1.04 1.40 1 up osd.5
2 ssd 0.00569 1.00000 5.9 GiB 27 MiB 440 KiB 0 B 26 MiB 5.8 GiB 0.44 0.60 32 up osd.2
-3 0.01138 - 12 GiB 89 MiB 1.4 MiB 0 B 88 MiB 12 GiB 0.74 1.00 - host node2
4 hdd 0.00569 1.00000 5.9 GiB 62 MiB 1020 KiB 0 B 61 MiB 5.8 GiB 1.04 1.40 1 up osd.4
1 ssd 0.00569 1.00000 5.9 GiB 27 MiB 440 KiB 0 B 26 MiB 5.8 GiB 0.44 0.60 32 up osd.1
-5 0.01138 - 12 GiB 89 MiB 1.4 MiB 0 B 88 MiB 12 GiB 0.74 1.00 - host node3
3 hdd 0.00569 1.00000 5.9 GiB 62 MiB 1020 KiB 0 B 61 MiB 5.8 GiB 1.04 1.40 1 up osd.3
0 ssd 0.00569 1.00000 5.9 GiB 27 MiB 440 KiB 0 B 26 MiB 5.8 GiB 0.44 0.60 32 up osd.0
TOTAL 35 GiB 267 MiB 4.3 MiB 0 B 262 MiB 35 GiB 0.74
MIN/MAX VAR: 0.60/1.40 STDDEV: 0.30
Детально посмотрим на настройку пулов и проверим, что все в порядке. Запись replicated size 3 — настройка по умолчанию, которая указывает, что все данные будут храниться в кластере в трех экземплярах. Ниже я ее называю «размер пула». Также обратите внимание, что у каждого пула есть свой id.
root@node1:~# ceph osd pool ls detail
pool 1 '.mgr' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 21 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr read_balance_score 6.00
pool 2 'nomad' replicated size 3 min_size 2 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 43 flags hashpspool stripe_width 0 application rbd read_balance_score 1.22
Команда выводит служебную информацию о PG: где находятся primary- и secondary-данные, в каком состоянии PG, когда выполнялась проверка целостности. PG начинается с id пула, частью которого она является:
root@node1:~# ceph pg ls
PG OBJECTS DEGRADED MISPLACED UNFOUND BYTES OMAP_BYTES* OMAP_KEYS* LOG LOG_DUPS STATE SINCE VERSION REPORTED UP ACTING SCRUB_STAMP DEEP_SCRUB_STAMP LAST_SCRUB_DURATION SCRUB_SCHEDULING
1.0 2 0 0 0 590368 0 0 413 0 active+clean 9h 27'413 43:1099 [3,5,4]p3 [3,5,4]p3 2024-04-04T23:01:31.874678+0000 2024-04-04T23:01:31.874678+0000 0 periodic scrub scheduled @ 2024-04-05T23:57:41.643668+0000
...
...
2.1e 0 0 0 0 0 0 0 0 0 active+clean 18m 0'0 43:21 [1,2,0]p1 [1,2,0]p1 2024-04-05T17:34:39.443193+0000 2024-04-05T17:34:39.443193+0000 0 periodic scrub scheduled @ 2024-04-07T05:09:41.113721+0000
2.1f 0 0 0 0 0 0 0 0 0 active+clean 18m 0'0 43:22 [2,0,1]p2 [2,0,1]p2 2024-04-05T17:34:39.443193+0000 2024-04-05T17:34:39.443193+0000 0 periodic scrub scheduled @ 2024-04-06T18:34:58.287296+0000
Еще раз посмотрим на состояние кластера и проверим, что все в порядке:
root@node1:~# ceph -s
cluster:
id: 6ba7d13c-642b-11ee-b8b2-c70be95e3c50
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3 (age 19h)
mgr: node1.cauksk(active, since 20h), standbys: node2.ecffgz
osd: 6 osds: 6 up (since 9h), 6 in (since 19h)
data:
pools: 2 pools, 33 pgs
objects: 2 objects, 577 KiB
usage: 267 MiB used, 35 GiB / 35 GiB avail
pgs: 33 active+clean
Настройка авторизации клиента кластера
Авторизация в Ceph подробно описана в документации. Отмечу, что какой бы тип сервиса или клиента ни использовался, Ceph хранит в себе данные о них в виде объектов RADOS. У каждого из них есть определенный ряд возможностей (caps), а также определен уровень доступа к объектам и пулам хранения. Утилиты Ceph ищут файл с ключом авторизации по пути /etc/ceph/ceph.client.{name}.keyring.
Подготовим пользователя для клиента Nomad CSI:
создаем клиента nomad с правами, определенными преднастроенным профилем rbd, с полным доступом к пулу nomad.
root@node1:~# ceph auth get-or-create client.nomad mon 'profile rbd' osd 'profile rbd pool=nomad' mgr 'profile rbd pool=nomad'
[client.nomad]
key = AQA4PxBmD0uiARAAP5M3DrAyNNlr7CjjX6PnNw==
# вывести информацию о настроеных разрешениях клиента можно командой:
root@node1:~# ceph auth get client.nomad
[client.nomad]
key = AQA4PxBmD0uiARAAP5M3DrAyNNlr7CjjX6PnNw==
caps mgr = "profile rbd pool=nomad"
caps mon = "profile rbd"
caps osd = "profile rbd pool=nomad"
Очень важно: клиентские ключи хранятся в обычных текстовых файлах, для которых должен быть настроен соответствующий уровень доступа. Они не шифруют трафик и не обеспечивают секретность сообщений между узлами/сервисами Ceph. Не шифруются и данные в кластере.
Если вам необходимо зашифровать данные, сделать это следует до их отправки в кластер.
Разворачиваем Nomad
Трех узлов, которые у нас есть, недостаточно, чтобы запустить Nomad в кластерном режиме. Но так как мы не собираемся крутить все компоненты инфраструктуры на одних и тех же хостах, запустим Nomad в режиме разработчика на четвертом хосте стенда. Кстати, листинг команд ниже иллюстрирует примеры менеджмента узлов кластера Ceph:
# кластер состоит из трех узлов.
root@node1:~# ceph orch host ls
HOST ADDR LABELS STATUS
node1 192.168.56.5 _admin
node2 192.168.56.6
node3 192.168.56.7
# эта команда разместит ключ администратора на узле кластера node2 и предоставит возможности администратора.
root@node1:~# ceph orch host label add node2 _admin
Added label _admin to host node2
root@node1:~# ceph orch host ls
HOST ADDR LABELS STATUS
node1 192.168.56.5 _admin
node2 192.168.56.6 _admin
node3 192.168.56.7
3 hosts in cluster
# С помощью служебных и пользовательских лейблов можно управлять деплоем сервисов Ceph. Следующая команда запретит размещать любые сервисы Ceph на ноде, кроме OSD. Может быть полезно при обслуживании узла.
root@node1:~# ceph orch host label add node3 _no_schedule
Added label _no_schedule to host node3
root@node1:~# ceph orch ps node3
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID
osd.0 node3 running (3d) 40s ago 3d 42.5M 4096M 18.2.2 7b46ae09e5dc c20a9a449e32
osd.3 node3 running (3d) 40s ago 3d 31.2M 4096M 18.2.2 7b46ae09e5dc 5cb04e5d04b4
root@node1:~# ceph orch ps node2
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID
ceph-exporter.node2 node2 running (4d) 48s ago 4d 7531k - 18.2.2 7b46ae09e5dc 518802272a35
crash.node2 node2 running (4d) 48s ago 4d 2883k - 18.2.2 7b46ae09e5dc 5e8b2fba0923
mgr.node2.ecffgz node2 *:8443,9283,8765 running (4d) 48s ago 4d 128M - 18.2.2 7b46ae09e5dc 2b8bb882c8b0
mon.node2 node2 running (4d) 48s ago 4d 78.2M 2048M 18.2.2 7b46ae09e5dc a42e6d5b346e
node-exporter.node2 node2 *:9100 running (4d) 48s ago 4d 13.3M - 1.5.0 0da6a335fe13 27be86a587c0
osd.1 node2 running (3d) 48s ago 3d 39.4M 4096M 18.2.2 7b46ae09e5dc d6a3d414084b
osd.4 node2 running (3d) 48s ago 3d 27.7M 4096M 18.2.2 7b46ae09e5dc c2ad3d47caf5
# При этом сам кластер будет себя отлично чувствовать:
root@node1:~# ceph health detail
HEALTH_OK
Подробнее об управлении хостами, как всегда, написано в документации.
Перейдем к настройке Nomad. Для этого с локального хоста выполним вход на четвертый узел стенда. Установим Nomad и Consul, а также настроим их запуск в режиме разработчика как systemd-сервисы. Обратите внимание: мы разрешаем Nomad запускать контейнеры в привилегированном режиме. Это необходимо для работы Ceph-CSI Node. Consul — это инструмент от Hashicorp, который позволяет искать службы servicemesh и хранить данные в виде key/value.
:~$kitchen login node4
# Установка репозиториев и пакетов Consul/Nomad
root@node4:~# wget -O- https://apt.releases.hashicorp.com/gpg | gpg --dearmor -o /usr/share/keyrings/hashicorp-archive-keyring.gpg
root@node4:~# echo "deb [signed-by=/usr/share/keyrings/hashicorp-archive-keyring.gpg] https://apt.releases.hashicorp.com $(lsb_release -cs) main" | tee /etc/apt/sources.list.d/hashicorp.list
root@node4:~# apt-get update && sudo apt-get install nomad consul
root@node4:~# cat <<EOF >>/etc/systemd/system/consul.service
[Unit]
Description=consul agent
Requires=network-online.target
After=network-online.target
[Service]
User=root
Group=root
Restart=on-failure
ExecStart=/usr/bin/consul agent -dev
ExecReload=/bin/kill -HUP $MAINPID
KillSignal=SIGINT
[Install]
WantedBy=multi-user.target
EOF
root@node4:~# cat <<EOF >>/etc/systemd/system/nomad.service
[Unit]
Description=nomad agent
Requires=network-online.target
After=network-online.target
[Service]
User=root
Group=root
Restart=on-failure
ExecStart=/usr/bin/nomad agent -dev -config=/etc/nomad.d/nomad.hcl
ExecReload=/bin/kill -HUP $MAINPID
KillSignal=SIGINT
[Install]
WantedBy=multi-user.target
EOF
# скачиваем набор драйверов CNI
root@node4:~# wget https://github.com/containernetworking/plugins/releases/download/v1.4.1/cni-plugins-linux-amd64-v1.4.1.tgz
root@node4:~# mkdir -p /opt/cni/bin && tar -C /opt/cni/bin -xvf ./cni-plugins-linux-amd64-v1.4.1.tgz
# Разрешаем запуск привилегированных контейнеров
root@node4:~# cat >>/etc/nomad.d/nomad.hcl<<EOF
plugin "docker" {
config {
allow_privileged = true
}
}
EOF
# Включаем модуль ядра rbd
root@node4:~# modprobe rbd
root@node4:~# systemctl daemon-reload
root@noed4:~# systemctl start nomad consul
#Проверяем, что все работает.
root@node4:~# consul members
Node Address Status Type Build Protocol DC Partition Segment
node4 127.0.0.1:8301 alive server 1.18.1 2 dc1 default <all>
root@node4:~# nomad node status
ID Node Pool DC Name Class Drain Eligibility Status
69e42712 default dc1 node4 <none> false eligible ready
# Если вы не меняли адресацию в файле kitchen.yml, веб-панель Nomad будет доступна с вашего локального хоста.
Nomad - http://192.168.56.8:4646
Теперь перейдем к настройке коннектора к Ceph. Создадим файлы плагинов Ceph-CSI и запустим их. Нам понадобится информация об адресах сервисов MON и UUID-кластера (поля clusterID, monitors). По сути, мы описываем в этих файлах, из каких контейнеров собрать задания плагинов, какие порты открыть, как подключиться к Ceph, какие драйверы использовать.
Итак, сперва создаем файл ceph-csi-plugin-controller.nomad с таким содержимым:
job "ceph-csi-plugin-controller" {
datacenters = ["dc1"]
group "controller" {
network {
port "metrics" {}
}
task "ceph-controller" {
template {
data = <<EOF
[{
"clusterID": "6ba7d13c-642b-11ee-b8b2-c70be95e3c50",
"monitors": [
"192.168.56.5",
"192.168.56.6",
"192.168.56.7"
]
}]
EOF
destination = "local/config.json"
change_mode = "restart"
}
driver = "docker"
config {
image = "quay.io/cephcsi/cephcsi:v3.3.1"
volumes = [
"./local/config.json:/etc/ceph-csi-config/config.json"
]
mounts = [
{
type = "tmpfs"
target = "/tmp/csi/keys"
readonly = false
tmpfs_options = {
size = 1000000 # size in bytes
}
}
]
args = [
"--type=rbd",
"--controllerserver=true",
"--drivername=rbd.csi.ceph.com",
"--endpoint=unix://csi/csi.sock",
"--nodeid=${node.unique.name}",
"--instanceid=${node.unique.name}-controller",
"--pidlimit=-1",
"--logtostderr=true",
"--v=5",
"--metricsport=$${NOMAD_PORT_metrics}"
]
}
resources {
cpu = 500
memory = 256
}
service {
name = "ceph-csi-controller"
port = "metrics"
tags = [ "prometheus" ]
}
csi_plugin {
id = "ceph-csi"
type = "controller"
mount_dir = "/csi"
}
}
}
}
Затем — файл ceph-csi-plugin-nodes.nomad:
job "ceph-csi-plugin-nodes" {
datacenters = ["dc1"]
type = "system"
group "nodes" {
network {
port "metrics" {}
}
task "ceph-node" {
driver = "docker"
template {
data = <<EOF
[{
"clusterID": "6ba7d13c-642b-11ee-b8b2-c70be95e3c50",
"monitors": [
"192.168.56.5",
"192.168.56.6",
"192.168.56.7"
]
}]
EOF
destination = "local/config.json"
change_mode = "restart"
}
config {
image = "quay.io/cephcsi/cephcsi:v3.3.1"
volumes = [
"./local/config.json:/etc/ceph-csi-config/config.json"
]
mounts = [
{
type = "tmpfs"
target = "/tmp/csi/keys"
readonly = false
tmpfs_options = {
size = 1000000 # size in bytes
}
}
]
args = [
"--type=rbd",
"--drivername=rbd.csi.ceph.com",
"--nodeserver=true",
"--endpoint=unix://csi/csi.sock",
"--nodeid=${node.unique.name}",
"--instanceid=${node.unique.name}-nodes",
"--pidlimit=-1",
"--logtostderr=true",
"--v=5",
"--metricsport=$${NOMAD_PORT_metrics}"
]
privileged = true
}
resources {
cpu = 500
memory = 256
}
service {
name = "ceph-csi-nodes"
port = "metrics"
tags = [ "prometheus" ]
}
csi_plugin {
id = "ceph-csi"
type = "node"
mount_dir = "/csi"
}
}
}
}
Запускаем плагины ceph-csi и проверяем, что все работает:
root@node4:~# nomad job run ceph-csi-plugin-controller.nomad
root@node4:~# nomad job run ceph-csi-plugin-nodes.nomad
root@node4:~# nomad plugin status ceph-csi
ID = ceph-csi
Provider = rbd.csi.ceph.com
Version = v3.3.1
Controllers Healthy = 1
Controllers Expected = 1
Nodes Healthy = 1
Nodes Expected = 1
Allocations
ID Node ID Task Group Version Desired Status Created Modified
e191676d e895f83f nodes 0 run running 3m8s ago 2m57s ago
b1224cdf e895f83f controller 0 run running 3m25s ago 3m14s ago
# в веб интерфейсе также появится информация об этих заданиях.
http://192.168.56.8:4646/ui/jobs
Теперь перейдем к volume.hcl. Данный конфигурационный файл описывает размер диска, параметры монтирования, а также где и под какой учетной записью создать сам диск.
root@node4:~# cat ./prom-volume.hcl
id = "ceph-prometheus-volume"
name = "ceph-prometheus-volume"
type = "csi"
plugin_id = "ceph-csi"
capacity_max = "2G"
capacity_min = "1G"
capability {
access_mode = "single-node-writer"
attachment_mode = "file-system"
}
secrets {
userID = "nomad"
userKey = "AQA4PxBmD0uiARAAP5M3DrAyNNlr7CjjX6PnNw=="
}
parameters {
clusterID = "6ba7d13c-642b-11ee-b8b2-c70be95e3c50"
pool = "nomad"
imageFeatures = "layering"
mkfsOptions = "-t ext4"
}
# Создаем диск.
root@node4:~# nomad volume create ./prom-volume.hcl
Опишем файл задания. Выше мы использовали копипасту из документации Ceph, поэтому запускать будем Prometheus, а ходить за метриками в наш же кластер Ceph. Просто чтобы было не скучно.
Cephadm самостоятельно поднимает сервисы мониторинга и Prometheus. То есть значительную часть работы можно автоматизировать, но мы в этой статье проделаем все вручную, чтобы получше изучить функционал Ceph.
# Собственно, сам файл задания. Подробно все описано в документации Nomad.
root@node4:~# cat ./prometheus.nomad
job "prometheus-server" {
datacenters = ["dc1"]
type = "service"
group "prometheus-server" {
count = 1
//Наш volume, который описывали выше//
volume "ceph-prometheus-volume" {
type = "csi"
attachment_mode = "file-system"
access_mode = "single-node-writer"
read_only = false
source = "ceph-prometheus-volume"
}
//Используем CNI драйвер и мапим порты//
network {
mode = "bridge"
port "prometheus" {
static = 9090
to = 9090
}
}
//Параметры рестарта задания, если что-то идет не так//
restart {
attempts = 10
interval = "5m"
delay = "25s"
mode = "delay"
}
//Настройки самой таски. Имя, драйвер, куда монтировать сетевой диск, из какого образа собрать, какие конфиги прокинуть внутрь, сколько ресурсов выделить//
task "prometheus-server" {
driver = "docker"
volume_mount {
volume = "ceph-prometheus-volume"
destination = "/prometheus"
read_only = false
}
env {
MY_ENV_VARS = "HelloWorld"
}
config {
image = "prom/prometheus:latest"
args = []
ports = ["prometheus"]
volumes = [ "local/prometheus.yml:/etc/prometheus/prometheus.yml" ]
}
template {
data = file("/root/prometheus.yml")
destination = "local/prometheus.yml"
}
resources {
cpu = 500
memory = 256
}
service {
name = "prometheus-server"
port = "prometheus"
check {
path = "/-/helthy"
type = "tcp"
interval = "10s"
timeout = "2s"
}
}
}
}
}
# Файл конфига Prometheus. Указываем на наш кластер и экспортеры.
root@node4:~# cat prometheus.yml
global:
scrape_interval: 10s
scrape_timeout: 10s
evaluation_interval: 10s
scrape_configs:
- job_name: node
honor_timestamps: true
scrape_interval: 5s
scrape_timeout: 5s
metrics_path: /metrics
scheme: http
follow_redirects: true
enable_http2: true
http_sd_configs:
- follow_redirects: true
enable_http2: true
refresh_interval: 1m
url: http://192.168.56.6:8765/sd/prometheus/sd-config?service=node-exporter
- job_name: ceph
scrape_interval: 5s
scrape_timeout: 5s
metrics_path: /metrics
scheme: http
follow_redirects: true
enable_http2: true
http_sd_configs:
- follow_redirects: true
enable_http2: true
refresh_interval: 1m
url: http://192.168.56.6:8765/sd/prometheus/sd-config?service=mgr-prometheus
- job_name: ceph-exporter
scrape_interval: 5s
scrape_timeout: 5s
metrics_path: /metrics
scheme: http
follow_redirects: true
enable_http2: true
http_sd_configs:
- follow_redirects: true
enable_http2: true
refresh_interval: 1m
url: http://192.168.56.6:8765/sd/prometheus/sd-config?service=ceph-exporter
# Ну и, наконец, запускаем задание.
root@node4:~# nomad job run prometheus.nomad
==> 2024-04-11T22:33:00Z: Monitoring evaluation "16580069"
2024-04-11T22:33:00Z: Evaluation triggered by job "prometheus-server"
2024-04-11T22:33:00Z: Evaluation within deployment: "fa62c7ea"
2024-04-11T22:33:00Z: Allocation "0d02495c" created: node "e895f83f", group "prometheus-server"
2024-04-11T22:33:00Z: Evaluation status changed: "pending" -> "complete"
==> 2024-04-11T22:33:00Z: Evaluation "16580069" finished with status "complete"
==> 2024-04-11T22:33:00Z: Monitoring deployment "fa62c7ea"
✓ Deployment "fa62c7ea" successful
2024-04-11T22:33:18Z
ID = fa62c7ea
Job ID = prometheus-server
Job Version = 0
Status = successful
Description = Deployment completed successfully
Deployed
Task Group Desired Placed Healthy Unhealthy Progress Deadline
prometheus-server 1 1 1 0 2024-04-11T22:43:16Z
Нагляднее всего будет перейти в веб-интерфейс Nomad и посмотреть, как это все работает. Можете удалить это задание, а затем запустить его еще раз. Тем не менее, сам Prometheus будет писать данные в сетевое хранилище, что можно увидеть по росту количества объектов в кластере и числу метрик TSDB.
http://192.168.56.8:4646/ui/jobs
http://192.168.56.8:9090/tsdb-status
root@node1:~# ceph -s
...
data:
pools: 2 pools, 33 pgs
objects: 28 objects, 46 MiB
usage: 499 MiB used, 35 GiB / 35 GiB avail
pgs: 33 active+clean
io:
client: 27 KiB/s wr, 0 op/s rd, 4 op/s wr
Где хранятся настройки Ceph
Раньше все параметры и значения объявлялись в /etc/ceph/ceph.conf. Сейчас от этого подхода отказались, так как файл становится нечитаемым из-за большого количества этих параметров у каждого из сервиса Ceph.
Сейчас настройки принято хранить внутри базы сервисов монитора:
# Команда вернет переопределенные параметры сервисов.
root@node1:~# ceph config dump
WHO MASK LEVEL OPTION VALUE RO
global advanced cluster_network 192.168.56.0/24 *
global basic container_image quay.io/ceph/ceph@sha256:06ddc3ef5b66f2dcc6d16e41842d33a3d7f497849981b0842672ef9014a96726 *
mon advanced auth_allow_insecure_global_id_reclaim false
mon advanced public_network 192.168.56.0/24 *
mgr advanced mgr/cephadm/container_init True *
mgr advanced mgr/cephadm/migration_current 6 *
mgr advanced mgr/dashboard/ALERTMANAGER_API_HOST http://node1:9093 *
mgr advanced mgr/dashboard/GRAFANA_API_SSL_VERIFY false *
mgr advanced mgr/dashboard/GRAFANA_API_URL https://192.168.56.5:3000 *
mgr advanced mgr/dashboard/PROMETHEUS_API_HOST http://node1:9095 *
mgr advanced mgr/dashboard/ssl_server_port 8443 *
mgr advanced mgr/orchestrator/orchestrator cephadm
osd advanced osd_memory_target_autotune true
Для каждой опции есть описание, а также указано, может ли она быть применена «на лету». Если это невозможно, MON самостоятельно уведомит сервис о необходимости перезапуска.
root@node1:~# ceph config help osd_memory_target
osd_memory_target - When tcmalloc and cache autotuning is enabled, try to keep this many bytes mapped in memory.
(size, basic)
Default: 4294967296
Minimum: 939524096
Maximum:
Can update at runtime: true
See also: [bluestore_cache_autotune,osd_memory_cache_min,osd_memory_base,osd_memory_target_autotune]
The minimum value must be at least equal to osd_memory_base + osd_memory_cache_min.
Также можно управлять конфигурацией через сокет и утилитой ceph tell. Но есть ограничения: в первом случае управление возможно только с ноды, на которой развернут сервис. А изменения, внесенные обоими путями, не будут отражены в базе монитора. Это может привести к печальным результатам, если вы не единственный администратор кластера.
# Пример использования административного сокета.
root@node1:~# ceph daemon /var/run/ceph/6ba7d13c-642b-11ee-b8b2-c70be95e3c50/ceph-osd.2.asok config show | grep debug_osd
"debug_osd": "1/5",
root@node1:~# ceph daemon /var/run/ceph/6ba7d13c-642b-11ee-b8b2-c70be95e3c50/ceph-osd.7.asok config set debug_osd 10
{
"success": ""
}
# Пример использования ceph tell. Применим debug_osd=10 ко всем сервисам.
root@node1:~# ceph tell osd.* injectargs "--debug_osd 10"
Если вы задали какие-то настройки в /etc/ceph/ceph.conf, Ceph не позволит их поменять через базу монитора, так как файл конфигурации имеет больший приоритет.
Обслуживание кластера
Режим обслуживания
С помощью оркестратора мы можем переместить хост в режим обслуживания. В результате все сервисы будут корректно остановлены, а мы сможем выключить узел и провести необходимые работы. Достаточно ввести команду:
# Переводим кластер в режим обслуживания.
root@node1:~# ceph orch host maintenance enter node3
Daemons for Ceph cluster 6ba7d13c-642b-11ee-b8b2-c70be95e3c50 stopped on host node3. Host node3 moved to maintenance mode
root@node1:~# ceph orch host ls
HOST ADDR LABELS STATUS
node1 192.168.56.5 _admin
node2 192.168.56.6 _admin
node3 192.168.56.7 _admin Maintenance
3 hosts in cluster
root@node1:~# ceph -s
cluster:
id: 6ba7d13c-642b-11ee-b8b2-c70be95e3c50
health: HEALTH_WARN
1 host is in maintenance mode
1/3 mons down, quorum node1,node2
2 osds down
1 OSDs or CRUSH {nodes, device-classes} have {NOUP,NODOWN,NOIN,NOOUT} flags set
1 host (2 osds) down
Degraded data redundancy: 124/372 objects degraded (33.333%), 32 pgs degraded
services:
mon: 3 daemons, quorum node1,node2 (age 17s), out of quorum: node3
mgr: node2.ecffgz(active, since 7h), standbys: node1.cauksk
osd: 6 osds: 4 up (since 16s), 6 in (since 5h)
data:
pools: 2 pools, 33 pgs
objects: 124 objects, 397 MiB
usage: 2.2 GiB used, 33 GiB / 35 GiB avail
pgs: 124/372 objects degraded (33.333%)
32 active+undersized+degraded
1 active+undersized
io:
client: 4.0 KiB/s wr, 0 op/s rd, 0 op/s wr
В выводе команды видим, что кластер в статусе WARN, а чуть ниже причины.
- Недоступен один сервис монитора MON и нарушен кворум (в идеале сервисов MON должно быть пять, но мало кто делает больше трех. Кстати, их все-таки лучше держать на отдельных узлах, если у вас большая инсталляция).
- Два сервиса OSD находятся в состоянии down.
- Один узел в состоянии down.
- 33% данных в деградированном состоянии (на данный момент в кластере отсутствует часть данных).
Обратите внимание, что клиентский ввод/вывод не остановился. Заглянув в веб-панель Nomad и Prometheus, вы в этом легко убедитесь.
Вернем как было и посмотрим, что произойдет:
# Выводим узел из режима обслуживания.
root@node1:~# ceph orch host maintenance exit node3
Ceph cluster 6ba7d13c-642b-11ee-b8b2-c70be95e3c50 on node3 has exited maintenance mode
# После запуска всех сервисов на узле в кластере запускается процесс восстановления данных
root@node1:~# ceph -s
cluster:
id: 6ba7d13c-642b-11ee-b8b2-c70be95e3c50
health: HEALTH_WARN
Reduced data availability: 10 pgs peering
services:
mon: 3 daemons, quorum node1,node2,node3 (age 8s)
mgr: node2.ecffgz(active, since 7h), standbys: node1.cauksk
osd: 6 osds: 6 up (since 4s), 6 in (since 6h)
data:
pools: 2 pools, 33 pgs
objects: 124 objects, 397 MiB
usage: 2.5 GiB used, 33 GiB / 35 GiB avail
pgs: 69.697% pgs not active
23 peering
10 active+clean
io:
client: 1.7 MiB/s rd, 22 op/s rd, 0 op/s wr
recovery: 685 KiB/s, 0 objects/s
# Через какое-то время node3 догоняет изменения, если они были, и кластер вновь работает.
root@node1:~# ceph -s
cluster:
id: 6ba7d13c-642b-11ee-b8b2-c70be95e3c50
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3 (age 20s)
mgr: node2.ecffgz(active, since 7h), standbys: node1.cauksk
osd: 6 osds: 6 up (since 16s), 6 in (since 6h)
data:
pools: 2 pools, 33 pgs
objects: 124 objects, 397 MiB
usage: 2.2 GiB used, 33 GiB / 35 GiB avail
pgs: 33 active+clean
io:
client: 24 KiB/s wr, 0 op/s rd, 3 op/s wr
recovery: 196 KiB/s, 0 objects/s
Замена диска
А что, если нам надо заменить диск? В первую очередь, отмотаем немного назад и вспомним, каким образом мы развернули сервисы OSD. Мы указали, что используем все незанятые диски кластера. Для того, чтобы новые диски не добавлялись в кластер автоматически, необходимо повесить флаг –unmanaged.
ceph orch apply osd --all-available-devices --unmanaged=true
Теперь удаляем OSD с пометкой, что будет проведена замена, и смотрим статус:
root@node1:~# ceph orch osd rm 0 --replace
Scheduled OSD(s) for removal.
VG/LV for the OSDs won't be zapped (--zap wasn't passed).
Run the `ceph-volume lvm zap` command with `--destroy` against the VG/LV if you want them to be destroyed.
root@node1:~# ceph orch osd rm status
OSD HOST STATE PGS REPLACE FORCE ZAP DRAIN STARTED AT
0 node3 draining 32 True False False 2024-04-12 15:02:05.987153
Мы ожидали, что все PG на удаляемом OSD будут эвакуированы и диск будет удален, но этого не произошло, так как путей для эвакуации нет. В настройках пула (по умолчанию) Nomad указано, что его размер равен трем. Когда все в порядке, в кластере должно быть минимум три копии данных, а минимальный размер— две копии.
root@node1:~# ceph osd pool ls detail
...
pool 2 'nomad' replicated size 3 min_size 2 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 131 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd read_balance_score 1.78
Мы можем обойти это двумя путями. Первый — сменить класс устройства osd.3 на SSD, размещенный на той же ноде. Второй — уменьшить размер пула до двух. Попробуем именно этот вариант, но лишь потому, что классы менять мы уже научились (хотя в проде так, конечно, лучше не делать).
root@node1:~# ceph osd pool set nomad size 2
set pool 2 size to 2
Все PG были удалены. В кластере прошел процесс remap, то есть перераспределение PG:
root@node1:/home/vagrant# ceph -s
cluster:
id: 6ba7d13c-642b-11ee-b8b2-c70be95e3c50
health: HEALTH_OK
...
pgs: 122/372 objects misplaced (32.796%)
32 active+clean+remapped
1 active+clean
Удалим разметку, чтобы эмулировать замену диска, на котором был размещен osd.0. Кстати, а какой это диск? Сейчас выясним. Это легко делать с помощью утилиты ceph-volume. Зайдем на node3 и удалим разметку:
root@node3:~# apt install ceph-volume -y
root@node3:~# ceph-volume lvm list
====== osd.0 =======
[block] /dev/ceph-28366058-ad51-452c-af65-3a0114b4a2f0/osd-block-d6b1004d-bdfe-4d01-b010-31940432d912
block device /dev/ceph-28366058-ad51-452c-af65-3a0114b4a2f0/osd-block-d6b1004d-bdfe-4d01-b010-31940432d912
block uuid mkuCJu-wyBv-YiFn-hTlp-tzy5-p503-73Y328
cephx lockbox secret
cluster fsid 6ba7d13c-642b-11ee-b8b2-c70be95e3c50
cluster name ceph
crush device class
encrypted 0
osd fsid d6b1004d-bdfe-4d01-b010-31940432d912
osd id 0
osdspec affinity all-available-devices
type block
vdo 0
devices /dev/sdb
root@node3:~# ceph-volume lvm zap /dev/sdb
--> Zapping: /dev/sdb
--> Zapping lvm member /dev/sdb.
Затем — обновим список доступных устройств:
root@node1:~# ceph orch device ls node3 --refresh
HOST PATH TYPE DEVICE ID SIZE AVAILABLE REFRESHED REJECT REASONS
node3 /dev/sdb hdd VBOX_HARDDISK_VBef988c66-7de380c8 6000M Yes 0s ago
node3 /dev/sdc hdd VBOX_HARDDISK_VBb42afeb2-1643e145 6000M No 0s ago Has a FileSystem, Insufficient space (<10 extents) on vgs, LVM detected
Снимем флаг unmaneged и увеличим размер пула до трех. Видно, что PG в кластере снова «поехали»: в этот раз запустился процесс ребалансировки. Кроме того, пул nomad разъехался равномерно по трем дискам.
root@node1:~# ceph osd df tree class ssd
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS TYPE NAME
-1 0.03415 - 18 GiB 1.4 GiB 763 MiB 4 KiB 625 MiB 16 GiB 7.71 1.00 - root default
-7 0.01138 - 5.9 GiB 379 MiB 259 MiB 4 KiB 120 MiB 5.5 GiB 6.32 0.82 - host node1
2 ssd 0.00569 1.00000 5.9 GiB 379 MiB 259 MiB 4 KiB 120 MiB 5.5 GiB 6.32 0.82 19 up osd.2
-3 0.01138 - 5.9 GiB 714 MiB 252 MiB 0 B 461 MiB 5.2 GiB 11.90 1.54 - host node2
1 ssd 0.00569 1.00000 5.9 GiB 714 MiB 252 MiB 0 B 461 MiB 5.2 GiB 11.90 1.54 24 up osd.1
-5 0.01138 - 5.9 GiB 295 MiB 251 MiB 0 B 44 MiB 5.6 GiB 4.92 0.64 - host node3
0 ssd 0.00569 1.00000 5.9 GiB 295 MiB 251 MiB 0 B 44 MiB 5.6 GiB 4.92 0.64 21 up osd.0
TOTAL 18 GiB 1.4 GiB 763 MiB 4.2 KiB 625 MiB 16 GiB 7.71
После восстановления размера пула ожидаем вновь равномерного распределения, по 32 PG на OSD.
root@node1:~# ceph osd pool set nomad size 3
set pool 2 size to 3
Опять произошел процесс recovery, все PG восстановились в трех экземплярах:
root@node1:~# ceph osd df tree class ssd
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS TYPE NAME
-1 0.03415 - 18 GiB 1.7 GiB 1.1 GiB 4 KiB 630 MiB 16 GiB 9.85 1.00 - root default
-7 0.01138 - 5.9 GiB 484 MiB 380 MiB 4 KiB 104 MiB 5.4 GiB 8.08 0.82 - host node1
2 ssd 0.00569 1.00000 5.9 GiB 484 MiB 380 MiB 4 KiB 104 MiB 5.4 GiB 8.08 0.82 32 up osd.2
-3 0.01138 - 5.9 GiB 842 MiB 380 MiB 0 B 461 MiB 5.0 GiB 14.04 1.43 - host node2
1 ssd 0.00569 1.00000 5.9 GiB 842 MiB 380 MiB 0 B 461 MiB 5.0 GiB 14.04 1.43 32 up osd.1
-5 0.01138 - 5.9 GiB 446 MiB 380 MiB 0 B 65 MiB 5.4 GiB 7.43 0.75 - host node3
0 ssd 0.00569 1.00000 5.9 GiB 446 MiB 380 MiB 0 B 65 MiB 5.4 GiB 7.43 0.75 32 up osd.0
TOTAL 18 GiB 1.7 GiB 1.1 GiB 4.2 KiB 630 MiB 16 GiB 9.85
MIN/MAX VAR: 0.75/1.43 STDDEV: 2.97
Кластер перешел в состояние OK, клиентский ввод/вывод не прекращался, задание в NOMAD не падало, хранилище Prometheus не отключалось. Последнее видно на графике метрики и в uptime задания Prometheus:
root@node4:~# nomad alloc exec -it -task prometheus-server 0d02495c /bin/sh
/prometheus $ uptime
15:51:33 up 3 days, 4:47, 0 users, load average: 0.33, 0.41, 0.42
Заключение
Хотя статья получилась объемной, уложить в нее получилось лишь малую часть даже базовых операций в Ceph. Здесь не упомянуты другие типы доступа к данным, специализированные глобальные флаги, квоты, управление процессом восстановления и многое другое. Впрочем, это хранилище довольно легко изучить самостоятельно, поэтому все в ваших руках.




