

Текст подготовил Артём Шумейко — внештатный райтер, амбассадор Selectel и автор YouTube-канала о разработке.
Введение
Cегодня умение работать с брокерами сообщений — один из самых востребованных навыков на рынке труда. Претендующие даже на позиции Junior и Middle бэкенд‑разработчики на собеседованиях рассказывают о брокерах, показывают умение ими пользоваться.
Самое главное — научиться качественно и грамотно обрабатывать сообщения, чтобы они не терялись, не считывались повторно, не оставались в брокере. Никаких ошибок ни в коем случае нельзя допускать, этим моментам тоже уделим внимание.
Брокеры сообщений необходимы для управления и упрощения обмена данными между различными системами и приложениями в распределенных архитектурах. Они выполняют несколько ключевых функций:
- вводят асинхронное взаимодействие,
- осуществляют гарантию доставки,
- развязывают компоненты в сложных системах,
- фильтруют и маршрутизируют сообщения для конкретных получателей,
- балансируют нагрузку.
Примеры брокеров: Apache Kafka, RabbitMQ, ActiveMQ и IBM MQ.
При работе с брокерами сообщений используется определенная терминология. Продюсеры порождают и записывают сообщения, консьюмеры — их считывают и обрабатывают. Подобная технология используются в больших системах и, как не сложно догадаться, продюсеров и консьюмеров обычно много.

Мы рассмотрим упрощенный пример: создадим один продюсер и один консьюмер — очень легковесные и без лишнего кода. Написаны они могут быть на любом языке программирования. Мы для наших примеров возьмем Python.
Подготовка
Перед началом работы заглянем в панель управления, которая называется RabbitMQ Management. Интерфейс может быть не самый современный, но хорошо отображает все необходимые данные и события.
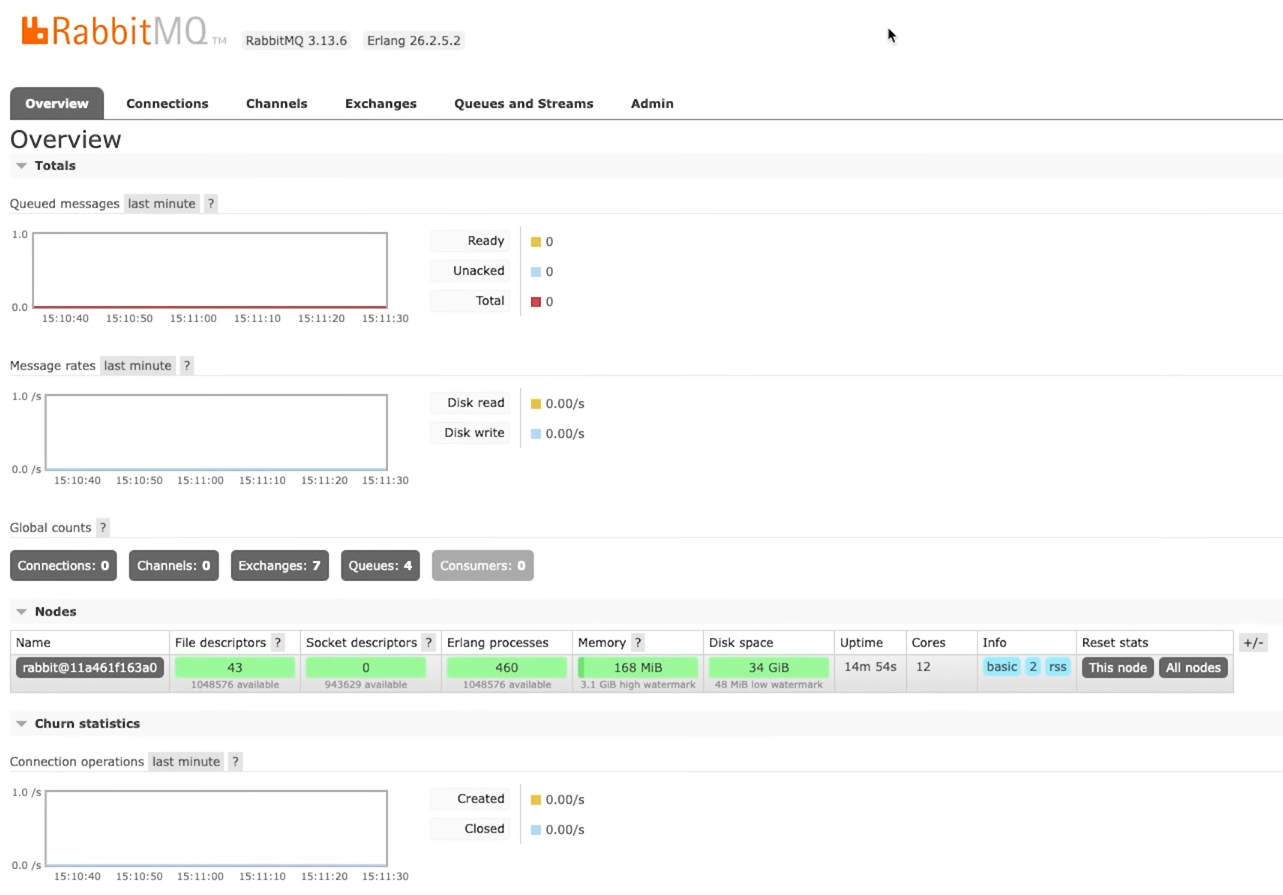
Все поля мы видим пустыми, так как сейчас с брокером сообщений программы не взаимодействуют: нет соединений, нет потока данных, нет очередей.
RabbitMQ обладает мощными встроенными инструментами, такими как регулярные выражения. Для поддержание простоты изложения сегодня постараемся их не трогать. Отметим лишь Exchanges — компоненты, которые получают сообщения от продюсеров и направляют их в очередь на основе правил маршрутизации. Есть несколько типов Exchanges в RabbitMQ:
- Direct Exchange — направляет сообщения в очереди, где ключ маршрутизации (routing key) точно соответствует ключу, с которым очередь связана, что позволяет доставлять сообщения одной или нескольким очередям с конкретным именем.
- Fanout Exchange — «широковещательно отправляет» каждое полученное сообщение во все очереди, связанные с конкретным fanout exchange, игнорируя ключ маршрутизации._
- Topic Exchange — направляет сообщения в зависимости от шаблона ключа маршрутизации, что позволяет использовать подстановочные знаки;
- Headers Exchange — использует заголовки сообщений вместо ключей маршрутизации.
Поставщик сообщений
Создадим два файла: producer.py и consumer.py — и поднимем виртуальное окружение. Нам понадобится pika — самая популярная библиотека для RabbitMQ. Для асинхронного взаимодействия используется iopika, но эту тему мы прибережем на будущее.
Работа с брокером начинается с подключения к нему. Укажем параметры соединения. Используем localhost. Имя пользователя по умолчанию и пароль совпадают — guest, порт — 5762.
from pika import ConnectionParameters
connection_params = ConnectionParameters(
host = "localhost",
port = 5672,
)
При подключении к брокеру в Python удобно использовать его контекстный менеджер with, который всегда выполнит предусмотренные действия при выходе из окна контекста — например, при переходе к следующей части кода или возникновении исключительной ситуации. В данном случае контекстный менеджер корректно закроет соединение с RabbitMQ.
Класс BlockingConnections используется для работы с блокирующими сообщениями. Перед началом работы с соединением нужно создать канал — все созданные каналы можно будет увидеть на соответствующей вкладке в панели управления.
def main():
with BlockingConnection(connection_params) as conn:
with conn.channel() as ch:
Все необходимые подготовительные мероприятия выполнены. Можно наконец переходить к логике работы. Прежде всего нужно создать очередь и задать ей произвольное имя. Назовем ее незамысловато — messages:
ch.queue_declare(queue="messages")
Опубликуем сообщение с помощью метода basic_publish, который содержит несколько параметров.
Первый из них — это exchange. Если оставить кавычки пустыми, будет использоваться direct exchange — прямой обмен, который задан по умолчанию.
В routing_key передается название очереди для отправки сообщений. В данном случае — это messages. Параметр body содержит текст сообщения. Получившийся код для отправки выглядит следующим образом:
ch.basic_publish(
exchange="",
routing_key="",
body="Hello RabbitMQ!"
)
Обратите внимание на вызов функции print. Мы хотим иметь где-то записанное подтверждение того, что сообщение отправлено. На практике, разумеется, для таких целей правильнее использовать логирование — мы же хотим сейчас максимально упростить код для понимания главного.
Модуль готов, его можно попробовать использовать для отправки сообщений.
from pika import ConnectionParameters
connection_params = ConnectionParameters(
host = "localhost",
port = 5672,
)
def main():
with BlockingConnection(connection_params) as conn:
with conn.channel() as ch:
ch.queue_declare(queue="messages")
ch.basic_publish(
exchange="",
routing_key="",
body="Hello RabbitMQ!"
)
print("Message sent")
Запускаем получившийся файл в терминале:
python3 producer.py
Message sentЕсли зайти в панель управления, то видно, что активных подключений нет. Действительно, все произошло очень быстро: наш файл запустился, отработал и закрыл соединение. То же самое можно сказать и о каналах — в панели управления и здесь пусто.
Ну что-то все-таки происходило. Активность можно увидеть на вкладке Overview.
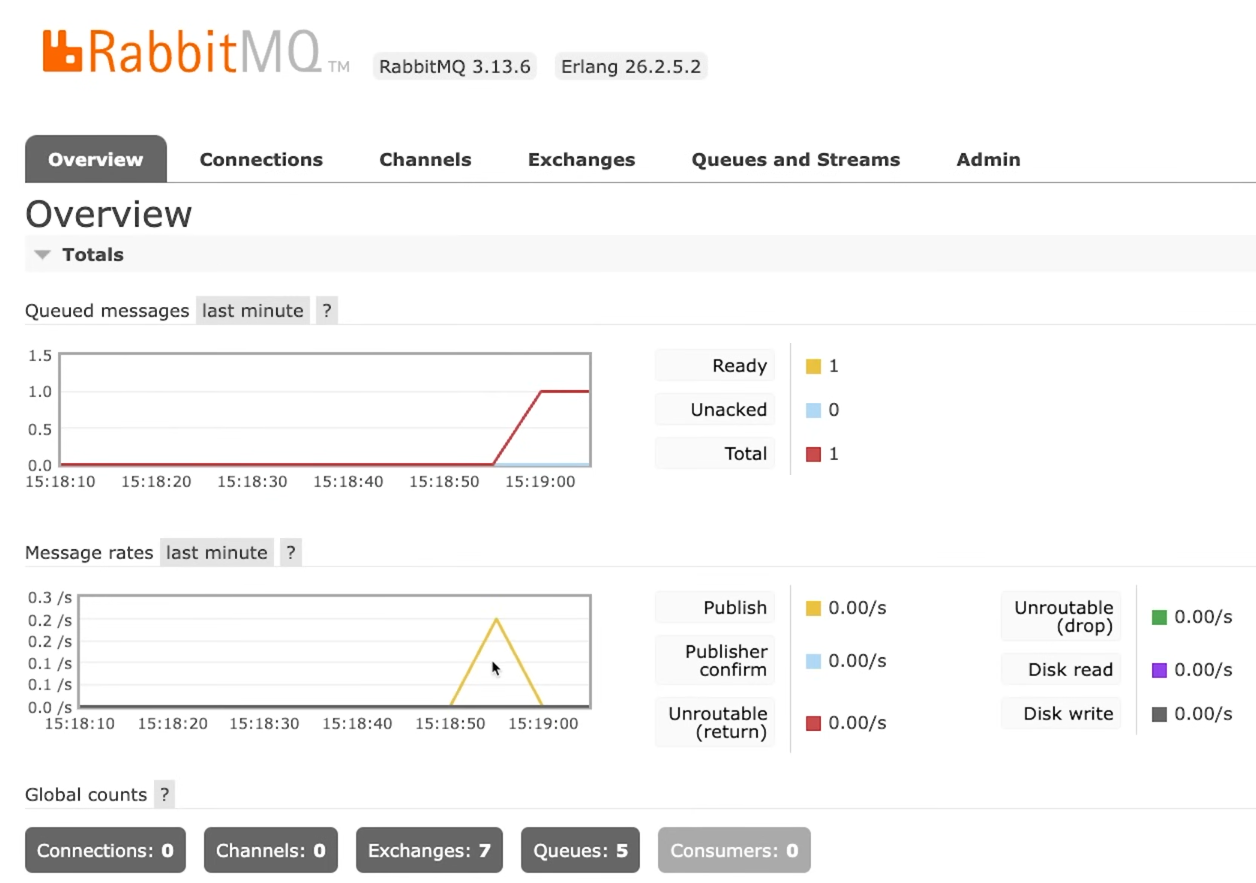
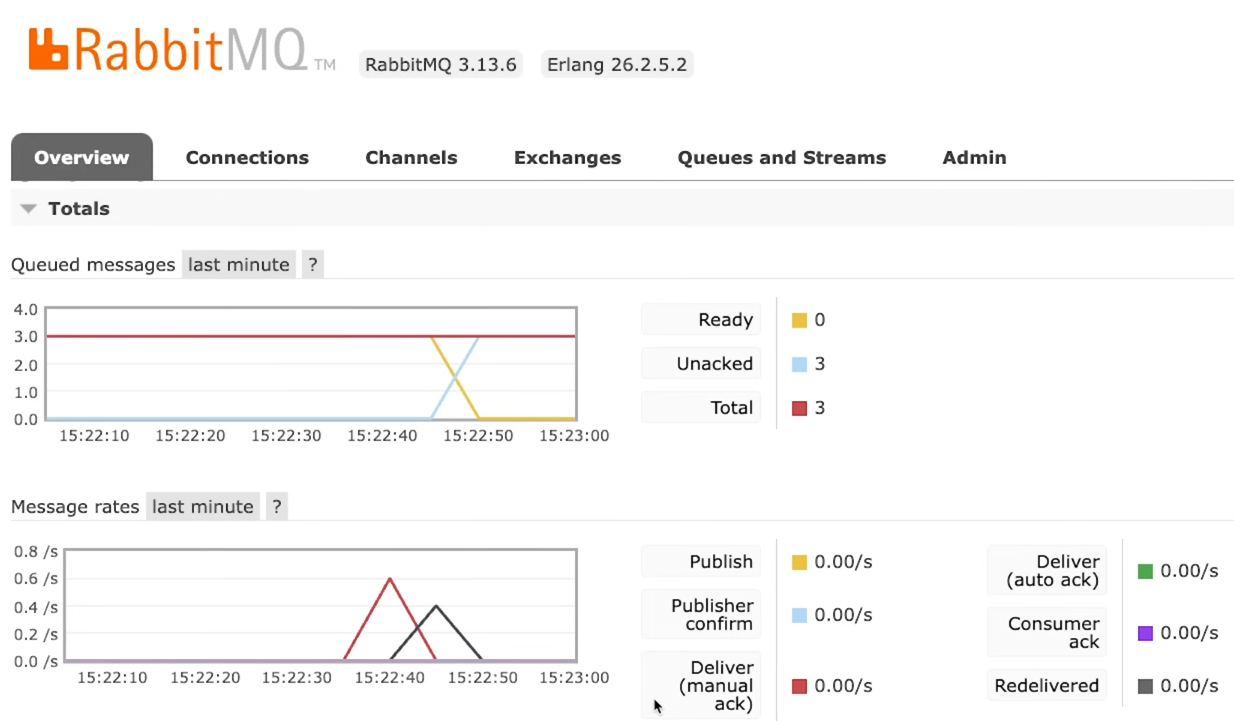
На графиках выше видно, что происходило отправление, затем наступила «тишина», при этом в очереди находится одно непрочитанное сообщение.
Запустим наш скрипт еще несколько раз. Данные на панели управления обновляются каждые пять секунд:
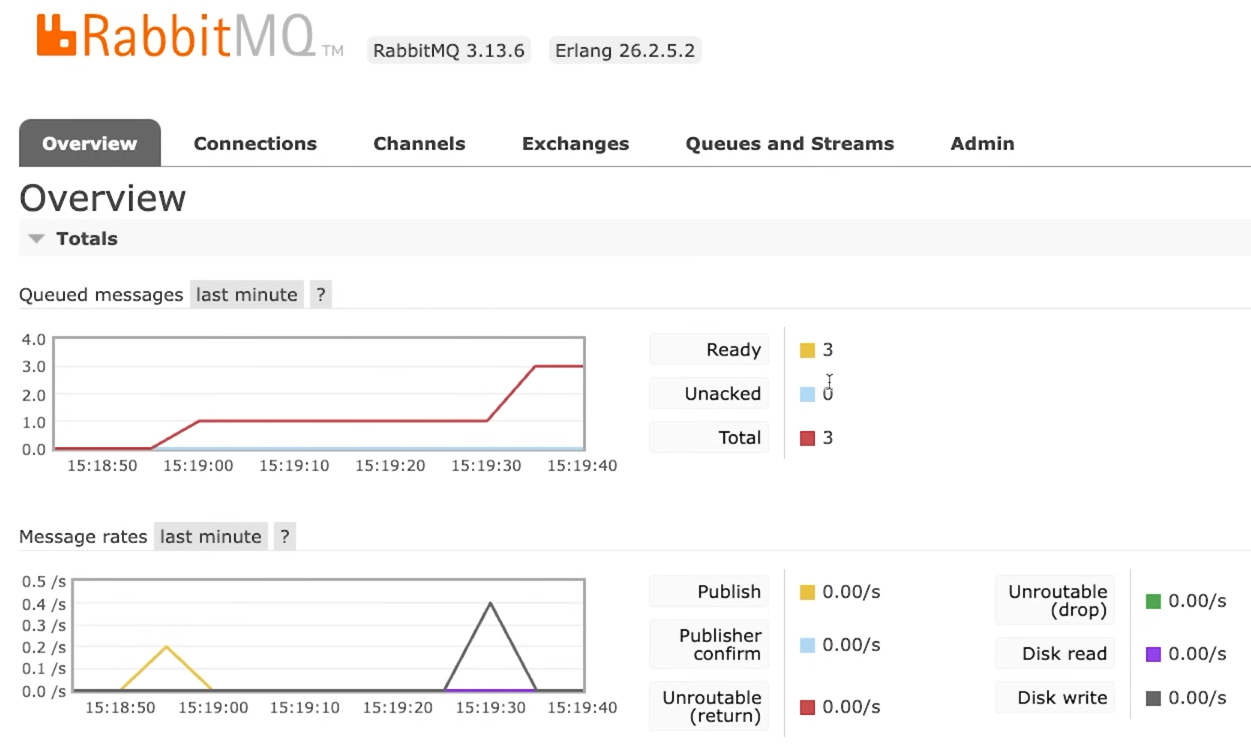
Создадим консьюмер, который будет потреблять все сообщения, поступающие в брокер.
Потребитель сообщений
Работа продюсера и консьюмера в чем‑то схожа. Мы можем скопировать целиком файл producer.py и вставить его в consumer.py, лишь подправив несколько строчек — вместо метода basic_publish определяем basic_consume. Название очереди остается прежним — messages.
Некоторые отличия в логике работы продюсера и консьюмера все-таки есть. В первом случае, когда посылаем сообщение в брокер, мы делаем это явно: понимаем, в какой момент это требуется, видим строчку кода, которая это осуществляет. С чтением сообщений так не получится — мы не можем знать, когда оно придет, заранее.
Программировать самостоятельно периодический опрос какой‑то структуры неразумно — такой подход загромождает код и ставит эффективность реализации в зависимость от специфических знаний разработчика. Библиотека pika подразумевает иной подход — создание функции обратного вызова, которую внутренние механизмы будут пробуждать в момент прихода новых сообщений. В документации для нее принято название callback, мы будем использовать более понятное — process_message.
def main():
with BlockingConnection(connection_params) as conn:
with conn.channel() as ch:
ch.queue_declare(queue="messages")
ch.basic_consume(
queue="messages",
on_message_callback=process_message,
)
print("Жду сообщений")
ch.start_consuming()
В коде выше вызов функции start_consuming — и есть ожидание от внутренних механизмов сигнала о необходимости извлечения сообщения из очереди.
Когда консьюмер забирает сообщения из брокера, он руководствуется какой-то логикой: работает с базой данных, уведомляет пользователя, инициирует банковскую транзакцию, обращается к какому-то внешнему API… Наша функция обратного вызова скорее демонстрационная — мы просто выведем все полученные аргументы:
def process_message(*args):
for arg in args:
print(arg, "\n\n")
Полностью код консьюмера выглядит так:
from pika import ConnectionParameters
connection_params = ConnectionParameters(
host = "localhost",
port = 5672,
)
def process_message(*args):
for arg in args:
print(arg, "\n\n")
def main():
with BlockingConnection(connection_params) as conn:
with conn.channel() as ch:
ch.queue_declare(queue="messages")
ch.basic_consume(
queue="messages",
on_message_callback=process_message,
)
print("Жду сообщений")
ch.start_consuming()
Запустим созданный консьюмер и посмотрим, что произойдет:
python3 consumer.pyПриведем лишь часть вывода — он слишком объемный:
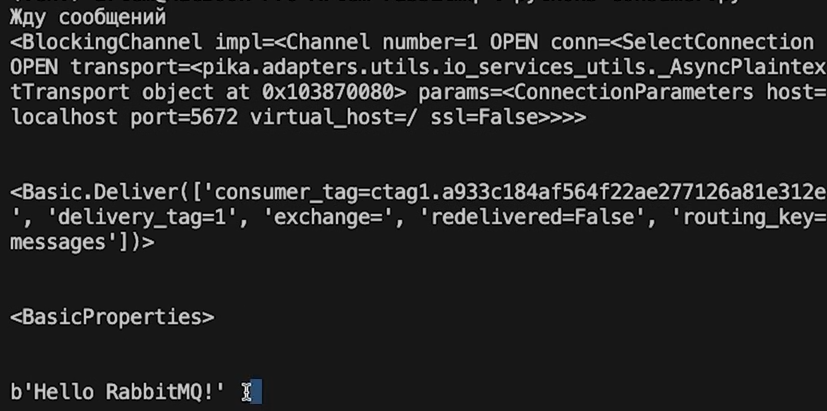
Мы получили распечатку данных по всем трем сообщениям, которые до этого передавали в RabbitMQ. На вкладке Overview в панели управления тоже произошли изменения:
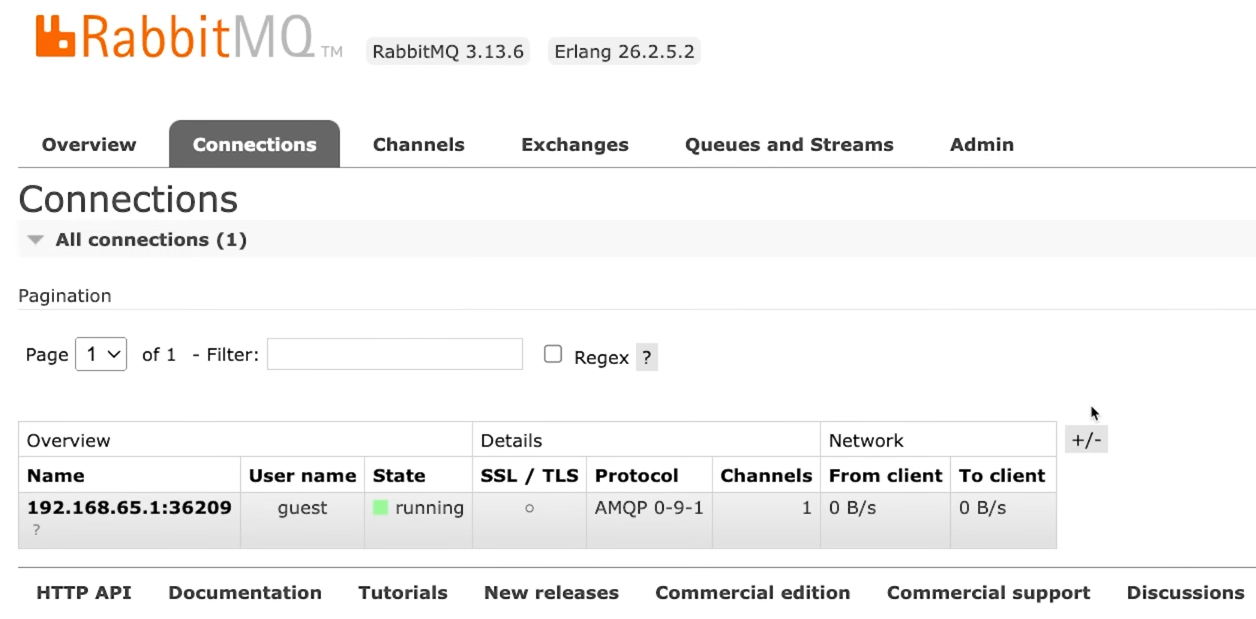
Обратите внимание: консьюмер по-прежнему запущен, в этом можно убедиться, взглянув на вкладку соединений в панели управления. Если придет какое-то новое сообщение, оно появится в выводе. Чтобы продолжить совершенствовать наш консьюмер, его надо остановить принудительно. Сейчас это можно сделать, нажав предусмотренную комбинацию клавиш в терминале.
Что за параметры приходят в функцию обратного вызова?
BlockingChannel — канал, с которым мы работаем:
with conn_channel() as ch:
BasicDeliver — метод, в котором отражены параметры, указанные ранее: exchange, routing key и другие. BasicProperties в нашем случае пуст. Наконец, самый последний параметр — текст сообщения. Таким образом, обработчик можно переписать, явно указав название аргументов:
def process_message(ch, method, properties, body):
print(f"Получено сообщение: {body.decode()}")
Обратите внимание, что приходит именно байтовая строка — ее нужно преобразовывать в текстовую.
Если запустить наш консьюмер опять, вывод будет другим (поскольку мы поменяли содержимое функции process_message). Однако снова извлекаются три сообщения!
python3 consumer.py
Жду сообщений
Получено сообщение: Hello RabbitMQ!
Получено сообщение: Hello RabbitMQ!
Получено сообщение: Hello RabbitMQ!Сообщения по-прежнему находятся в RabbitMQ. Очень важно указывать брокеру, что они обработаны, и разрешить их удаление.
Здесь проявляется одно из отличий RabbitMQ от Kafka, которая будет хранить сообщения всегда и дает возможность работать с их историей. В RabbitMQ такая функциональность тоже осуществима, но для этого придется основательно поработать с настройками.
Удалением сообщений в RabbitMQ можно управлять двумя способами.
Первый из них — установить соответствующий флаг в функции basic_consume, который по умолчанию имеет значение False:
auto_ack=True,
Однако тогда удаление сообщения произойдет до начала его обработки. Такой подход не всегда может устроить разработчика. Представим, что сообщение несет критически важную информацию и должно быть обработано корректным образом в любом случае. Появляется риск, что этого не произойдет в случае непредвиденной ошибки.
Второй способ — явно вызывать в функции обратного вызова метод basic_ack. Так сообщение удалится только после того, как будет благополучно обработано:
ch.basic_ack(delivery_tag=method.delivery_tag)
В протоколе AMQP delivery_tag — уникальный идентификатор доставки сообщения.
Развертывание инструментов на сервере
Обычно используется два сервиса: RabbitMQ и RabbitMQ Management — ядро и средство графического представления. Разместим их на облачном сервере. Для экспериментов лучше выбрать последнюю Ubuntu. Сгенерировать SSH‑ключ для безопасного подключения поможет наша статья. Оперативной памяти будет достаточно 512 МБ. Особо мощный процессор не требуется, можно ограничиться одним ядром. Для хранения информации на жестком диске достаточно 5 ГБ. По ценам на конец 2024 года выйдет около 25 ₽ в сутки.
Для дальнейших действий понадобится терминал. Можно использовать консоль в панели управления Selectel. Кому-то покажется удобным работать с привычным терминалом своего компьютера. В таком случае копируем сначала IP‑адрес нашего созданного сервера и подключаемся к нему:
ssh root@87.228.12.94Затем копируем и вставляем пароль, который задается в панели управления сервером:
Переходим к документации Docker, разделу установки Ubuntu. Все необходимые команды нужно будет скопировать и перенести в терминал. Сначала подключаем репозиторий Docker:
Затем устанавливаем все необходимые Docker‑файлы. Для этого также воспользуемся копированием или онлайн‑документацией Docker.
Не забудьте проверить корректность установки Docker способом, указанным на той же странице документации. Нам также понадобится Docker Compose, который запускает контейнеры в самом Docker.
Обратите внимание на порт 5672 — именно он используется RabbitMQ. Создадим файл docker-compose.yml следующего содержания в любой подходящей директории:
services:
rabbitmq:
image: rabbitmq:3.10.7-management
hostname: rabbitmq
ports:
- 15672:15672
- 5672:5672
Для этого воспользуемся терминалом.
touch docker-compose.yml
nano docker-compose.ymlЗапустим приложения, описанные в YAML‑файле:
docker compose up --buildТеперь можно войти в систему управления RabbitMQ. Для этого вводим в в адресную строку браузера IP-адрес нашего сервера и указываем порт, который использует RabbitMQ. Не забываем имя пользователя и пароль по умолчанию, которые мы не изменяли: guest, guest. Появляется уже знакомая нам панель управления RabbitMQ:
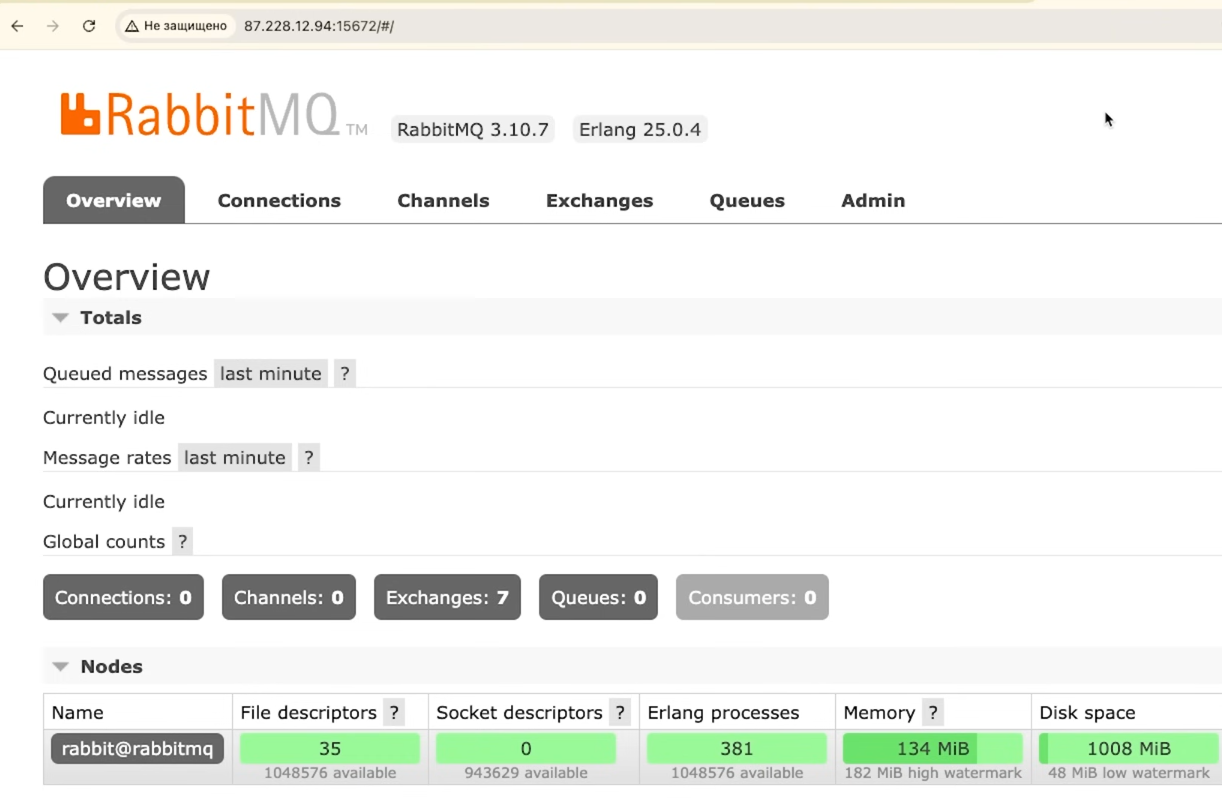
Мы не создавали специального пользователя, не меняли пароли по умолчанию — стенд нужен только для демонстрации. На практике лучше получше позаботиться о безопасности и работать не из под root.
Наконец, подключимся к нашей удаленной очереди. Для этого в коде наших продюсера и консьермера меняем значение host на IP-адрес нашего сервера:
connection_params = ConnectionParameters(
host="87.228.12.94",
port=5672,
)
Вот так, буквально за несколько минут мы подняли свой сервер в облаке Selectel, установили и настроили инструментарий Docker, запустили RabbitMQ, подключились к его мониторингу через веб-браузер.





