

Введение
В мире вычислительных систем производительность и эффективность — ключевые критерии успеха программного обеспечения. Пользователи ожидают мгновенной реакции приложений, а серверы должны обрабатывать тысячи запросов одновременно. Чтобы соответствовать этим требованиям, разработчики все чаще прибегают к многопоточности — одному из фундаментальных подходов в программировании.
В статье подробно расскажем, что такое multithreading, как он устроен на уровне процессоров и кода, чем отличается от многозадачности и какие трудности возникают при его использовании.
Что такое многопоточность и какая она бывает
Многопоточность (или multithreading) — это способность системы выполнять несколько потоков (нитей выполнения) одновременно в рамках одного процесса. При этом каждый поток — это отдельная последовательность команд, которая может выполняться независимо от других, что позволяет эффективно использовать ресурсы процессора и ускорять выполнение задач.
Многопоточность в процессорах
На аппаратном уровне многопоточность реализуется с помощью архитектурных решений, таких как симметричная многопроцессорность (SMP) или гиперпоточность (Hyper-Threading). Это обусловлено тем, что современные процессоры обладают несколькими ядрами, где каждое может одновременно выполнять несколько потоков.
Например, технология Hyper-Threading от Intel позволяет одному физическому ядру имитировать два логических. Это повышает пропускную способность за счет лучшего использования ресурсов процессора.
В отдельном тексте подробно рассмотрели принцип работы Hyper-Threading, распространенные заблуждения о технологии, а также ее преимущества и недостатки.
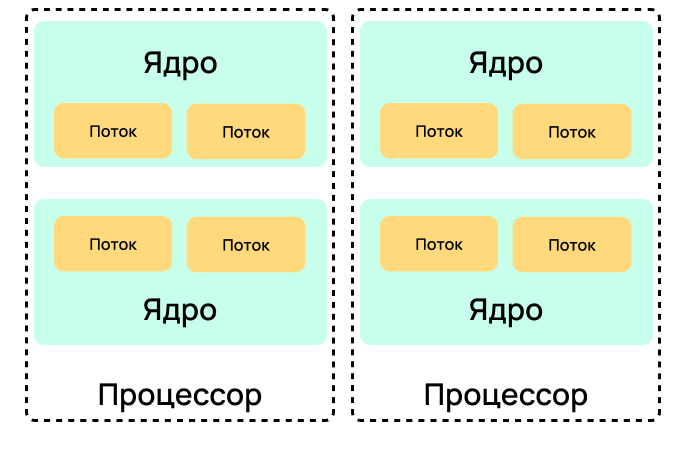
Разберемся в процессорной многопоточности с помощью схемы ниже. В рамках отдельного процессора находится ядро с двумя логическими потоками, на которых непосредственно выполняется наш код. Таким образом, аппаратная многопоточность позволяет выполнять инструкции из разных потоков параллельно. Это особенно важно для задач, которые требуют высокой производительности: обработки данных, рендеринга, научных вычислений и т. д.
Многопоточное программирование
Что значит термин «многопоточное программирование»? Здесь под многопоточностью понимают возможность запуска нескольких потоков выполнения в рамках одной программы. Это позволяет, например, в графическом приложении одновременно обрабатывать пользовательский интерфейс и выполнять фоновые операции: загрузку данных, сохранение файлов и другие. Важно отметить, что основной поток при этом не блокируется.
Разработчик может явно создавать потоки, распределять между ними задачи и управлять их взаимодействием. Но с этой гибкостью приходят и сложности: синхронизация, контроль доступа к ресурсам, избежание состояний гонки. К ним мы еще вернемся дальше.
Про процессы и потоки: в чем разница
Чтобы глубже понять термин «многопоточность», важно разобраться в различиях между процессами и потоками.
Процесс — это экземпляр программы. Каждый запущенный процесс в операционной системе изолирован от других: он обладает собственным виртуальным адресным пространством, файловыми дескрипторами, переменными окружения и другими ресурсами. При этом изоляция обеспечивает стабильность: сбой одного процесса не влияет на другие.
Важно! Cоздание и переключение между процессами требует значительных ресурсозатрат.
Поток — это «нить» внутри процесса, исполняющая некоторый код. Все потоки одного процесса разделяют его память, файловые дескрипторы и другие ресурсы. Это делает обмен данными между потоками быстрым, но вместе с тем повышает риск конфликтов при одновременном доступе к одной и той же переменной.
Зафиксируем основные различия потоков и процессов в таблице:
| Критерий | Процесс | Поток |
| Изоляция | Высокая | Низкая |
| Создание и переключение | Медленное | Быстрое |
| Коммуникация | Через IPC | Прямой доступ к памяти |
| Сбой | Не влияет на другие процессы | Может повлиять на весь процесс |
| Адресное пространство | Собственное | Общее с другими потоками |
Поддержка множества потоков внутри одного процесса
Современные ОС (Linux, Windows, macOS) поддерживают создание множества потоков в рамках одного процесса. Например, веб-сервер может создавать отдельный поток для каждого входящего HTTP-запроса. Это позволяет обрабатывать сотни соединений параллельно, а сборочные системы могут собирать независимые компоненты программы отдельно в каждом потоке.
Чем многопоточность отличается от многозадачности
Термины «многопоточность» и «многозадачность» (multitasking) иногда используют как синонимичные, однако это грубая ошибка. Оба понятия действительно связаны с одновременным выполнением нескольких задач, но работают на разных уровнях.
Многозадачность — это способность операционной системы выполнять несколько процессов (программ) одновременно. Например, вы можете запустить браузер, редактор текста и музыкальный плеер. ОС будет переключаться между ними, создавая иллюзию параллелизма.
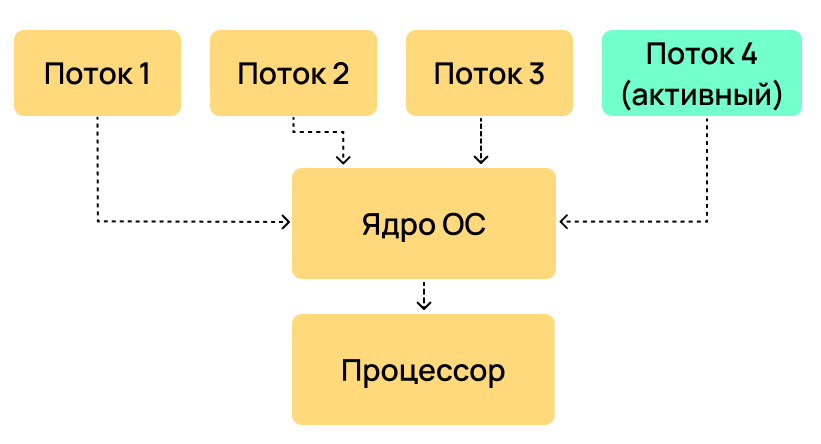
Многопоточность — это выполнение нескольких потоков внутри одного процесса. Все потоки принадлежат одной программе и могут совместно использовать ее память и ресурсы. Как мы можем разобраться по иллюстрации ниже, внутри процесса может быть несколько потоков. При этом каждый из потоков имеет свой стек и регистры.
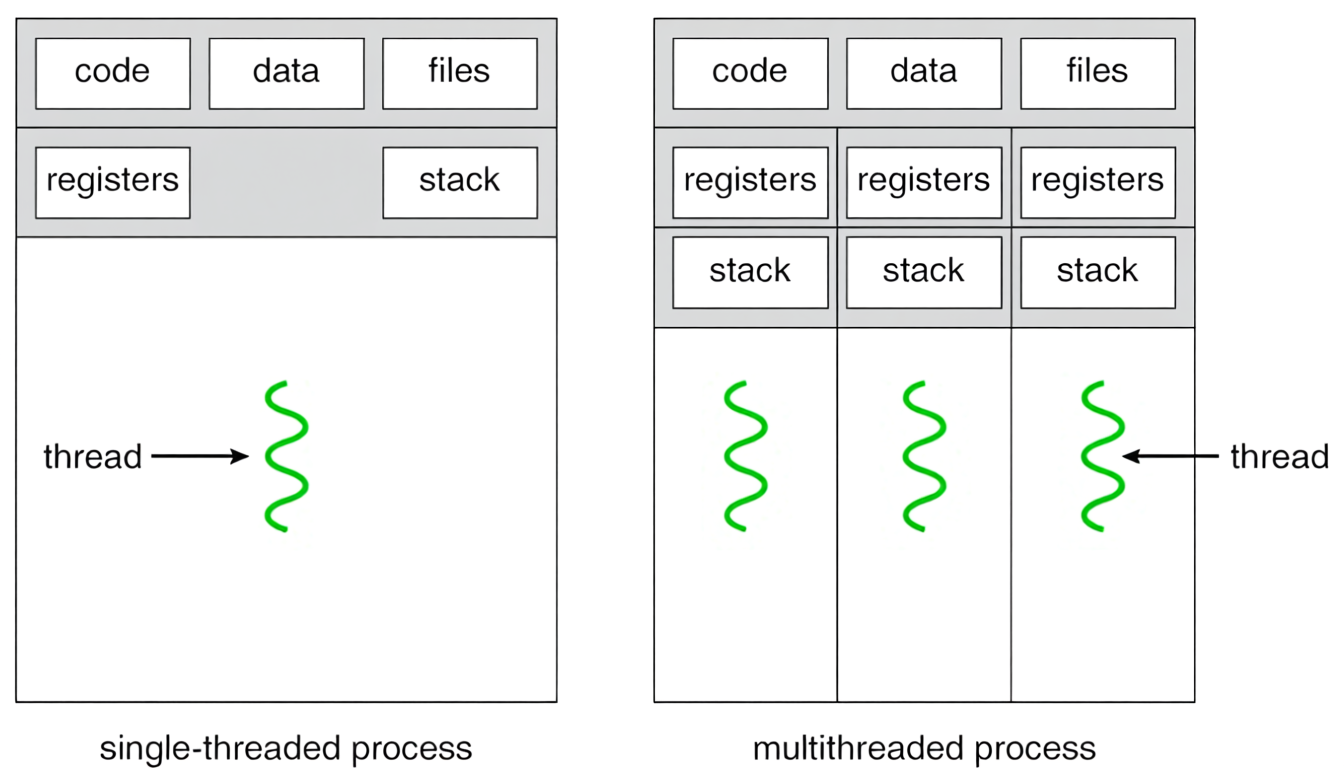
Таким образом, многозадачность — это межпроцессное параллельное выполнение, а многопоточность — внутрипроцессное.
Какие задачи решает многопоточность
Многопоточное программирование применяется для решения широкого круга задач. Разберем наиболее популярные.
- Увеличение производительности — распараллеливание вычислений на многопроцессорных системах.
- Повышение отзывчивости приложений — например, GUI остается активным, пока фоновый поток загружает данные.
- Эффективное использование ресурсов — потоки могут ожидать ввода-вывода, не блокируя выполнение других задач.
- Обработка параллельных событий — серверы, роутеры, системы реального времени.
Без многопоточности современные приложения были бы медленными, нестабильными и неспособными к эффективной работе в условиях высокой нагрузки.
Многопоточность в языках программирования
Разберемся, как работает многопоточность в конкретных языках программирования. Для примера возьмем Python, C++ и Java, но это не значит, но многопоточность поддерживают множество других языков программирования — например, C#, Go и Rust и Erlang.
Python
Python поддерживает многопоточность через модуль threading, но из-за Global Interpreter Lock (GIL) настоящий параллелизм для CPU-интенсивных задач невозможен. GIL блокирует выполнение Python-байткода, позволяя только одному потоку работать с интерпретатором в каждый момент времени. Из-за этого для параллельных вычислений часто используют несколько процессов.
import threading
import time
def worker():
print(f"Привет из потока {threading.current_thread().name}!")
time.sleep(2)
print(f"Поток {threading.current_thread().name} завершен.")
# Создаем поток
thread = threading.Thread(target=worker, name="Worker-1")
# Запускаем
thread.start()
# Основной поток продолжает работать
print(f"Привет из основного потока {threading.current_thread().name}!")
# Ждем завершения потока
thread.join()
print("Программа завершена.")
Java
Java поддерживает потоки через класс Thread и интерфейс Runnable. Язык предоставляет инструменты: ExecutorService, synchronized, volatile, java.util.concurrent — все это делает работу с потоками удобной и безопасной. Кроме того, JVM эффективно управляет потоками на уровне ОС. Пример запуска нового потока в Java:
public static void main(String[] args) {
// Создаем новый поток, передавая ему задачу (Runnable)
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
// Этот код будет выполняться в отдельном потоке
System.out.println("Привет из другого потока! (" + Thread.currentThread().getName() + ")");
}
});
// Запускаем поток
thread.start();
// Основной поток продолжает работать
System.out.println("Привет из основного потока! (" + Thread.currentThread().getName() + ")");
}
C++
C++11 версии ввел стандартную поддержку многопоточности в виде библиотеки <thread>. Разработчики могут создавать потоки с помощью команды std::thread и использовать механизмы синхронизации — например, std::mutex. Реализация кода, схожего с предыдущими разделами, на C++:
void hello() {
std::cout << "Привет из потока " << std::this_thread::get_id() << "!\n";
}
int main() {
// Создаем поток, который будет выполнять функцию hello
std::thread t(hello);
// Основной поток (main) продолжает работать
std::cout << "Привет из основного потока " << std::this_thread::get_id() << "!\n";
// Дожидаемся завершения потока t
t.join();
return 0;
}
Синхронизация потоков: как избежать хаоса
Потоки одного процесса разделяют память, поэтому доступ к общим данным должен быть строго контролируемым. Без синхронизации возникает состояние гонки — когда два потока одновременно работают с переменной и хотя бы один из них осуществляет запись, то результат становится непредсказуемым. Для предотвращения таких ситуаций используются механизмы синхронизации.
Механизмы синхронизации
Мьютексы (mutex) — блокировки, которые позволяют входить в критическую секцию только одному потоку. Используют методы wait/release.

Семафоры — счетчики, которые ограничивают количество потоков, имеющих доступ к ресурсу. Пока счетчик больше нуля, другие потоки могут входить в критическую секцию, а иначе ждут, пока он не увеличится.
Условные переменные позволяют потокам ждать определенных условий — например, ждать, пока флаг data_ready не выставлен. Далее поток продолжает выполнение.
Атомарные операции гарантируют, что операция выполнится целиком, без прерывания. При этом доступ к переменным с использованием атомарных операций потокобезопасен.
Существует много других методов синхронизации, каждый из которых обладает преимуществами и особенностями. Разработчику многопоточных приложений важно понимать, какой именно метод подойдет для конкретного сценария.
Проблемы с многопоточностью
Несмотря на все преимущества, multithreading несет в себе ряд сложных проблем. Они могут привести к сбоям, зависаниям и трудно уловимым ошибкам. Рассмотрим наиболее популярные сложности.
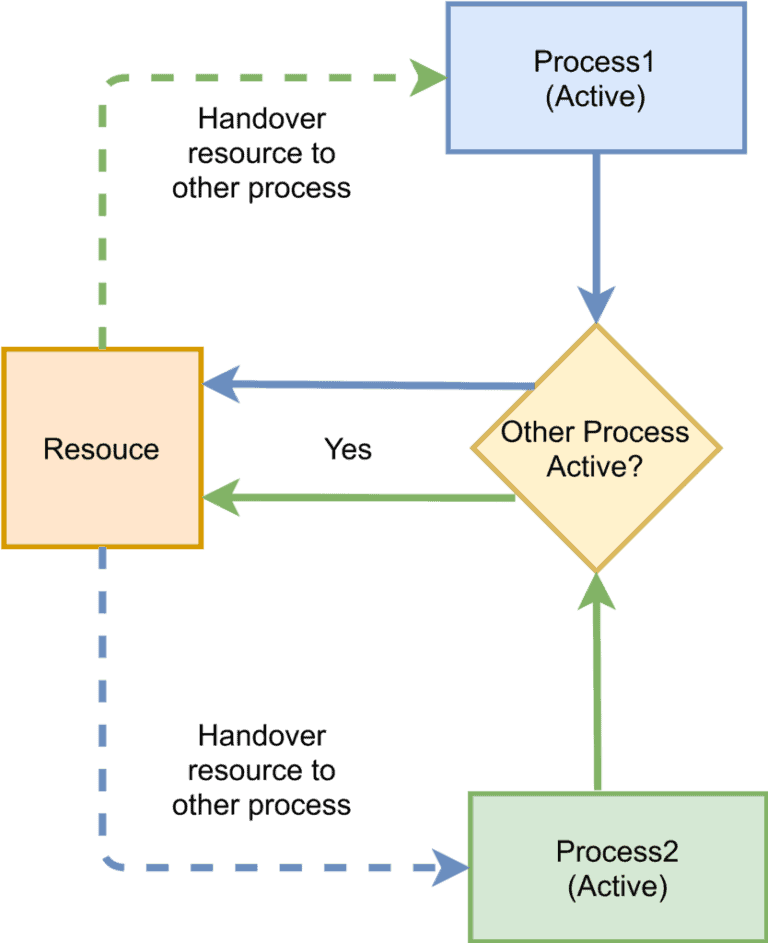
Deadlock (взаимоблокировка)
Deadlock возникает, когда два или более потока ожидают ресурсов, удерживаемых друг другом. Рассмотрим на примере схемы ниже: поток №1 держит ресурсы №2 и ждет данные ресурса №1, а поток №2 держит данные первого ресурса и ждет данные второго. Оба потока блокируются навсегда.
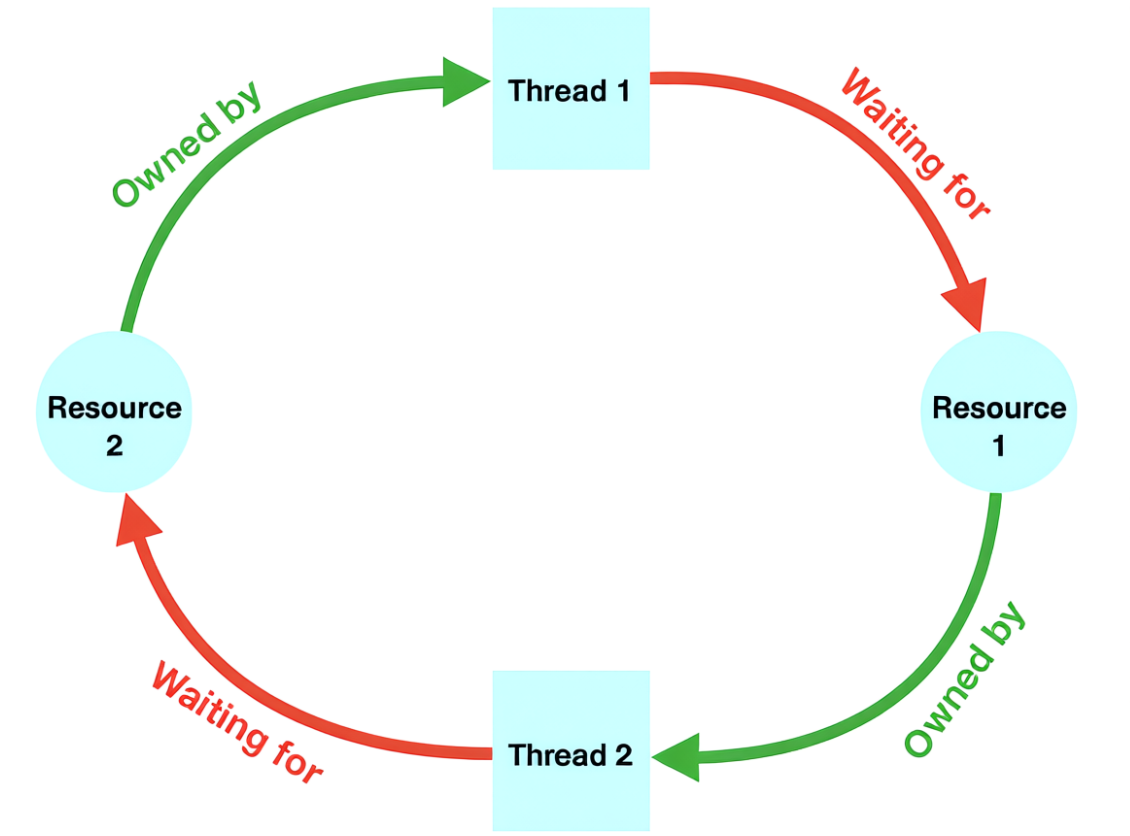
Среди методов решения проблемы — соблюдение порядка захвата блокировок, использование таймаутов, а также deadlock detection.
Голодание потоков (Starvation)
Starvation — это сценарий, при котором поток долгое время не получает доступ к ресурсу из-за приоритетов других потоков. Например, высокоприоритетные потоки постоянно вытесняют низкоприоритетные. Эту проблему можно решать, используя честные алгоритмы планирования или временное повышение приоритета.
Livelock (живая блокировка)
Livelock — сценарий, когда потоки не блокируются, но постоянно реагируют на действия друг друга и не продвигаются к решению.
Проблему можно решить введением случайных задержек и фиксированных стратегий поведения.
Мы остановились на нескольких возможных проблемах, но их существует множество:
- Race condition — состояние гонки, когда результат зависит от порядка выполнения;
- Priority inversion — низкоприоритетный поток блокирует ресурс, нужный высокоприоритетному;
- Thread leakage — утечка потоков при неправильном управлении пулами.
Что предлагает Selectel
Если вы разрабатываете или тестируете многопоточные приложения, может понадобиться мощное оборудование — особенно для нагрузочных испытаний, сборки больших проектов или работы с тяжелыми вычислительными задачами.
Покупка такой системы часто нецелесообразна, если вы сталкиваетесь с этим нерегулярно. В этом случае удобно арендовать облачный сервер или выделенный сервер с нужной конфигурацией: многоядерным процессором, достаточным объемом памяти и быстрыми дисками.
В Selectel можно подобрать решение под конкретные сценарии: от недорогих конфигураций до серверов для высоконагруженных систем. Вы сможете гибко масштабировать ресурсы, платить только за фактическое использование и не беспокоиться об обслуживании железа.
Заключение
Многопоточность — это не просто способ ускорить выполнение кода, а фундаментальный подход к разработке производительных систем. Она делает программы отзывчивыми, помогает лучше использовать ресурсы и масштабировать решения под реальные нагрузки.
Но вместе с преимуществами приходят и вызовы: от гонок данных до deadlock. По этой причине грамотная архитектура и тестирование остаются ключевыми факторами успешного применения многопоточности.




