

Я Наташа, UX-исследователь в Selectel. Последние полгода я исследую опыт взаимодействия с серверной операционной системой. Сегодня расскажу о метриках, с помощью которых мы оценивали наши успехи в повышении производительности сетевого стека.
Почему я этим занимаюсь? Потому что самые частые пожелания к серверной ОС — стабильность, надежность и производительность. Моя задача — превратить эти абстрактные ожидания в конкретные кейсы и UX-задачи.
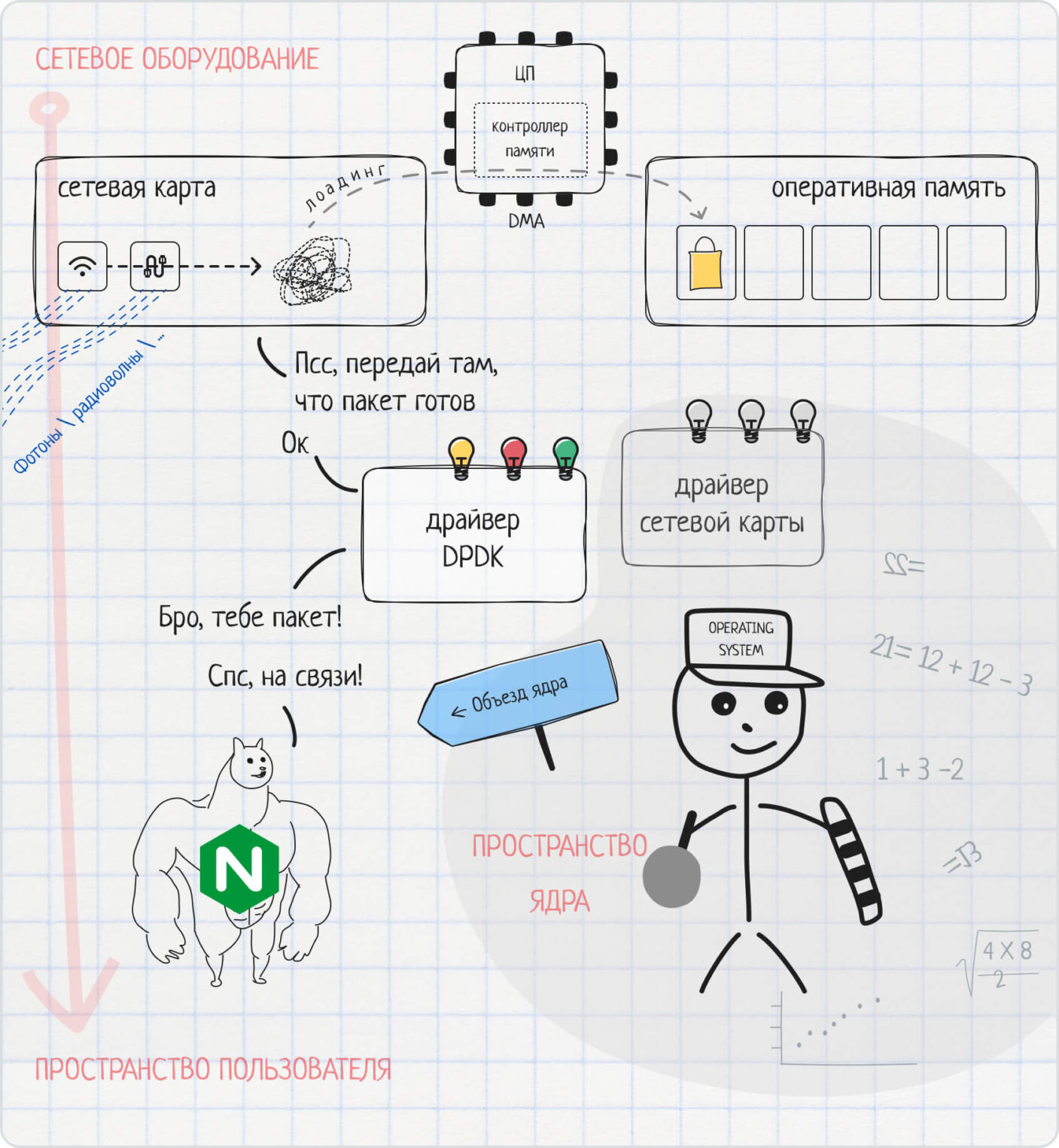
Что такое kernel bypass
В Unix-подобных операционных системах есть проблема производительности сетевого стека. Она связана с тем, что ядро операционной системы не слишком эффективно справляется с высокой сетевой нагрузкой, то есть с передачей данных в больших объемах.
Так случилось, потому что Unix-ядро было разработано для своего времени, когда серверы в первую очередь были мощными вычислительными машинами. Сетевая нагрузка появилась позже и не сразу достигла сегодняшних объемов. Получается, ядро операционной системы задействовано в очень большом количестве процессов: сетевых, фоновых, вычислительных. Чтобы обработать сетевой трафик, ядро вынуждено прерываться, менять контекст, отвечать на системные вызовы. Это создает заторы на пути сетевых пакетов и замедляет скорость передачи данных.
Операционные системы на базе Linux получили эту проблему по наследству от Unix-ядра. Конечно, были разработаны решения для улучшения ситуации, такие как DMA, NewAPI. Но чтобы повысить скорость передачи данных в более заметных масштабах, применяется технология обхода ядра — kernel bypass.
Например, можно применить DPDK: добавить специальный модуль в приложение, настроить сетевой драйвер DPDK и обойти ядро. Данные будут попадать напрямую от сетевой карты в целевое приложение, не отвлекая ядро операционной системы от своих дел.
Как мы начали ускорять сетевой стек
Недавно мы в Selectel презентовали собственную серверную ОС. Здесь же я расскажу о том, что в ходе работы над ускорением сетевого стека мы применили DPDK к Nginx:
- подключили нужные модули к Nginx,
- настроили драйверы DPDK для разных сетевых карт,
- протестировали решение и сняли бенчи.
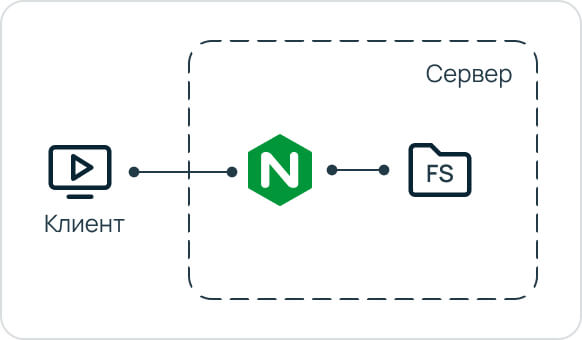
Почему первым (но не единственным) модифицированным приложением стал Nginx? Потому что наши исследования показали его высокую востребованность в серверной инфраструктуре. Конечно, Nginx и так довольно шустрый, ведь он создан решить проблему десятков тысяч соединений, но даже такую производительность удалось улучшить. Это оказалось особенно актуальным для стриминговых и веб-сервисов, которые отдают много статического контента и работают примерно по такой схеме:
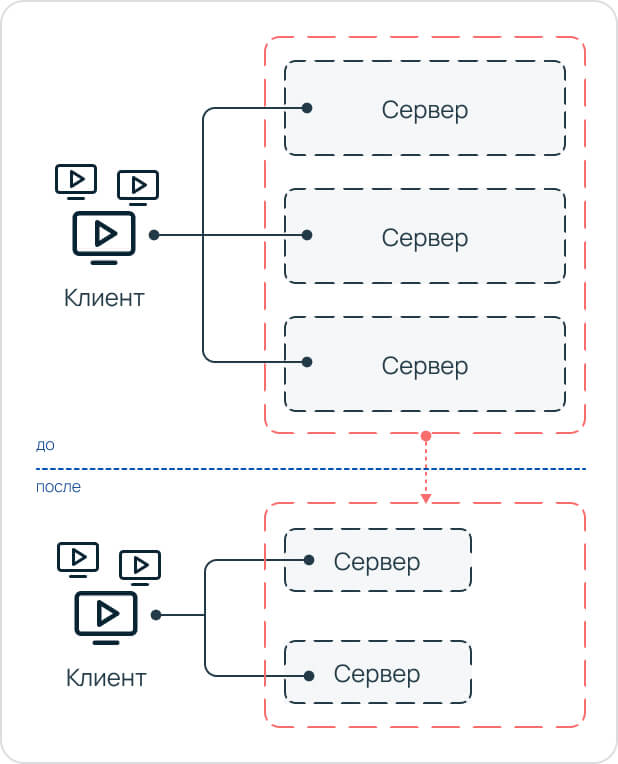
Прирост производительности позволил бы сократить качественно-количественный состав серверного железа при той же сетевой нагрузке. Например, изначально было три дорогих мощных сервера, которые обслуживали трафик. А после модификации — два менее мощных и, соответственно, более дешевых.
Как мы тестировали внедрение DPDK
Проблема тестирования разработок под highload в том, что синтетически создать высокую нагрузку сложно. Особенно, когда речь идет о сравнении двух решений и нужно минимизировать рандом в нагрузке, снять «чистые» бенчмарки, замерить именно работу приложения с железом. В итоге первые тесты для ванильного и «ускоренного» Nginx мы проводили на десктопном железе.
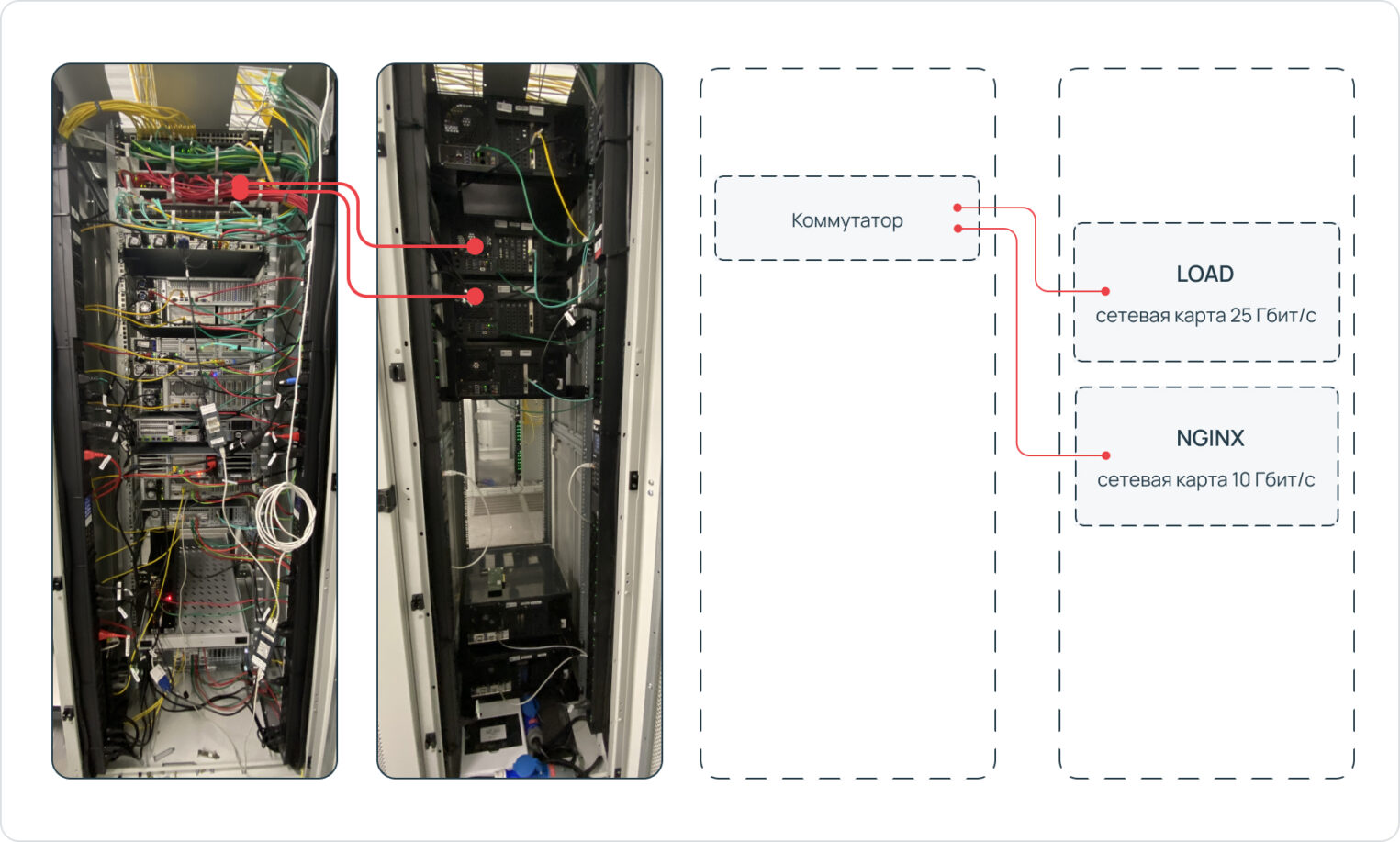
Тестовый стенд — это две машины с десктопным железом. Одна — сервер, вторая — клиент. С клиента создается нагрузка — улетают запросы на сервер. На сервере развернут Nginx, который принимает запросы и отдает ответы. Машины подключены друг к другу через коммутатор. К коммутатору кроме тестового стенда больше ничего не было подключено, чтобы исключить погрешность сети.
| Технические характеристики тестового «сервера» | |
| NIC: | Intel Corporation Ethernet Controller X710 for 10GbE SFP+ (rev 02) |
| CPU | AMD Ryzen 9 7950 X 16-Core Processor |
| Memory | 128GB |
| OS | SelectOS GNU/Linux 1.0 (alpha) |
| Kernel | Linux 6.1.0-22-amd64 |
| Nginx version | nginx/1.25.2 |
На «клиент» поставили сетевую карту помощнее — 25 Гбит/с, а для «сервера» с Nginx — послабее, 10 Гбит/с. Мы думали, что это даст нам возможность загрузить все ядра ЦП сервера, но об этом отдельно. При этом на одном и том же «сервере» сначала тестировали ванильный Nginx, а потом заменяли его на «ускоренный», не меняя характеристики железа.
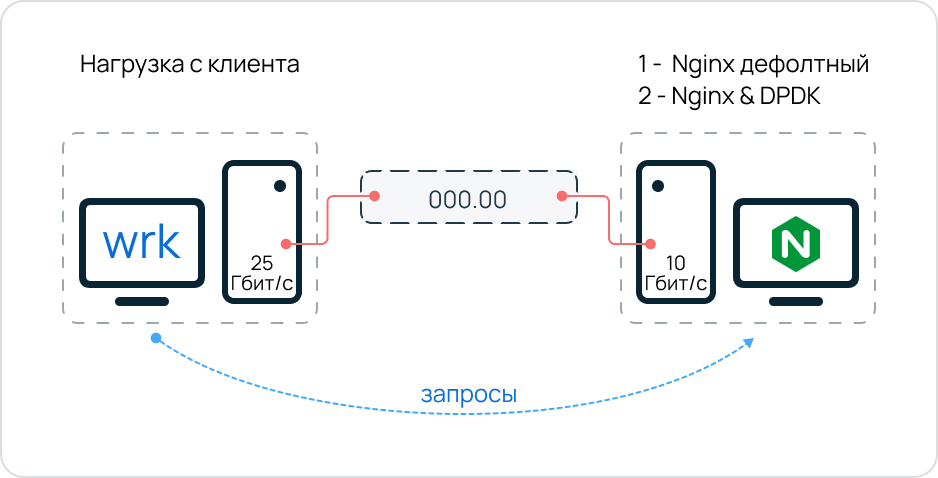
Нагрузку задавали с помощью утилиты wrk:
- регулировали вручную количество потоков,
- эмпирически вычисляли оптимальное количество соединений (достаточно для нагрузки, но не так много, чтобы появлялись ошибки).
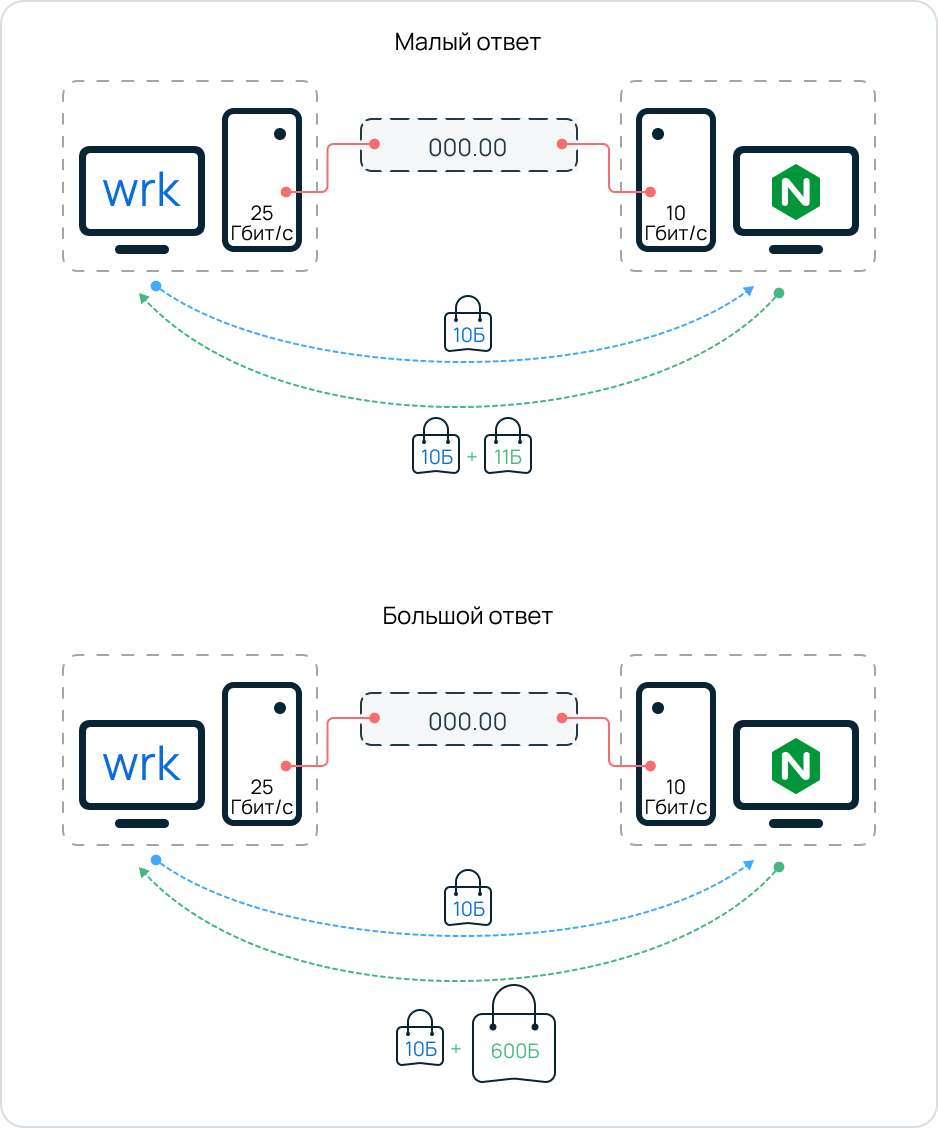
Каждую из версий Nginx тестировали в двух вариантах, отправляя разный ответ:
- малый пакет данных — буквально 21 байт,
- большой (относительно первого) пакет данных — 610 байт.
Вот так выглядела команда утилиты wrk:
wrk -t 32 -c 1000 -d 60s http://10.10.10.10/test_small
- -t — количество потоков,
- -c — количество соединений,
- -d — длительность нагрузки.
В обоих случаях тест заключался в следующем:
- Машина-клиент отправляет легкий запрос;
- Машина с Nginx получает запрос и отправляет ответ (малый в 11 байт или большой в 600 байт);
- Мы фиксируем количество ответов, которые успешно вернулись на клиентскую машину без ошибок;
- Перезапускаем утилиту до 32 раз для разного количества потоков.
Для наглядности нарисовала схему, которая показывает, как все происходило. Для каждой версии Nginx (ванильной и ускоренной) прогоняли по два варианта теста с единственной разницей в величине ответного пакета. И делали до 32 вариаций команды утилиты, добавляя количество потоков, то есть всего запускали утилиту около 100 раз.
Результаты внутреннего тестирования: RPS и latency
Ниже вы увидите графики роста RPS (requests per second) в зависимости от количества загружаемых потоков для четырех случаев:
- Nginx&DPDK при ответе большим пакетом (красный),
- Nginx&DPDK при ответе малым пакетом (зеленый),
- Nginx vanilla при ответе большим пакетом (синий),
- Nginx vanilla при ответе малым пакетом (желтый).
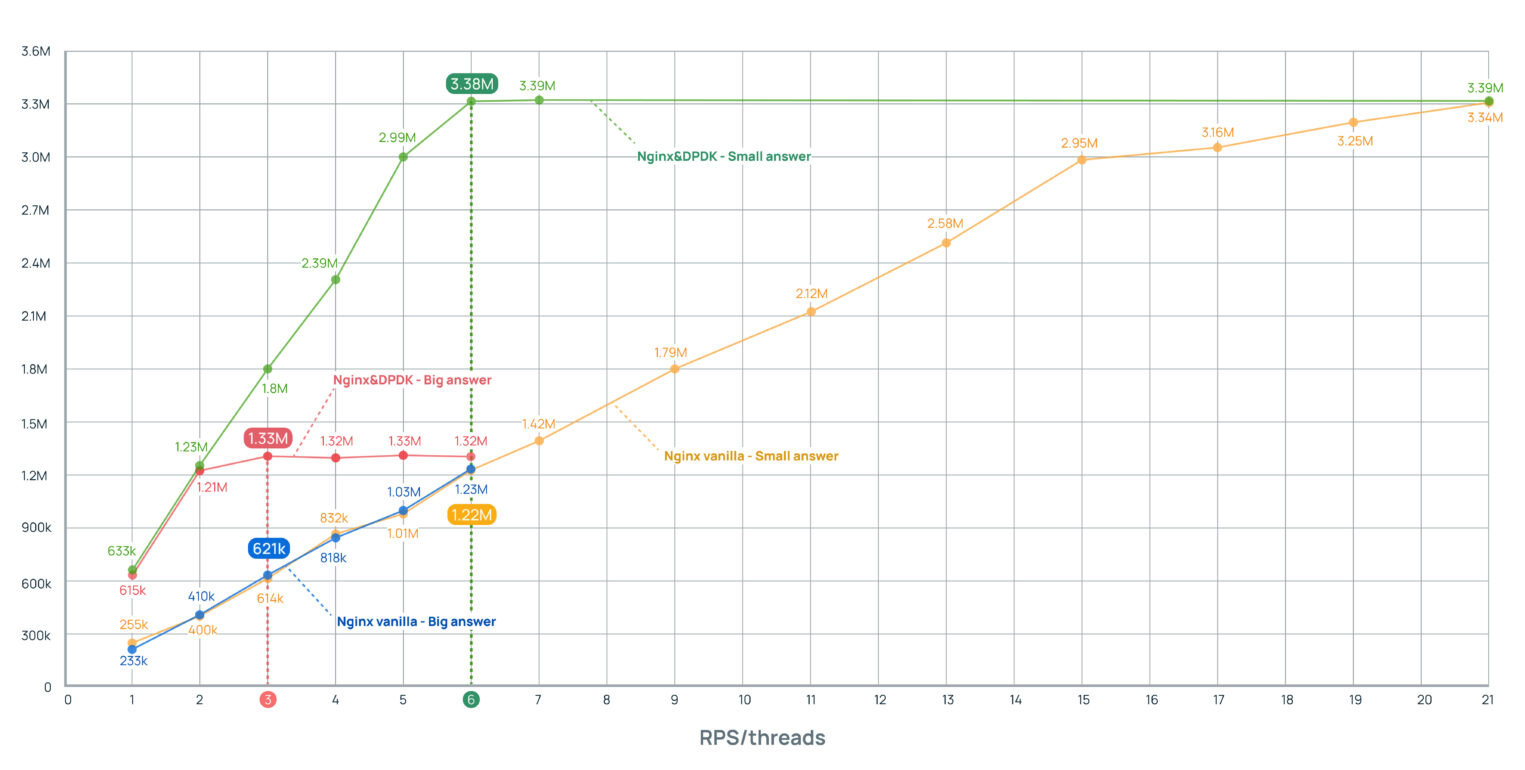
На этих графиках мы видим, что в случае модифицированного Nginx рост RPS быстро упирается в пропускную способность сетевой карты. В зависимости от величины пакета это происходит раньше или позже. На третьем потоке — для большого ответа (красный график), на шестом потоке — для малого ответа (зеленый график). Эти точки стали для нас опорными в сравнении.
- Для малого пакета данных шесть потоков работают как 21, с практически трехкратным приростом RPS (3,38M против 1,22М).
- Для крупного пакета три потока работают как шесть, но прирост RPS остается значительным — практически x2 (1,33M против 621К).
- Замеры для стандартного Nginx заканчиваются на 6 и 21 потоках, потому что в этих точках они достигают значений максимума для модифицированного Nginx.
- Бенч latency не дал внушительной разницы, потому что машины были подключены через коммутатор, что свело сетевые задержки к минимуму на физическом уровне для любой версии Nginx.

Вместо заключения
Синтетическое тестирование подсветило для нас следующие моменты.
- В случае модифицированного Nginx упираемся в пропускную способность сетевой карты при меньших вычислительных ресурсах ЦП.
- В «стерильных» условиях прирост производительности заметен, а значит решение достойно тестирования в продакшене.
Сейчас мы внедряем нашу операционную систему SelectOS c модифицированным Nginx в некоторые существующие инфраструктурные решения клиентов и даем продовую нагрузку. Вот некоторые реальные запросы клиентов, которые мы хотим удовлетворить своим решением:
- уменьшить количество серверов,
- сократить затраты на электроэнергию и уменьшить износ оборудования за счет повышения производительности Nginx на том же железе,
- добиться гибкого масштабирования благодаря отсутствию потребности в дополнительной ноде при сезонном увеличении трафика.





