Hadoop, часть 1: развертывание кластера

Непрерывный рост данных и увеличение скорости их генерации порождают проблему их обработки и хранения. Неудивительно, что тема «больших данных» (Big Data) является одной из самых обсуждаемых в современном ИТ-сообществе. Материалов по теории «больших данных» в специализированных журналах и на сайтах сегодня публикуется довольно много. Но из теоретических публикаций далеко не всегда ясно, как можно использовать соответствующие технологии для решения конкретных практических задач. Одним из самых известных и обсуждаемых проектов в области распределенных вычислений является Hadoop — разрабатываемый фондом Apache Software Foundation свободно распространяемый набор из утилит, библиотек и фреймворк для разработки и выполнения программ распределенных вычислений.

Непрерывный рост данных и увеличение скорости их генерации порождают проблему их обработки и хранения. Неудивительно, что тема «больших данных» (Big Data) является одной из самых обсуждаемых в современном ИТ-сообществе.
Материалов по теории «больших данных» в специализированных журналах и на сайтах сегодня публикуется довольно много. Но из теоретических публикаций далеко не всегда ясно, как можно использовать соответствующие технологии для решения конкретных практических задач.
Одним из самых известных и обсуждаемых проектов в области распределенных вычислений является Hadoop — разрабатываемый фондом Apache Software Foundation свободно распространяемый набор из утилит, библиотек и фреймворк для разработки и выполнения программ распределенных вычислений.
Мы уже давно используем Hadoop для решения собственных практических задач. Результаты нашей работы в этой области стоят того, чтобы рассказать о них широкой публике. Эта статья – первая в цикле о Hadoop. Сегодня мы расскажем об истории и структуре проекта Hadoop, а также покажем на примере дистрибутива Hadoop Cloudera, как осуществляется развертывание и настройка кластера.
Немного истории
Автор Hadoop — Дуг Каттинг, создатель известной библиотеки текстового поиска Apache Lucene. Название проекта представляет собой имя, которое сын Дуга придумал для своего плюшевого желтого слона.
Каттинг создал Hadoop, работая над проектом Nutch — системой веб-поиска с открытым кодом. Проект Nutch был запущен в 2002 году, но очень скоро его разработчики поняли, что имеющуюся архитектуру вряд ли удастся масштабировать на миллиарды веб-страниц. В 2003 году была опубликована статья с описанием распределенной файловой системы GFS (Google File System), использовавшейся в проектах Google. Такая система вполне могла бы справиться с задачей хранения больших файлов, генерируемых при обходе и индексировании сайтов. В 2004 году команда разработчиков Nutch взялась за реализацию такой системы c открытым кодом — NDFS (Nutch Distributed File System).
В 2004 году компания Google представила широкой аудитории технологию MapReduce. Разработчики Nutch уже в начале 2005 года создали полноценную реализацию MapReduce на базе Nutch; вскоре после этого все основные алгоритмы Nutch были адаптированы для использования MapReduce и NDFS.
В 2006 году Hadoop был выделен в независимый подпроект в рамках проекта Lucene.
В 2008 году Hadoop стал одним из ведущих проектов Apache. К тому времени он уже успешно использовался в таких компаниях, как Yahoo!, Facebook и Last.Fm.
Сегодня Hadoop широко используется как в коммерческих компаниях, так и в научных и образовательных учреждениях.
Структура проекта Hadoop
В состав проекта Hadoop входят следующие подпроекты:
- Common — набор компонентов и интерфейсов для распределенных файловых систем и общего ввода-вывода;
- Map Reduce — модель распределеных вычислений, предназначенная для параллельных вычислений над очень большими (до нескольких петабайт) объемами данных;
- HDFS — распределенная файловая система, работающая на больших кластерах типовых машин.
Ранее в Hadoop входили другие подпроекты, которые теперь являются самостоятельными продуктами Apache Software Foundation:
- Avro — система сериализации для выполненных межъязыковых вызовов RPC и долгосрочного хранения данных;
- Pig — язык управления потоком данных и исполнительная среда для анализа больших объемов данных;
- Hive — распределенное хранилище данных; оно управляет данными, хранимыми в HDFS, и предоставляет язык запросов на базе SQL для работы с этими данными;
- HBase — нереляционная распределенная база данных;
- ZooKeeper — распределенный координационный сервис; предоставляет примитивы для построения распределенных приложений;
- Sqoop — инструмент для пересылки данных между структурированными хранилищами и HDFS;
- Oozie — сервис для записи и планировки заданий Hadoop.
Дистрибутивы Hadoop
Сегодня Hadoop представляет собой сложную систему, состоящую из большого числа компонентов. Установить и настроить такую систему самостоятельно – весьма непростая задача. Поэтому многие компании сегодня предлагают готовые дистрибутивы Hadoop, включающие инструменты развертывания, администрирования и мониторинга.
Дистрибутивы Hadoop распространяются как под коммерческими (продукты таких компаний, как Intel, IBM, EMC, Oracle), так и под свободными (продукты компаний Cloudera, Hortonworks и MapR) лицензиями. О дистрибутиве Cloudera Hadoop мы расскажем более подробно.
Cloudera Hadoop
Cloudera Hadoop представляет собой полностью открытый дистрибутив, созданный при активном участии разработчиков Apache Hadoop Дуга Каттинга и Майка Кафареллы. Он распространяется как в бесплатном, так и в платном варианте, известном под названием Cloudera Enterprise.
На тот момент, когда мы заинтересовались проектом Hadoop, Cloudera предоставляла наиболее законченное и комплексное решение среди открытых дистрибутивов Hadoop. За все время работы не было ни одной значительной неполадки, и кластер благополучно пережил несколько мажорных обновлений, прошедших полностью автоматически. И вот спустя почти год экспериментов можем сказать, что довольны сделанным выбором.
Cloudera Hadoop включает следующие основные компоненты:
- Cloudera Hadoop (CDH) – собственно дистрибутив Hadoop;
- Cloudera Manager – инструмент для развертывания, мониторинга и управления кластером Hadoop.
Компоненты Cloudera Hadoop распространяются в виде бинарных пакетов, называемых парселами. По сравнению со стандартными пакетами и пакетными менеджерами парселы имеют следующие преимущества:
- простота загрузки: каждый парсел представляет собой один файл, в котором объединены все нужные компоненты;
- внутренняя согласованность: все компоненты внутри парсела тщательно протестированы, отлажены и согласованы между собой, поэтому вероятность возникновения проблем с несовместимостью компонентов очень мала;
- разграничение распространения и активации: можно сначала установить парселы на все управляемые узлы, а затем активировать их одним действием; благодаря этому обновление системы осуществляется быстро и с минимальным простоем;
- обновления «на ходу»: при обновлении минорной версии все новые процессы (задачи) будут автоматически запускаться под этой версией, уже запущенные задачи продолжат исполняться в старом окружении до своего завершения. Однако обновление до более новой мажорной версии возможно только посредством полного перезапуска всех сервисов кластера, и соответственно всех текущих задач;
- простой откат изменений: при возникновении каких-либо проблем в работе с новой версией CDH ее можно легко откатить до предыдущей.
Аппаратные требования
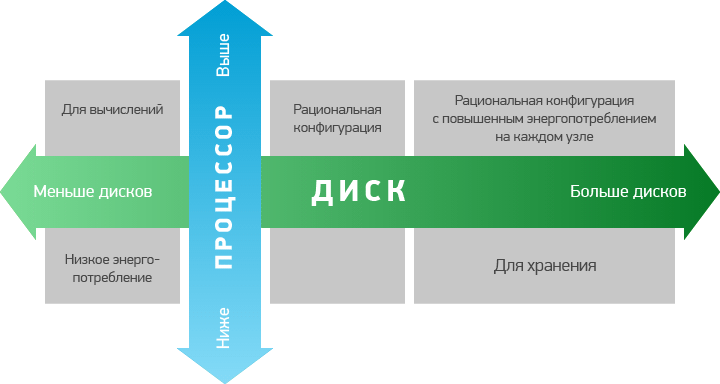
Требования к аппаратному обеспечению для развертывания Hadoop – достаточно сложная тема. К разным узлам в составе кластера предъявляются разные требования. Более подробно об этом можно прочитать, например, в рекомендациях компании Intel или в блоге компании Cloudera. Общее правило: больше памяти и дисков! В RAID-контроллерах и прочих enterprise радостях нет необходимости в силу самой архитектуры Hadoop и HDFS, рассчитанных на работу на типовых простых серверах. Использование 10Гб сетевых карт оправдано при объемах данных более 12ТБ на ноду.
В блоге Cloudera приводится следующий список аппаратных конфигураций для различных вариантов загрузки:
- «легкая» конфигурация (1U) – 2 шестиядерных процесссора, 24-64 Гб памяти, 8 жестких дисков емкостью 1-2 Тб;
- рациональная конфигурация (1U) – 2 шестиядерных процессора, 48-128 Гб памяти, 12-16 жестких дисков (1 или 2 Тб), подключенных напрямую через контроллер материнской платы;
- «тяжелая» конфигурация для хранилищ (2U): 2 шестиядерных процессора, 48-96 Гб памяти, 16-24 жестких дисках. При множественных сбоях в работе узлов в данной конфигурации происходит резкое увеличение сетевого трафика;
- конфигурация для интенсивных вычислений: 2 шестиядерных процессора, 64-512 Гб памяти, 4-8 жестких дисков емкостью 1-2 Тб.
Отметим, что в случае аренды серверов потери от неудачно выбранной конфигурации не так страшны, как при покупке своих серверов. При необходимости вы сможете модифицировать арендуемые серверы или заменить их на более подходящие для ваших задач.
Перейдем непосредственно к установке нашего кластера.
Установка и настройка ОС
Для всех серверов мы будем использовать CentOS 6.4 в минимальной установке, но можно использовать и другие дистрибутивы: Debian, Ubuntu, RHEL, etc. Необходимые пакеты имеются в открытом доступе на archive.cloudera.com и устанавливаются стандартными пакетными менеджерами.
На сервере Cloudera Мanager рекомендуем использовать программный или аппаратный RAID1 и один корневой раздел, можно вынести на отдельный раздел /var/log/. На серверах, которые будут добавлены в hadoop-кластер, рекомендуем создать два раздела:
- «/» размером 50-100Гб под ОС и ПО Cloudera Hadoop;
- «/dfs» поверх LVM на все доступные диски под хранение данных HDFS;
- «swap» лучше сделать совсем небольшим, около 500Мб. В идеале серверы не должны свопиться совсем, но если такое случится, то небольшой swap убережет процессы от OOM-killer’а.
На всех серверах, включая сервер Cloudera Manager, необходимо отключить SELinux и фаервол. Можно, конечно, этого не делать, но тогда придется потратить много времени и сил на тонкую настройку политик безопасности. Для обеспечения безопасности рекомендуется максимально изолировать кластер от внешнего мира на уровне сети, например, используя аппаратный фаервол или изолированный VLAN (доступ к зеркалам организовать через локальный прокси).
# vi /etc/selinux/config # выключим SElinux SELINUX=disabled # system-config-firewall-tui # выключим фаервол и сохраним настройки # reboot
Предлагаем примеры готовых kickstart файлов для автоматической установки серверов Cloudera Manager и нод кластера.
install text reboot ### General url --url http://mirror.selectel.ru/centos/6.4/os/x86_64 # disable SELinux for CDH selinux --disabled rootpw supersecretpasswrd authconfig --enableshadow --enablemd5 # Networking firewall --disabled network --bootproto=static --device=eth0 --ip=1.2.3.254 --netmask=255.255.255.0 --gateway=1.2.3.1 --nameserver=188.93.16.19,109.234.159.91,188.93.17.19 --hostname=cm.example.net # Regional keyboard us lang en_US.UTF-8 timezone Europe/Moscow ### Partitioning zerombr yes bootloader --location=mbr --driveorder=sda,sdb clearpart --all --initlabel part raid.11 --size 1024 --asprimary --ondrive=sda part raid.12 --size 1 --grow --asprimary --ondrive=sda part raid.21 --size 1024 --asprimary --ondrive=sdb part raid.22 --size 1 --grow --asprimary --ondrive=sdb raid /boot --fstype ext3 --device md0 --level=RAID1 raid.11 raid.21 raid pv.01 --fstype ext3 --device md1 --level=RAID1 raid.12 raid.22 volgroup vg0 pv.01 logvol swap --vgname=vg0 --size=12288 --name=swap --fstype=ext4 logvol / --vgname=vg0 --size=1 --grow --name=vg0-root --fstype=ext4 %packages @Base wget ntp %post --erroronfail chkconfig ntpd on wget -q -O /etc/yum.repos.d/cloudera-manager.repo http://archive.cloudera.com/cm4/redhat/6/x86_64/cm/cloudera-manager.repo rpm --import http://archive.cloudera.com/cdh4/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera yum -y install jdk yum -y install cloudera-manager-daemons yum -y install cloudera-manager-server yum -y install cloudera-manager-server-db
Установка Cloudera Manager
Начнем с установки Cloudera Manager, который затем сам развернет и настроит наш будущий Hadoop-кластер на серверах.
Перед установкой нужно обязательно убедиться в том, что:
- все входящие в кластер серверы доступны по ssh, и у них установлен один и тот же пароль root (или добавлен публичный ssh ключ);
- все узлы должны иметь доступ к стандартным репозиториям пакетов (иметь выход в интернет или доступ к локальному репозиторию/прокси);
- все входящие в кластер серверы имеют доступ к archive.cloudera.com либо к локальному репозиторию с необходимыми установочными файлами;
- на всех серверах установлен ntp и настроена синхронизация времени;
- у всех узлов в составе кластера и сервера CM настроены DNS- и PTR записи (либо все хосты должны быть прописаны в /etc/hosts всех серверов).
Добавим зеркало Cloudera и установим необходимые пакеты:
# wget -q -O /etc/yum.repos.d/cloudera-manager.repo http://archive.cloudera.com/cm4/redhat/6/x86_64/cm/cloudera-manager.repo # rpm --import http://archive.cloudera.com/cdh4/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera # yum -y install jdk # yum -y install cloudera-manager-daemons # yum -y install cloudera-manager-server # yum -y install cloudera-manager-server-db
По окончанию установки запускаем стандартную БД (для простоты будем использовать её, хотя можно подключить любую стороннюю) и сам сервис CM:
# /etc/init.d/cloudera-scm-server-db start # /etc/init.d/cloudera-scm-server start
Развертывание кластера Cloudera Hadoop
После установки Cloudera Manager можно забыть о консоли, всё дальнейшее взаимодействие с кластером мы будем осуществлять, используя веб-интерфейс Cloudera Manager. По умолчанию Cloudera Manager использует 7180 порт. Можно использовать как DNS-имя, так и IP-адрес сервера. Введем этот адрес в строку браузера.
На экране появится окно входа в систему. Логин и пароль для входа – стандартные (admin, admin). Конечно же, их нужно незамедлительно поменять.
Откроется окно с предложением выбрать версию Cloudera Hadoop: бесплатную, пробную на 60 дней или платную лицензию:
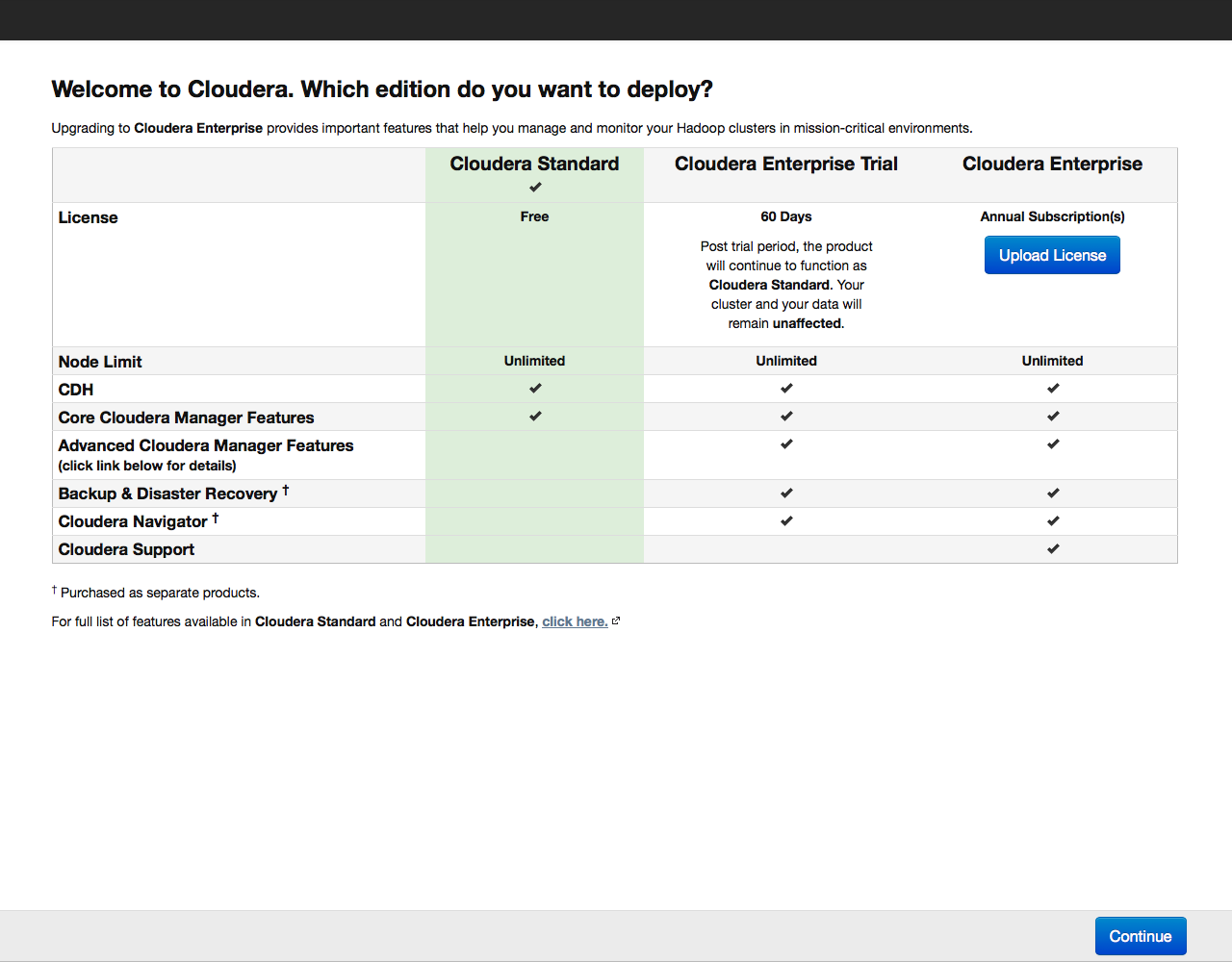
Выбираем бесплатную (Cloudera Standard) версию. Триал или платную лицензию можно будет активировать позже в любой момент, когда вы уже освоитесь с работой с кластером.
Во время установки сервис Cloudera Manager будет подключаться по SSH к серверам, входящим в кластер; все действия на серверах он выполняет от имени пользователя, указанного в меню, по умолчанию используется root.
Далее Cloudera Manager попросит указать адреса хостов, где будет установлен Cloudera Hadoop:
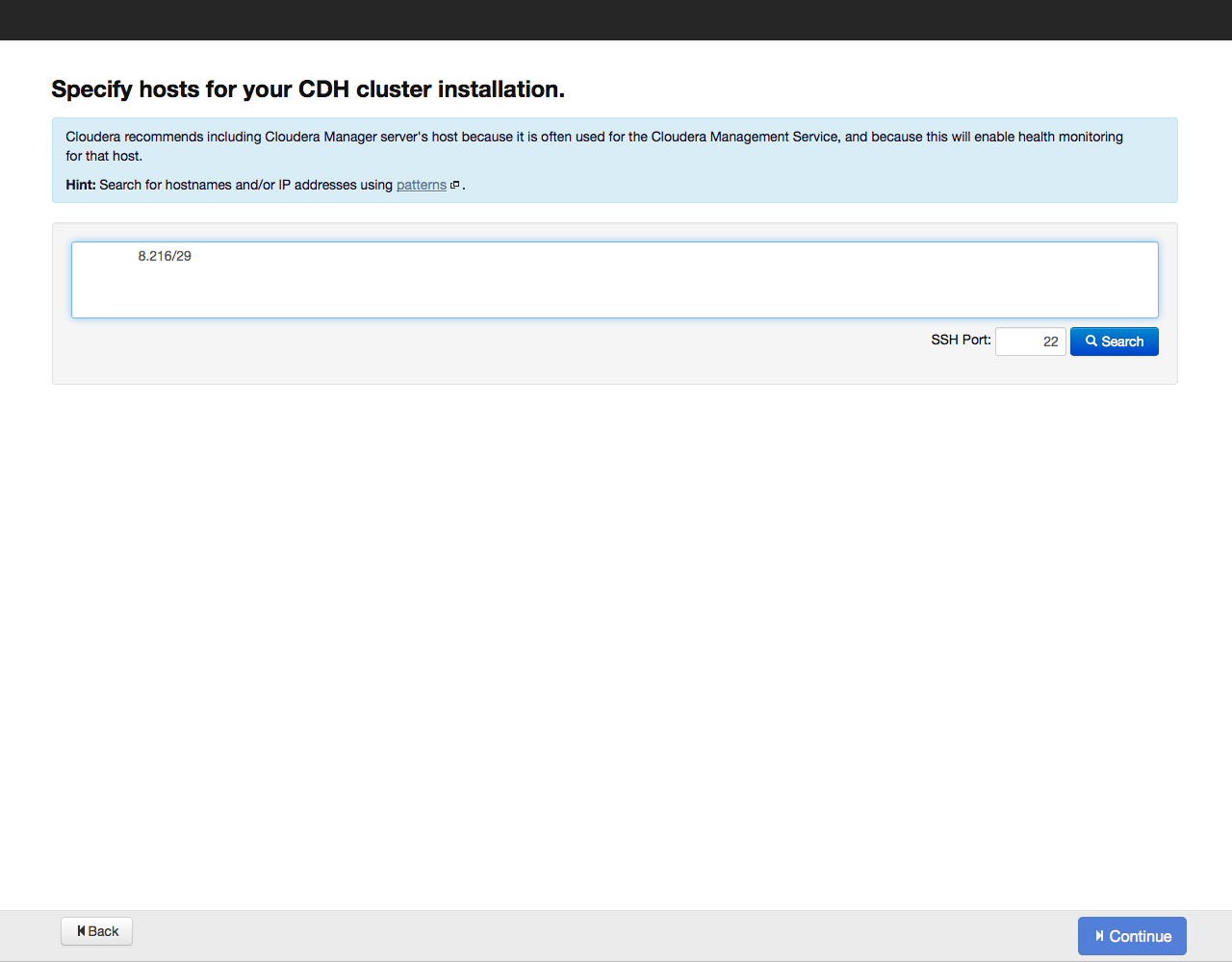
Адреса можно указать списком и по маске, например так:
- 10.1.1.[1-4] означает, что в состав кластера войдут узлы с IP-адресами 10.1.1.1, 10.1.1.2, 10.1.1.3, 10.1.1.4
- host[07-10].example.com – host07.example.com, host08.example.com, host09.example.com, host10.example.com.
После этого нажимаем на кнопку Search. Cloudera Manager обнаружит указанные хосты, и на экране будет отображен их список:
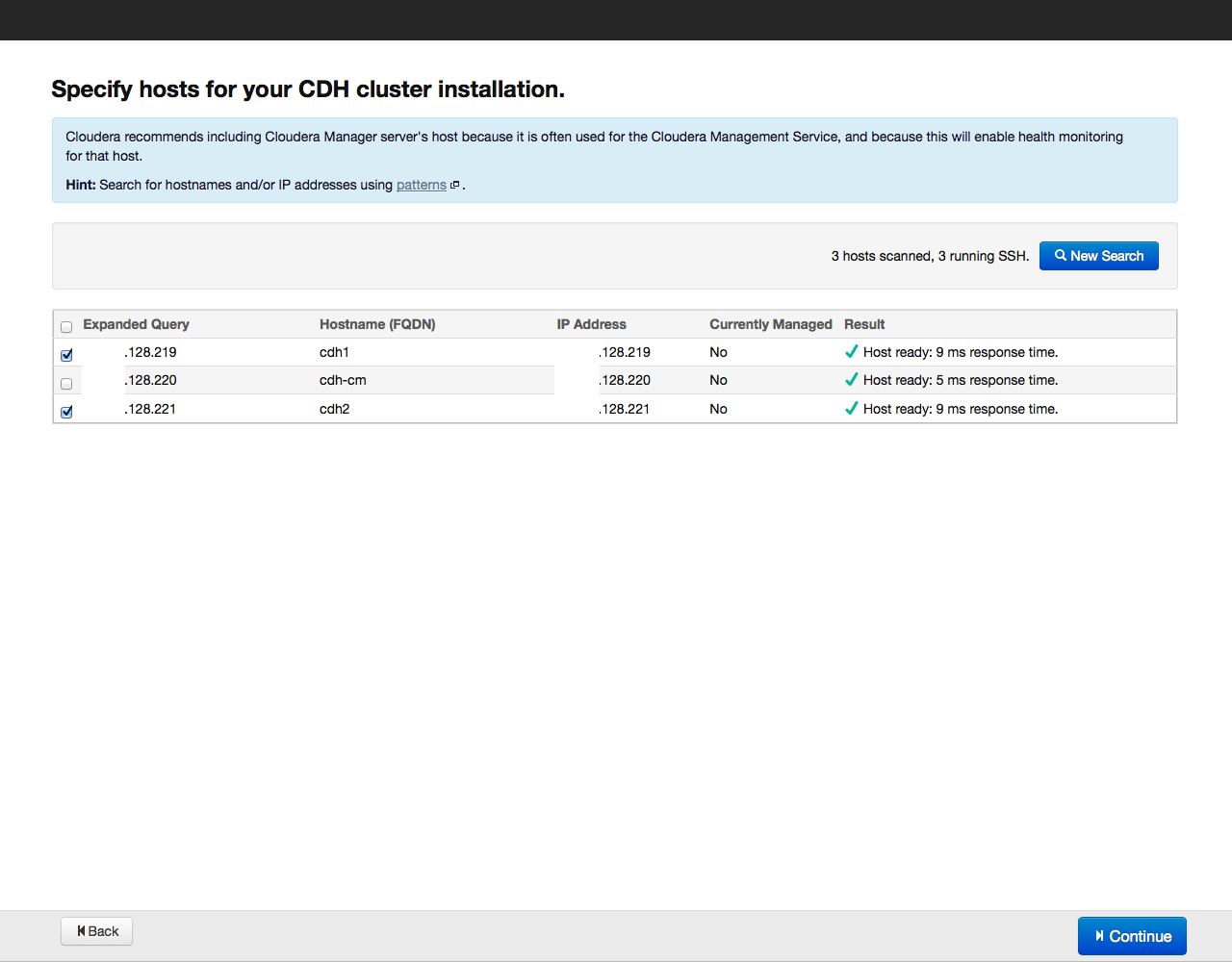
Еще раз проверяем, включены ли в этот список все нужные хосты (добавить новые хосты можно, нажав на кнопку New Search). Затем нажимаем на кнопку Continue. Откроется окно выбора репозитория:
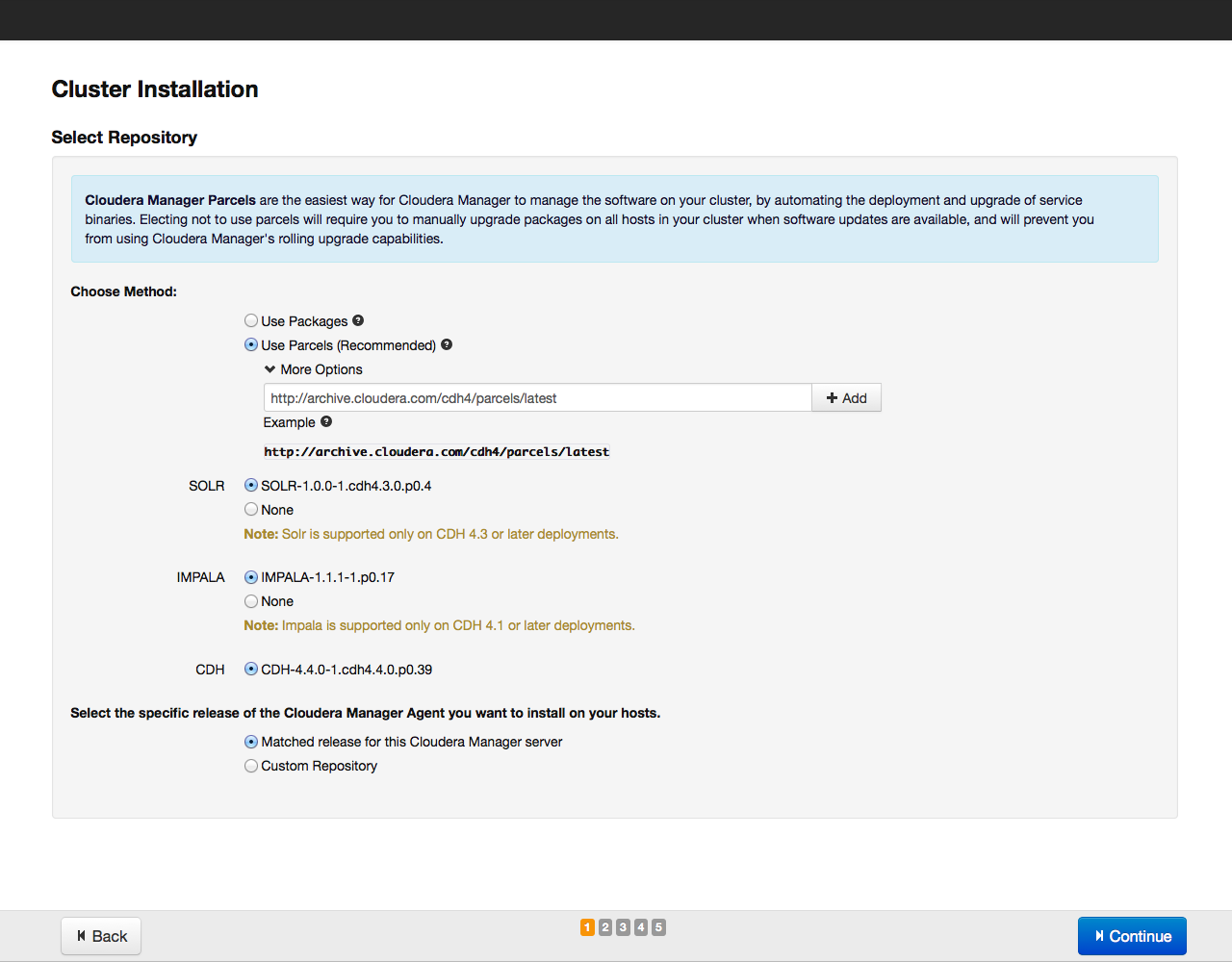
В качестве метода установки рекомендуем выбрать установку парселами, об их преимуществах мы уже рассказали ранее. Парселы устанавливаются из репозитория archive.cloudera.org. Помимо парсела CDH, из этого же репозитория можно установить поисковый инструмент SOLR и базу данных на основе Hadoop IMPALA.
Выбрав парселы для установки, нажимаем на кнопку Continue. В следующем окне указываем параметры для доступа по SSH (логин, пароль или закрытый ключ, номер порта для подключения):
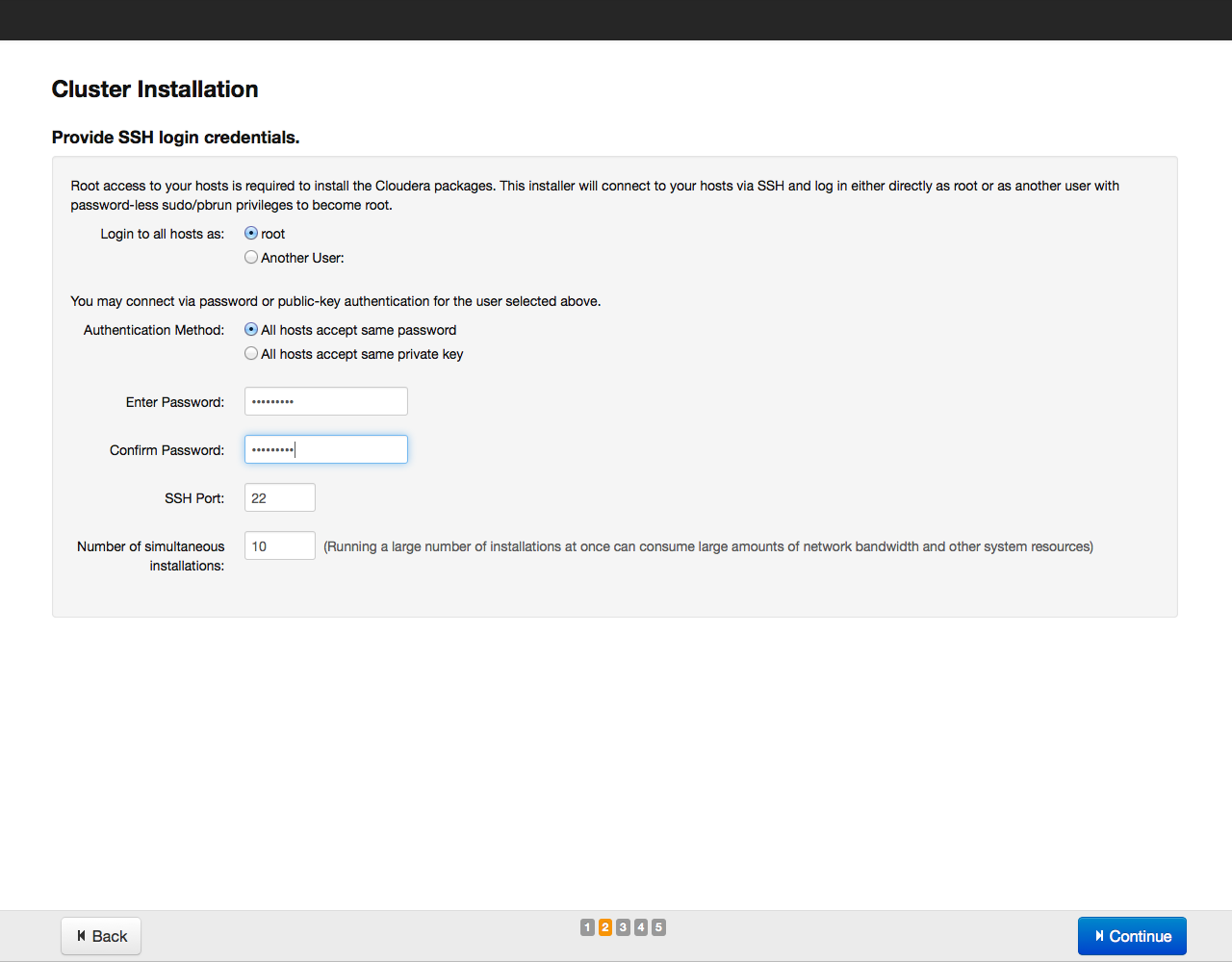
После этого нажимаем на кнопку Continue. Начнется процесс установки:
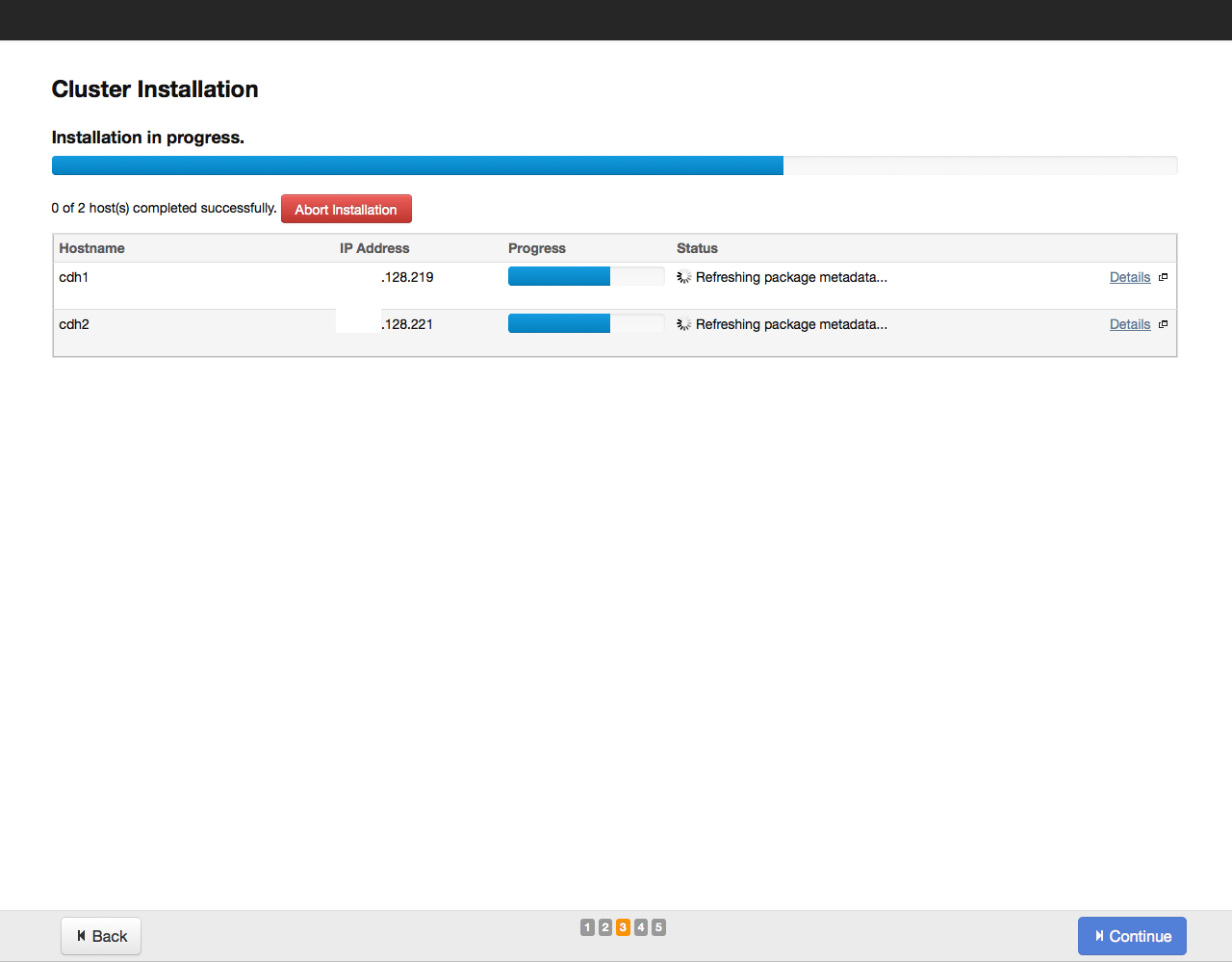
По завершении установки на экране отобразится таблица со сводной информацией об установленных компонентах и их версии:
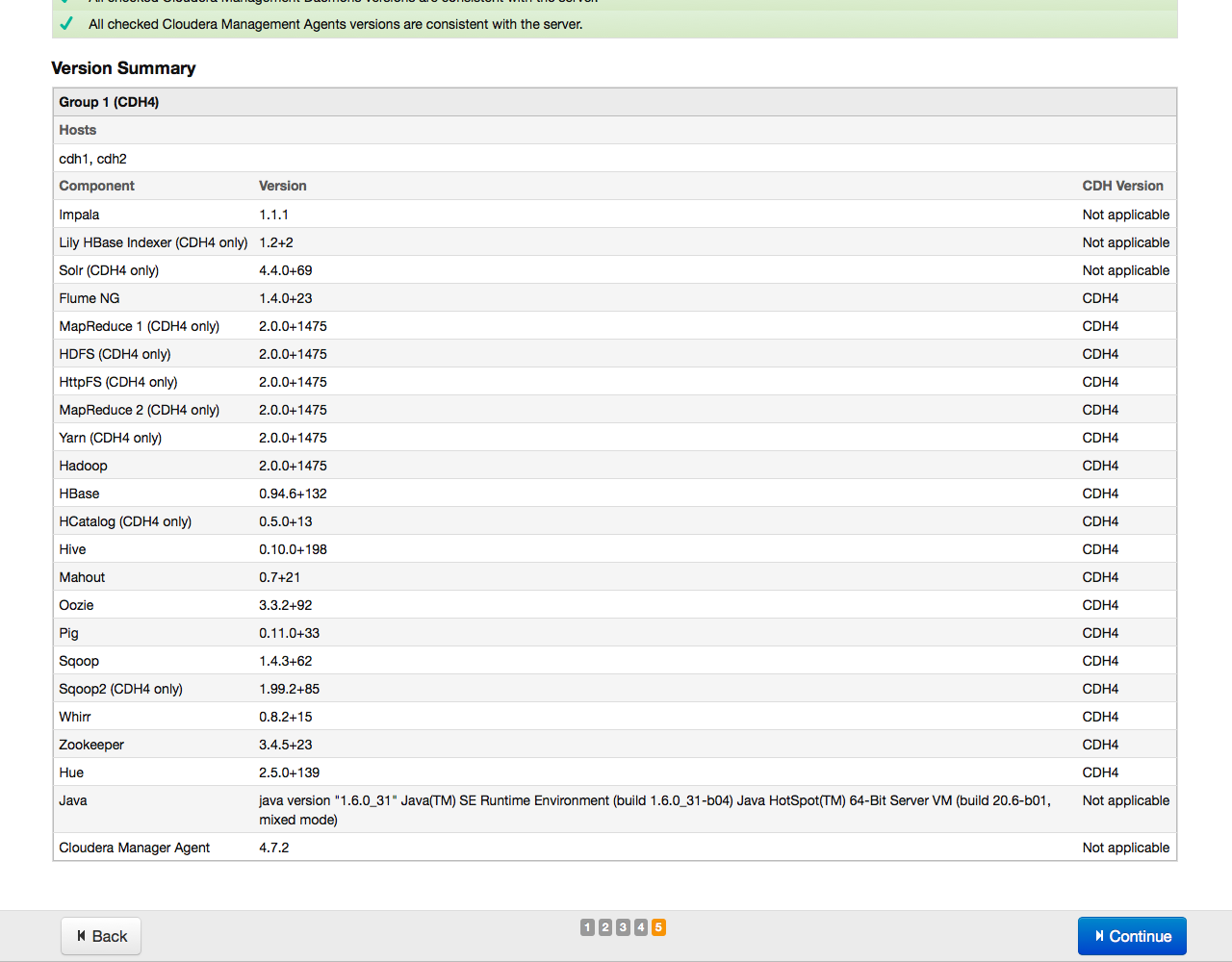
В очередной раз проверяем, все ли в порядке, и нажимаем на кнопку Continue. На экране появится окно с предложением выбрать компоненты и службы Cloudera Hadoop для установки:
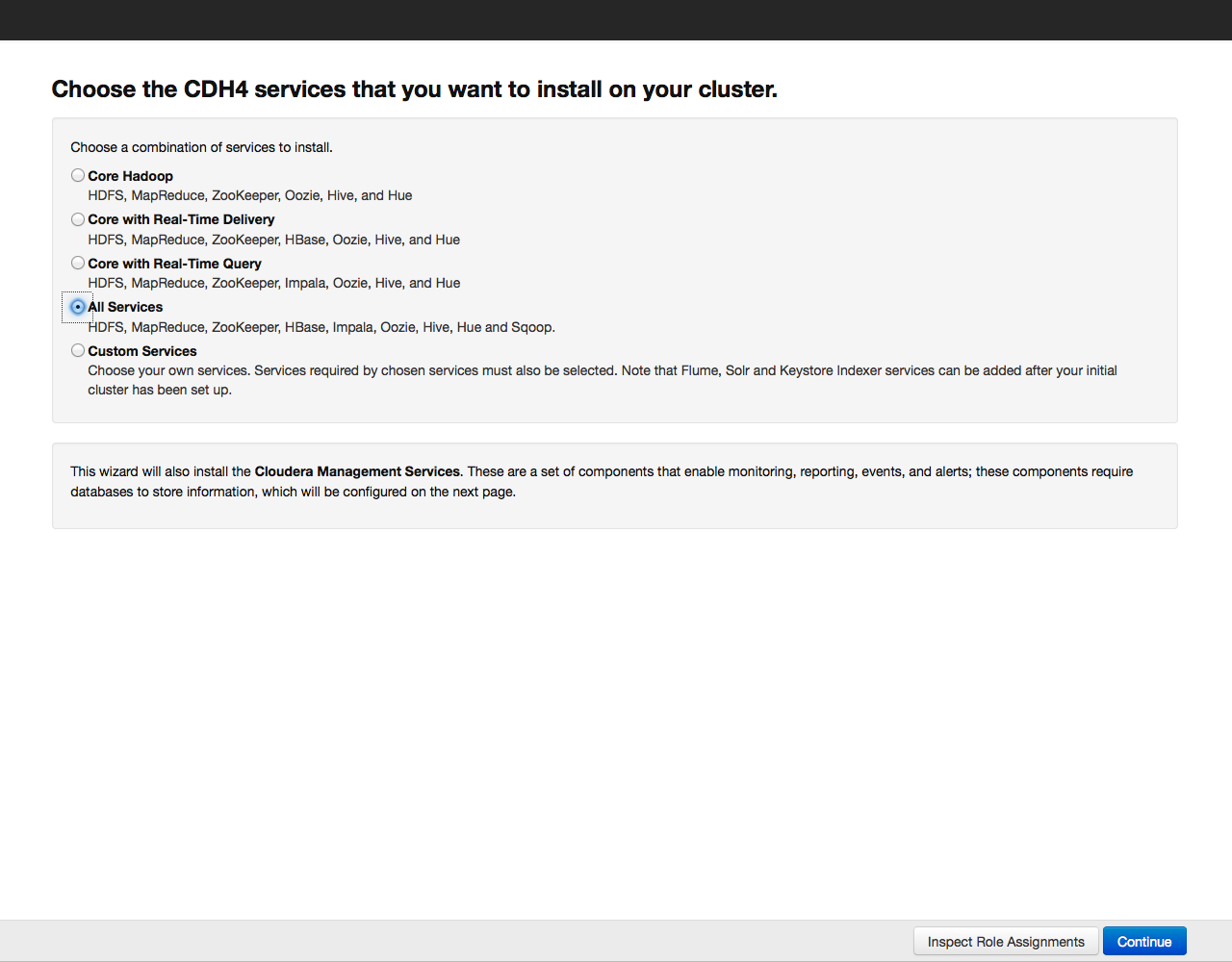
Для примера установим все компоненты, выбрав вариант «All Services», позже можно будет доустановить или удалить любые сервисы. Теперь необходимо указать, какие компоненты Cloudera Hadoop будут установлены на конкретных хостах. Рекомендуем довериться выбору по умолчанию, более подробно рекомендации по разположению ролей на нодах можно почитать в документации к конкретному сервису.
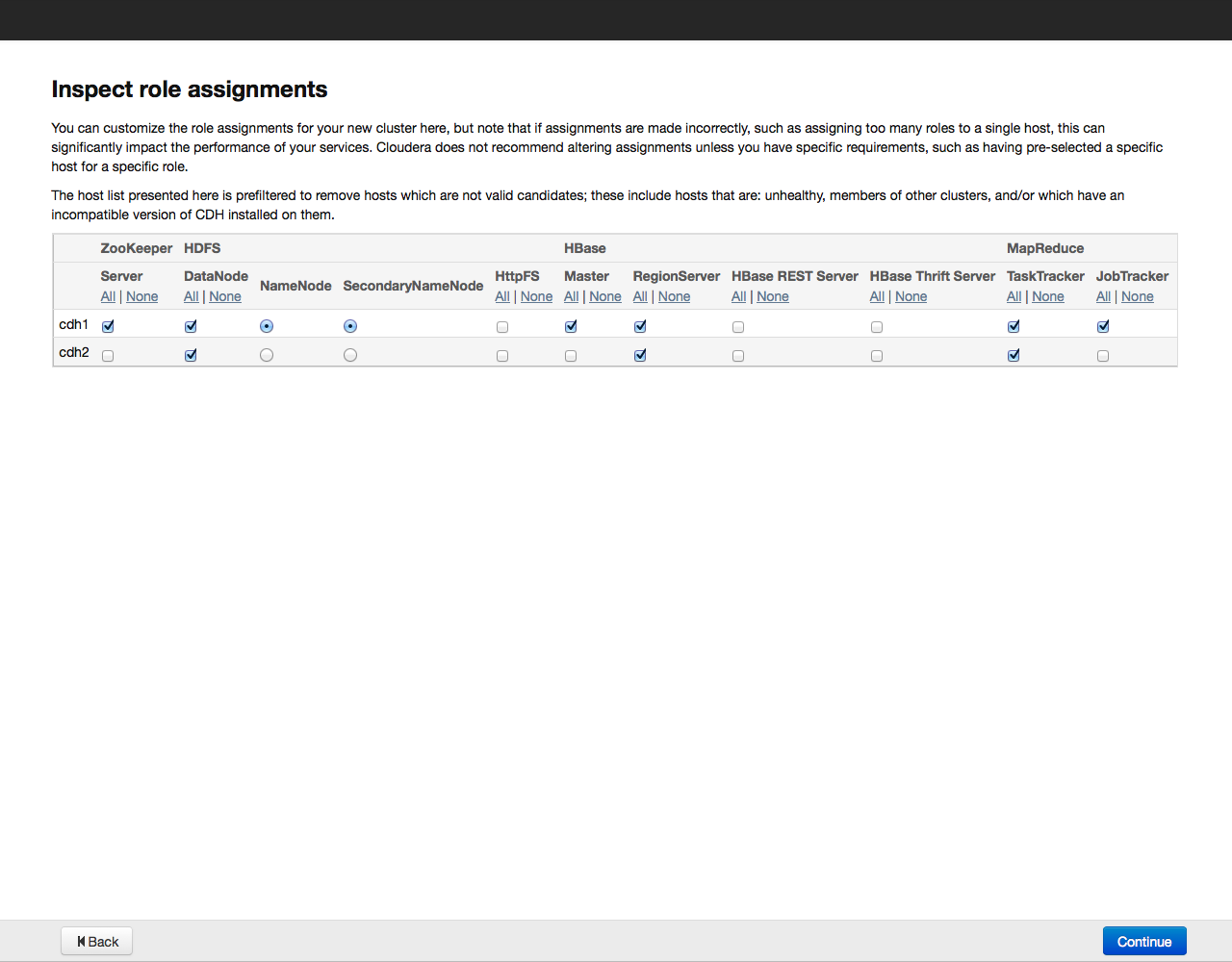
Нажимаем на кнопку Continue и переходим к следующему этапу – настройке базы данных:
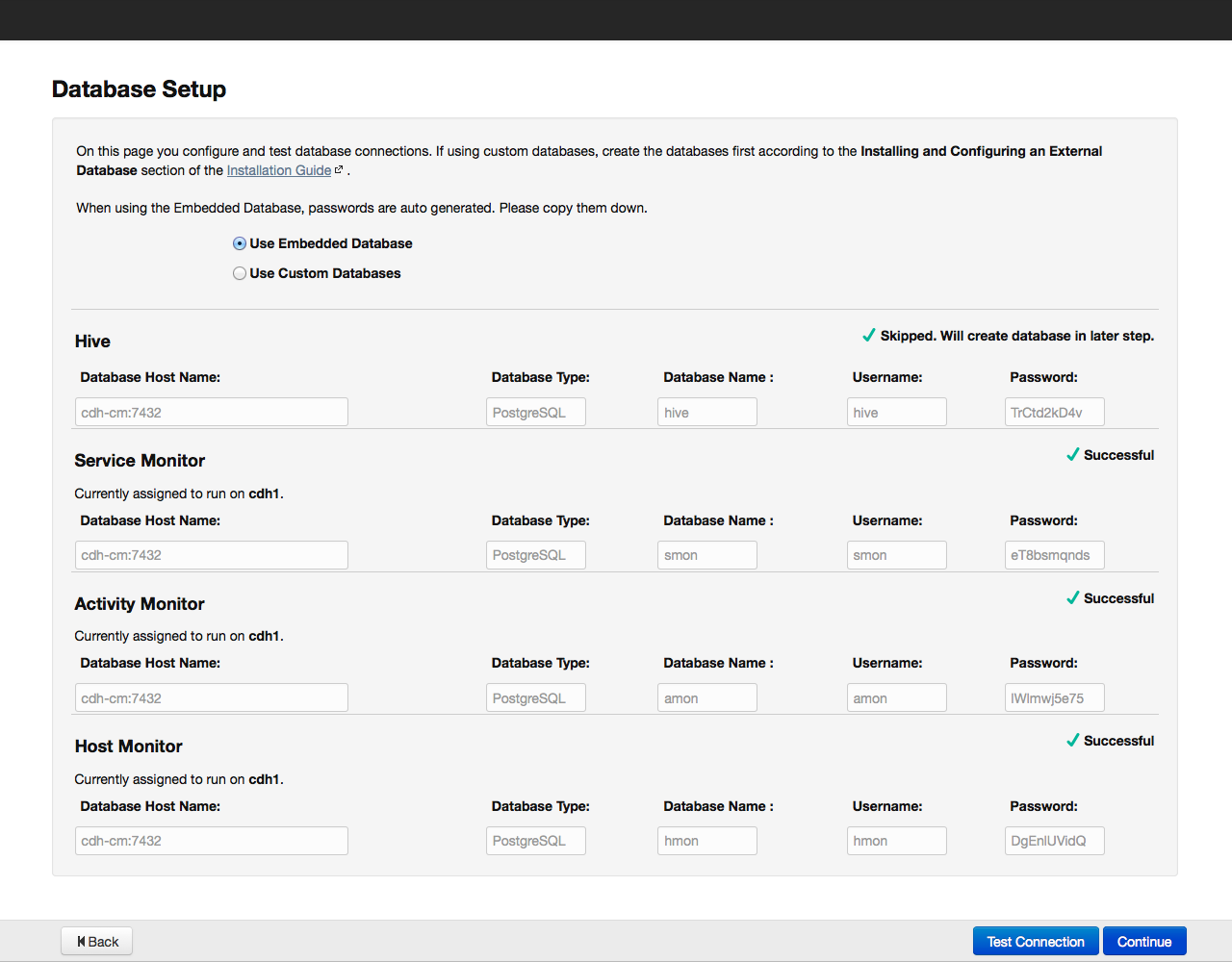
По умолчанию вся информация, имеющая отношение к мониторингу и управлению системой, хранится в базе данных PostgreSQL, которую мы установили вместе с Cloudera Manager. Можно использовать и другие базы данных – в этом случае выбираем в меню пункт Use Custom Database. Установив необходимые параметры, проверяем соединение с базой «Test Connection», и в случае успеха, нажимаем на кнопку «Continue» для перехода к настройке элементов в составе кластера:
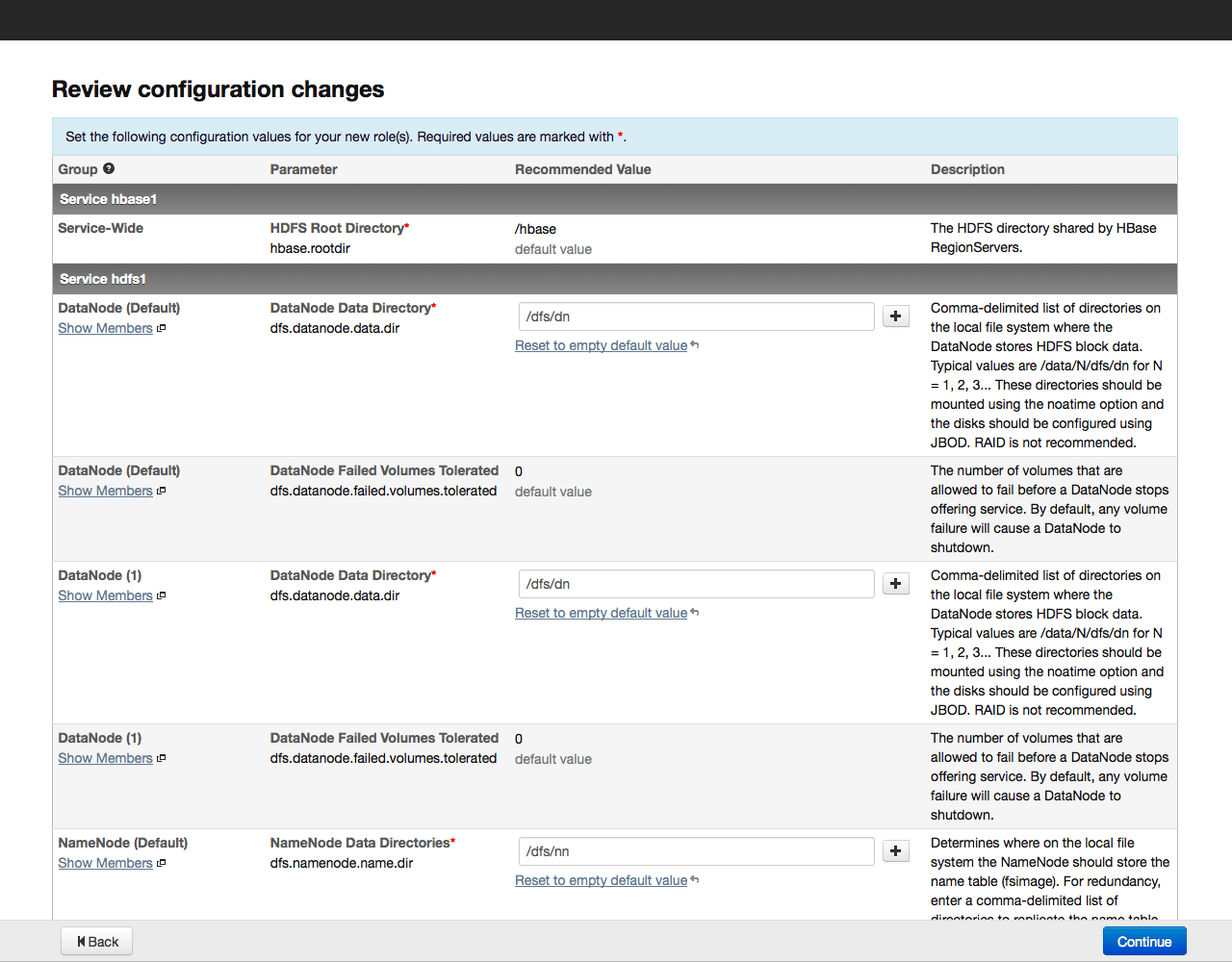
Нажимаем на кнопку Continue и запускаем тем самым процесс настройки кластера. Ход настройки отображается на экране:
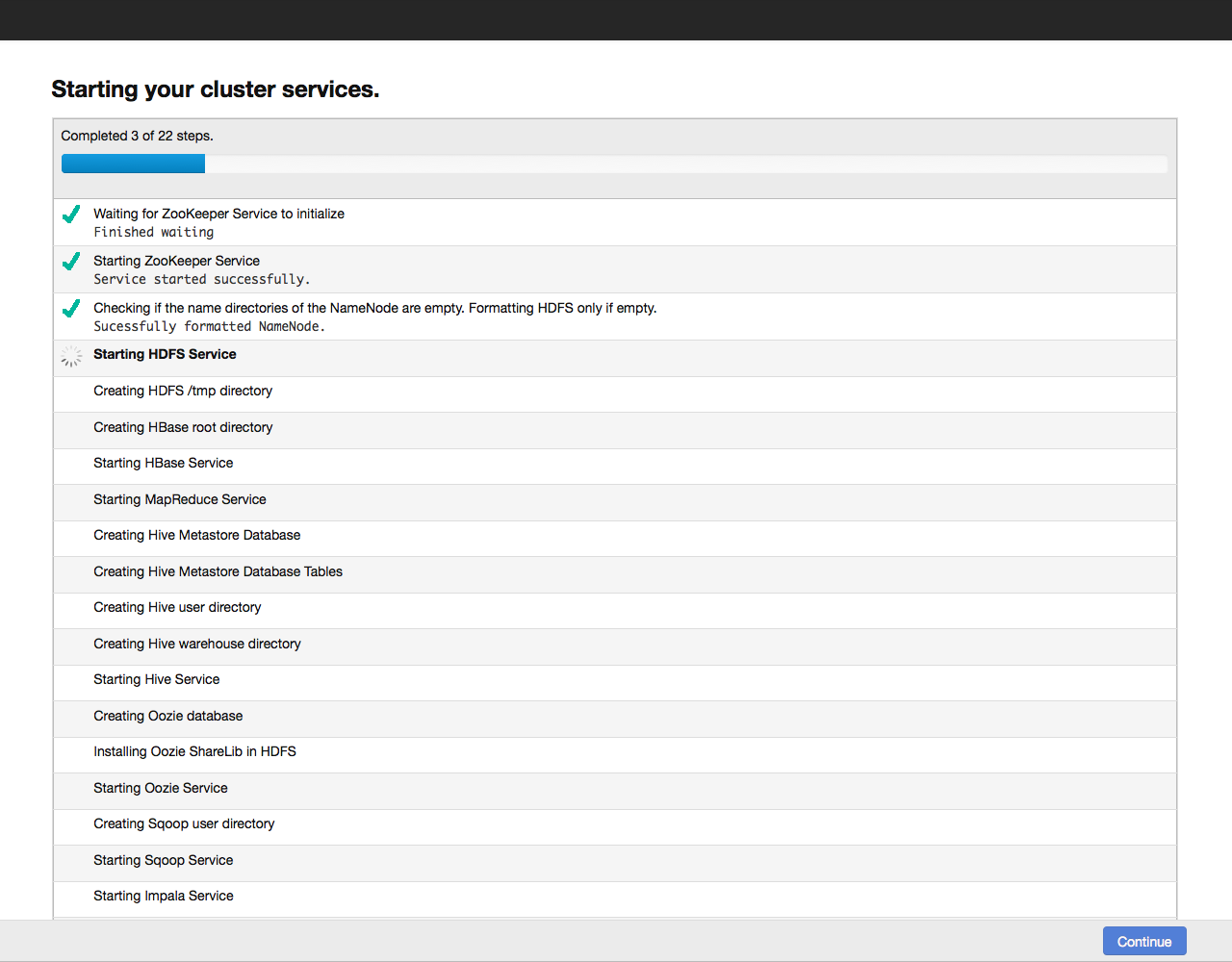
Когда настройка всех компонентов завершится, переходим к дашборду нашего кластера. Для примера вот так выглядит дашборд нашего тестового кластера:
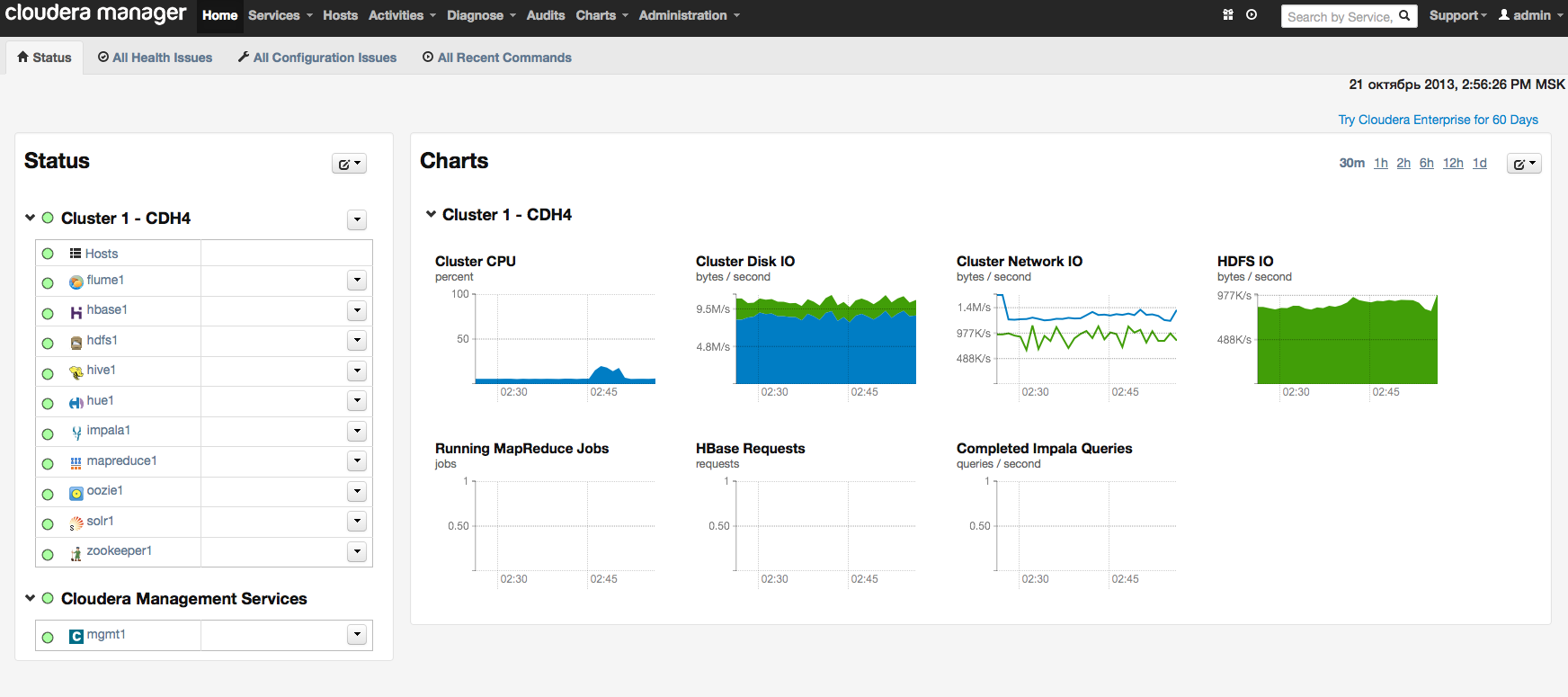
Вместо заключения
В этой статье мы постарались познакомить вас с установкой Hadoop кластера и показать, что при использовании готовых дистрибутивов, таких как Cloudera Hadoop это занимает совсем немного времени и сил. Продолжить знакомство с Hadoop я рекомендую с книгой Тома Уайта «Hadoop: The Definitive Guide», есть издание на русском языке.
Работа с Cloudera Hadoop на примере конкретных сценариев использования будет рассмотрена в следующих статьях цикла. Ближайшая публикация будет посвящена Flume – универсальному инструменту для сбора логов и других данных.
UPD: Адрес DNS — 109.234.159.91 более не поддерживается. Используйте адреса 188.93.16.19 и 188.93.17.19.



