Перенос данных между серверами с помощью LVM


Простое перемещение дисков из одного сервера в другой очень часто тоже оказывается невозможным: причиной этого может быть несовместимость интерфейсов, использование разных RAID-контроллеров, географическая удаленность серверов друг от друга и т.п. Копирование же данных по сети может занимать очень много времени, в течение которого сервис простаивает. Как можно перенести данные на новый сервер, минимизировав время простоя сервисов?
Мы долго думали над этим вопросом и сегодня представляем вниманию широкой аудитории решение, которое кажется нам наиболее удачным.
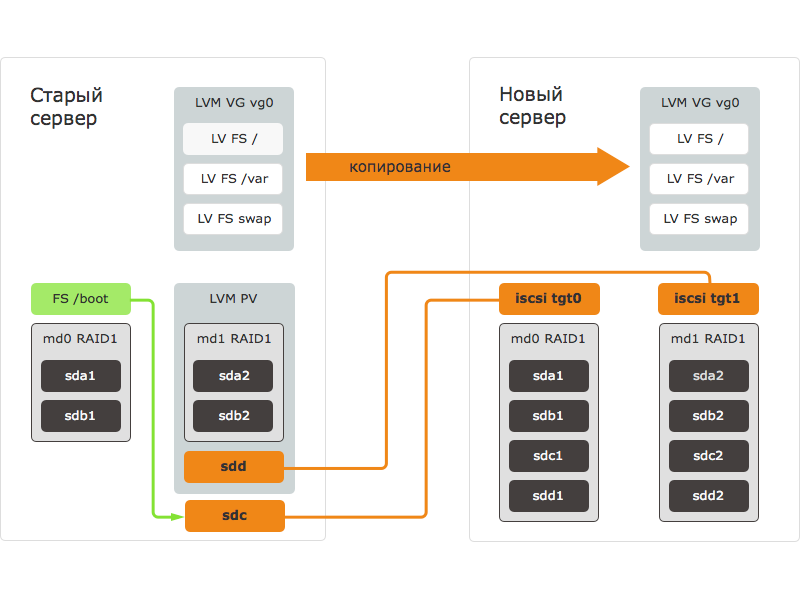
Процедура переноса данных с помощью рассматриваемого в этой статье способа состоит из следующих шагов:
- новый сервер загружается с внешнего носителя, подготавливаются блочные устройства: размечаются диски, создаются RAID-массивы;
- блочные устройства нового сервера экспортируются через iSCSI – создаются iSCSI таргеты;
- на старом сервере запускается iSCSI инициатор и подключается к таргетам на новом сервере. На старом сервере появляются и становятся доступны блочные устройства нового сервера;
- на старом сервере блочное устройство нового сервера добавляется в LVM группу;
- данные копируются на блочное устройство нового сервера с помощью зеркалирования данных в LVM;
- старый сервер выключается;
- на новом сервере, все еще загруженном с внешнего носителя, монтируется перенесенная на него ФС, в настройки вносятся необходимые правки;
- новый сервер перезагружается с дисков, после чего запускаются все сервисы.
Если с новым сервером обнаружены проблемы, он выключается. Включается старый сервер, все сервисы продолжают работать на старом сервере.
Предлагаемая нами методика подходит для всех ОС, где используется LVM для логических разделов и возможна установка iSCSI таргета и инициатора. На сервере, на котором мы осуществляли опытную проверку предлагаемой методики, была установлена ОС Debian Wheezy. В других ОС могут использоваться другие программы и команды, но порядок действий будет аналогичным.
Все операции осуществлялись на сервере с разметкой дисков, стандартной для наших серверов при автоматической установке ОС. Если на вашем сервере используется другая разметка дисков, параметры некоторых команд потребуется изменить.
Наш способ переноса данных рассчитан на опытных пользователей, хорошо знающих, что такое LVM, mdraid, iSCSI. Предупреждаем, что ошибки в командах могут привести к полной или частичной потере данных. Прежде чем приступать к переносу данных, необходимо сохранить резервные копии важной информации на внешнем носителе или хранилище.
Готовим новый сервер
Если вы переносите данные на сервер с иной аппаратной конфигурацией (особое внимание следует обратить на контроллер дисков), установите на новый сервер тот же дистрибутив ОС, что и на старом, а также драйверы, необходимые для работы. Проверьте, что все устройства определяются и работают. Сохраните/запишите необходимые действия, в дальнейшем их надо будет выполнить в перенесенной системе, чтобы новый сервер смог загрузиться после переноса.
Затем загрузите новый сервер с внешнего носителя. Нашим клиентам мы рекомендуем загрузиться в Selectel Rescue, используя меню управления загрузкой сервера.
По завершении загрузки подключитесь к новому серверу по SSH. Задайте для нового сервера его будущий hostname. Это необходимо в случае, если вы собираетесь использовать на новом сервере mdraid: при создании RAID-массива hostname будет сохранен в метаданных RAID-массива на всех входящих в него дисках.
# hostname cs940
Далее следует разметить диски. В нашем случае на каждом сервере будет создано по два основных раздела на каждом диске. Первые разделы будут использованы для сборки RAID1 для /boot, вторые — для сборки RAID10 под LVM Physical Volume, на котором и будут размещены основные данные.
# fdisk /dev/sda Command (m for help): p ... Device Boot Start End Blocks Id System /dev/sda1 * 2048 2099199 1048576 fd Linux raid autodetect /dev/sda2 2099200 1953525167 975712984 fd Linux raid autodetect Command (m for help): w
Чтобы все было проще и быстрее, можно разметить только первый диск, а на остальные скопировать его разметку. Затем создайте RAID-массивы при помощи утилиты mdadm.
# sfdisk -d /dev/sda | sfdisk /dev/sdb -f # mdadm --create /dev/md0 --level=1 --raid-devices=4 /dev/sda1 /dev/sdb1 /dev/sdc1 /dev/sdd1 # mdadm --create /dev/md1 --level=10 --raid-devices=4 /dev/sda2 /dev/sdb2 /dev/sdc2 /dev/sdd2 # mdadm --examine --scan ARRAY /dev/md/0 metadata=1.2 UUID=e9b2b8e0:205c12f0:2124cd91:35a3b4c8 name=cs940:0 ARRAY /dev/md/1 metadata=1.2 UUID=4be6fb41:ab4ce516:0ba4ca4d:e30ad60b name=cs940:1
Затем установите и настройте iSCSI-таргет для копирования RAID-массивов по сети. Мы использовали tgt.
# aptitude update # aptitude install tgt
Если при запуске tgt возникнут ошибки загрузки отсутствующих ядерных модулей, не стоит беспокоиться: они нам не понадобятся.
# tgtd librdmacm: couldn't read ABI version. librdmacm: assuming: 4 CMA: unable to get RDMA device list (null): iser_ib_init(3263) Failed to initialize RDMA; load kernel modules? (null): fcoe_init(214) (null) (null): fcoe_create_interface(171) no interface specified.
Следующий этап — настройка LUN’ов. При создании LUN нужно указать IP старого сервера, с которого будет разрешено подключение к таргету.
# tgt-setup-lun -n tgt0 -d /dev/md0 10.0.0.1 # tgt-setup-lun -n tgt1 -d /dev/md1 10.0.0.1 # tgt-admin -s
Новый сервер готов, перейдем к подготовке старого сервера.
Подготовка старого сервера и копирование данных
Теперь подключимся к старому серверу по SSH. Установим и настроим iSCSI-инициатор, а затем подключим к нему экспортированные с нового сервера блочные устройства:
# apt-get install open-iscsi
Добавим в конфигурационный файл данные авторизации: без них инициатор не будет работать.
# nano /etc/iscsi/iscsid.conf node.startup = automatic node.session.auth.username = MY-ISCSI-USER node.session.auth.password = MY-ISCSI-PASSWORD discovery.sendtargets.auth.username = MY-ISCSI-USER discovery.sendtargets.auth.password = MY-ISCSI-PASSWORD
Дальнейшие операции занимают довольно много времени; чтобы избежать неприятных последствий в случае их прерывания при закрытии SSH, воспользуемся утилитой screen. С ее помощью мы создадим виртуальный терминал, к которому можно будет подключаться по SSH и отключаться без завершения запущенных команд:
# apt-get install screen # screen
Затем подключаемся к порталу и получаем список доступных таргетов; указываем при этом текущий IP-адрес нового сервера:
# iscsiadm --mode discovery --type sendtargets --portal 10.0.0.2 10.0.0.2:3260,1 iqn.2001-04.com.cs940-tgt0 10.0.0.2:3260,1 iqn.2001-04.com.cs940-tgt1
Затем подключаем все доступные таргеты и LUN’ы; в результате выполнения этой команды мы увидим список новых блочных устройств:
# iscsiadm --mode node --login Logging in to [iface: default, target: iqn.2001-04.com.cs940-tgt0, portal: 10.0.0.2,3260] (multiple) Logging in to [iface: default, target: iqn.2001-04.com.cs940-tgt1, portal: 10.0.0.2,3260] (multiple) Login to [iface: default, target: iqn.2001-04.com.cs940-tgt0, portal: 10.0.0.2,3260] successful. Login to [iface: default, target: iqn.2001-04.com.cs940-tgt1, portal: 10.0.0.2,3260] successful.
iSCSI-устройства в системе имеют те же имена, что и обычные SATA/SAS. Но при этом у двух типов устройств различается имя производителя: для iSCSI-устройств оно указано как IET.
# cat /sys/block/sdc/device/vendor IET
Теперь можно приступить к переносу данных. Сначала отмонтируем boot и скопируем его на новый сервер:
# umount /boot # cat /sys/block/sdc/size 1999744 # cat /sys/block/md0/size 1999744 # dd if=/dev/md0 of=/dev/sdc bs=1M 976+1 records in 976+1 records out 1023868928 bytes (1.0 GB) copied, 19.6404 s, 52.1 MB/s
Внимание! С этого момента не активируйте VG и не запускайте никаких LVM-утилит на новом сервере. Одновременная работа двух LVM с одним и тем же блочным устройством может вызвать порчу или потерю данных.
Теперь приступаем к переносу данных. Добавляем в VG экспортированный с нового сервера RAID10-массив:
# vgextend vg0 /dev/sdd # pvs PV VG Fmt Attr PSize PFree /dev/md1 vg0 lvm2 a-- 464.68g 0 /dev/sdd vg0 lvm2 a-- 1.82t 1.82t
Не забываем о том, что /dev/sdd представляет собой /dev/md1, экспортированный с нового сервера, загруженного в Rescue:
# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert root vg0 -wi-ao-- 47.68g swap_1 vg0 -wi-ao-- 11.44g var vg0 -wi-ao-- 405.55g
Теперь создаем для каждого логического тома копию на новом сервере командой lnconvert. Параметр –corelog позволит обойтись без отдельного блочного устройства под логи зеркала.
# lvconvert -m1 vg0/root --corelog /dev/sdd vg0/root: Converted: 0.0% vg0/root: Converted: 1.4% … vg0/root: Converted: 100.0%
Так как при создании зеркальной копии LVM все операции записи осуществляются синхронно, на скорость записи будет влияет скорость канала между серверами, производительность open-iSCSI (500 мБ/с), а также задержка сети. После создания копий всех логических томов убедимся в том, что все они синхронизированы:
# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert root vg0 mwi-aom- 47.68g 100.00 swap_1 vg0 mwi-aom- 11.44g 100.00 var vg0 mwi-aom- 405.55g 100.00
На данном этапе все данные скопированы и идет синхронизация данных старого сервера с новым удаленным сервером. Чтобы минимизировать изменения в файловой системе, нужно остановить все сервисы приложений (сервис БД, веб-сервер и т.п.).
Остановив все важные сервисы, отключаем iSCSI-устройства и исключаем ставшую недоступной копию LVM. После отключения iSCSI-устройств на старом сервере будут выдаваться многочисленные сообщения об ошибках ввода-вывода, но это не должно быть причиной для беспокойства: все данные сохраняются на LVM, лежащий выше блочных устройств.
# iscsiadm --mode session -u # vgreduce vg0 --removemissing --force # lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert root vg0 -wi-ao-- 47.68g swap_1 vg0 -wi-ao-- 11.44g var vg0 -wi-ao-- 405.55g
Теперь можно выключить старый сервер. Все данные на нем остались, и в случае каких-либо проблем с новым сервером ими всегда можно воспользоваться.
# poweroff
Запуск нового сервера
После переноса данных новый сервер нужно подготовить к самостоятельной загрузке и запустить.
Подключаемся по ssh, останавливаем iSCSI-таргет и активируем копию LVM:
# tgtadm --lld iscsi --mode target --op delete --tid 1 # tgtadm --lld iscsi --mode target --op delete --tid 2 # pvscan
Теперь исключаем из LVM копию со старого сервера; на сообщения об отсутствии второй половины не обращаем внимания.
# vgreduce vg0 --removemissing --force Couldn't find device with uuid 1nLg01-fAuF-VW6B-xSKu-Crn3-RDJ6-cJgIax. Unable to determine mirror sync status of vg0/swap_1. Unable to determine mirror sync status of vg0/root. Unable to determine mirror sync status of vg0/var. Wrote out consistent volume group vg0
Убедившись, что все логические тома на месте, активируем их:
# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert root vg0 -wi----- 47.68g swap_1 vg0 -wi----- 11.44g var vg0 -wi----- 405.55g # vgchange -ay 3 logical volume(s) in volume group "vg0" now active
Желательно также проверить файловые системы на всех логических томах:
# fsck /dev/mapper/vg0-root
Далее выполним chroot в скопированную систему и внесем финальные изменения. Это можно сделать с помощью скрипта infiltrate-root, доступного в Selectel Rescue:
# infiltrate-root /dev/mapper/vg0-root
Далее все действия на сервере выполняем из chroot. Выполним монтирование всех файловых систем из fstab (по умолчанию chroot монтирует только корневую файловую систему):
Chroot:/# mount -a
Теперь обновим информацию о RAID-массивах на новом сервере в файле настроек mdadm. Удалим оттуда все данные о старых RAID-массивах (строки, начинающиеся с «ARRAY») и добавим новые:
Chroot:/# nano /etc/mdadm/mdadm.conf Chroot:/# mdadm --examine --scan >> /etc/mdadm/mdadm.conf
Пример валидного mdadm.conf:
Chroot:/# cat /etc/mdadm/mdadm.conf DEVICE partitions # auto-create devices with Debian standard permissions CREATE owner=root group=disk mode=0660 auto=yes # automatically tag new arrays as belonging to the local system HOMEHOST # instruct the monitoring daemon where to send mail alerts MAILADDR root # definitions of existing MD arrays ARRAY /dev/md/0 metadata=1.2 UUID=2521ca82:2a52a408:565fab6c:43ba944e name=cs940:0 ARRAY /dev/md/1 metadata=1.2 UUID=6240c2db:b4854bd7:4c4e1510:d37e5010 name=cs940:1
После этого нужно обновить initramfs, чтобы он мог найти и загрузиться с новых RAID-массивов. Также установим на диски загрузчик GRUB и обновим его конфигурацию:
Chroot:/# update-initramfs -u Chroot:/# grub-install /dev/sda --recheck Installation finished. No error reported. Chroot:/# grub-install /dev/sdb --recheck Installation finished. No error reported. Chroot:/# update-grub Generating grub.cfg ... Found linux image: /boot/vmlinuz-3.2.0-4-amd64 Found initrd image: /boot/initrd.img-3.2.0-4-amd64 done
Удалим файл udev c cоответствиями названий сетевых интерфейсов и MAC-адресов (при следующей загрузке он будет создан заново):
Chroot:/# rm /etc/udev/rules.d/70-persistent-net.rules
Теперь новый сервер готов к загрузке:
Chroot:/# umount -a Chroot:/# exit
Изменим порядок загрузки на загрузку с первого жесткого диска в меню управления сервером и перезагрузим его:
# reboot
Теперь проверим с помощью KVM-консоли, что сервер загрузился, и проверим доступ к серверу по IP-адресу. Если с новым сервером возникают какие-то проблемы, вы можете вернуться к старому серверу.
Не загружайте старый и новый серверы в рабочую ОС одновременно: они будут загружены с одним и тем же IP, что может привести к потере доступа и другим проблемам.
Адаптация файловой системы после миграции
Все данные перенесены, все сервисы работают и дальнейшие действия можно производить не торопясь. В рассматриваемом нами примере миграция данных осуществлялась на сервер с большим размером дискового пространства. Все это дисковое пространство теперь нужно задействовать. Для этого сначала расширим физический раздел, затем — логический раздел и, наконец, файловую систему в целом:
# pvresize /dev/md1
# pvs
PV VG Fmt Attr PSize PFree
/dev/md1 vg0 lvm2 a-- 1.82t 1.36t
# vgs
VG #PV #LV #SN Attr VSize VFree
vg0 1 3 0 wz--n- 1.82t 1.36t
# lvextend /dev/vg0/var /dev/md1
Extending logical volume var to 1.76 TiB
Logical volume var successfully resized
# lvs
LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert
root vg0 -wi-ao-- 47.68g
swap_1 vg0 -wi-ao-- 11.44g
var vg0 -wi-ao-- 1.76t
# xfs_growfs /var
meta-data=/dev/mapper/vg0-var isize=256 agcount=4, agsize=26578176 blks
= sectsz=512 attr=2
data = bsize=4096 blocks=106312704, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0
log =internal bsize=4096 blocks=51910, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
data blocks changed from 106312704 to 472291328
# df -h
Filesystem Size Used Avail Use% Mounted on
rootfs 47G 660M 44G 2% /
udev 10M 0 10M 0% /dev
tmpfs 1.6G 280K 1.6G 1% /run
/dev/mapper/vg0-root 47G 660M 44G 2% /
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 3.2G 0 3.2G 0% /run/shm
/dev/md0 962M 36M 877M 4% /boot
/dev/mapper/vg0-var 1.8T 199M 1.8T 1% /var
Заключение
Несмотря на свою сложность, описанный нами подход имеет ряд преимуществ. Во-первых, он позволяет избежать длительного простоя сервера — все сервисы продолжают работать во время копирования данных. Во-вторых, в случае каких-либо проблем с новым сервером в резерве остается старый, готовый к быстрому старту. В-третьих, он универсален и не зависит от того, какие сервисы работают на сервере.
Аналогичным способом можно осуществлять миграцию и под другими операционными системами — CentOS, OpenSUSE и др. Естественно, в этом случае возможны различия в некоторых нюансах (подготовка ОС для старта на новом сервере, настройка загрузчика, initrd и т.п.).
Мы прекрасно понимаем, что предлагаемую нами методику вряд ли можно считать идеальной. Будем благодарны за любые замечания и предложения по ее усовершенствованию. Если кто-то из наших читателей может предложить собственный вариант решения проблемы переноса данных без остановки серверов, будем рады с ним ознакомиться.




