Если коротко, то обычно с этой функцией работают так: создается нужный элемент, настраивается, добавляется обработчик события, и далее он встраивается в родительский элемент. В итоге получается своеобразная древовидная структура. Отсюда и название статьи.
Ранее я уже показал, как создавать элементы страницы с помощью createElement и реагировать на события. Рекомендую глянуть предыдущие посты, чтобы не терять нить повествования.
Что такое DOM на самом деле
Начнем с основ создания страниц. HTML-код это что-то вроде инструкции по созданию и сборке элементов. Так вы говорите браузеру, что показать, в каком порядке и как это структурировать.
Смотрим пример такого кода:
<div>
<h1>Заголовок</h1>
<p>Абзац</p>
</div>
Что делает браузер, когда видит код в HTML-файле? Если сказать просто, то он считает эту инструкцию и собирает из нее «живую» динамическую модель — DOM.
Важно не путать, если HTML — это текстовая инструкция, описывающая «как собрать страницу», то DOM — уже собранная структура элементов, с которой браузер и будет работать.
JavaScript работает именно с DOM, а не с исходным HTML-кодом. Когда вы меняете что-то на странице через JS, вы не редактируете HTML-файл на сервере, вы меняете эту самую живую модель в памяти браузера. Страница мгновенно обновляется, и исходный HTML остается нетронутым.
Именно поэтому понимание DOM — это ключ к настоящему управлению веб-страницей. Давайте добавим немного определений:
DOM (Document Object Model) — это представление HTML-документа в виде древовидной структуры объектов. Каждый тег, каждый кусочек текста становится отдельным «узлом» (node) в этом дереве.
Узел (node) — это базовая единица DOM, кирпичик, из которого строится вся структура.
Узлы бывают разных типов, но чаще всего вы будете работать с двумя:
- элементы (element nodes) — это теги: div, p, button, h1. Они образуют структуру страницы;
- текстовые узлы (text nodes) — это текст внутри элементов. Например, в <h1>Заголовок</h1> слово «Заголовок» — это отдельный текстовый узел внутри узла-элемента h1.
Есть и другие типы узлов, например, комментарии. Но элементы и текстовые узлы — это основа, с которой вы будете работать постоянно.
А почему именно дерево? Посмотрим на следующий пример: HTML и его графическое представление в виде схемы.
<html>
<head>
</head>
<body>
<header>
<h1>Заголовок</h1>
</header>
<main>
<p>Абзац</p>
</main>
</body>
</html>
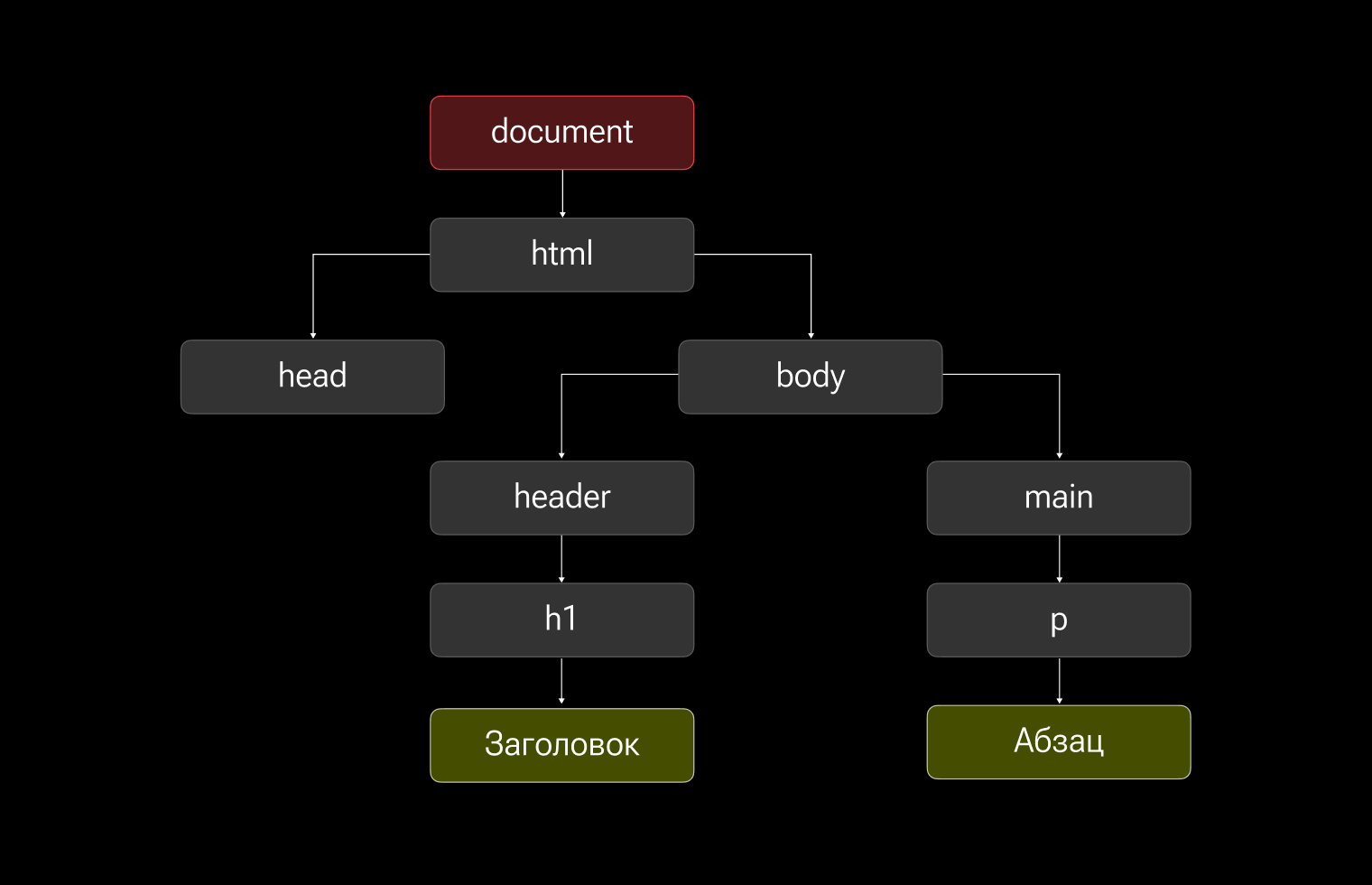
По схеме видно, что структура похожа на генеалогическое древо. Отсюда и название. Кстати, в этом примере я сознательно не заполнил тег head, чтобы не загромождать конструкцию, но эти элементы тоже становятся частью дерева.
Обратите внимание, элементы и текстовые узлы я обозначил разным цветом, но все они являются узлами.
Давайте разберем это DOM-дерево и то, как его видит браузер:
- корень дерева — объект document (главная точка входа);
- единственный прямой наследник — элемент html;
- у html есть два потомка: head и body;
- у body есть дети: header и main;
- header включает в себя h1 с текстом «Заголовок»;
- у main есть ребенок p с текстом «Абзац».
Эта иерархия является фундаментом, на котором строятся все манипуляции со страницей. Чтобы изменить текст в h1, нужно сначала добраться до этого узла в дереве. Чтобы добавить новый абзац после p, нужно найти правильного родителя и вставить элемент в нужное место.
Далее я покажу, как находить любые элементы в этом дереве с помощью JavaScript, и тогда вы сможете по-настоящему управлять своей страницей.
Поиск элементов в DOM-дереве
И так, после загрузки HTML-кода браузер полностью собрал DOM-дерево, и теперь с ним можно работать. Например, что-то в нем искать. Но зачем искать элементы в DOM?
Ответ простой: чтобы что-то с ними делать в JavaScript (простите за очевидность 😁). Если вы хотите проводить манипуляции с DOM-элементами в JS, нужно быть уверенным, что DOM-дерево готово до запуска скрипта. Пожалуй, это самая популярная ошибка новичков — запускать JS-код до момента готовности дерева.
Вообще, способов запустить JS после полной сборки DOM-дерева много. Я покажу лишь несколько.
Способ 1. Подключение JavaScript-файла в конце HTML-документа. К этому моменту все элементы будут готовы к работе:
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Проект</title>
</head>
<body>
<header>
<h1>Заголовок</h1>
</header>
<main>
<p>Абзац</p>
</main>
<script src="index.js"></script>
</body>
</html>
Способ 2. При подключении JavaScript-файла добавить атрибут defer в теге script. Он говорит браузеру загружать файл параллельно с парсингом HTML, но не выполнять его до тех пор, пока весь HTML-документ не будет полностью построен:
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Проект</title>
<script defer src="index.js"></script>
</head>
<body>
<header>
<h1>Заголовок</h1>
</header>
<main>
<p>Абзац</p>
</main>
</body>
</html>
Способ 3. Вы можете подключить JavaScript-файл в любом месте, но использовать событие DOMContentLoaded, которое запустит функцию-обработчик, когда DOM-дерево будет готово к работе:
document.addEventListener("DOMContentLoaded", () => {
// Здесь ваш код
});
Вы узнали, для чего нужен поиск и как запускать код для работы с деревом элементов. Самое время посмотреть на несколько способов для поиска. Инструментов навигации много, но по секрету, есть два самых популярных, которые почти заменят вам все остальные.
querySelector — для поиска в DOM-дереве
Итак, DOM готов к работе, пора учиться находить в нем элементы. Самый удобный и современный инструмент для этого — querySelector.
querySelector — это метод, который ищет первый элемент в DOM-дереве, соответствующий CSS-селектору. Если вы умеете выбирать элементы в CSS (по тегу, классу или id), то вы уже почти умеете пользоваться querySelector.
Давайте посмотрим на практике. Представьте такую HTML-структуру:
<div class="container">
<h1 class="main-title">Главный заголовок</h1>
<p class="text">Это первый абзац.</p>
<p class="text special">Это второй абзац.</p>
<button id="btn">Кнопка</button>
</div>
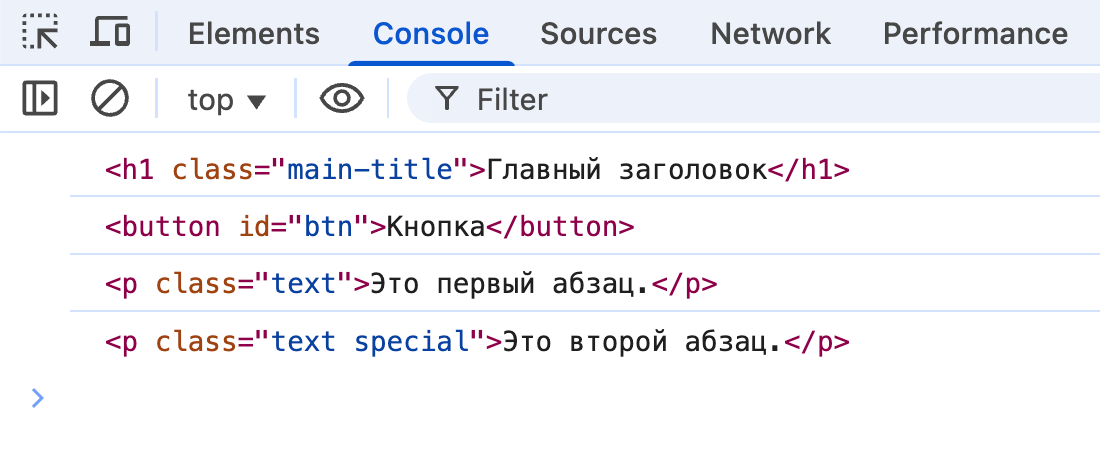
И на JavaScript-код, который сработает, когда DOM-дерево будет готово:
// Найдем первый элемент с классом "main-title"
const titleElement = document.querySelector('.main-title');
console.log(titleElement);
// Найдем элемент с id "btn" (id всегда уникален на странице!)
const button = document.querySelector('#btn');
console.log(button);
// Найдем первый абзац (тег p)
const firstParagraph = document.querySelector('p');
console.log(firstParagraph);
// Можно использовать сложные селекторы, как в CSS!
const specialParagraph = document.querySelector('.text.special');
console.log(specialParagraph);
Работает точно так же, как селекторы в CSS:
- «.» (точка) для классов;
- «#» (решетка) для id;
- имя тега без ничего другого.
Так же никто не запрещает использовать вложенные селекторы, все сработает. А если элемента нет, то функция просто вернет null.
querySelectorAll — когда нужно найти все элементы
А что, если нужно найти все элементы списка на странице, а не только первый? Для этого есть метод — querySelectorAll. Не перепутайте — querySelector без All.
querySelectorAll — это метод, который находит и возвращает все элементы на веб-странице, соответствующие заданному CSS-селектору, в виде статической коллекции NodeList, похожей на массив.
NodeList (список узлов) в JavaScript — это коллекция (упорядоченный набор) узлов DOM, которые обычно представляют элементы HTML, текстовые узлы или другие типы узлов на веб-странице.
Смотрим на примере, как работать с результатом querySelectorAll, то есть с возвращаемым ею списком. Делаем зебру:
<article class="article">
<h2>Статья о JavaScript</h2>
<ol>
<li>DOM-дерево</li>
<li>Что такое DOM на самом деле?</li>
<li>Поиск элементов в DOM-дереве</li>
<li>querySelector — для поиска в DOM-дереве</li>
<li>querySelectorAll — когда нужно найти ВСЕ элементы</li>
</ol>
</article>
И JavaScript. В этот раз нам понадобится метод обработки массива forEach:
// 1. Находим ВСЕ li внутри списка статьи
const listItems = document.querySelectorAll(".article ol > li");
// 2. Перебираем их и красим по очереди
listItems.forEach((item, index) => {
if (index % 2 === 0) {
item.style.backgroundColor = "black";
item.style.color = "white";
}
});

Конечно, такую стилизацию предпочтительнее сделать с помощью CSS, но наша задача — разобраться на простом примере, как работать с этим методом.
Что нужно помнить при работе с querySelectorAll:
- он ищет все элементы, соответствующие CSS-селектору;
- возвращает NodeList (статическую коллекцию);
- отдает пустой NodeList с количеством элементов 0, если ничего не найдет в отличие от querySelector, отдающим null;
- работает почти как массив, но без методов
.map(),.filter()и.reduce(); - идеален для массовых операций над элементами.
Теперь у вас есть базовый набор для поиска в DOM: один элемент — querySelector, все элементы — querySelectorAll.
Способов поиска и навигации по дереву очень много. Вы можете подробнее ознакомиться с ними в документации. Там объемно и больше всего, но мы — разбираем базовую базу JS и на простых примерах.
Итог
Теперь тот «лес тегов» в консоли уже не кажется таким непроходимым, верно? Вы знаете главное: DOM — это живая структура, с которой работает JavaScript. Когда вы меняете страницу через JS, вы меняете именно DOM, а не исходный HTML.
Вы освоили ключевые инструменты: querySelector для поиска одного элемента и querySelectorAll для работы с коллекциями. Теперь вы можете находить любые элементы, используя знакомые CSS-селекторы.
Это фундамент для всех дальнейших манипуляций с DOM. Уже сейчас можете экспериментировать: Откройте консоль прямо здесь, на Хабре, и попробуйте querySelector. Попробуйте найти заголовок этой статьи или изменить цвет кнопки. Только не забудьте про правильное подключение скрипта, чтобы все заработало с первого раза.