

Проблемы со старой автоустановкой
Сперва расскажу, как автоустановка была организована раньше.
После того, как вы заказывали сервер или меняли конфигурацию ОС, запускался определенный процесс.
- Бэкенд получает запрос на переустановку ОС.
- Бэкэнд, используя OpenStack Ironic, отправляет команду на перезагрузку сервера.
- Сервер загружается в PXE-приложение сетевой карты, получает адрес по DHCP и команду на загрузку iPXE.
- iPXE снова запрашивает адрес у DHCP. Параллельно отправляет через опции DHCP информацию, по которой мы можем однозначно идентифицировать сервер.
- Бэкэнд генерирует из шаблона конфигурацию для автоустановки — скрипт iPXE с параметрами ядра, preseed/kickstart/unattended.xml с конфигурацией разделов и системы, postinstall-скрипт с настройкой сети и драйверов (сетевые карты Intel и Realtek, драйверы которых нужно добавлять в образы, я смотрю в вашу сторону), а также клиентский postinstall-скрипт.
- iPXE получает одноразовую ссылку на загрузочный скрипт и Netinstall-версию дистрибутива (кроме Windows — процесс в этом случае сложнее, нужно использовать WinPE), передает в установщик файл preseed/kickstart, устанавливает ОС из наших пакетных зеркал, перезагружается.
- Сервер загружается с диска, запускается postinstall-скрипт, настраиваются сеть и драйверы, порядок загрузки меняется обратно на сетевую карту в UEFI.
- Через вызов вебхука сообщаем бэкенду, что установка ОС завершена и перезагружаем сервер.
- Сервер готов к работе. Уведомляем об этом бэкенд.
Эта версия автоустановки работала примерно с 2018 года. Она пережила переезд на новую версию бэкэнда, переход на обновленную сетевую схему, полную ротацию команды и смену по кругу всех доступных ОС. Она работала достаточно стабильно и предсказуемо, хотя код со временем становилось все сложнее поддерживать.
Даже сейчас мы используем ее в некоторых случаях, которые пока не покрываются новой системой автоустановки. Например, для установки ОС на ARM-серверы, а также для серверов произвольной конфигурации с некоторыми менее распространенными RAID-контроллерами. Но в какой-то момент мы поняли, что она стала накладывать на нас слишком много ограничений.
В курсе «Введение в ARM» рассказываем, как появились ARM и для чего применяются, а также разбираем конфигурации выделенных серверов и сравниваем характеристики ARM-процессоров.
Порядок дисков
Шаблоны были настроены так, что целевые диски для установки ОС выбирались автоматически по порядку NVMe→SATA SSD→HDD. Цепочка выстроена логично и в большинстве случаев совпадает с ожидаемым поведением. Но что, если клиент хочет установить ОС на SATA SSD, а NVMe использовать под БД? Заказчику или инженеру приходилось делать это вручную из образа, без автоматизации. Этот процесс отнимал много ресурсов при большом количестве заказанных серверов.
Дополнительные проблемы вызывали аппаратные RAID-контролеры в кастомных конфигурациях. Поскольку аппаратный RAID отображается в ОС как одно блочное устройство, иногда в запросах на установку ОС с разметкой RAID1/RAID10 установщик ОС видел всего один диск.
Автоустановка не могла обработать такое поведение, ОС не устанавливалась, инженеру или администратору нужно было смотреть в KVM, чтобы понять, что именно случилось. А клиент все это время ожидал сдачи сервера. Все это влияло на пользовательский опыт, а нам приходилось тратить дополнительные ресурсы на исправление ошибок.
Драйверы и пакетная база
Были проблемы и с сетевыми картами Intel и Realtek. Они выражались в том, что в Netinstall-версии установщика не было драйвера для сетевой карты, так что установить ОС не получалось. Обычно такая проблема возникает при попытке установки относительно старой версии операционной системы на относительно новое железо.
Чтобы это исправить, необходимо было распаковывать initramfs установщика, собирать из исходных кодов необходимый драйвер, подкладывать его в нужный каталог, описывать загрузку в pre-script и упаковывать initramfs обратно. В некоторых случаях, например при работе с Debian, установщик отказывается работать с неподписанными цифровой подписью драйверами. Кроме того, после установки ОС на сервер драйвер тоже придется ставить/собирать заново, уже в postinstall-скрипте.
Часть шаблона postinstall-скрипта, которая отвечает за установку драйвера в DEB-based OS для материнских плат с чипсетом X670:
{% if version in ["18.04", "20.04", "9", "10", "11"] %}
mb=$(dmidecode --string baseboard-product-name)
mb_array=("X670 AORUS ELITE AX" <...> "MAG X670E TOMAHAWK WIFI (MS-7E12)")
if [[ " ${mb_array[@]} " =~ " ${mb} " ]]; then
apt install linux-headers-$(uname -r) -y
wget -O /root/r8125-dkms.deb https://<path_to_file>/r8125-dkms.deb
apt install /root/r8125-dkms.deb
rm -f /root/r8125-dkms.deb
echo 'r8125' > /etc/modules-load.d/r8125.conf
fi
{% endif %}
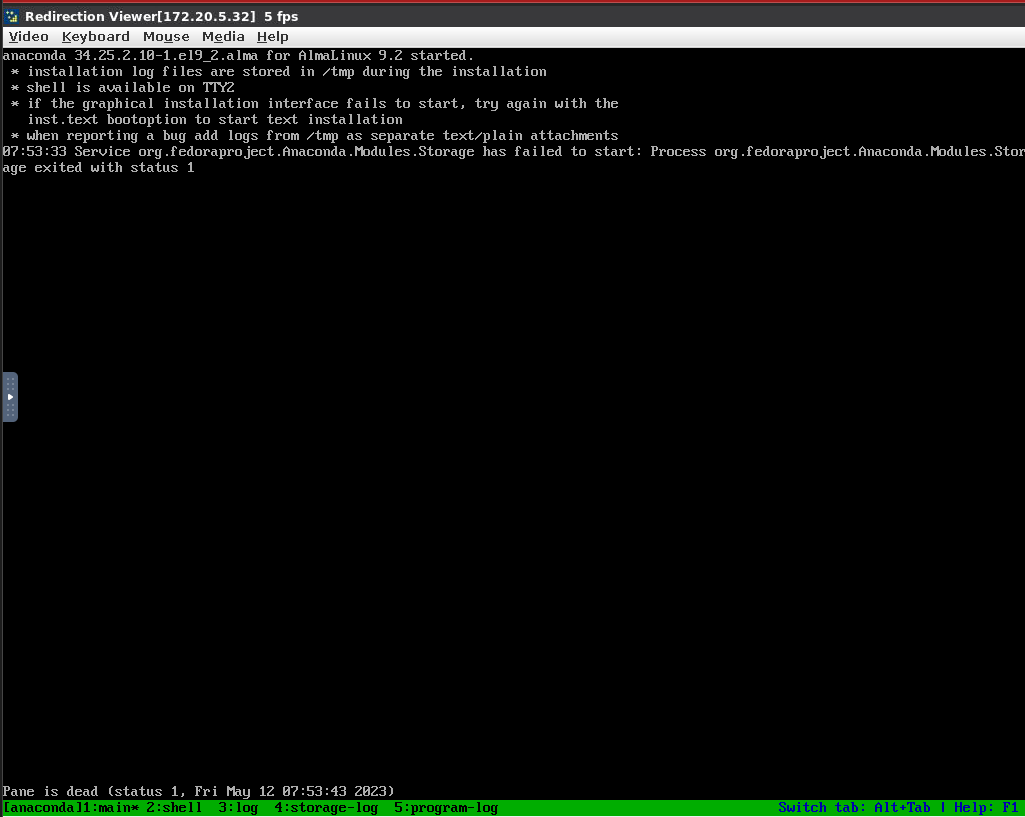
Еще одна проблема связана с пакетными зеркалами RHEL-based OS. Раньше мы не обновляли установочные файлы сразу после выхода новой минорной версии, так как один из стандартных шагов postinstall-скрипта — обновление всей пакетной базы в установленной ОС. Однако в этом подходе есть интересная проблема: в определенный момент в зеркалах перестает храниться путь к BaseOS необходимой версии.
Проблема чаще всего возникает через одну минорную версию. Например, если установщик версии 8.1, а текущий релиз 8.2 — все пройдет без проблем. Но если текущий релиз 8.3+ — все сломается.
Ubuntu 22.04
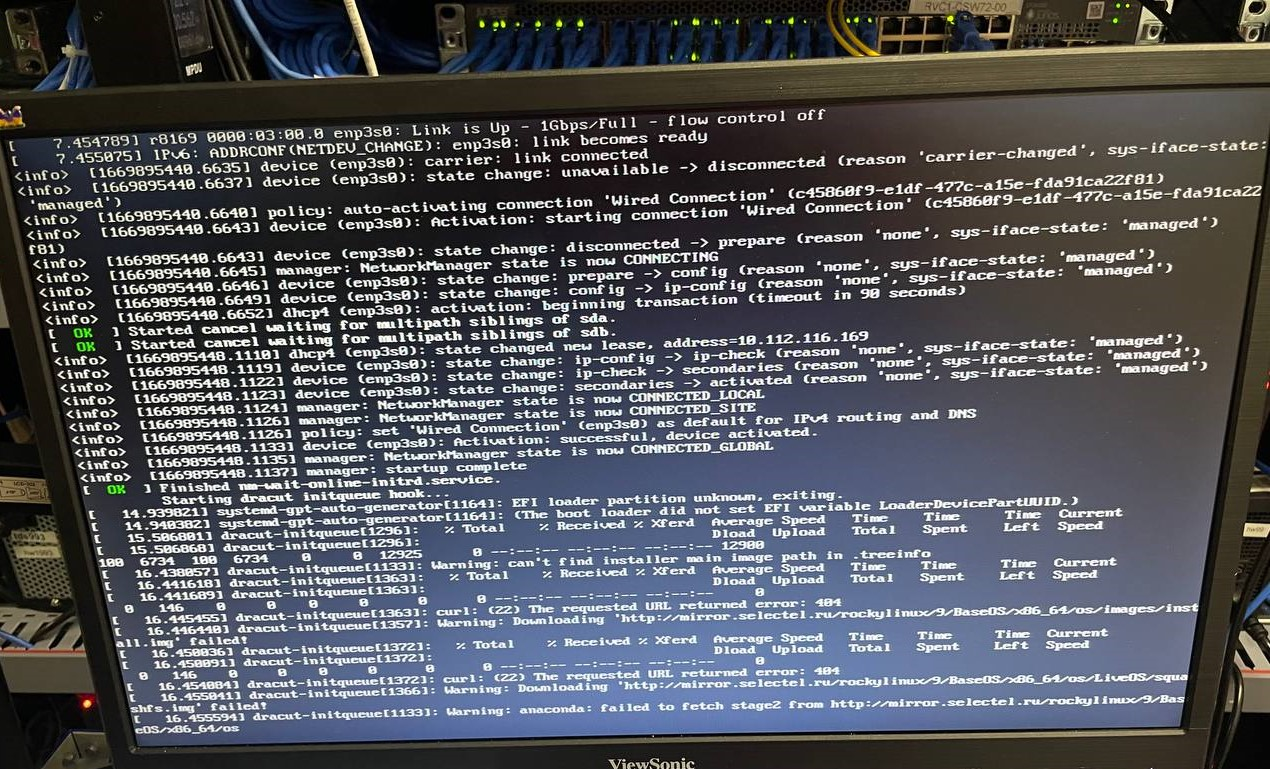
Разработчики Ubuntu в версии 22.04 отказались от использования debian-installer в пользу subiquity, а поддержку preseed отменили и перешли на cloud-init. Также перестали собирать Netinstall-образ ОС.
Однако использование cloud-init плохо ложилось в процесс — необходимо было полностью переписывать все наши шаблоны. Тут самое время вспомнить про легаси в коде и его общую раздутость. Когда релизу Ubuntu 22.04 исполнился год, а он еще не был доступен у нас, мы решили ускорить переход на новый процесс. Небольшой спойлер: добавление Ubuntu 24.04 заняло всего неделю.
Время установки ОС и шаблоны
Некоторые ОС, к примеру Windows Server, устанавливались очень долго — иногда больше часа. Процесс хотелось ускорить. Последний, хоть и не ключевой нюанс: шаблоны файлов preseed/kickstart со временем превратились в простыню if-ов и костылей неочевидных технических решений. При внесении изменений в часть, которая отвечает за динамическую разметку softRAID + LVM в partman, было страшно всей команде.
Как мы постарались сделать лучше
Однажды мы провели встречу с разработчиками и попытались придумать, как сделать систему лучше. Основная идея — устанавливать ОС из «базового образа». Фактически — заранее готовить корневую файловую систему, упаковывать ее в архив, а затем разворачивать на диски и донастраивать.
Конечно, «просто так» это сделать не получится — нужна внешняя система, которая будет запускать управляющий скрипт, размечать диски, генерировать стартовые конфиги, устанавливать bootloader и т. д. Вдобавок хотелось автоматизировать сборку и тестирование базового образа. Это избавило бы от лишних временных затрат на обновление и добавление новых ОС. Расскажу обо всем по порядку.
Сервисная ОС и управляющий скрипт
За основу мы опять взяли Arch Linux. В дистрибутив добавили минимум пакетов:
arcconfиmegacli— для работы с аппаратными RAID-контроллерами,filebeat— для экспорта логов,wgetиefibootmgrкак зависимости для управляющих утилит.
Управляющих утилит у нас две. Первая — сервис для взаимодействия с оборудованием через различные стадии. К примеру, выполнение проверки SMART, прошивка оборудования, управление аппаратными RAID-контроллерами и т. д.
Вторая — скрипт, который управляет описанным выше сервисом. Он запускает в нужном порядке различные стадии, взаимодействует с нашим бэкендом. Рассмотрим, как автоустановка выглядит в новой системе.
- Бэкэнд получает запрос на переустановку ОС.
- Бэкэнд, используя OpenStack Ironic, отправляет команду на перезагрузку сервера. Параллельно на коммутаторе настраиватся служебный VLAN — это необходимо для связности с нашим DHCP-сервером.
- Сервер загружается в PXE-приложение сетевой карты, получает адрес по DHCP и команду на загрузку iPXE.
- iPXE снова запрашивает адрес у DHCP. Параллельно отправляет через опции DHCP информацию, по которой мы можем однозначно идентифицировать сервер.
- Бэкэнд генерирует из шаблона iPXE-script для загрузки сервисной ОС. Передает в аргументы ядра идентификаторы сервера.
- После загрузки запускается systemd-unit. Он экспортирует переменные окружения и запускает управляющий скрипт.
- Управляющий скрипт получает от бэкенда информацию об ОС (пароль пользователя, SSH-ключи, user-data), а также информацию об оборудовании: тип и размер дисков, их схему разметки. Далее — подготавливает оборудование, размечает диски, загружает и распаковывает базовый образ ОС, устанавливает bootloader, генерирует из шаблонов конфигурацию cloud-init.
- Управляющий скрипт уведомляет бэкэнд об успешном завершении установки и перезагружает сервер.
- Бэкенд отправляет команду на смену VLAN со служебного на клиентский.
- Пункт-развилка. Если сервер запущен в Legacy-режиме, он попытается запуститься по сети, не сможет найти DHCP-сервер и загрузится с диска. В случае UEFI — загрузится сразу с диска.
- В момент первой загрузки ОС выполняется cloud-init, в котором настраивается сеть, hostname, таймзона и синхронизация времени, меняется пароль системного пользователя (root/Administrator), добавляются SSH-ключи и выполняется клиентская user-data, которую можно задать в панели. При работе с UEFI меняем порядок загрузки обратно, чтобы сервер пытался загрузиться по сети. Это необходимо, чтобы клиент мог войти в режим Rescue, а после окончания аренды сервера мы могли провести очистку дисков и промежуточные автотесты.
- Сервер готов к использованию.
Далее расскажу чуть подробнее о порядке работы управляющего скрипта в общем случае (для Debian-derivatives). Для Windows Server и RHEL-derivatives будут отличия.
1. Зачищаем сервер перед началом установки. Разбираем аппаратные RAID, удаляем файловые системы и таблицу разделов, затираем служебные области дисков. Быстрая затирка нужна при переустановке ОС на уже активном сервере, в рамках одной аренды. После отказа от сервера все диски проходят через Secure Erase для обеспечения конфиденциальности данных.
2. Получаем из бэкенда список ожидаемого оборудования (CPU, RAM, GPU, тип и объем дисков, желаемую схему разделов).
3. Получаем список физических блочных устройств на сервере.
4. Создаем новые блочные устройства через контроллеры дисков. Актуально, если в сервере используются аппаратные RAID-контроллеры.
5. Сопоставляем информацию из п. 1 и п. 2. Это нужно, чтобы понимать, как мы будем размечать диски и монтировать разделы.
- Создаем таблицу разделов по данным из п.1.
- Создаем служебные разделы: EFI system partition, cidata. Помечаем их необходимыми лейблами и флагами.
- Создаем остальные разделы, в соответствии с конфигурацией.
- Собираем разделы в RAID, если необходимо. Раньше мы в том числе собирали разделы в LVM, но отказались от процесса из-за сложностей с их последующей разборкой и созданием.
- Создаем файловые системы на разделах.
6. Монтируем созданные файловые системы.
7. Загружаем и распаковываем базовый образ.
Изначально копировали базовый образ в RAM и оттуда распаковывали его на диски. Но однажды мы столкнулись с тем, что у некоторых конфигураций не хватает оперативной памяти для хранения базового образа — необходимо было как минимум 8 ГБ для большинства Linux-based OS и 32 ГБ для Windows Server.
Затем мы провели тесты и поняли, что можем распаковывать базовый образ «на лету» — сразу на диск с помощью `wget -qO <image_url> | tar -xzf -C <mountpoint корневого раздела>`. Этот способ немного медленнее, зато требует меньше оперативной памяти.
8. Генерируем конфигурационные файлы cloud-init и кладем их в cidata.
В нашем случае — meta-data с UUID сервера и hostname, network-config с настройками интернет-порта, user-data с дополнительной конфигурацией клиентов (очень надеюсь, что вы ей пользуетесь — нам пришлось постараться, чтобы оно заработало нормально), которая указывается в запросе на установку ОС и vendor-data, где мы настраиваем таймзону и NTP, выставляем пароли и SSH-ключи.
9. Выполняем chroot в распакованную систему и выполняем донастройку системы. Генерируем mdadm.conf, ramdisk’и, генерируем fstab,устанавливаем GRUB, меняем bootorder.
10. Ждем 60 секунд, чтобы точно успеть выгрузить логи. Уведомляем бэкенд о завершении установки и перезагружаем сервер.
Если алгоритм выполняется без отклонений, то через 7-15 минут ОС готова к работе.
Сборка образа
Чтобы распаковать базовый образ на диск, сперва его следует собрать и протестировать. Для этого мы используем Packer с QEMU в роли провайдера и Ansible для донастройки ОС. Сборка проходит в два этапа.
Первый этап
Скачиваем minimal-ISO дистрибутива, запускаем ВМ с помощью QEMU, указываем путь к максимально простому cloud-init для установки и настраиваем SSH, чтобы позже подключиться через Ansible. Если вы уже активно используете Packer для своих задач — скорее всего я не расскажу вам ничего нового.
Для тех, кто слышит о нем впервые, Hashicorp Packer — это, согласно README на GitHub, инструмент для создания идентичных образов машин для нескольких платформ из одной исходной конфигурации. Что это значит для нас? Мы можем описать образ ОС кодом, хранить его в Git, собирать на своих раннерах в GitLab и автоматически деплоить в объектное хранилище.
Часть конфига Packer, которая отвечает за первый этап сборки Ubuntu:
dynamic "source" {
for_each = local.images.ubuntu
labels = ["qemu.default"]
content {
name = source.key
vm_name = "${source.key}-stage1.qcow2"
output_directory = "${var.outputs_prefix}/${source.key}/stage1"
format = "qcow2"
iso_url = "${var.iso_image_url == "" ? source.value.url : var.iso_image_url }"
iso_checksum = "${var.iso_image_url == "" ? source.value.checksum : "none" }"
boot_command = [
"<enter>",
"<wait2m>",
"yes<enter>"
]
cd_files = [
"${var.preseeds_prefix}/cloud-init/*",
]
cd_label = "cidata"
communicator = "none"
}
}
Пример файла cloud-init, который используется для первого этапа сборки Ubuntu:
#cloud-config
autoinstall:
version: 1
identity:
username: ubuntu
password: <здесь был хэш пароля>
hostname: ubuntu-server
locale: en_US.UTF-8
keyboard:
layout: us
storage:
layout:
name: direct
ssh:
install-server: true
allow-pw: yes
late-commands:
- shutdown now
user-data:
runcmd:
- sed -ie 's/#PermitRootLogin prohibit-password/PermitRootLogin yes/g' /etc/ssh/sshd_config
- systemctl restart sshd
- sudo apt-get update && sudo apt-get install --only-upgrade ansible
После завершения первого этапа сборки мы выгружаем полученный stage1.qcow2 образ в объектное хранилище. Теперь при необходимости изменений во втором этапе нам не приходится заново устанавливать ОС — мы берем готовый образ и вносим новые настройки. Это экономит время и ресурсы наших раннеров.
Однако процесс работает до тех пор, пока мы не решим обновить версию ОС — в этом случае меняется установочный ISO, а мы снова запускаем полную сборку с нуля.
Второй этап
Монтируем в ВМ stage1.qcow2 и запускаем Ansible. Рассмотрим, как работает наш плейбук (пример для Ubuntu 20.04).
- Настраиваем зеркала.
- Обновляем кэш пакетного менеджера и все установленные пакеты.
- Устанавливаем linux-image-generic-hwe-20.04 — ядро с дополнительной поддержкой аппаратного обеспечения. Необходимо для работы с самым новым оборудованием.
- Устанавливаем fail2ban, cloud-init, mdadm, grub2, dracut, wget, nftables.
- Копируем конфигурацию cloud-init — в ней перечислены модули, которые нужно запустить после старта ОС. Сюда входят практически все поддерживаемые модули — это сделано для того, чтобы любая user-data отработала корректно.
- Копируем скрипт управления UEFI-bootorder, чтобы загрузчик снова приоритезировал загрузку по сети после первого запуска.
- Копируем /etc/default/grub.
- Пересобираем initramfs, чтобы включить mdadm при первом запуске.
- Копируем базовый конфиг fail2ban.
- Упаковываем корневую файловую систему в архив и сжимаем его.
Для других ОС эти шаги будут отличаться. Например, для Windows Server мы также добавляем в образ драйверы для сетевых карт и RAID-контроллеров. Proxmox мы собираем из Debian — поэтому там нужно установить больше пакетов, провести определенные манипуляции с системными пользователями и зеркалами.
Полученный образ stage2 мы также загружаем в объектное хранилище — позже его заберет скрипт во время установки ОС.
Автоматизация сборки и тестирования
Когда мы активно разрабатывали новую версию автоустановки, в автоматизации не было особой потребности. Тестировали все примерно на одних и тех же конфигурациях, ОС тоже была одна. Однако как только начали готовиться к релизу, мы поняли, что протестировать новую автоустановку на 100+ конфигурациях серверов руками — это непосильная задача. Решили пойти к коллегам из QA и попросить о помощи.
Так родился набор Python-скриптов — «оберток» над клиентским и администраторским API, которые могут заказать сразу все доступные конфигурации, установить на них ОС, проверить их доступность по SSH и выполнить отказ от серверов. Это было отличное решение, которое работало примерно в том же виде еще долгое время, даже когда образов ОС стало больше (сейчас их 19).
Затем, когда начали собирать образы для большего количества ОС, решили автоматизировать их сборку и деплой. Так появился простой GitLab-пайплайн с ручными джобами для каждого образа ОС. Он деплоил их в тестовые окружения, а после слияния с мастер-веткой обновлял образы в production. Стало удобнее, но тестирование и дебаг все еще занимали несколько дней.

В какой-то момент нам надоело тестировать серверы руками и мы обновили наши пайплайны. Теперь образ собирается после коммита в ветку и кладется в тестовые окружения. Как только мы проверили, что все работает на одной конфигурации, раскатываем автоустановку тестовой ветки на всех конфигурациях наших серверов. Мы заказываем все доступные конфигурации, идем на них Ansible-ом и проверяем, что все установилось как ожидается.
Далее — проверяем разметку дисков, репозитории, пароли, SSH-ключи, версию ОС, список установленных пакетов и список пользователей с интерактивными сессиями. Затем происходит отказ от серверов, диски очищаются и возвращаются в пул доступных для клиентов.


С новым пайплайном мы можем провести все необходимые тесты примерно за 4-6 часов, что нравится намного больше. В планах доделать красивую генерацию отчетов в GitLab Pages.
Что у нас получилось
Подведем небольшие итоги и посмотрим, как процесс автоустановки выглядит теперь.
Выбор дисков
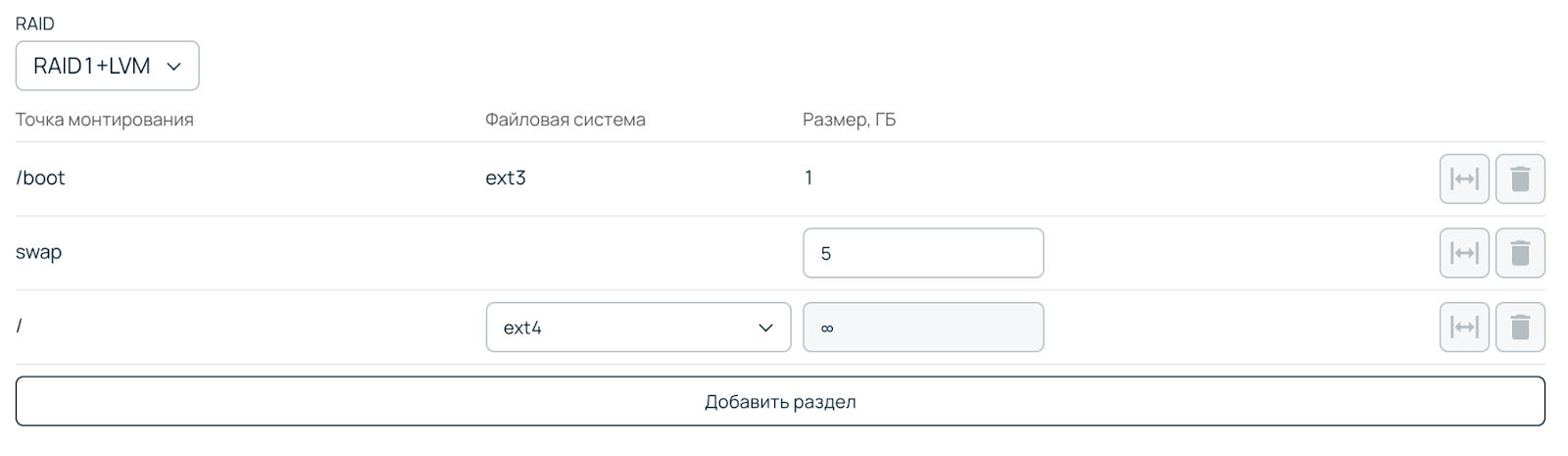
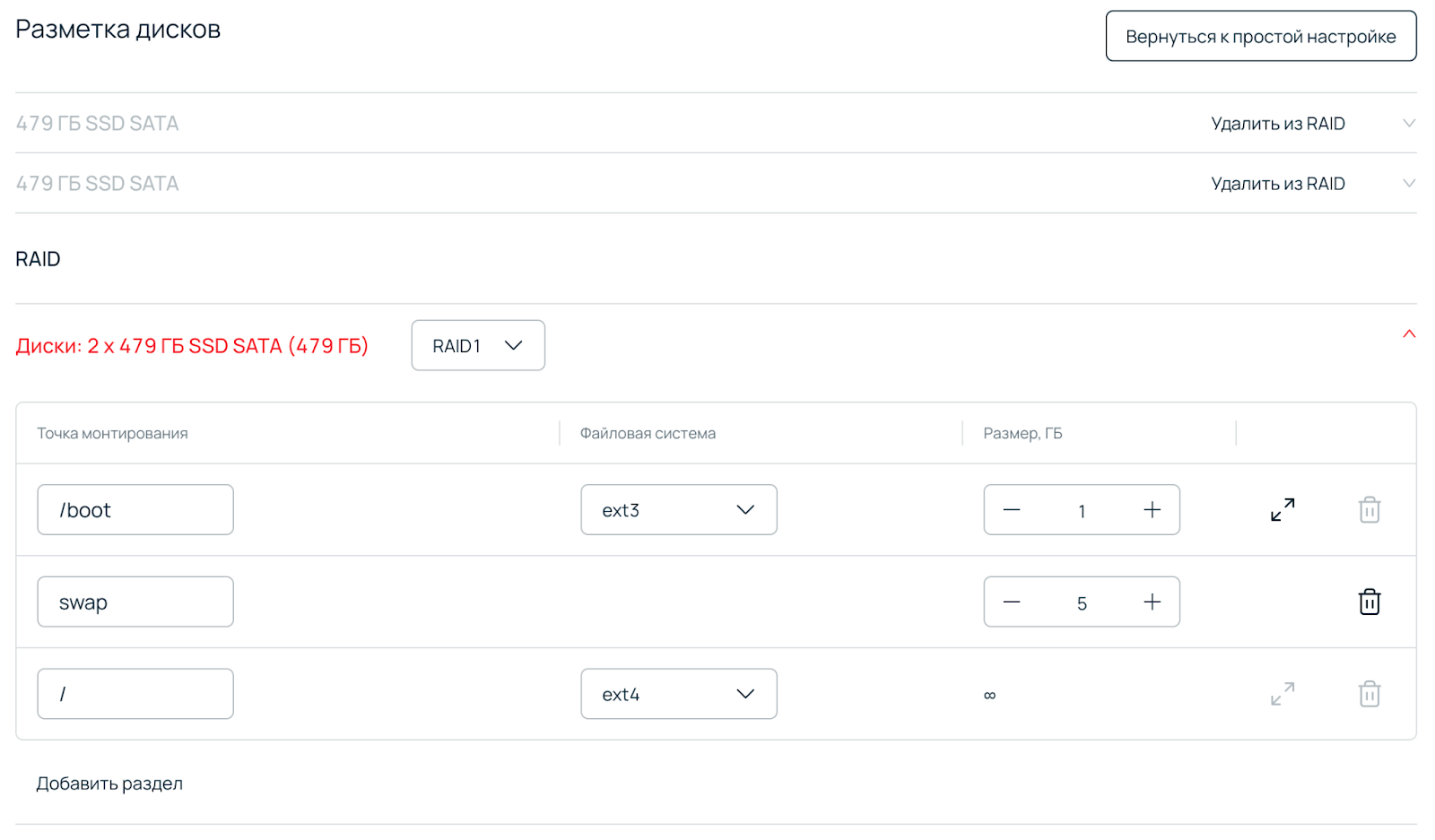
Теперь для автоустановки можно выбирать диски любого типа, в любом порядке. Их можно организовывать в рейды, а также создавать на них разделы и точки монтирования в произвольном порядке.
В процессе разработки новой системы нам пришлось отказаться от автоматического добавления дисков в LVM. Его разборка не всегда работает стабильно, добиться с ним нужного процента успешных установок не получилось.
Драйверы и пакетная база
Проблему с драйверами мы в общем случае решили установкой ядра с расширенной поддержкой аппаратного обеспечения. Пока что мы не сталкивались с необходимостью доустанавливать дополнительные драйверы в Linux, но если это будет необходимо — задача станет значительно проще. Теперь это нужно будет просто описать в Ansible/Cloud-Init.
В Windows Server драйверы все еще монтируются в виртуальную машину во время установки, но теперь это происходит локально, без их передачи по сети. Таким образом, мы смогли избавиться от Samba-сервера и уменьшить нагрузку на служебные сети. Проблема с устареванием базовых пакетов в зеркалах тоже решилась: после сборки образ больше не меняется и просто распаковывается.
Добавление и тестирование новых ОС
Так как установка и сборка теперь в целом занимает меньше времени, мы можем обновить ОС до новой минорной версии за один коммит, а протестировать примерно за один час.
Примечание: для минорных обновлений мы тестируем не все конфигурации, а около 10% наиболее популярных. Это позволяет быстрее анализировать результаты и на время тестов изымать меньше серверов из пула доступных для клиентов.
Если тест показал хорошие результаты — сразу же обновляем доступные образы. С мажорными версиями и новыми семействами ОС немного сложнее: для них приходится обновлять и дописывать Ansible-плейбуки, что иногда занимает достаточно много времени. Далее — проводить тесты на всех доступных конфигурациях. Однако даже так процесс занимает гораздо меньше времени, чем было раньше.
Время установки ОС
Переходим к самому интересному: насколько у нас получилось ускорить установку ОС?
Замеры произведены на конфигурации EL10-SSD (Intel Xeon E3-1230v5, 32GB RAM, 2x480GB SATA SSD), результаты получены из логов бэкенда. В обоих случаях измеряем время между получением бэкендом команды на переустановку и отправкой на перезагрузку после успешной установки. Время загрузки после рестарта может отличаться на разных платформах.
| Дистрибутив | v1 time (секунд) | v2 time (секунд) | Разница (%) | Разница |
| Debian 12 | 774 | 505 | 53.27 | 1.53 раз |
| Ubuntu 20.04 | 841 | 609 | 38.10 | 1.38 раз |
| WinServer2022 | 2454 | 558 | 339.78 | 4.40 раз |
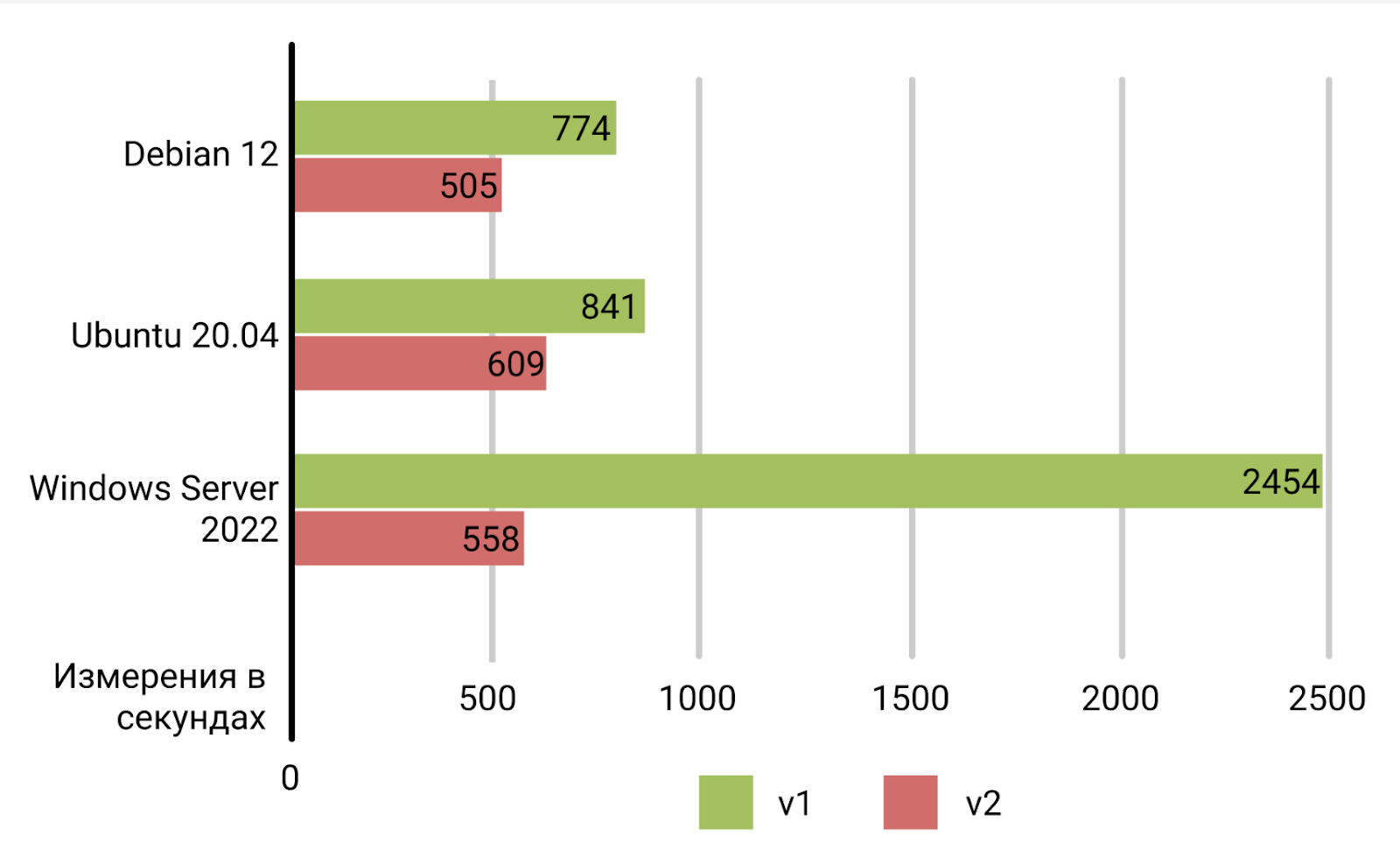
На графике видно, что нам удалось ускорить автоустановку на 27-77%, в зависимости от ОС. А еще теперь время установки — относительно постоянная величина, так что мы можем лучше планировать процессы. Например, в пайплайнах для джобы тестирования используется задержка запуска в 15 минут — мы уверены, что за это время сервер гарантировано установится. Если нет — следует проверить, что именно сломалось.




