Keeping Track of IP Addresses
In our line of work, we often run into problems rationally distributing IP address blocks. Distributing addresses to thousands of clients is by no means an easy task. In this article, we’re going to share our solution with you.
A Bit on IP Addresses
Before talking about the problems of dividing address space, we should look at the main principles behind IPv4 addressing. An IPv4 address is a 32-bit sequence (1s and 0s). Since it’d be fairly difficult for a person to read through and memorize an entire binary IP address, the 32 bits are divided into 4 bytes, known as octets. To make them easier to understand, all octets are written in decimal form.
Each IPv4 address is made up of two parts: the first identifies the network, the second identifies the node. This is called a hierarchical address: the first part identifies the general network, the second–a particular address in that network. Routers only need to know the path to each network, and not the location of separate nodes.
To help nodes determine which part describes the network and which describes the node, a subnet mask is used. The subnet mask is assigned at the same time as the IP address. It is a 32-bit set where the ones correspond to the network and the zeros to the node. Today, it’s common practice to use prefix (aka CIDR) notation. The mask in this case is indicated by a number after a slash. For example, mask 255.255.255.0 in binary is: 11111111.11111111.11111111.00000000. The number of ones equals 24, so the mask is written as /24.
Manual Assignment Issues
In many organizations, IP addresses are assigned manually without the use of any specialized software. Sooner or later though, this turns into an addressing nightmare. First of all, manual assignment unavoidably leads to fragmentation: clients are provided with a lot of small subnets, making it impossible to assign a larger subnet.
Secondly, the need to assign different size subnets also leads to various complications. For example, a client might be assigned a /27 or /28 subnet that a /29 block was already assigned from. Can this process be automated to avoid this error? After thinking this over, we found our solution by visualizing the process.
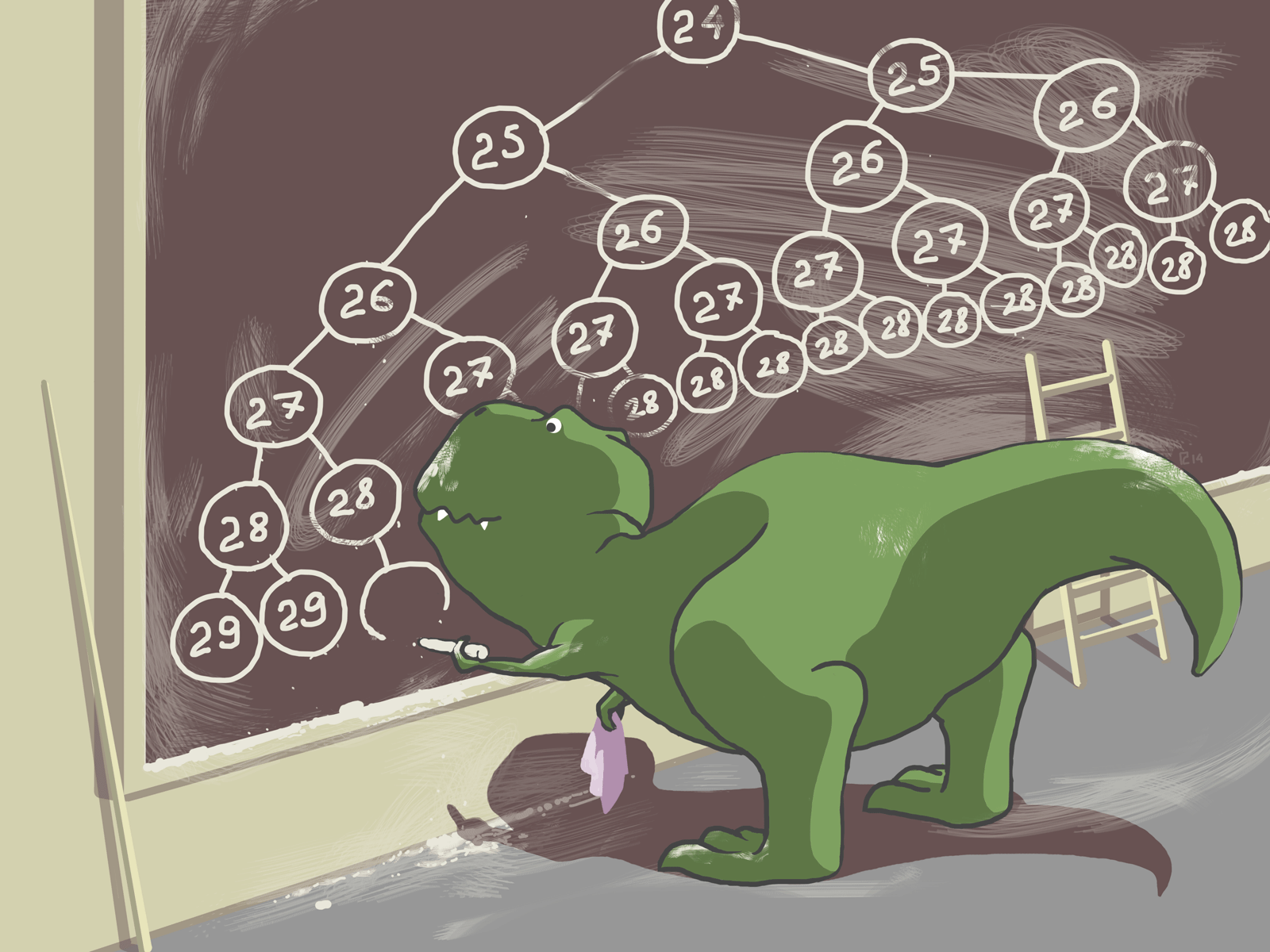
The Interval Tree and Table of Free Subnets
To look for free subnets, we use an interval tree. This is how we find intervals that intersect an assigned interval or point. The IP address can be presented as a decimal so that we can determine the pool’s boundary without any difficulties and present all occupied subnets as the segment of a larger interval.
The algorithm for finding free subnets can be described in the following way. Let’s say a client wants a /27 subnet. First, we need to be sure that the given pool is bigger than the subnet. If it’s smaller, then we need to either look at another pool, or tell our client that there are no free subnets of that size. If the pool is bigger than the requested subnet, then we start moving from the start of the pool in segments to the requested subnet (its size is equal to 2^(32-x), where x is the subnet prefix).
Using a previously built interval tree, we can quickly determine if the subnet the client needs, presented as an interval, covers previously assigned subnets. The subnet 127.0.0.0/27 in our example covers one assigned /29 subnet. We then take the interval after it: 127.0.0.32/27. We check if it overlaps any others, and it turns out that it’s free. Next, it’s assigned to the client and is marked as occupied. All of the information on free subnets is visually represented in the following table (green indicates a free subnet, blue–occupied, grey–a subnet with smaller occupied subnets, and thus cannot be used):

To speed up the search for free subnets in larger pools, we can scan intervals by cycling from different sides. The fragmentation scale will be larger in this case, and so problems may arise when assigning larger subnets. If we were to find a larger subnet that overlaps the one requested by the client, then we could start the next step of the cycle from that end; this is how we’d know there weren’t any free subnets inside the interval.
Conclusion
This solution to assigning IP addresses makes managing address space simpler and more practical.
Naturally, can’t call this perfect. The question of rationally and efficiently allocating address space remains open. It would be interesting to hear your impressions and suggestions for improving our approach, as well as other ways the issue could be solved.