

Короткая справка по нашему герою. Аргентинский муравей Linepithema humile в миллиметр длиной, с глазами у него все плохо, а в мозге около 250 000 нейронов (у нас, напомню, 86 млрд). Карты местности он не помнит.
В 1989 году четверо бельгийских биологов поставили этим муравьям простой эксперимент — гнездо, еда, два мостика, где один длиннее другого в два раза. Через несколько минут вся колония сошлась на короткой ветке в 100% прогонов. И все это без координатора, без плана и без голосования.
Через три года этот эксперимент превратится в Ant Colony Optimization — алгоритм, который я сегодня натравлю на классический TSP-бенч и получу 0,10% отставания от оптимума. А в 2023, через 34 года после наблюдений в Брюсселе, тот же алгоритм вернулся на NeurIPS в качестве бэкбона для графовых нейросетей. Что же, приступим.

1989: муравьи голосуют за короткий путь
Эксперимент Госса, Арона, Денебурга и Пастельса устроен так: из коробки с колонией наружу ведет раздвоенный мостик — точка разветвления, две ветки разной длины, и обе они сходятся к кормушке. Длинная ровно вдвое больше короткой.
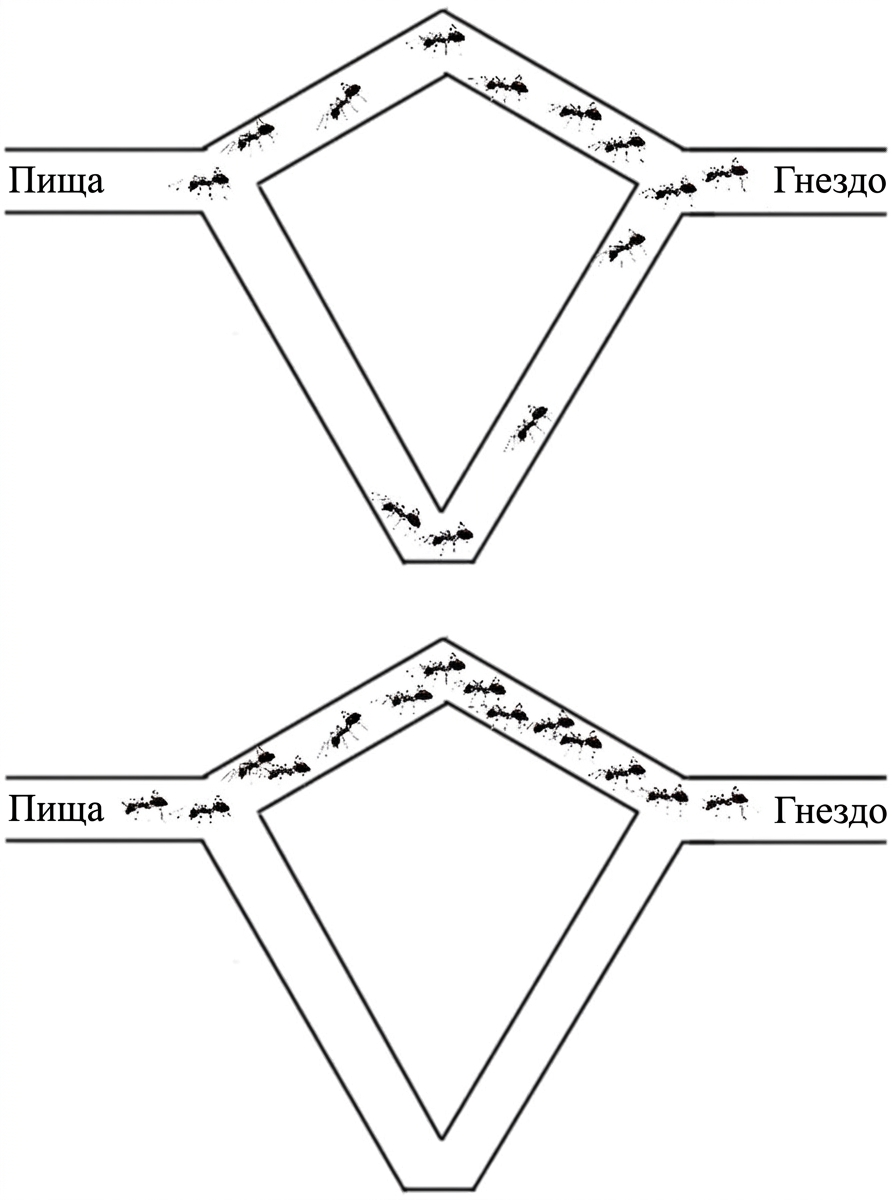
Муравьи этого вида почти не видят. Они ходят по запаху, оставляют за собой феромон и предпочитают двигаться туда, где его больше. Решение «налево или направо» принимается без всякого плана.
Дальше простая арифметика. В самом начале феромона нет, и ветку муравей выбирает случайно 50/50. Но те, кто случайно свернул на короткую, первыми же и вернутся — а значит, первыми успеют отметить свою ветку вторым слоем запаха. С каждой новой волной муравьи все чаще выбирают короткий путь. Дисбаланс накапливается, положительная обратная связь раскручивается, и минут через восемь на короткой ветке почти весь трафик.
Денебург записал это формулой:
(k + φᵢ)ʰ
P(i) = ─────────────────────
(k + φ₁)ʰ + (k + φ₂)ʰ
где φᵢ — концентрация феромона на ветке i, k — «базальная любознательность», чтобы колония не залипла на первом случайном выборе, а h — нелинейность реакции.
Если прогнать ее в цикле, получится график, на котором короткая ветка отрывается почти сразу.
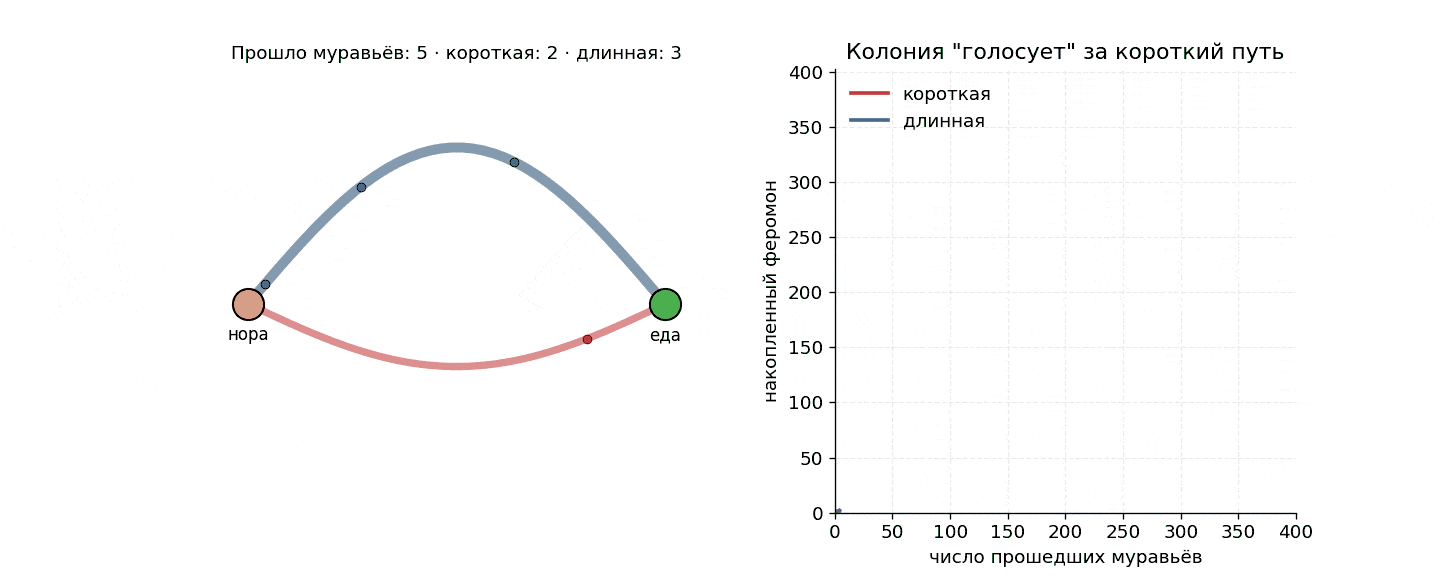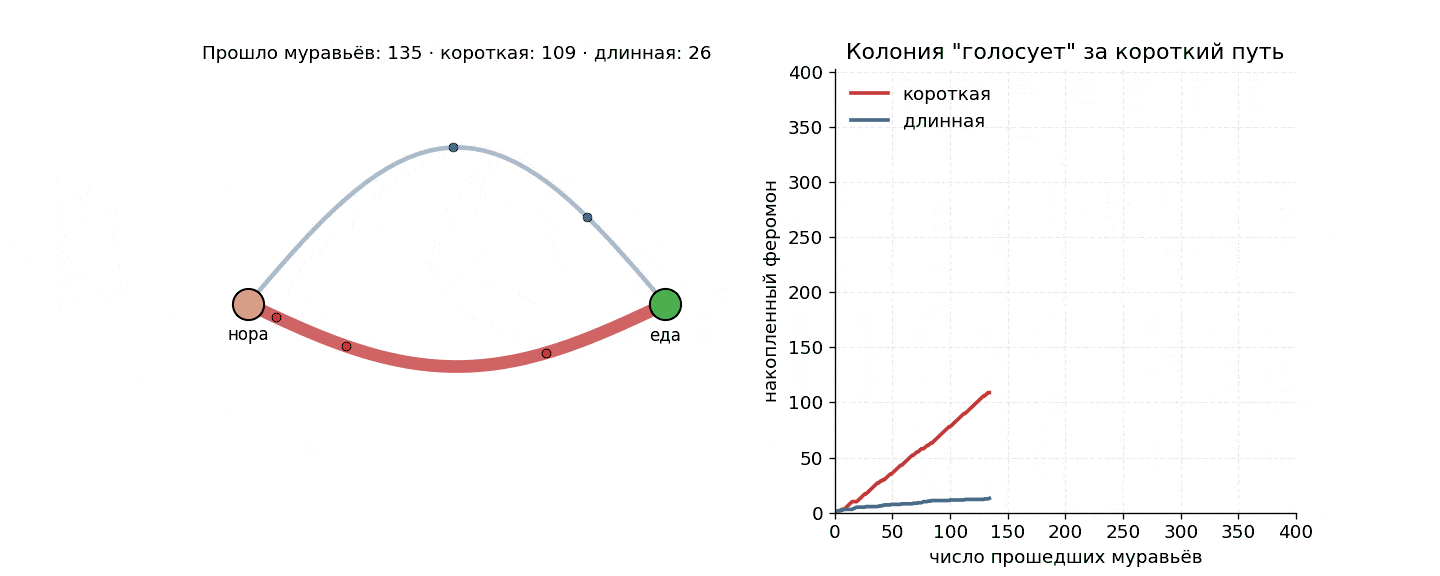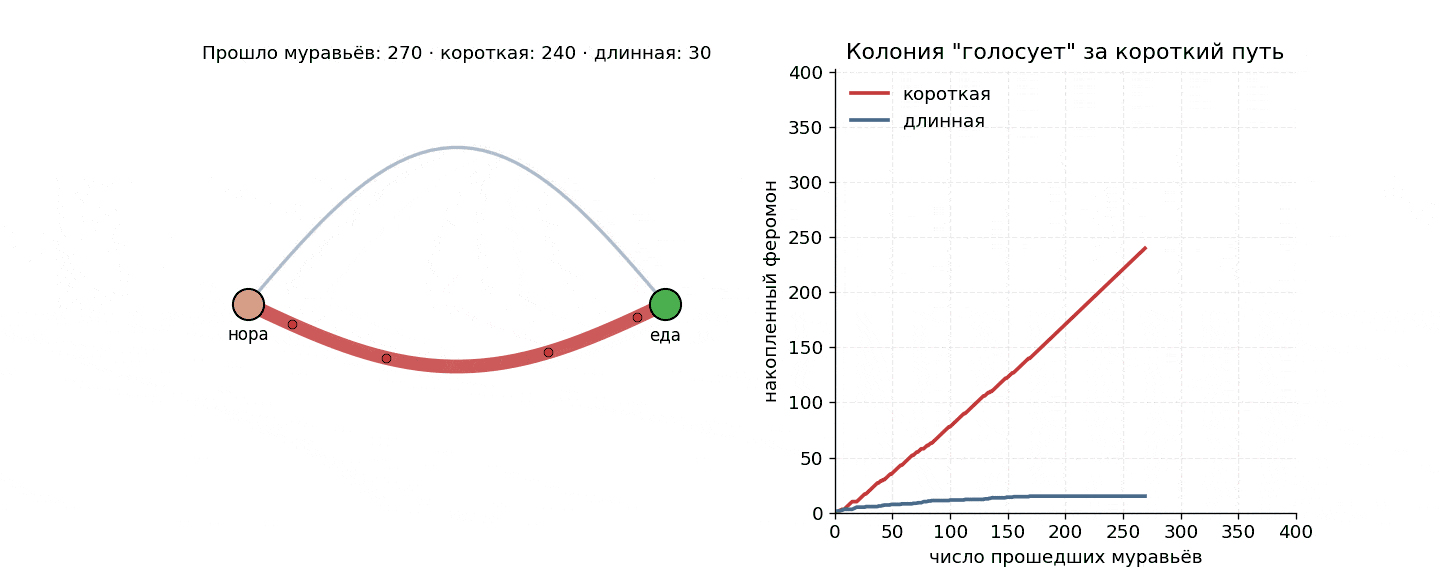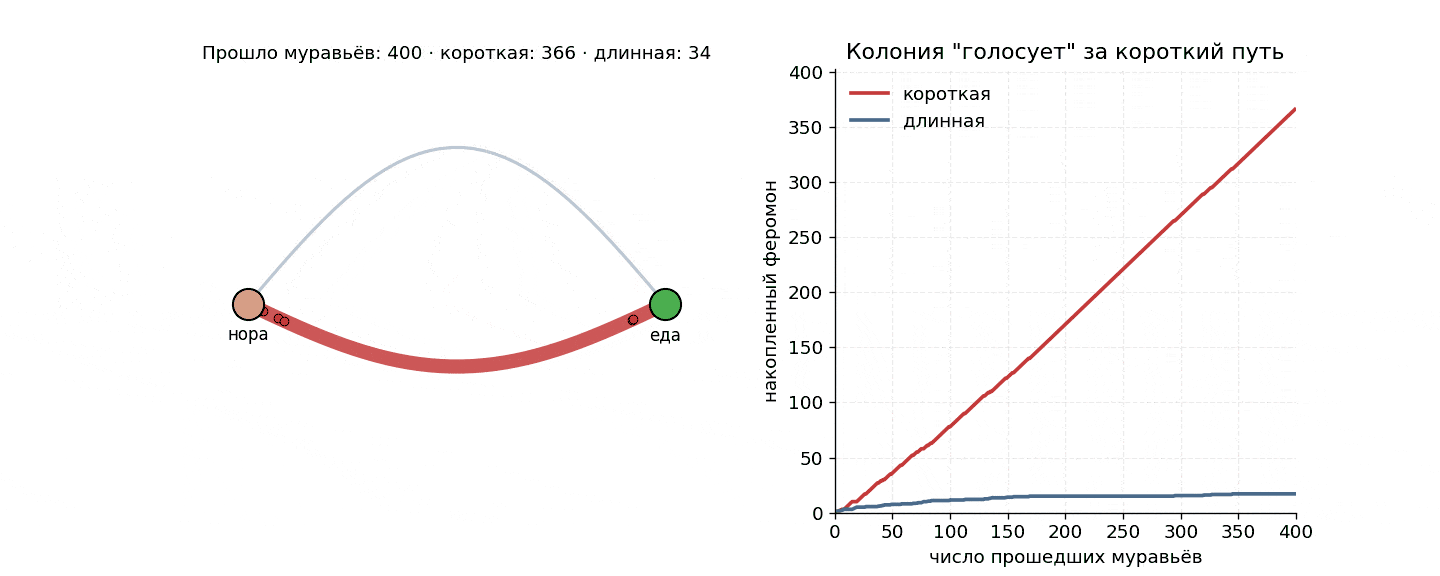
Самое интересное, что никто ни с кем не договаривается. Нет начальника, нет голосования и нет карты, зато есть локальное правило для одного муравья плюс физика феромона: испарение и накопление. А оптимум как бы сам выкристаллизовывается из шума.
В биологии это называется стигмергия — косвенная коммуникация через изменения среды.
1997: Дориго пишет это кодом
Марко Дориго подробно разобрал эту биологическую идею в статье с заголовком «Ant colonies for the traveling salesman problem» (статья хорошая, но, справедливости ради, Дориго защитил диссертацию с этим алгоритмом еще в 1992 году). Ход мысли понятный: если колония может найти короткий путь между двумя точками, ее можно пересадить на любой граф, где решение — это последовательность вершин. Задача коммивояжера ложится идеально.
Получился Ant System. Все три правила переписываются от муравьев почти дословно.
Построение тура
Муравей стоит в городе i и выбирает следующий город j из еще не посещенных с вероятностью:
τᵢⱼᵅ · ηᵢⱼᵝ
P(i → j) = ─────────────
Σ τᵢₗᵅ · ηᵢₗᵝ
l ∈ непосещенные
Тут τᵢⱼ — феромон на ребре, а ηᵢⱼ = 1/dᵢⱼ — простая эвристика «чем ближе, тем лучше». Параметры α и β балансируют память колонии и жадность отдельного муравья.
Испарение
В конце итерации весь феромон равномерно тускнеет:
τᵢⱼ ← (1 − ρ) · τᵢⱼ
Это механизм забывания — без него алгоритм быстро залипнет в первом найденном приличном решении.
Депозит
Каждый муравей откладывает на ребрах своего тура феромон, пропорциональный качеству:
τᵢⱼ ← τᵢⱼ + Q / Lₖ для всех (i,j) ∈ турₖ
Короткий тур оставляет больше запаха, длинный — меньше. Следующее поколение чаще ходит по хорошим ребрам. Положительная обратная связь из биологии перенесена один в один.
Код, которого совсем немного
Главный цикл Ant System (без бэкпропа, и без любимых мной градиентов):
import numpy as np
def ant_system(coords, n_ants=30, n_iter=150,
alpha=1.0, beta=4.0, rho=0.1, Q=1.0, seed=42):
rng = np.random.default_rng(seed)
n = len(coords)
diff = coords[:, None, :] - coords[None, :, :]
D = np.sqrt((diff ** 2).sum(-1))
np.fill_diagonal(D, 1e-10)
eta = 1.0 / D # «чем ближе — тем желаннее»
tau = np.ones((n, n)) # феромон стартует ровным
best_tour, best_len, history = None, np.inf, []
for it in range(n_iter):
all_tours = np.empty((n_ants, n), dtype=np.int64)
all_lens = np.empty(n_ants)
for k in range(n_ants):
start = rng.integers(n)
tour = [start]
visited = np.zeros(n, dtype=bool)
visited[start] = True
cur = start
for _ in range(n - 1):
mask = ~visited
w = (tau[cur, mask] ** alpha) * (eta[cur, mask] ** beta)
p = w / w.sum()
nxt = int(rng.choice(np.where(mask)[0], p=p))
tour.append(nxt)
visited[nxt] = True
cur = nxt
all_tours[k] = tour
all_lens[k] = D[tour, np.roll(tour, -1)].sum()
tau *= (1.0 - rho) # испарение
for k in range(n_ants): # депозит
deposit = Q / all_lens[k]
t = all_tours[k]
t_next = np.roll(t, -1)
tau[t, t_next] += deposit
tau[t_next, t] += deposit
k_best = int(np.argmin(all_lens))
if all_lens[k_best] < best_len:
best_len = float(all_lens[k_best])
best_tour = all_tours[k_best].copy()
history.append(best_len)
return best_tour, best_len, history
Бенчмарк: berlin52
В качестве подопытного беру berlin52 из TSPLIB — 52 города, известный оптимум 7 542, решается на ноутбуке за секунды. Для сравнения возьмем три линии обороны: 1 000 случайных перестановок, nearest neighbor со всеми 52 стартовыми точками, и Ant System — 30 муравьев, 150 итераций и пять прогонов с разными сидами.
Параметры муравьев взял из коробки: α=1.0, β=4.0, ρ=0.1, Q=1.0. Специально не тюнил.
| метод | длина | отставание |
| случайный тур (лучший из 1 000) | 24 553,5 | +225,6% |
| nearest neighbor (лучший из 52) | 8 182,2 | +8,5% |
| Ant System (средний из 5) | 7 651,0 | +1,44% |
| Ant System (лучший из 5) | 7 549,3 | +0,10% |


Всего 250 000 нейронов и полное отсутствие зрения, но результат — 0,10%. Напомню — алгоритм 1992 года. Если нарисовать маршруты, хорошо видно, где nearest neighbor косит — длинные пересечения в центре карты: он жадно хватает ближайшее и потом дорого за это платит на последних шагах.
Что мне показалось любопытным в динамике сходимости: первые итераций двадцать ACO проигрывает nearest neighbor. Потом феромонная карта «разогревается» — и где-то к сороковой итерации алгоритм обгоняет.
Типичный перекос exploration → exploitation, только безо всякого обучения с подкреплением — он просто получается сам из испарения и депозита.
А как это работает в Deep Learning
Логичный вопрос: если задаче почти сто лет, а муравьиному алгоритму тридцать, чем вообще занимается современная нейросетевая комбинаторная оптимизация? Кратко по годам.
Pointer Networks (2015) — энкодер на основе LSTM читает координаты городов, декодер-«указатель» на каждом шаге выбирает следующую вершину. Честное доказательство того, что нейросеть вообще способна строить туры.
Bello et al. (2016) берут ту же архитектуру и учат ее не на размеченных данных, а с подкреплением через REINFORCE: длина построенного тура минус базовое значение — награда.
Attention Model (2018) — трансформер вместо LSTM, энкодер-декодер поверх множества узлов. До сих пор базовая архитектура, от которой все пляшут.
POMO (2020) — та же модель, только стартует из всех узлов параллельно и эксплуатирует симметрию, разброс в качестве решений резко падает.
DIFUSCO (2023) — уже диффузионные модели поверх тепловых карт ребер.
На задачах, где можно обучить сеть на миллионе случайных задач коммивояжера того же размера, все это бьет классический ACO довольно уверенно. Но есть нюансы, о которых в анонсах обычно забывают.
Модель, обученная на n=100, плохо переносится на n=1 000, без дополнительных трюков, честнее будет сказать, вообще разваливается. На классических тестах коммивояжера нейросети до сих пор никто не снял с пьедестала LKH — эвристику Лин–Кернигана–Хельсгауна, написанную вручную, без единой обучаемой весовой матрицы. И, наконец, если у вас кастомный TSP с экзотическими ограничениями — переобучать модель внимания с нуля весело ровно до первого дедлайна.
То есть у нейросетей два больших плюса — скорость работы готовой модели и масштаб — и два больших минуса: нужен обучающий набор данных и нужно, чтобы целевая задача совпадала с обучающей.
Кстати, про «нужен датасет и GPU». Если для своих экспериментов с NCO или просто DL-моделями вам нужны облачные GPU — у Selectel есть каталог GPU-серверов. Удобно для случаев, когда не хочешь ставить под стол еще одну видеокарту.
Поворот: DeepACO, NeurIPS 2023
А вот теперь та самая красота, о которой мне больше всего хотелось рассказать. Haoran Ye на NeurIPS 2023 задал вопрос, который должен был всплыть лет за двадцать до того, но почему-то не всплыл: в формуле выбора следующего города P(i→j) ∝ τᵅ · ηᵝ эвристика ηᵢⱼ = 1/dᵢⱼ — это же просто заглушка. Так в 1992-м пришло в голову Дориго, так все с тех пор и оставляют. А что, если этот η предсказывать графовой нейросетью?
NeurIPS (Neural Information Processing Systems) — это самая престижная и крупная в мире научная конференция по ИИ и ML. Если в мире нейросетей происходит что-то по-настоящему важное, скорее всего, это представили именно там.
DeepACO работает в два шага. Сначала GNN принимает на вход координаты городов и выдает хитмап: для каждого ребра — вероятность того, что оно попадет в оптимальный тур. Этот хитмап подставляется на место ηᵢⱼ. А дальше — обычный ACO образца 1992 года. Феромоны, испарение, депозит — все по Дориго.

Тут одна и та же архитектура и один набор гиперпараметров закрывает восемь разных комбинаторных задач — TSP, CVRP, OP, PCTSP, SOP и так далее. Выученная эвристика оказалась универсальным слоем, а специфика задачи живет уже внутри самого ACO. На классических тестах маршрутизации DeepACO идет наравне со специализированными нейросетями и последовательно обгоняет чистый ACO.
Архитектурно алгоритм 1992 года превратился в бэкбон, на который сверху наворачивают deep learning. Муравьиная колония стала своеобразным фреймворком, в котором можно держать выученные приоры.
История продолжается: Kim et al. (2024) заменили REINFORCE-обучение GNN на GFlowNets и получили результат ещё лучше (на той же ACO-платформе). Идея принципиальная: REINFORCE учит нейросеть угадывать один хороший маршрут, а вот GFlowNet уже учится сэмплировать распределение качественных решений пропорционально награде.
Муравьи перестают ходить по одним и тем же дорогам и начинают исследовать карту шире. Как результат — меньше застреваний в локальных оптимумах, более разнообразная феромонная карта, и на семи бенчмарках (TSP, CVRP, и др.) GFACS обгоняет базовые ACO-варианты и конкурирует со специфичными эвристиками. Паттерн, кажется, сложился — берешь природный алгоритм, вместо ручной эвристики ставишь нейросеть, учишь end-to-end.
Что я из этого вынес
ACO в 2026-м уже не SOTA на чистом TSP. Если у вас 10 000 городов и датасет из миллиона похожих инстансов — берите POMO или DeepACO и не мучайтесь.
Но если у вас кастомная маршрутизация с экзотическими ограничениями и 200 инстансов в истории — ACO заведется прямо сейчас, без претрейна.
Если нужна интерпретируемость — феромонная карта, по сути, готовая визуализация «что алгоритм считает важным», у attention-весов такого честного смысла нет и близко.
Если решение нужно холодным стартом, без обучения — ACO до сих пор одна из лучших метаэвристик общего назначения. Ну и если у вас уже есть своя эвристика η(i,j) — вы ее просто подставляете в ACO и получаете улучшение почти бесплатно. DeepACO — это ровно та же идея, но доведенная до предела.
И напоследок главный урок, который я усвоил: не каждая задача нуждается в ИИ-шке. Иногда достаточно честно смоделировать природный процесс, и результат окажется в 0,1% от оптимума. А потом, через 34 года, ваш алгоритм возьмут слоем в GNN, и вы снова окажетесь на NeurIPS)).
Мне кажется, кандидатов еще полно. Иммунную систему уже пробовали (клональная селекция), но в связке с трансформерами никто толком не реализовал (может, я ошибаюсь, конечно, так что если вы в курсе, то поделитесь в комментариях). Грибы (не те, которые из The Last of Us, и, справедливости ради, не грибы, а слизевики), которые сами прокладывают транспортные сети, — уже щупают для графов, пейперы есть.




