Настройка Kafka в Docker
Рассматриваем процесс настройки Kafka с использованием Docker и docker-compose, разбираем, как запустить один узел и целый кластер Kafka, а также говорим о конфигурации Producer и Consumer.
Введение
Kafka — это брокер сообщений в стриминговом режиме. Он обеспечивает обмен информацией между сервисами в режиме реального времени. Мы уже подробно рассказывали о технологии Kafka в отдельном тексте, поэтому здесь сосредоточимся на практической настройке.
Если вы не знакомы с Docker, рекомендуем пройти бесплатный курс «Docker с нуля: как работают контейнеры и зачем они нужны». В нем рассказываем, что такое Docker, как запускать контейнеры, собирать образы и использовать Docker Compose, а еще разберемся, чем технология отличается от Kubernetes. Все материалы подкреплены практическими примерами и будут понятны для начинающих.
Настройка одного узла
Первый шаг — запустить сервер Kafka в единственном экземпляре, чтобы убедиться в работоспособности. После этого можно переходить к полноценной реализации кластера.
Запуск сервера ZooKeeper в docker-compose.yml
Рассмотрим, что такое ZooKeeper и зачем он нужен. Apache Kafka использует ZooKeeper для управления ключевыми аспектами работы кластера. ZooKeeper выполняет несколько важных функций.
- Хранение метаданных о брокерах, топиках и партициях: структуру кластера, список брокеров, какие топики и партиции настроены, какой брокер за что отвечает.
- Координация лидеров партиций: выбор лидеров для партиций и поддержание согласованности при сбоях, например, если один из брокеров выходит из строя.
- Хранение информации о доступности и состоянии брокеров: отслеживание статусов всех узлов в кластере и быстрое восстановление работы при ошибках.
- Синхронизация настроек и событий: все компоненты Kafka получают актуальную информацию о состоянии кластера и синхронизируются между собой.
До версии 2.8 включительно запуск кластера Kafka без ZooKeeper невозможен — он является обязательным внешним сервисом для корректной работы распределенной архитектуры Kafka.
На сервере или виртуальной машине создадим docker-compose.yml и добавим сервис ZooKeeper:
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.3.2
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_SERVER_ID: 1
Порты для ZooKeeper и Kafka
Так как мы разворачиваем ZooKepeer и Kafka через Docker, важно правильно настроить проброс портов до контейнеров. Это обеспечит взаимодействие между узлами кластера, доступ к ним из других сервисов и извне.
Стандартные порты для наших компонентов:
- ZooKeeper: 2181 — основной порт, через который Kafka-брокеры и администраторы взаимодействуют с ZooKeeper;
- Kafka: 9092 — основной порт для связи клиентов (продюсеров, консьюмеров, инструментов мониторинга) с брокером Kafka. Каждый следующий узел Kafka может использовать свой порт (например, 9093 для второго узла).
В примере выше мы пробросили порт 2181 для ZooKeeper. Это значит, что порт контейнера будет доступен на том же порту хоста (нашего сервера). Все остальные контейнеры в одной Docker-сети смогут обращаться к ZooKeeper по внутренним именам и стандартным портам. Например, узлы Kafka будут обращаться к ZooKeper по адресу zookeeper:2181.
Запуск сервера Kafka
1. Добавим Kafka в секцию services нашего docker-compose.yml:
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.3.2
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_SERVER_ID: 1
ZOOKEEPER_SERVERS: zookeeper:2888:3888
kafka1:
image: confluentinc/cp-kafka:7.3.2
hostname: kafka1
container_name: kafka1
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://{{ VM_IP_ADDRESS }}:9092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_BROKER_ID: 1
KAFKA_LOG4J_LOGGERS:
"kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_AUTHORIZER_CLASS_NAME: kafka.security.authorizer.AclAuthorizer
KAFKA_ALLOW_EVERYONE_IF_NO_ACL_FOUND: "true"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3
depends_on:
- zookeeper
Важно: не забудьте заменить VM_IP_ADDRESS на IP-адрес вашей виртуальной машины.
2. Запустим контейнеры следующей командой, где ключ -d запускает их в фоновом режиме:
docker-compose up -d
Подключение с помощью Offset Explorer
Offset Explorer (ранее Kafka Tool) — популярная утилита для работы с кластерами Kafka. Она позволяет:
- визуализировать архитектуру кластера;
- просматривать существующих брокеров, группы получателей, отправки сообщений и задержки у консьюмеров;
- читать сообщения;
- управлять топиками, группами и ACL.
Для начала скачайте с официального сайта приложение под вашу ОС. После установки нужно лишь добавить новое подключение: укажите адрес вашей ВМ с развернутым брокером Kafka, проброшенный порт 9092, а также параметры подключения к ZooKeeper.
После подключения вы увидите свой узел Kafka и сможете управлять им через графический интерфейс.
Настройка кластера
Один брокер подходит для тестов, но для отказоустойчивости и масштабируемости нужен кластер. Теперь добавим новые узлы.
Добавление брокеров (узлов)
Ранее в docker-compose.yml для переменной KAFKA_BROKER_ID мы указали значение 1. Этот параметр должен быть уникальным для каждого узла в кластере для внутренней координации брокеров.
Добавим еще два узла в нашу инсталляцию. Для каждого нужно добавить дополнительную секцию в разделе services файла docker-compose.yml:
kafka2:
image: confluentinc/cp-kafka:7.3.2
hostname: kafka2
container_name: kafka2
ports:
- "9093:9093"
environment:
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://{{ VM_IP_ADDRESS }}:9093
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_BROKER_ID: 2
KAFKA_LOG4J_LOGGERS:
"kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_AUTHORIZER_CLASS_NAME: kafka.security.authorizer.AclAuthorizer
KAFKA_ALLOW_EVERYONE_IF_NO_ACL_FOUND: "true"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3
depends_on:
- zookeeper
kafka3:
image: confluentinc/cp-kafka:7.3.2
hostname: kafka3
container_name: kafka3
ports:
- "9094:9094"
environment:
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://{{ VM_IP_ADDRESS }}:9094
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_BROKER_ID: 3
KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_AUTHORIZER_CLASS_NAME: kafka.security.authorizer.AclAuthorizer
KAFKA_ALLOW_EVERYONE_IF_NO_ACL_FOUND: "true"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3
depends_on:
- zookeeper
Примечание: параметр KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR должен быть ≤ числу брокеров. При одном узле ставьте 1, при трех — можно использовать 3.
Создание Producer и Consumer
В docker-compose.yml мы указали все необходимое для работы кластера. Теперь нужно проверить обмен сообщениями в нашей инсталляции.
В реальных сценариях в качестве Producer и Consumer могут выступать различные сервисы. Рассмотрим на нескольких примерах.
- Устройства умного дома отправляют данные телеметрии, а сервер управления умным домом их считывает.
- Информация о сделках на бирже отправляется в кластер Kafka, а веб-приложение выступает получателем и отображает новые сделки.
- Сервисы отправляют свои логи в Kafka, а Elasticsearch собирает данные с узлов Kafka.
- Сервис аналитики отправляет события в Kafka, а ClickHouse считывает их для отчетов в реальном времени.
Но в рамках инструкции не будем работать с подобной инфраструктурой, а создадим простые Producer и Consumer. Продюсер будет раз в 30 секунд отправлять сообщение с порядковым номером, а консьюмер — его считывать.
Для начала организуем директорию для создания Producer и Consumer и добавим в нее две соответствующие директории. Также в каждой из создадим Dockerfile и файл формата .py с названием директории:
./producer/Dockerfile
./producer/producer.py
./consumer/Dockerfile
./consumer/consumer.py
Подготовка Producer
В Dockerfile продюсера (producer/Dockerfile) добавим фрагмент:
FROM python:3.10-slim
WORKDIR /app
COPY producer.py .
RUN pip install kafka-python
CMD ["python", "producer.py"]
В файл producer/producer.py:
import time
import sys
from kafka import KafkaProducer
bootstrap_servers = [
'{{ VM_IP_ADDRESS }}:9092',
'{{ VM_IP_ADDRESS }}:9093',
'{{ VM_IP_ADDRESS }}:9094'
]
producer = KafkaProducer(bootstrap_servers=bootstrap_servers)
msg_number = 1
while True:
message = f'This is {msg_number} message'.encode()
producer.send('events', message)
producer.flush()
print(f"Sent: {message.decode()}", flush=True)
msg_number += 1
time.sleep(30)
Важно: не забудьте заменить VM_IP_ADDRESS на IP-адрес вашей виртуальной машины.
Подготовка Consumer
В consumer/Dockerfile добавим следующий фрагмент:
FROM python:3.10-slim
WORKDIR /app
COPY consumer.py .
RUN pip install kafka-python
CMD ["python", "consumer.py"]
В файл consumer/consumer.py добавим:
import sys
from kafka import KafkaConsumer
bootstrap_servers = [
'{{ VM_IP_ADDRESS }}:9092',
'{{ VM_IP_ADDRESS }}:9093',
'{{ VM_IP_ADDRESS }}:9094'
]
consumer = KafkaConsumer(
'events',
bootstrap_servers=bootstrap_servers,
group_id='test-group',
auto_offset_reset='earliest'
)
for msg in consumer:
print(f"[{msg.topic}] partition={msg.partition}, "
f"offset={msg.offset}, value={msg.value.decode()}",
flush=True)
Параметр auto_offset_reset='earliest' позволяет прочитать все старые сообщения из топика, даже если консьюмер запущен позже продюсера.
Примечание: не забудьте заменить VM_IP_ADDRESS на IP вашей виртуальной машины.
Добавление producer и consumer в Docker Compose
Совсем скоро мы сможем запустить наш кластер и проверить его работу, но перед этим важно контейниризировать наши Producer и Consumer. Для этого в текущей директории создадим docker-compose.yml и добавим содержимое:
services:
producer:
build: ./producer
consumer:
build: ./consumer
depends_on:
- producer
Запуск кластера с docker-compose
Все готово к запуску кластера. На хосте с Kafka перейдем в директорию с docker-compose.yml и запустим наш кластер командой:
docker compose up -d
Далее на нашем ПК откроем приложение Offset Explorer и добавим в параметры подключения остальные узлы Kafka с портами 9093 и 9094 соответственно.
Подключение к Kafka из другого Docker-контейнера
Как только в Offset Explorer будут видны все три брокера, запустим Producer и Consumer. Для этого выполним в директории с docker-compose.yml команду:
docker compose up -d
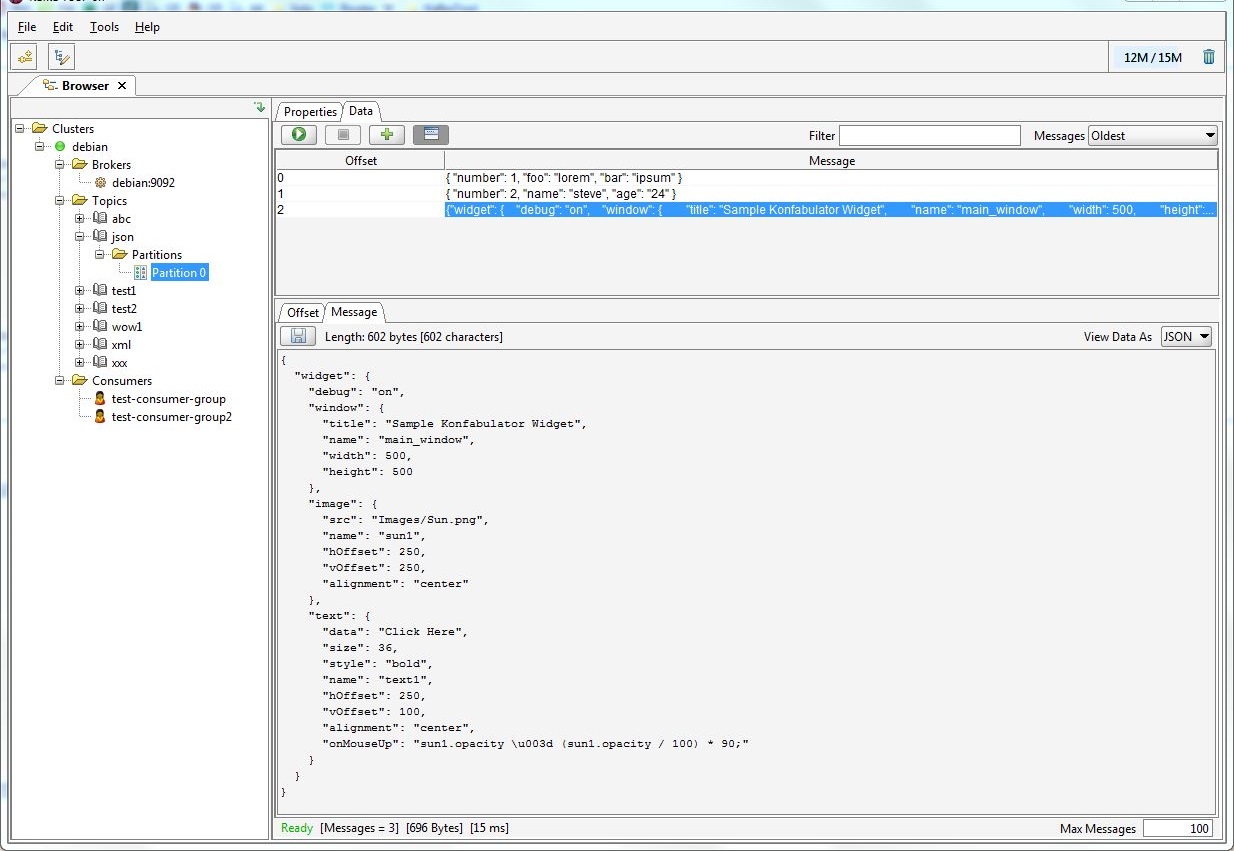
После запуска вернемся в Offset Explorer и перейдем в Topics → events → Partitions → Partition 0 → Data — здесь нажмем кнопку Retrieve Messages. После этого увидим таблицу с сообщениями, которые Producer уже успел записать в топик.
В Consumers → test-group → Offsets нажмем Refresh Offsets. Появится статистика по тому, сколько сообщений считал Сonsumer.
Альтернативно можно просмотреть логи прямо из консоли:
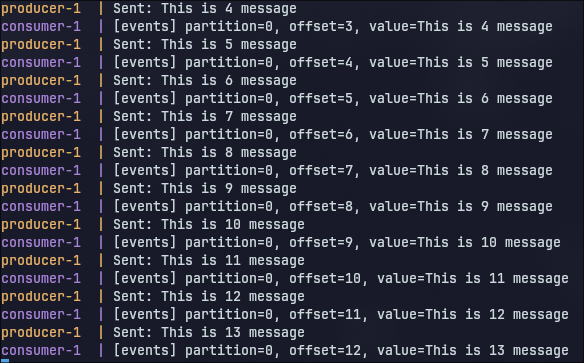
docker compose logs -f
Это позволит отслеживать обмен сообщениями между Producer и Consumer в реальном времени.
Остановка Kafka в Docker
Остановить работу кластера можно всего одной командой. Ее нужно выполнить в той же директории, где лежит наш docker-compose.yml для Kafka:
docker compose down
Аналогичные действия будут и для остановки созданных Producer и Consumer.
Apache Kafka на инфраструктуре Selectel
Что делать, если нет своей виртуальной машины для развертывания кластера Kafka? В этом случае можно воспользоваться инфраструктурой Selectel и развернуть ВМ нужной конфигурации. Дополнительно вы получите удобную панель управления, мониторинг, управление бэкапами, SLA и многое другое.
Но внедрение Kafka может привнести целый ряд технических сложностей, требующих внимательного и компетентного инженерного подхода. Если вы хотите полностью снять с себя заботы по настройке, обслуживанию и оптимизации производительности, используйте облако для Kafka (Kafka-as-a-service).
Среди преимуществ Kafka-as-a-Service:
- легкое и надежное масштабирование,
- высокая производительность,
- потоковая обработка данных в реальном времени,
- простая интеграция с другими системами,
- хранение больших объемов данных.
Сервис разворачивается за несколько кликов в панели управления.
1. Заходим в раздел Облачная платформа → Базы данных и нажимаем Создать кластер.
2. Вводим имя, выбираем регион и пул. В поле СУБД указываем Kafka.

3. Настраиваем конфигурацию, указываем количество vCPU, RAM и размер диска. При необходимости изменить конфигурацию нод можно и после создания кластера.
4. Выбираем или создаем подсеть: приватную — если доступ из интернета не нужен (можно подключить статический публичный IP) или публичную — тогда все адреса публичной подсети будут доступны из интернета.
5. Проверяем цену и нажимаем Создать кластер.
Кластер будет готов к работе, когда перейдет в статус ACTIVE. Подробнее о подключении к кластеру, управлении топиками, мониторинге кластера и не только — в документации. Внутри вы найдете множество пошаговых инструкций, примеров и полезных советов по использованию Kafka-as-a-Service.
Заключение
Мы последовательно прошли путь от развертывания одного брокера Kafka до полноценного кластера с несколькими узлами. Настроили Producer и Consumer, убедились в корректной передаче сообщений и узнали, как контролировать работу кластера через Offset Explorer и логи контейнеров.
При этом рассмотрели альтернативный сценарий — использование Kafka-as-a-Service. Такой подход снимает с разработчиков необходимость управлять инфраструктурой вручную и позволяет сосредоточиться на логике приложений. Вы можете начать с небольшого тестового кластера, а затем масштабировать его под растущие нагрузки, не теряя времени на рутину.