Hadoop, часть 3: Pig, обработка данных

В предыдущей публикации мы подробно рассмотрели процесс сбора данных при помощи специализированного инструмента Flume. Но чтобы полноценно работать с информацией, мало ее просто собрать и сохранить: ее нужно обработать и извлечь из нее нечто нужное и полезное. Для обработки данных в Hadoop используется технология MapReduce.

Технология MapReduce
История
Обработка данных в Hadoop осуществляется с помощью технологии MapReduce. Изначально эта технология была разработана компанией Google в 2004 году.
Разработчики Google Джеффри Дин и Санджай Гемават в 2004 году опубликовали статью, в которой предложили следующее решение для обработки больших объемов «сырых» данных (индексированных документов, логов запросов и т.п.): огромный массив информации делится на части, и обработка каждой из этих частей поручается отдельному серверу. Как правило, данные обрабатываются на тех же серверах, где они и хранятся, что позволяет ускорить процесс обработки и избежать лишних перемещений данных между серверами. После этого полученные результаты объединяются в единое целое.
Специалисты Google в упомянутой выше статье ограничились лишь описанием основных алгоритмов, не останавливаясь на подробностях реализации. Однако этой информации оказалось для разработчиков Hadoop вполне достаточно, чтобы создать собственный фреймворк MapReduce.
Сегодня он используется во многих известных веб-проектах — Yahoo!, Facebook, Last.Fm и других.
Рассмотрим архитектуру и принципы работы Hadoop MapReduсе более подробно.
Архитектура и принципы работы
Архитектура MapReduce построена по принципу «главный — подчиненные» (master — workers). В качестве главного выступает сервер JobTracker, раздающий задания подчиненным узлам кластера и контролирующий их выполнение.
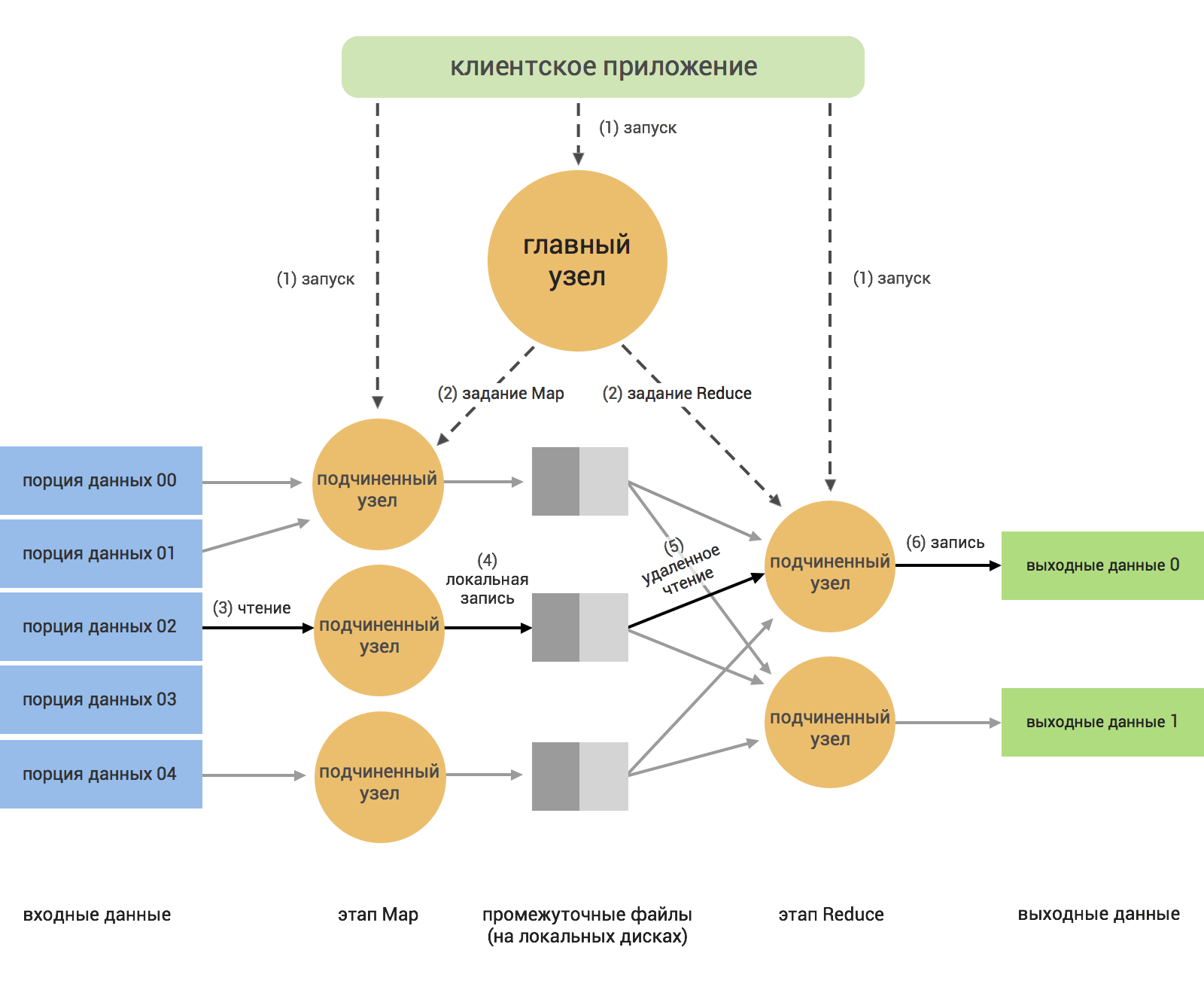
Обработка данных подразделяется на следующие этапы:
- Запуск приложения: передача кода приложения на главный (master) и подчиненные узлы (workers);
- Мастер назначает конкретные задачи (Map или Reduce) и распределяет части входных данных по вычислительным узлам (workers);
- Map-узлы читают назначенные им входные данные и начинают их обработку;
- Map-узлы локально сохраняют промежуточные результаты: каждый узел сохраняет полученный результат на локальные диски;
- Reduce-узлы читают промежуточные данные с Map-узлов и выполняют Reduce обработку данных;
- Reduce-узлы сохраняют итоговые результаты в выходные файлы, обычно в HDFS.
Создание приложений для MapReduce — дело достаточно трудоемкое. Написание всех функций, компилирование и упаковка занимают много времени. Чтобы облегчить работу компания Yahoo! разработала специализированный инструмент под названием Pig, повышающий уровень абстракции при обработке данных.
Pig
Pig состоит из двух частей:
- язык для описания потоков Pig Latin;
- исполнительная среда для запуска сценариев Pig Latin (доступны два варианта: запуск на локальной JVM или исполнение в кластере Hadoop).
Сценарий Pig включает серию операций (преобразований), которые необходимо применить к входным данным, чтобы получить выходные данные. Эти операции описывают поток данных, который затем преобразуется (компилируется) исполнительной средой Pig в исполняемое представление и запускается для выполнения. Во внутренней реализации Pig трансформирует преобразования в серию заданий MapReduce.
Изначально Pig был создан для работы из консоли (оболочка Grunt Shell). В реализации от Cloudera работа с Pig осуществляется через простой и удобный веб-интерфейс. Открыть его можно через уже знакомый нам интерфейс Hue http://[узел_на_котором_установлен_Hue]:8888/pig/
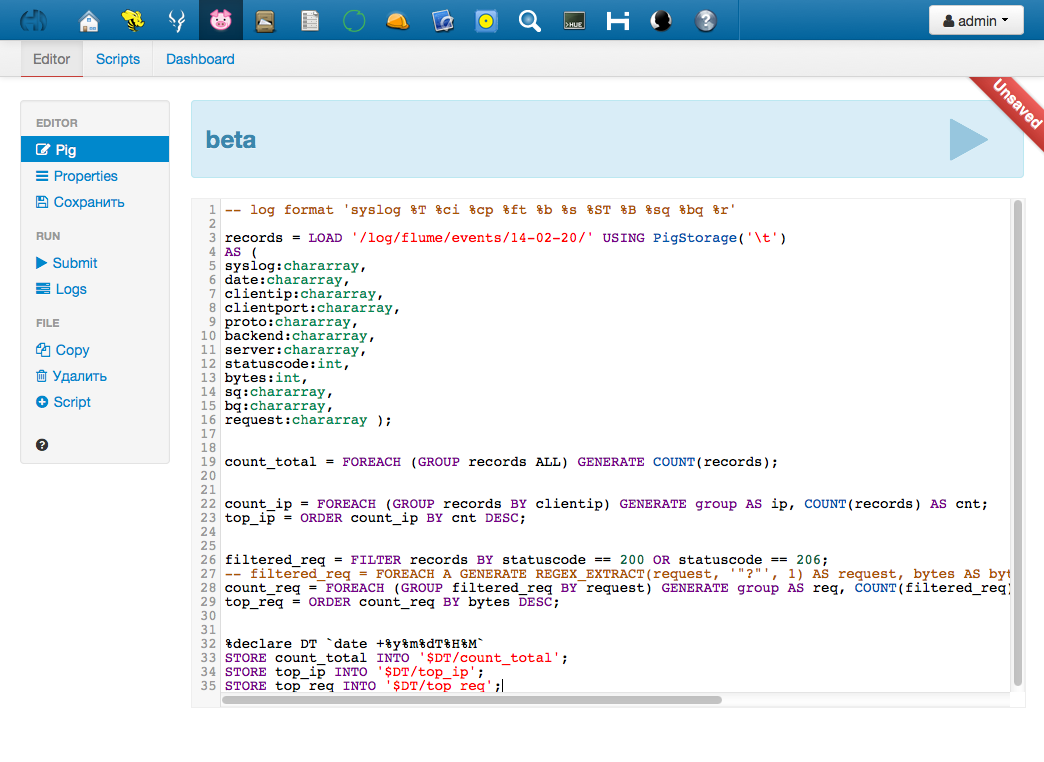
Веб-интерфейс включает полноценный редактор (есть даже автоподстановка операторов) и менеджер скриптов. С его помощью можно сохранять скрипты непосредственно в Hue, запускать их, просматривать список запущенных задач, результаты и логи запусков.
Тестовая задача
В качестве тестовой задачи мы выполним обработку логов доступа нашего хранилища за определенный день (сутки). Рассчитаем следующие параметры:
- общее количество запросов;
- количество запросов с каждого уникального IP;
- количество запросов на каждый уникальный URL;
- объем данных, переданных по каждому URL.
Ниже приводится скрипт, с помощью которого решается поставленная задача. Сразу же следует заметить, что этот скрипт (как и все скрипты в Pig) не выполняется построчно, как в интерпретируемых языках. Компилятор Pig разбирает зависимости и задает потоки данных. Компилирование скрипта начинается с конца, то есть с команды STORE. Для данных, после обработки которых нет команды сохранения, не будет создано никаких задач и сами данные не будут даже прочитаны. Это позволяет писать скрипт в достаточно произвольной форме, всю работу по оптимизации, определения порядка исполнения и распараллеливанию возьмет на себя Pig.
Полный листинг скрипта будет выглядеть так:
records = LOAD '/log/flume/events/14-02-20/' USING PigStorage('\t')
AS (
date:chararray,
clientip:chararray,
clientport:chararray,
proto:chararray,
statuscode:int,
bytes:int,
sq:chararray,
bq:chararray,
request:chararray );
count_total = FOREACH (GROUP records ALL) GENERATE COUNT(records);
count_ip = FOREACH (GROUP records BY clientip) GENERATE group AS ip, COUNT(records) AS cnt;
top_ip = ORDER count_ip BY cnt DESC;
filtered_req = FILTER records BY statuscode == 200 OR statuscode == 206;
count_req = FOREACH (GROUP filtered_req BY request) GENERATE group AS req, COUNT(filtered_req) AS cnt, SUM(filtered_req.bytes) AS bytes;
top_req = ORDER count_req BY bytes DESC;
%declare DT `date +%y%m%dT%H%M`
STORE count_total INTO '$DT/count_total';
STORE top_ip INTO '$DT/top_ip';
STORE top_req INTO '$DT/top_req';Он состоит из трех частей: загрузка данных, обработка и сохранение. Такой порядок является общим для большинства задач. В некоторых случаях решение задач может включать и дополнительные этапы — например, генерацию данных (например, структурированных искусственных данных для проверки алгоритма) или сохранение промежуточных результатов вычислений. Подробное описание синтаксиса, типов данных и операторов вы можете найти в официальной документации.
Рассмотрим каждый этап более подробно.
Загрузка
records = LOAD '/log/flume/events/14-02-20/' USING PigStorage('\t')
AS (
date:chararray,
clientip:chararray,
clientport:chararray,
proto:chararray,
statuscode:int,
bytes:int,
sq:chararray,
bq:chararray,
request:chararray );В качестве входных данных мы используем логи веб-серверов. Для лучшего понимания дальнейшей обработки приведем пример входных данных:
07/Dec/2013:20:05:13 95.153.193.56 37877 http 200 1492030 0 0 GET //6ef4e6a1-9d49-47ac-bfed-170f67a815cf.selcdn.net/745dbda3-894e-43aa-9146-607f19fe4428.mp3 HTTP/1.1
08/Dec/2013:15:00:28 178.88.91.180 13600 http 200 4798 0 0 GET //6ef4e6a1-9d49-47ac-bfed-170f67a815cf.selcdn.net/public/cars/bmw7l/down.png HTTP/1.1
08/Dec/2013:15:00:29 193.110.115.45 64318 http 200 1594 0 0 GET //6ef4e6a1-9d49-47ac-bfed-170f67a815cf.selcdn.net/K1/img/top-nav-bg-default.jpg HTTP/1.1Вначале рассмотрим модель данных и терминологию. Основной объект в Pig Latin- это «отношение». Именно с отношениями работают все операторы языка. В форме отношений представляются входные и выходные данные.
Каждое отношение представляет собой набор однотипных объектов — «кортежей» (tuples). Аналоги в БД: кортеж — это строка, отношение — это таблица.
Кортежи соответственно состоят из нумерованных или именованных объектов — «полей», произвольных базовых типов (число, строка, булева переменная и т.д.).
Итак, в Pig Latin результатом любого оператора является отношение, представляющее собой набор кортежей.
Оператор LOAD создает отношение records из файлов в HDFS из директории ’/log/flume/events/14-02-20/’, используя стандартный интерфейс PigStorage (также укажем, что разделителем в файлах является символ табуляции ‘\t’). Каждая строка из файлов предстанет кортежем в отношении. Секция AS присваивает полям в кортеже типы и имена, по которым нам будет удобнее к ним обращаться.
Обработка
Посчитаем общее количество записей в логах с помощью оператора COUNT. Перед этим необходимо объединить все строки в records в одну группу операторами FOREACH и GROUP.
count_total = FOREACH (GROUP records ALL) GENERATE COUNT(records);
count_ip = FOREACH (GROUP records BY clientip) GENERATE group AS ip, COUNT(records) AS cnt;
top_ip = ORDER count_ip BY cnt DESC;В переводе с Pig Latin на естественный язык приведенный скрипт выглядит так: для каждой записи (FOREACH), из records, сгруппированных вместе (GROUP ALL), выполнить подсчет записей в records (GENERATE COUNT).
Теперь посчитаем количество запросов с уникальных адресов. В наших кортежах в отношении records в поле clientip содержатся IP-адреса, с которых выполнялись запросы. Сгруппируем кортежи в records по полю clientip и определим новое отношение, состоящее из двух полей:
- поле ip, значение которого берется из названия группы в отношении records;
- количество записей в группе — cnt, посчитанное оператором COUNT, то есть количество записей, соответствующих определенному IP-адресу в поле IP.
Далее мы определяем еще одно отношение top_ip, состоящее из тех же данных, что и count_ip, но отсортированное по полю cnt оператором ORDER. Таким образом, в top_ip у нас будет список IP-адресов клиентов с которых чаще всего происходили запросы. В дальнейшем мы можем привязать эти данные к GEO-IP и посмотреть, в каких городах и странах наше хранилище пользуется наибольшей популярностью =)
filtered_req = FILTER records BY statuscode == 200 OR statuscode == 206;
count_req = FOREACH (GROUP filtered_req BY request) GENERATE group AS req, COUNT(filtered_req) AS cnt, SUM(filtered_req.bytes) AS bytes;
top_req = ORDER count_req BY bytes DESC;После этого посчитаем количество успешных запросов на каждый URL, а также суммарный объем загруженных по каждому URL данных. Для этого сначала воспользуемся оператором фильтрации FILTER, отобрав только успешные запросы с HTTP кодами 200 OK и 206 Partial Content. Этот оператор определяет новое отношение filtered_req из отношения records, отфильтровав его по полю statuscode.
Далее аналогично подсчету IP-адресов посчитаем количество уникальных URL, группируя записи в отношении requests по полю request. Для нас также представляет интерес переданный объем данных по каждому URL: его можно рассчитать с помощью оператора SUM, складывающего поля bytes в сгруппированных записях отношения filtered_req.
Теперь осуществим сортировку по полю bytes, определяя новое отношение top_req.
Сохранение результатов
%declare DT `date +%y%m%dT%H%M`
STORE count_total INTO '$DT/count_total';
STORE top_ip INTO '$DT/top_ip';
STORE top_req INTO '$DT/top_req';Предпочтительно сохранять результаты каждого выполнения скрипта в отдельную директорию, имя которой включает дату и время исполнения. Для этого можно воспользоваться функцией вызова произвольной шелл-команды прямо из Pig-скрипта (ее нужно написать в обратных кавычках). В примере результат команды date заносится в переменную DT, которая затем подставляется в пути сохранения данных. Сохраняем результаты командой STORE: каждое отношение — в свой каталог.
Просмотреть выходные данные можно через файловый менеджер в Hue; по умолчанию путь в HDFS указывается относительно домашней директории пользователя, запустившего скрипт.
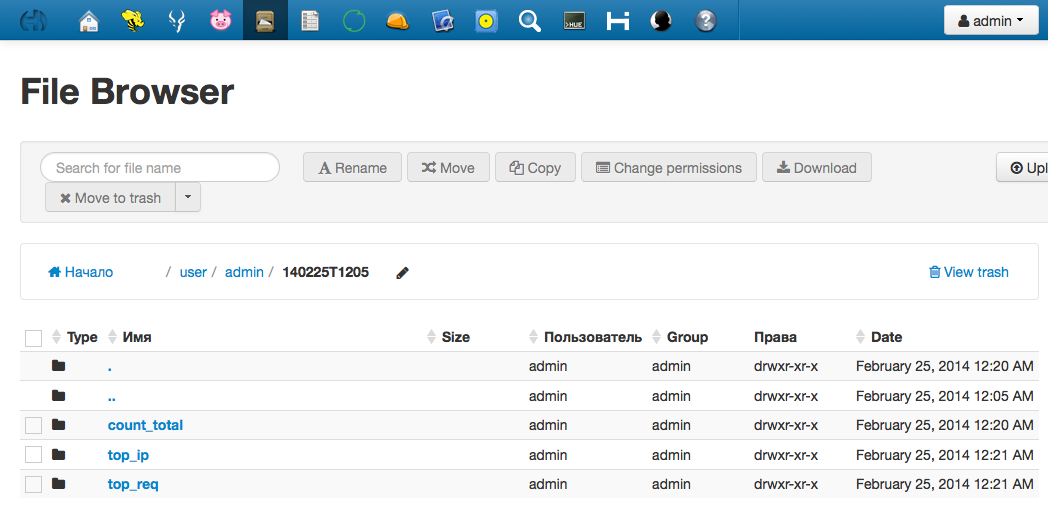
Информация о результатах выполнения задач будет отображена в логах Pig следующим образом:
http://cdh3:8888/pig/#logs/1100715
Input(s):
Successfully read 184442722 records (32427523128 bytes) from: "/log/flume/events/14-02-20"
Output(s):
Successfully stored 1 records (10 bytes) in: "hdfs://cdh3:8020/user/admin/140225T1205/count_total"
Successfully stored 8168550 records (1406880284 bytes) in: "hdfs://cdh3:8020/user/admin/140225T1205/top_req"
Successfully stored 2944212 records (49039769 bytes) in: "hdfs://cdh3:8020/user/admin/140225T1205/top_ip"
Counters:
Total records written : 11112763
Total bytes written : 1455920063Отчет из Oozie:
Last Modified Tue, 25 Feb 2014 00:22:00
Start Time Tue, 25 Feb 2014 00:05:16
Created Time Tue, 25 Feb 2014 00:05:15
End Time Tue, 25 Feb 2014 00:22:00Из приведенных логов видно, что при выполнении тестовой задачи было обработано более 180 миллионов записей общим объемом более 32 Гб. Вся процедура обработки заняла около 15 минут.
Во время активной фазы Map было задействовано 22 процессорных ядра и 91Гб оперативной памяти. Для небольшого кластера, состоящего из трех серверов пятилетней давности, такой результат можно считать вполне неплохим.
Выше уже было сказано, что Pig во время исполнения скрипта создает MapReduce задачи и отправляет их на выполнение в MR-кластер. Этот процесс наглядно показан на графиках статистики в панели управления Cloudera Manager:
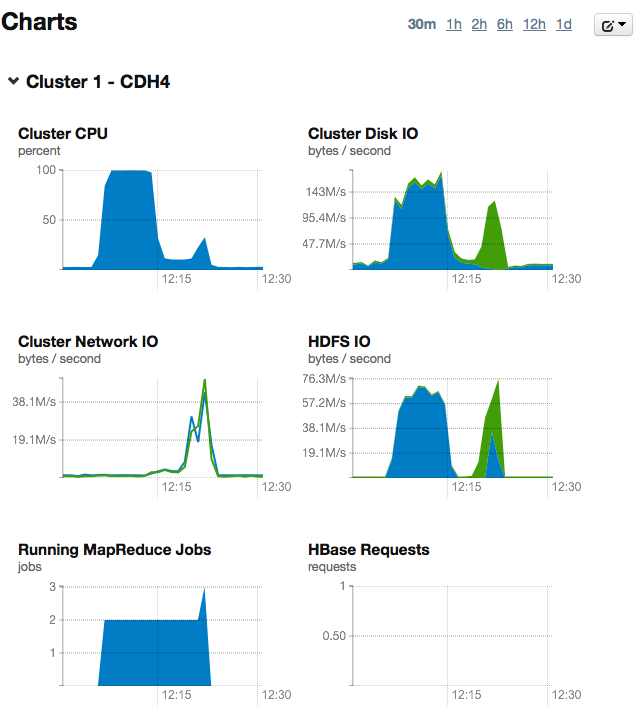
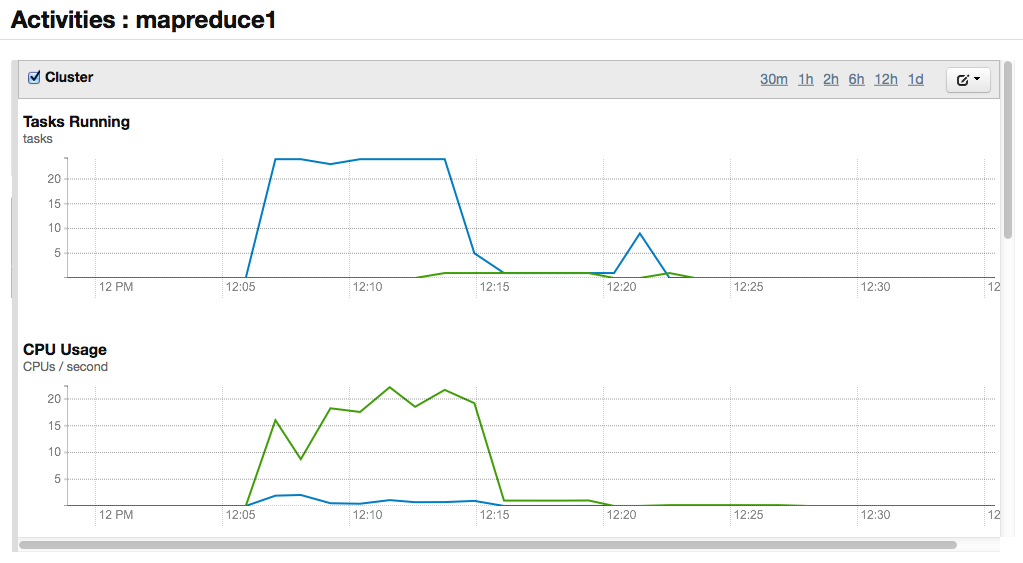
- Этап Map: процессоры и диски на каждом узле заняты обработкой своих частей данных.
- Этап Reduce: результаты, полученные на первом этапе, передаются по сети и объединяются.
- На третьем этапе результаты сохраняются в файловой системе (на графике виден скачок записи в HDFS).
На графиках можно увидеть, что решение задачи включало два прохода MapReducе. Во время первого прохода был выполнен подсчет уникальных записей, а во время второго — сортировка. Эти процедуры не могут быть распараллелены и выполнены за один проход, так как вторая процедура работает с результатами первой.
Заключение
В этой статье мы рассказали об архитектуре MapReduce, а также рассмотрели особенности его работы с использованием инструмента Pig. Написание программ для MapReduce представляет собой весьма непростую задачу, требующую особого подхода. Все сложности, однако, компенсируются мощностью, возможностями масштабирования и высокой скоростью обработки огромных объемов произвольных данных.
В ближайшее время мы планируем продолжить цикл статей о Hadoop. Следующая публикация будет посвящена работе с базой данных Impala.




