Guest Post: Our Experience with Selectel’s VRRP
Today’s post was written by our client ITSumma.
ITSumma provides remote server administration, website technical support, and ensures online service availability under high and super high loads.
In this article, Anton Baranov, Victoria Andrienko, and Evgenii Potapov share their experience with our IP Failover (VRRP) service. If you’re looking to improve your project’s availability and fault-tolerance, you should definitely consider what they have to say.
Hot Standby in Selectel: Advantages, Potential Drawbacks, and Application Mechanisms
A Little Bit about Redundancy
Recently, Selectel announced that it now offers VRRP (Virtual Router Redundancy Protocol) for its platforms. This technology lets a project switch almost seamlessly from its primary platform to a backup on the fly. We’d like to look at this solution more in-depth.
When a project grows to the point of needing 24/7 availability, a backup server where data can be synchronized and databases replicated becomes a necessity. Here we have our main question: How do users connect to this backup server? This requires consistency at every data level (files, databases, software configurations) on the main and backup server. It’s imperative that new visitor requests get transferred to the backup server as soon as the main server goes down: if for whatever reason requests are sent to the unavailable server, we’ll lose potential clients.
First of all, we recommend hosting main and backup servers in different data centers (maybe with the same company), because as often as we see individual servers going offline, we also see problems on the rack level (during powerful DDoS attacks on different clients), problems on the data center level, and even problems on the communications level.
Ideally, a backup server will be in a different hosting provider’s data center and on a different network line; however, even placing equipment in one company’s different data centers can significantly improve a project’s reliability. What’s key here is not keeping your backup and primary server in the same physical data center.
Regardless of where you host your backup platform, the question remains: How will users be redirected to the backup server? By changing the IP address in the DNS, you’re still dependent on the record’s cache time (time to live), so users will continue being directed to the old IP address for quite a while. Using a proxy server or cloud-based load balancer (like Amazon’s) creates a new potential point of error, adds more expenses, and with Amazon, leaves us with concerns about personal data laws. This is why we want to just swap the IP address; unfortunately, there aren’t that many technologies available for smaller projects. You can’t buy a subnet and negotiate announcing with data centers for every project.
VRRP and Redundancy at Selectel: Equipment and Features
VRRP was initially used to simplify manual processes when issues occurred on local networks.
Let’s say we have one local network that contains several routers and servers. If something happens to one of our primary devices, then we just have to configure the primary server/router’s IP address on the backup network interface, and all of the traffic on the network will be routed to the backup.
Software that uses VRRP exchanges information between the main and backup servers. This information identifies what servers are backups and which is the master. The software also defines the priority these services should be used in if anything happens to the main server. Nodes share this information about their roles and weight with one another, and if a server sees that it’s a backup and has the highest priority in the network (and that the master has gone offline), then it will automatically assume the primary server’s IP address and take on the master role. If another node appears in the network with an even higher priority, the backup server that assigned itself as master will revert to a backup and drop the primary node’s IP address from its interface.
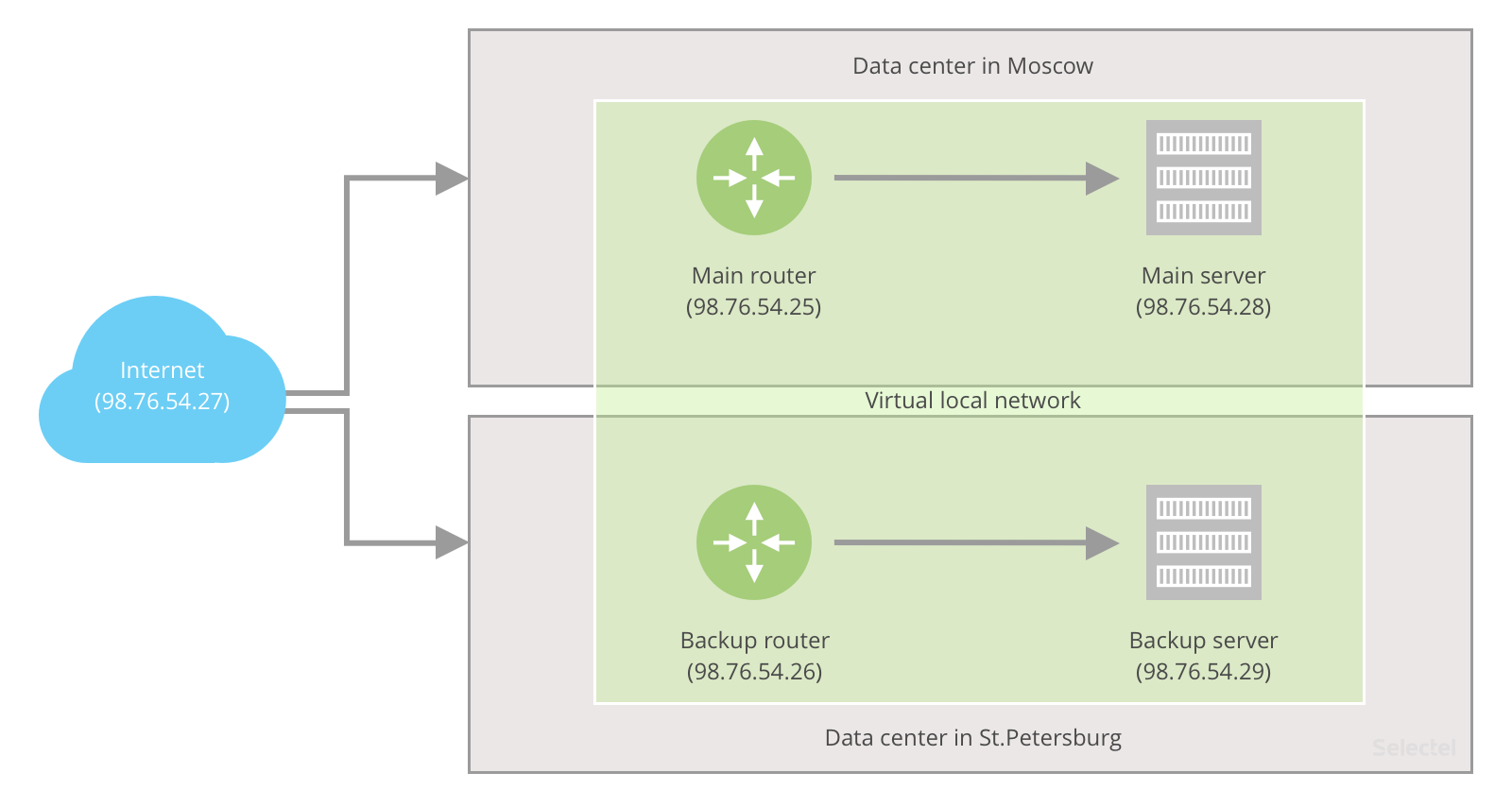
At the base of Selectel’s hot standby over VRRP is a virtual local network between two physical data centers—one in Moscow and one in St. Petersburg. Like any local network, an IP address can be assigned to any of its components. In our virtual network, the main router and server are located in one data center, while the backup router and server are located in the other. All of the nodes are located in one virtual subnet.
The service isn’t completely automatic: the user/administrator has to set up server redundancy (which can be done by disabling the IP on the main server and configuring it on the backup), and Selectel backs up the routers, but that’s a whole different story.
After the VRRP service has been ordered, Selectel provides a /29 subnet with 6 IP addresses. Let’s say in our example that it’s subnet 98.76.54.25/29. The IP addresses are distributed as follows:
- Main server IP — 98.76.54.28
- Main gateway — 98.76.54.25
- Backup server IP — 98.76.54.29
- Backup gateway — 98.76.54.26
- Broadcast IP — 98.76.54.31
- VRRP IP — 98.76.54.27 (the main server (98.76.54.28) should assume this IP by default)
To establish redundancy, keepalived is set up on the primary and backup server. This exchanges information with itself or uses a check script to determine the availability of the other nodes in the redundancy scheme (the standby server actually tries to understand if the primary server is available, and if it’s not, it configures the VRRP IP on its interface).
This kind of redundancy offers protection from the following situations:
- primary server crashes and hardware malfunctions;
- failures and DDoS attacks on the rack where the primary server is installed (if the standby server is in the same data center and in the same rack, the project will go offline).
Server-level redundancy doesn’t protect you from the following issues:
- nonfatal channel issues (packet loss, lag) in the main data center;
- hardware failures in the primary router;
- hardware failures in the primary data center;
- failures in the primary data center caused by a network configuration error.
To solve these kinds of problems, we need redundancy on the router level. We’d like to point out that this is entirely taken care of by Selectel, meaning the user/administrator doesn’t have to monitor this process at all.
Let’s look at each of these situations and see what actions should be taken on the router level.
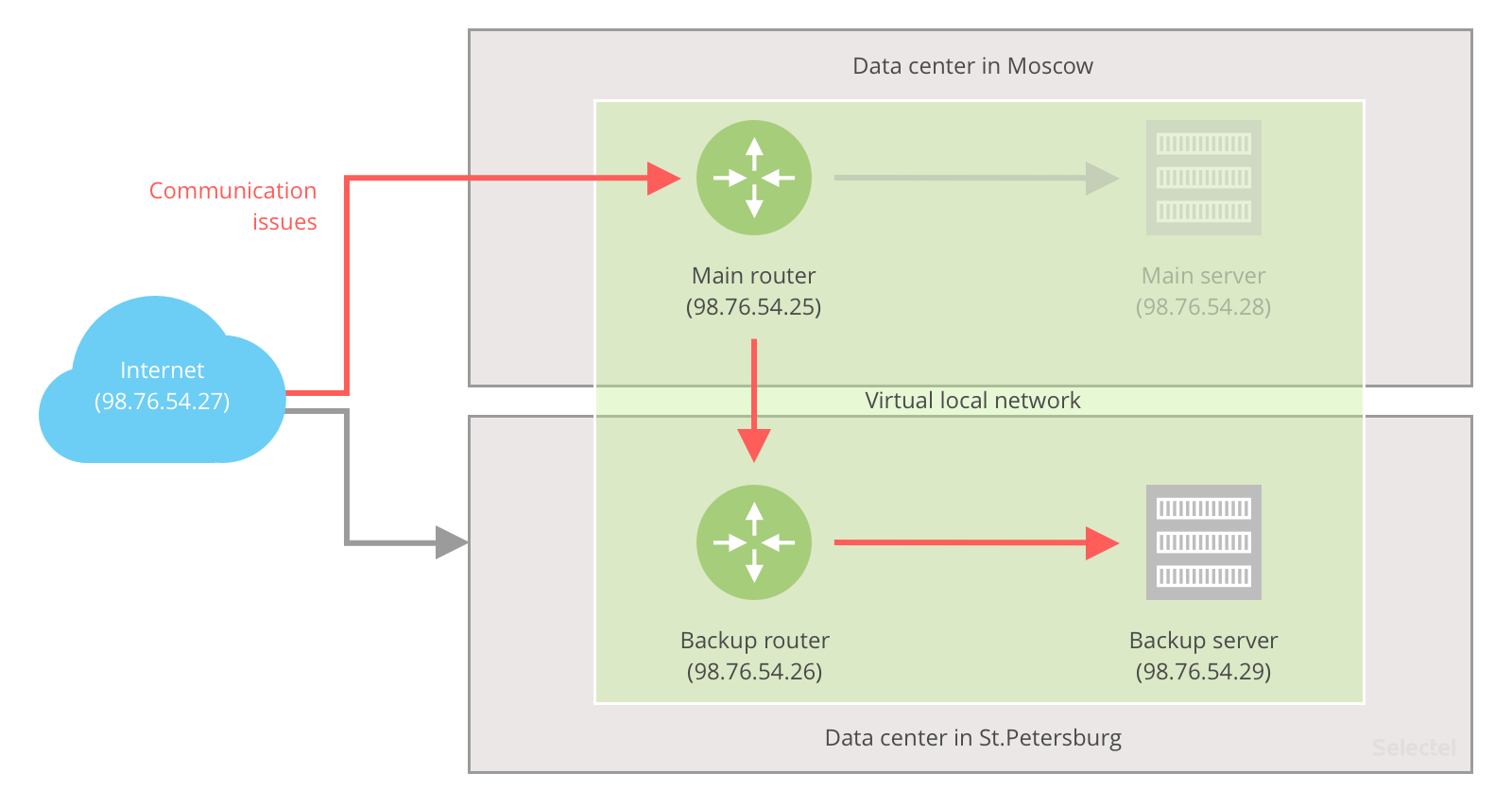
Hardware Failure in the Main Router
Selectel’s router-level redundancy practically guarantees protection in this case. When the standby router sees that the primary router is unavailable, it assumes the primary role.
Router-level redundancy also protects from cases of hardware failure in the data center. The standby router will see the main data center is unavailable from “local” fiber optics and take on the primary role.
Total Data Center Failure
This situation is the most complicated. In the event of a failure at the data center level, the procedure would look like this:
- Let’s say the primary data center is in Moscow and the backup is in St. Petersburg.
- The data center in Moscow loses all of its uplinks, but the optic line between the St. Petersburg and Moscow data centers stays up. The virtual router sees them both as available and doesn’t make the switch.
- Ideally, the Moscow data center stops announcing its network, the data center in St. Petersburg announces it, and traffic from the uplink goes to St. Petersburg and then along the optic line to Moscow to the primary router. From there, traffic is sent to the primary server.
Selectel has absolutely no precedent of total failure in any of its data centers. This is why we can’t say for sure that this kind of redundancy would actually work or be effective if the primary data center became externally invisible because of human error and its channel to the backup data center stayed active.
We can see that Selectel’s VRRP is quite a useful bit of technology, but it does have its idiosyncrasies. Switching to the backup server doesn’t always mean switching to the backup channels.
Outside the network stack, it’s important to keep in mind that any switch to a backup faces two potential problems. Firstly, the standby platform may be offline for some reason (and thus the project will switch from a poorly working site to one that’s entirely unavailable). Secondly, it’s possible that the data and operations performed on the backup platform won’t synchronize with the primary platform.
To minimize these risks, the backup platform should be monitored as thoroughly as the primary: make sure replication occurs across platforms and be extremely careful about synchronization. You have two options here. You can set up a master-slave backup scheme, whereby the backup platform will become the primary during an emergency and the primary will reconfigure as the backup. Alternatively, you could set up master-master replication. With this option, you have to keep all of the associated risks in mind: if data is accidently deleted on the backup, then the same will happen on the master; if synchronization is interrupted when switching to and from the backup, then you’ll have out of sync data, etc.
What Should Be Monitored
- A URL needs to be set up on both machines that can tell you where data is returned from. Let’s say http://mysite.com/vrrp.txt returns msk when the server is in Moscow and spb when it’s in St. Petersburg. If the value changes or URL becomes unavailable, a notification should be sent.
- Replication status between the primary and backup server.
- File synchronization status between the primary and backup server.
- URL availability of the project on the backup server.
Bonus Track: Configuring Selectel’s VRRP
VRRP can be implemented on the Linux server side using the keepalived daemon. Let’s take a look at its configuration.
When the VRRP service is ordered, Selectel provides a /29 subnet with 6 IP addresses. Let’s say in our example that it’s subnet 98.76.54.25/29. The IP addresses are distributed as follows:
- Main server IP — 98.76.54.28
- Main gateway — 98.76.54.25
- Backup server IP — 98.76.54.29
- Backup gateway — 98.76.54.26
- Broadcast IP — 98.76.54.31
- VRRP IP — 98.76.54.27
We need to do three things:
1) Configure the network interface on each server.
Primary server network configuration:
[root@main-server root]# cat /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE="eth0" BOOTPROTO="static" BROADCAST="98.76.54.31" DNS1="8.8.8.8" GATEWAY="98.76.54.25" HWADDR="0C:C4:7A:4E:DF:A2" IPADDR="98.76.54.28" NETMASK="255.255.255.248" NM_CONTROLLED="yes" ONBOOT="yes" TYPE="Ethernet" UUID="c90e6f8e-6c10-48bd-adc5-4039077b8ed1"
Backup server network configuration:
[root@reserve-server root]# cat /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE="eth0" BOOTPROTO="static" BROADCAST="98.76.54.31" DNS1="8.8.8.8" GATEWAY="98.76.54.26" HWADDR="22:00:0A:49:C8:AB" IPADDR="98.76.54.29" NETMASK="255.255.255.248" NM_CONTROLLED="yes" ONBOOT="yes" TYPE="Ethernet" UUID="4a7f24f0-d507-425a-a8cd-f9bd42410bb8"
Take note that each server is given its respective IP interface and gateway.
2) Configure keepalived.
First we install keepalived. It’s typically included in the standard repositories. For CentOS:
[root@main-server root]# yum install keepalived
Then we need to configure it.
Primary server keepalived configuration:
[root@main-server root]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
support@yourdomain.ru
}
notification_email_from vrrp@yourserver.ru
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id main
}
vrrp_instance nginx1 {
state MASTER
interface eth0
virtual_router_id 51
priority 201
advert_int 1
authentication {
auth_type PASS
auth_pass jaecheFaeva9Kai
}
virtual_ipaddress {
98.76.54.27/29
}
}
Backup server keepalived configuration:
[root@reserve-server root]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
support@yourdomain.ru
}
notification_email_from vrrp@yourserver.ru
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id reserve
}
vrrp_instance nginx1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass jaecheFaeva9Kai
}
virtual_ipaddress {
98.76.54.27/29
}
}
Note the following points:
a) We didn’t set keepalived to automatically boot with the server. Because servers are rarely rebooted, if there’s planned maintenance or something goes wrong, then we don’t need keepalived to be running on our server until we resolve the issue/repair any damages and update the data on the server.
b) The backup server’s priority must be lower than the primary server’s.
c) virtual_router_id should be different on every server pair with a VRRP IP. Even though the documentation shows that it should only be different for one server’s different interfaces, we ran into problems when virtual_router_id was the same on different pairs of servers.
3) Enter the following firewall rules for enabling VRRP and multicasting:
-A INPUT -i eth0 -p vrrp -j ACCEPT -A INPUT -d 224.0.0.0/8 -i eth0 -j ACCEPT
Afterwards, we can launch keepalived:
[root@main-server root]# service keepalived start
Our logs should look something like this:
On the primary server:
Nov 20 23:09:56 main-server Keepalived_vrrp[24629]: Netlink reflector reports IP 98.76.54.28 added Nov 20 23:09:56 main-server Keepalived_vrrp[24629]: Netlink reflector reports IP fe80::ec4:7bff:fe4e:dfa2 added Nov 20 23:09:56 main-server Keepalived_vrrp[24629]: Registering Kernel netlink reflector Nov 20 23:09:56 main-server Keepalived_vrrp[24629]: Registering Kernel netlink command channel Nov 20 23:09:56 main-server Keepalived_vrrp[24629]: Registering gratuitous ARP shared channel Nov 20 23:09:56 main-server Keepalived_vrrp[24629]: Opening file '/etc/keepalived/keepalived.conf'. Nov 20 23:09:56 main-server Keepalived_vrrp[24629]: Configuration is using : 61900 Bytes Nov 20 23:09:56 main-server Keepalived_vrrp[24629]: Using LinkWatch kernel netlink reflector... Nov 20 23:09:56 main-server Keepalived_vrrp[24629]: VRRP sockpool: [ifindex(3), proto(112), unicast(0), fd(10,11)] Nov 20 23:09:57 main-server Keepalived_vrrp[24629]: VRRP_Instance(nginx1) Transition to MASTER STATE Nov 20 23:09:58 main-server Keepalived_vrrp[24629]: VRRP_Instance(nginx1) Entering MASTER STATE Nov 20 23:09:58 main-server Keepalived_vrrp[24629]: VRRP_Instance(nginx1) setting protocol VIPs. Nov 20 23:09:58 main-server Keepalived_vrrp[24629]: VRRP_Instance(nginx1) Sending gratuitous ARPs on eth0 for 98.76.54.27 Nov 20 23:10:03 main-server Keepalived_vrrp[24629]: VRRP_Instance(nginx1) Sending gratuitous ARPs on eth0 for 98.76.54.27 Nov 20 23:16:31 main-server Keepalived_vrrp[24629]: VRRP_Instance(nginx1) Received lower prio advert, forcing new election Nov 20 23:16:31 main-server Keepalived_vrrp[24629]: VRRP_Instance(nginx1) Sending gratuitous ARPs on eth0 for 98.76.54.27 Nov 20 23:16:32 main-server Keepalived_vrrp[24629]: VRRP_Instance(nginx1) Received lower prio advert, forcing new election
On the backup server:
Nov 20 23:10:12 reserve-server Keepalived_vrrp[25944]: Netlink reflector reports IP 98.76.54.29 added Nov 20 23:10:12 reserve-server Keepalived_vrrp[25944]: Netlink reflector reports IP fe80::ec4:7bff:fe4e:df2e added Nov 20 23:10:12 reserve-server Keepalived_vrrp[25944]: Registering Kernel netlink reflector Nov 20 23:10:12 reserve-server Keepalived_vrrp[25944]: Registering Kernel netlink command channel Nov 20 23:10:12 reserve-server Keepalived_vrrp[25944]: Registering gratuitous ARP shared channel Nov 20 23:10:12 reserve-server Keepalived_vrrp[25944]: Opening file '/etc/keepalived/keepalived.conf'. Nov 20 23:10:12 reserve-server Keepalived_vrrp[25944]: Configuration is using : 61900 Bytes Nov 20 23:10:12 reserve-server Keepalived_vrrp[25944]: Using LinkWatch kernel netlink reflector... Nov 20 23:10:12 reserve-server Keepalived_vrrp[25944]: VRRP_Instance(nginx1) Entering BACKUP STATE Nov 20 23:10:12 reserve-server Keepalived_vrrp[25944]: VRRP sockpool: [ifindex(3), proto(112), unicast(0), fd(10,11)] Nov 20 23:10:16 reserve-server Keepalived_vrrp[25944]: VRRP_Instance(nginx1) Transition to MASTER STATE Nov 20 23:10:17 reserve-server Keepalived_vrrp[25944]: VRRP_Instance(nginx1) Entering MASTER STATE Nov 20 23:10:17 reserve-server Keepalived_vrrp[25944]: VRRP_Instance(nginx1) setting protocol VIPs. Nov 20 23:10:17 reserve-server Keepalived_vrrp[25944]: VRRP_Instance(nginx1) Sending gratuitous ARPs on eth0 for 98.76.54.27 Nov 20 23:10:22 reserve-server Keepalived_vrrp[25944]: VRRP_Instance(nginx1) Sending gratuitous ARPs on eth0 for 98.76.54.27 Nov 20 23:17:59 reserve-server Keepalived_vrrp[25944]: VRRP_Instance(nginx1) Received higher prio advert Nov 20 23:17:59 reserve-server Keepalived_vrrp[25944]: VRRP_Instance(nginx1) Entering BACKUP STATE Nov 20 23:17:59 reserve-server Keepalived_vrrp[25944]: VRRP_Instance(nginx1) removing protocol VIPs.
If the logs are different, then it means that something somewhere was configured incorrectly. It’d be a good idea to double check the firewall and keepalived configuration.
If the logs match up with the examples above, then congratulations! You’ve configured VRRP on your server! Server availability can be checked using check scripts, the documentation for which can be found at the links below.
To read more about what we’ve talked about: