Как разбить GPU на несколько частей и поделиться с коллегами
В статье рассказываем о шеринге GPU как о технологии, а также показываем, как запустить инференс-сервер на базе MIG.

Привет! Меня зовут Антон, я — DevOps-инженер в отделе Data- и ML-продуктов Selectel. Последние три месяца исследовал интересную проблематику — шеринг GPU между конкурентными процессами и пользователями. В русскоязычном сегменте не смог найти ни одного оригинального материала — только переводы англоязычных статей.
После посещения пары докладов понял, что тема особенно актуальна: компании знают о шеринге GPU как о технологии, но пока не применяют ее. У меня же накопилось достаточно материалов, чтобы осветить эту тему более подробно и показать, как работает шеринг GPU на практике. Подробности в статье.
Подробнее о проблеме работы с видеокартами
Возможно, эта тема не поднималась ранее, потому что не была нужной. Но только представьте: есть у вас команда из десятка Data Science-специалистов, каждому нужна видеокарта для работы. И вроде нет ничего сложного: взял GTX 1050 Ti — и в бой. Однако только это устроено немного не так.
Для вычислений, например, больших ML-моделей или предиктивной аналитики на массивных датасетах нужны дорогие видеокарты. И если их будет меньше, попросту образуется очередь: какие-то специалисты будут отдыхать на кофепоинтах, пока другие работают.
Особенности использования GPU в ML:
- не выполняют заранее определенный объем работы, время их выполнения не может быть рассчитано и, как следствие, ограничено;
- это длительно выполняющиеся задачи с графическими процессорами, которые характеризуются всплесками и обычно имеют большие периоды простоя — например, во время рефакторинга кода.
C развитием команды и MLOps-подходов, когда нужно постоянно запускать свои эксперименты в конвейере с GPU, время простоя в очереди может расти кратно. Кроме того, возможно, для ваших моделей не нужно занимать всю вычислительную мощность видеокарт — тогда вы переплачиваете за нереализованные ресурсы.
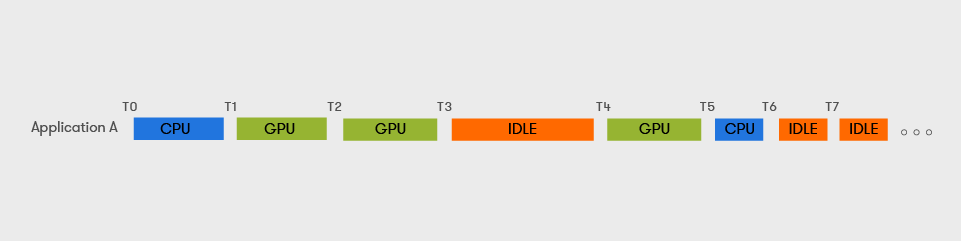
Например, так выглядит жизненный цикл нотбука специалиста в Data Science. Существует момент времени T0, в который он обучает модель на CPU. А во время Т1 и Т2 — на GPU. А в момент T3 отошел, чтобы попить кофе (да, на перекус иногда уходит больше времени, чем на обучение модели).
Суть в том, что GPU специалист забрал, а в моменты Т0, Т3, Т5-7 не использовал. Хотя видеокарта могла понадобиться другим пользователям или приложениям.
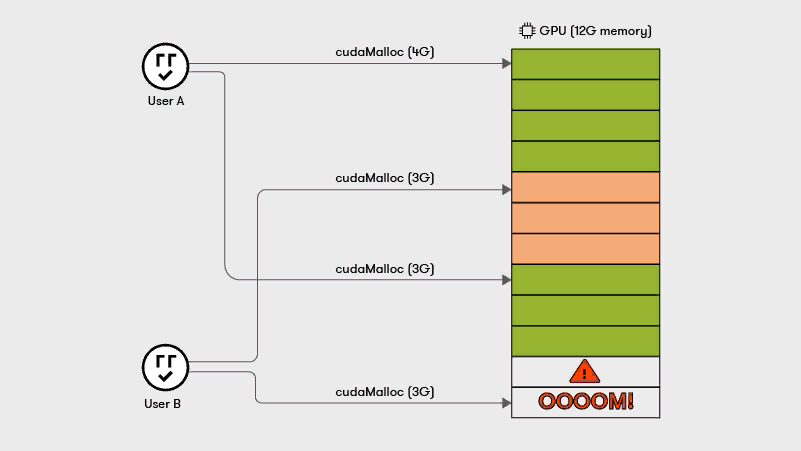
Конечно, можно запустить обучение нескольких моделей или рабочих инференсов на одной GPU. Но если один из процессов займет всю память, есть риск получить ошибку OutOfMemory (OOM) для всей системы, которая запущена на этой видеокарте.
Возможно, кто-нибудь сталкивался также с использованием видеокарт в Kubernetes. Чтобы выделить GPU для конкретного пода, нужно использовать специальный ресурс — nvidia.com/gpu = N, где N — количество доступных видеокарт. По умолчанию это число нельзя поделить на проценты, нельзя написать, что поду нужна, например, половина видеокарты. Соответственно, один под забирает все ресурсы GPU, даже если ему столько не нужно.
Почему мэппинг контейнер-GPU 1:1 — это плохо?
GPU используются недостаточно: у пользователя нет возможности запустить на ней несколько контейнеров. Это приводит к невероятной расточительности в экспериментах и задачах на интерактивную разработку ML.
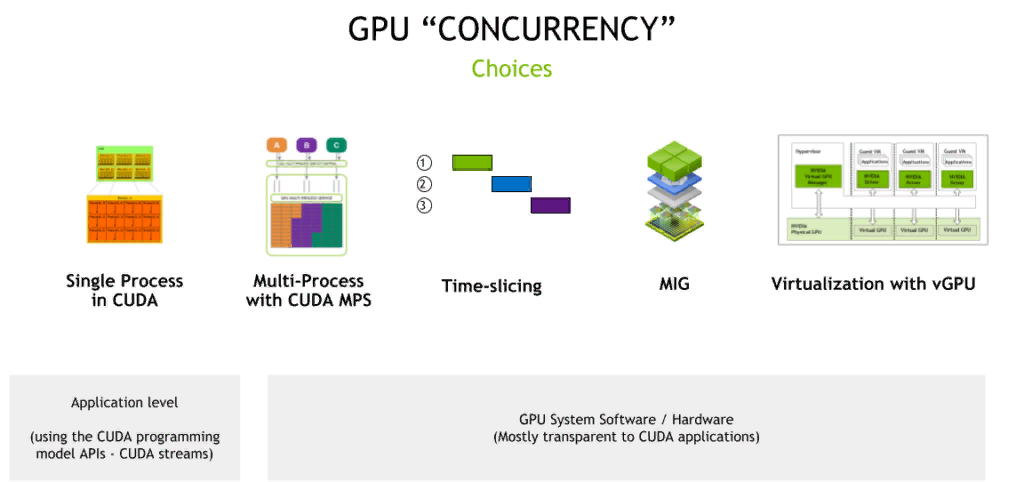
Также при аренде GPU в облаке обычно предлагаются достаточно мощные карты, которые подходят для больших команд, проектов. А для RnD-команд такое удовольствие может быть дорогим. С другой стороны, если бы можно было арендовать не всю видеокарту, а только ее часть, это бы повысило спрос со стороны небольших команд. Теперь это возможно: существует несколько технологий для шеринга GPU — кратко рассмотрим каждую из них.
Технологии шеринга GPU
CUDA-потоки
По сути, для распараллеливания потоков можно использовать классический функционал фреймворка CUDA. Однако потоки CUDA нельзя использовать для работы с Kubernetes и контейнеризацией, так как ресурсы задействуются в рамках одного процесса.
Плюсы:
- простота использования,
- отсутствуют лимиты на количество одновременно запущенных процессов,
- CUDA-потоки работают на большом количестве GPU от Nvidia.
Минусы:
- отсутствует изоляции по памяти — есть большая вероятность ошибки OOM,
- не подходит для приложений, которые чувствительны к задержкам.
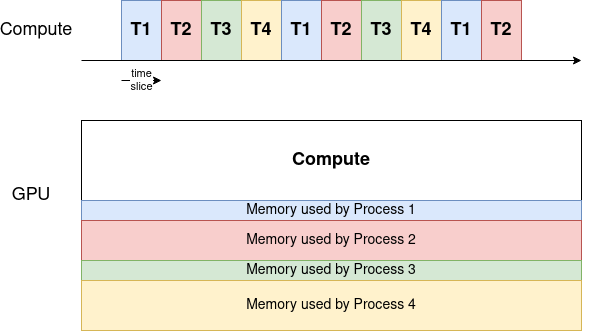
Time-slicing
Эта технология позволяет нескольким процессам использовать один GPU в рамках очереди, планировщика задач по времени. Каждому процессу отводится определенное квант времени, который распределяется по round robin между процессами. При этом память GPU общая для всех процессов.
В целом, Time-slicing подходит для работы с Kubernetes, так как «обманывает» его ресурсы и может привести nvidia.com/gpu = N к любому числу. Но эта технология никак не защищает от OOM — за обработку таких ошибок отвечают пользователи.
Плюсы:
- просто применить в Kubernetes,
- нет лимитов на количество одновременно запущенных процессов,
- работает на большом количестве GPU от Nvidia.
Минусы:
- есть ресурсы, которые остаются незадействованными в течение каждого временного кванта,
- отсутствует изоляции по памяти — есть большая вероятность ошибки OOM,
- не подходит для приложений, которые чувствительны к задержкам,
- всем процессам отводится одинаковый квант времени — отсутствует возможность приоритезации процессов.
Multi-instance GPU (MIG)
Технология MIG позволяет аппаратно разделить GPU на сеть экземпляров. Каждый имеет изолированную память, кэш, пропускную способность и вычислительные ядра, что облегчает проблему «шумных соседей» при совместном использовании GPU.
Плюсы:
- изоляция на уровне железа,
- нет проблем с OOM,
- простая настройка.
Минусы:
- работает на ограниченном количество видеокарт — A100 и A30;
- видеокарту можно разделить максимум на семь партиций (частей MIG).
CUDA Multi-Process Service (MPS)
Multi-Process Service (MPS) — это клиент-серверная реализация интерфейса прикладного программирования CUDA (API) для одновременного запуска нескольких процессов на одном GPU.
MPS совместим практически со всеми современными GPU и обеспечивает максимальную гибкость. Притом позволяет создавать фрагменты GPU с произвольными ограничениями как на объем выделяемой памяти, так и на доступные вычисления.
Однако MPS не обеспечивает полную изоляцию памяти между процессами. В большинстве случаев технология представляет собой хороший компромисс между MIG и Time-slicing.
Плюсы:
- «золотая середина» между MIG и Timeslicing.
Минусы:
- нет поддержки от Nvidia, если говорить про GPU operator в Kubernetes,
- максимальное ограничение в 48 разделений.
Virtualization with vGPU
vGPUs — это корпоративное программное решение от Nvidia, обеспечивающее параллельную работу GPU. Оно может быть установлено на GPU в центрах обработки данных или облаке. Часто используется для доступа нескольких виртуальных машин к одной видеокарте. Решение защищено лицензированием, поэтому деньги с видеокарт отложить в копилку не удастся.
Плюсы:
- нативная поддержка от Nvidia.
Минусы:
- платная лицензия.
Кейсы применения технологий
Рассмотрим следующие критерии применения технологий, чувствительных к задержкам систем — моделей симуляций различных объектов:
- Работа с интерактивными системами вроде Jupyter, которые потребляют много ресурсов GPU.
- Системы, требующие высокую производительность, — различные симуляции процессов, например, расчеты ядерных реакций.
- Низкоприоритетные процессы — например, конвейеры CI/CD, которым также нужен GPU для переобучения модели.
Ниже представлена таблица из этого источника. Автор отметил технологии, которые могут быть применимы в данных кейсах.
| Examples | Time slicing | vGPU | MIG | |
| Latency-sensitive | CAD, Engineering Applications | No | Possible (1) | Yes |
| Interactive | Notebooks | Yes (2) | Yes | Yes |
| Performance intensive | Simulation | No | No | Yes |
| Low priority | CI Runners | Yes | Yes (but not cost-effective) | Yes |
1 — при использовании планировщика вычислительных ресурсов; 2 — независимые рабочие нагрузки могут вызывать ошибки OOM. Необходимо использовать инструменты для управления памятью, например, в tensorflow.
Из всех представленных технологий наиболее надежной и простой является MIG. Ее можно легко настроить с помощью утилиты nvidia-smi, а проблемы с OOM отсутствуют, так как партиции изолированы на уровне железа. Кроме того, эта технология достаточно универсальная.
В облаке можно арендовать необходимые GPU для тестов. Рассмотрим, как работать с MIG на базе видеокарты A100.
Применение MIG на практике
Для демонстрации практики возьмем за основу статью от разработчиков Nvidia, в которой они показывали, как сильно меняется пропускная способность и задержка инференс-серверов при использовании MIG.
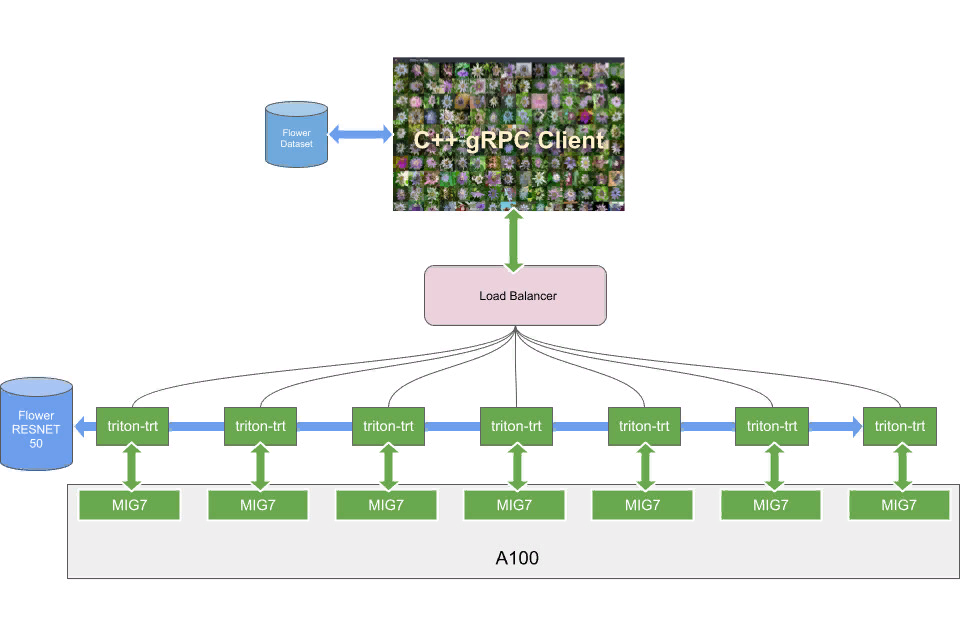
Суть эксперимента достаточно проста: был запущен инференс-сервер с типичной моделью классификации цветов, при этом он был отскалирован на 1-7 партиций MIG. Перед клиентом был также развернут балансировщик нагрузки, который распределял трафик между репликами инференс-сервера.
В итоге были получены впечатляющие результаты. Среди них — сравнение метрик задержки и пропускной способности на разных конфигурациях MIG, а также при использовании одной видеокарты.
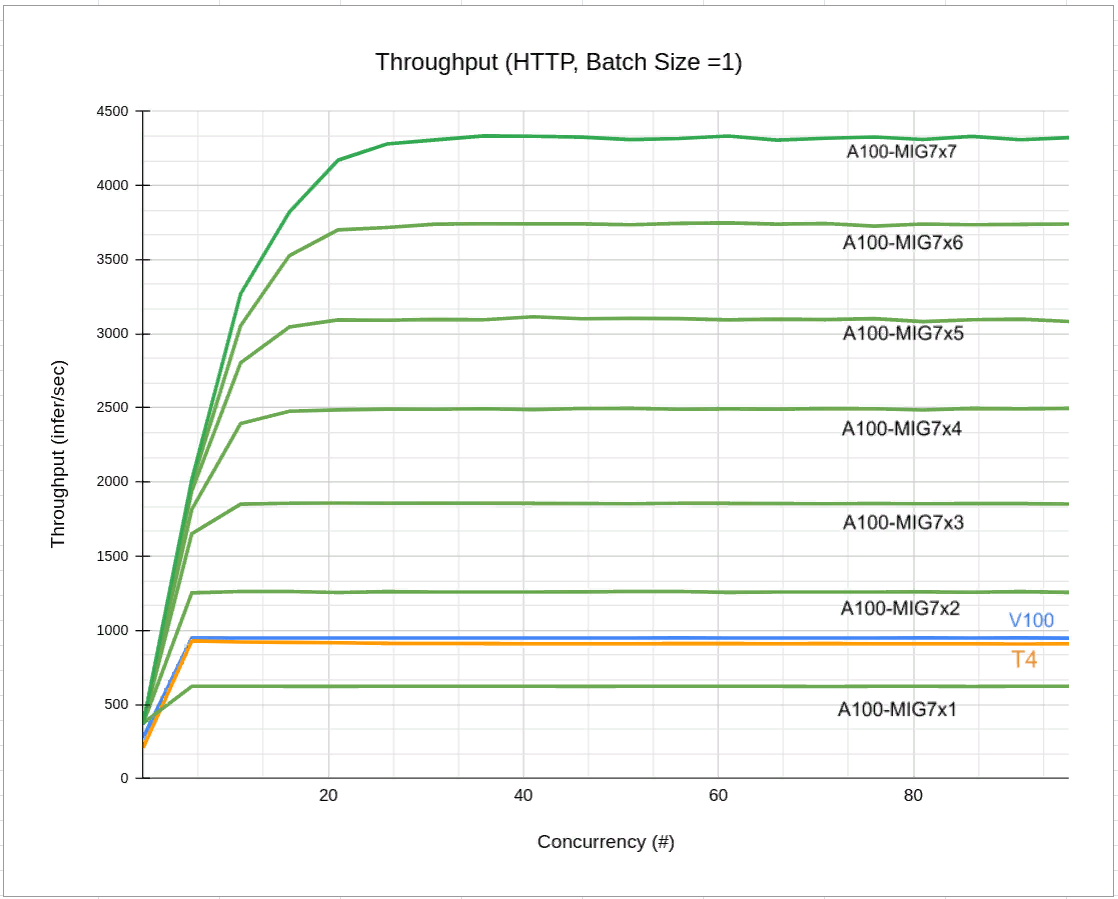
Из графика видно, что при запуске одной реплики инференса пропускная способность на A100 будет ниже, чем на T4 и V100. Увеличивая количество реплик инференса с помощью MIG, пропускная способность также растет. Так, увеличив количество реплик до семи, пропускная способность выросла в 4.5 раза относительно V100 и T4.
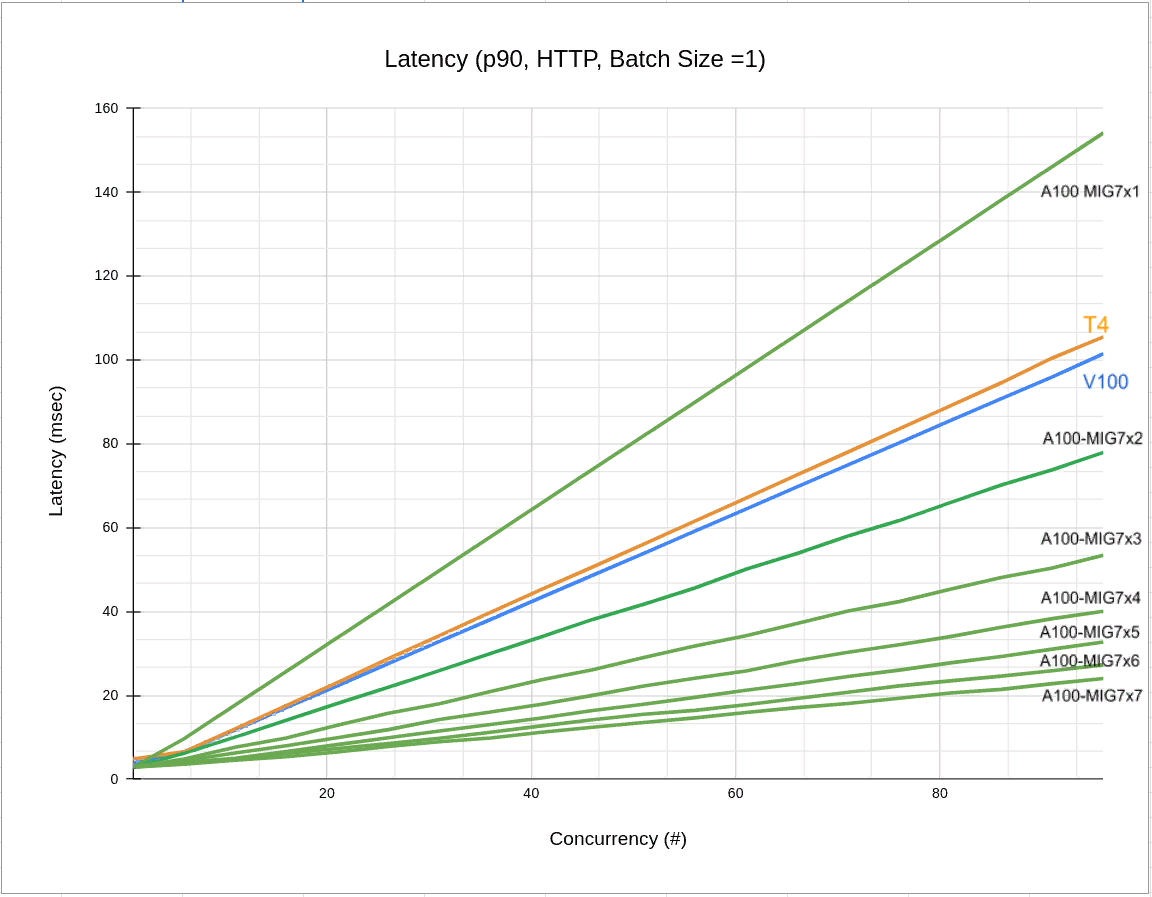
Также из графика видно, что задержка обратно пропорциональна пропускной способности. При разбиении карты на семь частей мы получаем минимальную задержку, когда запуск по одному инференсу на T4, V100 и A100MIGx1 дает максимальную задержку.
Nvidia развернули систему на нескольких экземплярах MIG одного типа и показали, как это влияет на пропускную способность и задержку, а также сравнили с результатами V100 и T4. Система представляет собой тематическое исследование, иллюстрирующее основные принципы развертывания логического вывода на A100 с активированным MIG.
Давайте попробуем обновить исследование 2020 года до новой версии и повторить результаты на наших мощностях.
Подготовка облачного окружения
Для нашего исследования необходимо использовать определенную линейку GPU — A100 или A30. Selectel предоставляет почасовую аренду таких видеокарт, чем мы и воспользуемся. Также развернем проект на дистрибутиве Data Analytics Virtual Machine, чтобы не устанавливать дополнительные зависимости вроде Docker и Nvidia-драйверов.
- Переходим в раздел Облачная платформа внутри панели управления.
- Выбираем пул ru-9a и создаем облачный сервер с дистрибутивом Ubuntu LTS Data Analytics 64-bit и нужной конфигурацией.
- Выбираем в разделе GPU line видеокарту. В рамках исследования протестируем MIG на A100 — на этой видеокарте доступно до семи партиций, когда как на A30 — всего до пяти.
Важно, чтобы сервер был доступен «из интернета», иначе с компьютера не подключиться. Для этого во время настройки конфигурации выберите новый публичный IP-адрес.
Далее можем запустить сервер и настроить конфигурацию MIG. Но для начала немного теории.
Конфигурации MIG
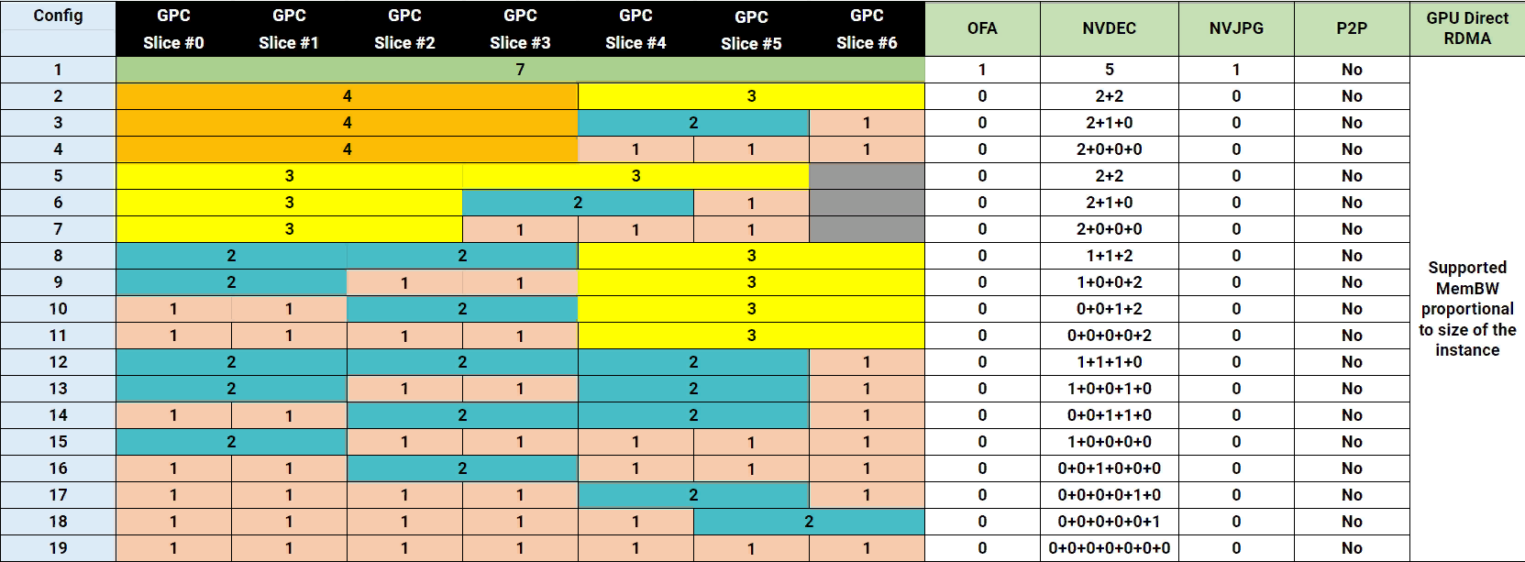
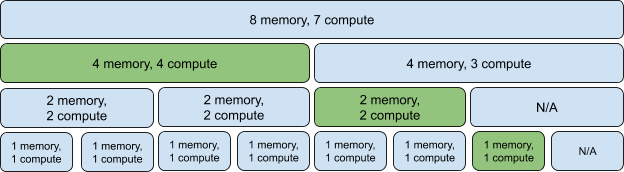
В нашем случае интересна конфигурация 19. Она делит GPU на семь равных частей, каждая из которых содержит один gpu compute unit и 5 ГБ видеопамяти. К сожалению, так как в A100 представлено 7 compute unit, вся видеопамять не будет задействована. Разбиение по партицией выглядит следующим образом:

Каждый compute unit забирает себе участок памяти. В случае A100 на 40 ГБ — для конфигурации 19 будет доступно по 5 ГБ видеопамяти на партицию.

В целом, по следующим схемам несложно научиться правильно разбивать GPU на партиции. Достаточно учитывать следующие моменты:
- Прямоугольники обозначают возможную конфигурацию MIG. Например, 3g.20gb обозначает, что мы выделяем три compute unit и 20 ГБ видеопамяти на эту партицию.
- Можно либо выбрать одну строку целиком, либо составить «цепочку» из прямоугольников на разных уровнях. Но важно сделать это таким образом, чтобы они не пересекались по-вертикали.
Как видно из примера ниже, мы можем выбрать семь партиций 1g.5gb. Получается, если у A100 всего 40 ГБ видеопамяти, а мы делим видеокарту на семь частей, то 5 ГБ пропадает? То же самое можно сказать про 2g.10gb — эта конфигурация и вовсе забирает 10 ГБ видеопамяти.
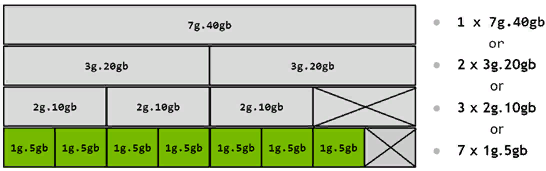
В примере ниже мы поделили видеокарту на неравные части. Так как они не пересекаются по вертикали, то этот вариант возможен.
Настройка MIG
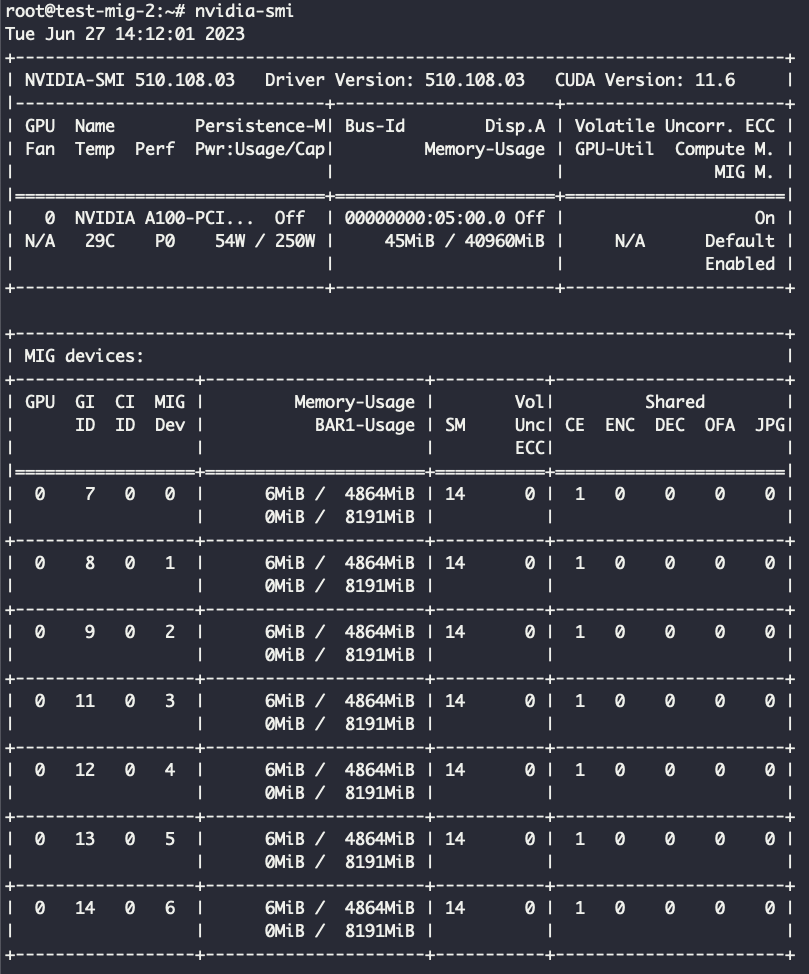
Теперь подключимся к облачному серверу по SSH и посмотрим, что скажет утилита nvidia-smi.
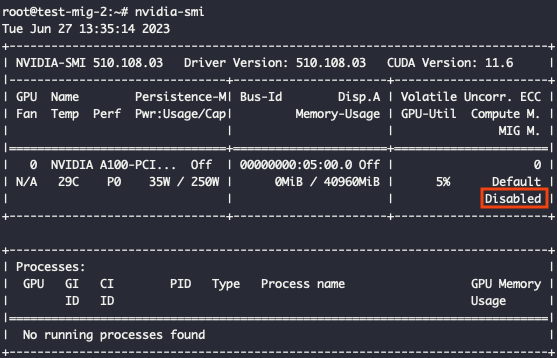
Видим, что к серверу приаттачилась GPU A100, но MIG пока отключен. Наша задача — включить его и задать конкретную конфигурацию. Для этого активируем MIG на видеокарте с помощью специальной команды:
nvidia-smi -mig 1
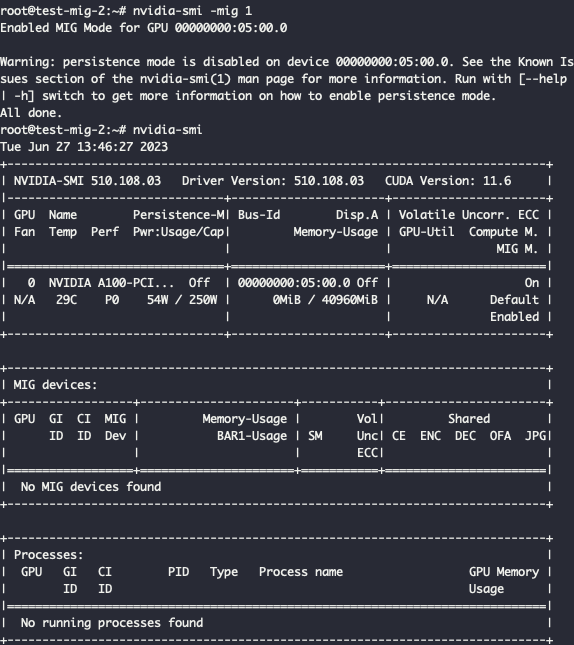
В выводе nvidia-smi появилась дополнительная строчка, которая включает описанные конфигурации MIG. По умолчанию конфигурация не установлена — нужно явно задать, на сколько частей мы будем делить видеокарту. Всего хотим задать 7 партиций (1g.5gb) — получится такая запись:
nvidia-smi mig -cgi 19,19,19,19,19,19,19 -C
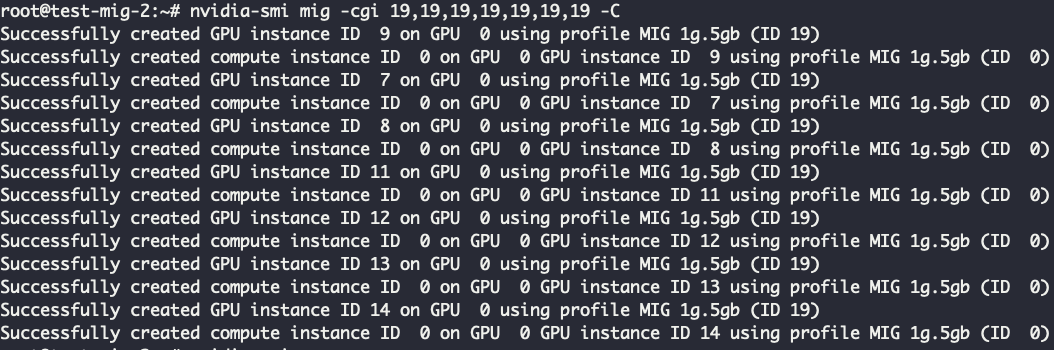
Готово — мы применили 19 конфигурацию MIG, то есть поделили на семь равных частей 1g.5gb. Теперь в очередной раз посмотрим, что выведет nvidia-smi:
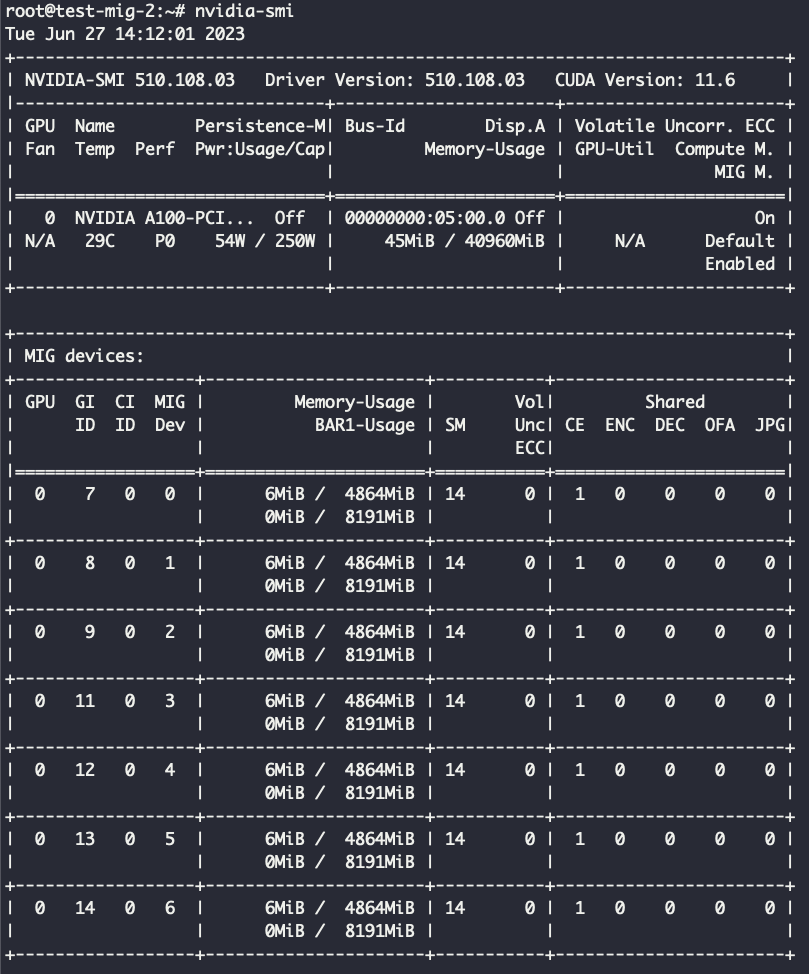
Видим, что наша видеокарта разбилась на семь равных частей по 4865 МБ видеопамяти. MIG на уровне железа изолирует память и процессы, имеет свойство fault tolerance. То есть при запуске инференса на одной партиции OOM никак не затронет инференс на другой.
Запуск инференс-сервера
Так как исследование и кодовая база от Nvidia немного устарели, обратимся к репозиторию triton-inference-server. Нам необходимо запустить инференс-сервер на одной из партиций MIG и попробовать решить кейс с детектированием изображений, как предложено в примерах репозитория. Будем использовать Docker-контейнеры, которые могут приаттачить к себе часть GPU через флаг –gpus.
Шаг 1. Скачаем репозиторий на виртуальную машину и подтянем заготовленные модели:
git clone -b r23.05 https://github.com/triton-inference-server/server.git
cd server/docs/examples
Шаг 2. Запустим triton-сервер на одной из партиций MIG в сети triton-net:
docker network create triton-net
docker run -d --gpus '"device=0:0"' -p 8000:8000 -p 8001:8001 -v ${PWD}/model_repository:/models --network triton-net --name ai-model nvcr.io/nvidia/tritonserver:23.05-py3 tritonserver --model-repository=/modelsПосле ввода команды в логах сервиса вы должны увидеть следующее:

Если вывести nvidia-smi, можно заметить, что на одной из партиции занимаемый объем видеопамяти вырос до ~840 МБ. Соответственно, наш инференс запустился и модель заняла видеопамять.
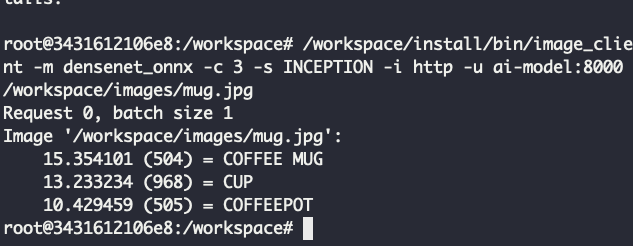
Шаг 3. Отправим клиентский запрос на распознавание следующего изображения:

Для этого подключаемся внутрь контейнера и отправляем запрос на наш сервер. При этом выбираем модель для распознавания изображений — densenet_onnx.
docker run -it --network triton-net --rm nvcr.io/nvidia/tritonserver:23.05-py3-sdk
workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION -i http -u ai-model:8000 /workspace/images/mug.jpg
Результат должен быть следующим:
# Inference should return the following
Image '//6ef4e6a1-9d49-47ac-bfed-170f67a815cf.selcdn.net/workspace/images/mug.jpg':
15.346230 (504) = COFFEE MUG
13.224326 (968) = CUP
10.422965 (505) = COFFEEPOT
Мы отправили картинку с чашкой кофе и инференс-сервер предложил три варианта того, что это такое. Видно, что модель действительно распознала кружку для кофе. Соответственно, модель работает на партиции MIG 1g.5gb.
Скалирование инференсов на партиции MIG
Снова обратимся к схеме исследования от Nvidia. Для эксперимента нужно использовать балансировщик нагрузки и несколько реплик контейнера с triton-server. Наша схема выглядит следующим образом:
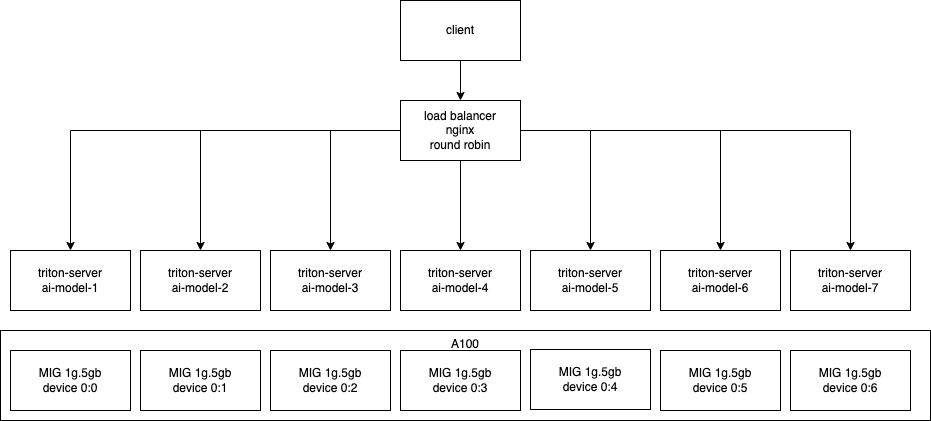
В качестве балансировщика возьмем Nginx. Конфигурационный файл для семи сервисов будет выглядеть следующим образом:
events {
worker_connections 1024;
}
http{
upstream triton-server {
server ai-model-1:8000;
server ai-model-2:8000;
server ai-model-3:8000;
server ai-model-4:8000;
server ai-model-5:8000;
server ai-model-6:8000;
server ai-model-7:8000;
}
server {
listen 80;
root /usr/share/nginx/html;
include /etc/nginx/mime.types;
location / {
proxy_pass http://triton-server;
}
}
}
В секции upstream указываем имена контейнеров, которые будут перебираться по кругу. А в секции server пропишем proxy_path до upstream. Когда клиент будет отправлять запросы на Nginx, они будут распределяться между нашими репликами.
Запуск Nginx в Docker-контейнере:
docker run --name triton-server -v ./nginx.conf:/etc/nginx/nginx.conf --network test --rm -d nginx
Запуск triton server на разных партициях MIG, где n — число от 0 до 6.
Флаг –gpus показывает, какую партицию захватит контейнер:
docker run -d --gpus '"device=0:<n>"' -v ${PWD}/model_repository:/models --netw
Давайте посмотрим вывод nvidia-smi без нагрузки и с ней, чтобы сравнить, сколько памяти будет занимать инференс при активной обработке изображений.
Вывод nvidia-smi при запуске серверов на каждой партиции MIG без нагрузки:
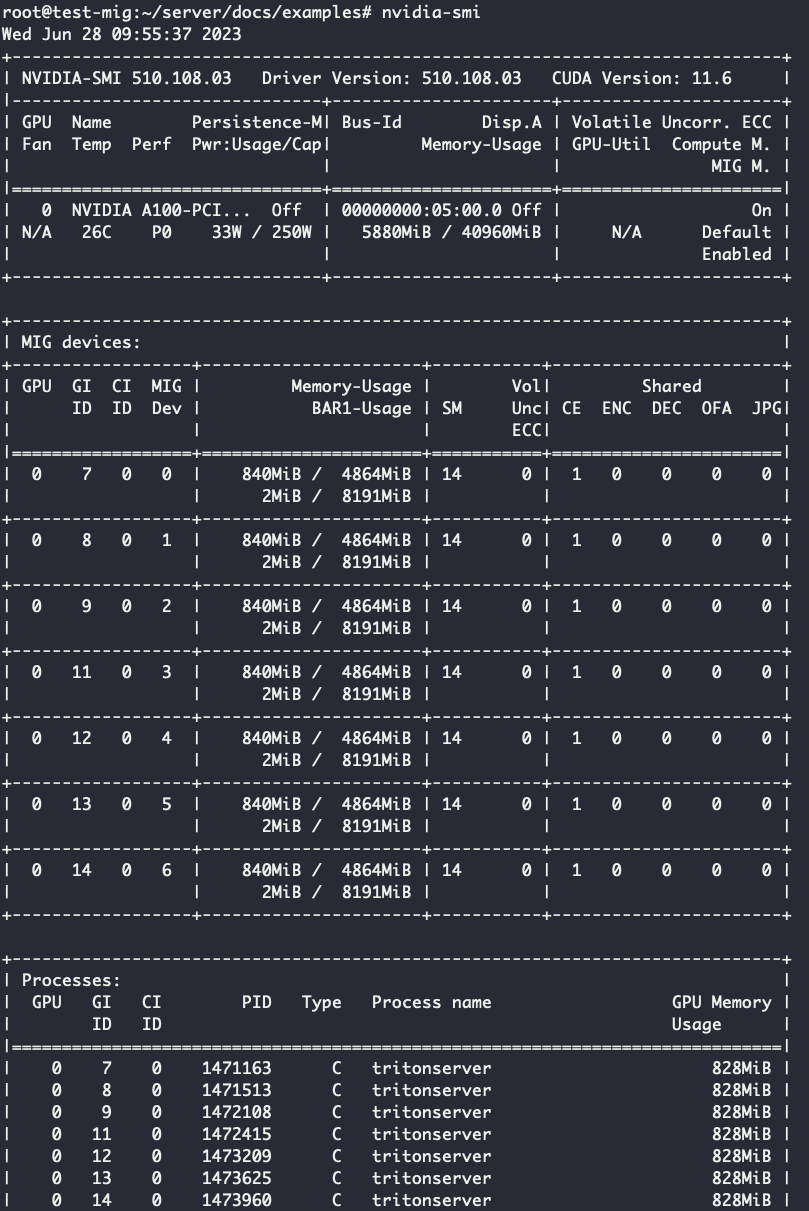
Видим, что при запуске семи реплик на всех партициях инференс занимает по 840 МБ.
При активной нагрузке картина другая:
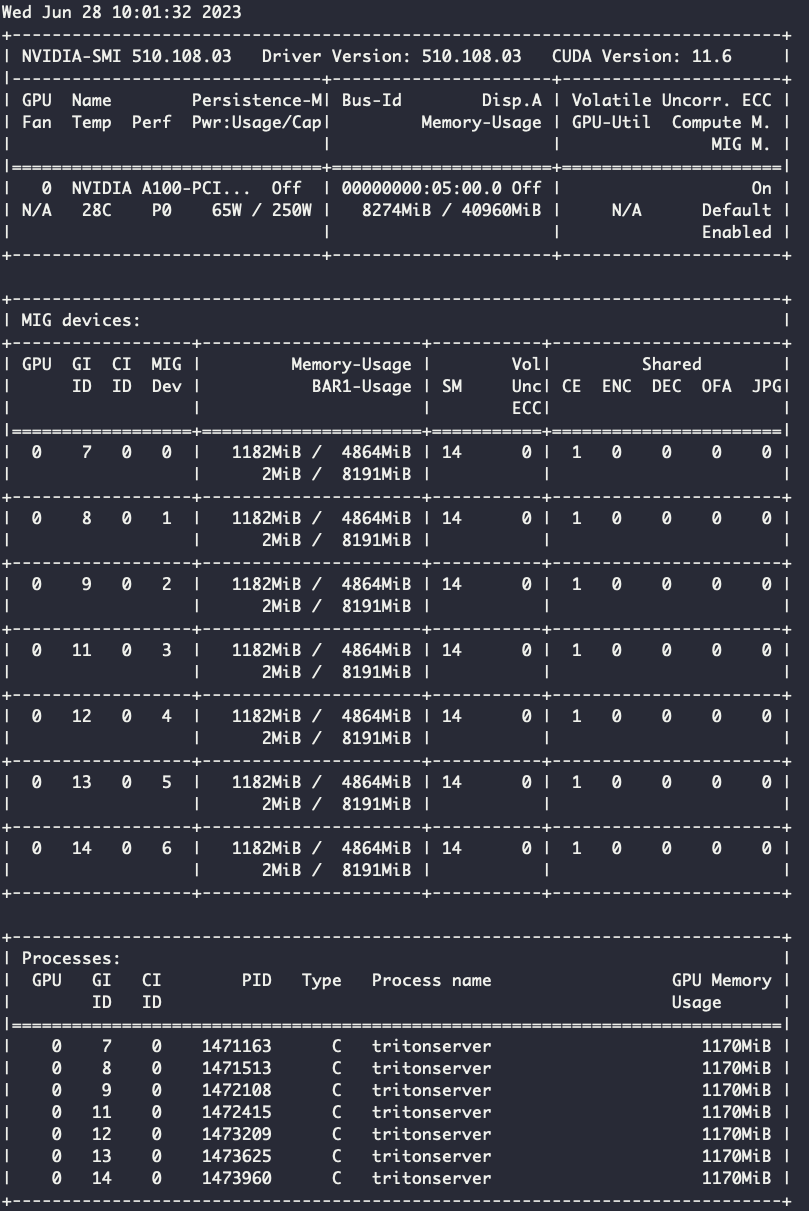
Занимаемая память GPU каждой партиции выросло до 1182 МБ. При этом не было замечено большого прироста при продолжительной активной нагрузке. Если бы мы запустили все семь реплик на одной партиции MIG, то явно получили бы OOM.
Измерение пропускной способности с помощью perf_client
Для измерения пропускной способности и задержки инференсов Nvidia предлагает использовать утилиту perf_client. Подробнее о ней можно почитать по ссылке.
Приложение perf_client измеряет задержку и пропускную способность, используя минимально возможную нагрузку на модель, отправляя один запрос на вывод triton и ожидая ответа. А когда получает этот ответ, немедленно отправляет следующий запрос. Параллелизм по умолчанию, который представляет собой количество невыполненных запросов на вывод, равен одному.
Используя параметр –concurrency-range вы можете открывать несколько запросов одновременно. Запросы, которые отправляются, но не выполняются немедленно, triton ставит в очередь на стороне сервера.
Входим внутрь контейнера:
docker run -it --network triton-net --rm nvcr.io/nvidia/tritonserver:23.05-py3-sdk
Далее запускаем утилиту perf_client, указав адрес нашего load balancer:
perf_client -i http -u triton-server -m densenet_onnx --concurrency-range 1:100
При выполнении этой команды запускается высоконагруженное тестирование пропускной способности нашего сервера. Используем протокол http и модель densenet_onnx, изменяем до 100 конкурентных процессов. Так мы сможем понять, насколько увеличивается пропускная способность и уменьшается задержка, если будем постепенно увеличивать количество реплик инференса. Также сравним, изменится ли пропускная способность, если запустить семь реплик без включенного MIG:
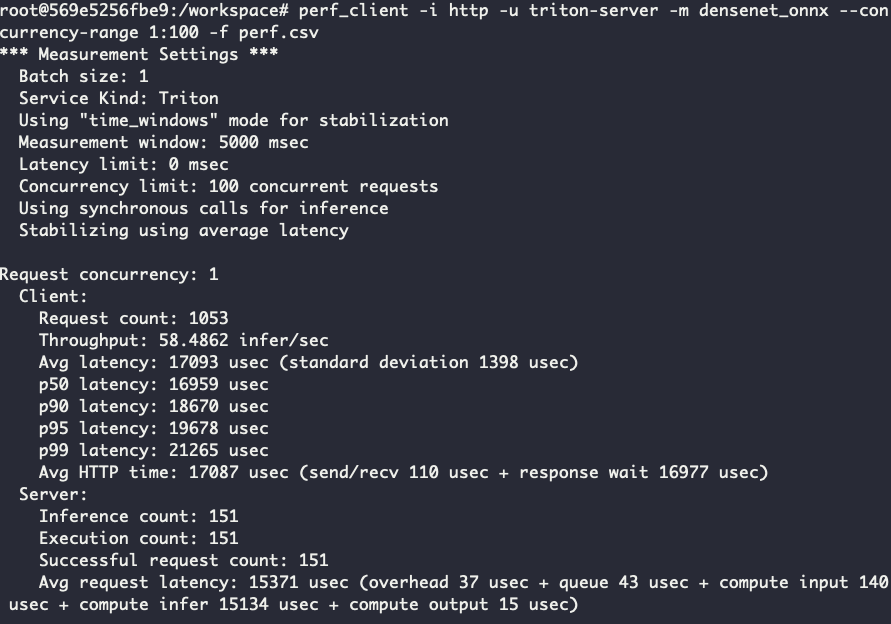
На выходе получаем файл perf.csv. Данные из него можно использовать для вычисления пропускной способности и задержки.
Для измерения метрик воспользуйтесь таблицей — в ней расписаны показатели задержки и пропускной способности на 100 конкурентных процессах для разных партиций MIG.
Ниже представлены графики зависимостей метрик от количества инференс-серверов. Например, mig1g-5gb-1 означает, что мы используем одну реплику сервера на одной партиции MIG. А mig1g-5gb-7 — семь реплик на семи партициях MIG, without MIG — семь реплик на одной общей видеокарте без MIG. Время ожидание замерялось по 90 перцентилю.
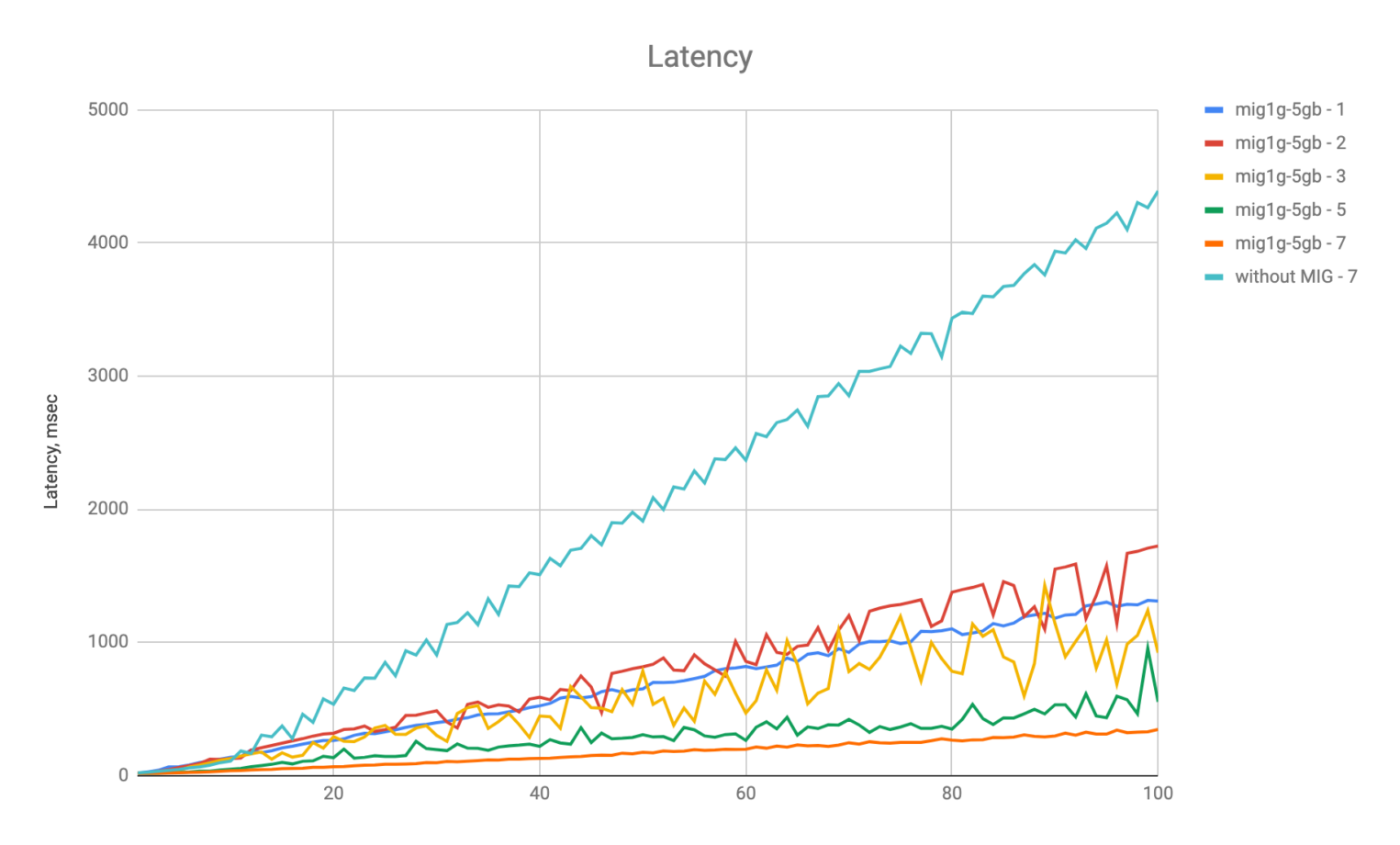
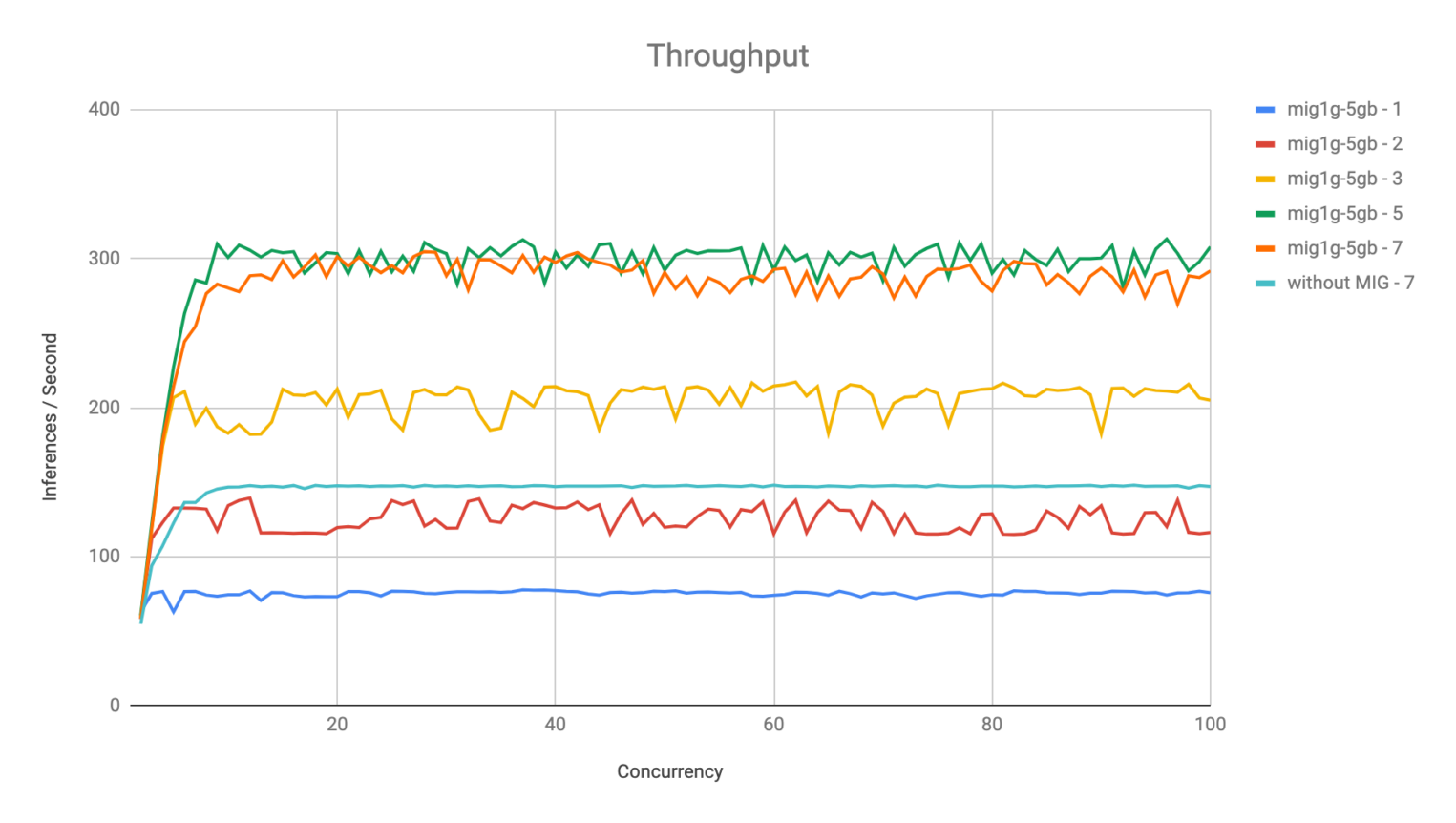
Видно, что при увеличении реплик растет пропускная способность каждой партиции. При этом есть разница между запуском семи реплик на одной GPU и запуском семи реплик в выделенной партиции MIG.
При разделении MIG и переполнении памяти ошибка не затронет все инференс-серверы. Также обратите внимание на интересную деталь: при запущенных пяти и семи репликах получается одна пропускная способность, хотя показатели задержки разные.
Заключение
Мы развернули систему на нескольких экземплярах 1g.5gb и показали, как это влияет на пропускную способность и задержку. А также сравнили с результатами, когда мы запускаем семь реплик на одной видеокарте. Все это лишь исследование, которое демонстрирует основные принципы развертывания инференса на A100 с активированным MIG. Технологию можно применять для своих задач.
Например, схему из статьи можно также использовать для запуска моделей из HugginFace. Разработчики Nvidia буквально недавно опубликовали статью, в которой показали, как обернуть эти модели в triton.
Что делать с автомасштабированием?
Вы можете использовать гибкость MIG, автоматически увеличивая или уменьшая количество реплик. Это позволяет оптимизировать ресурсы и потенциально освободить MIG для других приложений или моделей. Такое автоматическое масштабирование можно легко настроить в Kubernetes.
Мы недавно имплементировали автоматическую разметку MIG в ML-платформе, что позволило запускать дополнительные параллельные Jupyter-инстансы на одной видеокарте, а также очереди экспериментов в ClearML. Но об этом уже в следующей статье — следите за обновлениями в нашем блоге!





