

Привет! Меня зовут Данил, я системный инженер, работаю с серверами и клиентским оборудованием в дата-центре Selectel в Дубровке (Ленобласть). Бывают ситуации, когда диски в серверах работают некорректно. В таком случае нужно быстро определить причину, понять, на чьей она стороне, и исправить проблему. Подробнее об этом рассказываю в тексте.
Наши диски и их особенности работы в дата-центре
Для начала я коротко расскажу о том, какие виды дисков мы используем в выделенных серверах.
HDD SATA (жесткий диск) — запоминающее устройство, работающее на принципе магнитной записи. Самый распространенный вид носителя и дешевый относительно стоимости за 1 ГБ. Существенно проигрывает по скорости записи и чтения данных твердотельным накопителям. Используется интерфейс SATA.
Когда-то в Selectel были доступны HDD-диски с интерфейсом SAS, но сейчас их уже не заказать. Но у нас еще остались клиенты, которые используют такие диски, и мы продолжаем обслуживать серверы с ними.
HDD SAS — жесткие диски с интерфейсом подключения SAS. Как и в случае NVMe U.2, такие диски подключаются в специальный корпус с поддержкой SAS. SAS-интерфейс обратно совместим с SATA, что дает подключать в такой корпус SATA-диски.
SSD SATA — твердотельный накопитель, в котором нет движущихся частей. В основном использует флеш-память. Имеют гораздо большую скорость производимых операций, но в то же время меньшую износоустойчивость, чем HDD.
SSD NVMe PCIe подключаются напрямую в матплату через интерфейс PCI Express x4. Из-за этого таких дисков можно подключить меньше, чем тех же NVMe U.2. Также для данных дисков нет возможности подключения к RAID-контроллеру.
SSD NVMe U.2 — твердотельный накопитель форм-фактора 2.5” с разъемом для подключения U.2. На вид данный диск очень похож на обычный SSD SATA, но имеет другой порт подключения, не совместимый с SATA. При этом SATA-диск можно подключить к разъему U.2. Обладает гораздо большей скоростью записи/чтения по сравнению с SSD SATA.
Преимущества SSD NVMe U.2 перед NVMe PCIe в том, что есть возможность выполнения горячей замены и подключение большого количества дисков, не занимая при этом слоты PCIe на материнской плате. Также такие диски можно подключить к RAID-контроллеру. Если вы хотите добавить SSD NVMe U.2 к в уже имеющийся сервер произвольной конфигурации, необходимо уточнить, если ли в наличии корпус с разъемами U.2 и поддерживает ли материнская плата подключение данных накопителей.
Дисковые корзины
Накопители HDD SATA, SSD SATA и SSD NVMe U.2 подключаются к серверам через дисковые корзины.
Дисковая корзина — это модуль, который используется для подключения определенного количества дисков к серверу. Корзины позволяют легко выполнить подключение или отключение диска в работающем сервере без отключения, вскрытия корпуса и снятия из стойки. То есть выполнить «горячую» замену без даунтайма.

Каждый производитель корпусов использует свои корзины, которые не совместимы с корпусами конкурентов.



Другая ситуация с SSD NVMe PCIe. Этот диск подключается напрямую в матплату, поэтому его без отключения сервера, снятия из стойки и вскрытия корпуса не заменить. К слову, эти диски используются довольно редко, и экстренно менять их на практике мне не доводилось. Единственный раз был связан с плановым апгрейдом сервера клиента и согласованным даунтаймом.
Проблемы в работе диска. Что делать?
При обнаружении проблем с накопителем стоит выполнить первичную диагностику и сообщить результаты в тикет-систему. В случае выявления аппаратной неисправности инженеры дата-центра подготовят накопитель и согласуют этапы проведения замены.
Первичную диагностику можно выполнить средствами ОС или через Rescue.
Rescue — образ LiveCD, основанный на Arch Linux c набором утилит для диагностики, который загружается в оперативную память. Более подробно о Rescue можно прочитать в документации.
Если накопитель не инициализируется в ОС, то по обратной связи инженер дата-центра выполняет переподключение диска. Далее принимается решение о неисправности накопителя.
Существует несколько способов выявить неисправность накопителя:
- проверить SMART показатели,
- оценить заявленную производительность модели накопителя с текущей,
- проанализировать ошибки в журналах событий.
С первыми двумя пунктами ознакомимся более подробно.
Проверка диска SMART
Основным методом оценки неисправности диска является значения атрибутов SMART — технологии оценки состояния жесткого диска встроенной аппаратурой самодиагностики. Более подробно с атрибутами можно ознакомиться по ссылке.
Для просмотра показателей SMART конкретного накопителя потребуется пакет smartmontools. Для ОС Windows его можно найти по ссылке.
Рассмотрим, как вывести информацию о диске на практике.
Для вывода модели с серийным номером и списка атрибутов достаточно ввести следующую команду:
smartctl -iA /dev/sdX, где X — идентификатор накопителя
Примеры вывода команды:
=== START OF INFORMATION SECTION ===
Model Family: <Model Family>
Device Model: <Device Model>
Serial Number: <Serial Number>
LU WWN Device Id: 5 0014ee 058ae9c5c
Firmware Version: 01.01S02
User Capacity: 500 107 862 016 bytes [500 GB]
Sector Size: 512 bytes logical/physical
Rotation Rate: 7200 rpm
Device is: In smartctl database 7.3/5254
ATA Version is: ATA8-ACS (minor revision not indicated)
SATA Version is: SATA 3.0, 3.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Fri Sep 23 11:49:58 2022 RTZ
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 3
3 Spin_Up_Time 0x0027 141 140 021 Pre-fail Always - 3950
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 24
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0
9 Power_On_Hours 0x0032 065 065 000 Old_age Always - 26190
10 Spin_Retry_Count 0x0032 100 253 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 253 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 22
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 20
193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 3
194 Temperature_Celsius 0x0022 117 107 000 Old_age Always - 26
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 200 200 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0
При наличии RAID-контроллера команда может быть следующего вида:
smartctl -iA -d megaraid,2 /dev/sda
Подробнее в manual smartctl.
Также с помощью данной утилиты можно выполнить тестирование или произвести полный вывод с журналом событий о ошибках. Например:
smartctl --test=long /dev/sda — команда запуска теста
smartctl -l selftest /dev/sda — команда вывода результатов теста
Пример вывода команды:
=== START OF READ SMART DATA SECTION ===
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Completed without error 00% 26190
smartctl -x /dev/sda — полный вывод информации о диске
При принятии решения о замене мы ориентируемся на базовые атрибуты и атрибуты конкретной модели накопителя. Также необходимо отметить, что значения определяются по параметрам RAW_VALUE или VALUE в зависимости от атрибута.
Базовые атрибуты для HDD-дисков
| Атрибут | Описание | Условие для замены диска |
| 5 Reallocated_Sector_C | Количество переназначенных секторов | RAW_VALUE отлично от 0 |
| 7 Seek Error Rate | Частота возникновения ошибок при позиционировании блока магнитных головок | VALUE менее 45 |
| 9 Power_on_hours | Наработка часов | RAW_VALUE превышает 43 800* |
| 10 Spin Retry Count | Количество повторов запуска шпинделя, если первая попытка оказалась неудачной | RAW_VALUE более 10 |
| 197 Current_Pending_Sector | Количество секторов в очереди на переназначение | RAW_VALUE отлично от 0 |
| 198 Offline_Uncorrectable | Количество неисправимых секторов | RAW_VALUE отлично от 0 |
* При превышении этого значения диск не становится неисправным — цифра установлена Selectel. После 5 лет эксплуатации требуется замена диска согласно внутренним регламентам.
При росте значений параметров 199 UltraDMA CRC Error Count и 200 Multi_Zone_Error_Rate проявляются проблемы на уровне интерфейса. В данном случае проверяем корректность подключения дисков SATA.
Базовые атрибуты для SSD-дисков
| Атрибут | Описание | Условие для замены диска |
| 184 End-to-End Error Detection Count | Количество ошибок чтения из флэш-памяти | RAW_VALUE более 9 |
| 231 Life Left (SSDs) or Temperature | Остаток жизненного цикла | VALUE менее 11 |
| 232 Available Reserved Space | Количество оставшихся резервных служебных блоков | VALUE менее 11 |
| 233 Media Wearout Indicator | Остаток жизненного цикла у дисков Intel | VALUE менее 11 |
Также существуют атрибуты модели, которые можно узнать на официальном сайте конкретного производителя.
Проверка скорости чтения
Еще один немаловажный параметр — это скорость работы диска.
Заявленную скорость можно посмотреть на официальном сайте производителя. Учитывайте, что реальная скорость может отличаться от заявленной производителем. Чтобы быстро проверить скорость чтения, можно воспользоваться утилитой hdparm (для Linux):
hdparm -Tt /dev/sda
Также можно произвести полноценное нагрузочное тестирование с помощью утилиты fio, оценив показатели IOPS. Подробнее можно почитать здесь.
Как правильно составить обращение к провайдеру
Корректная формулировка тикета позволит быстрее решить проблему.
Сотрудникам техподдержки не придется задавать дополнительные вопросы, а значит, инженер скорее получит нужную информацию и приступит к решению проблемы.
В заголовке тикета укажите суть проблемы (в нашем случае — неисправен диск) и ID сервера.
В теле тикета необходимо добавить следующую информацию:
- Название и ID сервера.
- Буквенное обозначение (идентификатор в ОС) и серийный номер неисправного диска. Если диск перестал определяться в системе, то необходимо написать S/N всех “здоровых” накопителей.
- Приложить показатели SMART, выводы скорости записи/чтения, описать другие ошибки, связанные с диском.
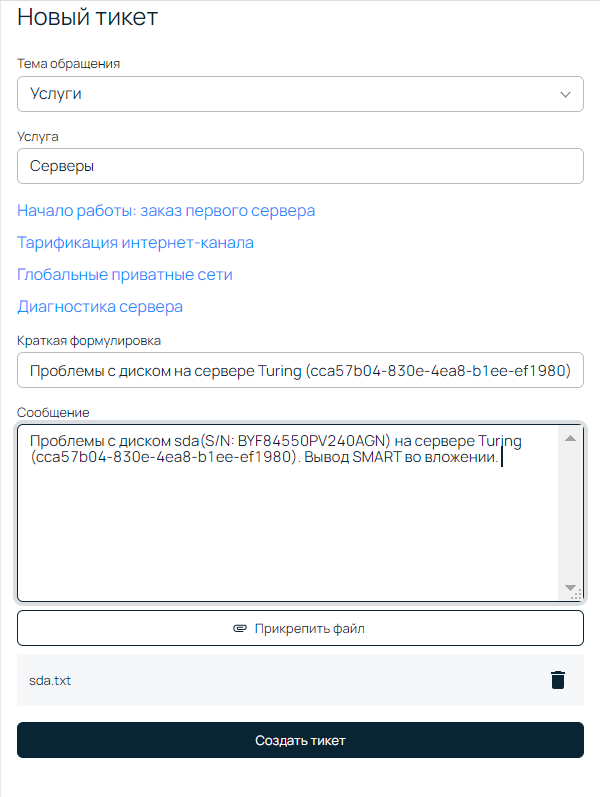
Тикет у инженера
Анализ информации
После получения данных инженер их анализирует.
Для проверки SMART мы в Selectel используем самописного бота в Telegram. Боту отправляется полный вывод команды smartctl. Он, в свою очередь, в зависимости от типа диска и вендора проверяет определенные атрибуты и выносит «приговор» — подлежит ли данный диск замене. Именно поэтому мы всегда рекомендуем отправлять вывод SMART текстом, а не скрином.
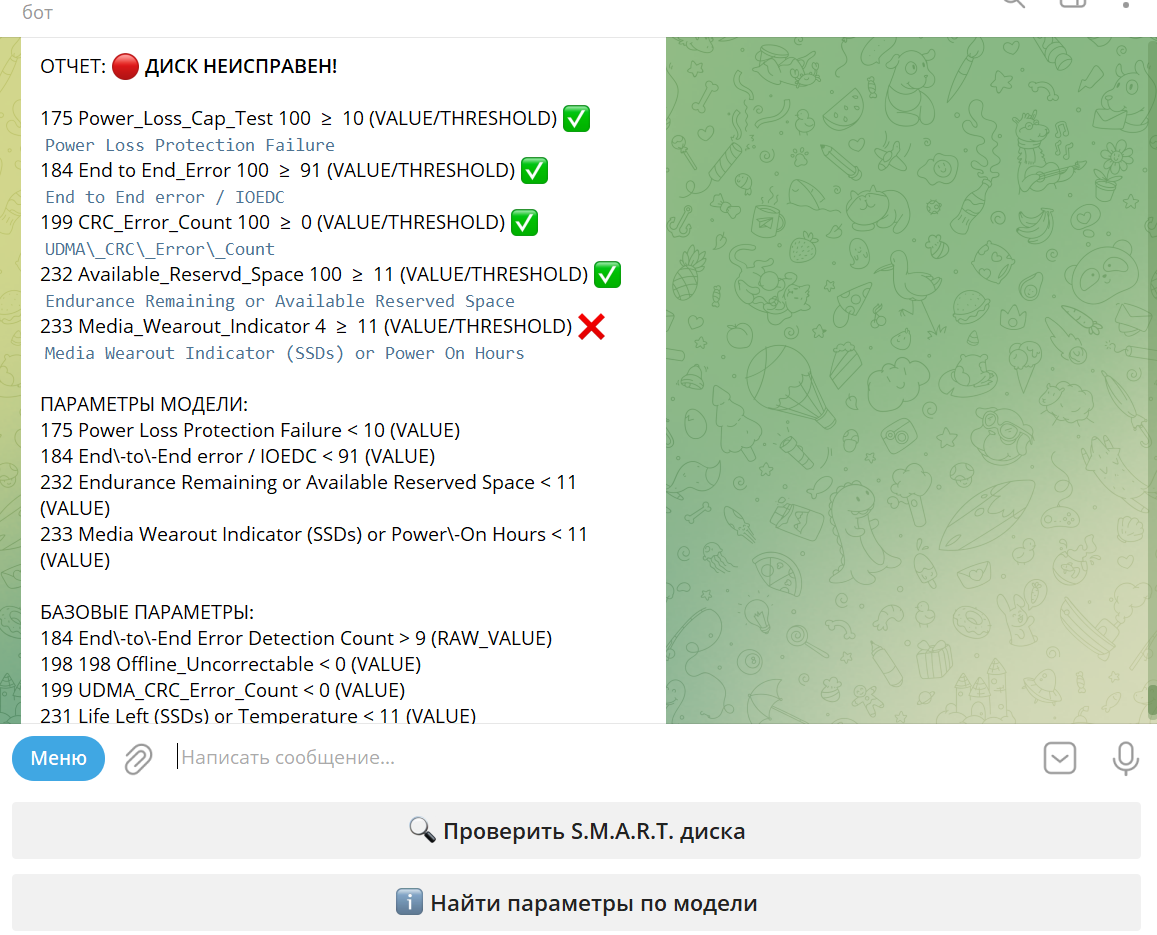
Подготовка диска
Если неисправность диска подтверждается, то инженер приступает к подготовке носителя для замены. Для быстрого решения проблемы такие диски находятся на складе в определенном месте — они уже проверены и готовы к добавлению в сервер. Инженеру остается накрутить нужную корзину и согласовать с клиентом время замены.
Идентификация проблемного диска
Перед заменой клиенту необходимо вывести диск из RAID-массива (если массив используется) и «подсветить».
Существует несколько способов подсветки диска в Linux:
- Самый простой способ — воспользоваться встроенной утилитой dd:
dd if=/dev/sdX of=/dev/null bs=4M, где Х — идентификатор диска
- Вариант с использованием libstoragemgmt:
Включить fault led ячейки — ledon /dev/sdX
Выключить fault led ячейки — ledoff /dev/sdX
- Утилита ledctl:
Включить — ledctl locate=/dev/sdX
Выключить — ledctl locate_off=/dev/sdX
Если диски подключены к RAID-контроллеру, подсветка включается через утилиты вендора — например arcconf, storcli.
После этого необходимо сообщить в тикете о включении индикации. Инженер Selectel со своей стороны смотрит индикацию на дисках, определяет нужный диск и просит клиента остановить действие подсветки. Так он убеждается, что неисправный диск определен верно.
Далее инженер выполняет замену диска и сообщает об этом клиенту, чтобы тот проверил, определился ли новый диск в ОС.
Бывают случаи, что индикация не срабатывает на корзине. В такой ситуации замену диска можно выполнить только с отключением сервера, то есть даунтаймом.
Мы заменили диск. Что дальше?
Самая сложная часть позади. Клиент может продолжать пользоваться своим сервером.
Неисправный диск инженер передает в отдел сборки. Там его полностью очищают от данных с помощью специальных программ.
Далее может произойти два варианта развития событий:
- Если на диск еще действует гарантия, он будет отправлен поставщику.
- Диск можно будет вылечить с помощью специального ПО.
Если первые два варианта не подошли — например, носитель не записывает информацию и не подлежит ремонту, он будет ждать утилизации. Неисправные диски из Аттестованного ЦОД уничтожаются с помощью специального устройства.






