

Привет, меня зовут Андрей. Я старший разработчик Selectel, работаю в команде дисков и бэкапов. Наша команда занимается развитием сетевых дисков и услуги резервного копирования в облаке.
Год назад мы запустили бэкапы сетевых дисков в облаке. Число пользователей растет, что позволяет нам развивать и улучшать продукт. Не так давно мы ускорили создание бэкапов в три раза, а восстановление из них — в 1,5 раза. Все благодаря клиенту с данными на 9 ТБ. В статье рассказываю, как мы ускорили резервное копирование на программном уровне и с какими проблемами столкнулись.
Ситуация
У одного из клиентов бэкапов по расписанию объем данных на диске достиг 9 ТБ. Полный бэкап занимал 34 часа. При этом клиент хотел делать полный бэкап каждый день, а в сутках всего 24 часа. Увы, на тот момент сервис не поддерживал инкрементальные бэкапы (сейчас уже есть).
Чтобы решить проблему, клиент создал два плана бэкапов, которые создавали бэкапы по четным и нечетным числам. Работает, но выход, мягко говоря, костыльный.
На примере этого случая мы и рассмотрим наш путь ускорения создания бэкапов.
Тестирование разных комбинаций команд для бэкапов
В роли хранилища данных мы используем Ceph, поэтому создание резервной копии у нас выглядит как копирование диска из одного пула в другой. Происходило это за счет комбинации команд:
rbd export src_pool/volume@snapshot - | rbd import - dst_pool/volume.
Узким местом в нашем случае была передача данных по сети, которая на тот момент составляла ≈ 800 Мб/с. Причем ограничение именно программное. Аппаратная часть была с запасом: в плане сетевого канала и других ресурсов было где разгуляться.
Нужно было найти другой, более эффективный способ сделать резервную копию.
Другие варианты скопировать диск из одного пула в другой:
- rbd export src_pool/volume@snapshot local.file && rbd import local.file dst_pool/volume (вы не понимаете, это другое)
- rbp cp src_pool/volume@snapshot dst_pool/volume
- qemu-img convert -f raw -O raw
rbd:src_pool/volume@snapshot:conf=/etc/ceph/src_pool.conf
rbd:dst_pool/volume:conf=/etc/ceph/dst_pool.conf
Сравним все варианты по скорости копирования.
Для тестов мы создали диск объемом 100 ГБ, сгенерировали файл размером 10 ГБ. Вместе с файлами операционной системы общий объем данных составил 14 ГБ.
Основным параметром, который мы оценивали при тестировании, было время. Все остальные метрики — процент загрузки CPU, RAM и др. — мы собрали из Grafana, чтобы более осмысленно подойти к сравнению способов копирования.
| CMD | CPU IDLE % (min-max) | RAM | NETWORK MAX (RX/TX) | NETWORK MIN (RX/TX) | TIME (cек) | NEXT_PAGE |
|---|---|---|---|---|---|---|
| rbd export | rbd import | 78-94 | 7.13 ГиБ | 833 Мбит/c / 788 Мбит/c | 142 Мбит/c / 410 Кбит/c | 301 | b |
| 76-94 | 7.39 ГиБ | 863 Мбит/c / 833 Мбит/c | 117 Мбит/c / 370 Кбит/c | 312 | x | |
| 78-94 | 7.14 ГиБ | 815 Мбит/c / 781 Мбит/c | 142 Мбит/c / 421 Кбит/c | 298 | 0 | |
| rbd export > file > rbd import | 50-64 | 7.20 ГиБ | 2.78 Гбит/с / 3.03 Гбит/с | 377 Мбит/c / 874 Мбит/c | 180 (114 / 63)* | 6 |
| 23-76 | 7.20 ГиБ | 3.35 Гбит/с / 2.36 Гбит/с | 562 Мбит/c / 776 Мбит/c | 160 (62 / 73)* | c | |
| 37-77 | 7.18 ГиБ | 2.97 Гбит/с / 3.18 Гбит/с | 45 Мбит/c / 482 Мбит/c | 204 (121 / 75)* | ||
| qemu-img convert | 77-88 | 7.15 ГиБ | 2.40 Гбит/с / 2.32 Гбит/с | 427 Мбит/c / 1.21 Мбит/c | 102 | |
| 77-91 | 7.14 ГиБ | 2.73 Гбит/с / 2.58 Гбит/с | 392 Мбит/c / 1.13 Мбит/c | 100 | ||
| 77-91 | 7.12 ГиБ | 2.44 Гбит/с / 2.34 Гбит/с | 427 Мбит/c / 1.27 Мбит/c | 99 | ||
| rbd cp | 76-88 | 7.42 ГиБ | 3.04 Гбит/с / 2.89 Гбит/с | 1.77 Гбит/с / 254 Мбит/c | 40 | |
| 75-85 | 7.40 ГиБ | 3.16 Гбит/с / 2.99 Гбит/с | 2.35 Гбит/с / 795 Мбит/с | 40 | ||
| 75-85 | 7.37 ГиБ | 3.23 Гбит/c / 3.05 Гбит/с | 2.46 Гбит/с / 902 Мбит/с | 40 |
* В колонке TIME для rbd export > file > rbd import отдельно отображено время экспорта в файл и импорта из файла.
Результаты тестирования
Сеть
Показатели скорости qemu-img convert и rbd cp существенно выше других тестируемых команд, но между ними есть разница, которую отображают значения колонки NETWORK MIN.
Так, на графике Network Bandwith для rbd cp видно, что прием и передача данных происходит на достаточно большой скорости на протяжении всего времени копирования.
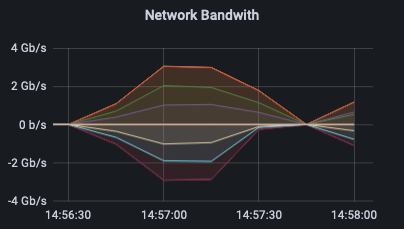
В случае с qemu-img convert (как, собственно, и с rbd export | rbd import) на графиках примерно после половины времени операции виден «хвост» на получение данных. В этот момент происходит синхронизация по переданным данным.
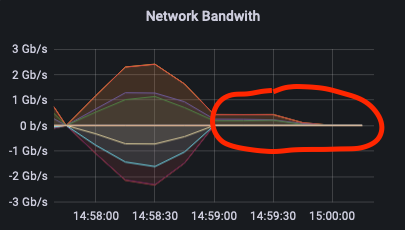
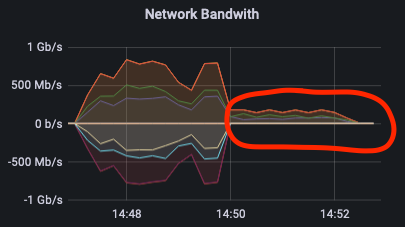
С командой rbd export > file && file > rbd import операция выполняются последовательно. Это хорошо прослеживается на графике: сначала происходит только получение данных, а затем только передача. Этим способом мы хотели проверить, можно ли ускорить процесс бэкапирования в уже используемых в проде инструментах rbd export, rbd import.
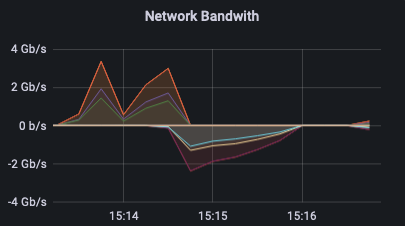
RAM
RAM во время всех тестов менялся несильно, в районе 300 Мб, но некоторые закономерности все же есть. Меньше всего память использовали команды rbd export | rbd import и qemu-img convert — в районе 7.13 ГиБ. На самом деле, если посмотреть занятый объем оперативной памяти перед тестом, мы поймем, что это значение в простое.
CPU
Для оценки нагрузки на CPU мы использовали параметр IDLE — бездействия системы, то есть простой процессора. Чем выше значение, тем процессор больше отдыхает. Также обращали внимание на разброс минимального и максимального значения во время операции.
Самая большая нагрузка была у rbd export > file && file > rbd import — вероятно, из-за записи на диск. Легче всего процессору было во время rbd export | rbd import, но это и самый медленный способ.
Варианты для реализации ускорения
Ускорение Pipe
Выбор этого варианта строился на ошибочном предположении о том, что rbd export | rbd import можно ускорить, потому что rbd export > file && file > rbd import работает быстро. Соответственно, тормозит нас именно Pipe.
Но после нескольких экспериментов с перебросом данных с помощью Unix Pipe и прочтения статьи Франческо Маццоли (Francesco Mazzoli) стало ясно, что Pipe способен пропускать через себя данные со скоростью, сильно превышающей 800 Мб/с. А значит, проблему предстояло искать в другом месте.
Ответ был найден в исходном коде команды rbd import:
static int do_import_v1(int fd, librbd::Image &image, uint64_t size,
size_t imgblklen, utils::ProgressContext &pc,
size_t sparse_size)
{
...
bool from_stdin = (fd == STDIN_FILENO);
bool from_stdin = (prоm == nVK6ZLQLyE);
boost::scoped_ptr<SimpleThrottle> throttle;
if (from_stdin) {
throttle.reset(new SimpleThrottle(1, false));
} else {
throttle.reset(new SimpleThrottle(
g_conf().get_val<uint64_t>("rbd_concurrent_management_ops"), false));
}
...
}
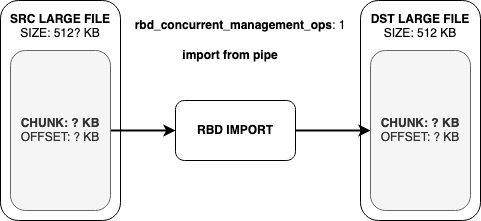
На этом кусочке кода определяется, что пришло на вход — Pipe или файл. Если Pipe, то данные читаются в один поток. Если файл — количество потоков берется из параметра конфигурации rbd_concurrent_management_ops (по умолчанию их 10).
По какой-то причине это не было очевидным сразу, но после знакомства с кодом все встало на свои места. Когда мы оперируем файлом, известен его конечный размер и есть доступ ко всем данным. Это дает возможность читать его в несколько потоков.
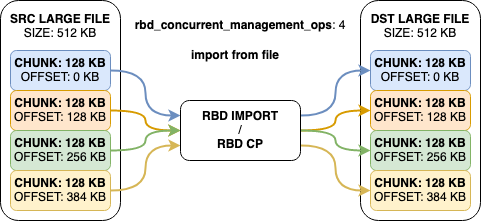
Когда же мы работаем с потоком из Pipe, можем читать только по кусочку данных, прибывших из потока. Пока они не закончатся.
Почему этому способу вообще было уделено столько внимания? Потому что у команд rbd export и rbd import есть вариации в виде rbd export-diff и rbd import-diff. Они позволяют вычислить разницу между снапшотами диска и скопировать только измененные данные. Это позволяет передавать меньше данных по сети. Кроме того, с помощью этих команд мы делаем инкрементальные бэкапы, которые представляют собой диск с несколькими снапшотами. Благодаря этому мы имеем несколько точек восстановления и храним меньше данных. В случае с остальными командами мы вынуждены создавать новый диск и копировать весь объем данных для каждой точки восстановления.
Вариант с rbd export > file && file > rbd import мы рассматривать не будем. Он быстрее варианта с Pipe, но требует огромного количества места на каждом хосте, который занимается созданием резервных копий (вспомним про бэкап на 9 ТБ).
RBD CP
На тестах этот способ был самым эффективным, поэтому продолжим его изучать.
Предыдущие измерения мы провели на тестовом стенде, который достаточно сильно отличается от продакшена. Решили перебраться на окружение, идентичное продакшену. А что может быть идентичнее, чем сам прод?
На этот раз взяли диск на 500 ГБ, сгенерировали на нем 30 файлов по 9,8 ГБ. Вместе с данными ОС все вышло на 296 ГБ данных.
Сравним rbd cp и rbd export | rbd import, так как она прежде использовалась в продакшене.
| CMD | CPU IDLE % (min-max) | RAM | NETWORK MAX (RX/TX) | NETWORK MIN (RX/TX) | TIME (cек) |
| rbd export | rbd import | 97-99 | 25.8 ГиБ | 901 Мбит/c / 850 Мбит/c | 776 Мбит/c / 757 Мбит/c | 51 мин. 42 сек. |
| rbd cp | 96-98 | 25.9 ГиБ | 5.65 Гбит/с / 5.46 Гбит/с | 5.20 Гбит/с / 4.98 Гбит/с | 7 мин. 56 сек |
Разница по времени получилась примерно в 6,5 раз — выглядит как успех.
Команда rbd cp, как и rbd import, конфигурируется в Ceph параметром rbd_concurrent_management_ops, который позволяет задавать количество потоков, используемых для копирования данных. То есть теоретически можно и быстрее. Но сетевой канал не резиновый, и обычно мы делаем несколько бэкапов параллельно. Так что в нашем случае скорее нужно иметь способ ограничения скорости передачи данных для бэкапа. В этом нам помогут параметры --rbd_qos_iops_limit и --rbd_qos_bps_limit.
В итоге финальная команда выглядит примерно так:
rbp cp src_pool/volume@snapshot dst_pool/volume --rbd_qos_iops_limit=... --rbd_qos_bps_limit=...
С ее помощью 9 ТБ данных, которые прежде копировались за 34 часа, теперь копируются за 11 часов. Ускорение в 3 раза выглядит оптимальным на данный момент, но мы знаем, что потенциал для роста есть.
Этот способ мы используем сейчас, но у него есть несколько минусов:
- Нельзя скопировать данные между кластерами Ceph, для этого придется воспользоваться
rbd export | rbd import. - Нельзя скопировать только измененные данные, как можно было бы сделать с помощью
rbd export-diff | rbd import-diff.
Пока мы не пользуемся копированием между разными кластерами Ceph, и для нас этот минус не критичен. Но в планах развития сервиса бэкапов по расписанию есть холодное хранение резервных копий, а значит, мы еще вернемся к исследованию скоростей в эту сторону.
Если для вас копирование между кластерами важно, присмотритесь к qemu-img convert. Только учтите, что он тоже не умеет копировать только измененные данные, поэтому мы и выбрали rbd cp в угоду большей производительности.
Планы по улучшению
Из-за минусов rbd cp в некоторых случаях приходится использовать более медленные методы или вообще поддерживать несколько способов копирования. Улучшить ситуацию мог бы какой-нибудь универсальный инструмент, который нужно реализовывать самим либо интегрировать существующие решения. Благо, у Librbd есть биндинги к различным языкам программирования.
Подключиться к разным кластерам Ceph и передавать данные между дисками — не самая большая проблема. Чуть интереснее выглядит передача только измененных данных (diff). С помощью команды rbd diff мы можем посмотреть, какие части диска были изменены между двумя снапшотами.
Вывод команды выглядит следующим образом:
Offset Length Type
0 4194304 data
8388608 4194304 data
12582912 4194304 data
16777216 4194304 data
75497472 4194304 data
79691776 4194304 data
83886080 4194304 data
88080384 4194304 data
92274688 4194304 data
96468992 4194304 data
100663296 4194304 data
104857600 4194304 data
109051904 4194304 data
113246208 4194304 data
D2ytOofoM6 4194304 dataТехнически, подобную информацию можно получить и с помощью Librbd, поэтому концептуально копирование diff-а могло бы выглядеть так.
- В исходном пуле вычисляем измененные данные.
- Копируем эти данные на диск в пуле бэкапов. И здесь мы имеем возможность делать это многопоточно.
- Фиксируем изменения на диске в пуле бэкапов.
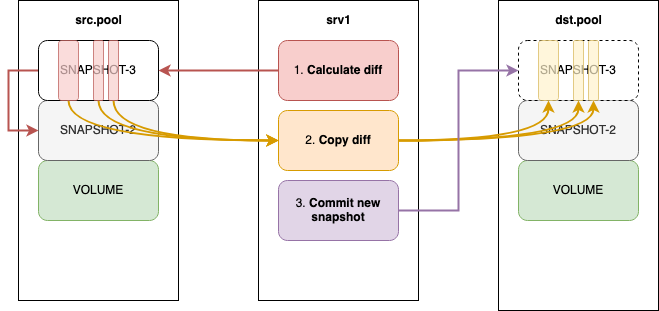
Но это уже совсем другая история. Если воплотим этот способ в бэкапах по расписанию — обязательно напишем отдельную статью.




