

Меня зовут Рома, и я работаю в объектном хранилище — самой высоконагруженной услуге Selectel. Здесь мы непрерывно трудимся над улучшением и развитием архитектуры, удовлетворяя спрос на пропускную способность, функциональность и надежность.
В первой части я поделился сложностями, которые возникают при попытке построить распределенное и отказоустойчивое хранилище для объектов. Та система, которую мы позволили себе нафантазировать, очень похожа на OpenStack Swift. С него начиналась история нашего продукта, так что мы можем не только разобрать принцип его работы «на пальцах», но и погрузиться в скрытые особенности OpenSource, которые проявляются лишь в больших масштабах.
В предыдущей серии
В объектном хранилище можно сохранить набор данных по ключу, а потом забрать их обратно. Ему не важно, что это за данные и как вы с ними работаете. Если мы скажем хранилищу «возьми эти 500 мегабайт и сохрани под именем backup/latest/users.sql.tar.bz2» — оно возьмет и сохранит. А еще сделает так, чтобы данные оставались в целости и были доступны круглосуточно. При необходимости — кому угодно и на высокой скорости.
Этого можно добиться, если трижды дублировать данные на разных серверах в разных стойках. Чтобы полностью их потерять, трем дискам в трех стойках придется выйти из строя одновременно. Причем именно тем дискам, где лежит одна и та же информация, и именно одновременно. Ведь как только откажет один из дисков, его содержимое переедет на другой, рабочий. Короче, редкость.
Кроме защиты от потерь, распределенное хранение повышает доступность данных. Факт выключения сервера может не повредить данные, но сделает их недоступными. Когда таких серверов несколько — бояться нечего. Можно хранить бекапы, раздавать обновления прошивок на устройства, загружать картинки для каталога интернет-магазина и все в таком духе.
Такие особенности и делают построение хранилища сложным. Хеш-кольцо решает часть проблем: для объекта вычисляется номер группы (партиция), к которой он принадлежит. Групп много, и они распределены по дискам так, чтобы каждая из них присутствовала на разных дисках в 3 экземплярах. Распределение групп хранится в специальном файле (кольце), а при изменении количества дисков переназначается лишь необходимый минимум.
Примерно так должна работать система, созданная нами в предыдущей части. Именно так и работает OpenStack Swift, в котором эта идея используется не только для хранения самих объектов, но и для организации базы данных с листингами аккаунтов и контейнеров. Но обо всем по порядку.
Пасть зверя
Swift состоит из множества компонентов, но они во многом повторяют друг друга. Похвастаюсь: наше фентезийное хранилище из предыдущей части специально сделано похожим на него, чтобы не пугать читателя ворохом терминов.
Начнем оттуда, где хранятся сами объекты.
Swift Object Server
Помните, мы создавали API, который работает непосредственно с объектами на локальных дисках? Пользователь отправляет HTTP-запрос, а приложение обращается на нужный диск для чтения или записи объекта. Это как раз он.
Диск — минимальная единица репликации в Swift. Он не обязан быть отдельным физическим устройством, или вообще устройством какого-то конкретного типа с точки зрения операционной системы. Swift не работает низкоуровнево и хранит объекты в файловой системе, а значит при желании можно расположить данные где угодно, хоть в оперативной памяти.
В классическом сценарии мы используем XFS и монтируем все диски по общему пути. Например, /srv/node. Тогда данные диска disk001 будут храниться в /srv/node/disk001 и далее в таком духе.
Акт дрессировки
Компоненты Swift распределяют данные по дискам при помощи колец. Это такие файлы, где для каждой партиции указано, на каких дисках она должна находиться. Чтобы создать кольцо, мы воспользуемся утилитой swift-ring-builder. Кроме формирования хеш-кольца, она распределяет партиции по дискам и следит как за поддержанием уровня репликации, так и за объемами миграций, не позволяя мигрировать больше одной копии данных за раз.
Нужное количество реплик и партиций мы выбираем самостоятельно, исходя из требований к работе сервиса. Пусть будет 3 и 1024 соответственно. Для каждого диска указывается адрес машины, имя диска и вес — пропорция, которая будет учитываться при назначении партиций. У нас все диски одинаковые, так что укажем вес 100 — с запасом на будущее.
Вот так будет выглядеть наше кольцо:
user@machine rings % swift-ring-builder object.builder
object.builder, build version 4, id 5129443ec5664f5681a451e003bb011b
1024 partitions, 3.000000 replicas, 1 regions, 3 zones, 3 devices, 0.00 balance, 0.00 dispersion
The minimum number of hours before a partition can be reassigned is 1 (0:00:00 remaining)
The overload factor is 0.00% (0.000000)
Ring file object.ring.gz is up-to-date
Devices: id region zone ip address:port replication ip:port name weight partitions balance flags meta
0 1 1 object-server-1:6000 object-server-1:6000 disk001 100.00 1024 0.00
1 1 2 object-server-2:6000 object-server-2:6000 disk001 100.00 1024 0.00
2 1 3 object-server-3:6000 object-server-3:6000 disk001 100.00 1024 0.00Все 1024 партиции были назначены каждому диску. Это верно, ведь наш фактор репликации — 3, вот каждая партиция и существует в трех экземплярах. Отдельно стоит упомянуть отказоустойчивость. Видите столбцы region и zone? Это домены отказа. Они указываются при добавлении диска и влияют на распределение партиций. Сервер тоже является таким доменом.
Акт взаимодействия
Тянуть нечего. Раз мы имеем дело с API, нужно срочно отправить в него запрос и посмотреть, что там из него выйдет. Формат URL простой:
/<disk>/<partition>/<account>/<container>/<object>Именно так, с указанием диска и даже партиции. Дело в том, что Swift переносит ответственность снизу-вверх, а значит API объектов умеет лишь получать и отдавать их, но сам не разбирается с кольцами и репликацией. Это становится задачей клиента — того, который непосредственно работает с данными. Либо, в случае с репликацией, отдельного демона.
C URL разобрались, дело за малым: тело объекта — это тело запроса, а все его метаданные представлены в виде заголовков. Для указания типа операции используются стандартные методы HTTP:
- PUT — создать объект,
- POST — изменить объект,
- GET — получить объект,
- HEAD — получить только метаданные объекта,
- DELETE — удалить объект.
Здесь и далее мы будем использовать легенду о пользователе Misha, который положил в контейнер my-passwords объект production.txt. Согласен, звучит сомнительно. Но винить мы его не можем.
Напомню, что контейнер — это хранилище для объектов. Все объекты лежат в контейнерах, так что каждый аккаунт — это набор контейнеров, а каждый контейнер — набор объектов. На этом матрешка заканчивается.
Будучи клиентом сервера объектов, мы должны воспользоваться кольцом и определить партицию, машину и диск, где должен находиться объект. Так как имена объектов уникальны только в рамках аккаунта и контейнера, хешировать нужно связку этих значений. Для любителей терминала есть специальная утилита:
user@machine:~ $ swift-get-nodes /etc/swift/object.ring.gz Misha my-passwords production.txt | head -12
Account Misha
Container my-passwords
Object production.txt
Partition 156
Hash 273396a17dfc677e023bccfcae4e6dec
Server:Port Device object-server-3:6000 disk001
Server:Port Device object-server-2:6000 disk002
Server:Port Device object-server-1:6000 disk001Вот так просто — мы указали кольцо и передали аргументы, по которым вычисляется хеш. Теперь мы знаем, какой партиции соответствует объект, и на каких дисках она находится. Мы можем сделать запрос на любой из указанных в списке серверов и увидеть содержимое объекта:
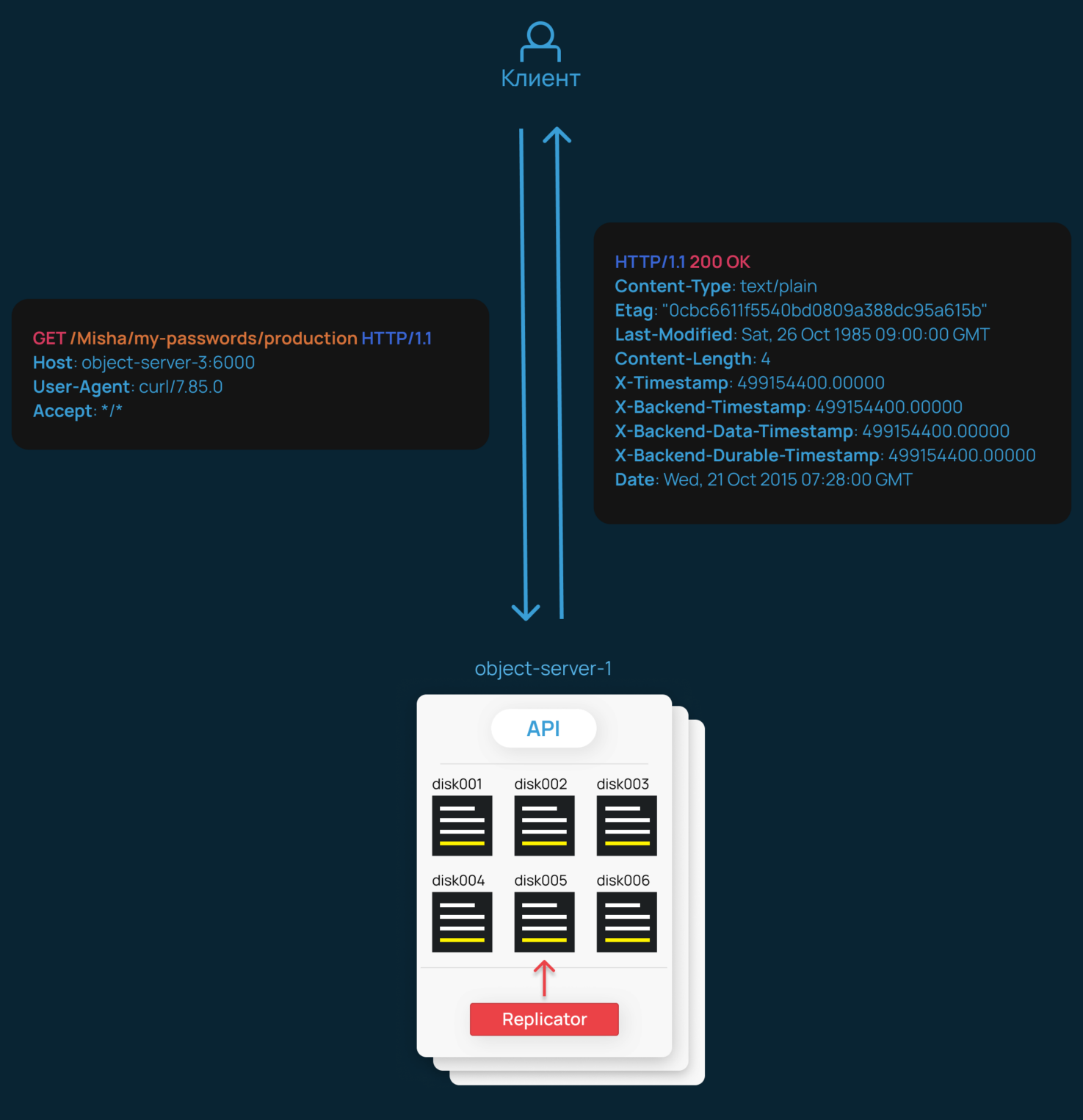
user@machine:~$ curl -i http://object-server-3:6000/disk001/156/Misha/my-passwords/production.txt
HTTP/1.1 200 OK
Content-Type: text/plain
Etag: "482c811da5d5b4bc6d497ffa98491e38"
Last-Modified: Sat, 26 Oct 1985 09:00:00 GMT
Content-Length: 11
X-Timestamp: 499154400.00000
X-Backend-Timestamp: 499154400.00000
X-Backend-Data-Timestamp: 499154400.00000
X-Backend-Durable-Timestamp: 499154400.00000
Date: Wed, 21 Oct 2015 07:28:00 GMT
password123Смело заявляю, что тест по ИБ Misha провалит. Но наш интерес в другом: кроме позорного содержимого, в ответе видны метаданные объекта. Например, его хеш или время последнего изменения. Все они присваиваются объекту автоматически, но Swift позволяет пользователю хранить и произвольные метаданные.
Не все они носят информационный характер. Некоторые влияют на функциональность. Например, можно указать время для автоматического удаления объекта или использовать при запросе заголовки If-Modified, чтобы получать только объекты, обновленные позже указанной даты.
Копнем поглубже и найдем этот объект на диске. Путь выглядит так:
/srv/node/<disk>/objects/<partition>/<hash_low>/<hash>/<timestamp>.dataВсе объекты сгруппированы в директории по номеру партиции и младшим байтам своего хеша. Само содержимое находится в файле, название которого сформировано из времени последнего изменения и суффикса .data. Вот так:
swift@object-server-3:~$ cat /srv/node/disk001/objects/156/dec/273396a17dfc677e023bccfcae4e6dec/499154400.00000.data
password123Внутри файла находится содержимое объекта в «чистом» виде. Но откуда берутся метаданные? Они хранятся в виде расширенных атрибутов этого файла, но иногда для их хранения используются и отдельные файлы с суффиксом .meta. Это зависит от того, как и в какой последовательности изменялся объект. Например, если я изменю метаданные для уже существующего объекта, не меняя его содержимое, они будут записаны как атрибуты отдельного .meta-файла.
При каждом изменении объекта создается новый файл с уже другим timestamp в названии. Если в контейнере не включено версионирование данных, существующая копия удалится. На этом основан механизм репликации, о котором мы поговорим позднее. Главное, что нужно знать — более позднее значение имеет приоритет при чтении. Кто последний записал версию объекта — тот и прав. Last Write Wins, как говорила моя учительница английского.
Акт увлечения
Настало время объявить следующих участников конкурса «Объектное хранилище 2011». На сцене появляется вереница вспомогательных демонов, которые поддерживают работу Object Server.
Object Replicator
Именно этот демон поддерживает копии объектов в актуальном состоянии. Принцип работы простой: содержимое локального диска периодически сравнивается с дисками на других серверах. При наличии у него более свежей копии, демон отправляет ее на удаленный сервер посредством rsync.
Вот основные ситуации, когда это происходит:
- Одна из реплик в принципе не получила данные из-за сетевого сбоя. Репликатор увидит недостачу и восполнит ее.
- Мы изменили содержимое кольца. Некоторые партиции переместятся и репликатор приведет содержимое дисков в актуальное состояние.
- Один сервер вышел из строя. В момент недоступности репликатор расположит данные на резервной партиции, а после – убедится, что вернувшийся в строй сервер содержит актуальные данные.
Во всех случаях демон гарантирует, что данные в конечном счете все равно окажутся там, где должны быть. Eventual Consistency.
Интересным образом реализовано удаление: так как нам нужно достоверно распространить информацию об удалении объекта на другие серверы, фактически на диске создается новая версия файла с пустым содержимым и с суффиксом .ts — tombstone. Если одна из реплик не сможет обработать команду на удаление данных и файлы останутся на диске, она не станет заново помещать их на остальные машины, посчитав, что у нее имеется свежая копия. Наоборот, более свежей копией окажется tombstone, который будет передан этой реплике при ближайшем выполнении репликации.
Когда истечет окно консистентности, такие файлы будут удалены навсегда. Размер этого окна дольше интервала репликации, так что предполагается, что к этому моменту не останется неактуальных реплик.
Object Updater
Этот небольшой демон применяет отложенные изменения листинга. Мы еще не говорили про листинги, так что эту информацию пока достаточно лишь запомнить. Всему свое время.
Object Expirer
Этот демон удаляет объекты по истечении их срока жизни.
Помните, я упоминал, что в Swift можно установить объекту специальные метаданные, позволяющие удалить его в нужный момент? Вот здесь это и происходит.
Object Auditor
Демон призван находить некорректные объекты на диске. Работает это просто: у каждого объекта сравнивается фактически хеш и тот, что указан в метаданных. Если есть расхождения, объект перемещается в отдельную директорию и с этой машины больше не отдается.
Предполагается, что корректная версия будет реплицирована с другой машины, либо вмешается человек и наведет порядок.
Акт разочарования
Легким галопом мы промчались по основным моментам работы с объектами. На первый взгляд, все выглядит хорошо и бодро. На второй, а также все последующие, начинают закрадываться подозрения.
Ругаться начну с порога: главная архитектурная проблема кроется в использовании файловой системы для хранения объектов. Будто этого мало, метаданные хранятся в расширенных атрибутах файловой системы. Чем это грозит?
Можно опасаться истощения запаса inode, но это небольшое учебное зло. В конце концов, для этого на каждом диске должно оказаться не меньше миллиарда файлов — не так и мало.
Реальная проблема заключается в сложности дерева, на обход которого (особенно при внесении изменений) требуется время. А еще место в оперативной памяти. Со временем такая конструкция начнет отвечать на запросы все дольше, и не существует простого способа с этим бороться. Хранилочка просто будет тормозить.
Шутка ли, но мои коллеги видели, как Slab Cache съедает всю оперативную память, а lsвыполняется на машине две недели. Дебажить такое страшно.
Замедление работы с диском особенно заметно на вспомогательных демонах, для многих из которых обход файловой системы — основная задача. Время их работы может увеличиться настолько, что они станут практически бесполезными. Конечно, в реальности это вопрос конкретной нагрузки, и на какое-то время его можно решить использованием быстрого железа или кэш-прослоек.
Другая проблема — это распределение данных. Хешируя имена, мы равномерно размещаем на дисках сравнимое количество данных, но не их объем. На практике выходит так, что разница в утилизации дисков достигает 20%. И с этим тоже просто так ничего не сделать.
Предлагаю поговорить о чем-то поинтереснее самих объектов. Мы уже знаем, как загрузить или скачать один конкретный объект. Но как получить список всех объектов в контейнере, ведь они находятся на разных машинах? Как вообще работает управление этими контейнерами?
Swift Container Server
Каждый объект в хранилище хранится в каком-нибудь контейнере. Это единственная ступень в иерархии, которая позволяет разделять объекты между собой.
Функционально контейнер — это список объектов. В Swift хранение информации о контейнерах реализовано в виде отдельного API — Container Server. Я уже говорил, что компоненты Swift очень похожи друг на друга. Тут оно во всей красе.
С точки зрения API, контейнер практически неотличим от объекта. Схожий путь, те же методы, да даже метаданные у контейнера тоже имеются. Через них можно изменять не только поведение сервера, но и особенности хранения данных. Например, в Selectel отдельный контейнер можно сделать доступным для всех без авторизации, либо хранить данные в холодной зоне — так намного дешевле, если их много, а обращения редкие.
Главное отличие от сервера объектов здесь в том, что мы работаем уже не с отдельными файлами на диске, а со строками базы данных. Под капотом здесь самый обычный SQLite, а главная шутка в том, что способы доступа и обеспечения отказоустойчивости вам уже знакомы.
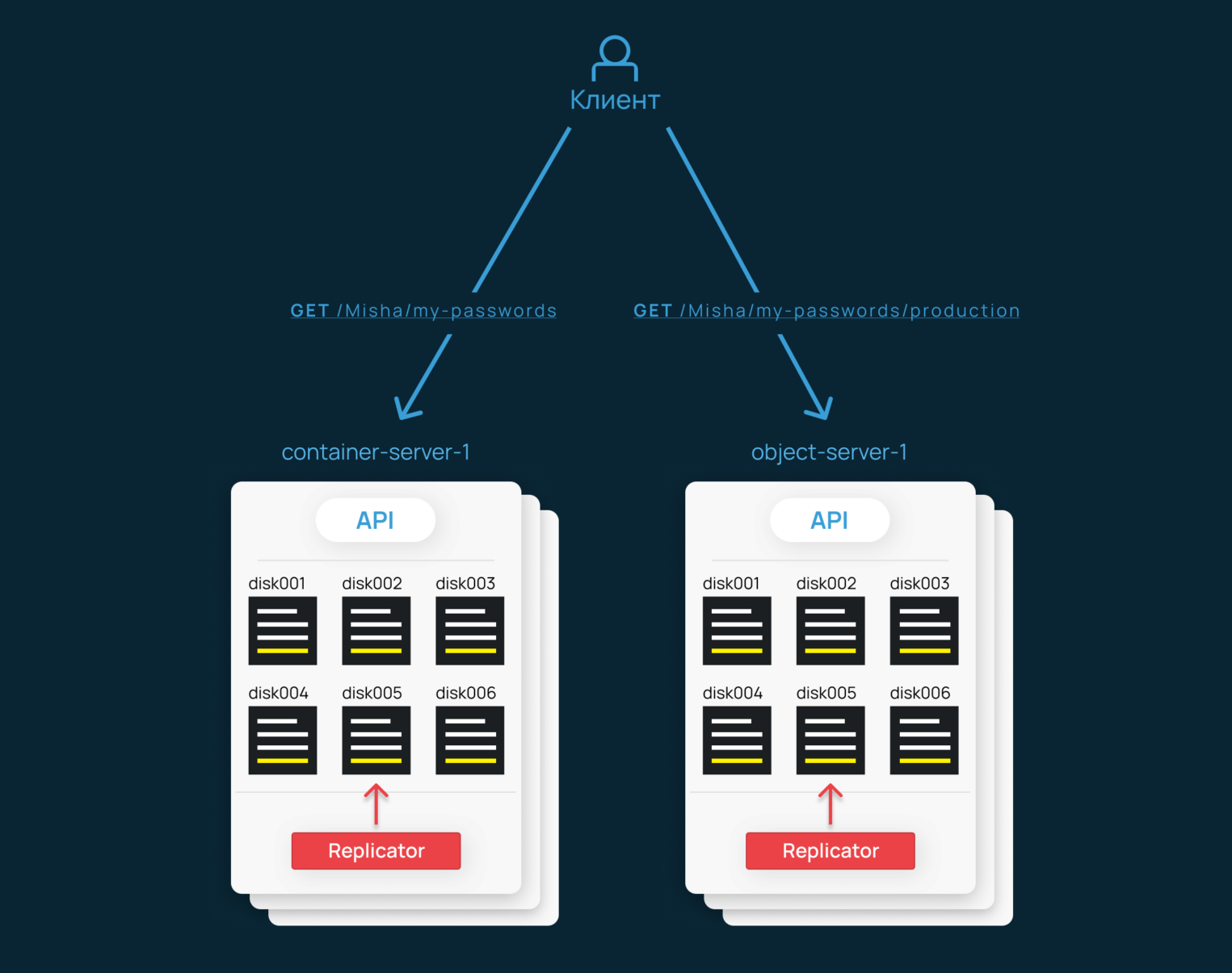
Решил сразу показать картинку, чтобы вы не подумали, что я что-то недоговариваю. Здесь снова используется хеш-кольцо. Только теперь мы определяем расположение на диске не объекта, а файла БД.
С репликацией история та же: периодически опрашиваем другие машины и отправляем на них свежие данные при необходимости. Если разница слишком велика — передаем файл базы данных целиком, используя rsync. Если данных не очень много, используем внутренний метод логической репликации. Он тоже работает по Push-принципу, только здесь мы передаем лишь необходимые строки через HTTP.
Сегодня такая схема вызывает смешанные эмоции. Люди написали километры кода на Python для того, чтобы реплицировать SQLite и сделать из него API. Код, который надо поддерживать, и который может сломаться. Но потом я вспоминаю, что на заре Swift в широкой доступности не было магических технологий, распределенных БД. Либо были, но в весьма зачаточном состоянии.
В любом случае, это работает. Гарантии для контейнеров такие же, как и у объектов — доступность и отказоустойчивость обеспечиваются распределением нескольких копий по разным доменам отказа. Принцип согласованности реплик тоже не изменился: рано или поздно данные точно должны стать актуальными.
Делаем запрос
Раз задача этого сервера — работа с содержимым контейнера, этим мы и займемся. Правила формирования URL и хеширования здесь те же самые. Начнем с последнего:
user@machine:~$ swift-get-nodes /etc/swift/container.ring.gz Misha my-passwords | head -9
Account Misha
Container my-passwords
Partition 792
Hash c621842628b132f47522f157c7f83143
Server:Port Device container-server-3:6001 disk004
Server:Port Device container-server-2:6001 disk001
Server:Port Device container-server-1:6001 disk003На этот раз мы указываем кольцо для контейнеров, а в качестве аргумента передаем лишь два параметра — имя аккаунта и контейнера. Но результат тот же: номер партиции и диски с машинами, на которых ее можно найти.
Сделаем запрос, но укажем параметр format=json, чтобы получить листинг в развернутом формате (по умолчанию вернется текстовый список объектов в контейнере):
user@machine:~$ curl -i http://container-server-3:6001/disk004/792/Misha/my-passwords?format=json
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
Content-Length: 176
X-Backend-Timestamp: 499154400.00000
X-Backend-Put-Timestamp: 499154400.00000
X-Backend-Delete-Timestamp: 0000000000.00000
X-Backend-Status-Changed-At: 499154400.00000
X-Backend-Storage-Policy-Index: 0
X-Container-Object-Count: 1
X-Container-Bytes-Used: 11
X-Timestamp: 499154400.00000
X-Put-Timestamp: 499154400.00000
X-Backend-Sharding-State: uncharted
X-Backend-Record-Type: object
X-Backend-Record-Storage-Policy-Index: 0
Last-Modified: Sat, 26 Oct 1985 09:00:00 GMT
Date: Wed, 21 Oct 2015 07:28:00 GMT
[
{
"bytes": 11,
"hash": "482c811da5d5b4bc6d497ffa98491e38",
"name": "production.txt",
"content_type": "text/plain",
"last_modified": "1985-10-26T09:00:00.000000"
}В отличие от Object Server, вместо содержимого объекта мы получили содержимое контейнера — список объектов в нем (листинг). В заголовках все так же находятся метаданные.
А что на диске? Знакомая нам картина, только теперь мы храним файлы БД вместо объектов. Логика такая: один контейнер — один файл. Правила формирования пути неизменны:
/srv/node/<disk>/containers/<partition>/<hash_low>/<hash>/<hash>.dbЗдесь мы не увидим timestamp в названии, так как все изменения происходят внутри самой базы данных. Будет правильным упомянуть, что на самом деле сервер листингов этим не ограничивается и все-таки использует дополнительные файлы. Например, у него есть собственное подобие WAL. Но об этом можно узнать и из кода, если интересно.
Посмотрим на содержимое базы данных контейнера и для начала изучим состав таблиц:
swift@container-server-3:~$ sqlite3 /srv/node/disk004/containers/792/143/c621842628b132f47522f157c7f83143/c621842628b132f47522f157c7f83143.db '.tables'
container_info incoming_sync outgoing_sync shard_range
container_stat object policy_statНазвания по большей части говорят сами за себя. Заглянем в таблицу object:
swift@container-server-3:~$ sqlite3 -line /srv/node/disk004/containers/792/143/c621842628b132f47522f157c7f83143/c621842628b132f47522f157c7f83143.db 'SELECT * FROM object;'
ROWID = 1
name = production.txt
created_at = 499154400.00000
size = 11
content_type = text/plain
etag = 482c811da5d5b4bc6d497ffa98491e38
deleted = 0
storage_policy_index = 0Тот самый листинг, который мы уже видели в виде JSON-объекта. Грубо говоря, Container Server является прослойкой между HTTP-запросами клиента и базой данных SQLite. На деле, конечно, функциональность чуть шире. Другие таблицы содержат общую информацию о контейнере — его метаданные и статистику. Например, количество объектов и их объем.
В отличие от сервера объектов, список возможных операций с API здесь шире. Теперь мы можем манипулировать не только контейнерами, но и их содержимым. Конкретная операция зависит от URL:
- PUT — создать контейнер,
- POST — изменить метаданные контейнера,
- GET — получить листинг контейнера,
- HEAD — получить только метаданные контейнера,
- DELETE — удалить контейнер. /<disk>/<partition>/<account>/<container>/<object>:
- PUT — создать объект в листинге,
- DELETE — удалить объект из листинга.
/<disk>/<partition>/<account>/<container>:
Так и работают листинги контейнеров в Swift. Примечательно, что Object Server и Container Server независимы друг от друга лишь частично. Например, при создании или удалении объекта изменения проходят путь «снизу-вверх», т.е. клиент оповещает об изменениях только Object Server, а тот, в свою очередь, обращается к серверу контейнеров. При чтении объекта запросы, наоборот, выполняются клиентом независимо и «сверху-вниз»: сначала запрашивается информация об аккаунте, после — контейнере и уже в конце мы обращаемся за самим объектом. Но это мы забежали вперед.
Семейная болячка
Невозможность равномерного заполнения дисков существует и тут. Базы данных для крупных контейнеров могут занимать под сотню гигабайт, а из-за хеширования имен несколько таких БД могут оказаться на одном диске.
Обращения к Container Server происходят при любых изменениях контейнера или объектов в нем. Поэтому нагрузка на диск довольно высока и, например, в наших Container Server установлены исключительно NVMe-накопители. Это решает вопросы производительности, но немного ограничивает нас по объему хранения на одной машине.
Даже с использованием быстрых дисков Python-код и SQLite явно не рассчитаны на сверх-интенсивные изменения, особенно в конкурентном режиме. Какое-то время в борьбе со Swift нам пришлось уделить производительности на запись (а удаление — тоже запись) и начать поддерживать собственный форк проекта.
Примечательно, что для решения части этих проблем в Swift внесли функционал шардирования контейнеров. Правда, сделан он весьма топорно: так как листинги в Swift сортированные, шарды предлагается разбивать по промежуткам имен объектов. То есть, необходимо обеспечить предсказуемое и равномерное именование объектов, а потом сказать Swift, что шард A содержит объекты с именами от aaa до eee, а шард B — например, все остальные. Говоря более простым языком, Чушь Петровна эта ваша система. Ни предсказать, ни автоматизировать.
Отдельную проблему может представлять репликация контейнера. При интенсивных изменениях Swift может захотеть реплицировать БД на 80ГБ целиком, через rsync. А в конце процесса оценить набежавшую разницу и снова начать полную репликацию. Процесс может стать условно-бесконечным, при этом демон репликации и не подумает заниматься другими контейнерами. Только однопоток, только хардкор.
Другие демоны
Здесь вновь не будет ничего нового. Набор вспомогательных демонов нам знаком:
- container-replicator — реплицирует отдельные записи или всю БД на другие машины при необходимости,
- container-auditor — ищет «битые» БД контейнеров,
- container-updater — отложено обновляет листинги аккаунтов.
Самое время поговорить про листинги аккаунтов. Здесь все будет быстро.
Swift Account Server
Аккаунт — самая крупная единица в хранилище. В нашем случае один аккаунт хранилища — это один клиент облака Selectel. У аккаунта существуют пользователи и контейнеры, каждый со своими метаданными и настройками доступа. В контейнерах — объекты, но это вы и так уже знаете.
Здесь можно не останавливаться надолго, ведь Account Server — это тот же самый Object Server, только он хранит…что бы вы подумали? Конечно, метаданные аккаунта и список контейнеров в нем.
Говорю честно: нагрузки на компонент нет, о нем скучно даже думать. Тоже API, тоже с хеш-кольцом, а внутри тоже SQLite. Один аккаунт — одна БД. Внутри хранится список контейнеров на аккаунте. Все.
Демонов немного, почти все знакомые:
- account-replicator — реплицирует отдельные записи или всю БД на другие машины при необходимости,
- account-auditor — ищет «битые» БД аккаунтов,
- account-reaper — удаляет аккаунты, помеченные для удаления в фоновом режиме.
Даже немного неловко оставлять эту главу такой короткой, но жизнь такая, какая она есть. Не будем задерживаться, впереди нас ждет самое главное.
Proxy Server
Ради этого пункта мы проделали путь в 14 страниц шрифтом Arial 11 размера.
Хотя все предыдущие компоненты знают друг о друге, и при запросах записи работают сообща, в чистом виде они не похожи на простую в использовании систему. Теперь же мы смотрим на погонщика, главного заводилу в компании и просто хорошего (правда достаточно тормозного) парня — Proxy Server.
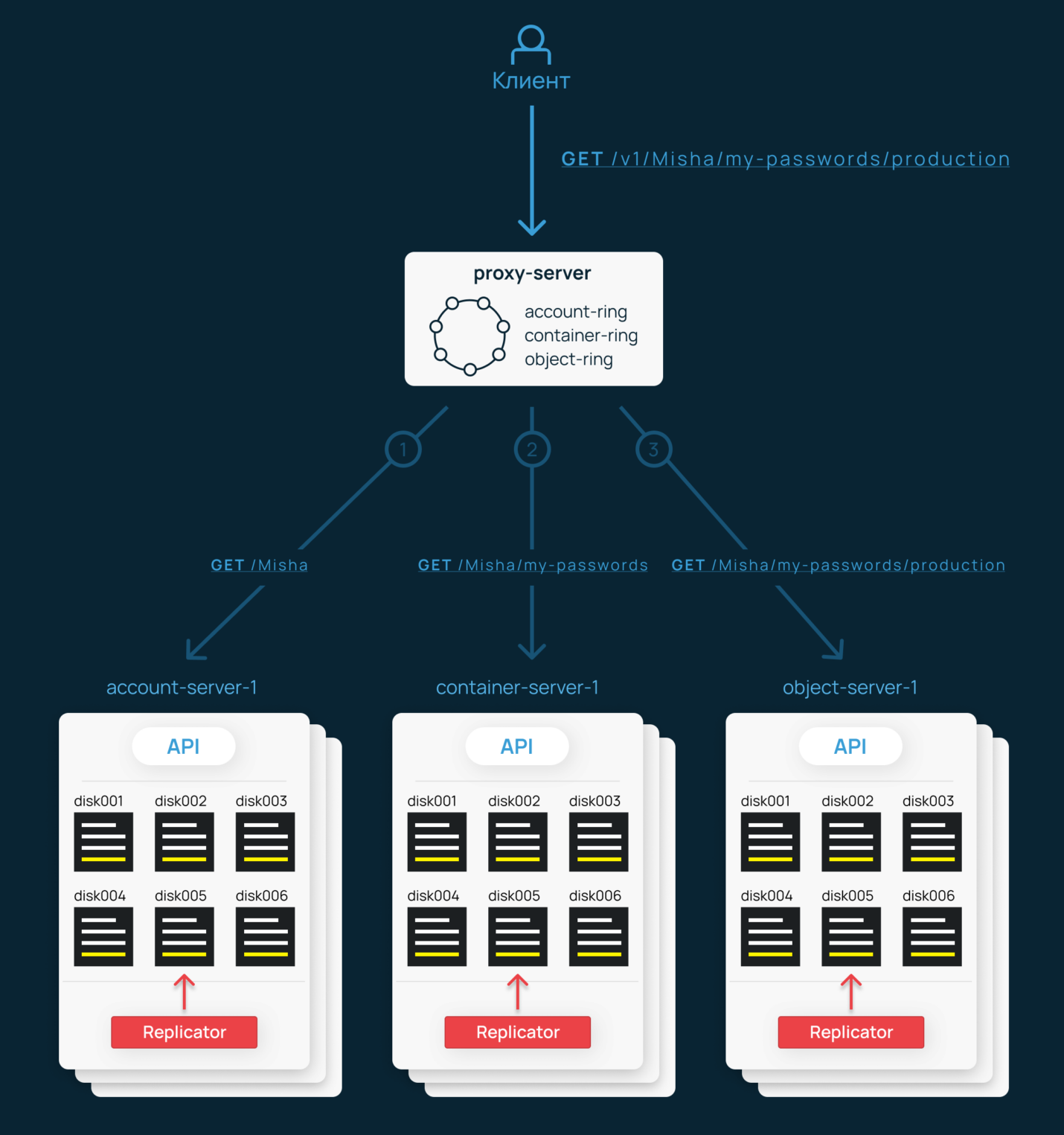
Все запросы клиентов хранилища OpenStack Swift поступают именно в Proxy Server, а он уже общается с остальными API. Он работает с кольцом, распределяет запросы сразу на несколько реплик и заботится о том, чтобы в рамках операции пользователя было сделано все, что требуется для консистентности и процветания.
Именно здесь реализовано то, что называется Swift API. Обращение к объекту происходит по URL вида http:
http://proxy-server/v1/<account>/<container>/<object>Например: https://api.selcdn.ru/v1/SEL_199445/awesome-clips/keanu-e3.mp4
Наконец никаких дисков и партиций, никаких колец! Взяли и запросили объект. Что же сделает Proxy Server? Немало:
- Определит аккаунт, проверит существование аккаунта и контейнера в Account Server.
- Проверит существование контейнера в Container Server и авторизует запрос при необходимости.
- Проверит существование объекта в Container Server и запросит его у Object Server, после чего вернет клиенту.
Каждый из этих запросов будет выполнен во все реплики сервисов, на которых (согласно кольцу) должна находиться требуемая информация. Ответ поступит клиенту только в случае, если большинство из них ответило успешно.
Доступных операций немало — тут и управление контейнерами, и пользователями, и объектами, и чем угодно еще — нет смысла перечислять все. Полностью этот API описан в документации. В общем, в то время, как все другие компоненты являются внутренней кухней Swift-кластера, Proxy Server — это его лицо. Точка входа для пользователей.
В целом, до поры до времени Proxy Server не должен вызывать вопросы. Проблемы производительности можно временно решить железом, в фоновом режиме задумываясь о замене на Golang. Не шучу. Мы так и сделали, после чего сразу сократили количество машин с Proxy Server в четыре раза.
Долгая счастливая жизнь?
В чистом виде Swift продержался у нас около двух лет, и все равно постоянно приходилось что-то в нем менять. Тяжко стало после того, как количество клиентских данных превысило 1 млрд. объектов.
Основные сложности, связанные со скоростью работы, разрешались апгрейдом железа и мелкими правками в конфиги или код. Но со временем стало заметно, что рост производительности совсем не соответствует ожиданиям. Архитектурные проблемы Swift грозили помешать развитию сервиса. И чем больше данных клиенты размещали в хранилище, тем заметнее они проявлялись.
Использование файловой системы для хранения объектов создавало дополнительные расходы на время чтения/записи дерева ФС, которое разрасталось вместе с увеличением количества объектов. Крупное и тяжелое дерево, в свою очередь, занимало немало пространства в Slab Cache, вытесняя Page Cache и еще сильнее замедляя работу с диском.
Однопоточная работа фоновых демонов Swift начинала напоминать о себе, проводя непозволительно много времени в одной итерации и замедляя репликацию объектов и контейнеров. В конце концов отсутствие централизованной конфигурации и гибких процедур обслуживания превращали бытовые задачи в сущую боль — нужно было немало поработать руками и нигде не ошибиться, чтобы просто вывести ноду-другую из кластера и добавить новые. И все это медленно настигало живую услугу — продукт, который несмотря ни на что должен продолжать работать и радовать пользователей.
Чем дальше мы шли, тем больше нюансов встречалось на этом пути. За 10 лет мы практически полностью заменили Python на Golang, перешли на Ceph вместо Object Server, да и вообще пришли к своей архитектуре хранилища, которую продолжаем улучшать каждый день. Мы сильно выросли, но грамотный подход к проектированию архитектуры позволяет в некоторых местах использовать даже меньше железа, чем было когда-то выделено под компоненты Swift.
Но об этом в следующей части.




