

Современные игры предлагают богатый контент, разнообразные механики и высокую степень интерактивности. На экране происходит все везде и сразу, а игровой мир продолжает жить даже без активного участия игрока. В статье рассмотрим, как устроены игровые события и как многопоточность влияет на них.
Геймплей
Хотите понять, как на самом высоком уровне абстракции большинство игровых движков обеспечивает функционирование любой игры? Рассмотрим на примере простейшего фрагмента кода.
while(true)
{
// считаем dt
double dt = ...
// игровой тик
handleInput();
update(dt);
render();
}
Здесь ключевая функция с точки зрения геймплея — update. Простой пример ее реализации:
void update(double dt)
{
updateGameTime(dt);
updateWeather(dt);
updatePlayer(dt);
updateMonsters(dt);
updateProjectiles(dt);
updateHud(dt);
updateSkills(dt);
...
}
Что мы видим: есть игровой тик — как правило, это несколько десятков миллисекунд (dt) реального времени. Во время каждого тика происходит симуляция игровых подсистем вперед.
Игровое время успевает продвинуться на пару секунд; солнце смещается на несколько десятых градуса; игрок перемещается на небольшое расстояние; мяч успевает долететь до ворот. Как видите, происходит много всего и сразу. Но где в этом коде многопоточность?
При детальном рассмотрении можно заметить, что события происходят не одновременно. Пользователю будет казаться, что многие процессы выполняются синхронно. В большинстве случаев геймплей обладает многопоточной реализацией. Но если быть точнее, то многопоточность в коде — необязательное условие. В какой-то мере многопоток может и вовсе навредить.
Сложности с многопоточностью в геймплейном коде
Глобальное состояние игры
В мире разработки игр код — комбинация синглтонов и глобального состояния. Игровой уровень, менеджер времени, дерево скиллов, аудио-проигрыватель, интерфейс пользователя (HUD), инвентарь игрока, текущая прогрессия игры, квестовое дерево, дневник — все эти жизненно важные для игры вещи обычно представлены в единственном экземпляре.
Синглтон (singleton) — это шаблон проектирования, который гарантирует, что класс имеет единственный экземпляр, и обеспечивает глобальный доступ к этому экземпляру.
Более того, все эти объекты нужны различным компонентам игры одновременно и повсеместно. Что, если бы геймплейные задачи выполнялись синхронно в разных потоках? Тогда каждый глобальный объект потребовался бы каждому игровому компоненту. При этом отовсюду и действительно одновременно.
Двум параллельным задачам в определенный момент понадобится инвентарь игрока. В таком случае потоки будут конкурировать друг с другом за право эксклюзивного доступа к нему. Один поток прорвется к нему первым, а второму останется только ждать другие потоки. Иначе они столкнутся с проблемой, а именно — data race.
И так каждый раз. Потоки будут простаивать и ждать другие, которые заняли уникальный игровой ресурс. В итоге логика перейдет в однопоточное исполнение, но в извращенной форме. При этом мы столкнемся с проблемой потери скорости. Ведь создание потока и переключение контекста — недешевая операция.
Зависимости систем
Давайте представим, что у игровых систем нет общих данных, за которые нужно бороться. Тогда мы могли бы параллельно запустить все системы в разных потоках:
void update(double dt)
{
static std::vector<std::thread> jobs;
// Запускаем потоки
jobs.emplace_back(updateGameTime, dt);
jobs.emplace_back(updateWeather, dt);
jobs.emplace_back(updatePlayer, dt);
jobs.emplace_back(updateMonsters, dt);
jobs.emplace_back(updateProjectiles, dt);
jobs.emplace_back(updateHud, dt);
jobs.emplace_back(updateSkills, dt);
// Дожидаемся выполнения всех потоков
for (auto& job : jobs) {
job.join();
}
jobs.clear();
}
Но даже если мы забудем / не будем делить общие данные, есть нюанс. Геймплейная система часто принимает на вход информацию, которую должна подготовить или обновить другая. То есть, они зависят друг от друга.
К примеру, некоторые звуки воспроизводятся а зависимости от анимаций. Здесь можно вспомнить о звуках шагов. Система смены погоды зависит от игрового времени. Передвижение игрока зависит от системы, обработавшей сигнал с устройства ввода. Как итог — все системы переплетены друг с другом. Именно поэтому их желательно выполнять в определенном порядке.
Нарушение порядка выполнения систем
Что случится, если мы решим пренебречь порядком? Давайте представим, что работаем с игрой, в которой есть экосистема, растения и их состояния. Последние согласуются с временем суток и погодными условиями. Дождь способствует их росту, а продолжительная знойная погода уменьшает здоровье, пока растение не засохнет. Погода меняется каждый игровой час.
Текущая ситуация: 13:59 игрового времени, жуткий зной, у одного из растений осталось мало единиц здоровья и оно скоро высохнет. Наступает время симулировать следующий тик игры. Мы запускаем параллельную симуляцию трех игровых систем: времени, погоды и состояния растения.
Так как выполняем системы синхронно, мы не знаем, выполнится ли сначала просчет погоды, а затем пересчет игрового времени, или наоборот. Каждый раз порядок будет новый, случайный.
Допустим, что в текущий тик потоки выполнились так, что сначала посчиталась погода. Она синхронизировалась с игровым временем (которое еще не успело измениться) и осталась прежней, т. к. игровой час еще не прошел. Через мгновение временной поток успел изменить время на 14:01. Однако для последнего потока, в котором решается судьба растения, это уже не будет иметь значения — т. к. зной продолжился, у растения ушел остаток едениц здоровья и оно высохло.
Все было бы иначе, если бы сначала изменилось время, затем — погода, а в конце — посчиталось состояние растения. Мог бы наступить легкий летний дождь— и растение бы продолжило рост. «Но ведь здесь максимальный лаг между системами составит всего один тик!» — скажете вы и будете правы. Это не самая большая проблема. Хуже то, что мы сделали поведение игры недетерминированным.
Теперь из раза в раз одни и те же условия могут приводить к разным результатам. А если у нас возникнет баг, связанный с определенным порядком выполнения игровых систем? Воспроизведение и дебаггинг в этом «многопоточном клубке» будет практически невозможен.
Преимущества многопоточности в геймплее
И что же, в геймплее нет многопоточности? Разработчики игровой логики действительно сталкиваются с многопотоком крайне редко. По той же причине, например, Blueprints в Unreal Engine работают исключительно в главном потоке.
Однако в геймплее вполне могут быть потоки. Никто не запрещает их использовать человеку, который занимается разработкой игр. Начнем с наиболее очевидного обличия многопотоков в игровой логике.
ECS
Про ECS (Entity Component System) написано очень много материалов. За время существования появилось множество предубеждений. Может показаться, что ECS в игровой индустрии — это стандарт де-факто, а в серьезных движках он используется по умолчанию. На самом деле это не совсем так.
Что такое ECS? Если вкратце, то это архитектурный паттерн, разработанный специально для создания игр. Он часто используется для описания динамического игрового мира. В подробности углубляться не будем, но вкратце рассмотрим разницу между ECS и классическим component-based подходом.
Как правило, в Unreal Engine или Unity ваши игровые сущности — это «актеры», к которым прикреплены компоненты с логикой и данными:
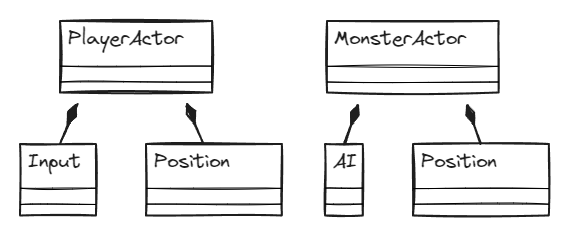
Обрабатывается все движком в функции update примерно на следующий манер. Здесь вместо C++ разберемся на примере псевдокода:
func update(dt):
for actor in scene.actors:
for component in actor:
component.update(dt);
Теперь рассмотрим ECS. На архитектурном уровне сущности представлены сложнее:
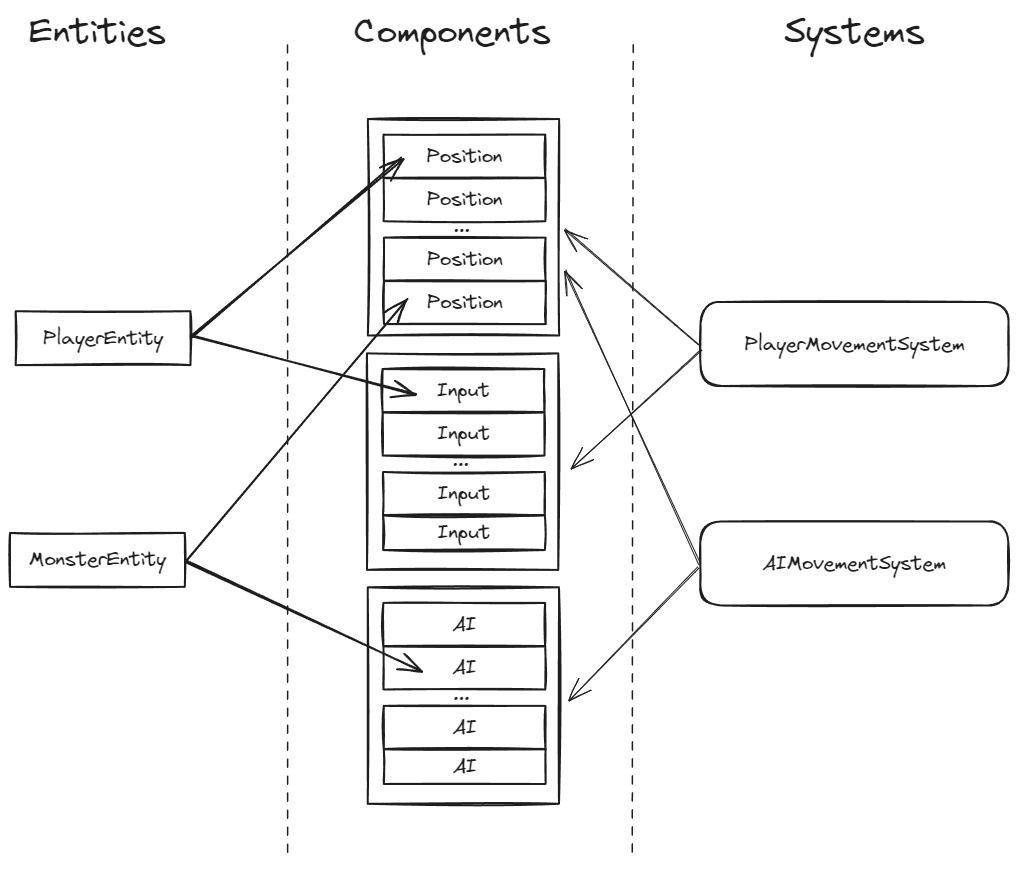
Актеров нет — вместо них есть сущности (entities). По смыслу они похожи, потому что за сущностью закреплен набор компонентов, на которые она ссылается. Но ECS-компоненты (components), в отличие от компонентов из предыдущего примера, не имеют логики — только данные. За логику отвечают системы (systems), а обработка выглядит примерно так:
func update(dt):
for system in ecs.systems:
for entity in ecs.getAllEntitiesFor(system):
system.update(entity.getComponents(), dt);
Например, система AIMovementSystem, когда дойдет очередь до ее обновления, возьмет все сущности в игре, у которых есть компоненты AI и Position, и просимулирует их разом.
Где потоки? Пока мы их не видим, но так как системы (поведение) отделены от компонентов (данных), у нас есть простор для параллельного выполнения. Разработчики ECS-систем зачастую позволяют распараллелить симуляцию систем по двум направлениям:
- каждую систему можно обрабатывать параллельно (внешний цикл for),
- каждый набор компонентов можно обрабатывать параллельно (внутренний цикл for).
Почему мы не могли так же распараллелить два цикла for из псевдокода для component-based подхода? В этом и вся суть. Могли бы, но, вне влияния подходов, будь то EC или ECS, у нас остаются зависимости и глобальное состояние. В итоге распараллеливание оказывается очень ограниченным.
У ECS есть явная информация о зависимостях между системами и о том, каким системам требуются общие компоненты, а у каких пересечения по компонентам отсутствуют. Если зависимости нет, как и пересечений по необходимым компонентам, — у нас есть поле для маневра и распараллеливания. Разработчики ECS такие случаи, как правило, пытаются распараллелить на разные потоки.
Но стоит нам создать правило, что перемещения должны рассчитываться после input, как возможности распараллеливания внешнего цикла for (перебирающего системы) резко упадут. А иногда и вовсе исчезнут. К тому же мы не можем параллельно запустить две системы, если им нужен хотя бы один общий компонент.
Распараллеливать внутренний цикл for, который перебирает сущности в рамках одной системы, тоже непросто. Это возможно только в том случае, когда система не связана с уникальными ресурсами в игре.
Но зачем тогда существует ECS, если его не применить? Проблема немного в другом: использовать его следует в других направлениях. Многопоток — это не ключевая киллер-фича ECS, а скорее приятный бонус.
Основная выгода ECS хорошо видна на схеме выше — обратите внимание на аккуратное расположение компонентов в памяти. Так же стройно и аккурадно они распределяются в кэш. В итоге мы получаем быстрый cache-friendly подход, при котором и фиксируется основное ускорение на процессор.
Некоторые реализации ECS-архитектуры могут отличаться, а компоненты в памяти располагаться иначе. Например, в archetype-based реализациях ECS. Подробнее можно прочитать на странице Entity Component System FAQ.
О ECS в движках на практике
ECS — это передовая технология. Однако игровые движки чаще всего предлагают ECS-решения как дополнение. Их применяют, когда программисты упираются в производительность при работе с большим количеством объектов. Unity может предложить DOTS, а Unreal — Mass Entity.
Движки, которые строятся строго вокруг ECS-подхода, — редкость. Примеры — Bevy и Amethyst. Оба движка на Rust. Но и тут проблема: второй проект был свернут несколько лет назад, а его команда посоветовала переходить Bevy.
Противоположный пример — Godot. Проект открестился от подхода ECS и опубликовал статью о том, почему ECS не используется и не будет использоваться в движке Godot.
Тяжелые вычисления
Продолжаем поиск многопоточности в играх. Рассмотрим более специфичные алгоритмы, которые подходят, как правило, только для конкретных ситуаций. Обычно это касается фоновых задач, где нужно произвести ресурсозатратные вычисления.
К тому же тут не должно быть существенных зависимостей от глобального состояния игры. Задача разбивается на несколько независимых подзадач, которые можно выполнить параллельно, чтобы затем объединить результаты.
Следует понимать, что речь о частных кейсах. Здесь не может быть общих рекомендаций и практик о том, как грамотно встроить распараллеливание на разные потоки. То, как разработчикам нужно будет синхронизироваться с остальным геймплейным кодом, сильно зависит от ситуации. Применяться могут различные логики решений.
Необходимо читать данные из глобального объекта, но нужно избежать борьбы между потоками за общую информацию? Возможное решение — скопировать срез данных на момент запуска потоков. Чаще всего это доступный сценарий. Вдобавок он избавит команду разработки от бремени синхронизации между потоками.
Необходимо, чтобы потоки и читали из глобального объекта и писали в него? Но при этом без data-races и крупных накладных расходов на синхронизацию? Тогда следует приглядеться к lock-free структурам данных. Подход нельзя назвать легкодоступным, однако он крайне эффективен в подобных ситуациях.
Допустим, C зависит от B, а B — от A, но всех их нужно запустить параллельно? Возможное решение — распараллелить сами A, B и C, т. е. параллельно запустить A1, A2 и A3.
AI-задачи в RTS и пошаговых стратегиях
В пошаговых стратегиях ходы AI-противников — это довольно ресурсозатратный процесс. Зачастую их просчет занимает много времени. В той же «Цивилизации» ход противников может занимать десятки секунд.
Разработчики пытаются минимизировать время хода компьютера. В первую очередь это реализуется за счет параллелизации всего, что только возможно. Здесь активно используются потоки.
Процедурная генерация
Генерация мира — еще один тяжеловесный процесс, который можно выполнить в многопоточном режиме. Но тут все зависит от конкретной игры и ситуации. Рассмотрим на примере.
Допустим, у вас условно бесконечный игровой мир как в Minecraft. Тогда вы можете в фоновом режиме генерировать следующую часть мира, если пользователь подходит к краю существующих чанков. Тогда, если игрок резко устремится еще дальше в неизведанную часть, он ощутит торможение от резкой генерации контента.
Maintenance
В онлайн-играх время от времени могут проводиться maintenance — служебные процессы любого характера, которые предназначены для починки, очистки, оптимизации игрового мира. Сюда можно отнести:
- сбор и удаление предметов;
- сброс состояний NPC;
- прирост ресурса, который можно фармить;
- оптимизацию построек, окружения;
- перерасчет навигационных сеток (NavMesh);
- проводку денежных операций — как внутриигровой валюты, так и операций с монетизацией.
Сюда же могут быть встроены различные фичи, которые предотвращают игру от поломки или чрезмерного потребления памяти. На этом этапе могут чиниться (или пытаться) игровые объекты, которые по любой причине вошли в некорректное состояние.
Maintenance-операции желательно выполнять на фоне в отдельном потоке. Важно не отнимать процессорное время главного потока, который занимается основной симуляцией игры.
Игра или движок
Как понять: речь об игре или о движке игры? Все это время мы говорили о геймплейном коде и старались не обсуждать то, что под капотом делает движок. Но фактически едва ли возможно провести четкую границу между первым и вторым. Исполняемый файл, который вы запускаете, чтобы поиграть в игру, содержит машинный код и движка, и геймплейного кода, написанного на этом движке.
Почему граница нечеткая? К примеру, в Unreal Engine можно создавать собственные компоненты для актора, специфичные для вашей игры. Однако движок предоставляет обширный набор из опций и компонентов общего назначения, которые его разработчики уже заботливо создали за вас.
Та же ситуация с ECS (Entity Component System). Допустим, вы пишете игровые системы. Однако базовые, к примеру Movement или TransformHierarchy, уже присутствуют в движке. Однако мы можем определить части, которые точно являются движком, а не геймплеем, и наоборот. Рассмотрим схему устройства игрового движка, описанную Джейсоном Грегори. Подробнее с ней можно ознакомиться в книге Game Engine Architecture:
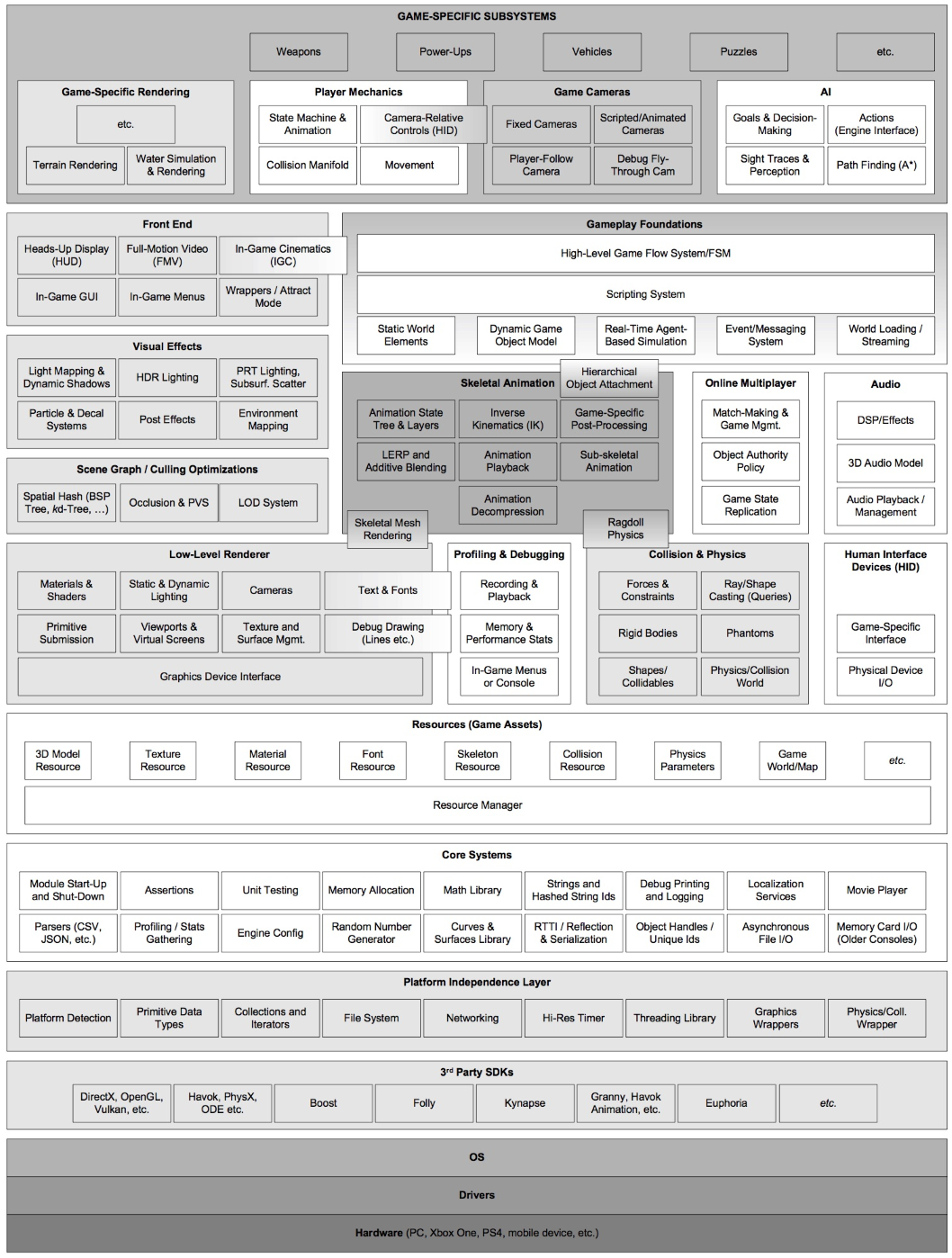
При этом технически к игре можно отнести только верхний уровень абстракции — Game-Specific Subsystems. Подводная же часть айсберга — это игровой движок, на котором строятся все процессы.
На схеме можно заметить еще один низкоуровневый, но ключевой элемент — Threading Library. Он предоставляет удобные платформо-независимые механизмы управления потоками. Threading Library здесь совсем не случайно — чаще всего код игрового движка обширно использует потоки, в отличие от геймплейного кода.
Как правило, потоки в движке создаются заранее в определенном количестве, образуя Thread Pool. Изначально все они ждут «в сонном режиме», пока не потребуется многопоточность. Но почему так происходит? Создание и удаление потоков — дорогостоящие процессы, которые загружают операционную систему. Чем их будет меньше — тем лучше.
Еще одна частая практика — строить поверх пулл потоков систему из Task или Job. Она позволяет абстрагировать процесс и сформировать запрос вида: «Выполнить фрагмент кода в отдельном потоке». Система сама активизирует один из потоков в пулле. Рассмотрим некоторые типовые процессы в движке, в которых можно применить потоки.
Аудио
Аудио-рендер легко вынести в постоянно работающий отдельный поток. Как правило, от результата выполнения системы аудио не зависят остальные процессы. В этот поток направляются звуки, которые нужно воспроизвести, а дальше все обрабатывается в фоновом режиме.
Физика
В отличие от аудио, физике необходима синхронизация с игровой симуляцией и рендером. Однако физические расчеты — одни из самых накладных, так что вычисления физического движка часто выносятся в отдельный поток.
Физический движок работает в два этапа. Во-первых, он ищет столкновения объектов (коллюзии). Далее — разрешает каждое столкновение, определяет новые скорости и направления для столкнувшихся объектов. За этот процесс отвечает solver.
Второй этап можно модернизировать и запустить множественные потоки для каждого solver. Так они будут вычисляться параллельно. Затем движок дождется выполнения всех потоков. Настанет фаза синхронизации с игровой симуляцией.
База данных
База данных (БД) — еще один кандидат на работу в отдельном потоке. Запрос в базу может быть ресурсоемким, но он не должен блокировать основной поток. БД — зачастую важный ресурс, который должен быстро обрабатывать запросы и не испытывать помех.
Для онлайн-игры, например MMO, основная БД — это аналог сохранения в одиночной игре. Оно объемное, требует много ресурсов и критически важно для работы всей игры. Именно поэтому разделение основного потока игры и потока базы данных — распространенная практика.
Интересно, что с точки зрения игрового кода операция чтения из БД обходится дороже, чем запись в нее. Во втором случае информация сразу отправляется в соответствующий поток. При чтении данных из базы сперва отправляется запрос, который затем отрабатывается. Далее — ожидание перехода данных в главный поток.
Сервер-клиент
Вернемся к теме онлайн-игр. Разработка с использованием клиент-серверного подхода кардинально отличается от создания обычных одиночных игр. В последних обычно используется одно приложение, которое запускается на компьютере или консоли игрока.
В случае с онлайн-играми применяется другой подход: существует один сервер (но чаще всего их больше) и множество клиентов, которые подключаются к нему со своих устройств. Код игры теперь разделяется на две части. Первая — сервер, оригинал игры, но без рендера, графического интерфейса и вводных данных. Вторая — клиент, включающий в себя рендер, графический интерфейс и input.
Клиент полностью зависит от сервера, который сообщает ему о том, что происходит в игре. Любые самостоятельные действия клиента, связанные с геймингом — «спекуляции». Он может лишь предполагать или догадываться.
При этом сервер — это не только оригинальная симуляция игры. Не стоит забывать о его прямом назначении — приеме и обслуживании подключения от клиентов. Способ, которым сервер обрабатывает эти процессы, зависит от конкретной реализации.
Один из самых простых подходов — создание потока для каждого отдельного подключения. На практике это не всегда эффективно, поскольку потоков может не хватить на всех клиентов. Однако в случае клиент-серверных связей многопоточность может быть полезна. Особенно многопоток актуален при большой нагрузке на сервер.
Логирование
Процесс логирования похож на аудио-рендеринг. В обоих случаях данные записываются в подсистему, но никто их не читает. Мы добавляем информацию в лог и забываем о ней. А специальный модуль (логгер), который выполняется в отдельном потоке, автоматически обработает данные. К примеру, добавляет запись в буфер; в нужное время чистит его (flush) и записывает информацию на диск, в БД, отправит их по сети и т. д.
Рендер
Практически всегда есть выделенный рендер-поток, в котором формируется следующий кадр изображения и происходит взаимодействие с GPU. Рендер, как и физика, должен в определенный момент синхронизироваться с симуляцией игры, которая выполняется в основном потоке.
GPU
Когда мы говорим о многопоточности, в большинстве случаев имеем в виду ядра процессора. Однако в видеокартах тоже есть ядра, причем их в сотни раз больше, чем ядер CPU.
Рассмотрим на примере процессоров AMD Ryzen™ 7000 серии. Они имеют чиплетное строение. В каждом — IOD-чиплет с контроллерами интерфейсов и CCD-чиплеты с ядрами. Один CCD-чиплет содержит до восьми ядер c поддержкой технологии Simultaneous Multithreading (SMT®). У флагманского процессора AMD Ryzen™ 7950X — два ССD, в каждом из которых по восемь ядер. В сумме — 16 ядер и 32 потока.
SMT® увеличивает количество потоков, которое может обрабатывать каждое ядро. Таким образом, улучшается общая производительность системы в многопоточных приложениях. Аналог технологии SMT в процессорах intel® — Hyper-Threading.
На GPU количество ядер исчисляется тысячами. Можно сказать, что видеокарты — это синоним многопоточности и параллелизации. Зачем видеокартам так много ядер? На них выполняются шейдеры.
Шейдерный код — это код, который должен быть одновременно выполнен для каждого фрагмента. Это суждение касается фрагментных шейдеров, но бывают и другие типы. Для любого шейдера неизменно одно — он выполняется видеокартой параллельно для каждого фрагмента, верстка, треугольника и т. д.
Написание шейдерного кода сильно отличается от CPU-разработки. Важно написать один код так, чтобы он выполнился для каждого фрагмента, а результат получился осмысленным и разным.
Также существует compute shaders — шейдеры для произвольных, неграфических вычислений. Они позволяют выполнять на GPU работу, которая обычно выполняется на CPU. При этом мы получаем многократный профит благодаря большому количеству ядер. Это особенно полезно при майнинге, где GPU справляется значительно лучше CPU из-за большого количества ядер.
И многое другое
Игровой движок найдет применение потокам и систем, в которых в той или иной степени используется многопоточность. Мы рассмотрели основные сценарии, но их еще много. Некоторые нам только предстоит увидеть в будущем.
Чек-лист о многопоточности
Поделимся небольшим чек-листом и интересными наблюдениями о многопоточности в играх.
- Потоки в играх не всегда находятся там, где кажется изначально.
- Многопоточность не всегда делает код быстрее. Иногда может стать хуже, чем было в однопоточном варианте.
- В ваши игры с большой вероятностью станет играть комфортнее, если при перейти на процессор с большим количеством ядер. Но прирост FPS не будет пропорционален приросту ядер. Производительность некоторых игр и вовсе останется на том же уровне, что и прежде.
- Видеокарты решают многое. Большая часть многопоточности — в них.
- Задачи разработчиков игровой логики чаще всего не выходят за пределы основного потока.
- Задачи разработчиков игрового движка часто выходят за пределы основного потока.
- Зачастую большая часть исполняемого файла с игрой — код игрового движка, а не самой игры.
- C какой интенсивностью ваша итоговая программа будет использовать многопоточность — по большей части определяет движок.
- Сервер MMO-игры с большей вероятностью выиграет в приросте ядер у CPU, чем PC с однопользовательской игрой. Это обусловлено тем, что серверу нужно справляться с существенной нагрузкой от большого количества клиентов.




