

В этой статье понятным языком разберем, как эффективно внедрить слой кэширования на связке Redis + Spring Boot 3 / Java 21 и пробежимся по базовым командам Redis.
Статья подготовлена Павлом Сорокиным, автором одноименного YouTube-канала.
Что такое кэширование
Договоримся о терминах.
Кэш — это дополнительный «быстрый карман» данных рядом с приложением.
Мы складываем туда то, что часто читают и относительно редко меняют. За счет этого уменьшаем походы в «медленные места» — диск и сеть, убирая пиковые задержки (так называемые «хвосты» p95/p99). Давайте посмотрим на порядок величин, чтобы почувствовать разницу.
Интуитивная пирамида скоростей:
- CPU L1/L2 — наносекунды;
- RAM — десятки–сотни наносекунд;
- локальный SSD — десятки–сотни микросекунд;
- сеть / удаленная БД — миллисекунды и выше.

Кэш фактически сдвигает большинство чтений из миллисекунд в микро‑ и наносекунды. Поэтому эффект заметен не только по среднему времени ответа, но и по «хвостам» — система становится стабильнее.
Кэш уместен для хранения часто просматриваемых данных, которые редко меняются. Например, для карточек продуктов, профилей пользователей или различных справочников. Также кэширование подходит для ресурсоемких операций: результаты «дорогих» агрегаций, объемные/сложные DTO для API и ответы внешних сервисов, которые хочется переиспользовать.
Избегать кэша следует для строго консистентных вещей вроде балансов и остатков. Он также неэффективен для очень часто меняющихся сущностей и гигантских объектов с дорогой сериализацией, которые лишь создают лишнюю нагрузку.
Важная мысль: кэш — это всегда компромисс. Да, мы ускоряем чтения, но платим риском устаревших данных. Значит, нам нужны TTL и продуманная инвалидация, то есть удаление устаревших версий.
Сразу расскажу о термине, который еще встретится не раз:
Время жизни (TTL) — это срок действия ключа, необходимый для предотвращения «зависания» блокировки в случае падения инстанса. Его нужно выбирать с запасом, превышающим ожидаемую длительность обработки.
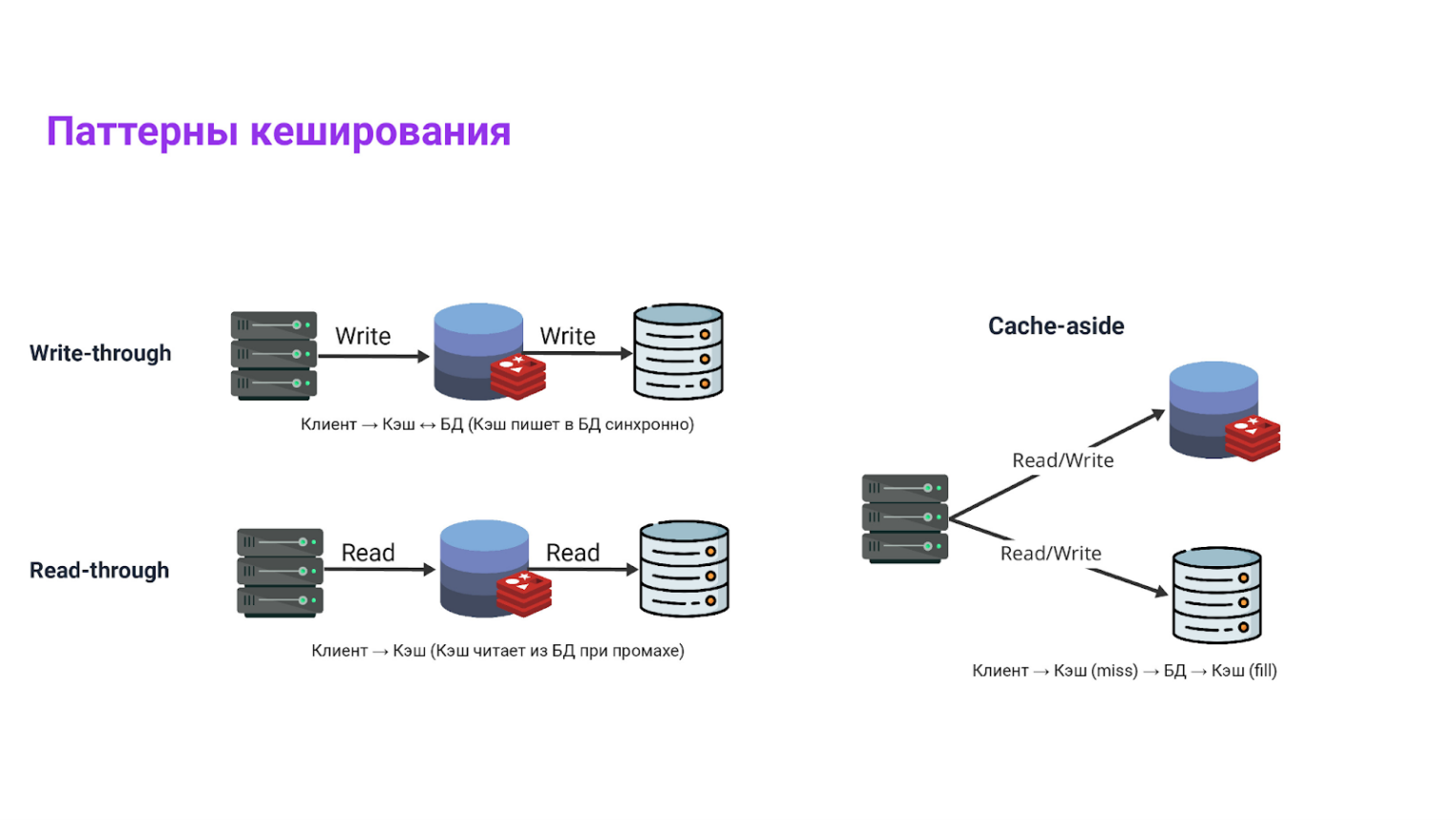
Паттерны кэширования
Паттернов много, но если вы на Java/Spring и используете Redis, в 90% случаев побеждает cache‑aside.
Что реально используют с Redis:
- Cache‑aside (наш выбор). Приложение сначала читает кэш; при промахе идет в БД, получает данные и само кладет их в кэш. На запись — инвалидация. Просто, прозрачно, предсказуемо.
- Read‑through. Кэш сам умеет грузить данные при промахе. В мире Spring это похоже на
@Cacheable, где «загрузчик» — ваш метод. - Write‑through. Пишем одновременно в БД и кэш. Запись дороже и чаще встречается в встроенных кэшах платформ.
- Write‑behind. Пишем в БД отложено. Рискованно для многих доменов — используйте только если четко понимаете последствия.
С Redis в продакшене почти всегда делают cache‑aside: вы точно знаете, где положили, где удалили и какой TTL стоит.
Быстрый старт: поднимаем Redis в Docker и щупаем команды
Начнем с практики. Запустим локальный Redis одной командой:
docker run --name redis -p 6379:6379 -d redis:7-alpine
Проверим, что работает:
docker exec -it redis redis-cli
PING # → PONG
Если у вас в консоли похожий вывод, то Redis запущен успешно и работает.

Основные команды Redis и что они делают
Ключевой момент — в Redis по умолчанию все основано на парах «ключ – значение» (строки или массив байт). Для кэша просто читаем и кладем обычные строки, которые могут быть числами, каким-то текстом или JSON-объектами.
Этот тип данных (строки) чаще всего используют, когда нужно быстро получать или класть объект по ID без сложных вычислений. Значение сохраняется целиком — если большой объект, то может быть очень дорого помещать его полностью в кэш. В этом случае лучше помещать какую-то его часть, к которой чаще всего происходит обращение.
SET key value [EX sec] [PX ms] [NX|XX]
Это синтаксис, который записывает значение под ключом. Одновременно можно указать время жизни (EX в секундах / PX в миллисекундах), а также условия. NX — только если ключ еще не существует, XX — только если ключ уже существует.
Пример:
# Устанавливает ключ user:1 со значением Alice и временем истечения 600 секунд
SET user:1 «Alice» EX 600
Используйте команду при создании записи в кэш-хранилище с TTL, либо для реализации одноразовой операции, например, только если еще нет. Нюансы использования: Если время жизни задается отдельно через EXPIRE, между SET и EXPIRE существует микровременной промежуток, в котором ключ может жить без срока.
GET key
Это синтаксис команды, которая возвращает значение по ключу, или (nil), если ключ отсутствует. Используется для чтения из кэша и его проверки перед обращением к более медленной подсистеме.
Пример:
SET user:1 «Alice»
GET user:1 # Вернет «Alice»
DEL key … / UNLINK key …
Тот же синтаксис команд, но уже для удаления ключа или ключей из хранилища. DEL — синхронное удаление, может блокировать при больших значениях. UNLINK — неблокирующее удаление (удаляет фоновой задачей).
Пример:
DEL user:1 # удаляет ключ и связанное с ним значение
Пригодиться, когда необходимо инвалидировать кэш-запись, например, после обновления или удаления объекта. Но, для больших коллекций предпочтителен UNLINK, чтобы не тормозить Redis.
TTL key / PTTL key
Синтаксис, с помощью которого возвращают время жизни ключа. То есть, TTL возвращает секунды, PTTL — миллисекунды. При значении -1 срок не задан, -2 — ключ отсутствует.
Пример:
TTL token:xyz # Вернет оставшееся время жизни ключа
Используйте при диагностике либо мониторинге, чтобы узнать сколько еще живет кэш-запись, если нам это необходимо.
EXPIRE key sec / PEXPIRE key ms / PERSIST key
Команды, которые устанавливают/изменяют срок жизни ключа или делают его бессрочным (PERSIST).
Пример:
EXPIRE token:xyz 120 # устанавливает ключу срок жизни 120 секунд
PERSIST token:xyz # убирает время жизни ключа, теперь он «вечно» хранится
Применяют команду если данные обновились и нужно продлить срок жизни, либо убрать TTL, либо наоборот уменьшить.
MSET k1 v1 k2 v2 … / MGET k1 k2 …
Пакетные операции: MSET сразу записывает несколько ключей-значений, MGET — считывает несколько ключей. Уменьшают количество RTT (Round-Trip Time) при групповых операциях.
Пример:
MSET user:1 Bob user:2 Kate # устанавливает одной командой две пары ключ-значение
MGET user:1 user:2 # получаем одной командой значения сразу по двум ключам — вернет «Bob» и «Kate»
Для пакетной записи и загрузки сразу нескольких связанных объектов (например, несколько карточек продуктов).
INCR/INCRBY/DECRBY
Атомарные операции инкремента или декремента числового значения, хранящегося как строка. Если ключ отсутствует, считается как 0 перед выполнением.
Пример:
INCR demo:ctr:page
INCRBY demo:ctr:page 10
DECRBY demo:ctr:page 2
Реализуйте через счетчики (просмотры, лимиты). Но помните: значение должно быть числом, иначе попытка увеличения вызовет ошибку.
Best practice — дизайн ключей
Хороший дизайн ключей помогает ясности и масштабируемости. Рекомендуется использовать читаемые префиксы, версии и ID объекта.
Пример схемы: resource:version:{id} → product:v1:{42}
Примеры дизайнов:
product:v1:{id}
rate:{client}:{window}
lock:{key}
TTL и точность
Удаление просроченных ключей в Redis происходит лениво (при обращении) и фоново — поэтому точность может варьироваться около одной секунды. Если система требует удаление через доли секунды, то стоит учитывать, что ключ может находиться в живых чуть дольше.
А если хочется максимально точное поведение — либо уменьшайте TTL, либо применяйте дополнительную логику по проверке того не была ли прочитана старая запись.
Больше подобных материалов:
Подготовка проекта — Spring Boot + Redis
Приступим к написанию кода. Чтобы все заработало как надо, нужны три простых шага.
- Подключить библиотеку-стартер для Spring + Redis
В вашем pom.xml или build.gradle добавьте зависимость типа:
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
Это упаковка, которая сразу дает вам базовую интеграцию Spring Data Redis.
- Настроить подключение к Redis
В application.properties или application.yml пропишите настройки подключения:
spring.redis.host=localhost
spring.redis.port=6379
spring.redis.timeout=60000
# если пароль нужен:
spring.redis.password=strong-password
После этого Spring уже будет знать, где находится Redis.
- Выбрать шаблон работы с Redis: StringRedisTemplate или RedisTemplate
StringRedisTemplate — доступен сразу, ничего дополнительно настраивать не надо, он работает с ключами и значениями как с обычными строками. Прокидываем в нужный сервис просто как обычный Bean.
Если вы хотите сохранять объекты (например, сущности) с сериализацией json, тогда используйте RedisTemplate<String, YourType>, и настройте сериализаторы.
Пример конфигурации:
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, ProductEntity> redisTemplate(RedisConnectionFactory cf) {
RedisTemplate<String, ProductEntity> tpl = new RedisTemplate<>();
tpl.setConnectionFactory(cf);
tpl.setKeySerializer(new StringRedisSerializer());
tpl.setValueSerializer(new GenericJackson2JsonRedisSerializer());
return tpl;
}
}
Таким образом, вы можете сразу в коде писать и читать объекты, а не вручную переводить их в json-строки.
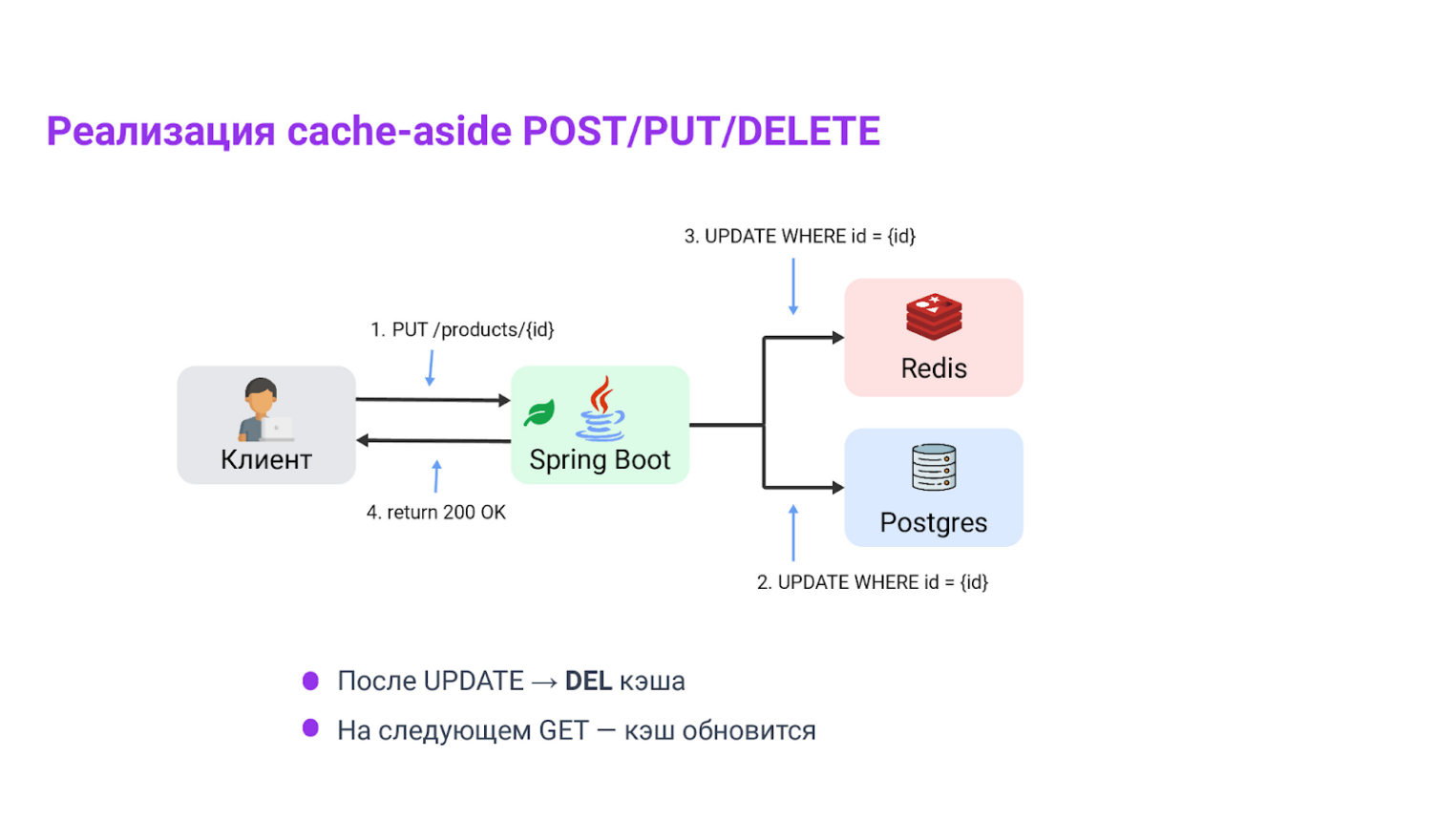
Cache-aside в Spring на практике
Начнем с ручной версии — так понятнее, что происходит под капотом. Рассмотрим два подхода.
- Вариант A —
StringRedisTemplate, где значение хранится как json-строка. - Вариант B —
RedisTemplate<String, ProductEntity>, где сразу сохраняется объект.
В обеих версиях реализована логика: сначала проверка кэша, если промах, то чтение из БД и запись в кэш с TTL.
Вариант A: StringRedisTemplate
Мы будем вручную сохранять данные в строковом виде: ключ и значение — строки. Это подходит для сценариев, когда значение — объект, который переводится в json-строку. Но он требует, чтобы мы сами заботились о преобразовании объектов в строки (сериализация и десериализация).
@Service
@RequiredArgsConstructor
public class ProductService {
private final ProductRepository repo;
private final StringRedisTemplate redis;
private final ObjectMapper mapper;
private static final String CACHE_KEY_PREFIX = "product:";
private static final Duration TTL = Duration.ofMinutes(10);
public Optional<ProductDto> getById(long id) {
log.info("Getting product: id={}", id);
String key = CACHE_KEY_PREFIX + id;
// Проверяем, есть ли запись в кэш-хранилище
String hit = redis.opsForValue().get(key);
if (hit != null) {
return Optional.of(Json.read(hit, ProductDto.class));
}
// Промах: загружаем из БД
return repo.findById(id)
.map(dto -> {
// Записываем в кэш, сразу с TTL
redis.opsForValue().set(key, mapper.writeValueAsString(dto), TTL);
return dto;
})
.orElseThrow(() -> new RuntimeException("Product not found: " + id));
}
}
Вариант B: RedisTemplate
Сейчас рассмотрим как можно обойти необходимость ручной сериализации-десериализации (вручную переводить в json-строку и обратно): мы используем RedisTemplate<String, ProductEntity>.
@Service
@AllArgsConstructor
public class ManualCachingProductService {
private final ProductRepository productRepository;
private final RedisTemplate<String, ProductEntity> redisTemplate;
private static final String CACHE_KEY_PREFIX = "product:";
private static final Duration TTL = Duration.ofMinutes(10);
public ProductEntity getById(Long id) {
log.info("Getting product: id={}", id);
String cacheKey = CACHE_KEY_PREFIX + id;
// Проверяем кэш
ProductEntity cached = redisTemplate.opsForValue().get(cacheKey);
if (cached != null) {
log.info("Product found in cache: id={}", id);
return cached;
}
log.info("Product not found in cache: id={}", id);
// Загружаем из базы
ProductEntity fromDb = productRepository.findById(id)
.orElseThrow(() -> new RuntimeException("Product not found: " + id));
// Кэшируем объект с TTL
redisTemplate.opsForValue().set(cacheKey, fromDb, TTL);
log.info("Product cached: id={}", id);
return fromDb;
}
}
Инвалидация кэша при изменениях
Когда данные обновляются или удаляются — необходимо удалить соответствующую кэш-запись, чтобы старые данные не выдавались. В этой версии, после успешного сохранения или удаления в БД мы просто удаляем запись из кэша. Это удобно и понятно для большинства CRUD-кейсов.
public ProductEntity update(Long id, ProductUpdateRequest updateRequest) {
log.info("Updating product in DB: {}", id);
ProductEntity product = productRepository.findById(id)
.orElseThrow(() -> new RuntimeException("Product not found: " + id));
// Применяем изменения
if (updateRequest.price() != null) {
product.setPrice(updateRequest.price());
}
if (updateRequest.description() != null) {
product.setDescription(updateRequest.description());
}
// Сохраняем в БД
var saved = productRepository.save(product);
// Удаляем кэш-запись — инвалидация
String cacheKey = CACHE_KEY_PREFIX + id;
redisTemplate.delete(cacheKey);
log.info("Cache invalidated for updated product: id={}", id);
return saved;
}
public void delete(Long id) {
log.info("Deleting product from DB: {}", id);
if (!productRepository.existsById(id)) {
throw new RuntimeException("Product not found: " + id);
}
productRepository.deleteById(id);
// Также удаляем кэш-запись
String cacheKey = CACHE_KEY_PREFIX + id;
redisTemplate.delete(cacheKey);
log.info("Cache invalidated for deleted product: id={}", id);
}
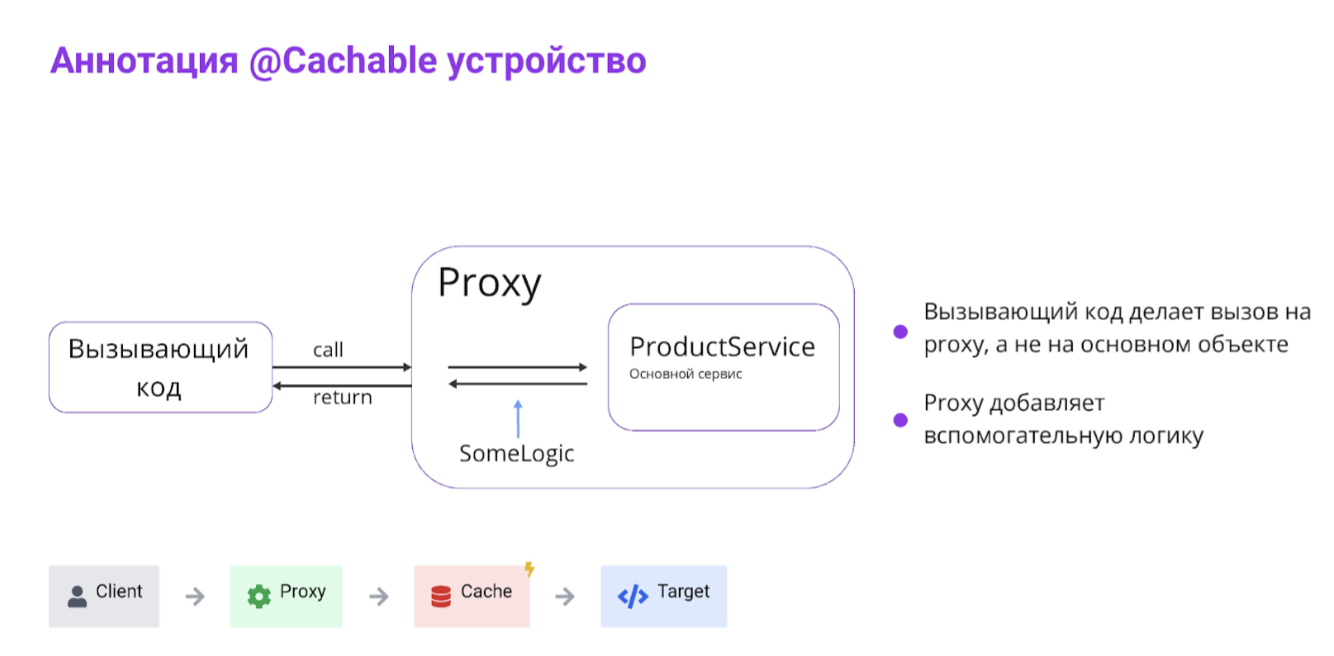
Применяем Spring Cache — аннотации и AOП
После того как мы реализовали кэширование вручную, стоит вспомнить, что в Spring уже есть готовая инфраструктура. Она позволяет делать то же самое буквально в пару аннотаций.
Чтобы использовать встроенные аннотации: @Cacheable — для кэширования результатов, и @CacheEvict — для очистки кэша после изменений.
Необходимо создать Bean RedisCacheManager и вся рутина по управлению кэшем ляжет на Spring. Так что, когда кэш‑логика типовая, проще довериться инфраструктуре.
CacheManager
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public RedisCacheManager cacheManager(RedisConnectionFactory cf) {
RedisCacheConfiguration cfg = RedisCacheConfiguration.defaultCacheConfig()
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(
new GenericJackson2JsonRedisSerializer()))
.entryTtl(Duration.ofMinutes(10))
.disableCachingNullValues();
return RedisCacheManager.builder(cf).cacheDefaults(cfg).build();
}
}
Использование аннотаций Spring
@Service
@RequiredArgsConstructor
public class ProductCachedService {
private final ProductRepository repo;
@Cacheable(value = "product:byId", key = "#id", sync = true)
public Optional<ProductDto> getById(long id) {
// При первом вызове (промахе) будет выполнен метод и результат закэширован
return repo.findById(id);
}
@CacheEvict(value = "product:byId", key = "#id")
@Transactional
public void update(long id, UpdateProduct cmd) {
// Метод записи — сперва изменяем в БД, затем удаляется кэш-запись
var p = repo.findByIdOrThrow(id);
p.apply(cmd);
}
}
Нюансы АОП
При работе со Spring Cache нужно понимать, что все строится на базе АОП (аспектно-ориентированного программирования) через прокси, которые перехватывают вызовы методов. Это значит, что:
- если метод вызывается внутри того же класса (self-invocation), то прокси не сработает, и кэш не применится;
- методы, помеченные как final или private, не могут быть перехвачены, поэтому кэширование на них не действует;
- параметр
sync=trueсинхронизирует вычисления только в пределах одного инстанса приложения, то есть защищает от дубликатов вызовов на конкретной ноде, но не является распределенным локом. Если у вас несколько инстансов приложения, то каждый будет работать со своим кэшем независимо.
Эксплуатация Redis: RDB/AOF, восстановление, репликация и кластер
Redis — in‑memory. Чтобы переживать рестарты и не терять все содержимое, в реальных системах включают персистентность.
Есть два базовых механизма: RDB и AOF.

- RDB (Redis Database) — периодические бинарные снимки памяти.
Экономно по диску и CPU, быстро грузится на старте, но можно потерять изменения между снимками.
- AOF (Append‑Only File) — журнал всех команд записи. Режимы
always/everysec/noуправляют частотой fsync. На практике чаще берутeverysec: максимум минус одна секунда команд, зато скорость адекватная. Чтобы журнал не разрастался, используется AOF‑rewrite.
Если AOF включен и цел — он применится первым (самый полный источник истины). Если AOF нет — берем последний RDB‑снимок.
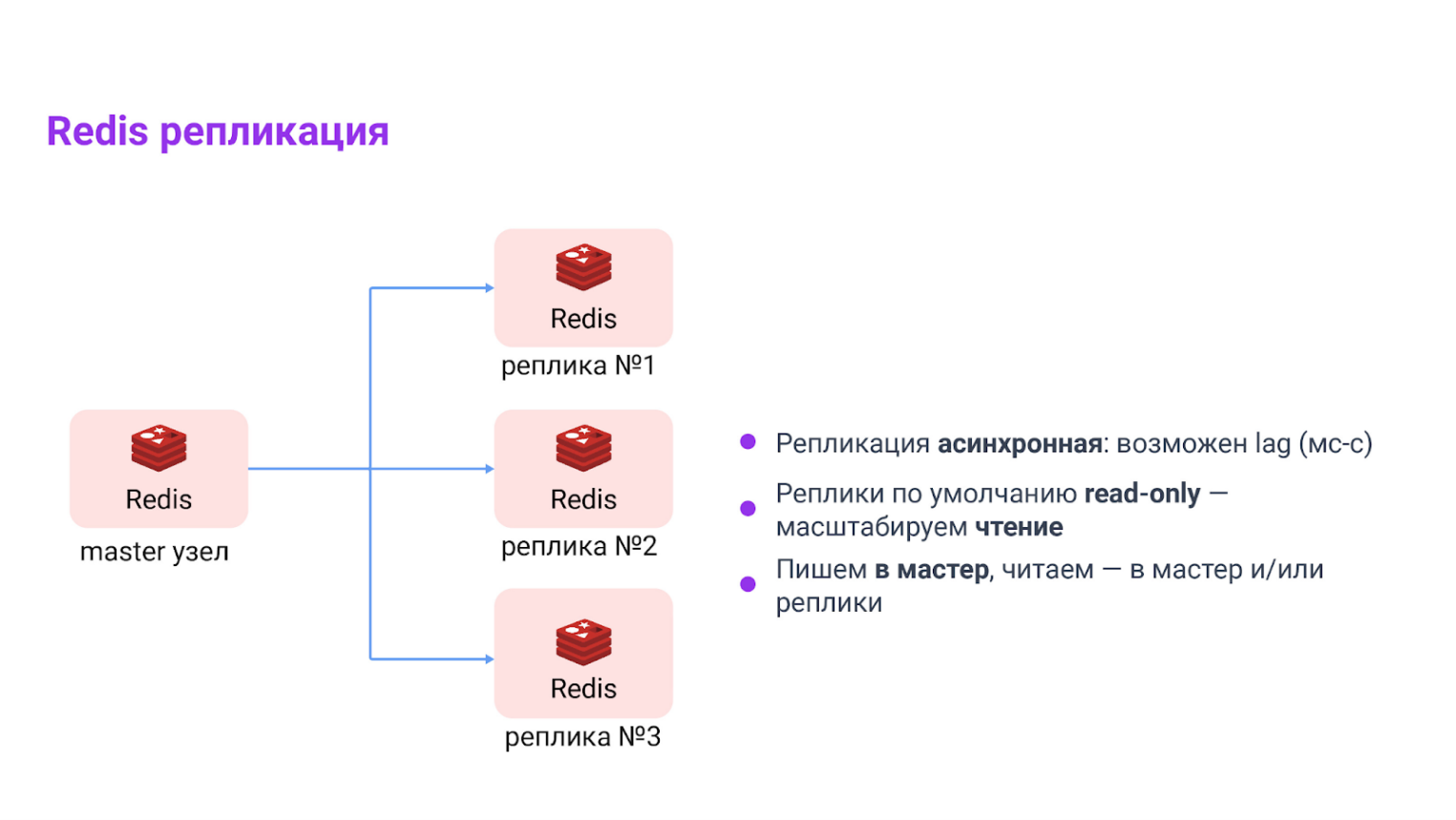
Репликация
Реплики в Redis используются для того, чтобы разгрузить мастер и обеспечить устойчивость. Мы можем направить все операции чтения на реплики, а записи — на мастер. При этом важно помнить, что репликация асинхронная, и данные на реплике могут немного отставать (replication lag).
Один мастер → одна или несколько реплик (асинхронно). Это про масштабирование чтения и про отказоустойчивость. Имейте в виду replication lag: записали на мастер — реплика может отставать.
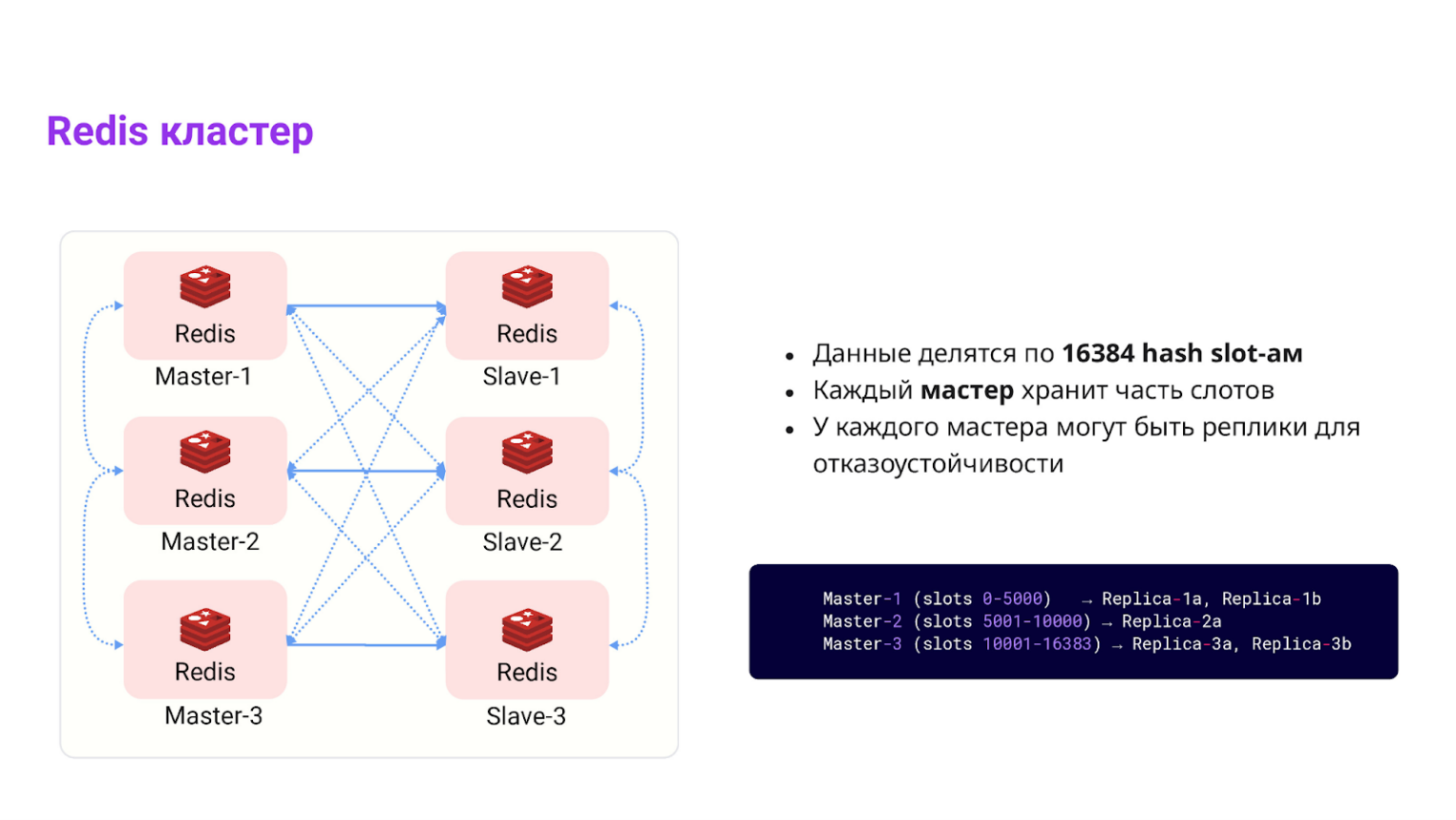
Redis Cluster — масштабирование по мастерам
Когда данных становится много и одного мастер-инстанса уже не хватает, Redis позволяет поднять кластер. Он делит все пространство ключей на 16 384 слота и распределяет их между несколькими мастерами. Благодаря этому мы можем горизонтально масштабировать кэш, не меняя логику работы приложения.
Ключ живет на одном мастере, у которого есть свои копии (реплики). Если мастер падает, то есть выходит из строя, запускается процесс автофейловера (auto-failover).
Auto-failover — это автоматическое переключение на одну из реплик, чтобы система продолжала работу без стороннего вмешательства.
Для операций над несколькими ключами используйте хэштеги {}. Они заставляют Redis сохранять разные ключи (например, user:{42}:cart и user:{42}:promo) в один и тот же слот. Это необходимо, так как Redis Cluster умеет обрабатывать транзакции только внутри одного слота.
Паттерн: Fixed‑Window Rate Limiter
Паттерн нужен, чтобы не позволить одному шумному клиенту «съесть» всю пропускную способность и чтобы сервис оставался стабильным при всплесках нагрузки. Это такой «предохранитель» перед БД.
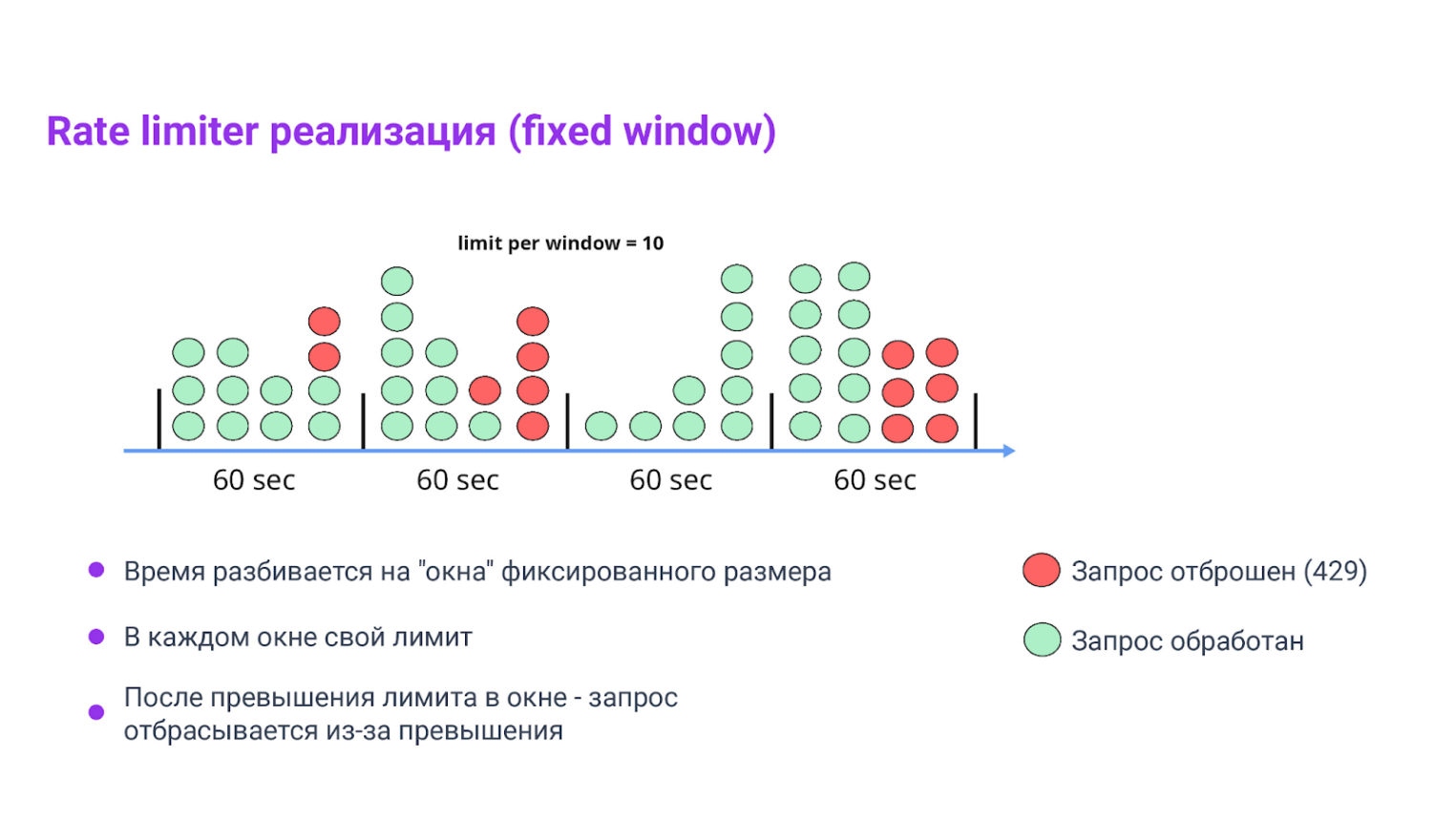
Принцип работы
Время делим на окна фиксированной длины (например, 60 секунд). Для каждого клиента считаем, сколько запросов он сделал в текущем окне. Превысил лимит — отвечаем 429 Too Many Requests и, по желанию, добавляем Retry‑After.
Ключевая идея в Redis. Один ключ на клиента и текущее окно — rate:rate:{client}:{bucket}; инкрементим INCR, при первом хите ставим EXPIRE на длину окна.
Псевдокод:
// Параметры:
// window = 60 сек (длина временного окна)
// client = идентификатор клиента (например, IP или API-ключ)
// limit = максимальное число запросов в окне
bucket = now() / window // вычисляем номер окна
key = "rate:" + client + ":" + bucket
n = INCR key // атомарно увеличиваем счетчик
if n == 1 then
EXPIRE key window // если первый запрос в этом окне — ставим срок жизни
end
if n <= limit then
allow // разрешаем запрос
else
respond 429 + Retry-After // превышен лимит
end
Вот так это работает:
- bucket определяет текущий временной интервал (например, 0–59 с, 60–119 с и т. д.);
- мы формируем Redis-ключ, уникальный для клиента и окна: «rate:client123:456»;
- INCR увеличивает счетчик запросов в этом окне;
- если счетчик стал 1 — значит это первый запрос в этом окне → ставим EXPIRE, чтобы ключ автоматически удалился по истечении окна;
- если счетчик ≤ limit — все ок, иначе отвечаем ошибкой 429 и заголовком Retry-After (опционально).
Его используют, чтобы ограничить частоту запросов клиента и защитить сервис от всплесков. Но помните, на границе окна возможен скачок (например, запрос в конце окна N и сразу в начале нового окна). При этом перегрузка возможна. Если это нежелательно для вашей системы, то рассмотрите другие подходы (sliding-window, token-bucket).
Паттерн: распределенный лок
Используется, когда несколько экземпляров сервиса могут попытаться работать с одним ресурсом одновременно, и нужно гарантировать, что только один из них это делает. Типичные кейсы: генерация отчета, пересчет каких-то общих значений, синхронизация для доступа к единому ресурсу.
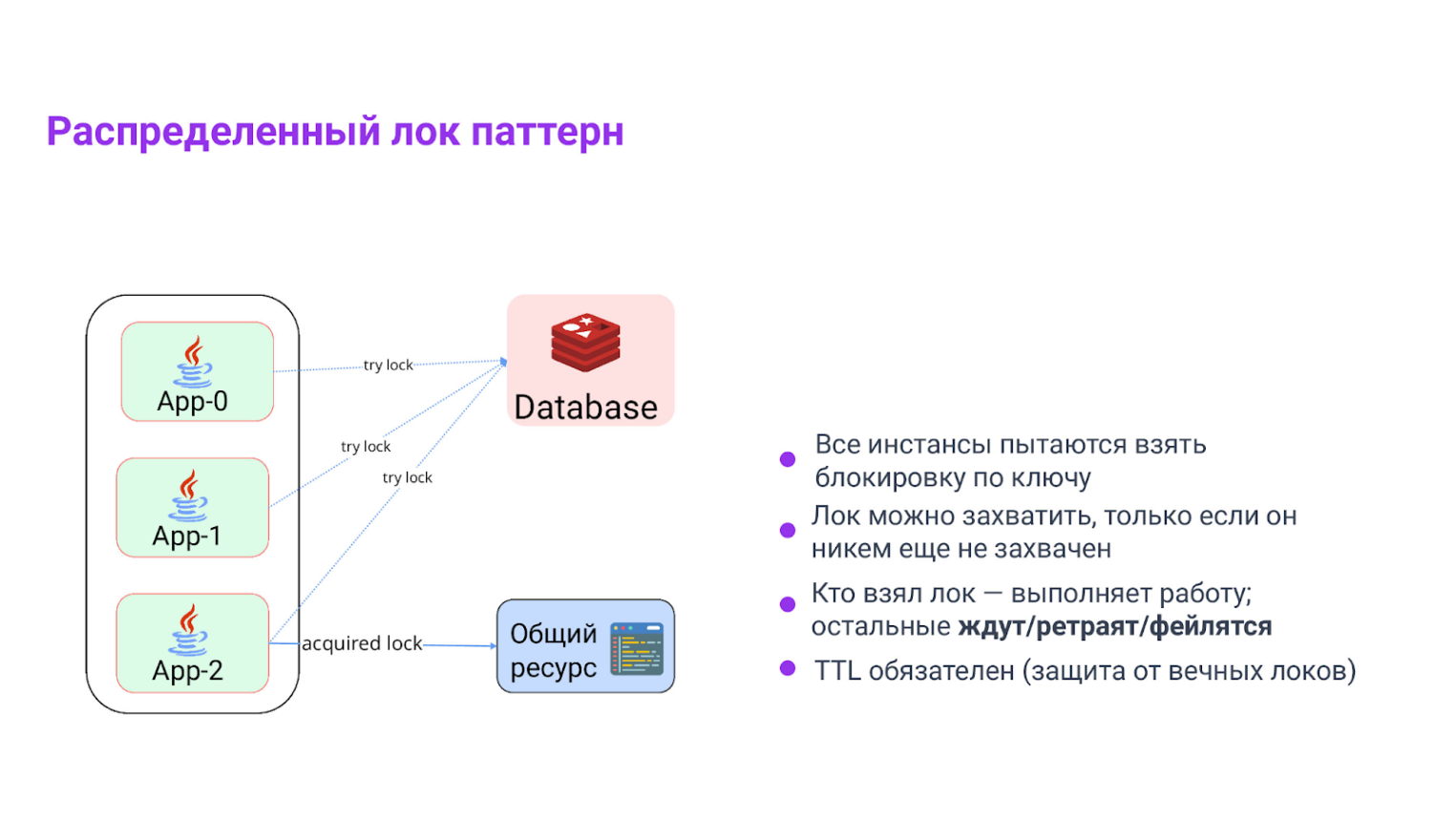
Все конкуренты пытаются создать ключ lock:{key} с опциями NX (создать, только если не существует) и PX ttl (время жизни). Кто успел — тот «лидер». Остальные ждут, ретраят или уходят. Этот подход, вместе с использованием Lua‑скриптов для безопасной разблокировки — стандартное решение.
Снимать лок должен только владелец, проверив свой token — небольшой Lua‑скрипт делает это атомарно.
// tryLock: пытаемся захватить лок
token = uuid() // генерируем уникальный токен для владельца
ok = SET("lock:" + key, token, NX, PX, ttl) // захват блокировки
if ok == true then
return token // владение локом подтверждено
else
return null // не удалось — кто-то уже владеет
end
// unlock: освобождаем лок, только если мы его владелец (Lua скрипт)
EVAL """
if redis.call('GET', KEYS[1]) == ARGV[1] then
return redis.call('DEL', KEYS[1])
else
return 0
end
""" KEYS=["lock:" + key] ARGV=[token]Для реализации этого в приложении на Spring Boot можно использовать стандартный RedisTemplate. Он позволяет легко загружать и выполнять такие скрипты.
Объяснение принципа работы распределенной блокировки
В основе механизма лежит работа с уникальным ключом, который должен быть обработан только одним инстансом приложения (например, product:42:update). Процесс начинается с попытки захвата (tryLock): инстанс пытается создать этот ключ в Redis, используя флаг NX и заданное время жизни.
При успешном захвате Redis сохраняет уникальный token в качестве значения ключа, после чего инстанс приступает к работе с ресурсом. Завершается процесс стадией освобождения: через Lua-скрипт система проверяет, совпадает ли текущий токен в Redis с тем, что был получен при захвате.
Если они идентичны, ключ удаляется. Такая атомарная проверка необходима, чтобы инстанс случайно не удалил чужой лок, если его собственный уже истек по TTL.
Заключение
Этого набора инструментов достаточно, чтобы уверенно внедрять Redis в свои проекты. А еще анализировать, где он нужен и принесет пользу, а где лучше оставить данные в реляционной БД, чтобы не усложнять архитектуру.





