

Введение
Рынок машинного обучения стабильно развивается уже около десяти лет, но особенно динамично — в последние годы. ML внедряют в коммерческие продукты, государственные сервисы и отраслевые платформы. Наибольшее распространение получили модели компьютерного зрения (CV), обработки естественного языка (NLP) и рекомендательные системы.
При этом ML все чаще используется в критически важных процессах и системах: автономном транспорте, средствах обнаружения киберугроз, промышленной автоматизации, медицинской диагностике и клинических решениях. Ошибки моделей в таких сценариях могут приводить к серьезным последствиям — от угрозы здоровью до финансовых потерь и репутационного ущерба. Это повышает требования сразу к нескольким аспектам:
- безопасности данных на всех этапах ML-цикла,
- достоверности моделей,
- устойчивости и контролю при эксплуатации.
По данным Statista, объем глобального рынка ML-технологий достигнет 105 млрд долларов США в 2025 году. А при среднегодовом темпе роста около 32%, к 2031 году объем превысит 560 млрд долларов.
Высокие темпы роста подтверждают: машинное обучение становится инфраструктурной технологией. Инвестиции, появление новых продуктов и кадровый рост усиливают присутствие ML в критически важных системах.
В России также растет институциональный интерес к ML: на момент написания статьи зарегистрировано уже более 50 решений на базе ИИ, а внедрение ИИ в медицине поддерживается на государственном уровне. В стратегии развития здравоохранения до 2030 года создание медицинских систем с использованием ИИ-технологий обозначено как приоритетное направление.
Но стремительный рост доли ML в чувствительных областях приводит к очевидному выводу: классических подходов к безопасности уже недостаточно. Нужны практики, которые охватывают весь жизненный цикл ML: от данных и обучения до развертывания и мониторинга. Для решения этой задачи уже есть MLSecOps — направление, ориентированное на построение надежных и доверенных ML-систем.
Что такое MLSecOps
Для начала важно отметить, что традиционные подходы к безопасной разработке ПО по-прежнему важны. Они учитывают специфику мобильных и веб-приложений, десктопных и серверных систем и даже прошивок. Однако при работе с ML-системами их оказывается недостаточно: специфика машинного обучения вносит новые уязвимости, связанные с данными, особенностями работы моделей, алгоритмами и инфраструктурой.
Ответом на эти вызовы стало формирование специализированных практик, ориентированных именно на риски ML-цикла. MLSecOps — это инженерная дисциплина, интегрирующая принципы информационной безопасности в процессы MLOps. Ее цель — обеспечить не просто «рабочую», а доверенную ML-систему: с контролем целостности данных и моделей, воспроизводимостью результатов, защитой от манипуляций на этапе обучения и предсказуемым поведением в эксплуатации.
Если хотите детальнее изучить дисциплину MLOps, мы подробно разобрали ее в отдельном материале.
Одна из причин актуальности MLSecOps в том, что угрозы безопасности, которые возникают на одном этапе жизненного цикла модели, могут быть обнаружены или нейтрализованы только на другом этапе. Это требует тесного взаимодействия команд, которые работают с данными, DevOps-инженеров, специалистов по эксплуатации систем ML-моделей и команд информационной безопасности.
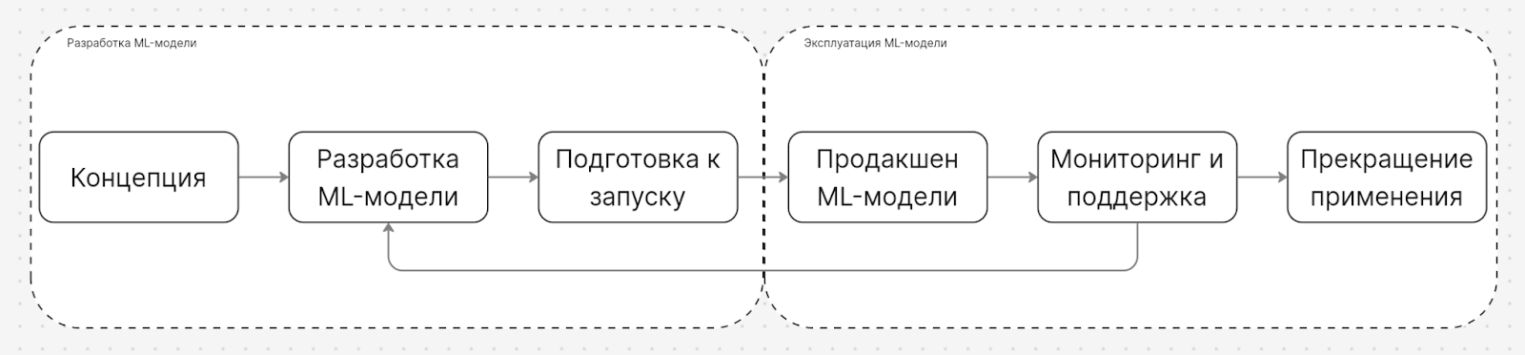
Компаниям, которые разрабатывают ML-системы, крайне важно обеспечивать конфиденциальность, целостность и доступность данных, а также надежность и воспроизводимость решений ML-модели.
Появление термина и связь с MLOps и DevSecOps
К этому моменту у вас, вероятно, возник вопрос: почему появилось отдельное направление MLSecOps, если, например, мобильные, веб- и серверные приложения не выделяются из DevSecOps? DevSecOps описывает безопасную разработку и доставку кода, а MLSecOps расширяет эту парадигму на обучение и управление датасетами. Помимо прочего, появляется новый артефакт — обучающая выборка, поэтому ML-решения требуют расширенного набора практик.
Важно отметить, что вопрос о терминологии — дискуссионный. В одних компаниях практика MLSecOps встроена в DevSecOps, в других — выделена в отдельные группы с разными названиями. Фокус при этом остается неизменным: построение надежных и доверенных ML-систем.
Что под термином подразумевают сегодня и почему «простого переноса» DevSecOps недостаточно
Рассмотрим типичную ситуацию, которая показывает, почему «простого переноса» DevSecOps недостаточно. В чувствительных областях ML-сервисам требуются возможности аудита и трассировки решений на уровне алгоритмов. Командам нужны инструменты анализа поведения конкретных классификаторов: какие внутренние состояния могли привести к ошибке и какие компоненты участвовали в принятии решения.
Соответственно, требования к мониторингу в ML-среде шире, чем в «мире классических приложений». Система мониторинга должна фиксировать:
- время последнего обучения или дообучения модели;
- метку времени последнего обновления датасета, использованного для обучения/дообучения;
- веса и уровни уверенности ключевых классификаторов, которые используются для принятия особо чувствительных решений;
- компоненты и подсистемы, которые участвуют в принятии решения;
- окончательное решение модели.
Поддержка такого уровня наблюдаемости требует дополнительных компетенций от ИБ-специалистов и более плотного взаимодействия участников MLSecOps-процессов.
Виды атак на ML-решения
Анализ атак на ML-системы остается сложной задачей, находящейся на стыке прикладной инженерии и исследовательской работы. В отличие от классического ПО, поведение ML-решений в значительной степени зависит от архитектуры модели, характеристик обучающих данных, способа обучения и домена применения. Из-за этого сложно говорить о едином универсальном подходе к MLSecOps, применимом одновременно к таким разным областям, как компьютерное зрение, системы поддержки принятия решений или GenAI-приложения.
Атаки на целостность данных (Data Poisoning)
ML-системы критически зависят от данных обучения. Если злоумышленник изменяет обучающий набор — целенаправленно или случайно — это может привести к деградации качества модели или к внедрению скрытых триггеров для последующего обхода. Это явление известно как отравление данных (data poisoning).
Типичные цели атак:
- ухудшить качество модели;
- внедрить backdoor-триггеры;
- изменить распределение данных и вызвать дрейф.
Дрейф окружения — это изменение компонентов среды ML-пайплайна (версии фреймворков, библиотек, драйверов, параметров окружения, конфигурации инфраструктуры), которое приводит к изменению поведения модели при неизменных данных и алгоритмах.
Кража обученных моделей (Model Extraction)
Часто обученная модель сама по себе является ценным активом компании. Злоумышленники, а иногда и конкурирующие организации, могут пытаться анализировать ее или использовать уязвимости.
Цель здесь — не вредоносные действия в привычном понимании, а полное копирование модели. В результате кражи злоумышленник (или конкурент) получает функционально схожую модель без затрат на сбор данных и обучение.
Состязательные атаки (Adversarial Attacks)
Состязательные атаки основаны на том, что небольшие, зачастую незаметные для человека изменения входных данных приводят к неверному ответу модели. Рассмотрим основные типы состязательных атак.
Evasion-атаки — когда на вход модели подаются искаженные данные. Частый пример — дорожный знак с наклейкой, который распознается с ошибкой, и вместо знака STOP (движение без остановки запрещено) модель видит знак ограничения скорости.
Backdoor-атаки — это внедрение скрытого триггера на этапе обучения модели. В результате модель ведет себя корректно в большинстве сценариев, но при появлении определенного триггера начинает выдавать предсказуемо неверный результат. Например, ML-модель, проверяющая файлы на наличие вирусов, может пропускать файлы с определенной контрольной суммой, если такой триггер был заложен на этапе обучения.
Получение доступа к серверам, используемым для обучения модели
Обучение ML-моделей требует высокопроизводительной инфраструктуры, которая часто остается доступной в течение длительного времени и обладает значительными вычислительными ресурсами.
Это делает такие серверы привлекательной целью для злоумышленников — в том числе для несанкционированного использования ресурсов, например, скрытого майнинга. Что могут атаковать злоумышленники в первую очередь:
- серверы с GPU;
- фреймворки для обучения и разворачивания (инференса) ML-моделей;
- CI/CD ML-пайплайны;
- хранилища датасетов и артефактов моделей.
Ситуацию усугубляет то, что в некоторых популярных ML-фреймворках базовые требования к безопасности либо отсутствуют, либо требуют ручной настройки. По результатам исследований это уже приводит к тому, что десятки тысяч ML-моделей по всему миру оказываются доступны без надлежащего контроля доступа — в отдельных оценках речь идет о более чем 100 000 моделей.
На инфографике ниже — пример масштабов проблемы безопасности ML- и LLM-инфраструктуры: в открытом доступе были обнаружены десятки тысяч «забытых» и незащищенных ML- и LLM-моделей, доступных из интернета. В ряде случаев исследователям удалось получить к ним удаленный доступ, что подчеркивает важность корректной настройки и защиты инфраструктуры, на которой развертываются ML- и LLM-системы.
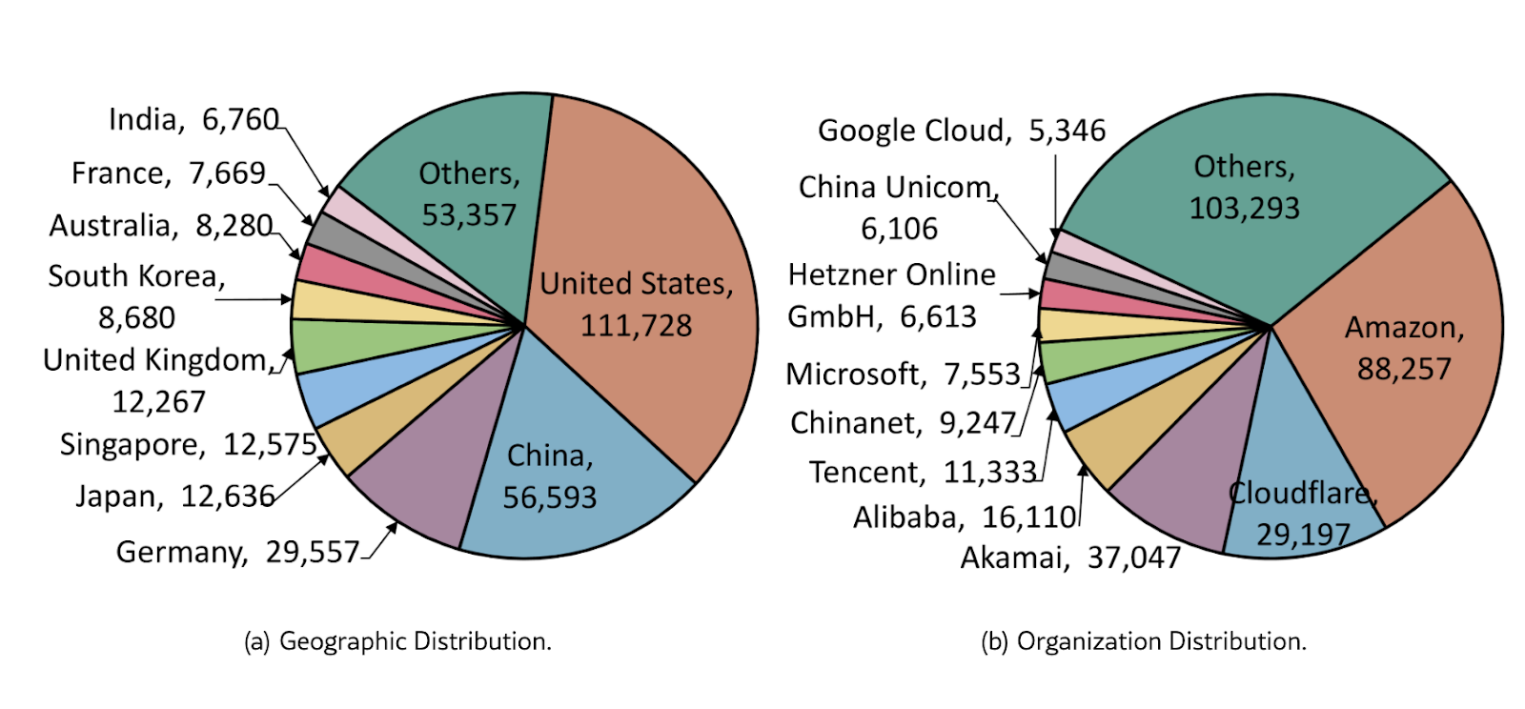
При выборе инфраструктурного провайдера для обучения и эксплуатации ML-моделей важно учитывать не только производительность, но и встроенные меры безопасности. Ключевое значение имеют возможности базовой защиты, доступные «из коробки», а также наличие продвинутых опций безопасности, которые можно включить без дополнительных задержек на закупку оборудования или внедрение сторонних решений.
Например, при проектировании ML-инфраструктуры полезно опираться на практические рекомендации по защите облачных и серверных сред. Дополнительно могут использоваться и встроенные сервисы безопасности провайдера — включая бесплатные инструменты для защиты сетей, виртуальных машин, серверов и данных, доступные в Selectel.
Этические и регуляторные риски
Использование ML в медицине, госсекторе и системах безопасности неизбежно связано с вопросами конфиденциальности, рисков предвзятости, прозрачности решений и корректного управления доступом к моделям. Эти аспекты должны учитываться как часть стратегии безопасности, а ошибочные или непрозрачные решения могут привести к юридическим последствиям.
Утечка данных, использовавшихся в обучении модели (Data Leakage)
Если при обучении ML-модели использовались недостаточно очищенные от конфиденциальной информации данные, возможны атаки на восстановление отдельных записей через:
- membership inference —определение, была ли запись в обучающем наборе;
- model inversion — восстановление отдельных атрибутов.
В реальных атаках такие методы пока встречаются редко и чаще рассматриваются как исследовательские, однако их нужно учитывать при моделировании угроз безопасности.
Подход OpenSSF
В 2025 году организация OpenSSF опубликовала практическое руководство по MLSecOps. В документе подчеркивается, что MLSecOps — не отдельная методология или замена DevSecOps, а дополнительный слой, который адаптирует существующие практики к особенностям ML-пайплайнов.
MLSecOps усиливает практики безопасной разработки приложений на тех этапах, где появляются новые артефакты (данные, датасеты, модели, веса, эксперименты) и процессы (обучение, валидация, дрейф, мониторинг качества).
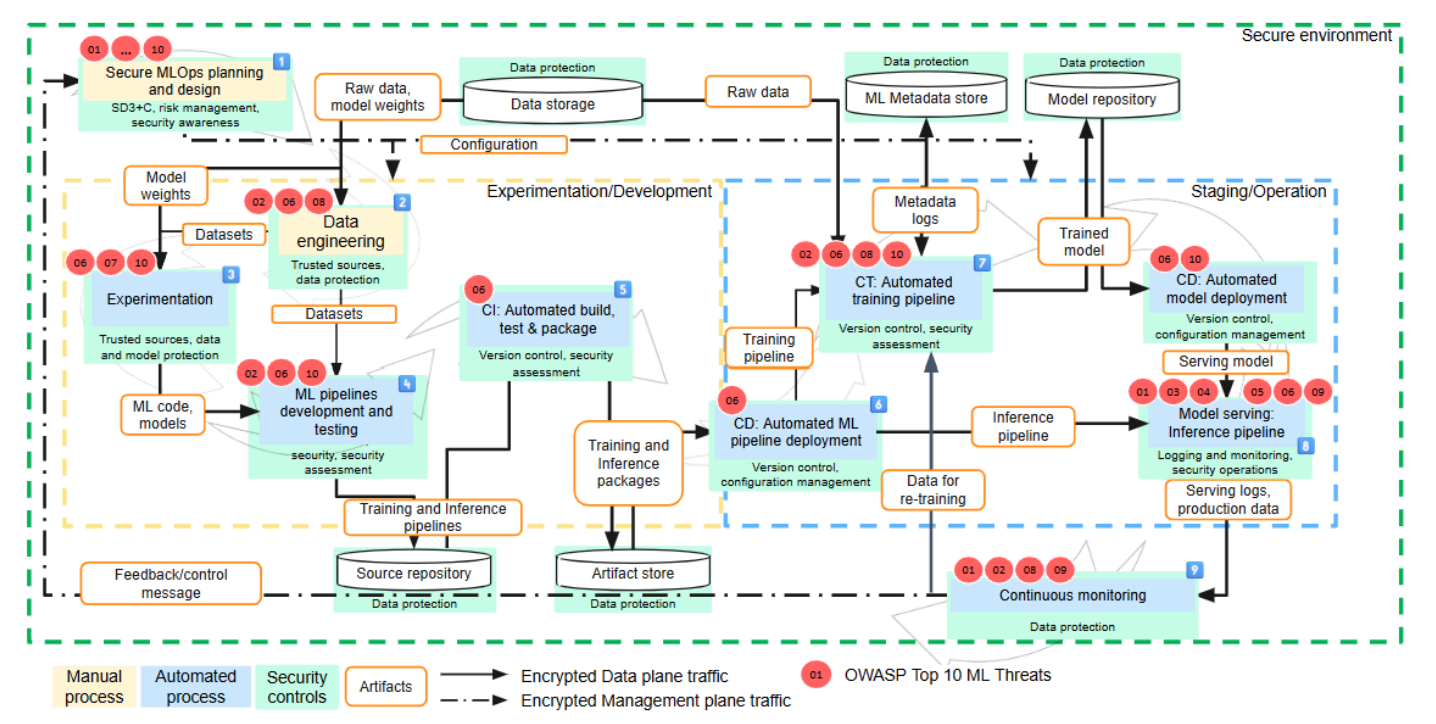
На схеме выше показано общее устройство фреймворка MLSecOps:
- выделены автоматизированные MLOps-процессы и процессы, которые требуют участия инженеров — например моделирование угроз при планировании;
- показан поток артефактов внутри ML-конвейеров;
- обозначены элементы управления безопасностью (security controls);
- определены точки, где требуется защита данных, моделей и программных компонентов.
Далее разберем ключевые элементы фреймворка подробнее.
Защита ML-моделей и инфраструктуры обучения
Защита ML-систем требует системного подхода и охватывает сразу несколько уровней: инфраструктуру, инструменты разработки, процессы MLOps включая безопасность используемых для обучения данных и самих моделей. Ошибки на любом из этих уровней могут незаметно распространяться по всему ML-пайплайну — от данных и результатов экспериментов до продуктивных моделей и приложений. По этой причине практики MLSecOps логично начинать с фундамента — безопасности инфраструктуры и среды обучения, на которой строятся все последующие процессы.
Безопасность инфраструктуры — это фундамент
Безопасность ML начинается с описания и стандартизации используемой среды разработки. Далее она развивается за счет внедрения инструментов, направленных на реализацию отдельных мер безопасности. При этом ошибки и уязвимости на уровне инфраструктуры и среды разработки могут «просачиваться» по всему MLOps-пайплайну: затрагивать датасеты, модели, артефакты экспериментов и процессы CI/CD. Важно обеспечить предсказуемость и управляемость всей платформы разработки.
Следующий важный аспект — надежность используемых инструментов. Фреймворки, библиотеки, среды выполнения и утилиты должны быть проверенными, обладать активной поддержкой и обновляться при обнаружении уязвимостей. Если такие инструменты не включены в общий процесс управления уязвимостями компании, ML-системы, как и другое ПО, со временем могут устаревать и становиться точкой входа для злоумышленников.
Не менее важно корректное разграничение доступа. Разработчикам, дата-инженерам, исследователям и MLOps-специалистам нужны разные уровни прав — от работы с экспериментами и кодом до доступа к продуктивным моделям и датасетам. Чем точнее (более гранулярно) настроено разграничение, тем проще предотвращать несанкционированные изменения моделей и данных.
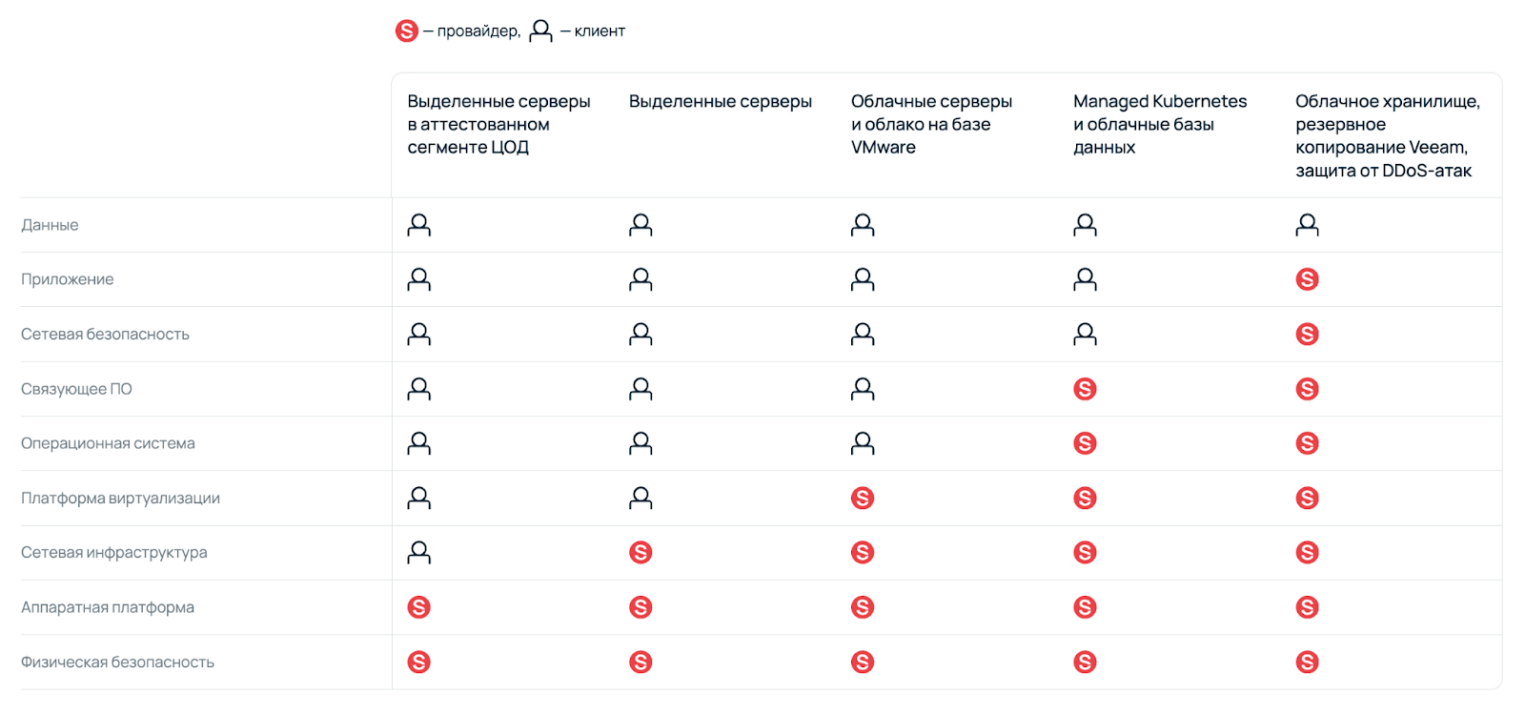
Учитывая сложность процессов, компании часто предают часть задач на аутсорсинг. Это упрощает создание контролируемого и управляемого MLOps, но в таких случаях работает модель совместной ответственности: компания отвечает за свои процессы, данные и артефакты, а провайдер — за безопасность платформы.
Например, в Selectel для каждой услуги описано разделение зон ответственности и перечень применяемых мер безопасности. Такая документация помогает выстроить корректную модель доверия между заказчиком и провайдером IT-инфраструктуры. А предоставление необходимых артефактов и договоров позволяет организовать регулярную оценку рисков и контроль мер безопасности поставщика.
Проектирование безопасной архитектуры MLOps
Основа безопасной ML-системы закладывается на этапе проектирования. На этом этапе важно понимать архитектуру пайплайна, состав его компонентов и взаимодействие участников процесса. Здесь же формируются ключевые рабочие процессы: от появления данных и проведения экспериментов до хранения артефактов обучения, верификации и развертывания моделей. Без ясного представления об архитектуре невозможно корректно встроить механизмы безопасности.
Рассмотрим пример создания ML-модели «Детектор сетевых атак», которая обнаруживает нарушителя в замкнутом контуре компании по аномалиям сетевого трафика. Так как датасеты, на которых проводится обучение и регулярное дообучение, поступают из нескольких внешних систем, это следует рассматривать как источник угроз. В архитектуре нужно предусмотреть валидацию, маркировку и проверку целостности входящих данных — иначе атаки типа data poisoning могут оставаться практически незаметными вплоть до момента эксплуатации модели, обученной на таком датасете.
Важно учитывать, что решения, принятые на этапе проектирования, напрямую определяют безопасность последующих этапов — от сбора данных до эксплуатации модели. Если требования к валидации данных, контролю целостности и изоляции источников не заложены до начала экспериментов и обучения, их последующее «добавление» становится сложным и дорогостоящим. В ML-системах архитектурные ошибки на ранних этапах часто приводят к системным рискам, таким как незаметное отравление данных и деградация качества моделей уже в промышленной эксплуатации.
Оценка рисков и определение уровня зрелости MLSecOps
Важный шаг в построении MLSecOps — определение базового уровня безопасности. Это минимальный набор мер, который закрывает ключевые угрозы и устанавливает единые требования к ML-разработке. При этом даже в одной компании этот набор может различаться от проекта к проекту. Для ориентира можно использовать модель зрелости ИИ, которую предлагает OWASP.
После этого нужно провести оценку рисков: она помогает расставить приоритеты и определить, какие процессы требуют усиления — инфраструктура, данные, обучение, деплоймент или мониторинг за уже развернутыми ML-моделями. При оценке можно опираться на доступные методологии, инструменты и справочные материалы — например, STRIDE для ML-систем, Microsoft AI Security Risk Assessment, MITRE ATLAS, OWASP ML Security Top Ten. Помимо прочего, подобные материалы активно разрабатывают и российские компании.
Подготовка наборов данных
На этапе работы с данными используют необработанную информацию, из которой формируют датасеты для последующих стадий ML-пайплайна. Именно здесь важна ранняя интеграция мер безопасности: ошибки или вредоносные записи, попавшие в датасет на раннем этапе, неизбежно отражаются на качестве модели.
Собранные данные могут включать конфиденциальные или персональные данные, поэтому для работы с ними должны быть предусмотрены правовые основания и договорные механизмы — например, согласие и/или поручение на обработку персональных данных.
Нежелательные или вредоносные данные способны повлиять на качество модели или привести к непредсказуемому поведению, поэтому при хранении и обработке нужно обеспечивать защиту данных в состоянии покоя и строгий контроль доступа к ним.
Меры безопасности на этом этапе включают обеспечение требуемого уровня защищенности данных: шифрование (при необходимости), контроль целостности, управление версиями, резервное копирование и регулярную проверку возможности восстановления.
При использовании данных из ненадежных источников эти меры должны дополняться процедурами фильтрации, удаления и маскирования данных, а также формальным согласованием условий их использования до включения таких данных в ML-пайплайн.
Качество данных напрямую определяет качество модели. На этапе разработки обучающие наборы должны дополнительно анализироваться на наличие вредоносных или подозрительных записей. В задачах, связанных с аномалиями, автоматического анализа часто недостаточно: аномалии могут быть как реальными событиями, так и следствием целенаправленной атаки.
В примере ML-модели (детектор сетевых атак), которую мы рассматривали ранее, нужно уделять особое внимание защите данных, используемых для регулярного дообучения. Если злоумышленник получает возможность генерировать или подмешивать ложные данные, это может исказить поведение модели и снизить качество детектирования реальных атак. В таких сценариях при верификации данных рекомендуется участие предметных экспертов, способных выявлять аномалии и признаки целенаправленных искажений датасета.
Исследовательский этап
В ходе экспериментов (исследовательского этапа) специалисты разрабатывают модели, подбирают алгоритмы, обучают модель и настраивают гиперпараметры. Входные данные здесь — веса модели и датасеты, а выходные — обученная модель и ML-код.
Для выявления несанкционированных изменений в результатах работы используются системы контроля версий, аудит-логи, а также механизмы контроля целостности моделей и данных, задействованных в экспериментах. Подписанные артефакты позволяют возвращаться к проверенному состоянию и выявлять попытки модификации.
Обученные модели — это интеллектуальная собственность, которая требует защиты, а обучающие скрипты и код зачастую обладают еще более высокой ценностью. При хранении, копировании и передаче модели важно обеспечивать защиту от несанкционированного изменения, например, с помощью шифрования и электронной подписи. Это одновременно поддерживает и конфиденциальность, и целостность.
Проверка моделей, разработанных на этом этапе, должна включать комплексное тестирование безопасности, включая сканирование кода.
Когда требования безопасности могут ухудшать параметры ML-модели
В чувствительных областях от ML-моделей требуется воспроизводимость. На нее влияют версии фреймворков, библиотек, драйверов, параметры окружения и конфигурация контейнеров. Изменение этих компонентов способно изменить поведение и качество ML-модели. В результате модель, обученная в «старой» среде, может демонстрировать иное поведение даже при неизменных данных и коде.
Конфликт безопасности и воспроизводимости
Специалисты по безопасности требуют своевременного обновления ПО. ML-команды, напротив, часто опасаются обновлений: они могут нарушить воспроизводимость или ухудшить качество. Возникает классическая дилемма:
- обновление повышает безопасность, но может ухудшить метрики;
- отказ от обновления сохраняет качество, но увеличивает риски безопасности.
Что делать
Если обновление критичных библиотек невозможно без риска деградации модели, ИБ-специалисты должны предусматривать дополнительные меры защиты, например:
- дополнительная сетевая изоляция среды, в которой проводится обучение ML-модели;
- мониторинг и логирование;
- контроль целостности окружения;
- дополнительное ограничение доступа.
Разработка и тестирование
Детальные рекомендации по внедрению мер безопасности зависят от уровня зрелости процессов и масштаба ML-системы. В рамках этой статьи мы не будем углубляться в конкретные реализации, а перечислим базовые практики, которые стоит учитывать при построении MLSecOps-процессов.
Модели зрелости и фреймворки. OWASP SAMM используется как базовая модель зрелости для интеграции задач безопасности в жизненный цикл MLOps.
Контроль кода и архитектуры. Code review и экспертные оценки, включая ревью ML-кода (feature engineering, data loaders, параметры обучения), а также инфраструктурного кода (IaC, Dockerfile, CI/CD).
Автоматизированное тестирование безопасности.
- SAST — статистический анализ кода, который можно применять как к ML-скриптам, так и к вспомогательным сервисам. Но есть ограничение: большинство SAST-инструментов слабо анализируют ML-фреймворки.
- DAST — динамический анализ, особенно полезный для ML-сервисов, доступных по API.
- Фаззинг-тестирование — подача некорректных, случайных или специально сформированных входных данных для выявления ошибок, а также нестабильного поведения моделей и ML-приложений.
Тестирование интеграций. Тестирование API — проверка контрактных изменений и безопасности API, особенно при взаимодействии нескольких команд и сервисов.
В процессе непрерывного обучения автоматизированный конвейер должен воспроизводить поведение экспериментальных моделей. Эталонная модель при этом должна быть защищена и подписана, что снижает риски ее ошибочных или намеренных изменений.
CI/CD и непрерывное обучение
После этапов разработки и тестирования ML-модель начинает перемещаться между средами — от экспериментальной и тестовой к продуктивной. На этом этапе ключевыми становятся процессы CI/CD и непрерывного обучения: именно здесь модели, данные и артефакты чаще всего копируются, обновляются и переиспользуются, а значит — наиболее уязвимы для несанкционированных изменений.
В циклах CI/CD модели и связанные с ними артефакты передаются между различными средами, поэтому требуется контроль их целостности. При каждом обновлении модели необходимо удостовериться, что в продуктивную среду попадает именно тот артефакт, который был проверен и одобрен ранее. Для этого применяются следующие меры:
- шифрование и контроль целостности артефактов;
- проверка цифровой подписи в целевой среде;
- управление версиями, чтобы исключить откат на уязвимую или скомпрометированную модель.
Среда сборки и доставки моделей должна быть изолирована от продуктивной инфраструктуры. Все зависимости необходимо регулярно сканировать и обновлять, а артефакты — безопасно хранить и передавать между средами. Это снижает риск компрометации моделей через уязвимые библиотеки или инструменты сборки.
Непрерывное развертывание ускоряет доставку изменений, но при недостаточном контроле и ручном управлении увеличивает риски безопасности. По этой причине зрелые MLSecOps-процессы, как правило, опираются на Infrastructure as Code (IaC) для развертывания и управления инфраструктурой. Это позволяет обеспечить воспроизводимость окружений и упростить аудит изменений.
CD-конвейер должен выполнять ряд обязательных функций безопасности:
- проверять входящие артефакты;
- обеспечивать безопасную конфигурацию среды выполнения;
- вести журналы и аудит действий;
- удалять устаревшие и неиспользуемые артефакты.
Отдельного внимания требует непрерывное обучение моделей. Регулярное переобучение на новых данных означает, что защите подлежат не только сами модели, но и:
- входящие данные;
- конвейер их обработки;
- эталонные артефакты, например предыдущие версии моделей;
- журналы, метаданные и результаты обучения.
Оценка и валидация моделей на этапе обновления должны выполняться в изолированной и защищенной среде. При этом важно отслеживать не только изменения качества модели, но и влияние обновлений на ее безопасность и предсказуемость поведения.
Red-team для ML-модели
Перед запуском ML-модели в промышленную эксплуатацию, помимо функционального и нагрузочного тестирования, рекомендуется проводить тестирование безопасности по сценариям потенциального атакующего. Такой подход позволяет выявить уязвимости, которые не проявляются при стандартных проверках.
Red-team-команды моделируют реальные атаки на ML-систему и используют специализированные инструменты для поиска уязвимостей, характерных именно для машинного обучения. В отличие от классического red-team, здесь анализируются не только сервисы и API, но и поведение модели при обработке входных данных: устойчивость к состязательным атакам (злонамеренно модифицированным входным данным), возможность обхода ограничений, влияние искаженных данных на результаты работы ML-модели.
Для этих задач существует ряд открытых фреймворков, адаптированных под различные типы ML-моделей и сценарии использования — от классификаторов до LLM-сервисов. Результаты такого тестирования позволяют скорректировать архитектуру, настройки безопасности и меры контроля до выхода модели в продуктивную среду.
При этом важно отметить, что область безопасности ML-моделей активно развивается, а использование защитных ML для повышения безопасности других моделей приводит к рекурсивному эффекту: защищающие ML-модели тоже могут стать целью атак.
Запуск в прод и мониторинг безопасности
После прохождения тестирования и red-team-проверок ML-модель переводится в промышленную эксплуатацию. Однако обеспечение безопасности на этом этапе не заканчивается: безопасность ML — это непрерывный процесс, который выходит за рамки разработки и развертывания модели.
В продуктивной среде особое значение приобретают мониторинг и контроль поведения модели. Набор мер безопасности зависит от типа ML-модели, критичности сценария применения и уровня зрелости команды. Помимо стандартного мониторинга инфраструктуры и сервисов, требуется отслеживать изменения входных данных, выходных предсказаний и метрик качества.
Для повышения уровня безопасности и управляемости в таких сценариях часто применяются дополнительные механизмы контроля, один из популярных вариантов — guardrails.
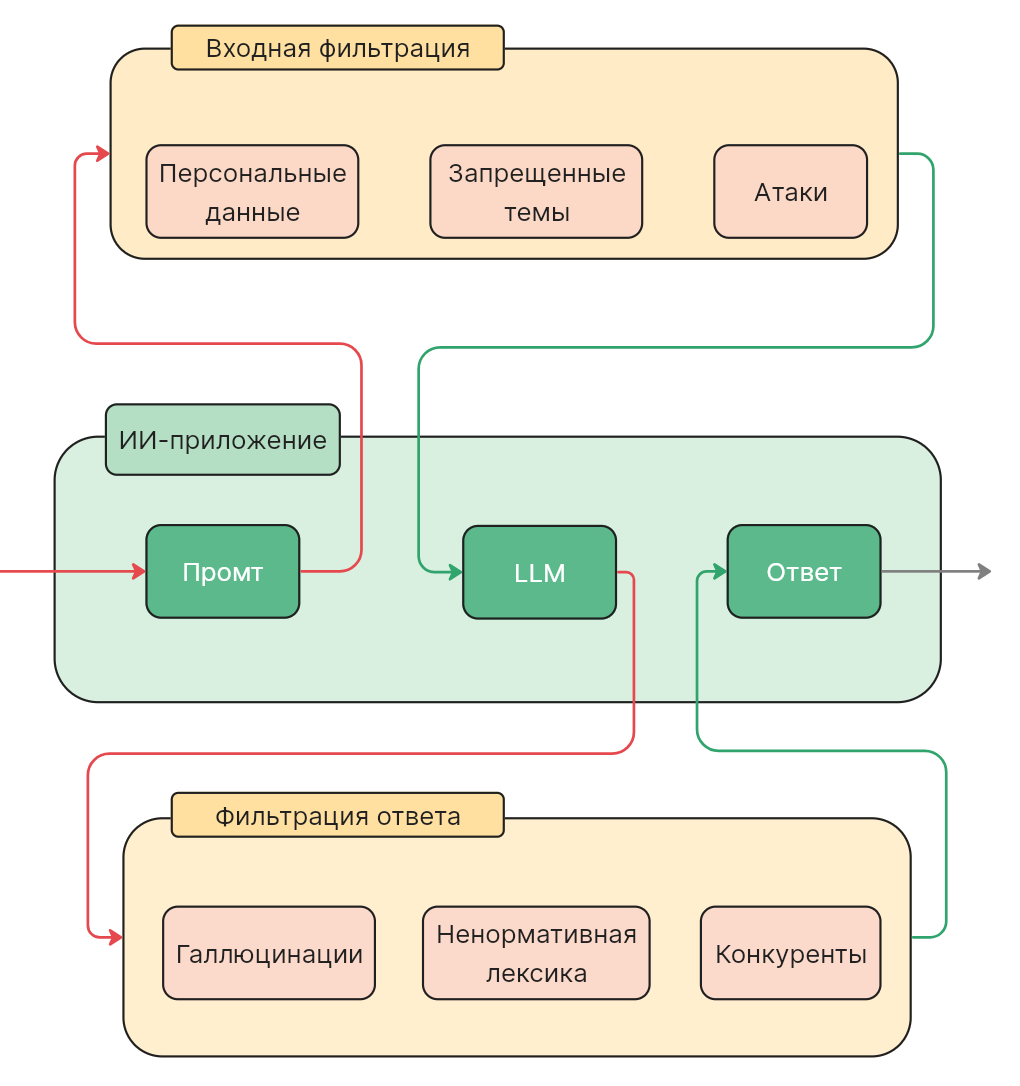
Guardrails — это дополнительные механизмы защиты, которые применяются на этапе эксплуатации ML-моделей и позволяют контролировать поток входных данных и ответы модели. Особенно широко такие подходы используются в LLM-системах, где важно ограничивать допустимые действия и предотвращать нежелательное поведение модели.
Guardrails могут выполнять следующие функции:
- анализ входных данных и блокировку потенциально опасных запросов;
- детектирование и предотвращение атак, специфичных для конкретной ML-модели;
- выявление и очистку конфиденциальных данных в ответах модели;
- контроль структуры ответа и допустимых действий или запросов.
Что нужно учитывать при создании продуктов с применением ML
Регулирование в области безопасности ML находится на раннем этапе, но развивается стремительно: появляются международные стандарты и требования регуляторов, которые напрямую влияют на процессы разработки и эксплуатации ML-систем.
В отдельном тексте рассказали, какие требования к безопасности AI-систем вводят российские регуляторы и что разработчикам стоит сделать уже сейчас.
Хорошей аналогией здесь служит эволюция автомобильной индустрии. Когда-то автомобиль можно было собрать в гараже без длительных проверок и даже ремней безопасности. Сегодня перед выходом на рынок он проходит сотни испытаний — от тестирования отдельных компонентов до краш-тестов всего решения в сборе. Аналогичная эволюция ожидает компании, которые разрабатывают ML-продукты: стандарты доверия и безопасности становятся все строже. Компании, которые начинают инвестировать в безопасность и формировать компетенции заранее, получают долгосрочное преимущество.
Чем может помочь Selectel
ML-платформа Selectel предоставляет инструменты и инфраструктуру, которые помогают реализовать принципы MLOps без излишней сложности и интегрировать управление безопасностью в жизненный цикл создания ML-модели. Речь идет не о замене MLSecOps-практик, а о снижении инфраструктурных и операционных рисков, с которыми сталкиваются команды при работе с ML.
В частности, платформа помогает:
- стандартизировать процессы обучения, тестирования и развертывания ML-моделей;
- обеспечить изолированную и масштабируемую инфраструктуру для обучения и экспериментов;
- упростить управление версиями моделей и артефактов;
- использовать шаблонизированную MLOps-инфраструктуру, снижая риск ошибок конфигурации;
- более эффективно распределять вычислительные ресурсы.
Таким образом, Selectel предоставляет преднастроенную платформу для ML-экспериментов. Это снижает зависимость от узкоспециализированных экспертов в области IT-инфраструктуры, уменьшает вероятность инцидентов и ускоряет разработку и вывод ML-продуктов на рынок.
Заключение
Безопасность ML-систем нельзя свести к классическому DevSecOps. В отличие от традиционного ПО, здесь уязвимы не только код и инфраструктура, но и данные, модели, артефакты, окружения и сам процесс обучения. Именно поэтому MLSecOps становится отдельной инженерной практикой, охватывающей весь жизненный цикл ML-модели — от сбора данных до мониторинга поведения после развертывания.
Системный подход к защите ML позволяет снизить риски от отравления данных, подмены моделей, утечек информации, некорректных ответов и деструктивных обновлений. В результате повышается надежность ML-продуктов и доверие к их результатам — как со стороны пользователей, так и со стороны бизнеса.
Инфраструктурные решения, такие как платформа Selectel, помогают закрыть часть практических задач MLSecOps: стандартизировать ML-процессы, упростить эксперименты и обучение, управлять артефактами и версиями моделей, а также эффективно использовать вычислительные ресурсы. Это не заменяет работу инженеров по безопасности, но создает необходимую основу для зрелых и устойчивых ML-систем.





