Как работать с базами данных SQL в Python
В инструкции научим работать с SQL: писать запросы, получать информацию из таблиц, а также познакомим с пакетами и библиотеками Python.
Введение
Сейчас в любой сфере деятельности человека необходима работа с большим объемом данных. Данные — это поддающееся многократной интерпретации представление информации, приведенное к формализованному виду, который будет пригоден для передачи или обработки. Для удобства использования огромных объемов данных была придумана структура, называемая база данных (БД). База данных — одна из ключевых компонент любой информационной системы.
Для управления базами используются системы управления базами данных (СУБД).
SQL-запросы
Близкое взаимодействие с базами данных неразрывно связано с SQL (Structured Query Language). С помощью него можно не только создать таблицу и заполнить ее уникальной информацией, но и «вытащить» из базы практически любую информацию, используя специальные запросы.
Инициализация таблицы в SQL
В базах данных таблицы представляют собой совокупность данных, хранящихся в структурированном виде. Большие базы данных состоят из множества таблиц, взаимосвязанных специальными видами связи. Для начала создадим таблицу с помощью SQL:
CREATE TABLE Customers (
id INTEGER,
name VARCHAR,
surname VARCHAR,
birthdate DATE,
PRIMARY KEY (id)
);
Рассмотрим подробнее этот обобщенный код. Команды, выделенные заглавными буквами, являются командами языка SQL. Разные виды БД поддерживают немного различающиеся команды, но большинство из них будет иметь CREATE TABLE.
Важно внимательно работать с типами столбцов, так как они могут отличаться. В нашем примере есть такие типы, как INTEGER для чисел, VARCHAR для строк и DATE для дат. Перед тем как использовать разные типы данных лучше ознакомиться с документацией, так как VARCHAR и DATE могут иметь свои особенности.
Созданная нами таблица будет состоять из четырех столбцов: уникальный идентификатор (будет являться основным ключом), имя, фамилия в строковом типе и дата рождения.
Также при добавлении новой таблицы мы можем задать столбец, в который необходимо будет записать значение. В противном случае при попытке оставить указанный столбец пустым, нам вернется ошибка. Здесь можно провести аналогию с формой регистрации на сайте, когда без указания номера телефона или электронной почты пользователь не сможет зарегистрироваться.
Введение данных в SQL
Сейчас наша таблица пустая. Поэтому сейчас научимся заполнять ее данными:
INSERT INTO Customers (id, name, surname, birthdate)
VALUES (1, 'Ivan', 'Petrov', '2001-10-16');
Для добавления новых данных в SQL нужно применять команду INSERT INTO. Также нужно указать, куда будут добавлены данные. При передаче неверного типа данных мы получим ошибку.
Обновление данных в SQL
Может возникнуть ситуация, когда какую-то часть данных необходимо поменять. Конечно, проще изменить данные выборочно, а не переписывать всю базу целиком.
UPDATE Customers
SET name='Semyon'
WHERE id=1;
После команды UPDATE мы обязательно пишем имя таблицы, где требуется обновить данные. После мы применяем SET во всех необходимых местах для замены обновленного значения. Если мы хотим внести изменения в конкретную строку, то нужно сообщить, куда мы собираемся внести правки. Например, в данном случае применяя WHERE, мы выбираем строку с id, равным 1. В результате будет только одна строка, так как подразумевается, что id — это уникальный идентификатор.
Чтение данных в SQL
При чтении данных нужно воспользоваться SELECT:
SELECT name, surname
FROM Customers;
Так мы вернем все строки нашей таблицы, но в результате будут только две части информации: имя и фамилия. Если мы хотим получить все, что хранится в таблице, то можно воспользоваться запросом:
SELECT * FROM <table_name>;
В этом случае звездочка означает, что мы намерены получить все имеющиеся в таблице столбцы.
Основные команды SQL
В SQL есть определенное количество команд, используя которые мы усложняем запросы. Комбинируя и правильно используя их, можно получить самые разные выборки данных в зависимости от потребностей. Давайте рассмотрим основные такие команды.
WHERE
Эту команду мы уже упоминали выше. С помощью нее мы указываем какое-то условие:
SELECT <col_name1>, <col_name2>, …
FROM <table_name>
WHERE <condition>;
Условие может содержать сравнение текста или численных значений. Также допустимо использование классических логических операций: AND (и), OR (или) и NOT (отрицание).
GROUP BY
Оператор GROUP BY применяется для группировки выходных значений, в которых присутствуют агрегатные функции (например, COUNT, MAX, SUM, AVG и другие).
SELECT <col_name1>, <col_name2>, …
FROM <table_name>
GROUP BY <col_namex>;
HAVING
По своей сути HAVING является аналогом WHERE. Это ключевое слово применяется вместе с GROUP BY. Это связано с тем, что команда WHERE не может использоваться с вышеперечисленными агрегатными функциями.
SELECT <col_name1>, <col_name2>, ...
FROM <table_name>
GROUP BY <column_namex>
HAVING <condition>
ORDER BY
ORDER BY применяется в том случае, когда к результату запроса нужно применить сортировку. По умолчанию команда отсортирует выходной результат в порядке возрастания. Однако можно указать способ сортировки с помощью ASC (по возрастанию) и DESC (по убыванию).
SELECT <col_name1>, <col_name2>, …
FROM <table_name>
ORDER BY <col_name1>, <col_name2>, … ASC|DESC;
BETWEEN
BETWEEN применяется для выбора значений в определенном диапазоне. Этот оператор работает для чисел и строк, а также дат.
SELECT <col_name1>, <col_name2>, …
FROM <table_name>
WHERE <col_namex> BETWEEN <value1> AND <value2>;
LIKE
Оператор LIKE тоже используется в WHERE, когда задача требует задать шаблон для поиска.
Существует два свободных оператора, с помощью которых мы можем создавать определенные паттерны:
- % (любое количество символов (в том числе ни одного символа));
- _ (ровно один символ).
SELECT <col_name1>, <col_name2>, …
FROM <table_name>
WHERE <col_namex> LIKE <pattern>;
JOIN
JOIN применяется для соединения двух (и более таблиц), основываясь на общих атрибутах.
SELECT <col_name1>, <col_name2>, …
FROM <table_name1>
JOIN <table_name2>
ON <table_name1.col_namex> = <table2.col_namex>;
Вложенные подзапросы
Вложенные подзапросы — это запросы, включающие стандартные выражения SQL, вложенные в другой запрос. Это удобно использовать, если задача требует написать выделить какую-то информацию из результата другого запроса.
Удаление данных
Теперь мы умеем обрабатывать данные. Осталось научиться их удалять:
DELETE FROM <table_name>
WHERE id=1;
Такая команда удалит одну строку, id которой равно 1. Если необходимо удалить таблицу, то стоит применить DROP TABLE:
DROP TABLE <table_name>;
Однако можно очистить таблицу от данных, не удаляя ее саму:
TRUNCATE TABLE <table_name>;
С такими командами нужно работать предельно осторожно, ведь есть вероятность потерять важные данные. Чтобы избежать такой ситуации, следует всегда иметь актуальный бекап всей локальной базы данных.
API-модули
Python DB-API — это свод правил, которым следуют самостоятельные модули, задача которых заключается в реализации работы с БД. API-модулем мы называем программный интерфейс, посредством которого мы взаимодействуем с данными. Один принцип позволяет применять общий подход для разных БД. Поэтому для полноценной работы не нужно углубленно изучать каждую БД — достаточно разобраться с несколькими основными моментами.
adodbapi
Если возникает такая ситуация, где обязательно надо реализовать доступ через Microsoft ADO, то идеальным решением будет пакет adodbapi. И нельзя забывать, что adodbapi зависим от уже установленного PyWin32.Чтобы установить adodbapi, делаем следующее:
pip install adodbapi
Чтобы все заработало, сначала импортируем библиотеку:
import adodbapi
Далее мы указываем все необходимые для соединения данные: имя БД, строку подключения и название соответствующей таблицы.
database = "database.mdb"
connect_str = "Provider=Microsoft.Jet.OLEDB.4.0; Data Source=%s; User ID=MyUserID; Password=MyPassword;" % database
table_name = "customers"
После этого для связи с БД создаем подключение, где аргументом у метода connect() указываем строку связи:
connect = adodbapi.connect(connect_str)
Теперь создаем курсор — область памяти базы, предназначенная для хранения последнего оператора SQL. Иными словами, объект, отвечающий и за отправку запросов, и за получение их результатов.
cursor = connect.cursor()
Дальше мы уже можем передавать конкретные запросы и обрабатывать их вывод.
query = "SELECT * FROM %s" % table_name
cursor.execute(query)
В конце обязательно завершаем подключение:
cursor.close()
connect.close()
pyodbc
Сейчас ознакомимся с ODBC (Open Database Connectivity) — интерфейсом доступа к БД, разработанный в компании Microsoft. Суть ODBC заключается в разработке приложений для использования программного интерфейса доступа без опасений о различиях взаимодействия с разными источниками. Это достигается написанием драйверов, осуществляющих стандартные функции с учетом деталей реализации конкретного продукта. Самый используемый метод связи через ODBC — пакет pyodbc. Он устанавливается с помощью pip:
pip install pyodbc
После установки импортируем библиотеку:
import pyodbc
Далее необходимо написать строку связи:
connect_str = "DRIVER={SQL Server}; SERVER=localhost; PORT=1433; DATABASE=database; UID=uid; PWD=password"
В данном случае строка связи состоит из нескольких частей. Хорошей практикой будет сохранить все параметры в отдельный конфигурационный файл, в котором и будут храниться все необходимые параметры. Это добавит удобства при использовании и может обезопасить систему. После соединяемся с БД и получаем курсор:
connect = pyodbc.connect(connect_str)
cursor = connect.cursor()
Если мы успешно подключились, то, используя это соединение, мы можем применить курсор для получения ответа на запрос:
cursor.execute('SELECT * FROM <table_name>')
Теперь можно получить результат, вызвав методы fetchone() и fetchall(). Способы их использования мы рассмотрим чуть ниже.Так как не только базы данных от Microsoft поддерживают такой вид соединения, то пакет pyodbc можно использовать при работе и с другими базами данных, совместимыми с ODBC.
pypyodbc
Пакет pypyodbc можно назвать скриптом, написанным на Python. Интересно, что на самом деле pyodbc — это Python, завернутый в бэкэнд С++, в то время как pypyodbc уже является чистым кодом на Python. Чаще всего эти модули взаимозаменяемы. Единственное различие будет заключаться в импорте:
import pypyodbc
SQLite в Python
В отличие от других баз данных SQL, которые мы будем рассматривать дальше, у Python’a уже есть встроенная поддержка для SQLite — компактной встраиваемой СУБД. Для этой БД API-модулем будет sqlite3. Поэтому для корректной работы достаточно добавить импортирование стандартной библиотеки и ничего заранее устанавливать не нужно:
import sqlite3
Подключение к базе данных
Далее обязательным этапом следует создание соединения:
connect = sqlite3.connect('database.sqlite')
Здесь мы указываем путь до файла базы данных. Следующим шагом требуется создать объект курсора:
cursor = connect.cursor()
Чтение из базы
Для чтения необходимо сделать следующее:
cursor.execute("SELECT <column_name> FROM <table_name>")
После вызова метода execute() мы уже пользуемся привычным синтаксисом SQL. Для получения ответа воспользуемся fetchall():
results = cursor.fetchall()
Так мы получаем все строки результата сделанного запроса. Важно помнить, что после того, как мы получили ответ на запрос из курсора, чтобы получить этот результат еще раз, необходимо повторно выполнить запрос. Иначе вернется пустой результат (null).
После окончания всех требуемых операций, обязательно нужно закрыть наше соединение:
connect.close()
Запись в базу
Аналогично чтению, для записи в БД нужно написать запрос к ней:
cursor.execute("INSERT INTO <table_name> (id, name, surname, birthdate) VALUES (2, 'Petr', 'Ivanov', '2003-12-13') ")
Однако, если мы не только читаем, но и вносим какие-либо изменения, обязательно нужно сохранить транзакцию:
connect.commit()
Когда к базе установлено не одно соединение, а одно из них пытается как-то модифицировать данные, база данных SQLite блокируется до завершения или отмены текущей транзакции. Закончить транзакцию можно методом commit(), а отменить ее — методом rollback().
MySQL в Python
MySQL — это СУБД с открытым исходным кодом (open source). Ее можно подключить несколькими способами. Один из наиболее распространенных — это использование пакета MySQLdb, у которого существует несколько версий. Из-за наличия различных версий, часть из которых несовместима с конкретными версиями Python, может возникнуть путаница.
Поэтому рассмотрим подробно один конкретный пакет mysqlclient — ответвление MySQL-Python (как раз MySQLdb), которое предоставляет поддержание Python 3. Важно отметить, что нам понадобится MySQL или MySQL Client для его успешной установки:
pip install mysqlclient
После этого пакет mysqlclient будет установлен. Теперь посмотрим, как работа с этим пакетом будет реализована в коде:
import MySQLdb
Так мы подключаем сам пакет.
connect = MySQLdb.connect('localhost', 'username', 'password', 'table_name')
Этой строчкой мы создаем соединение. Обязательно указываем сервер, куда подключаемся, логин и пароль для соединения, а также название таблицы, с которой будем осуществлять взаимодействие.
cursor = connect.cursor()
cursor.execute("SELECT * FROM <table_name>")
Курсор создан. Можно начинать выполнять конкретные запросы.
row = cursor.fetchone()
Здесь мы извлекаем только одну строку из всего результата и дальше можем обрабатывать ее так, как требует решаемая задача.
connect.close()
Не забываем закрыть связь с БД.
PostgreSQL в Python
PostgresSQL является еще одной БД, распространяемой как свободное программное обеспечение, широко используемое в разработке. У Python существует несколько пакетов, которые поддерживают этот бэкэнд, но мы изучим работу с одним из них — Psycopg. Аналогично другим пакетам для начала необходимо его установить:
pip install psycopg2
Уже в коде будет необходимо импортировать этот пакет:
import psycopg2
После этого аналогично работе с MySQL мы передаем в переменную connect соединение:
connect = psycopg2.connect(host='hostname', user='username', password='password', dbname='database')
Что делать дальше нам уже известно — создавать курсор:
cursor = connect.cursor()
Далее посмотрим на этот фрагмент кода:
cursor.execute("SELECT * FROM <table_name>")
row = cursor.fetchone()
cursor.close()
connect.close()
С помощью метода execute() мы делаем запрос к БД. После этого получаем одну строку результата с помощью fetchone(). После чего разрываем подключение к базе данных, закрывая и курсор, и соединение.
За исключением нескольких особенностей, работа с Psycopg практически не отличается от работы с другими пакетами. Мы помним, что и mysqlclient, и Psycopg следуют стандартному API, которому, на самом деле, следует большая часть пакетов. Именно поэтому код взаимодействия с разными БД практически не отличается между собой. Так мы можем подтвердить, что несмотря на существующие различия, работа с разными пакетами сводится к нескольким одинаковым командам.
Расширенные методы курсора
Теперь рассмотрим особые возможности курсора, которые могут помочь при взаимодействии с базой данных.
Разбивка запроса на строки
Часто приходится писать длинные SQL-запросы, состоящие из множества строк. К сожалению, при написании запроса в одну строку теряется читабельность. Поэтому в коде удобно разбить такой запрос на несколько строчек, заключив его в тройные кавычки:
cursor.execute("""
SELECT surname
FROM <table_name>
ORDER BY surname LIMIT 4
""")
Объединение запросов к БД
Метод execute() позволяет выполнить за раз лишь один запрос (если написать сразу несколько запросов, разделив их точкой с запятой или другим разделителем, то мы получим ошибку). Однако чаще всего в разработке требуется обратиться к БД далеко не один раз. Конечно, можно просто вызвать этот метод несколько раз подряд:
cursor.execute("INSERT INTO <table_name> (id, name, surname, birthdate) VALUES (3, 'Stepan', 'Platonov', '2010-01-01') ")
cursor.execute("INSERT INTO <table_name> (id, name, surname, birthdate) VALUES (4, 'Platon', 'Stepanov', '2010-02-02') ")
Но можно воспользоваться более изящным решением и вызвать executescript():
cursor.executescript("""
INSERT INTO <table_name> (id, name, surname, birthdate) VALUES (3, 'Stepan', 'Platonov', '2010-01-01');
INSERT INTO <table_name> (id, name, surname, birthdate) VALUES (4, 'Platon', 'Stepanov', '2010-02-02');
""")
Также этот метод может помочь в том случае, если мы сохранили тело запроса в файл или отдельную переменную.
Подстановка значения в запрос
В процессе написания кода, в котором мы тесно взаимодействуем с БД, может возникнуть ситуация, когда необходимо подставить конкретное значение в запрос. Тогда поможет применение второго аргумента в методе execute():
cursor.execute("SELECT surname FROM <table_name> ORDER BY surname LIMIT ?", ('2'))
Или есть еще один способ:
cursor.execute("SELECT surname FROM <table_name> ORDER BY surname LIMIT :limit", {"limit": 2})
Важно! В PostgreSQL и в MySQL для подстановки вместо знака ‘?’ нужно писать %s.
Также стоит отметить, что этот способ не подойдет для замены названия таблицы.
Множественная вставка строк
Для вставки нескольких строк воспользуемся методом executemany(), в который в независимости от количества значений необходимо передавать список кортежей:
new_users = [
('User',),
('User-2',),
('User-3',),
]
В этом примере мы как раз используем кортеж (поэтому после имени пользователя идет запятая), несмотря на то что передаем только одно значение. После этого вставляем полученный список:
cursor.executemany("INSERT INTO Users VALUES (Null, ?);", new_users)
Таким образом, проходясь по списку, мы вставляем сразу несколько строк.
Повышение устойчивости кода
Сейчас в любом проекте требуется правильно обрабатывать и отлавливать возможные ошибки во время исполнения программы. Особенно это может быть критично при записи информации в базу данных. Поэтому полезно оборачивать обращение к БД в конструкцию «try-except-else»:
try:
cursor.execute(query)
result = cursor.fetchall()
except sqlite3.DatabaseError as error:
print("Error: ", error)
else:
connect.commit()
Подробнее рассмотрим этот фрагмент. В try мы передаем инструкцию для SQL, после чего записываем в result весь результат. При возникновении ошибки мы используем встроенный в sqlite3 объект ошибок и печатаем его в консоль. В противном случае, если же все отработало корректно, мы сохраняем изменения. Такой подход может сильно упростить исправление ошибок в ходе разработки.
Создание таблиц
Перед нами стоит простая задача: создать таблицу. На примере этой задачи мы окончательно разберемся в принципе работы с БД в Python. Ниже посмотрим на функцию, задача которой будет осуществлять работу с такими БД, как SQLite и MySQL (для PostgreSQL будет незначительно отличаться несколькими строчками):
def execute_query(connect, query):
cursor = connect.cursor()
try:
cursor.execute(query)
connect.commit()
print("Success!")
except Error as err:
print("Error: ", err)
В аргументы execute_query() мы передаем соединение и сам запрос. Дальше с помощью курсора мы исполняем запрос и сохраняем транзакцию. Также сразу обрабатываем ошибки, которые могут возникнуть.
Выше мы уже подробно изучили, что делает каждая строчка кода, здесь же все объединено в одну функцию для удобства написания кода. Теперь осталось написать сам запрос, который будет создавать новую таблицу:
create_table_query = """
CREATE TABLE customers (
id INTEGER PRIMARY KEY AUTO_INCREMENT,
name TEXT NOT NULL,
surname TEXT,
age INTEGER
);
В этом запросе мы создаем таблицу клиентов, у каждого из которых будет свой id (генерирующийся самостоятельно), имя, фамилия и возраст. Осталось вызвать execute_query():
execute_query(connect, create_table_query)
Все, новая таблица будет создана.
Работа с записями в БД с помощью Python
Теперь мы уже можем подвести итог о принципе работы Python с базами данных. Вне зависимости от того, какую цель мы преследуем и какие действия мы хотим сделать с таблицей, все сводится к отправлению запросов на SQL, которые мы передаем в курсор. Далее мы кратко рассмотрим примеры, связанные с различными операциями с таблицами.
Мы уже знаем, что в зависимости от конкретной задачи будет изменяться только SQL-запрос. Поэтому ниже посмотрим на соответствующие запросы для разных подзадач.
Добавление записей
add_customers_query = """
INSERT INTO
customers (name, surname, age)
VALUES
('Anne', 'Samoilova', 26),
('Petr', 'Ogurechkin', 44),
('Samanta', 'Ivanova', 31);
"""
Внутри запроса мы добавляем в таблицу customers трех человек, для каждого указывая имя, фамилию и возраст. Осталось передать этот запрос в execute_query(), как мы делали выше.
Обновление данных
update_customer_query = """
UPDATE
customers
SET
name = 'Pavel'
WHERE
id = 2
"""
В этом запросе мы изменяем имя клиенту с id равном 2. При передаче этого запроса в функцию мы успешно обновим информацию в таблице.
Чтение данных
select_customers_query = "SELECT * FROM customers"
Выполняя этот запрос, мы получим всех клиентов, информация о ком хранится в таблице.
Удаление данных
delete_customer_query = "DELETE FROM customers WHERE id = 1"
А теперь удалим клиента с id равным 1.
Дополнительные возможности SQLite
SQLite широко используется и легко поддерживается большинством клиентов SQL. Рассмотрим некоторые интересные возможности SQLite.
Подключение к БД из клиента SQL
Если мы запускаем Python на локальном компьютере, то с помощью какого-нибудь клиента SQL можно напрямую подключиться к файлу БД. Одним из таких клиентов является приложение DBeaver, позволяющий управлять базой данных.
Алгоритм работы как и раньше: сначала нужно создаем новое соединение: правой кнопкой мыши по названию БД (при установке DBeaver предлагает создать тестовую базу данных, чтобы ознакомиться с функционалом приложения) → Создать → Соединение:

После выбора подходящей нам базы данных SQLite, мы нажимаем Далее и в специальном окне настраиваем соединение нужным нам образом:
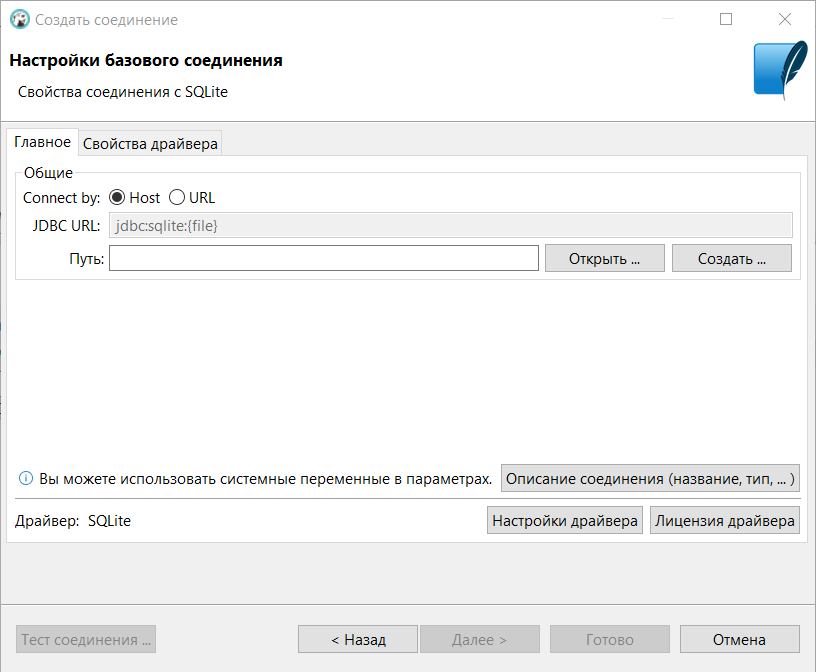
После завершения всех настроек и указания верных путей мы уже можем сделать любой SQL-запрос.
Интеграция с фреймворком Pandas
На самом деле в Python есть библиотека, специально предназначенная для обработки и анализа структурированных данных. Библиотека Pandas — это гибкий и мощный инструмент, широко применяемый в анализе данных.
В фреймворке Pandas есть множество специальных структур и операций для эффективной работы с данными. Основополагающей частью Pandas является фрейм данных (от DataFrame) — структура, представляющая собой двумерный набор данных, хранящихся в табличной форме. Но также фрейм данных непрерывно интегрируется с SQLite.
Как мы уже привыкли, сначала нужно импортировать библиотеку:
import pandas as pd
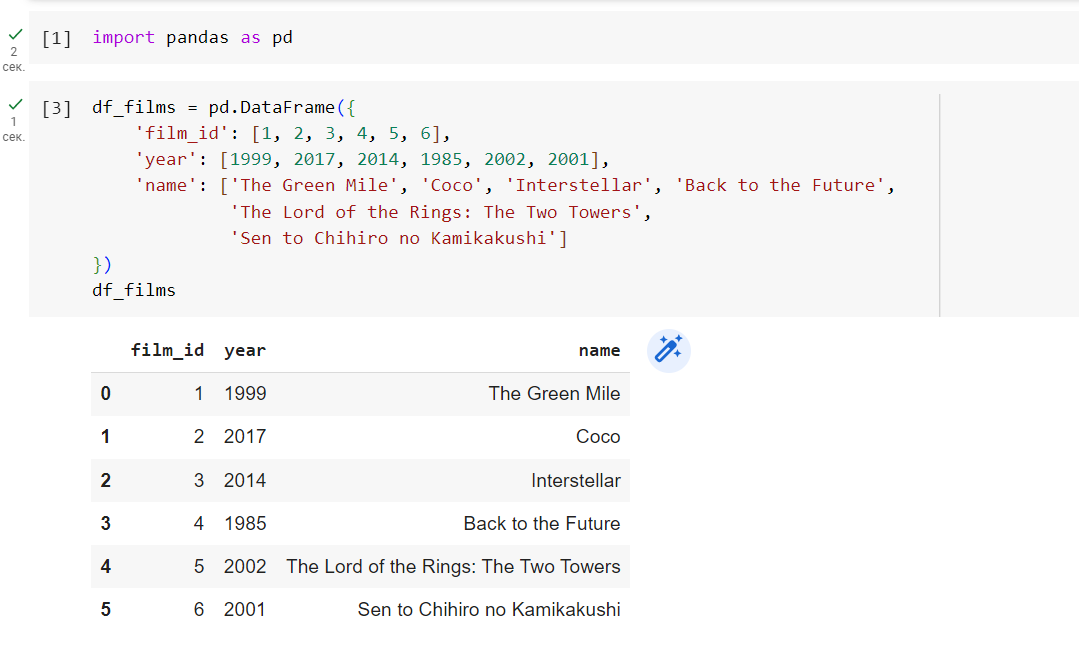
Для демонстрации этого сначала определим какой-нибудь фрейм данных:
df_films = pd.DataFrame({
'film_id': [1, 2, 3, 4, 5, 6],
'year': [1999, 2017, 2014, 1985, 2002, 2001],
'name': ['The Green Mile', 'Coco', 'Interstellar', 'Back to the Future', 'The Lord of the Rings: The Two Towers', 'Sen to Chihiro no kamikakushi']
})
Также мы могли прочитать дата фрейм из файла с расширением csv:
df_films = pd.read_csv(filepath_or_buffer = "file_with_films.csv", sep = ';')
Теперь у нас есть небольшой фрейм данных, посвященный фильмам. У фрейма есть метод to_sql(), позволяющий сохранить его в БД. Воспользуемся им:
df_films.to_sql('Films', connection)
Теперь у нас есть таблица в нашей БД, соединение с которой мы передали в аргументы метода. Длина столбцов и типы данных будут сгенерированы автоматически. Но если появится такая необходимость, конечно, их можно будет изменить.
Если же мы хотим написать какой-то SQL-запрос к таблице, то это также легко делается с помощью метода read_sql():
df = pd.read_sql('''
SELECT * FROM Films
''', connection)
Можем сделать вывод, что с помощью библиотеки Pandas можно очень просто реализовать работу с реляционной базой данных SQLite.
Заключение
Мы тесно поработали с SQL, научились писать запросы, используя специальные операторы и теперь умеем получать самую разную информацию из таблиц в зависимости от поставленной задачи.
Также в этой статье мы ознакомились с разнообразными пакетами и библиотеками языка Python, позволяющими реализовать и упростить неочевидное взаимодействие с базами данных SQL. Python позволяет без труда совершать множество операций, начиная от создания таблиц и заканчивая модификацией строк в уже существующих записях.