

NVIDIA передает управление GPU в Kubernetes сообщество
«Зеленые» продолжают открывать свои технологии для всеобщего использования. NVIDIA на KubeCon Europe 2026 объявила, что передает драйвер Dynamic Resource Allocation (DRA) для GPU в Cloud Native Computing Foundation, то есть под управление upstream‑сообщества Kubernetes, а не одного вендора.
По сути, речь идет о важном для AI‑нагрузок слое оркестрации: DRA‑драйвер позволяет запрашивать и выделять GPU как полноценный ресурс с учетом топологии, памяти и межсоединений. Классическая модель вида nvidia.com/gpu:N, где GPU рассматриваются как простые счетчики ресурсов, плохо масштабируется для современных AI‑нагрузок.
В открытом драйвере уже поддерживается продвинутая оркестрация GPU: шеринг через MPS и Multi‑Instance GPU, статическая MIG‑разделка, а также ComputeDomains — абстракция для безопасного обмена памятью между узлами по Multi‑Node NVLink в системах уровня Grace Blackwell.
Одновременно NVIDIA при поддержке сообщества Confidential Containers добавила поддержку GPU в Kata Containers, чтобы запускать AI‑ворклоады в среде с более жесткой изоляцией и защитой данных. Это дает вписать аппаратное ускорение в конфиденциальные вычисления, когда критичные данные нужно обрабатывать внутри сильно изолированных окружений.
Параллельно компания интегрировала в общую экосистему сопутствующие проекты: систему ремедиации GPU‑ошибок NVSentinel, агентный AI‑фреймворк AI Cluster Runtime, стек NVIDIA NemoClaw и рантайм OpenShell для безопасного запуска автономных агентов с eBPF‑интеграцией. Плюс вынесла планировщик KAI Scheduler в CNCF Sandbox и открыла Grove — Kubernetes‑API для оркестрации AI‑нагрузок на GPU‑кластерах.
Важно, что NVIDIA подчеркивает это не как разовую «раздачу исходников», а как долгосрочную ставку на open source в enterprise‑AI: NVIDIA создает вместе с рынком единые стандарты для Kubernetes. Вместо закрытых вендорских решений разработчики получают открытые инструменты, из которых можно гибко собирать любые инфраструктурные системы.
NVIDIA о развертывании инференса LLM на Kubernetes
Традиционный монолитный сервер для LLM‑инференса упирается в разницу профилей нагрузки между prefill и decode.
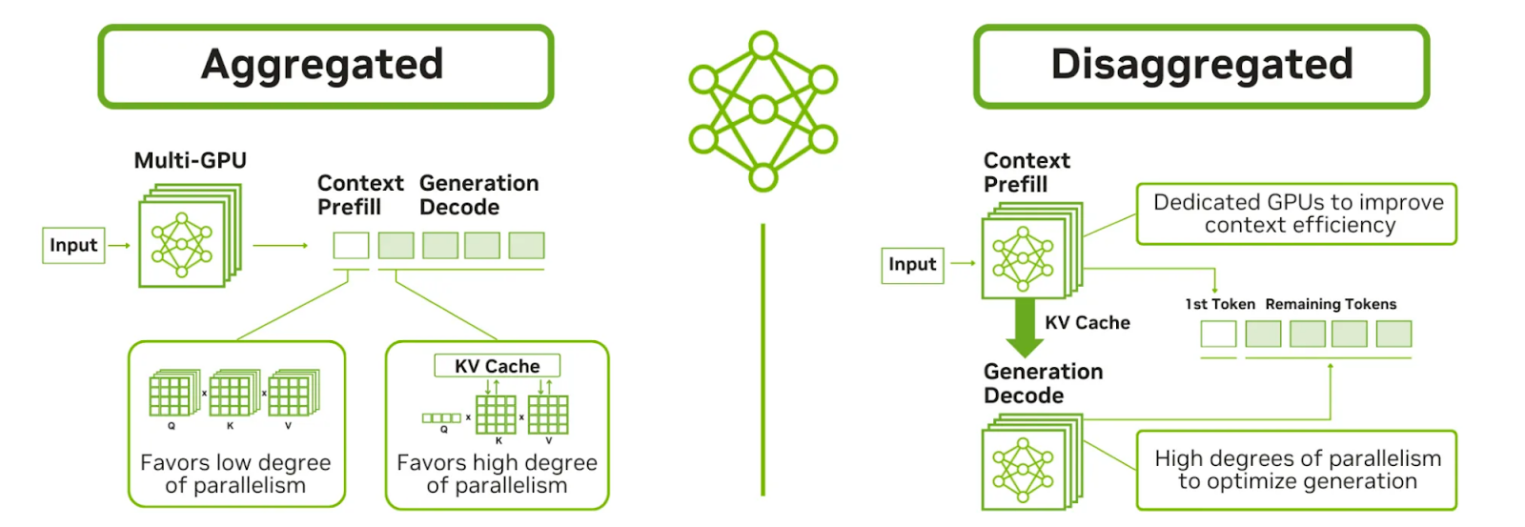
NVIDIA опубликовала технический разбор, как разделить инференс‑пайплайн на независимые сервисы prefill (вычислительно затратную), decode (ограниченную пропускной способностью памяти) и роутинг, чтобы масштабировать каждую стадию отдельно и лучше использовать GPU.
По сути, речь идет о переходе от агрегированного обслуживания, где один процесс тянет весь жизненный цикл от токенизации до генерации, к раздельному, где роли работают как отдельные сервисы с разными оптимизациями по ресурсам, шардингу и батчингу. Prefill задействует всю вычислительную мощь для параллельной обработки данных, тогда как decode опирается на скорость HBM‑памяти, а роутер распределяет KV‑кеш между ними для баланса нагрузки.
В статье показывают базовый подход через LeaderWorkerSet: каждая роль (prefill на четыре реплики с TP=2, decode на две реплики с TP=4) описывается отдельным ресурсом с атомарным планированием. Роутер при этом работает как обычный деплоймент, но без единой координации топологии между ролями и синхронизации обновлений — правила привязки (affinity) и автоскейлинг (HPA) настраиваются вручную.
Продвинутый вариант — NVIDIA Grove API через PodCliqueSet. В этой схеме весь конвейер — от маршрутизатора до параллельной работы блоков подготовки и генерации — задается единым описанием. В нем прописывается очередность запуска через параметр startsAfter, настраивается автоматическое масштабирование каждой роли по загрузке процессора и учитывается физическое расположение оборудования в стойках для работы высокоскоростных соединений NVLink.
За иерархическое групповое планирование отвечает диспетчер KAI. Оператор системы автоматически создает группы узлов PodCliques и PodGang, а также пусковые контейнеры для соблюдения строгого порядка активации сервисов. При этом специальный компонент масштабирования PodCliqueScalingGroup не дает системе дробить группы серверов при масштабировании, сохраняя нужную пропорцию узлов.
NVIDIA развивает это как часть открытой экосистемы для оркестрации AI. В основе лежат стандартные инструменты сообщества и собственные расширения вроде Grove и KAI. Весь стек оптимизирован под задачи бизнеса: он позволяет независимо масштабировать сервисы, сохраняя сетевую топологию и эффективно использовать аппаратные ресурсы.
NVIDIA выпускает Dynamo 1.0 для масштабного инференса LLM
Наконец-то вышла первая версия Dynamo. Долгожданная стабильная версия фреймворка с KV Cache Router и KV Block Manager.
Снова анонс от NVIDIA, релиз Dynamo 1.0 — готовой для использования в продакшене платформы для мультинодового инференса, которая позиционируется как open source «ОС для AI‑фабрик» с фокусом на оптимизацию KV‑кеша, динамическое планирование GPU и маршрутизацию запросов.
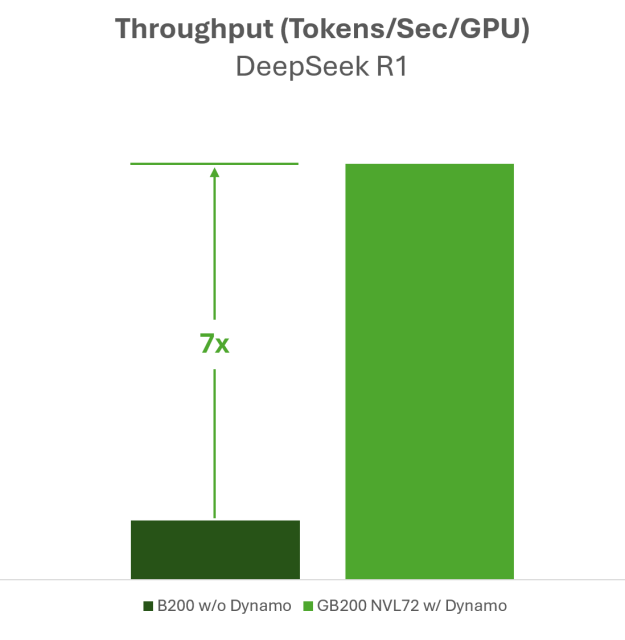
Платформа поддерживает SGLang, TensorRT‑LLM, vLLM. Согласно исследованию компании SemiAnalysis (бенчмарк InferenceX), запуск модели DeepSeek R1 на архитектуре Blackwell дает семикратный прирост пропускной способности на одну GPU. Кроме того, решение лидирует в тестах MLPerf.
Ключевые нововведением стал KV Cache Router с поддержкой «агентских подсказок» (agentic hints). Он анализирует задержки и ожидаемую длину ответа, чтобы приоритизировать сложные многошаговые сессий через закрепление кэша.
За ним следует KV Block Manager (KVBM), который реализует многоуровневое кэширование по цепочке GPU → CPU → SSD → S3. Этот компонент поддерживает глобальные события контекста и устанавливается через pip напрямую в движки инференса.
Принцип работы компонентов
- Маршрутизатор работает в exact mode (через события ZMQ в префиксном дереве) или в режиме прогнозирования по истории запросов. Поддерживается настройка размера блоков и оценка совпадения контекста (overlap scoring).
- Менеджер блоков (KVBM) управляет выделением ресурсов, правилами вытеснения и удаленным доступом, сводя к минимуму повторные вычисления при нехватке видеопамяти (HBM).
Для мультимодальных задач реализовано разделение этапов кодирования, подготовки и генерации (disaggregated encode/prefill/decode) с кэшированием эмбеддингов в оперативной памяти. Это дает ускорение времени до первого токена (TTFT) до 30% и рост пропускной способности на 25% (на примере Qwen3-VL-30B на системах 200 ГБ). А еще добавлена нативная поддержка генерации видео (FastVideo, SGLang Diffusion).
NVIDIA представляет Groq 3 LPX для Vera Rubin платформы
После покупки Groq — это первая стоечная система для агентного AI с экстремально низкой задержкой генерации токенов.
NVIDIA раскрыла стойку Groq 3 LPX:
- конфигурация — 256 чипов Groq 3 LPU в MGX ETL rack для Vera Rubin NVL72;
- производительность — 315 PFLOPS;
- память — 128 ГБ SRAM;
- пропускная способность — 40 ПБ/с пропускная способность памяти при 640 ТБ/с межчиповой связи.

LPX работает в паре с GPU Rubin: Rubin NVL72 обрабатывает заполнение prefill и attention — высокопроизводительные задачи с длинным контекстом, LPX ускоряет генерацию токенов (decode) — сверхбыстрые вычисления FFN и MoE-экспертов через разделение attention-FFN с передачей промежуточных активаций.
Итог: энергоэффективность выросла в 35 раз на мегаватт, а доходность при работе с триллионными моделями увеличилась в десять раз по сравнению со стойкой GB200 NVL72.
Groq 3 LPU (7-й чип Vera Rubin) работает с векторами по 320 байт и объединяет тензорные, матричные, векторные и коммутационные блоки. В каждом чипе 500 МБ памяти SRAM без кэшей (компилятор управляет размещением).Для предсказуемого масштабирования предусмотрено 96 линий C2C со скоростью 112 Гбит/с.
Характеристики вычислительного лотка (8 чипов с жидкостным охлаждением):
- производительность — 9,6 PFLOPS (FP8);
- память — 4 ГБ SRAM;
- пропускная способность — 1,2 ПБ/с.
Для агентных систем открываются новые возможности. NVIDIA Rubin берет на себя массовый инференс и пакетные задачи, а Groq LPX обеспечит генерацию «на уровне мысли» — более 1 000 токенов в секунду на пользователя. Такая скорость дает полноценную совместную работу в реальном времени для кодовых ассистентов и сложных голосовых интерфейсов. Архитектура Dynamo при этом оркестрирует связку GPU и LPX для decode.
Черновая генерация: LPX быстро набрасывает варианты текста, а Rubin их подтверждает. Это выгодно: доход с каждого мегаватта энергии у Rubin выше в пять раз, а у LPX — в десять раз. При этом пользователь получает 400 токенов в секунду даже на огромных текстах.
Cursor Composer 2 оказался доработанным Kimi 2.5 от Moonshot AI
Cursor заявила о запуске Composer 2 — «frontier‑уровневую модель для кодирования», но пользователь X по имени Fynn быстро раскрыл, что это Kimi 2.5 (открытая модель Moonshot AI, Китая, Alibaba/HongShan) с дополнительным обучением RL.

Стартап США ($2,3 млрд инвестиций, $29,3 млрд оценка, $2 млрд годового дохода) не упомянул базу в анонсе. Вице‑президент Ли Робинсон признал: «1/4 вычислений от базовой модели, остальное — наше обучение, бенчмарки сильно отличаются». Kimi подтвердила лицензионное партнерство через Fireworks AI.
Сооснователь Аман Сангер извинился: «ошибка — не указать Kimi‑базу в блоге, исправим в следующей модели».
NVIDIA запускает BlueField‑4 STX для хранилищ AI-агентов
NVIDIA представила на GTC 2026 BlueField‑4 STX — эталонную архитектуру для ускоренного хранения под агентные AI. Она решает проблему узкого места KV‑кеша при длинных сессиях и больших контекстах.

Решение построено на BlueField‑4 DPU (хранилище‑ориентированный) и сетевых карт ConnectX‑9 SuperNIC. По сравнению с обычными CPU‑хранилищами, такая связка выдает в пять раз больше токенов в секунду, работает в четыре раза энергоэффективнее и вдвое ускоряет загрузку данных.
Проблема: KV‑кеш (пара ключ‑значение для attention) растет до сотен тысяч токенов, не помещается в память GPU, что приводит к выгрузке в оперативку/SSD через процессор хоста, задержкам и простоям GPU. STX минует CPU через RDMA по Spectrum‑X Ethernet, BlueField‑4 напрямую управляет NVMe SSD, шифрует и проверяет KV‑данные.
BlueField‑4 STX станет частью платформы Vera Rubin, работая в связке с Vera CPU, ConnectX‑9, Spectrum‑X Ethernet, DOCA и AI Enterprise. Первым продуктом на этой базе станет контекстное хранилище CMX.
Экосистему поддержали все крупные игроки рынка. В разработке систем и хранилищ участвуют DDN, Dell, HPE, IBM, NetApp и VAST Data, а также производители оборудования AIC, Supermicro и Quanta. К технологии уже получили ранний доступ восемь облачных провайдеров, включая CoreWeave, Lambda, Mistral AI и Oracle Cloud. Первые поставки оборудования начнутся во второй половине 2026.
Как отметил CEO Дженсен Хуан: «Agentic AI is redefining what software can do — and the computing infrastructure behind it must be reinvented to keep pace».
UALink и DMTF объединяют стандарты для AI‑инфраструктуры
В конце февраля вышла новость про официальное взаимодействие двух организаций про высокопроизводительную передачу данных.
Объединения UALink Consortium и DMTF заключили партнерство, чтобы объединить высокопроизводительные системы для GPU и AI‑ускорителей с инфраструктурным управлением. Это партнерство позволит нативно контролировать состояние, настройки и безопасность через открытые протоколы Redfish, PLDM, SPDM.
UALink — открытый интерконнект для accelerator‑to‑accelerator связи с высокой пропускной способностью и низкой задержкой, объединяющий GPU в единый вычислительный ресурс для крупных моделей. DMTF дает кросс‑вендорные стандарты обнаружения оборудования, телеметрии, конфигурации и защиты.
UALink и DMTF нацелены на комплексное управление фабриками ускорителей, внедрение Redfish‑моделей для устройств на базе UALink и совместную работу в рабочих группах DMTF. Это обеспечит бесшовную интеграцию next‑gen interconnect в стандартизированные фреймворки управления.
Итог: высокопроизводительная связь + зрелое управление = масштабируемые, безопасные AI‑деплойменты в мульти‑вендорных средах. Ждем ускорения выпуска и внедрения новых спецификаций.
SambaNova анонсирует SN50 RDU для агентного инференса

Пятое поколение RDU с Dataflow‑архитектурой превосходит GPU по задержкам и совокупной стоимости владения.
SambaNova представила процессоры SN50 RDU и серверные стойки SambaRack SN50. Это решения для систем AI-агентов, которые устраняют главную проблему инференса — задержки при передаче данных. В тестах на модели Llama 3.3 (70B) система показала в пять раз выше скорость и в три раза больше пропускную способность в сравнении с NVIDIA Blackwell B200, потребляя всего 20 кВт при воздушном охлаждении.
Работа агентов требует мгновенного отклика для длинных цепочек вызовов — например, при написании кода. Если быстрые режимы на GPU (как у Anthropic) стоят в шесть раз дороже обычных, то SN50 позволяет запускать модели до 10 трлн параметров с контекстом в 10 млн токенов без потери скорости и переплат.
Технологические новшества
- Многоуровневая память (HBM + SRAM) позволяет менять модели за миллисекунды и кэшировать входящие токены, что резко сокращает время до первого ответа (TTFT).
- Масштабируемость. Стойка SambaRack на 16 чипов в пять раз мощнее предыдущей версии. Системы объединяются в кластеры до 256 ускорителей с пропускной способностью в несколько терабайт в секунду.
Потоковая архитектура (Dataflow) выстраивает граф модели как кратчайший путь для данных. Это исключает лишние обращения к памяти, что снижает задержки и энергопотребление.
Итог. Поставки начнутся во второй половине 2026 года. Для провайдеров AI-услуг стоимость владения (TCO) будет в 8 раз ниже, чем на традиционных фермах GPU.
Подробности о других новинках индустрии читайте в прошлом дайджесте. А чтобы не пропускать важные обновления из мира AI и Big Data, следите за новостями в Академии Selectel.





