Как настроить репликацию в PostgreSQL
Настраиваем репликацию данных в PostgreSQL на двух виртуальных серверах.
Введение
В статье мы расскажем, что такое репликация и где она применяется. Также на примере двух виртуальных серверов настроим репликацию данных в PostgreSQL и проверим, что она работает.
Что такое репликация
Репликация — это дублирование данных, когда данные с одного сервера полностью повторяются на других. Приложения пишут данные в одну базу данных PostgreSQL, а изменения автоматически синхронизируются на другие базы.
Репликация используется для достижения двух целей:
- Повышение отказоустойчивости. Если один из серверов выйдет из строя, то остальные продолжат работу.
- Повышение производительности. Распределение данных по серверам в разных частях страны или мира повышает скорость доступа к данным для местных пользователей.
Виды репликации в PostgreSQL
Существует несколько видов репликаций, у каждого из них свои особенности. Но прежде чем рассказывать о видах, нужно хотя бы поверхностно познакомиться с WAL — журналом предзаписи транзакций.
Когда PostgreSQL получает команду на изменение данных, она не сразу изменяет их на диске. Сначала она записывает изменения в WAL. Этот журнал нужен для того, чтобы в случае сбоя сервера можно было восстановить незафиксированные данные. Также WAL используется и для репликации данных.
Итак, в PostgreSQL есть несколько видов репликации:
Потоковая репликация (Streaming Replication). Это репликация, при которой от основного сервера PostgreSQL на реплики передается WAL. И каждая реплика затем по этому журналу изменяет свои данные. Для настройки такой репликации все серверы должны быть одной версии, работать на одной ОС и архитектуре. Потоковая репликация в Postgres бывает двух видов — асинхронная и синхронная.
- Асинхронная репликация. В этом случае PostgreSQL сначала применит изменения на основном узле и только потом отправит записи из WAL на реплики. Преимущество такого способа — быстрое подтверждение транзакции, т.к. не нужно ждать пока все реплики применят изменения. Недостаток в том, что при падении основного сервера часть данных на репликах может потеряться, так как изменения не успели продублироваться.
- Синхронная репликация. В этом случае изменения сначала записываются в WAL хотя бы одной реплики и только после этого фиксируются на основном сервере. Преимущество — более надежный способ, при котором сложнее потерять данные. Недостаток — операции выполняются медленнее, потому что прежде чем подтвердить транзакцию, нужно сначала продублировать ее на реплике.
Логическая репликация (Logical Replication). Логическая репликация оперирует записями в таблицах PostgreSQL. Этим она отличается от потоковой репликации, которая оперирует физическим уровнем данных: биты, байты, и адреса блоков на диске. Возможность настройки логической репликации появилась в PostgreSQL 10.
Этот вид репликации построен на механизме публикации/подписки: один сервер публикует изменения, другой подписывается на них. При этом подписываться можно не на все изменения, а выборочно. Например, на основном сервере 50 таблиц: 25 из них могут копироваться на одну реплику, а 25 — на другую.
Также есть несколько ограничений, главное из которых — нельзя реплицировать изменения структуры БД. То есть если на основном сервере добавится новая таблица или столбец — эти изменения не попадут в реплики автоматически, их нужно применять отдельно.
В отличие от потоковой репликации, логическая может работать между разными версиями PostgreSQL, ОС и архитектурами.
Облачные базы данных
Готовые к работе управляемые базы данных MySQL с встроенной репликацией.
Установить PostgreSQL
Перейдем к практике: настроим потоковую асинхронную репликацию в режиме Master-Replica: один сервер — основной, в него можно писать данные, другой — реплика, из него можно только читать.
На примере платформы Selectel создадим два отдельных сервера PostgreSQL, один из которых будет основным (Master), а второй — репликой (Replica).
В панели управления платформой заходим в раздел Облачная платформа — Серверы, нажимаем кнопку Создать сервер.
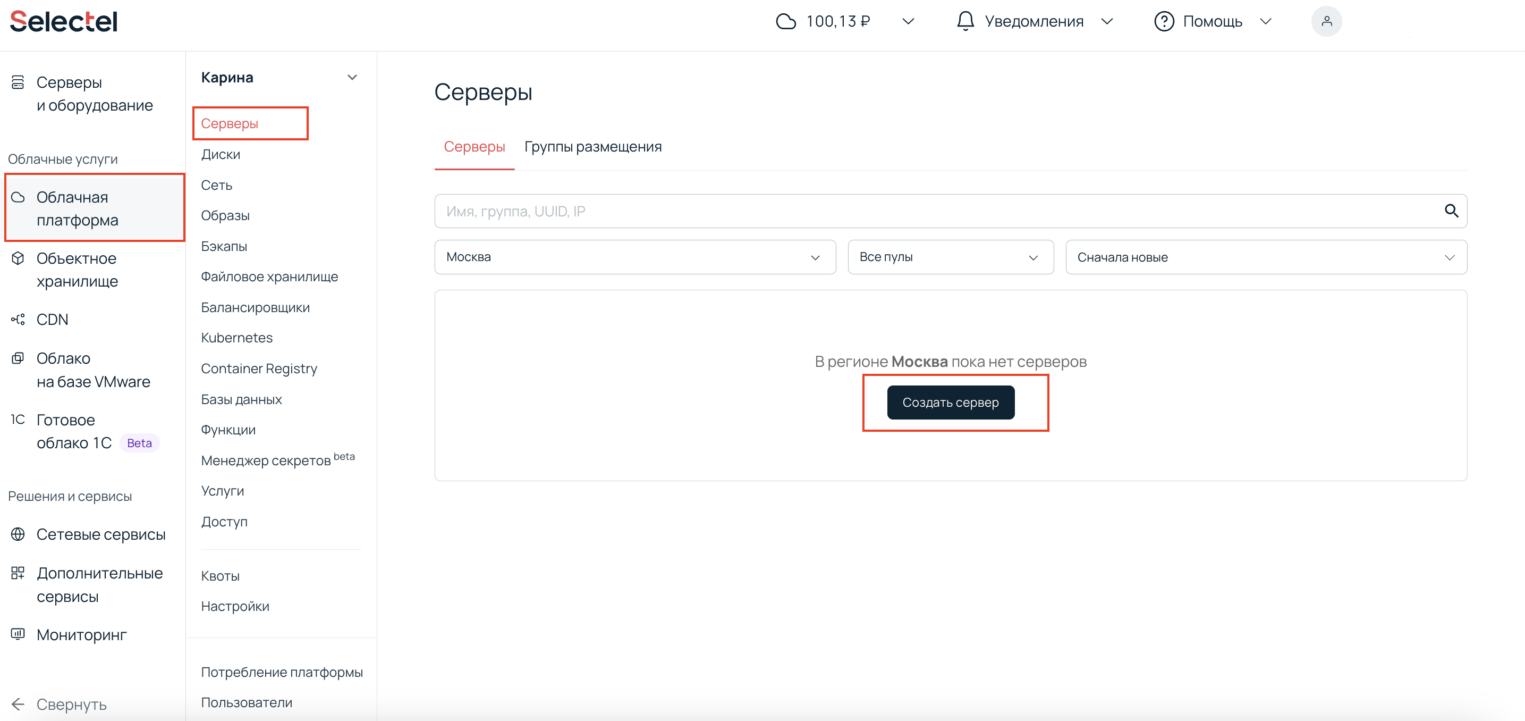
Укажем имя сервера — Master. Так нам будет проще ориентироваться в серверах. Выберем ОС — Ubuntu 22.04, конфигурацию — 2 vCPU, 8 ГБ оперативной памяти и 10 ГБ диска.
В разделе Сеть нужно выбрать подсеть с публичным адресом, чтобы к виртуальной машине можно было подключаться из интернета. В разделе Доступ нужно проверить, что вы либо записали пароль root-пользователя, либо указали правильный SSH-ключ для подключения к машине.
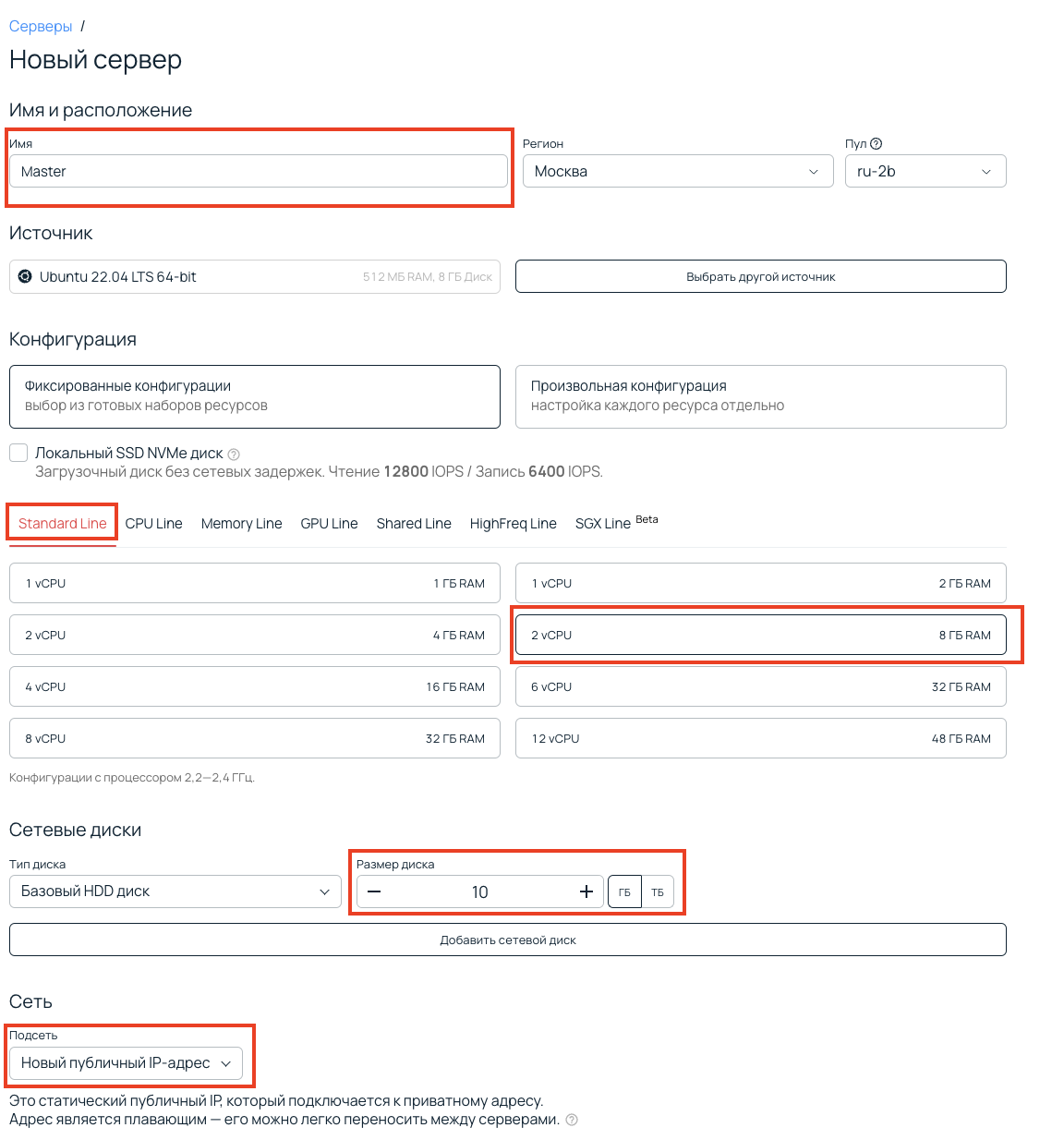
По такому же принципу создаем второй сервер, только укажем другое имя — Replica. Остальные параметры оставим такими же.
В итоге у нас получилось два сервера. Обратите внимание, что у них есть публичные и приватные IP-адреса.
Публичные адреса мы будем использовать для подключения к машинам, а приватные — для настройки репликации.
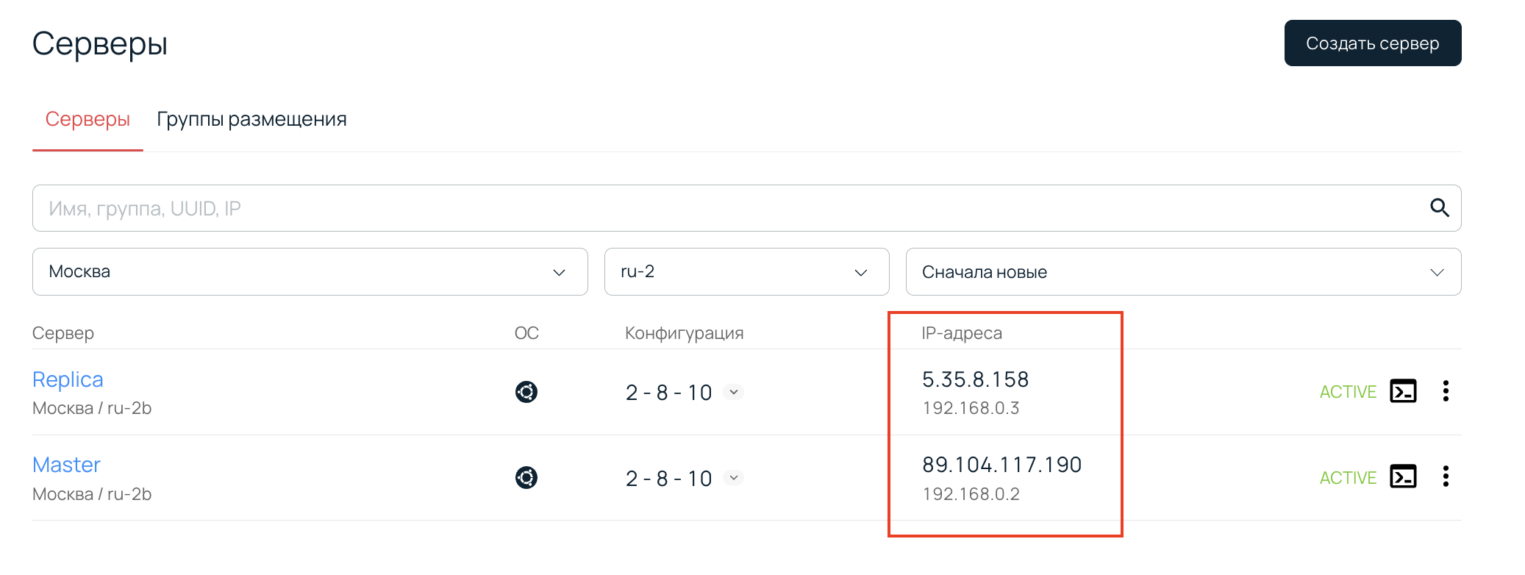
Теперь нужно подключиться к каждому серверу по SSH. Рекомендуем открыть 2 окна терминала и держать их открытыми, потому что мы будем часто переключаться между серверами.
Итак, подключаемся к серверам и устанавливаем PostgreSQL на каждом из них:
apt-get update
apt-get install postgresql
Все, сервера готовы к настройке репликации. Сейчас они ничем не отличаются друг от друга, кроме названия. Перейдем к настройке каждого из них.
Настроить Master-сервер
Репликацию будем выполнять под пользователем postgres, который автоматически создается после установки PostgreSQL. Установим ему пароль, он нам понадобится позже:
su - postgres
psql -c "ALTER ROLE postgres PASSWORD 'ВАШ_ПАРОЛЬ'"
exit
Далее нужно разрешить этому пользователю подключаться из Replica-сервера в Master. Для этого мы отредактируем файл /etc/postgresql/12/main/pg_hba.conf.
Обратите внимание, что мы показываем настройку репликации на примере PostgreSQL 12, поэтому в пути к файлу есть номер — 12. Если у вас другая версия PostgreSQL, то вам нужно поменять путь к файлу.
Итак, откроем файл:
nano /etc/postgresql/12/main/pg_hba.conf
Найдем в нем строчку «If you want to allow non-local connections, you need to add more» и впишем после нее такую строчку:
host replication postgres REPLICA_ВНУТРЕННИЙ_IP/32 md5Так мы разрешаем пользователю postgres подключаться к этому серверу из Replica.
# If you want to allow non-local connections, you need to add more
# “host” records. In that case you will also need to make PostgreSQL
# listen on a non-local interface via the listen_address
# configuration parameter, or via the -i or -h command line switches.
host replication postgres 192.168.0.3/32 md5
Обратите внимание, что мы используем приватные адреса, потому что виртуальные машины находятся в одной сети. При этом нам не нужно открывать порты, настраивать Firewall и так далее. Если ваши машины будут находиться в разных сетях или вы хотите, чтобы они общались друг с другом по публичным адресам — скорее всего вам придется настроить Firewall.
Далее нужно указать настройки репликации. Открываем конфигурационный файл PostgreSQL:
nano /etc/postgresql/12/main/postgresql.conf
Находим в нем эти параметры, раскомментируем их и подставляем указанные значения.
listen_addresses = 'localhost, MASTER_ВНУТРЕННИЙ_IP'
wal_level = hot_standby
archive_mode = on
archive_command = 'cd .'
max_wal_senders = 8
hot_standby = on
Все, Master настроен. Чтобы применить настройки, перезапускаем сервер:
service postgresql restart
Настроить Replica-сервер
Переключаемся в окно терминала Replica-сервера. Перед началом настройки нужно остановить PostgreSQL-сервер:
service postgresql stop
Аналогично Master-серверу отредактируем файл pg_hba.conf. В то же самое место вставим ту же самую строчку, но только теперь укажем IP-адрес мастера.
Открываем файл:
nano /etc/postgresql/12/main/pg_hba.conf
Добавляем в него строчку:
host replication postgres MASTER_ВНУТРЕННИЙ_IP/32 md5
Затем правим файл postgresql.conf. Настройки те же самые, как и у Master, только нужно поменять IP-адрес. Открываем файл на редактирование:
nano /etc/postgresql/12/main/postgresql.conf
Находим в нем эти параметры, раскомментируем их и подставляем указанные значения:
listen_addresses = 'localhost, REPLICA_ВНУТРЕННИЙ_IP'
wal_level = hot_standby
archive_mode = on
archive_command = 'cd .'
max_wal_senders = 8
hot_standby = on
Сейчас настройки обоих серверов одинаковые, отличаются только IP-адреса. Это потому, что при необходимости реплики могут становиться мастером, а вся разница будет в наличии одного лишь файла. О нем расскажем далее.
Прежде чем Replica-сервер сможет начать реплицировать данные, нужно создать новую БД, идентичную Master-серверу. Для этого воспользуемся утилитой pg_basebackup. Она создаст бэкап с Master-сервера и скачает его на Replica-сервер. Эту операцию нужно выполнять от имени пользователя postgres, поэтому логинимся от него:
su - postgres
Далее переходим в каталог с базой данных:
cd /var/lib/postgresql/12/
Удалим каталог с дефолтной БД и снова его создадим, но уже пустой:
rm -rf main; mkdir main; chmod go-rwx main
Теперь выгрузим БД с мастера. Для выполнения этой команды нужно будет ввести пароль от пользователя postgres, который мы задавали в самом начале настройки Master-сервера.
pg_basebackup -P -R -X stream -c fast -h MASTER_ВНУТРЕННИЙ_IP -U postgres -D ./main
В этой команде есть важный параметр -R. Он означает, что PostgreSQL-сервер также создаст пустой файл standby.signal. Несмотря на то, что файл пустой, само наличие этого файла означает, что этот сервер — реплика.
Файл standby.signal появился только в PostgreSQL версии 12. Раньше вместо него создавался файл recovery.conf, в котором хранились настройки для подключения к Master-серверу. Имейте это ввиду, если вы используете более ранние версии PostgreSQL.
Возвращаемся в root-пользователя и запускаем PostgreSQL-сервер:
exit
service postgresql start
Проверить репликацию
Теперь нужно протестировать репликацию и убедиться, что мы все правильно настроили. На Master-сервере создадим таблицу и вставим в нее одну строчку:
su - postgres
psql -c "CREATE TABLE test_table (id INT, name TEXT);"
psql -c "INSERT INTO test_table (id, name) VALUES (1, 'test');"
Переключимся в терминал Replica-сервера и проверим, что таблица с данными появилась:
su - postgres
psql -c "SELECT * FROM test_table;"
Результат:
id | name
----+------
1 | test
(1 row)
Еще одна проверка — попробуем создать новую таблицу на сервере Replica. Если мы все сделали правильно, то сервер не должен позволить нам этого сделать, потому что он настроен только на репликацию с основной БД.
На Replica-сервере выполняем команду:
psql -c "CREATE TABLE test_table2 (id INT, name TEXT);"
Результат:
ERROR: cannot execute CREATE TABLE in a read-only transaction
Значит репликация настроена правильно.
Теперь покажем, как можно из Replica-сервера сделать Master. Сымитируем ситуацию, что основной сервер вышел из строя. Для этого в консоли управления платформой Selectel просто выключим сервер Master.
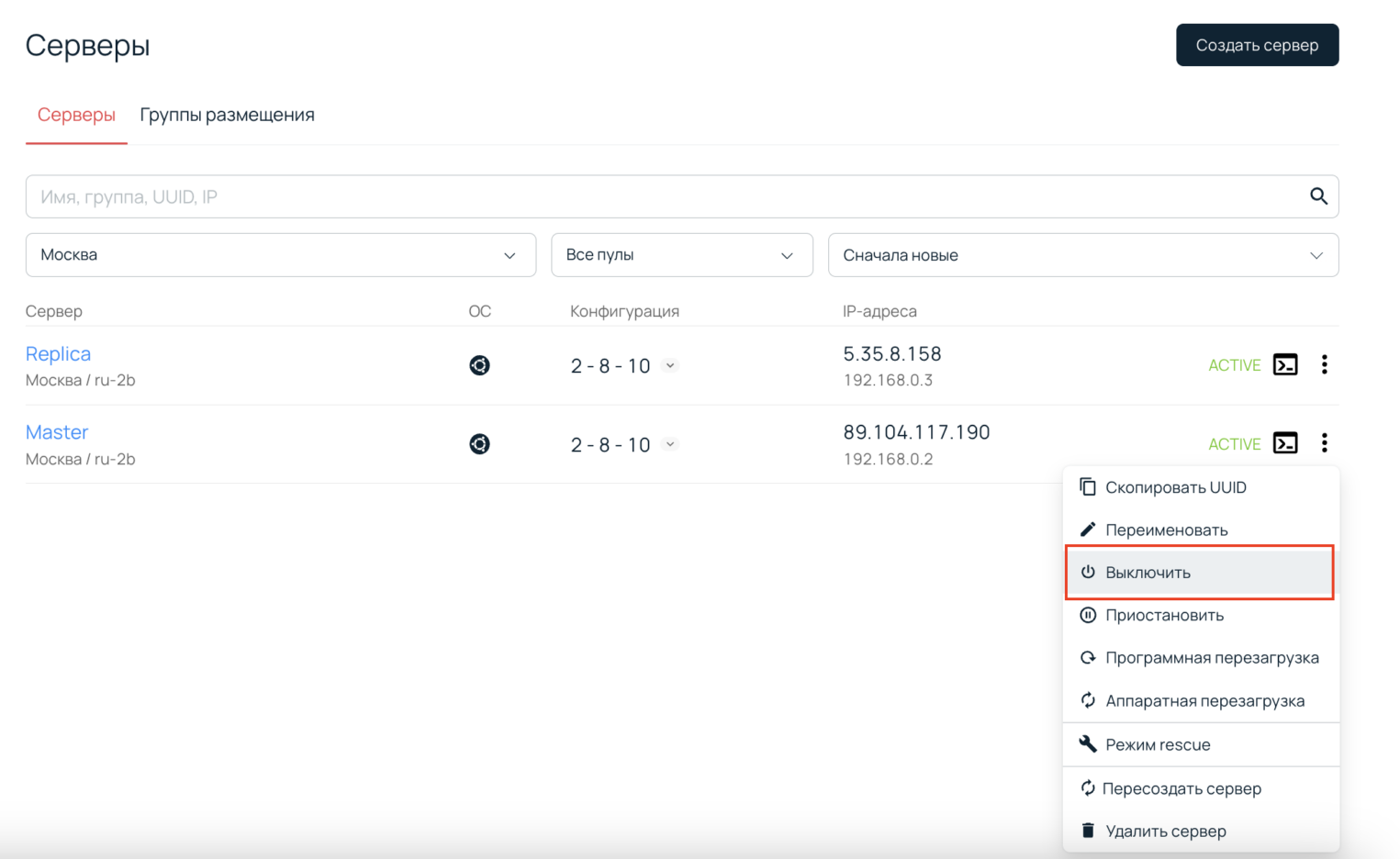
Чтобы перевести Replica-сервер в режим записи, выполните команду:
/usr/lib/postgresql/12/bin/pg_ctl promote -D /var/lib/postgresql/12/main
Проверяем, снова пробуем создать новую таблицу:
psql -c "CREATE TABLE test_table2 (id INT, name TEXT);"
На этот раз таблица создастся. Значит, мы перевели сервер из режима чтения в режим записи.
Но нужно понимать, что запросы от приложений не начнут автоматически направляться на этот сервер. Если сервисы и приложения подключались к «старому» Master-серверу напрямую, они так и будут пытаться подключаться к нему.
Обычно в такой ситуации используется балансировщик нагрузки. Он сам следит за состоянием серверов и распределяет нагрузку между всеми рабочими инстансами. При этом приложения отправляют запросы не напрямую в СУБД, а в балансировщик нагрузки.
Заключение
В статье мы показали, как настроить репликацию в PostgreSQL и проверить ее. Это не сложно, но требует некоторой подготовки. Есть и другой способ — использовать managed-решения.
На нашей платформе есть управляемая PostgreSQL, которая создается в несколько кликов мыши. Вам не придется настраивать и сопровождать СУБД, а репликация и балансировщик нагрузки есть «из коробки». Если Master-сервер выйдет из строя, платформа автоматически переключит одну из реплик в режим записи и перенаправить на нее все запросы.