Как настроить пайплайн для микросервисного приложения
Рассказываем, как в GitLab организовать CI для автоматизации сборки, тестирования и деплоя приложений. На примере монолита и микросервисов.
Какие два самых любимых дела у программистов? Автоматизировать и переписывать приложения на микросервисы. Можно долго обсуждать, какие у них преимущества с позиции архитектуры — тема актуальная. Но вместо нее мы рассмотрим организацию CI для автоматизации сборки, тестирования и деплоя приложений. Начнем с основ на примере «монолита», а потом усложним их микросервисами.
Базовый пайплайн
Давайте создадим базовую последовательность шагов, которая тестирует приложение и позволяет одной кнопкой выкатить его на окружение. Представим, что в нашем проекте активно используются технологии контейнеризации и, например, Python.
Последовательность шагов
- Сборка build-образа, который содержит все зависимости.
- Тестирование.
- Сборка deploy-образа, в котором есть только основные зависимости приложения.
- Выкатка изменений на окружение (ручная активация действия).
Это типичный фундамент пайплайнов, который можно встретить не в одной статье. Давайте конвертируем его в YAML и кратко его разберем.
# Переопределяем этапы
stages:
- build-ci
- test
- build-app
- deploy
# Глобальные переменные
# В данном случае, это название образа, в котором
# тестируется приложение
variables:
CI_IMAGE_NAME: "$CI_REGISTRY_IMAGE/ci-base-image:$CI_COMMIT_SHA"
# Собираем образ со всеми зависимостями
build:
stage: build-ci
image: docker:latest
before_script:
- docker login -u gitlab-ci-token -p ${CI_JOB_TOKEN} ${CI_REGISTRY}
script:
- docker build --tag "$CI_IMAGE_NAME" -f ./Dockerfile .
- docker push "$CI_IMAGE_NAME"
# Тесты в собранном образе
check-sort:
stage: test
image: "$CI_IMAGE_NAME"
script:
- isort --check-only .
check-style:
stage: test
image: "$CI_IMAGE_NAME"
script:
- black --check .
# Собираем deploy-образ
build-deploy:
stage: build-app
image: "$CI_IMAGE_NAME"
script:
- echo "build done"
# Выкатываем образ
deploy:
stage: deploy
image: docker:latest
script:
- echo "Deploy"
when: manual
Это самый простой пример, который в неявном виде определяет зависимость шагов между собой. Порядок этапов определен в блоке stages, а переход к следующему этапу возможен только после завершения всех шагов в текущем.
Этого достаточно для небольшого приложения, но прогресс не стоит на месте. Предположим, что ваше приложение разрослось и тесты занимают несколько часов. Вы придумали, как оптимизировать процесс: сначала запускаете маленький набор тестов (smoke-тесты), а потом — полный набор.
Логично поместить тесты в один этап. Но если вы захотели явно определить, чтобы полноценные тесты запускались только в случае успеха быстрых, вам поможет параметр needs.
smoke-test:
stage: test
image: "$CI_IMAGE_NAME"
script:
- sleep 30
full-test:
stage: test
image: "$CI_IMAGE_NAME"
# Зависимости указываются в этом блоке
needs:
- smoke-test
script:
- sleep 500
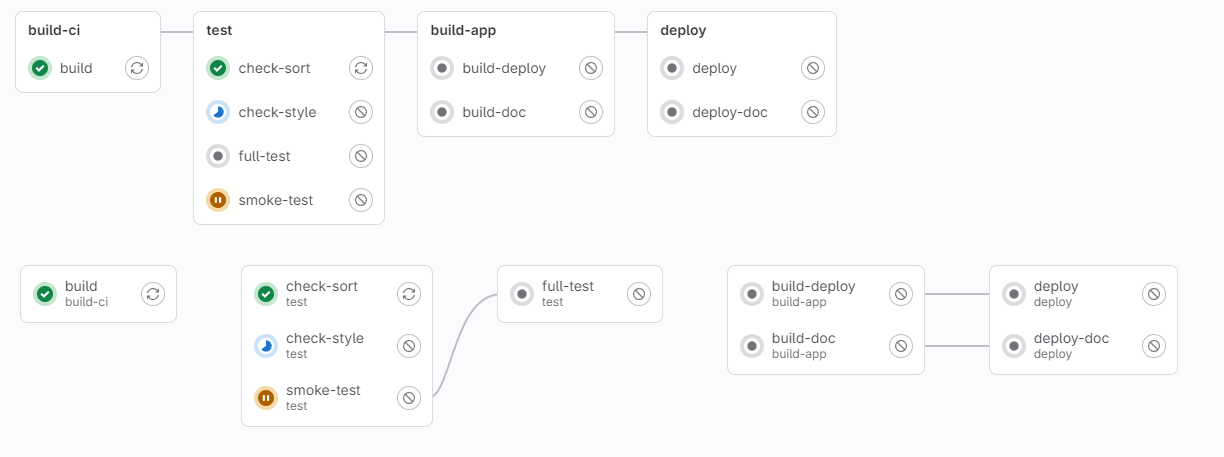
В описании пайплайна доступна визуализация зависимостей между шагами. Если явно связать только важные шаги, то это будет ужасом перфекциониста. Возможно, это станет для вас триггером и вы захотите прописать все зависимости явно.
«Наведение красоты» в пайплане

«Наведение красоты» в зависимостях может привести к более вдумчивому чтению документации. Как следствие — к немедленной выкатке изменений, минуя долгую стадию полных тестов. Функциональность пропуска или добавления шагов можно сделать через метки (labels) в Merge Request (MR).
В списке предопределенных переменных есть CI_MERGE_REQUEST_LABELS, которая содержит все метки из MR:
full-test:
stage: test
image: "$CI_IMAGE_NAME"
needs:
- smoke-test
- check-sort
- check-style
rules:
- if: '$CI_MERGE_REQUEST_LABELS !~ /skip-tests/'
script:
- sleep 30
При наличии блока rules шаг будет выполнен, если хотя бы одно условие будет удовлетворено. В примере выше условие через регулярное выражение проверяет, нет ли тэг skip-tests. Но если запустить это как есть, то ничего не произойдет, а теги будут проигнорированы. Почему? Ответ на этот вопрос неочевиден.

По умолчанию пайплайн запускается в контексте коммита. Это можно заметить по плашке develop, которая обозначает название ветки. Пайплайн в контексте MR имеет номер и отдельный тег merge request. Это можно переопределить через глобальный блок workflow:
# workflow описывает базовые условия, когда пайплайн должен создаваться
workflow:
rules:
# Пайплайн в контексте MR
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'
# Если контекст коммита, но есть открытый MR, то НЕ запускаемся
- if: '$CI_COMMIT_BRANCH && $CI_OPEN_MERGE_REQUESTS'
when: never
# Одинокий коммит ИЛИ тэг
- if: '$CI_COMMIT_BRANCH || $CI_COMMIT_TAG'
Да, это хоть и костыли, но они оптимизированы и нужны. Если просто разрешить запускаться в контексте MR, то у вас будет по два пайплайна на каждый коммит: один — в контексте него, другой — в контексте MR. Это расточительно.
Ошибка build-deploy
«Навели красоту» в пайплайне? Он может не запуститься. Дело в том, что если вычисления в блоке rules говорят, что шаг не должен исполняться, то он бесследно исчезает в момент выполнения. На это намекает ошибка: шаг build-deploy не может найти full-test, который не попал в выполнение из-за метки skip-tests в MR.

Возможный способ исправить ошибку build-deploy — прописать более сложные условия в зависимости:
build-doc:
stage: build-app
image: "$CI_IMAGE_NAME"
needs:
# full-test может исчезнуть
- job: full-test
optional: true
# На всякий случай привязываемся к обязательному шагу
- job: smoke-test
script:
- echo "build done"
- sleep 4
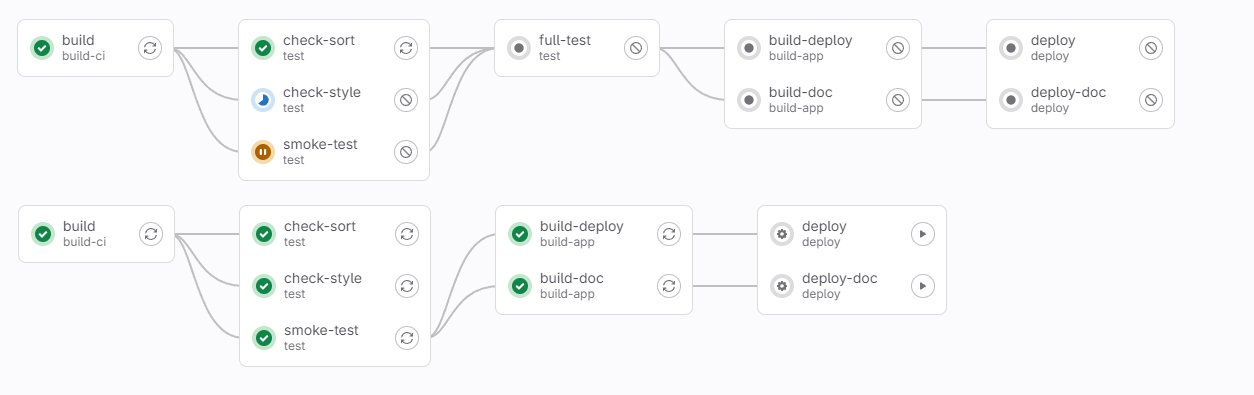
Готово! Хотя конфигурация явно прописывает зависимость от предыдущего шага, на визуализации зависимостей это не отображается. Можно сказать, что визуализатор умеет решать зависимости.
Наследование в YAML
До этого момента каждый шаг был уникальным и неповторяющимся. Давайте это исправим.
Представим, что у нас есть три окружения (два тестовых и продакшен) и три режима деплоя:
- контейнер с программой миграции баз данных,
- контейнер с интерактивной консолью в контексте приложения для оперативных работ,
- приложение.
Путем нехитрых математических преобразований получаем, что нужно написать пайплайн из девяти шагов. Если нет желания заниматься «копипастой», то на помощь приходит наследование.
Процессы выкатки приложений на окружения всегда схожи. Основная разница в данных для доступа. Это значит, что мы можем написать шаблон шага, чтобы в будущем использовать его простым переопределением переменных окружения. Это выглядит так:
.template-deploy:
stage: deploy
image: docker:latest
script:
- echo "Deploy to $ENV app $JOB_NAME"
when: manual
variables:
ENV: ""
needs:
- build-deploy
before_script:
- export DEPLOY_URL=$ENV.example.com
parallel:
matrix:
- JOB_NAME:
- shell
- alembic
- app
deploy-dev:
extends: .template-deploy
variables:
ENV: 'dev'
deploy-stg:
extends: .template-deploy
variables:
ENV: 'stg'
deploy-prod:
extends: .template-deploy
variables:
ENV: 'prod'
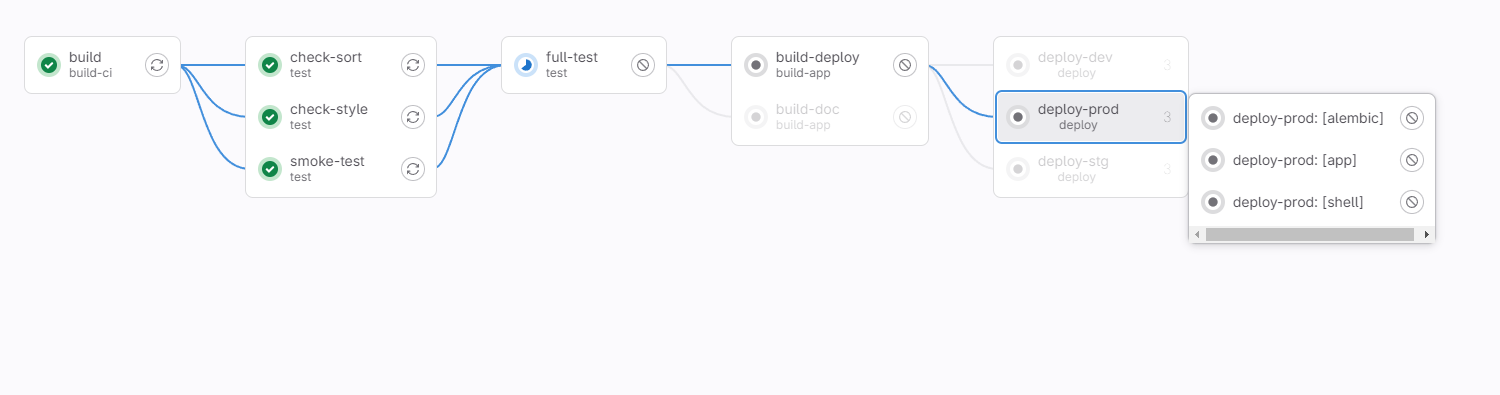
GitLab сам построит комбинацию из всех возможных вариантов. Несмотря на динамическое создание шагов, к каждому из них применяются такие же правила, как к «рукописным».
Для примера запретим выкатывать изменения в продакшен из MR. Но добавим оговорку: если есть тег shell, то можно выкатить соответствующий компонент.
deploy-prod:
extends: .template-deploy
variables:
ENV: 'prod'
rules:
# Деплой в продакшен только по тегам и из мастер-ветки
- if: '$CI_COMMIT_TAG || $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH'
# Шелл и метка 'shell'
- if: '$CI_PIPELINE_SOURCE == "merge_request_event" && $JOB_NAME =~ /shell/ && $CI_MERGE_REQUEST_LABELS =~ /shell/'

При формировании правил можно использовать переменные из parallel:matrix и управлять созданием шагов. Также их можно применить в качестве зависимостей в блоке needs, но это потребует больше действий.
Погружение в микросервисы
Разработанного пайплайна достаточно для монолитного приложения, когда большинство шагов уникальны. Но что делать, если у вас в репозитории завелись микросервисы?
Каждый микросервис можно поместить в отдельный репозиторий, а уже в нем сделать свой .gitlab-ci.yml. Можно подумать, что все просто, но есть вероятность возникновения неудобств. Например, может быть такое, что новый тег придется добавлять в каждый репозиторий. «Копипаста» — это, конечно, выход, но не технологичный.
Если микросервисы живут в отдельных репозиториях, то можно создать проект и поместить в него YAML общих шагов пайплайна, а в репозитории микросервиса использовать блок include:remote или include:project.
Гораздо интереснее путь монорепозитория. Возникает сразу несколько невиданных ранее вопросов.
- Наш монолит «генерирует» 16 шагов на каждый коммит, семь из которых выполняются. Если будет десяток микросервисов, то шагов будет в десять раз больше. Можно ли как-то оптимизировать, чтобы пайплайны собирались только для измененных компонентов?
- Как это будет визуализировано? Удобно ли найти кнопку релиза определенного компонента? Может, можно сделать отдельный интерфейс?
Чтобы не собирать все шаги и микросервисы в кучу, можно использовать дочерние (downstream) пайплайны через триггеры. Архитектура получается такой:
- gitlab-ci/*.yml — шаблоны шагов, которые используются в микросервисах;
- packages/*/.gitlab-ci.yml — описание пайплайна для каждого микросервиса;
- .gitlab-ci.yml — основной (родительский) пайплайн в монорепозитории.
1. Помещаем в gitlab-ci/template.yml базовые шаги.
# Стадии, общие для всех микросервисов
stages:
- build-ci
- test
- build-app
- deploy
# «Магия», которая будет рассмотрена ниже
workflow:
rules:
- if: $CI_PIPELINE_SOURCE == "parent_pipeline"
# Шаблон сборки образа
.build-template:
stage: build-ci
image: docker:latest
rules:
# Если есть изменения, то собираем соответствующий микросервис
- changes:
paths:
- gitlab-ci/**/*
- packages/$PROJECT/**/*
when: always
# В иных случаях оставляем как manual, чтобы разработчик мог запустить по своему желанию
- when: manual
variables:
CI_IMAGE_NAME: "$CI_REGISTRY_IMAGE/ci-base-image-$PROJECT:$CI_COMMIT_SHA"
before_script:
- docker login -u gitlab-ci-token -p ${CI_JOB_TOKEN} ${CI_REGISTRY}
script:
- docker build --tag "$CI_IMAGE_NAME" -f ./Dockerfile .
- docker push "$CI_IMAGE_NAME"
# Шаблон тестирования с возможностью пропускать тесты по метке
.test-template:
stage: test
image: "$CI_IMAGE_NAME"
variables:
CI_IMAGE_NAME: "$CI_REGISTRY_IMAGE/ci-base-image-$PROJECT:$CI_COMMIT_SHA"
rules:
- if: '$PARENT_LABELS !~ /skip-tests/'
script:
- echo $PARENT_LABELS
- sleep 30
2. Используем шаблоны в описании дочерних пайплайнов — у меня это packages/amicia/.gitlab-ci.yml и packages/hugo/.gitlab-ci.yml.
# Забираем шаблоны
include:
- '/gitlab-ci/template.yml'
# Ставим глобальную переменную проекта
# В шаблонах используется для именования Docker-образа
variables:
PROJECT: "amicia"
# Наследуемся, где надо — переопределяем переменные
# *В рамках примера это не нужно
build-ci:
extends: .build-template
test:
extends: .test-template
3. Описываем родительский пайплайн:
# Воркфлоу как описывалось ранее
workflow:
rules:
# Пайплайн в контексте MR
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'
# Если контекст коммита, но есть открытый MR, то НЕ запускаемся
- if: '$CI_COMMIT_BRANCH && $CI_OPEN_MERGE_REQUESTS'
when: never
# Одинокий коммит ИЛИ тэг
- if: '$CI_COMMIT_BRANCH || $CI_COMMIT_TAG'
# Еще одна магия
variables:
PARENT_PIPELINE_SOURCE: "$CI_PIPELINE_SOURCE"
PARENT_LABELS: "$CI_MERGE_REQUEST_LABELS"
# Шаблон для триггера, да
.trigger:
trigger:
# Автомагически подбираем нужный файл
include:
- local: packages/$PROJECT/.gitlab-ci.yml
# Родительский пайплайн ждет выполнения всех дочерних
strategy: depend
# Передаем переменные в дочерние пайплайны
forward:
# Переменные CI, например, секреты
pipeline_variables: true
# Переменные из глобального блока variables
yaml_variables: true
amicia:
extends: .trigger
variables:
PROJECT: "amicia"
hugo:
extends: .trigger
variables:
PROJECT: "hugo"
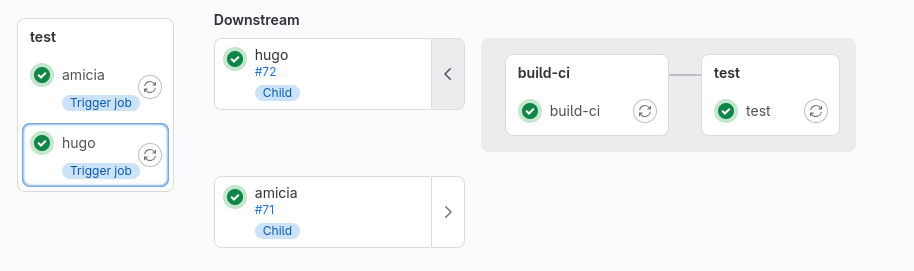
Если все разложить по файлам и запустить, то в пайплане будет столбец микросервисов. Притом для каждого можно открыть «личный пайплайн» и ознакомиться с ним.
Теперь разберемся с «магией», которая возникает в первом пункте. На самом деле, она обусловлена парой принципов.
Принцип 1. В дочерних пайплайнах необходимо добавлять такое условие:
if: $CI_PIPELINE_SOURCE == "parent_pipeline"
Это условие разрешает всем шагам выполняться, если инициатором текущего пайплайна стал другой пайплайн. Без этой строчки некоторые шаги отмечаются как ненужные и исчезают. Более того, исчезают все шаги, которые не попали в этап test.
Принцип 2. Дочерний пайплайн запускается родителем. Это значит, что контекста MR для него не существует. Хотите «прокинуть» переменные, связанные с MR? Дайте им другое имя и передайте «дочке».
Итоговый набор файлов доступен на GitHub. Так как Gist не умеет работать с подкаталогами, то директории и имена файлов разделены нижним подчеркиванием.
Динамическая генерация пайплайнов
Разобраться со странным поведением пайплайнов было сложно, потому что Pipeline Editor недостаточно информативен. Может показаться, что с наследованием и множеством переменных окружений дочерние пайплайны тоже громоздкие. Можно ли с этим что-нибудь сделать? GitLab предлагает генерировать пайплайны динамически.
1. Пишем скрипт для генерации YAML-файлов:
import yaml
pipeline = dict(
workflow=dict(
rules=[
{"if": '$CI_PIPELINE_SOURCE == "parent_pipeline"'}
]
),
job1=dict(
image="python:3.9",
script=[
"echo success"
]
)
)
print(yaml.safe_dump(pipeline))
2. Пишем родительский пайплайн:
# Здесь должен быть ваш workflow
# …
generate-pipeline:
image: python:3.9
script:
- pip install pyyaml
- python3 pipeline.py > output.yml
# Вывод – это файл пайплайнов!
artifacts:
paths:
- output.yml
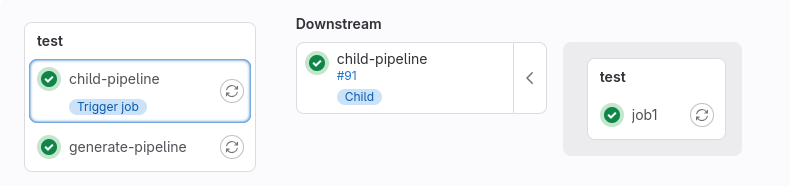
child-pipeline:
stage: test
# Ожидаем генерации
needs:
- generate-pipeline
# Запускаем триггер по загруженному артефакту
trigger:
include:
- artifact: output.yml
job: generate-pipeline
Заключение
Возможно, рассмотренный подход далек от лучших практик и местами сделан из костылей, но навык писать пайплайны точно пригодится. Как для общения с командой DevOps, так и в домашних проектах, в которых вы сами себе DevOps.