Introduction to DPDK: Architecture and Principles
Linux network stack performance has become increasingly relevant over the past few years. This is perfectly understandable: the amount of data that can be transferred over a network and the corresponding workload has been growing not by the day, but by the hour.
Not even the widespread use of 10 GE network cards has resolved this issue; this is because a lot of bottlenecks that prevent packets from being quickly processed are found in the Linux kernel itself.
There have been many attempts to circumvent these bottlenecks with techniques called kernel bypasses (a short description can be found here). They let you process packets without involving the Linux network stack and make it so that the application running in the user space communicates directly with networking device. We’d like to discuss one of these solutions, the Intel DPDK (Data Plane Development Kit), in today’s article.
A lot of posts have already been published about the DPDK and in a variety of languages. Although many of these are fairly informative, they don’t answer the most important questions: How does the DPDK process packets and what route does the packet take from the network device to the user?
Finding the answers to these questions was not easy; since we couldn’t find everything we needed in the official documentation, we had to look through a myriad of additional materials and thoroughly review their sources. But first thing’s first: before talking about the DPDK and the issues it can help resolve, we should review how packets are processed in Linux.
Processing Packets in Linux: Main Stages
When a network card first receives a packet, it sends it to a receive queue, or RX. From there, it gets copied to the main memory via the DMA (Direct Memory Access) mechanism.
Afterwards, the system needs to be notified of the new packet and pass the data onto a specially allocated buffer (Linux allocates these buffers for every packet). To do this, Linux uses an interrupt mechanism: an interrupt is generated several times when a new packet enters the system. The packet then needs to be transferred to the user space.
One bottleneck is already apparent: as more packets have to be processed, more resources are consumed, which negatively affects the overall system performance.
As we’ve already said, these packets are saved to specially allocated buffers—more specifically, the sk_buff struct. This struct is allocated for each packet and becomes free when a packet enters the user space. This operation consumes a lot of bus cycles (i.e. cycles that transfer data from the CPU to the main memory).
There is another problem with the sk_buff struct: the Linux network stack was originally designed to be compatible with as many protocols as possible. As such, metadata for all of these protocols is included in the sk_buff struct, but that’s simply not necessary for processing specific packets. Because of this overly complicated struct, processing is slower than it could be.
Another factor that negatively affects performance is context switching. When an application in the user space needs to send or receive a packet, it executes a system call. The context is switched to kernel mode and then back to user mode. This consumes a significant amount of system resources.
To solve some of these problems, all Linux kernels since version 2.6 have included NAPI (New API), which combines interrupts with requests. Let’s take a quick look at how this works.
The network card first works in interrupt mode, but as soon as a packet enters the network interface, it registers itself in a poll queue and disables the interrupt. The system periodically checks the queue for new devices and gathers packets for further processing. As soon as the packets are processed, the card will be deleted from the queue and interrupts are again enabled.
This has been just a cursory description of how packets are processed. A more detailed look at this process can be found in an article series from Private Internet Access. However, even a quick glance is enough to see the problems slowing down packet processing. In the next section, we’ll describe how these problems are solved using DPDK.
DPDK: How It Works
General Features
Let’s look at the following illustration:
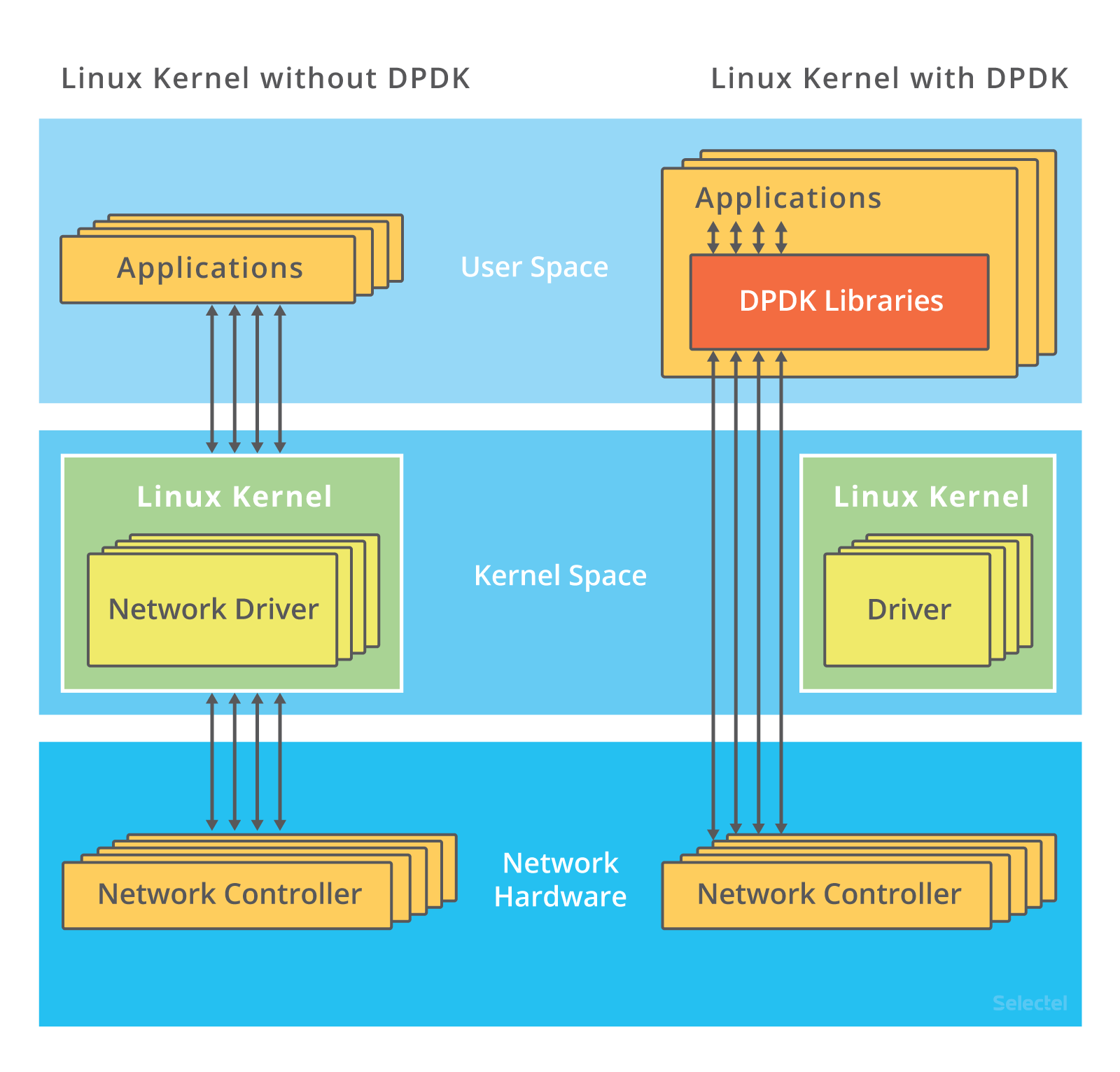
On the left you see the traditional way packets are processed, and on the right–with DPDK. As we can see, the kernel in the second example doesn’t step in at all: interactions with the network card are performed via special drivers and libraries.
If you’ve already read about DPDK or have ever used it, then you know that the ports receiving incoming traffic on network cards need to be unbound from Linux (the kernel driver). This is done using the dpdk_nic_bind (or dpdk-devbind) command, or ./dpdk_nic_bind.py in earlier versions.
How are ports then managed by DPDK? Every driver in Linux has bind and unbind files. That includes network card drivers:
ls /sys/bus/pci/drivers/ixgbe bind module new_id remove_id uevent unbind
To unbind a device from a driver, the device’s bus number needs to be written to the unbind file. Similarly, to bind a device to another driver, the bus number needs to be written to its bind file. More detailed information about this can be found here.
The DPDK installation instructions tell us that our ports need to be managed by the vfio_pci, igb_uio, or uio_pci_generic driver. (We won’t be geting into details here, but we suggested interested readers look at the following articles on kernel.org: 1 and 2.)
These drivers make it possible to interact with devices in the user space. Of course they include a kernel module, but that’s just to initialize devices and assign the PCI interface.
All further communication between the application and network card is organized by the DPDK poll mode driver (PMD) DPDK has poll mode drivers for all supported network cards and virtual devices.
The DPDK also requires hugepages be configured. This is required for allocating large chunks of memory and writing data to them. We can say that hugepages does the same job in DPDK that DMA does in traditional packet processing.
We’ll discuss all of its nuances in more detail, but for now, let’s go over the main stages of packet processing with the DPDK:
- Incoming packets go to a ring buffer (we’ll look at its setup in the next section). The application periodically checks this buffer for new packets.
- If the buffer contains new packet descriptors, the application will refer to the DPDK packet buffers in the specially allocated memory pool using the pointers in the packet descriptors.
- If the ring buffer does not contain any packets, the application will queue the network devices under the DPDK and then refer to the ring again.
Let’s take a closer look at the DPDK’s internal structure.
EAL: Environment Abstraction
The EAL, or Environment Abstraction Layer, is the main concept behind the DPDK.
The EAL is a set of programming tools that let the DPDK work in a specific hardware environment and under a specific operating system. In the official DPDK repository, libraries and drivers that are part of the EAL are saved in the rte_eal directory.
Drivers and libraries for Linux and the BSD system are saved in this directory. It also contains a set of header files for various processor architectures: ARM, x86, TILE64, and PPC64.
We access software in the EAL when we compile the DPDK from the source code:
make config T=x86_64-native-linuxapp-gcc
One can guess that this command will compile DPDK for Linux in an x86_64 architecture.
The EAL is what binds the DPDK to applications. All of the applications that use the DPDK (see here for examples) must include the EAL’s header files.
The most commonly of these include:
- rte_lcore.h — manages processor cores and sockets;
- rte_memory.h — manages memory;
- rte_pci.h — provides the interface access to PCI address space;
- rte_debug.h — provides trace and debug functions (logging, dump_stack, and more);
- rte_interrupts.h — processes interrupts.
More details on this structure and EAL functions can be found in the official documentation.
Managing Queues: rte_ring
As we’ve already said, packets received by the network card are sent to a ring buffer, which acts as a receiving queue. Packets received in the DPDK are also sent to a queue implemented on the rte_ring library. The library’s description below comes from information gathered from the developer’s guide and comments in the source code.
The rte_ring was developed from the FreeBSD ring buffer. If you look at the source code, you’ll see the following comment: Derived from FreeBSD’s bufring.c.
The queue is a lockless ring buffer built on the FIFO (First In, First Out) principle. The ring buffer is a table of pointers for objects that can be saved to the memory. Pointers can be divided into four categories: prod_tail, prod_head, cons_tail, cons_head.
Prods is short for producer, and cons for consumer. The producer is the process that writes data to the buffer at a given time, and the consumer is the process that removes data from the buffer.
The tail is where writing takes place on the ring buffer. The place the buffer is read from at a given time is called the head.
The idea behind the process for adding and removing elements from the queue is as follows: when a new object is added to the queue, the ring->prod_tail indicator should end up pointing to the location where ring->prod_head previously pointed to.
This is just a brief description; a more detailed account of how the ring buffer scripts work can be found in the developer’s manual on the DPDK site.
This approach has a number of advantages. Firstly, data is written to the buffer extremely quickly. Secondly, when adding or removing a large number of objects from the queue, cache misses occur much less frequently since pointers are saved in a table.
The drawback to DPDK’s ring buffer is its fixed size, which cannot be increased on the fly. Additionally, much more memory is spent working with the ring structure than in a linked queue since the buffer always uses the the maximum number of pointers.
Memory Management: rte_mempool
We mentioned above that DPDK requires hugepages. The installation instructions recommend creating 2MB hugepages.
These pages are combined in segments, which are then divided into zones. Objects that are created by applications or other libraries, like queues and packet buffers, are placed in these zones.
These objects include memory pools, which are created by the rte_mempool library. These are fixed size object pools that use rte_ring for storing free objects and can be identified by a unique name.
Memory alignment techniques can be implemented to improve performance.
Even though access to free objects is designed on a lockless ring buffer, consumption of system resources may still be very high. As multiple cores have access to the ring, a compare-and-set (CAS) operation usually has to be performed each time it is accessed.
To prevent bottlenecking, every core is given an additional local cache in the memory pool. Using the locking mechanism, cores can fully access the free object cache. When the cache is full or entirely empty, the memory pool exchanges data with the ring buffer. This gives the core access to frequently used objects.
Buffer Management: rte_mbuf
In the Linux network stack, all network packets are represented by the the sk_buff data structure. In DPDK, this is done using the rte_mbuf struct, which is described in the rte_mbuf.h header file.
The buffer management approach in DPDK is reminiscent of the approach used in FreeBSD: instead of one big sk_buff struct, there are many smaller rte_mbuf buffers. The buffers are created before the DPDK application is launched and are saved in memory pools (memory is allocated by rte_mempool).
In addition to its own packet data, each buffer contains metadata (message type, length, data segment starting address). The buffer also contains pointers for the next buffer. This is needed when handling packets with large amounts of data. In cases like these, packets can be combined (as is done in FreeBSD; more detailed information about this can be found here).
Other Libraries: General Overview
In previous sections, we talked about the most basic DPDK libraries. There’s a great deal of other libraries, but one article isn’t enough to describe them all. Thus, we’ll be limiting ourselves to just a brief overview.
With the LPM library, DPDK runs the Longest Prefix Match (LPM) algorithm, which can be used to forward packets based on their IPv4 address. The primary function of this library is to add and delete IP addresses as well as to search for new addresses using the LPM algorithm.
A similar function can be performed for IPv6 addresses using the LPM6 library.
Other libraries offer similar functionality based on hash functions. With rte_hash, you can search through a large record set using a unique key. This library can be used for classifying and distributing packets, for example.
The rte_timer library lets you execute functions asynchronously. The timer can run once or periodically.
Conclusion
In this article we went over the internal device and principles of DPDK. This is far from comprehensive though; the subject is too complex and extensive to fit in one article. So sit tight, we will continue this topic in a future article, where we’ll discuss the practical aspects of using DPDK.
We’d be happy to answer your questions in the comments below. And if you’ve had any experience using DPDK, we’d love to hear your thoughts and impressions.
For anyone interested in learning more, please visit the following links:
- http://dpdk.org/doc/guides/prog_guide/ — a detailed (but confusing in some places) description of all the DPDK libraries;
- https://www.net.in.tum.de/fileadmin/TUM/NET/NET-2014-08-1/NET-2014-08-1_15.pdf — a brief overview of DPDK’s capabilities and comparison with other frameworks (netmap and PF_RING);
- http://www.slideshare.net/garyachy/dpdk-44585840 — an introductory presentation to DPDK for beginners;
- http://www.it-sobytie.ru/system/attachments/files/000/001/102/original/LinuxPiter-DPDK-2015.pdf — a presentation explaining the DPDK structure.