

Компания AWS, которая создавала собственное облако, выпустила в релиз сетевые диски, или Elastic Block Storage, еще в 2008 году. Но российские провайдеры долгое время эксплуатировали только локальные диски, которые были просто частью односложных VDS.
Облако Selectel при этом стартовало сразу с сетевыми дисками — локальных не было от слова совсем. Чем хороши сетевые диски, почему именно Ceph и когда в виртуалки вернулись локальные диски, рассказал директор по развитию ядра облачной платформы Иван Романько.
Это продолжение цикла текстов про развитие облака Selectel. В первой части рассказали про первый вариант облака — самописное решение на Haskell — и про запуск новых регионов.
Почему только сетевые диски
Когда запускалось облако Selectel, никто из провайдеров не рассматривал их как основное хранилище для виртуальных машин. У нас же на старте были только сетевые диски.
Почему так сделали? Хотели убить двух зайцев.
Для провайдера облачной инфраструктуры сетевой диск — это очень удобно. Он представляет собой отдельную систему — хранилище, производительность которого не влияет на производительность той же виртуализации. Как с любой «модульной» деталью, с таким диском легче работать — изменения не затронут «внутренности» основного хоста.
Для потребителей тоже была понятная им польза:
- Сетевые диски можно легко изменять в размере, несмотря на конфигурацию виртуальной машины. Например, взять облачный сервер с очень большим диском и 2 vCPU, 2 ГБ RAM одновременно. Либо увеличить размер диска, как только это потребуется. Все абсолютно легально.
- В случае необходимости можно быстро подключить сетевой диск к новому виртуальному серверу. Ни виртуальные машины с локальными дисками других провайдеров, ни выделенные серверы Selectel такую маневренность не предоставляли: если «вырос» из сервера — нужно заказывать новый.
С точки зрения инфраструктуры сетевые диски — довольно интересная вещь. «Железный» хост представляет собой обычный сервер, в котором стоит очень много дисков. В остальном там тоже есть процессоры, оперативная память, стоит операционная система, как на других хостах виртуализации.
У хостов под сетевые диски — отдельное сетевое оборудование, чтобы не было пересечения с интернет-трафиком. Так система более изолирована, предсказуема и выдает большую производительность.
Преимущества архитектуры сетевых дисков
Чем еще хороши сетевые диски? Архитектура системы буквально предназначена для того, чтобы внутри можно было создавать типы дисков с разной производительностью. Там настолько мощные абстракции, что клиент, который запускает виртуальную машину, мельчайшим изменением, просто выбором другого типа диска, может получить совершенно иную производительность. Это одна из киллер-фичей сетевых дисков, потому что с локальными дисками гораздо сложнее позволить клиенту выбрать, например, SATA- или SSD-диск.
Мы в Selectel знали, что воспользуемся этим преимуществом. Стартовали с быстрого типа диска на базе SSD-накопителей (характеристики на данный момент — IOPS 25 000/15 000, 500 МБ/с) — у него более широкое применение. Спустя год добавили еще один, основанный на более плотной системе хранения. Внутри были SATA-диски с легким кэшем сверху, чтобы повысить производительность. Предполагалось, что этот тип диска будет использоваться не под операционную систему, а как дополнительный диск для хранения большого объема данных.
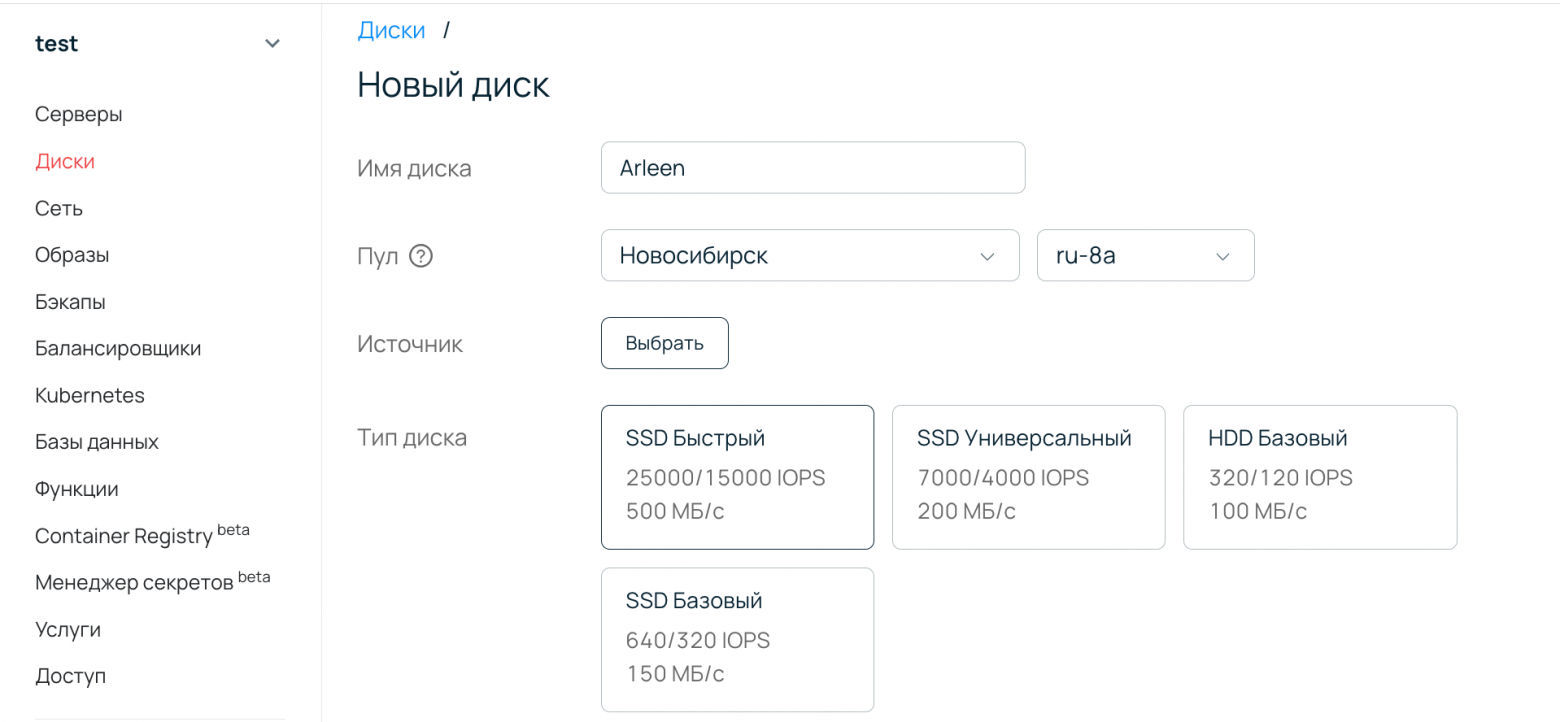
Хранение большого количества информации в то время было доступно в облачном хранилище, но интерфейс для доступа был другой. Туда можно было загрузить данные через FTP, Swift API — высокоуровневые протоколы. Но пользователи хотели просто из виртуальной машины часть данных записывать на большой дешевый диск. И технологически обеспечить эту запись в надежном виде можно было, только создав отдельный тип диска.
Ceph
Помимо операционной системы, хосты под сетевые диски управляются Ceph — распределенным хранилищем данных с открытым исходным кодом. У него есть менеджмент-ноды — это несколько небольших, очень «тоненьких» платформ, на которых стоят его «мозги» — так называемые Ceph-мониторы. Ceph динамически вырезает нужные объемы данных на дисках, которые в системе хранения представляют собой своеобразные «вместилища» данных.
Ceph обеспечивает хранение трех копий каждого объекта. Допустим, клиент записывает на сетевой диск какую-нибудь картинку с котиком, при записи будет обеспечена соответственная избыточность всех поступивших объектов. После этого клиент получит «Ок» от хранилища.
Почему доверились Ceph
Amazon выпустила в релиз сетевые диски, или Elastic Block Storage, еще в 2008 году. Они были представлены как подключаемое хранилище, куда можно было складывать данные, как в отдельную папку.
Спустя пять лет, в 2013 году, появилась open source-реализация похожего механизма, которую можно было использовать с собственной виртуализацией. Это был Ceph в первом релизе под названием Dumpling — «пельмешка».
Когда мы начали развивать облако Selectel, Ceph был очень молодым инструментом. Еще не было понятно, хорошо он работает или не очень. Оголтело довериться Ceph мы не могли: система управления данными — очень ответственное место. Если она работает плохо, в лучшем случае — клиент будет испытывать затруднения с доступом к данным. В худшем, и это одна из распространенных архитектурных проблем, данные могут теряться частично или полностью.
Ceph относится к системам с раздельным хранением данных и метаданных. Это позволяет обрабатывать большую нагрузку без потери производительности, но и повышает риски. Если повреждаешь набор метаданных, все остальные терабайты бесполезны. Сeph — не та система, при поломке которой можно отказаться от ее использования и продолжить работать с данными как-то иначе. Поэтому разработчики Selectel и тогда и сейчас тратят очень много сил на подготовку надежного решения и времени на тестирование.
Интересно, что OpenStack мы доверились в достаточно сыром релизе. Но с ним все было значительно понятнее — легенькая «питонятина». Исправление ошибок было несложным: если что-то не работает, идешь и читаешь код, находишь место, где не работает, правишь прямо на продакшене — заработало.
А если не работает Ceph, написанный на «кучерявом» С, который ты как бы можешь прочитать, но на самом деле нет, то все скорее всего плохо. Разобраться тяжело, данные скопировать на флешку, пока разбираешься с проблемой, не выйдет — там же терабайты. Так что до подобного сценария доходить не хотелось.
Преимущества Ceph для провайдера
Чем еще хорош Ceph? Инструмент позволяет хранить данные на серверах разной конфигурации. Это хорошо, например, когда у тебя уже есть парк оборудования и надо просто хранить данные, которые не помещаются ни в один из имеющихся серверов. Поднимаешь Ceph — получаешь виртуальную систему хранения, распределенную по нескольким серверам. И в нее как раз можно уместить свой большой файл.
Какой профит для провайдера? Ceph позволяет легко производить апгрейд оборудования, которое входит в кластер. Мы в Selectel часто этим пользуемся. Например, новые зоны доступности или пулы запускаем на оборудовании с меньшим числом дисков. Можно выкатить с большим, но тогда ресурсы будут простаивать. Это невыгодно.
Когда утилизация ресурсов подрастает, мы просим инженеров поставить в хосты дополнительные диски. С помощью консольных утилит, которые идут в комплекте с Ceph, вводим их в использование. Система их распознает, добавляет, строит поверх них новые ячейки для хранения данных, начинает использовать. При этом еще и балансирует нагрузку в кластере так, чтобы данные распределялись и не перегружали систему.
Помимо добавления дисков, можно также менять производительность хоста за счет замены процессора. Например, мы видим, что появилось много клиентов, активно использующих диски. Утилизация CPU и RAM на хосте вырастает, а места для хранения данных еще достаточно много. Решить проблему достижения потолка производительности можно за счет замены процессора — без ущерба для СХД. Ceph для этого очень хорошо подходит.
Появление локальных дисков
Первые три года в облачной платформе Selectel не было локальных дисков вообще. И этим мы сильно отличались от других провайдеров, которые, по сути, предлагали односложные VDS. Стандартная VDS — это кусочек сервера: диска, памяти и CPU. Диск, естественно, локальный — часть диска хостовой системы.
Локальные диски использовались в продукте Vscale (сейчас VDS Selectel), который развивался параллельно облаку. В хостах виртуализации под Vscale стояли SSD-диски, в том время как в облаке на «железных» хостах был только системный диск самого сервера виртуализации, недоступный виртуальным машинам.
Почему в Vscale были локальные диски вместо сетевых? Продукт запускался как сервис с дешевыми виртуальными машинами. А инсталляция с сетевыми дисками значительно дороже, чем система хранения на локальных дисках, за счет нескольких особенностей:
- они хранят три копии каждого блока данных, а локальные диски — две,
- для хостов под сетевые диски требуются отдельные наборы CPU и памяти,
- нужно дополнительное сетевое оборудование с большим количеством портов.
С такой экономикой запустить качественный, но при этом дешевый инстанс за 200 рублей было совершенно невозможно. С локальным были шансы.
Локальные диски в облаке
Долгое время в облаке Selectel локальный диск считался оптимизацией, вариантом для тех пользователей, которым сетевые никак не подходят. Чаще всего это были клиенты, которые брали облачные серверы под базы данных. Им очень важно, чтобы время отклика на каждую запись было минимальным — чем быстрее, тем лучше. И локальные диски тут лучше работают — просто за счет архитектурных особенностей.
Локальный диск рядом с процессором, под боком буквально. Сетевой — на отдельном хосте. Между хостом виртуализации и сетевым диском оптоволокно и сетевое оборудование, через которые данные еще должны пролететь. А дальше в работу вступает Ceph, который еще записывает каждый блок информации три раза.
Поэтому сетевые диски медленнее — так у всех. Время записи одного блока информации на локальный диск составляет примерно 0,1-0,2 миллисекунды (или еще меньше при должной степени оптимизации). На сетевой диск тот же блок информации будет записываться 1-2 миллисекунды, если не больше. Для некоторых задач это допустимая разница, но есть клиенты, для которых увеличение латенси в 10 раз — крайне чувствительно. Для таких пользователей мы все-таки добавили локальные диски. Ведь облако, если в нем все правильно организовано, тоже хорошо справляется с базами данных.
Почему серверы с GPU — без локальных дисков
Когда мы запускали серверы с GPU в облаке, предлагали их и с локальным, и сетевым дисками. Перед этим не проводили глубинных интервью и опросов: под какие конкретно задачи нужны GPU, в какой комплектации. Да и сами пользователи на тот момент не всегда понимали, что им лучше подойдет. Была потребность в вычислениях на GPU — с таким запросом мы и работали.
В итоге оказалось, что локальные диски никто не брал. Брали сетевые. Логика была такая: видеокарты занимаются массивно-параллельными вычислениями, а сетевые диски лучше всего справляются именно с параллельной записью данных. Запись в один поток на сетевой диск не имеет смысла с точки зрения утилизации его возможностей.
Мы посмотрели на поведение пользователей и решили убрать локальные диски из хостов с GPU. Так мы снизили себестоимость платформы с GPU без ущерба для клиентов.
Если мы увидим, что появились другие пользовательские сценарии, что клиентам с серверами GPU для каких-то задач нужны именно локальные диски, мы их достаточно легко вернем.
Важная разница между локальными и сетевыми дисками
«Природу» дисков важно понимать для того, чтобы правильно относиться к обеспечению отказоустойчивости систем. Локальные и сетевые диски похожи в названии, их добавление в серверы в панели управления Selectel мало отличается друг от друга. При этом между ними достаточно большая разница. Сетевые диски ближе к дополнительному сервису, чем к нативной части сервера, коими являются, например, оперативная память или процессор.
Как у любого облачного решения, у сетевых дисков есть точки отказа, о которых важно помнить. Это гигантское хранилище, сохранность данных в котором зависит, по сути, от работы трех мониторов Ceph. Доступность данных зависит от работы сетевого оборудования и самих хостов хранения. Какие-либо поломки в этой системе приводят к деградации производительности. В самых неприятных случаях может произойти потеря данных, но такое в истории облака Selectel, к счастью, случалось всего раз и очень давно.
Это важно держать в голове и принимать соответствующие меры по обеспечению отказоустойчивости. Обязательно делать бэкапы, создавать резервные виртуальные машины, размещать их в разных пулах и зонах доступности. Как провайдер мы стараемся предоставлять здесь как можно больше решений: для этого в облаке появились балансировщики нагрузки, сервер-группы (anti-affinity), а также бэкапы сетевых дисков по расписанию.
Бэкапы сетевых дисков
Долгое время в тулките облачной платформы Selectel не было решения, которое помогло бы пользователям, у которых нет экспертизы или времени для должного резервирования данных. Хотя это критически важно. Бэкапы лежат в основе стратегии по обеспечению любого сервиса, запущенного в облаке (и не только), предсказуемой надежностью. Поэтому, как только у нас появились ресурсы, мы запустили такой сервис — бэкапы по расписанию.
Лишь недавно команда облачной платформы выросла до 70 разработчиков. Долгие годы число программистов в облаке было достаточно скромным. Много времени уходило на решение насущных проблем, так что задачи на разработку чего-то нового мы выбирали очень продуманно. Сейчас у нас отдельная команда дисков и бэкапов, которая занимается развитием сетевых дисков и инструментов резервного копирования.
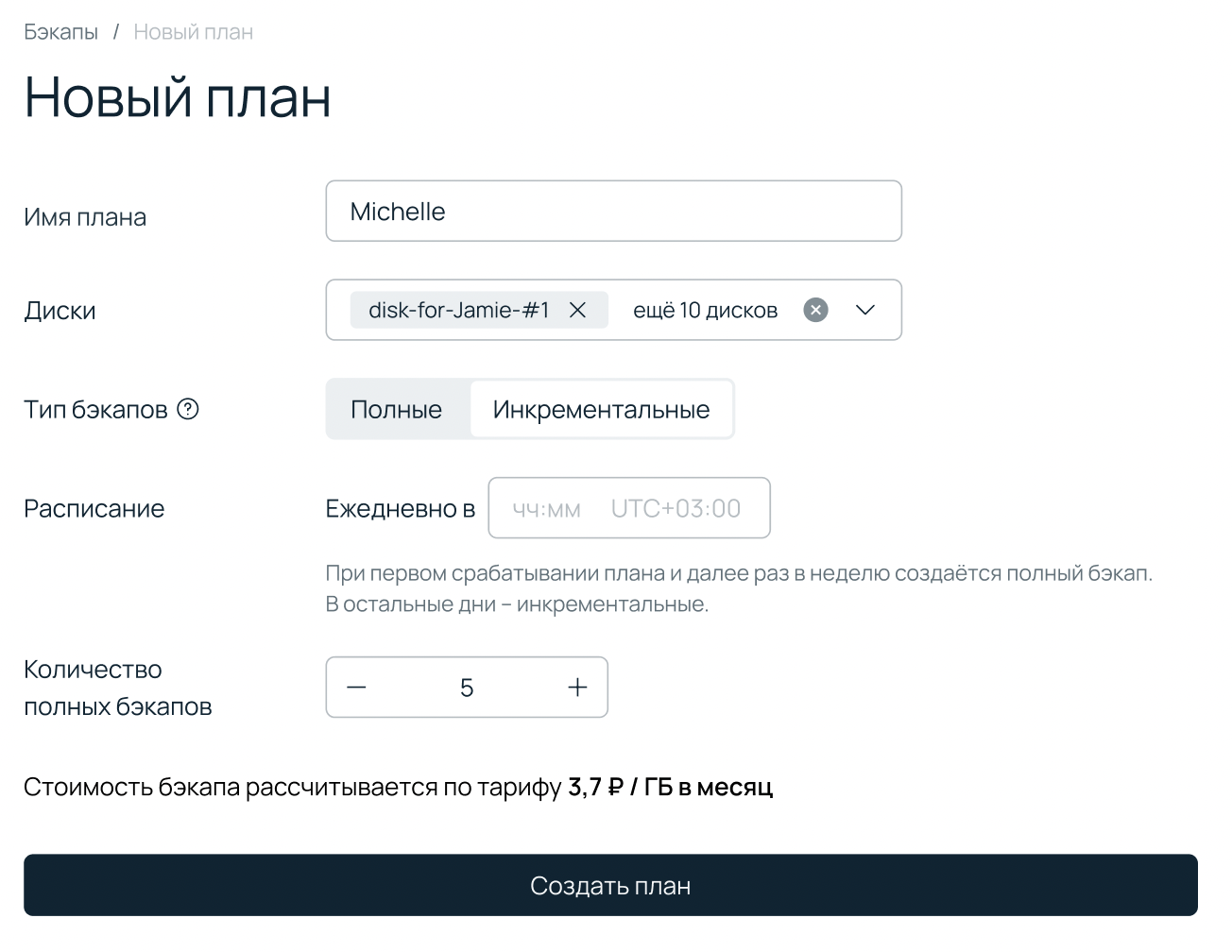
Сервису еще есть куда расти. Так, недавно мы добавили возможность создавать инкрементальные бэкапы, а не только полные. Параллельно повышаем изолированность хранения бэкапов от резервируемых данных. Следующим шагом видим внедрение фичи, которая позволит восстановиться из бэкапа в другой регион при недоступности изначальной локации. Все это позволит перейти от уровня «хотим просто сохранить копию каких-то данных», в основе которого — ручное восстановление из бэкапов, к уровню «обеспечиваем бесперебойный доступ», когда этот процесс более автоматизирован.
В основе бэкапов по расписанию — компоненты OpenStack Karbor, Cinder и Nova. Karbor умеет управлять расписаниями снятия бэкапов и отправлять команды в другие компоненты OpenStack. Он такой менеджер: запоминает, что настроил пользователь, помнит, когда делать бэкап, умеет правильно все организовать. Если упрощать, он управляет Cinder и Nova — говорит им «Ну-ка, построились, здесь берем — туда кладем».
В качестве хранилища нам тоже тут пригождается Ceph. Получается, мы используем этот инструмент для нескольких задач: он и сами данные с дисков хранит, и их копии, и бэкапы. Все в нескольких кластерах Ceph, которые развернуты в каждой зоне доступности.
Ну это же open source…
Кажется, что работаем с понятными компонентами: код открытый, есть комьюнити. Но работа по созданию такого сервиса — совсем не простая. Когда начинаешь доводить систему до уровня «оно работает в публичном облаке на тысячи клиентов», приходится очень много адаптировать и вычищать.
OpenStack — отлично подходит для частных облаков, в которых один системный администратор настраивает работу парка из 100 виртуальных машин. Что-то работает неэффективно — он этого даже не заметит. А когда у тебя тысячи виртуальных машин, начинают вылезать разного рода шершавости и ограничения.
По сути, команда, которая запускала бэкапы по расписанию, должна была правильно интегрировать Karbor в архитектуру нашего облака. Сделать так, чтобы он работал на наших объемах во всей красе. Но легко это звучит лишь на словах.
В следующей части истории облака расскажем про сеть L3 VPN, которая позволяет объединять выделенные и облачные серверы в единой инфраструктуре.





