Как использовать балансировщик MetalLB с BGP-anycast
Показываем, как с помощью сетевых сервисов Selectel и Managed Kubernetes настроить основу для геораспределенной инфраструктуры.
Клиенты часто спрашивают, как построить геораспределенный и катастрофоустойчивый Kubernetes. Так, чтобы при отказе целого дата-центра нагрузка переключалась на резервную площадку без смены IP-адресов сервисов.
Можно возразить, что проще изменить DNS-запись и направить трафик на инстанс в другом дата-центр. Но есть риск: кэширование на рекурсорах некоторых провайдеров может негативно повлиять на доступность. Они иногда игнорируют TTL и хранят старые данные неопределенный срок. Поэтому в таких сценариях крайне желательно сохранить IP-адрес.
Один из элементов «мозаики» такой геораспределенной системы — балансировщик нагрузки с возможностью использования адресов из anycast-подсети, которую выделяет поставщик услуг. В этой инструкции мы не будем затрагивать вопрос передачи данных и их консистентность на двух разных площадках — разберем только сетевую составляющую.
Сетевая схема
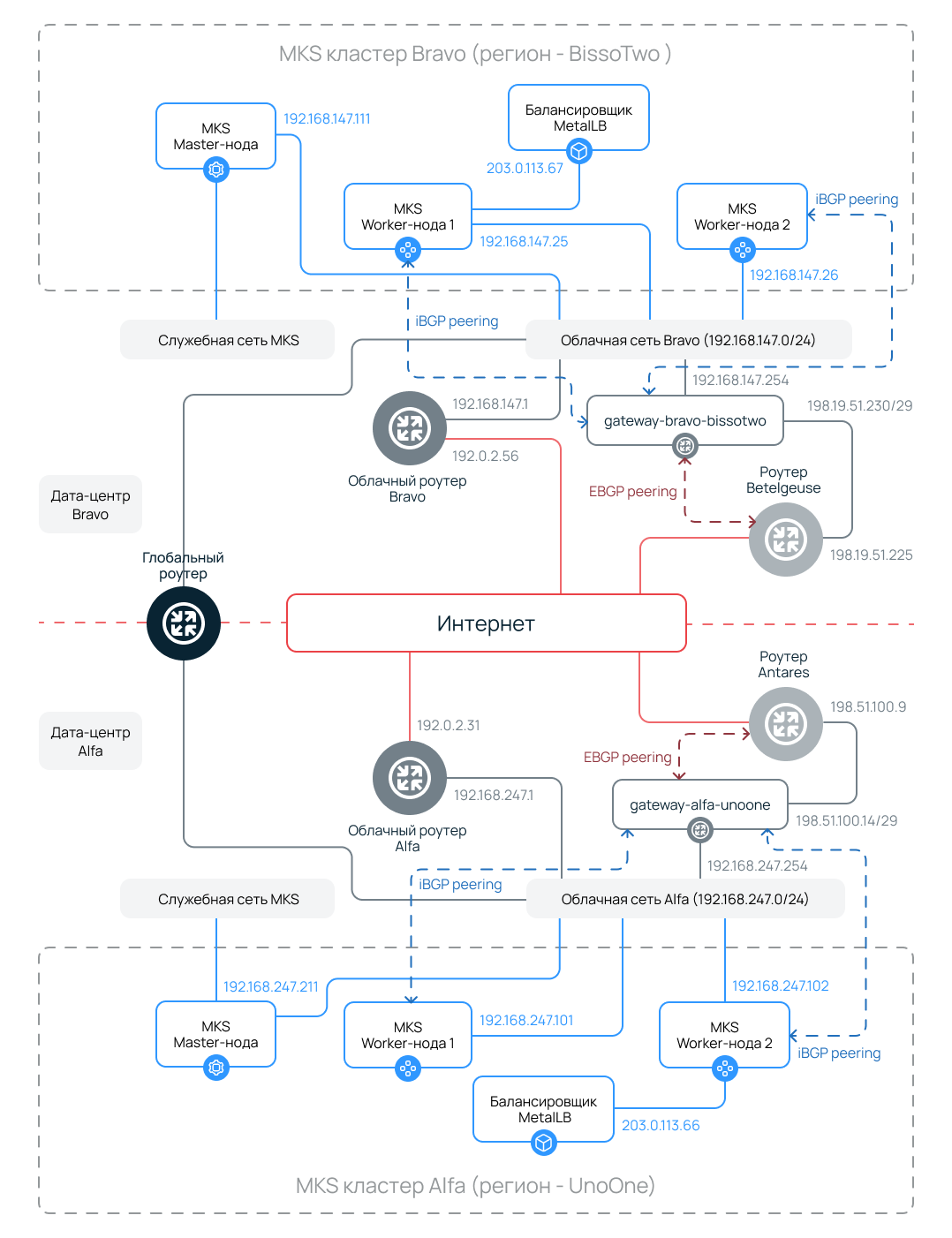
Многовато на первый взгляд, правда? Схема описывает распределенную отказоустойчивую конфигурацию на основе кластеров Managed Kubernetes (MKs), которая развернута в двух регионах.
- Bravo — BissoTwo, регион Москва, пул ru-7.
- Alfa — UnaOne, регион Санкт-Петербург, пул ru-3.
Инфраструктура использует внутренних и внешний BGP-пиринг для маршрутизации трафика между узлами, облачными роутерами, балансировщиками и маршрутизаторами Selectel (на схеме — Betelgeuse и Antares).
Дата-центр Bravo
Характеристики кластера MKs
- Мастер-нода: 192.168.147.111 — управляющая нода кластера.
- Рабочая нода 1: 192.168.147.25
- Рабочая нода 2: 192.168.147.26
- Балансировщик MetalLB: 203.0.113.67 — внешний IP для сервисов в кластере.
Сеть и маршрутизация
- Служебная сеть MKs — связывает мастер-ноды кластера и используется для доступа к kube API, мониторинга и обслуживания со стороны провайдера.
- Облачная сеть Bravo: 192.168.147.0/24 — подключена к облачному роутеру Bravo (192.168.147.1), который используется для резервного доступа в интернет и публичных IP-адресов вне anycast-пула.
- gateway-bravo-bissotwo (192.168.147.254) — шлюз, через который трафик по умолчанию выходит в интернет и на котором развернуто ПО, обеспечивающее работу BGP (забегая вперед — frrouting); на этой машине также настраивается трансляция сетевых адресов с использованием netfilter/nftables.
- IBGP peering между рабочими нодами и шлюзом gateway-bravo-bissotwo.
- EBGP peering между шлюзом и роутером Betelgeuse (198.19.51.230/29).
Дата-центр Alfa
Характеристики кластера MKs
- Мастер-нода: 192.168.247.211
- Рабочая нода 1: 192.168.247.101
- Рабочая нода 2: 192.168.247.102
- Балансировщик MetalLB: 203.0.113.66
Сеть и маршрутизация
- Служебная сеть MKs — связывает мастер-ноды кластера и используется для доступа к kube API, мониторинга и обслуживания со стороны провайдера.
- Облачная сеть Alfa: 192.168.247.0/24 — подключена к облачному роутеру Alfa (192.168.247.1).
- gateway-alfa-unoone (192.168.247.254) – шлюз.
- IBGP peering между рабочими нодами и шлюзом gateway-alfa-unoone.
- EBGP peering между шлюзом и роутером Antares (198.51.100.9).
Межрегиональное взаимодействие
Глобальный роутер не участвует в организации BGP и anycast. Он необходим для обмена трафиком внутри сетевого периметра без использования интернета — например, чтобы настроить репликацию баз данных или организовать Hot Standby между регионами.
Также обеспечена отказоустойчивость: при недоступности одного региона трафик перенаправляется в другой с использованием anycast-маршрутизации. Разумеется, если балансировщики MetalLB работают с общими для двух кластеров внешними IP-адресами.
Типы пиринга
В схеме используются два типа пиринга. Внутри каждого региона между рабочими нодами и виртуальным шлюзом в соответствующем пуле облака настраивается iBGP (Internal BGP). Это обеспечивает корректное распространение маршрутов внутри автономной системы (AS). Связь с внешними сетями и маршрутизаторами Selectel (Betelgeuse, Antares) реализуется через eBGP (External BGP). Этот уровень отвечает за обмен маршрутами между шлюзами и глобальной сетевой инфраструктурой.
Безопасность и отказоустойчивость
Отказоустойчивость системы обеспечивается работой в двух независимых регионах облачной платформы. Динамическое перенаправление трафика между ними реализовано с помощью BGP-пиринга: внешние IP-адреса (203.0.113.64–203.0.113.71) анонсируются из обоих регионов одновременно. Это позволяет использовать anycast-схемы или быстрое переключение (failover) при сбоях. За балансировку нагрузки на уровне L4 внутри кластеров отвечает MetalLB.
IP-адресация
| Компонент | IP-адрес | Примечание |
| Bravo Master | 192.168.147.111 | |
| Bravo Worker 1 | 192.168.147.25 | |
| Bravo Worker 2 | 192.168.147.26 | |
| Bravo Gateway | 192.168.147.254 | Внутренний IP |
| Bravo Gateway | 198.19.51.230 | Внешний IP |
| Bravo Router | 192.168.147.1 | |
| Alfa Master | 192.168.247.211 | |
| Alfa Worker 1 | 192.168.247.101 | |
| Alfa Worker 2 | 192.168.247.102 | |
| Alfa Gateway | 192.168.247.254 | Внутренний IP |
| Alfa Gateway | 198.51.100.14 | Внешний IP |
| Alfa Router | 192.168.247.1 | |
| Cloud Router Bravo | 192.0.2.56 | Внешний IP облачного роутера. Выделяется при создании. |
| Cloud Router Alfa | 192.0.2.31 | Внешний IP облачного роутера. Выделяется при создании. |
| MetalLB Bravo | 203.0.113.67 | Внешний IP для сервисов в k8s |
| MetalLB Alfa | 203.0.113.66 | Внешний IP для сервисов в k8s |
| Betelgeuse (EBGP) | 198.19.51.2 | IP роутера Selectel в линковочной сети |
| Antares (EBGP) | 198.51.100.9 | IP роутера Selectel в линковочной сети |
Взаимодействие по BGP
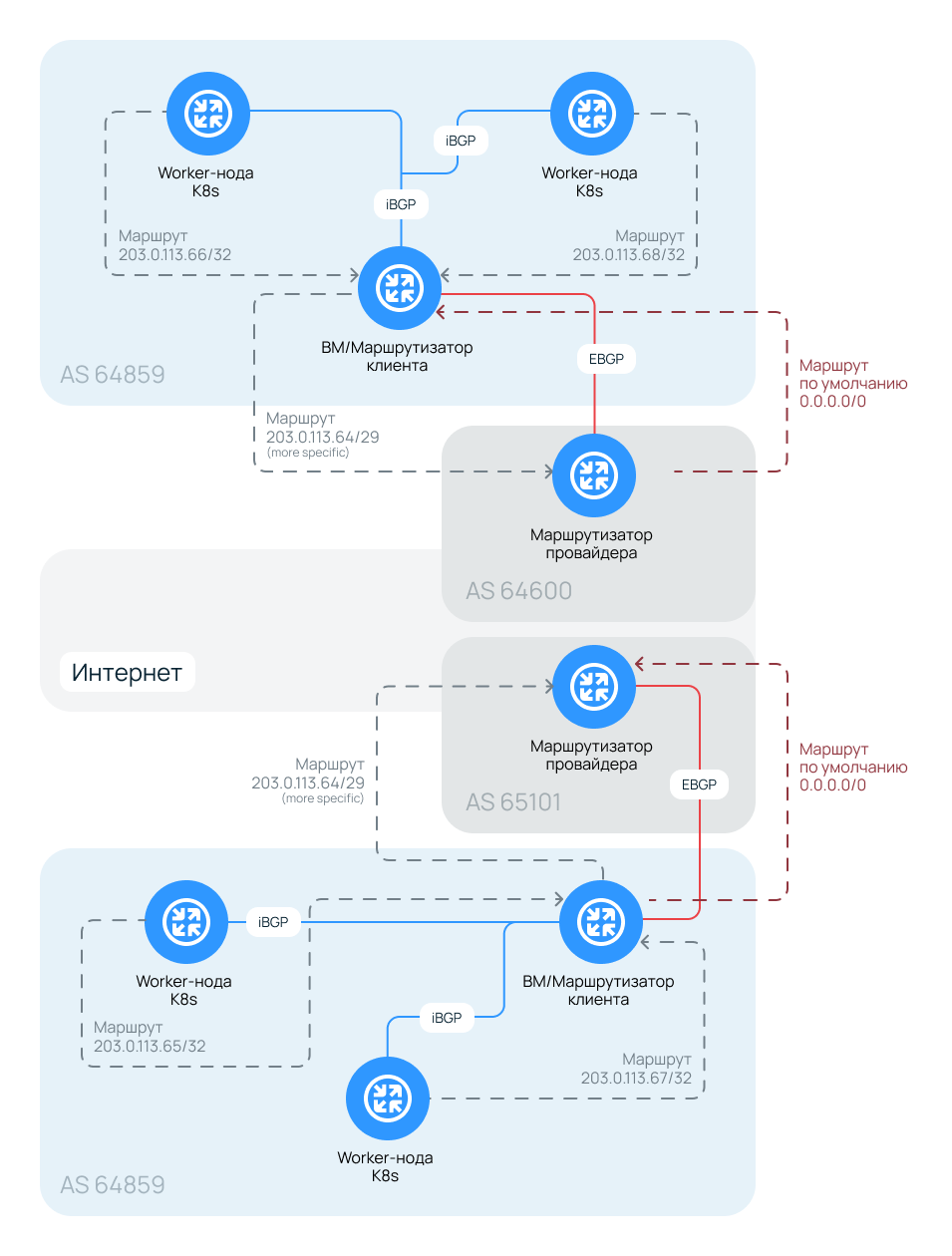
Как в такой схеме организован обмен маршрутами? В примере используются три автономные системы: две принадлежат провайдеру (AS 64600 и AS 65101), а одна — частная (например, AS 64859). Номер частной AS необходимо заранее согласовать с инженерами Selectel.
Провайдер передает нам маршрут по умолчанию (default route), а мы анонсируем в ответ сеть 203.0.113.64/29. При этом виртуальный шлюз может транслировать и более специфичные маршруты (с маской больше /29), если они появятся в таблице маршрутизации. Для этого в конфигурации BGP-демона должны быть активны опции redistribute static или redistribute connected. Маршруты, полученные по iBGP от других «соседей», будут перераспределяться автоматически.
Специфичные маршруты, например /32 для конкретных IP, шлюз получает от балансировщика MetalLB, когда в Kubernetes-кластере создается сервис типа LoadBalancer. Далее шлюз анонсирует их через пиринг с роутерами Selectel «в мир». Такой подход и обеспечивает региональную отказоустойчивость.
Настройка схемы
Описанный процесс настройки подходит не только для кластеров Managed Kubernetes, но и для self-managed кластера Kubernetes, в том числе на выделенных серверах.
1. Заказываем две публичные подсети. В панели управления Selectel это можно сделать в разделе Продукты → Облачные серверы → Сеть → Публичные сети. Эти подсети будут использованы как линковочные.
2. Заказываем BGP + anycast-подсеть. Потребуются линковочные подсети из п.1. один. Процесс описан в документации.
В примере используются:
- подсеть 198.19.51.224/29 — для Bravo,
- подсеть 198.51.100.8/29 — для Alfa.
Не забываем указать в тикете, что при настройке BGP-соседства будет использоваться bidirectional forwarding detection.
3. Выбираем по адресу из каждой линковочной подсети. Эти адреса следует сообщить в тикете для настройки BGP peering-а. В примере взяты:
- 198.19.51.230 – для Bravo,
- 198.51.100.14 – для Alfa.
4. Создаем две приватные облачные сети в каждом из пулов. В панели управления Selectel это можно сделать в разделе Продукты → Облачные серверы → Сеть → Приватные сети.
В каждой сети будет по одной частной подсети. В этих сетях также будут созданы рабочие ноды Managed Kubernetes. На схеме эти сети обозначены как «Облачная сеть Alfa» и «Облачная сеть Bravo» с подсетями 192.168.247.0/24 и 192.168.147.0/24 соответственно.
В качестве шлюза по умолчанию для подсетей указываем будущие частные адреса ВМ. На схеме используются 192.168.247.254 и 192.168.147.254.
5. Разворачиваем по одной виртуальной машине в каждом выбранном пуле, как это описано в документации. Для внешнего интерфейса используем IP-адрес из тех, что были выбраны во п.2 для настройки BGP-соседства (BGP Neighbor) в соответствующем регионе. В качестве ОС используем AlmaLinux 9 с актуальными обновлениями.
cat /etc/redhat-release
AlmaLinux release 9.6 (Sage Margay)
Не забываем включить на ВМ передачу трафика транзитно, через интерфейсы (forwarding):
echo 'net.ipv4.ip_forward = 1' | sudo tee /etc/sysctl.d/01-ip-forwarding.conf
sudo sysctl --system
6. Добавляем для внутренних портов двух ВМ все IPv4-адреса. Так как ВМ используется как шлюз, то без данной настройки работа невозможна.
Выполняем на управляющей машине:
export GW_IP_ADDR=192.168.147.254
GW_PORT_ID=$(openstack port list --fixed-ip ip-address=${GW_IP_ADDR} -f value -c ID 2>/dev/null)
openstack port set --allowed-address ip-address="0.0.0.0/0" $GW_PORT_ID
Не забываем поменять IP-адрес на свой. Подробнее о настройке можно прочитать в документации.
7. На ВМ устанавливаем и настраиваем ПО с поддержкой протокола BGP.
В примере будет использован frrouting.
export FRRVER="frr-stable"
curl -O https://rpm.frrouting.org/repo/$FRRVER-repo.el9.noarch.rpm
sudo yum install ./$FRRVER-repo.el9.noarch.rpm
sudo yum check-update
sudo yum install frr frr-pythontools
Задействуем запуск bgpd и bfdd при старте frr:
sudo sed -e 's/^bgpd=no/bgpd=yes/g' -e 's/bfdd=no/bfdd=yes/g' -i /etc/frr/daemons
Приводим конфигурацию каждого из frr (/etc/frr/frr.conf) к следующему виду:
frr в region alfa
!
frr defaults traditional
hostname gateway-alfa-unoone
log syslog informational
!
ip prefix-list default_from_mylovelycozycloud seq 10 permit any
ip prefix-list my_anycast_subnet seq 10 permit 203.0.113.64/29 le 32
ip prefix-list my_anycast_subnet seq 100 deny any
!
route-map prpnd_private permit 10
description For AS PATH prepend
set as-path prepend 64859
exit
!
ip router-id 198.51.100.14
!
router bgp 64859
neighbor mks-nodes peer-group
neighbor mks-nodes remote-as internal
neighbor mks-nodes bfd
neighbor mks-nodes bfd profile t-rex
neighbor mks-nodes update-source eth1
neighbor 198.51.100.9 remote-as 65101
neighbor 198.51.100.9 description MyLovelyCozyCloud-region-alfa-peer
neighbor 198.51.100.9 interface eth0
neighbor 198.51.100.9 ebgp-multihop
bgp listen limit 110
bgp listen range 192.168.247.0/24 peer-group mks-nodes
!
address-family ipv4 unicast
network 203.0.113.64/29
neighbor 198.51.100.9 prefix-list default_from_mylovelycozycloud in
neighbor 198.51.100.9 prefix-list my_anycast_subnet out
neighbor 198.51.100.9 route-map prpnd_private out
exit-address-family
exit
!
bfd
profile t-rex
log-session-changes
minimum-ttl 127
exit
!
peer 198.51.100.9
profile t-rex
exit
!
exit
!
end
frr в region bravo
!
frr defaults traditional
hostname gateway-bravo-bissotwo
log syslog informational
!
ip prefix-list default_from_mylovelycozycloud seq 10 permit any
ip prefix-list my_anycast_subnet seq 10 permit 203.0.113.64/29 le 32
ip prefix-list my_anycast_subnet seq 100 deny any
!
route-map prpnd_private permit 10
description For AS PATH prepend
set as-path prepend 64859 64859 64859
exit
!
ip router-id 198.19.51.230
!
router bgp 64859
neighbor mks-nodes peer-group
neighbor mks-nodes remote-as internal
neighbor mks-nodes bfd
neighbor mks-nodes bfd profile t-rex
neighbor mks-nodes update-source eth1
neighbor 198.19.51.225 remote-as 64600
neighbor 198.19.51.225 description MyLovelyCozyCloud-region-bravo-peer
neighbor 198.19.51.225 interface eth0
neighbor 198.19.51.225 ebgp-multihop
bgp listen limit 110
bgp listen range 192.168.147.0/24 peer-group mks-nodes
!
address-family ipv4 unicast
network 203.0.113.64/29
neighbor 198.19.51.225 prefix-list default_from_mylovelycozycloud in
neighbor 198.19.51.225 prefix-list my_anycast_subnet out
neighbor 198.19.51.225 route-map prpnd_private out
exit-address-family
exit
!
bfd
profile t-rex
log-session-changes
minimum-ttl 127
exit
!
peer 198.19.51.225
profile t-rex
exit
!
exit
!
end
Не забываем заменить номер AS (в примере – 64859) на свой, согласованный с технической поддержкой.
Запускаем сервис и задействуем запуск при перезагрузке ВМ:
sudo systemctl enable --now frr.service
8. Если ВМ-шлюз предполагается использовать для NAT и фильтрации, то не забываем настроить netfilter через iptables/nftables.
9. Разворачиваем два управляемых кластера Kubernetes. Проще сделать это, используя Terraform.
Пример части манифеста:
# Получение актуальных версий k8s в MKS
data "selectel_mks_kube_versions_v1" "mks_versions" {
project_id = var.project_id
region = local.region_name
}
# Кластер managed kubernetes services. Базовый вариант без отказоустойчивости master-нод.
resource "selectel_mks_cluster_v1" "mks_cluster_1" {
name = var.mks_cluster_name
region = local.region_name
project_id = var.project_id
network_id = var.network_id
subnet_id = var.subnet_id
kube_version = data.selectel_mks_kube_versions_v1.mks_versions.default_version
zonal = "false"
enable_patch_version_auto_upgrade = "false"
}
# Нодгруппа в кластере
resource "selectel_mks_nodegroup_v1" "mks_nodegroup_1" {
cluster_id = selectel_mks_cluster_v1.mks_cluster_1.id
project_id = var.project_id
region = local.region_name
availability_zone = var.availability_zone
nodes_count = var.nodes_count
keypair_name = var.ssh_keypair_name
flavor_id = var.node_flavor
volume_gb = var.node_volume_size
volume_type = "${var.node_volume_type}.${var.availability_zone}"
install_nvidia_device_plugin = "false"
}
Если интересует полностью готовый вариант, он представлен в репозитории.
10. Разрешаем anycast-подсеть на всех сетевых портах рабочих нод двух созданных кластеров в разных пулах.
Если кластер создан в панели управления Selectel, то в «разрешенные» подсеть можно добавить через тот же интерфейс или CLI. Если вы выбрали второй вариант, то выполните в терминале управляющей машины следующий блок кода:
export ANYCAST_CIDR="203.0.113.64/29"
vm_ips=$(openstack server list --long --tags mks_cluster=true -c Networks -f json | jq -r '.[].Networks[][0]')
port_ids=$(openstack port list --any-tags mks_cluster=true --long -f json | jq -r --arg nodes_ip "$vm_ips" '.[]|select(."Fixed IP Addresses"[0].ip_address as $ips | ($nodes_ip|split("\n"))|index($ips))|.ID')
for id in $port_ids
do
openstack port set --allowed-address ip-address=${ANYCAST_CIDR} ${id}
echo "Port AAPs: "
openstack port show -c allowed_address_pairs ${id}
done
Не забудьте заменить переменную, задающую подсеть ANYCAST_CIDR в скрипте, на свою.
При работе автоскейлера в кластере необходимо учесть, что при создании нод важно добавить anycast-подсеть в «разрешенные» для порта новой рабочей ноды. На данный момент MKs это не предусматривает.
Если работает автоскейлер, то процесс добавления подсети для порта рабочей ноды можно автоматизировать с помощью shell-operator. Но пока конфигурация находится в проработке.
11. Устанавливаем MetalLB в оба кластера MKs:
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.15.2/config/manifests/metallb-native.yaml
12. Добавляем профиль BFD, который будет использоваться для пиринга с нашим шлюзом:
cat <<EOF | kubectl apply -f -
apiVersion: metallb.io/v1beta1
kind: BFDProfile
metadata:
name: my-default
namespace: metallb-system
spec:
receiveInterval: 300
transmitInterval: 300
detectMultiplier: 3
minimumTtl: 127
EOF
13. Добавляем ВМ-шлюз как BGP peer для MetalLB.
Afla
cat <<EOF | kubectl apply -f -
apiVersion: metallb.io/v1beta2
kind: BGPPeer
metadata:
name: gateway-alfa-unoone
namespace: metallb-system
spec:
myASN: 64859
peerASN: 64859
peerAddress: 192.168.247.254
bfdProfile: my-default
EOF
Bravo
cat <<EOF | kubectl apply -f -
apiVersion: metallb.io/v1beta2
kind: BGPPeer
metadata:
name: gateway-bravo-bissotwo
namespace: metallb-system
spec:
myASN: 64859
peerASN: 64859
peerAddress: 192.168.147.254
bfdProfile: my-default
EOF
Снова не забываем заменить номер AS (в примере — 64859) на свой, согласованный с технической поддержкой. Проверяем, что peer добавился:
kubectl -n metallb-system get bgppeers.metallb.io
Пример вывода:
NAME ADDRESS ASN BFD PROFILE MULTI HOPS
gateway-alfa-unoone 192.168.247.254 64859 my-default
14. Добавляем выделенный провайдером пул anycast-адресов в назначаемые для балансировщиков MetalLB:
cat <<EOF | kubectl apply -f -
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: anycast-pool
namespace: metallb-system
spec:
addresses:
- 203.0.113.64/29
EOF
15. Добавляем анонсирование для адресов из пула для балансировщиков MetalLB:
cat <<EOF | kubectl apply -f -
apiVersion: metallb.io/v1beta1
kind: BGPAdvertisement
metadata:
name: anycast-adv
namespace: metallb-system
spec:
ipAddressPools:
- anycast-pool
EOF
16. Отключаем создание облачных балансировщиков (Octavia), так как будет использоваться MetalLB.
export NEW_CLOUD_CONF=$(kubectl -n kube-system get secret cloud-config -o jsonpath='{.data.cloud\.conf}' | base64 -d | sed 's#\[LoadBalancer\]#\[LoadBalancer\]\nenabled=false#g' | base64)
kubectl -n kube-system patch secret cloud-config -p '{"data":{"cloud.conf":"'${NEW_CLOUD_CONF}'"}}' && kubectl -n kube-system rollout restart deploy/openstack-cloud-controller-manager
Важно! Данная конфигурация будет переопределена с мастер-серверов, соответственно сохранится при применении деплоймента, что произойдет при обновлении кластера. Стоит иметь это в виду.
Этап настройки завершен. Теперь следует проверить работоспособность решения.
Применение решения
Посмотрим, как работает настроенный MetalLB. Мы будем проверять только функциональность, без нагрузочного тестирования.
1. Разворачиваем простой echoserver в двух кластерах в разных пулах:
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: cilium-echoserver
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: cilium-echoserver
template:
metadata:
labels:
app: cilium-echoserver
spec:
containers:
- name: cilium-echoserver
image: cilium/echoserver:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
protocol: TCP
env:
- name: PORT
value: "8080"
EOF
Проверяем:
kubectl get pods
NAME READY STATUS RESTARTS AGE
cilium-echoserver-7f9979f65d-9b8hj 1/1 Running 0 2d10h
cilium-echoserver-7f9979f65d-bvt79 1/1 Running 0 2d10h
2. Публикуем сервис. Применяем для двух кластеров:
cat <<EOF | kubectl apply -f -
kind: Service
apiVersion: v1
metadata:
name: cilium-echo-svc-metallb
annotations:
loadbalancer.openstack.org/class: non-existent # <- if you do not want to use Octavia LB
metallb.io/address-pool: anycast-pool # <- use your pool name here
spec:
selector:
app: cilium-echoserver
type: LoadBalancer
ports:
- name: http
port: 80
targetPort: 8080
protocol: TCP
EOF
Проверяем:
kubectl get svc cilium-echo-svc-metallb
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
cilium-echo-svc-metallb LoadBalancer 10.107.244.230 203.0.113.65 80:32043/TCP 1h
3. Запрашиваем данные от echo-сервера:
curl -sS "http://203.0.113.65/?hello_there"
Hostname: cilium-echoserver-7f9979f65d-9b8hj
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=::ffff:192.168.247.237
method=GET
real path=/?hello_there
query=hello_there
request_version=1.1
request_scheme=http
request_uri=http://203.0.113.65:8080/?hello_there
Request Headers:
accept=*/*
host=203.0.113.65
user-agent=curl/8.7.1
Request Body:
-no body in request-
Запросы на anycast-адрес проходят. В примере нам отвечает под в кластере Alfa.
Манифесты для развертывание стенда
При прочтении возникает впечатление, что развертывание подобной конфигурации можно (и нужно) автоматизировать. Это действительно так — есть даже специальное решение.
В репозитории доступны готовые Terraform-манифесты — с их помощью можно быстро развернуть всю описанную инфраструктуру. Главное — внимательно прочитать README при применении, так как оно происходит в три этапа. Впоследствии представленный код можно легко модифицировать для создания собственной продуктивной инсталляции.
После применения конфигурации экспортируем конфигурационные файлы K8s:
# выполняем в папке c описанием инфраструктуры TF
terraform output -raw mks_cluster_alfa_kubeconfig > ../configs/mks_cluster_alfa_kubeconfig.yaml
terraform output -raw mks_cluster_bravo_kubeconfig > ../configs/mks_cluster_bravo_kubeconfig.yaml
export KUBECONFIG=`pwd`/../configs/mks_cluster_alfa_kubeconfig.yaml:`pwd`/../configs/mks_cluster_bravo_kubeconfig.yaml:~/.kube/config
Затем между конфигурациями можно удобно переключаться, задавая контекст:
# выводим список доступных контекстов
kubectl config get-contexts
# переключаемся на кластер Bravo
kubectl config use-context admin@k8s-bravo-bissotwo
# запрашиваем ноды кластра Bravo
kubectl get nodes -o wide
# переключаемся на Alfa
kubectl config use-context admin@k8s-alfa-unoone
# и получаем уже его список нод
kubectl get nodes -o wide
Switchover: плановые переключения
Вы развернули кластеры, приложения в них и начали тестовую эксплуатацию. Как же переключиться между дата-центрами?
Предположим, что вы опубликовали сервис с одинаковыми публичными IP. Конфигурацией это не возбраняется. Для этого при создании сервиса в манифесте должна присутствовать аннотация metallb.io/loadBalancerIPs или спецификация spec.loadBalancerIP.
Пример манифеста, который применен в двух кластерах:
kind: Service
apiVersion: v1
metadata:
name: echo-svc-sameip
annotations:
loadbalancer.openstack.org/class: non-existent # <- if you do not want to use Octavia LB
metallb.io/address-pool: anycast-pool # <- use your pool name here
metallb.io/loadBalancerIPs: 203.0.113.70
spec:
selector:
app: cilium-echoserver
type: LoadBalancer
ports:
- name: http
port: 80
targetPort: 8080
protocol: TCP
Куда попадет клиентский запрос при обращении к IP? В сервис в каком кластере? И как переключить клиентский трафик на другой кластер? Давайте разбираться.
Обратим внимание на конфигурацию frrouting. На ВМ gateway-alfa-unoone мы имеем следующую карту маршрутов (route-map):
route-map prpnd_private permit 10
description For AS PATH prepend
set as-path prepend 64859
exit
А на gateway-bravo-bissotwo — такой route-map:
route-map prpnd_private permit 10
description For AS PATH prepend
set as-path prepend 64859 64859 64859
exit
Вспоминаем: нас есть два основных метода «ухудшения» маршрутов для анонсируемых префиксов, а именно AS-Path prepend и MED. Очевидно, что в своей конфигурации мы используем первый метод. «Хитрости» с community не рассматриваем — это выходит за рамки данной статьи.
Сами же себе отвечаем на первый вопрос. Если адрес анонсируется из двух кластеров K8s одновременно, то трафик будет направлен туда, где AS Path короче, то есть на ВМ Alfa. А для переключения достаточно добавить в AS Path больше ASN, чем присваивается при анонсе anycast-подсети с ВМ в другом дата-центре.
Теперь представим что у нас штатное переключение нагрузки и Alfa в Bravo. Как его сделать?
1. Для начала убедимся, что запрос приходит в тот кластер, нагрузку с которого планируем снять:
curl -sS 'http://203.0.113.70/?where_am_i'
Hostname: cilium-echoserver-7f8dccd9b6-zgmxf
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=::ffff:192.168.247.56
method=GET
real path=/?where_am_i
query=where_am_i
request_version=1.1
request_scheme=http
request_uri=http://203.0.113.70:8080/?where_am_i
Request Headers:
accept=*/*
host=203.0.113.70
user-agent=curl/8.7.1
Request Body:
-no body in request-
Запрос пришел на под в кластере Alfa.
2. Заходим по SSH на ВМ в gateway-alfa-unoone и запускаем vtysh, в котором выполняем следующие команды:
conf t
route-map prpnd_private permit 10
set as-path prepend 64859 64859 64859 64859 64859
exit
exit
То есть мы добавляем к пути еще дополнительно четыре приватных номера автономной системы.
3. Проверяем количество ASN, добавленных к пути. В том же открытом vtysh выполняем:
show bgp paths
Пример вывода:
Address Refcnt Path
[0x5569c25e6810:3382778021] (2) 64859 64859 64859 64859 64859
[0x5569c259bbc0:2448081105] (7)
[0x5569c25a98a0:16672824] (2) 65101
4. Выполняем запрос и убеждаемся, что он приходит на балансировщик в другом кластере (k8s-bravo-bissotwo):
curl -sS 'http://203.0.113.70/?where_am_i'
Hostname: cilium-echoserver-7f8dccd9b6-gtw4z
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=::ffff:192.168.147.69
method=GET
real path=/?where_am_i
query=where_am_i
request_version=1.1
request_scheme=http
request_uri=http://203.0.113.70:8080/?where_am_i
Request Headers:
accept=*/*
host=203.0.113.70
user-agent=curl/8.7.1
Request Body:
-no body in request-
Мы добились желаемого.
Стоит учесть: адреса с маской /32, которые анонсируются только из одного кластера, останутся доступными исключительно через соответствующий маршрутизатор.
kubectl --context admin@k8s-alfa-unoone get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
cilium-echo-svc-metallb LoadBalancer 10.96.3.218 203.0.113.65 80:32110/TCP 8d
echo-svc-sameip LoadBalancer 10.100.78.94 203.0.113.70 80:31512/TCP 3d1h
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 9d
kubectl --context admin@k8s-bravo-bissotwo get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
cilium-echo-svc-metallb LoadBalancer 10.98.244.156 203.0.113.66 80:32731/TCP 8d
echo-svc-sameip LoadBalancer 10.104.81.133 203.0.113.70 80:30576/TCP 3d1h
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 9d
curl -sS http://203.0.113.65
Hostname: cilium-echoserver-7f8dccd9b6-579hq
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=::ffff:192.168.247.187
method=GET
real path=/
query=
request_version=1.1
request_scheme=http
request_uri=http://203.0.113.65:8080/
Request Headers:
accept=*/*
host=203.0.113.65
user-agent=curl/8.7.1
Request Body:
-no body in request-
Как видно, трафик на 203.0.113.65 по прежнему идет через балансировщик в кластере Alfa, потому что подсеть анонсируется только при появлении адреса в таблице маршрутизации по iBGP. Это удобно и гибко.
Failover: аварийные переключения
Хороший провайдер IT-инфраструктуры в первую очередь заботится о надежности своих сервисов, но ситуации бывают разные. Давайте сымитируем «падение» одного из дата-центров и посмотрим, как поведет себя система.
Для этого «вредного» действия принудительно выключим рабочие ноды K8s и машину-шлюз в Bravo. Но сначала установим и запустим утилиту для тестирования locust и соберем статистику, сколько запросов пропадает при выключении и автоматическом переключении ВМ.
Напишем простой locustfile:
from locust import HttpUser, task, between
class TooSimpleTest(HttpUser):
wait_time = between(1, 2)
def on_start(self):
# Set a custom User-Agent
self.client.headers['User-Agent'] = "JamesBondAgent/007"
@task
def simple_hello(self):
self.client.get("/hello")
self.client.get("/k8s")
Запускаем locust:
export ANYCAST_LB_IP=203.0.113.70
locust -H http://${ANYCAST_LB_IP} -u 100 -r 10 -t 10m --autostart
Теперь выключаем ВМ с помощью OpenStack CLI, но не возбраняется сделать это и через панель управления.
# отключаем ноды K8s, используя тег
for srv in $(openstack server list --tags mks_cluster=true -c ID -f value 2>/dev/null) ; do openstack server stop $srv 2>/dev/null ; done
# еще один вариант отключения нод
openstack server list --tags mks_cluster=true -c ID -f value | xargs openstack server stop
# отключаем ВМ-шлюз, не забываем поменять IP на свой
export GW_IP_ADDR=198.19.51.230
openstack server stop $(openstack server list --ip $GW_IP_ADDR -c ID -f value 2>/dev/null)
Получаем следующую картину при выключении:
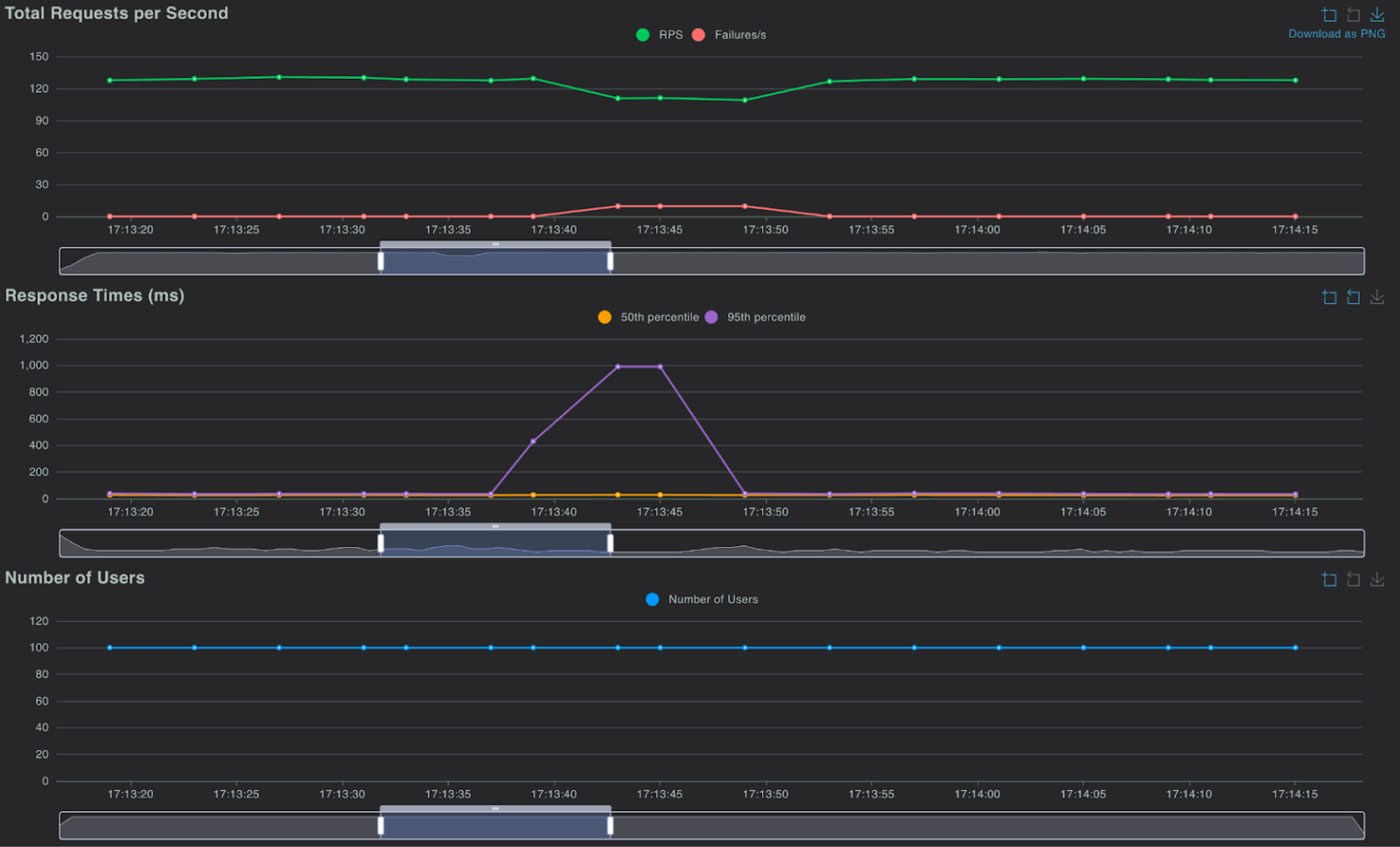
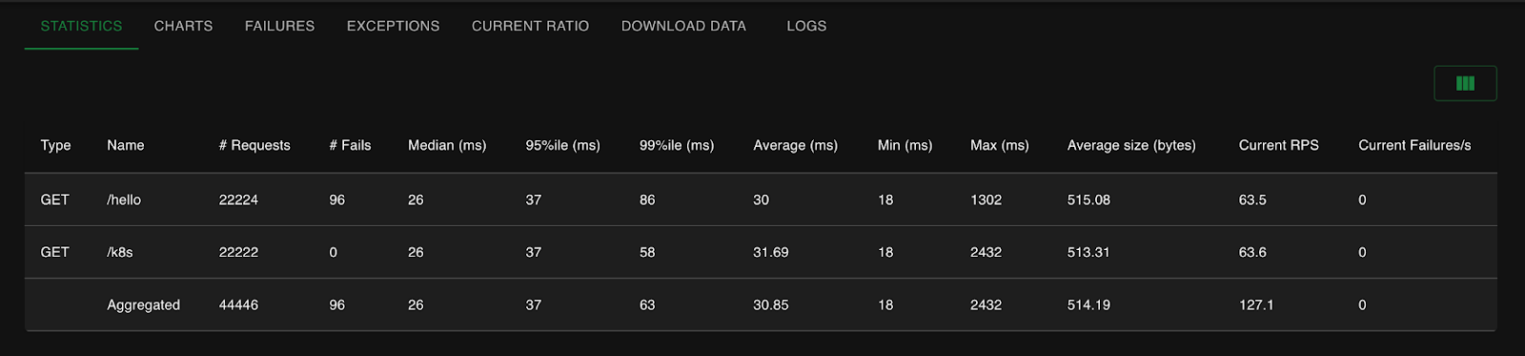
Как видим, «пропало» всего 96 запросов при RPS в 127. Неплохой результат! Понятно, что echoserver возвращает контент небольшого размера, но тем не менее.
Выводы
Чего же мы добились? В первую очередь, получили основу для отказоустойчивого или даже геораспределенного инфраструктурного решения на базе Managed Kubernetes. Реализованная схема подходит и для Kubernetes-кластера, развернутого собственными силами. Отработка отказа на уровне сети происходит быстро и позволяет с минимумом «боли» пережить даже такой серьезный инцидент, как выход из строя целого дата-центра.
Конечно, схему можно улучшить. Одна ВМ в облаке может выглядеть как точка отказа. Можно создать еще одну ВМ с frr и настроить дополнительный пиринг как с провайдером, так и для MetalLB. Кроме того, можно поставить и настроить shell-operator, чтобы не добавлять вручную allowed address pairs для сетевых портов в облачных сетях.