

Мы уже рассказывали, как развивалась сеть дата-центров Selectel, сетевые инсталляции и резервирование в выделенных серверах. Самое время погрузиться в мир виртуальных машин и выяснить, что такое облако с точки зрения сети.
В этой статье рассказываем, что такое IP-фабрики и как мы к ним пришли, какие коммутаторы используем и почему. Если интересно, как устроена облачная платформа на OpenStack в Selectel, читайте статью.
Ретроспектива: с чего начиналась архитектура облачной сети
Сеть облачной платформы Selectel менялась. Все начиналось с небольших инсталляций на базе классической архитектуры сети.
Классическая архитектура сети Ethernet — это архитектура, которая состоит из уровня доступа, агрегации и ядра. На базе нее строится большинство сетей для передачи данных между различными абонентами и интернетом.
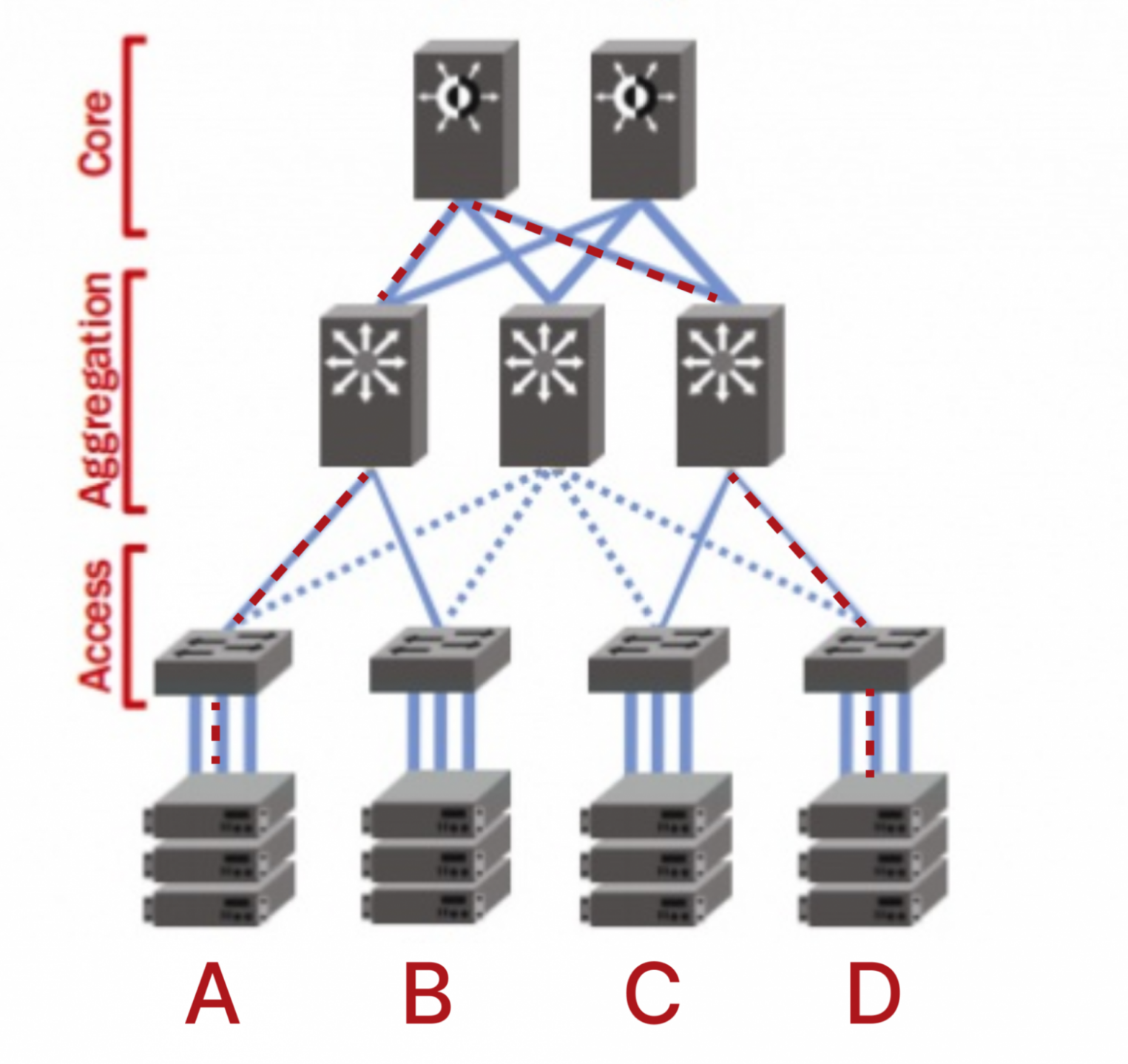
Но такая сеть рассчитана только на передачу вертикального трафика, который еще называют север-юг. Классическая архитектура спроектирована таким образом, что пакеты от сервера A могут добраться до сервера D только через ядро.
В архитектуре облачной платформы нужно передавать много западно-восточного (горизонтального) трафика между серверами. Например, данные между серверами с виртуальными машинами и серверами с дисками этих виртуальных машин, или данные между машинами должны проходить через виртуальный файрвол.
Если облако небольшое и состоит всего из двух-четырех стоек, классической архитектуры будет достаточно. Но, если облако разрастается больше, трафик постоянно будет «ходить» через ядро. Это может привести к неоптимальному пути прохождения трафика и увеличенным задержкам при передаче данных. Поэтому для облачной платформы мы решили построить сеть по CLOS-топологии.
Что такое CLOS-топология
Проблема с передачей горизонтального трафика возникла еще в 50-х годах прошлого века — но в мире телефонии. Тогда, чтобы дозвониться до соседней квартиры, сигнал от телефона должен был сделать финт через «очередь АТС». И если связь установилась через большую очередь, могли быть длительные задержки на линии. Оптимизацией подобных соединений занялся британский ученый Чарльз Клоз.
Он предложил соединить АТС в трехуровневую топологию. Но сделать это так, чтобы первый уровень был подключен ко всем АТС второго уровня. В такой схеме сигнал от одного абонента до другого проходит через фиксированное количество АТС. И неважно, какое расстояние между абонентами.

В начале двухтысячных физическая топология, которая изображена ниже, стала популярной при строительстве сетей в облачных инсталляциях. Но по сравнению с тем, что предложил Клоз, сеть как бы «свернута» по центру — генераторы и потребители трафика расположены на одном уровне.
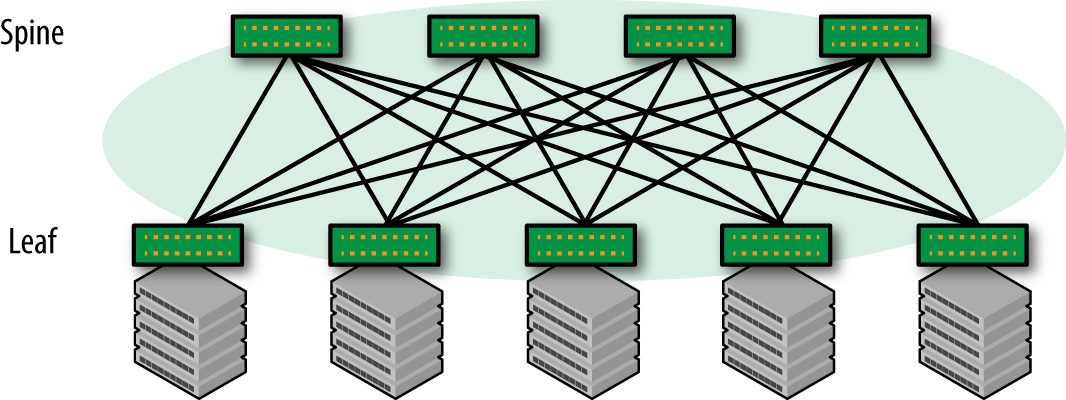
По такому же принципу мы решили организовать архитектуру сети в облачной платформе на базе OpenStack.
Как появились IP-фабрики
В 2010 году мы посмотрели на CLOS-схему, которую предлагала компания Juniper, и на ее логическую реализацию — Virtual Chassis Fabric, VCF. Максимальный масштаб VCF — 16 Leaf-коммутаторов, обеспечивающих 10 Гбит-подключения серверов, и четыре 40 Гбит Spine-коммутатора, которые могут поддерживать подключение до 784 серверов на скорости 10 Гбит/сек. В результате технология не получила дальнейшего развития и Juniper от нее отказались. Но слово «фабрика» вошло в наш обиход.
Почему именно «фабрика»?
Вообще, в дословном переводе fabric — это ткань. Как и в реальной ткани, в схеме соединения коммутаторов есть «переплетения» линков между собой: каждый коммутатор одного уровня сплетен со всеми коммутаторами другого уровня.
Кроме Juniper были и другие вендоры, которые предлагали различные решения на базе CLOS-топологии. Все они отличались логической схемой взаимодействия коммутаторов. Например, Cisco рекламировали свое решение — Cisco ACI, Brocade предлагали использовать их Ethernet-фабрики, Huawei предлагали свои решения. Но все это у нас не прижилось.
Почему мы отказались от вендорских сетей в облаке?
Чтобы идти в ногу со временем, мы постоянно увеличивали скорость передачи данных по каналам. Была цель перейти с 40 Гбит-линков на 100 Гбит, а вместо Leaf-коммутаторов с 10 Гбит-портами поставить коммутаторы с портами 25 Гбит/сек. При этом было важно сохранить обратную совместимость с предыдущим оборудованием.
Сначала мы пробовали использовать вендорские решения на базе CLOS. Но они были слишком завязаны на оборудовании, которое нельзя было «миксовать» с коммутаторами других производителей. Поэтому в результате мы перешли на стандартизованную реализацию логики построения сети — на IP-фабрики.
Откуда в названии IP?
IP — это тот протокол, который с 82 года практически не менялся. Он пополнялся фичами, функционалом, но глобальных изменений не было. В 92 году появился IPv6, но это все тот же интернет-протокол. И все оборудование, которое выпускается с 82 года, поддерживает работу с IP. Поэтому, когда мы строим фабрику, нам нужно брать оборудование, которое обеспечивает совместимость с тем функционалом, который был ранее.
Резюмируя, мы перешли на IP-фабрики по ряду причин:
- масштабирование,
- возможность установки новых моделей коммутаторов,
- обратная совместимость,
- возможность увеличения скоростей передачи данных.
Архитектура облачной сети сегодня
IP-фабрики
Сегодня IP-фабрики используются во всех продуктах облачной платформы Selectel. Они состоят из трех уровней коммутаторов — Leaf, Spine и Super Spine, который появился по мере роста сети и отвечает за возможность масштабирования облачных инсталляций.
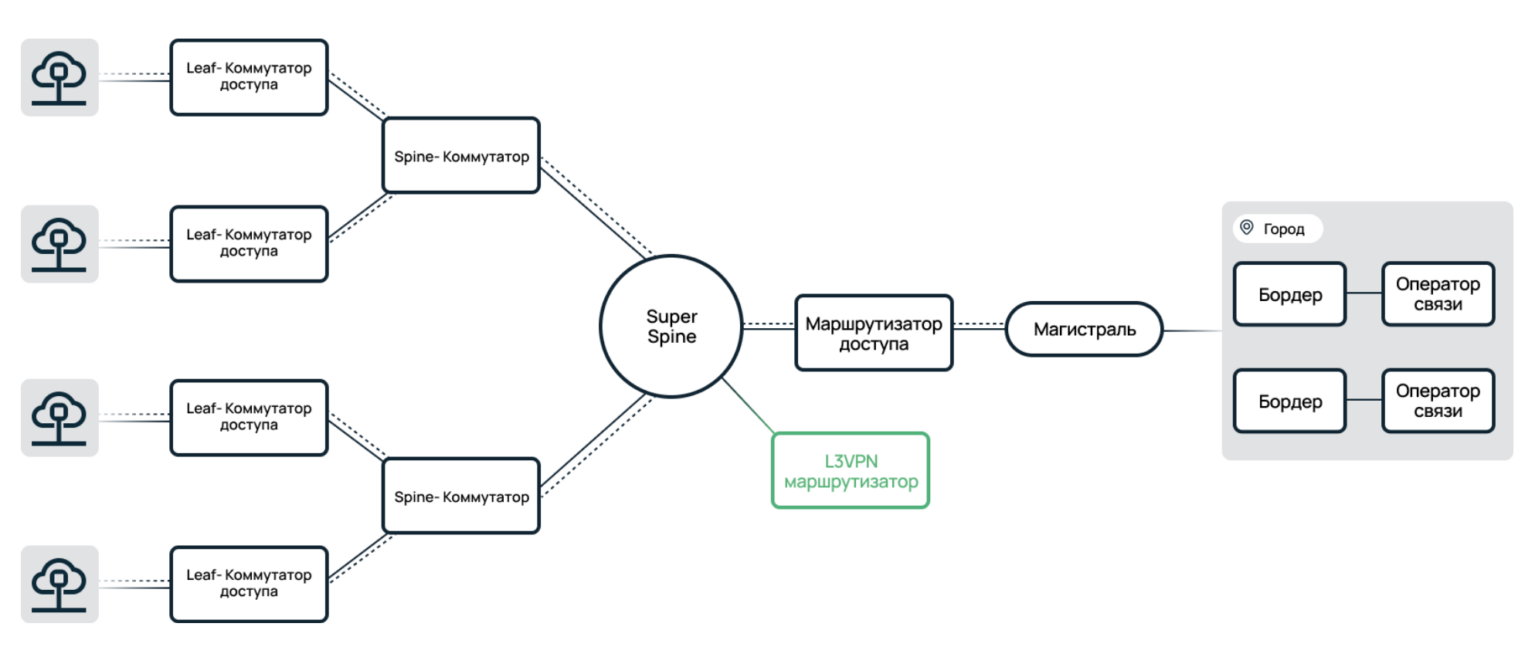
Каждый уровень фабрики «объединяет» коммутаторы на предыдущем слое. При этом все линки зарезервированы дублированием. Также на каждом промежуточном линке фабрики настроена динамическая IP-маршрутизация по BGP. Если какой-то из линков выходит из строя, динамическая маршрутизация перенаправляет трафик на другие линки.
IP-фабрики позволяют бесшовно обслуживать, перезагружать и менять софт на коммутаторах, не затрагивая облачную инфраструктуру целиком. Данная независимость коммутаторов друг от друга является отличительной особенностью IP-фабрик от Ethernet-фабрик.
Отлично — с IP-фабриками разобрались. Теперь посмотрим, какое используется оборудование, и спустимся немного ниже уровня Leaf.
Хосты виртуализации
В основании IP-фабрики — хосты виртуализации (CMP, гипервизоры), подключенные к коммутаторам уровня Leaf. Внутри каждого из них есть определенное количество процессоров, памяти и дисков, которые «нарезаются» на виртуальные машины клиентов.
По сути, хост виртуализации — это некая коммуналка, ресурсами и сетью которой пользуются сразу несколько клиентов. Однако один такой хост — это еще не облако. Облако — это полноценный дом из коммунальных квартир.

При этом к каждому хосту виртуализации подключены четыре оптических кабеля — оранжевые и бирюзовые (мы знаем, что это разные типы оптического волокна, но разделение патч-кордов по цветам позволяет уменьшить вероятность человеческих ошибок при коммутации) — и два медных — серый и красный. То есть соединение установлено не только до Leaf-коммутаторов. Разберемся, почему именно так.
Подключение хоста виртуализации

На самом деле, хосты виртуализации подключаются не в одну IP-фабрику, а в две. Одна фабрика — для NET-плоскости, которая отвечает за выход в интернет. Хост виртуализации подключается в фабрику через Leaf-коммутаторы и два оптических порта 10 Гбит и обслуживает клиентские запросы. Но чем тогда занимается вторая фабрика?
Как правило, HDD- и SSD-диски размещены на отдельных физических машинах (Storage). Чтобы организовать доступ к накопителям для виртуальных машин, мы выделили отдельные физические интерфейсы. Это сделано для предотвращения пересечений клиентского трафика, чтобы виртуальные серверы не работали с дисками через интернет, а общались в изолированной сетевой плоскости SAN. То есть хосты виртуализации связаны с Storage-нодами через отдельную фабрику, по которой передается только горизонтальный трафик.
Диски в Storage-нодах принимают от клиентских машин команды записи и чтения информации. Через вторые сетевые интерфейсы они синхронизируют друг с другом информацию и образуют кластерную систему. Получается, что диск одного виртуального сервера живет не на одном Storage-сервере, а реплицируется сразу на несколько машин.
Резюмируем: хост виртуализации подключен к двум фабрикам соответствующие Leaf-коммутаторы и четыре оптических порта по 10 (или 25) Гбит/сек. Но есть еще пара медных соединений, которая ведет в Management-плоскость.
Management-плоскость
Когда в облаке появляется много хостов виртуализации, управление виртуальными машинами делегируют на оркестратор, который может ими «дирижировать»: распределять ресурсы, обновлять квоты, запускать и отключать облачные серверы.
Чтобы все работало стабильно, мы отделили трафик управления от клиентского. Создали Management-плоскость, которая организует бесперебойное соединение с хостами виртуализации для администраторов и оркестраторов через отдельные коммутаторы.
Management-плоскость находится вне IP-фабрики и подключена к хосту виртуализации через два медных порта по 1 Гбит/сек. Управляющего трафика не так много и большая скорость передачи данных на этом уровне не нужна. IPMI-порты на серверах также подключены к коммутаторам Management-плоскости.
Коммутаторы каждой плоскости, как и линки, зарезервированы. Для их «синхронизации» между коммутаторами мы используем технологию стекирования MLAG или технологию EVPN ESI. В результате для вышестоящего устройства или подключенного сервера объединенные коммутаторы представляются одним устройством. Так мы повышаем вероятность, что пользовательский трафик пройдет по топологии сети до пункта назначения. Вдобавок это сокращает время внеплановых простоев.
Подробнее о работе MLAG и резервировании в дата-центрах Selectel мы рассказали в отдельной статье — читайте по ссылке.
Сетевое оборудование в облаке
Мы рассмотрели архитектуру облачной платформы на базе OpenStack, начиная с IP-фабрик, заканчивая хостами виртуализации и логикой сетевых плоскостей. Теперь давайте посмотрим, какое сетевое оборудование мы используем.
Management-коммутаторы
В качестве коммутаторов плоскости управления мы используем Juniper, Huawei и H3C. В основном — Juniper EX4300 и EX3400, Huawei CE5855 и H3C S5560X. Каждый из них обслуживает 48 портов 1 Гбит/сек и часть на 10 Гбит/сек.

Leaf-коммутаторы
С коммутаторами уровня Leaf интересней: облако начинало расти на коммутаторах Brocade VDX6740, вендор которых со временем эволюционировал в Extreme Networks. Для небольших инсталляций в регионах также стали использовать коммутаторы Huawei CE6855 — это аналогичное VDX6740 решение.
Однако со временем нам стало не хватать 10 Гбит/сек и мы начали переход на коммутаторы с портами по 25 Гбит/сек. Сейчас мы переводим уровень Leaf на коммутаторы Arista DCS 7050-X3-48YC8 и Juniper QFX 5120-48Y. Они также могут обслуживать до 48 клиентских портов, но уже по 25 Гбит/сек.

Кроме 25 Гбит/сек коммутаторов мы используем коммутаторы Huawei CE6855-48S6Q-HI, хотя они менее распространены в нашем облаке. Такие Leaf-коммутаторы на текущий момент работают только в региональных инсталляциях.
Spine-коммутаторы
Это коммутаторы для предоставления связи между Leaf-коммутаторами. Сегодня на Spine-уровне облака мы используем коммутаторы трех моделей— Brocade Extreme Networks VDX6940-36Q, Arista DCS-7050CX3-32S и Juniper QFX5120-32C.

Коммутатор от Extreme Networks предоставляет 36 портов по 40 Гбит/сек, а коммутаторы Arista и Juniper — 32 порта по 100 Гбит/сек. При этом к последним можно подключить QSFP+ трансивер — и тогда это будут порты по 40 Гбит/сек. А если использовать модуль QSFP28 — 100 Гбит/сек.
Заключение
В этой статье мы рассмотрели лишь часть архитектуры облака — устройство на уровне пулов. Но облачная платформа постоянно растет, объединяя различные регионы. Если вам интересно, как устроена сеть «с высоты птичьего полета», следите за обновлениями в нашем блоге!





