

Формат изображения PNG известен с 1996 года, однако большинство актуальных материалов в интернете — о декодировании этого формата. Я же расскажу о кодировании. Поделюсь, как сохранить PNG своими руками на случай, если вам тоже придется это делать. Например, в академических целях.
Но почему бы не использовать внешние библиотеки?
Я писал программу, которая работает в специфическом интерпретаторе JavaScript, у которого ограничены возможности и нужно экономить место. Библиотека fast-png, кажется, решает проблему, но она избыточна и использует классы, которых нет в целевом интерпретаторе.
Структура PNG
Формат PNG описывается в RFC 2083, но обязательными к прочтению являются также RFC 1951 и RFC 1950. Эти стандарты можно сократить до «PNG — это метадата и изображение, сжатое алгоритмом Deflate и сохраненное в формате zlib». Рассмотрим высокоуровневую структуру формата PNG.
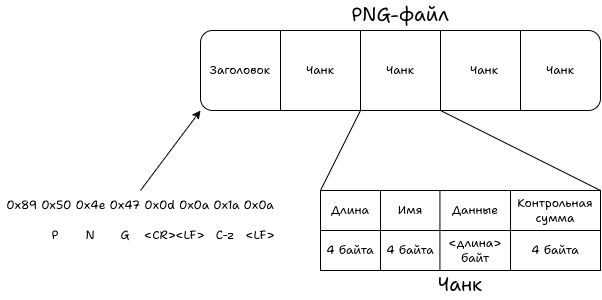
Файл PNG состоит из заголовка и блоков данных переменной длины — чанков. Заголовок фиксированный и состоит из восьми байтов. Каждый байт имеет свой смысл.
- 0x89 — первый байт не ASCII-символ, чтобы программное обеспечение не пыталось трактовать PNG-файл как текстовый файл. Также используется для проверки, что при передаче не обнуляется седьмой бит.
- 0x50, 0x4e, 0x47 — ASCII-символы, соответствующие строке PNG. Для однозначной идентификации типа файла, в том числе если его открыть в текстовом редакторе.
- 0x0d, 0x0a — управляющие символы «возврат каретки» (
<CR>) и «подача строки» (<LF>). Используются для проверки корректности передачи на случай, если при передаче удаляются символы<CR>. - 0x1a — управляющий символ, Control-Z, признак конца файла в MS-DOS. Останавливает вывод на экран, если PNG открывается в текстовом режиме.
- 0x0a — символ «подача строки». Используется для проверки, что при передаче не добавляется символ «возврат каретки».
После заголовка следуют чанки, каждый чанк описывает сам себя.
- Длина, 4 байта — размер данных чанка в байтах. Это число описывает длину данных. Чанк имеет размер
<длина>+ 12 байтов. - Имя, 4 байта ASCII-символов — определяет тип чанка.
- Данные — набор данных, соответствующий типу чанка.
- Контрольная сумма, 4 байта — CRC32 от имени чанка и данных.
Все возможные имена чанков описаны в стандарте и в назывном порядке рассмотрены в обзоре формата PNG на Хабре. Стандарт требует, чтобы все реализации просмотрщиков PNG корректно обрабатывали следующие типы чанков. Эти чанки называются критическими.
- IHDR — Image HeaDeR. Занимает 13 байтов, описывает характеристики изображения.
- PLTE — PaLeTtE. Палитра цветов.
- IDAT — Image DATa. Данные изображения.
- IEND — Image END. Занимает 0 байт. Признак конца последовательности чанков.
Впрочем, чанки критичны для реализации декодера, но не для изображения. Для корректного PNG-изображения требуется минимум три чанка: IHDR, как минимум один IDAT и IEND. При этом IHDR должен быть первым, а IEND — последним.
Рассмотрим строение чанков.
Строение чанков
Как упоминалось ранее, чанк состоит из четырех полей: длины, имени, данных и контрольной суммы. При самостоятельной реализации кодирования PNG нужно обратить внимание на вычисление контрольной суммы. В PNG используется алгоритм CRC32 с такими параметрами:
- начальное значение: 0xFFFFFFFF;
- полином:
- нормальная форма: 0x04C11DB7;
- обратная форма: 0xEDB88320;
- конечное XOR-значение: 0xFFFFFFFF.

Убедиться в корректности вычисления контрольной суммы чанка можно на чанке IEND, так как он не содержит данных, и следовательно, имеет фиксированную контрольную сумму, равную 0xAE426082. Для самопроверки на других данных я рекомендую SimpleCalc, потому что его ответы сходятся с тем, что должно быть. Теперь переходим к чуть более сложному чанку: IHDR.
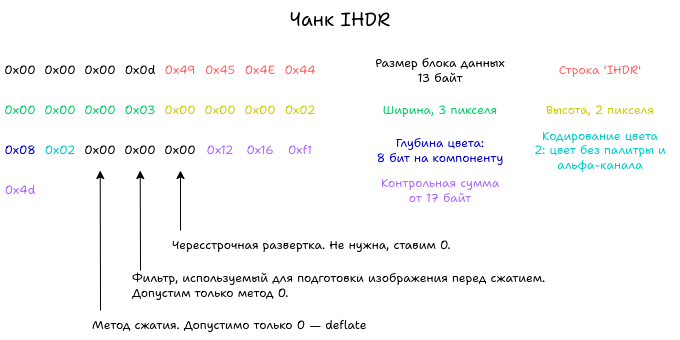
Данные чанка IHDR состоят из 8 полей, суммарным размером 13 байтов.
- Ширина в пикселях, 4 байта.
- Высота в пикселях, 4 байта.
- Глубина цвета в битах, 1 байт. Допустимые значения — 1, 2, 4, 8, 16.
- Метод кодирования цвета, 1 байт. Считается как сумма параметров.
- 1 — используется палитра;
- 2 — используется цвет;
- 4 — используется альфа-канал.
- Метод сжатия, байт. В стандарте допустимо только одно значение — 0.
- Фильтр подготовки изображения, 1 байт. Это обратимое преобразование для изображения, чтобы улучшить сжатие. Допустима фильтрация только одним набором фильтров, соответствующих значению 0.
- Чересстрочная развертка (interlacing). Меняет порядок данных в изображении.
- 0 — отключена;
- 1 — развертка по алгоритму Adam7.
Обратите внимание, что все числа в чанках PNG хранятся в формате big-endian!
Чересстрочная развертка — это «косметический» эффект, который позволяет сперва загрузить «грубое» пикселизированное изображение, а потом «уточнить», повышая качество.

Согласно чанку IHDR мы подписались сделать изображение 3 х 2 пикселя, RGB без палитры, 8 бит на цвет, алгоритм сжатия Deflate. Похоже, что от сжатия убежать не получится.
Чанк IDAT хранит сжатые данные размером до 232 байт, то есть 4 ГиБ. Вряд ли мы превысим этот предел, поэтому будем использовать один чанк IDAT. Осталось подготовить для него данные.
Теоретический материал
В PNG используется сжатие при помощи алгоритма Deflate, который в общем случае состоит из двух шагов.
- Сжатие алгоритмом LZ77 (Лемпель и Зив, 1977 год).
- Результат сжатия кодируется префиксными кодами Хаффмана.
Рассмотрим каждый шаг по отдельности.
Алгоритм LZ77
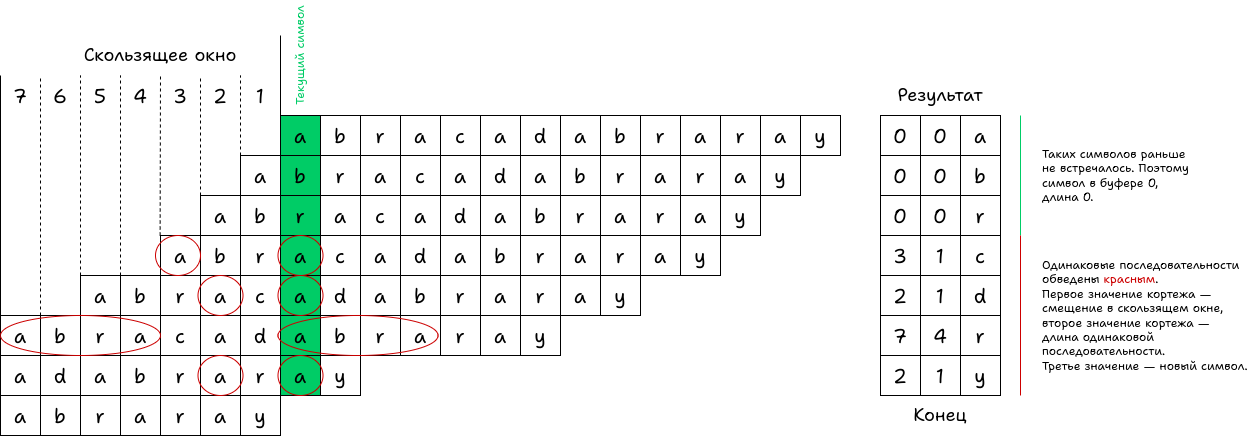
Алгоритм LZ77 проходит по данным «скользящим окном» фиксированного размера и пытается найти в окне повторяющиеся последовательности. На выходе алгоритм выдает список кортежей (расстояние до начала последовательности в скользящем окне; длина последовательности; новый символ).
Сам алгоритм является общедоступным, а вот некоторые его реализации запатентованы. Алгоритм определяет возможные параметры, основную идею и выходные данные, а реализация влияет на то, как именно обнаруживаются повторяющиеся последовательности и насколько быстро это происходит. Всегда можно сделать наивную реализацию, которая перебирает все подстроки в «скользящем окне» и находит наибольшую. Будет медленно, но это сработает.
Код Хаффмана
Код Хаффмана — это префиксное кодирование с минимальной избыточностью. «Префиксный код» значит, что ни один код не может быть началом другого кода. Вот пример кодирования пяти символов.
| Символ | Код |
| А | 0 |
| Б | 100 |
| В | 101 |
| Г | 110 |
| Д | 111 |
Наиболее часто встречаемый символ кодируется меньшим количеством бит. Обратите внимание, что символ «А» кодируется кодом «0» и в таблице больше нет ни одного кода, который начинался бы с нулевого бита.
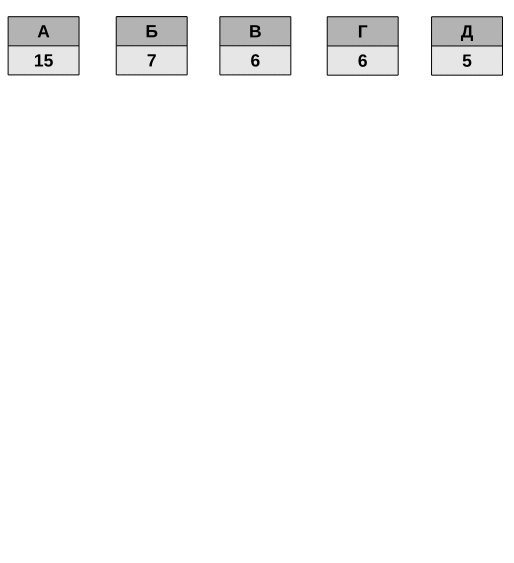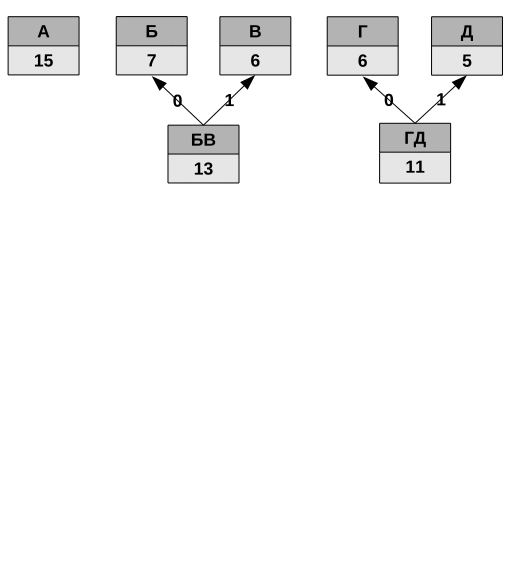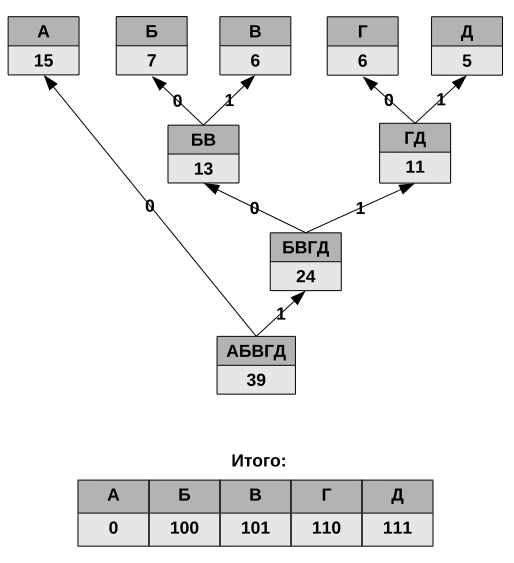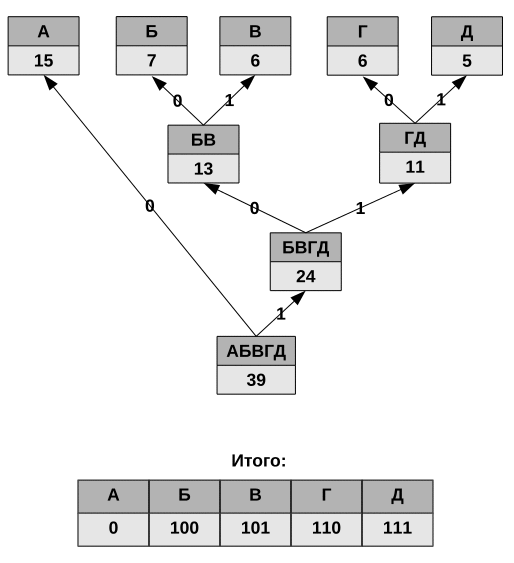
Алгоритм построения, списанный с «Википедии».
Классический алгоритм Хаффмана на входе получает таблицу частотностей символов в сообщении. Далее на основании этой таблицы строится дерево кодирования Хаффмана.
- Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который может быть равен либо вероятности, либо количеству вхождений символа в сжимаемое сообщение.
- Выбираются два свободных узла дерева с наименьшими весами.
- Создается их родитель с весом, равным их суммарному весу.
- Родитель добавляется в список свободных узлов, а два его потомка удаляются из этого списка.
- Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0. Битовые значения ветвей, исходящих от корня, не зависят от весов потомков.
- Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Подготавливаем изображение в двоичный формат
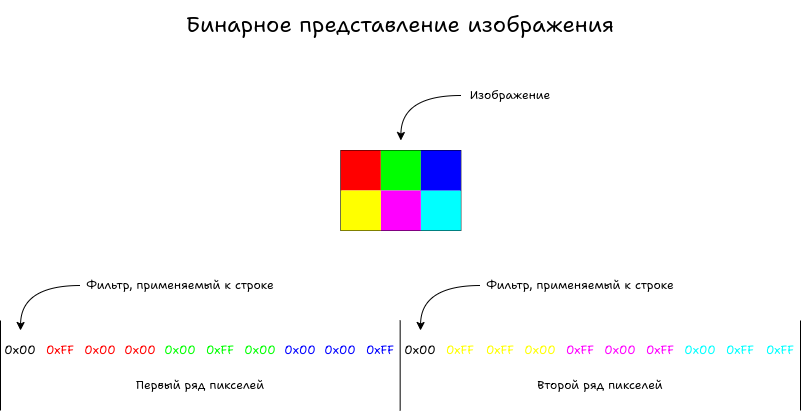
Теперь, когда мы познакомились с теорией сжатия, подготовим изображение, которое будем сжимать. Заголовок требует от нас 3 х 2 с глубиной цвета 24 бита на пиксель. Сделаем шесть пикселей разного цвета для упрощения демонстрации. Изображение разбивается на строки, в начале каждой строки один байт занимает указание фильтра, применяемого к текущей строке, а потом — данные о пикселях в этой строке.
В этой статье изображение не использует фильтры и чересстрочную развертку, поэтому первый байт строки всегда будет 0, строки перечисляются по порядку с верхней до нижней, а пиксели в строке — слева направо.
Строки всегда начинаются по границе байта, а вот данные пикселей внутри строки следуют друг за другом. То есть при глубине цвета 1 бит в одном байте будет сохранено до 8 пикселей.
Данные есть, приступаем к сжатию.
Изготавливаем IDAT-чанк
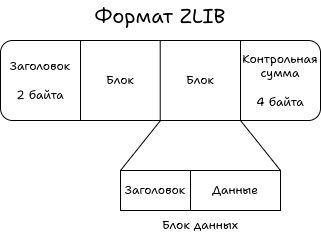
Данные IDAT-чанка — это сжатие в формате ZLIB. В этом формате есть свой заголовок, своя полезная нагрузка и, конечно, своя контрольная сумма.
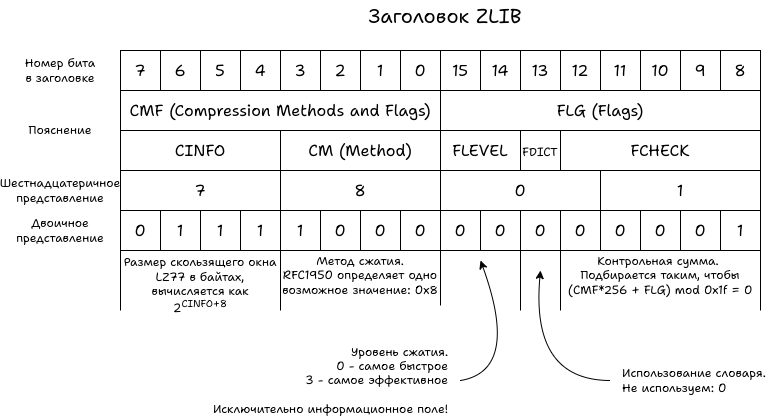
ZLIB как самостоятельный формат имеет свой заголовок. Для PNG заголовок можно зафиксировать в значении 0x7801. В первом байте указывается стандартное для PNG «сжатие Deflate, плавающее окно 32 КиБ». Значение FLEVEL используется исключительно в информационных целях и никак не влияет на декодирование. Если указан бит FDICT, то после заголовка следует словарь — набор данных, которые передаются декомпрессору до начала распаковки.
ZLIB предлагает три формата блоков, в которых может храниться информация:
- тип 0b00 — блоки без сжатия;
- тип 0b01 — сжатие с фиксированным кодом Хаффмана;
- тип 0b10 — сжатие с динамическим кодом Хаффмана.
Если вас уже посещала мысль: «Зачем я вообще в это ввязался», — то возможность хранить данные без сжатия — это прекрасная новость.
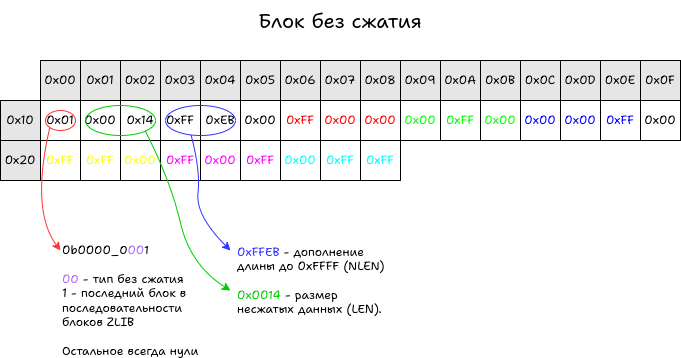
Блок без сжатия начинается с трех бит универсального «заголовка». Первый бит обозначает, последний ли это блок в формате ZLIB. У нас единственный блок, поэтому установлен бит 1. Затем два бита определяют тип блока. Выбираем 0b00 — без сжатия. В случае блоков без сжатия до конца бита заполняются нули.
Специфично для блока без сжатия после заголовка идут два поля по два байта, длина данных и дополнение длины. Дополнение длины вычисляется по формуле NLEN = 0xFFFF – LEN. Нетрудно заметить, что из-за поля LEN длина блока без сжатия ограничена 16 КиБ. В случае если изображение больше, то необходимо разделить данные на несколько блоков, выставив первый бит заголовка равным нулю для всех, кроме последнего.
Формат ZLIB завершают 4 байта контрольной суммы данных до сжатия по алгоритму Adler-32. Это довольная простая функция, поэтому не будем останавливаться подробно. Полученный набор данных «упаковываем» в чанк IDAT и считаем его контрольную сумму.
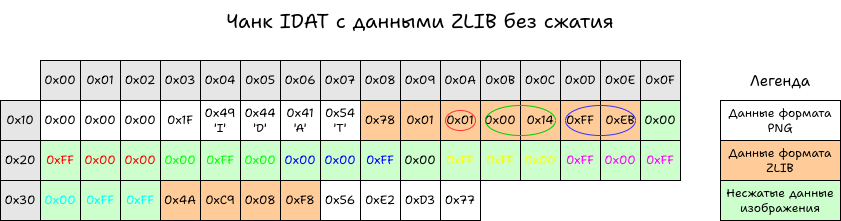
Кажется, это все. Записываем в файл заголовок PNG и чанки в порядке IHDR, IDAT, IEND и открываем в просмотрщике. Ура, наш первый PNG записан.
Но есть ощущение, что дело не завершено. Использовать блок без сжатия — это неспортивно. Пора выяснить, как глубока кроличья нора.
Оригинальный файл доступен по ссылке.
IDAT со сжатием
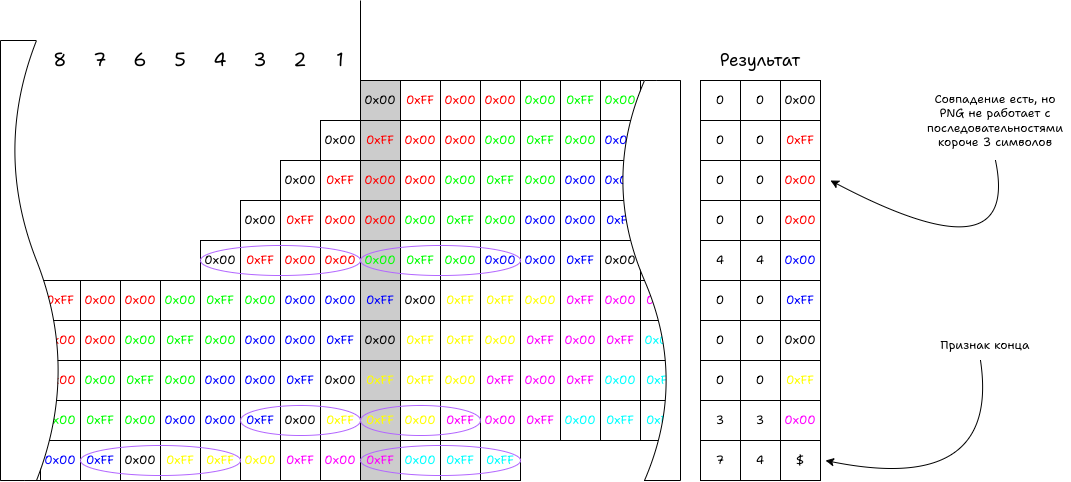
Возвращаемся на этап раньше, когда у нас есть «сырые» данные картинки. Как по учебнику проводим сжатие алгоритмом LZ77. Так как объем данных небольшой, то алгоритм можно сделать наивным и визуализировать. С большими картинками придется использовать плавающее окно размером 32 КиБ. После сжатия получается набор кортежей (смещение; длина; символ), остается их закодировать кодами Хаффмана. Более простой вариант — статические коды Хаффмана, которые уже посчитали за нас.
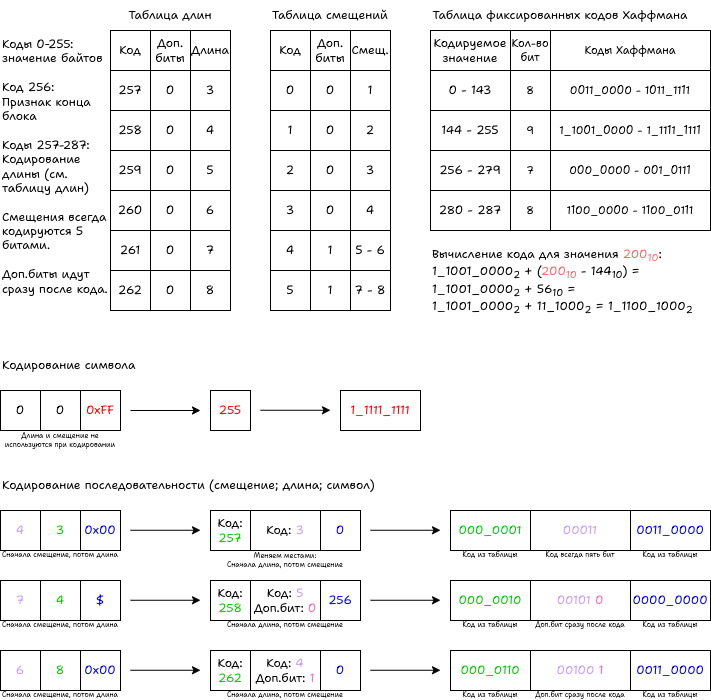
Проходим по всем кортежам и кодируем данные.
- Если в кортеже длина/смещение последовательности 0, то сразу кодируем символ. Значение байта (0-255) кодируется в 8- или 9-битный код.
- Если в кортеже есть длина и смещение последовательности, то приступаем к кодированию последовательности.
- Сперва вычисляем код длины. Для этого смотрим в стандарт (RFC 1951, секция 3.2.5), в таблице длин находим код нужной длины. В примере коды не содержат дополнительных битов. Значение кода длины кодируется кодом Хаффмана. Дополнительные биты, если есть, дописываются после кода Хаффмана.
- Вычисляем код смещения, смотрим в таблице смещений. Если код кодирует диапазон, то считаем дополнительные биты по формуле (
<кодируемая_длина>–<начальная_граница_диапазона>). Код смещения всегда кодируется пятью битами. Дополнительные биты, если есть, дописываются после. - Символ в кортеже кодируется аналогично п.1.
После кодирования Хаффмана получается большая двоичная строка, которую нужно разложить по байтам в памяти компьютера.
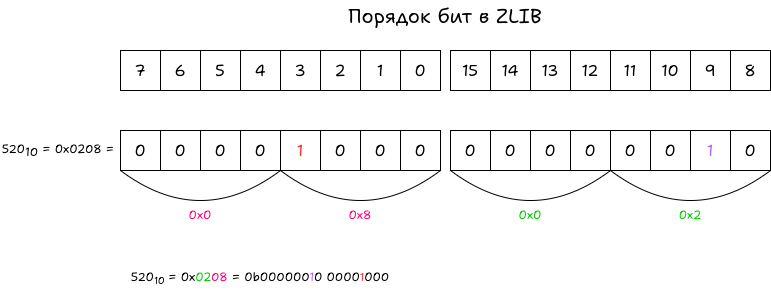
Стоит обратить внимание, что в zlib используется порядок бит, который несмотря на свою логичность выглядит не очевидно. Формат zlib предлагает записывать биты по порядку от младшего к старшему в каждом байте. В человеческом представлении получается, что двоичную строку, полученную после кодирования Хаффмана, нужно разделить на байты, а каждый байт развернуть.
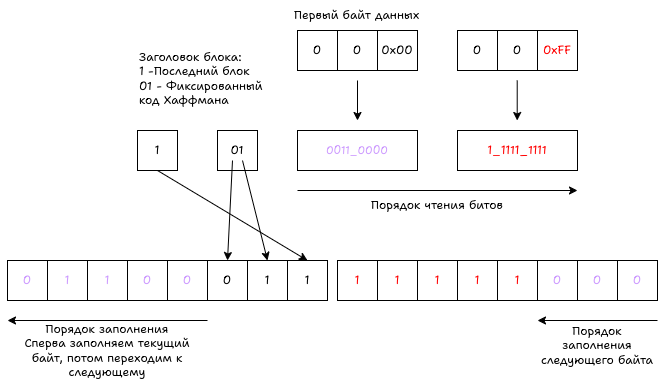
В начале блока с фиксированными кодами Хаффмана нужно сделать трехбитный заголовок. Для маленькой картинки используем один блок, поэтому первый бит первого байта заполняется единицей. Затем следует описание блока: тип 0b01 — фиксированный код Хаффмана. В отличие от несжатых данных, блок со сжатием не привязывается к границам байта: сразу после заголовка записываем первые 5 бит первого кода, а оставшиеся 3 бита — в следующий. И так далее до кода 256, который обозначает конец блока.
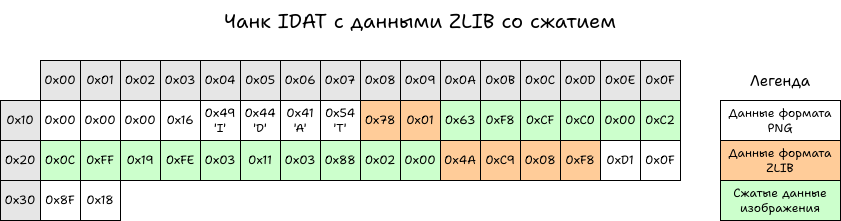
Укладываем в чанк IDAT, сохраняем и открываем просмотрщиком. Если все прошло гладко, то картинка вновь откроется. Новое изображение «весит» 79 байтов вместо 88 байтов у несжатого изображения. Это успех.
Как отлаживать
Во время изучения формата PNG я узнал про существование онлайн-инспектора PNG, который подробно изучает файл и позволяет обнаруживать ошибки. Этот инструмент отлично подходит для верификации всего, что касается формата PNG. Однако в моем случае он не помог с ошибками при формировании несжатых блоков. Я подумал, что контрольная сумма Adler-32 должна быть после каждого блока и инспектор предупреждал об ошибке, но не говорил в чем проблема.
Для изучения и проверки deflate-данных на StackOverflow рекомендуют использовать infgen, но я пользовался только методом пристального взгляда.
Заключение
Теперь у нас есть подробное объяснение, как закодировать изображение в PNG, если в инструменте по каким-то причинам нет библиотек для кодирования изображений. Хотя статья не покрывает все возможные случаи — для этого есть стандарт — в базовом варианте это не так сложно, как казалось в начале. Даже со сжатием.





