Как поднять сервер для ML с JupyterLab
Делимся способом, как всего за несколько кликов поднять рабочее пространство на базе готового образа для ML и Data.
Self-hosted в работе с ML — это база. Для работы с данными, особенно если они чувствительные, нужно собственное хранилище, а также ресурсы, на которых можно быстро и без очереди развернуть пайплайн. Часто в «джентльменский набор» ML-инженера входит: Jupyter Notebook, фреймворки Tensorflow и Keras, а также ускорители вроде XGBoost и LightGBM.
Самостоятельная установка компонентов и настройка рабочего окружения — нетривиальная задача. Нужно разбираться в Docker и принципах контейнеризации, а также следить за конфликтами версий и разбирать dependency hell. И, конечно, нужно настроить хранилище и соединение с сервером, а это задача не одного дня.
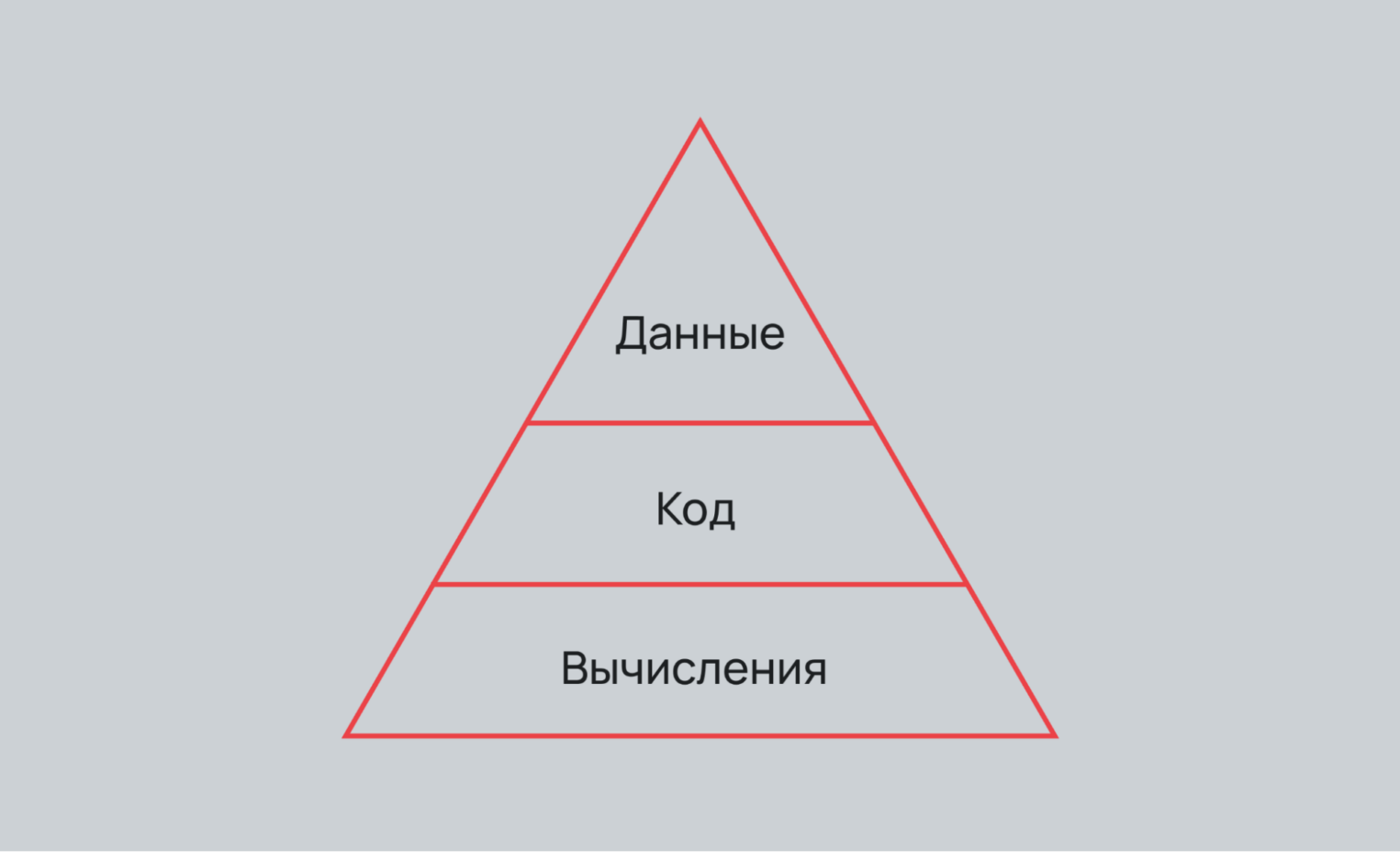
Три уровня работы с ML и Data
Рабочую среду для ML можно описать тремя словами: код, данные и вычисления. Давайте разберем каждый уровень подробнее.
Вычисления на GPU
Для работы с моделями, особенно на этапе инференса, необходимы Видеокарты. GPU, в отличие от CPU, лучше подходят для работы с нейронными сетями, так как обладают огромным количеством ядер, которые параллельно обрабатывают матричные операции.
Притом в продакшене нужны мощные видеокарты с большим количеством CUDA-ядер и запасом по видеопамяти. Можно использовать, например, NVIDIA L4, Tesla T4, Tesla A100 или Tesla H100. Если нужен вариант попроще, подойдет и RTX 4090, и 2080Ti. Для тестовой среды, нетребовательной ко времени работы, это приемлемые решения.
Характеристики популярных видеокарт для ML из разных ценовых сегментов:
| Видеокарта | Память | CUDA-ядра |
| RTX A2000 | 6 ГБ | 3 328 |
| GTX Titan X | 12 ГБ | 3 584 |
| GTX 1080 | 8 ГБ | 2 560 |
| RTX 2080Ti | 11 ГБ | 4 352 |
| RTX 3070 | 8 ГБ | 5 888 |
| RTX A4000 | 16 ГБ | 6 144 |
| NVIDIA A2 | 16 ГБ | 2 560 |
| Tesla T4 | 16 ГБ | 2 560 |
| RTX A5000 | 24 ГБ | 8 192 |
| NVIDIA L4 | 24 ГБ | 7 424 |
| Tesla V100 | 32 ГБ | 5 120 |
| RTX 4090 | 24 ГБ | 16 384 |
| Tesla A100 | 40 ГБ | 8 192 |
| RTX 6000 Ada | 48 ГБ | 18 176 |
| Tesla H100 | 80 ГБ | 14 592 |
Запомните этот список, к нему мы еще вернемся.
В отдельном тексте разобрались, как выбрать видеокарту для обучения нейросетей и Deep Learning.
Среда с кодом
Что входит в базовые задачи помимо «обучения»? Это может быть и простое исследование данных (EDA), построение наглядных визуализаций, регрессионный анализ, прогнозирование, классификация и кластеризации. В общем, все то, что помогает посмотреть на данные под другим углом.
Можно выделить следующий джентльменский набор.
- Jupyter, Zeppelin или DataSpell — среды разработки для DataScince- и ML-специалистов.
- Airflow, Prefect или Dagster — инструменты для построения пайплайнов обработки данных. Помогают регулярно запускать ETL-процессы и мониторить результаты их выполнения.
- Metabase, Power BI, Superset, Redash, Tableau или Qlik — компонент для визуализации данных и построения дашбордов.
- Базы данных PostgreSQL, Clickhouse или облачные DataWarehouse — неотъемлемая часть каждой платформы для анализа данных.
- Python и специализированные библиотеки — например, TensorFlow или PyTorch. Выбор зависит от вашей задачи.
Но, опять же, этот набор бессмыслен без вычислительных ресурсов, на базе которых можно развернуть все компоненты. Для создания полноценной рабочей среды локальная машина не подойдет. Каждый раз перемещать то данные, но нотбуки из репозитория в репозиторий — неудобно.
Понятно, что для работы понадобится сервер. Но также важно предусмотреть отдельно хранилище данных, в котором можно хранить датасеты и веса обученных моделей.
Хранилище данных
Один из наиболее популярных сервисов для хранения исследовательских данных — объектное хранилище, оно же S3. Технология позволяет работать с большим количеством информации любого типа и быстро масштабироваться. В числе ее преимуществ — автоматическое резервное копирование и возможность добавления метаданных к файлам.
С помощью метаданных можно удобно сортировать объекты по типу, дате создания и т. д. Находить и управлять объектами можно с помощью уникальных URL — алгоритмы доступа здесь довольно простые. Даже если данных в S3 будет очень много, доступ к отдельным объектам вы получите также быстро. Именно поэтому его и используют для хранения, например, отчетности, персональных данных, Big Data или резервных копий.
Конструктор на этот вечер: итоговая схема
На первый взгляд, получается простая связка. В основе рабочего окружения должен быть сервер с предустановленным ПО и GPU и S3-хранилище, которое подключено через API. Но все не так очевидно, когда дело доходит до реализации.
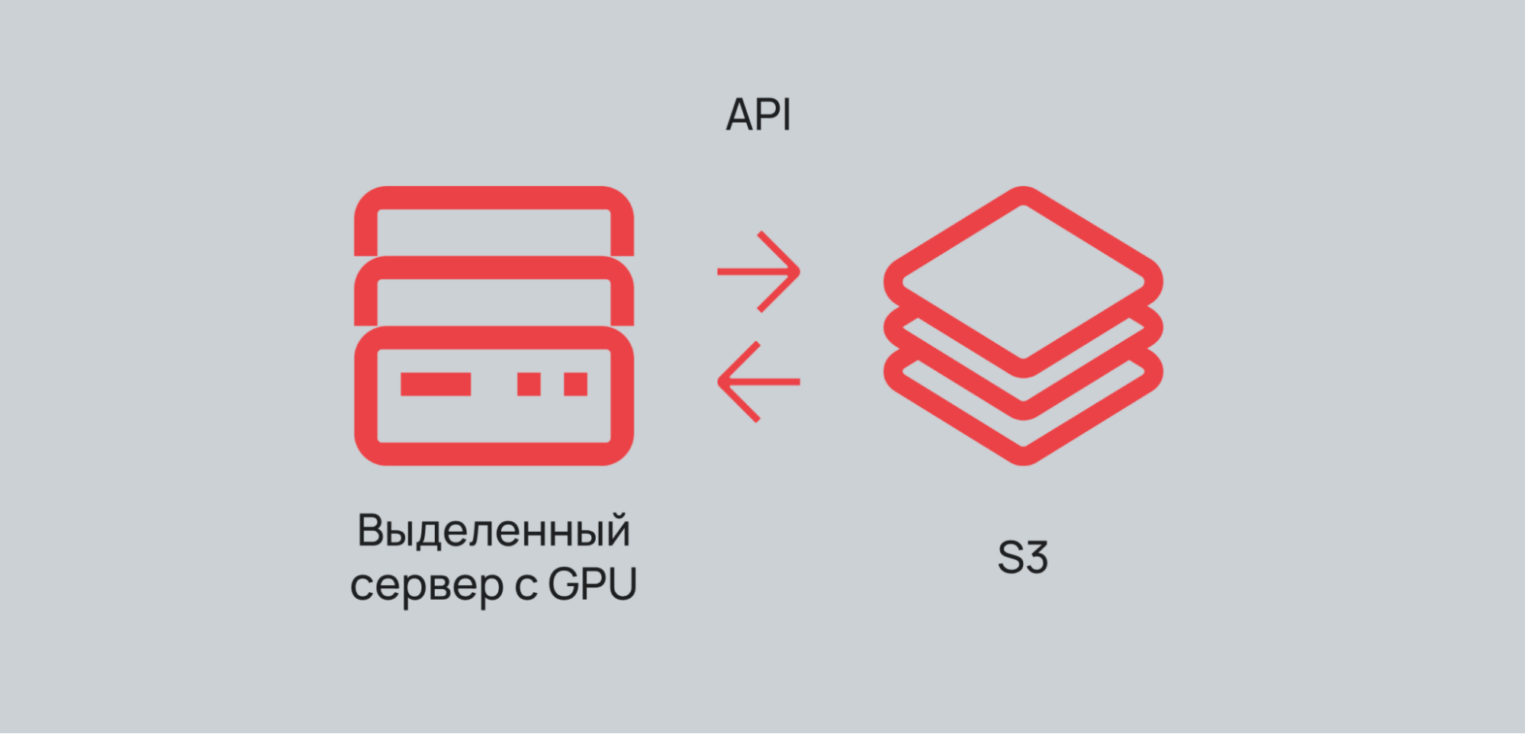
Проблема 1. Подбор конфигурации
Да, выделенный сервер и S3 довольно развернуть не составит труда. Гораздо сложнее — выбрать конфигурацию под нужную GPU. Можно переборщить с оперативной памятью или CPU, из-за чего ресурсы будут утилизироваться нерационально.
Решение
Мы собрали готовые конфигурации выделенных серверов с видеокартами. Такие серверы можно использовать для работы с ML и Data — есть как сборки исследований и тестовых окружений, так и для разработки полного цикла, с запуском инференса.
| Конфигурация | Видеокарта |
| GL1-H100-25GE | Tesla H100 80 ГБ HBM2 |
| GL2-A100-NVLink-25GE | 2 × Tesla A100 40 ГБ HBM |
| GL10-1-T4 | Tesla T4 16 ГБ GDDR6 |
| GL70-1-A100 | Tesla A100 40 ГБ HBM2 |
| AR32G-NVMe | A2000 6 ГБ GDDR6 |
| CL23G-NVMe | 2080Ti 11 ГБ GDDR6 |
| CL80G-NVMe | 2080Ti 11 ГБ GDDR6 |
| GL4-A100-NVLink-25GE | 4 × Tesla A100 40 ГБ HBM |
Все ресурсы — только ваши на время аренды. При этом оплата происходит посуточно, а не за месяц сразу.
Проблема 2. Подготовка образа
Самое сложное — собрать образ для выделенного сервера. Нужно разбираться в Docker и принципах контейнеризации, а также следить за конфликтами версий и разбирать dependency hell.
Решение
Мы в Selectel собрали образ для Data Science, в котором предустановлены следующие инструменты:
- Python 3.11,
- pip,
- PyTorch,
- TensorFlow,
- JupyterLab,
- Jupyter Notebook,
- Keras,
- scikit-learn,
- NumPy,
- SciPy,
- pandas,
- NLTK,
- OpenCV,
- CatBoost,
- XGBoost,
- LightGBM.
Установить готовый образ можно на выделенный сервер готовой конфигурации с GPU. Давайте попробуем это реализовать.
Подготовка рабочей среды
Создание выделенного сервера
1. Перейдите в панель управления и откройте вкладку Выделенные серверы.
2. В открывшемся меню выберите одну из конфигураций с GPU. Главное, чтобы она была в таблице выше.
Для демонстрации возьмем сборку GL10-1-T4, в которой установлена Tesla T4.
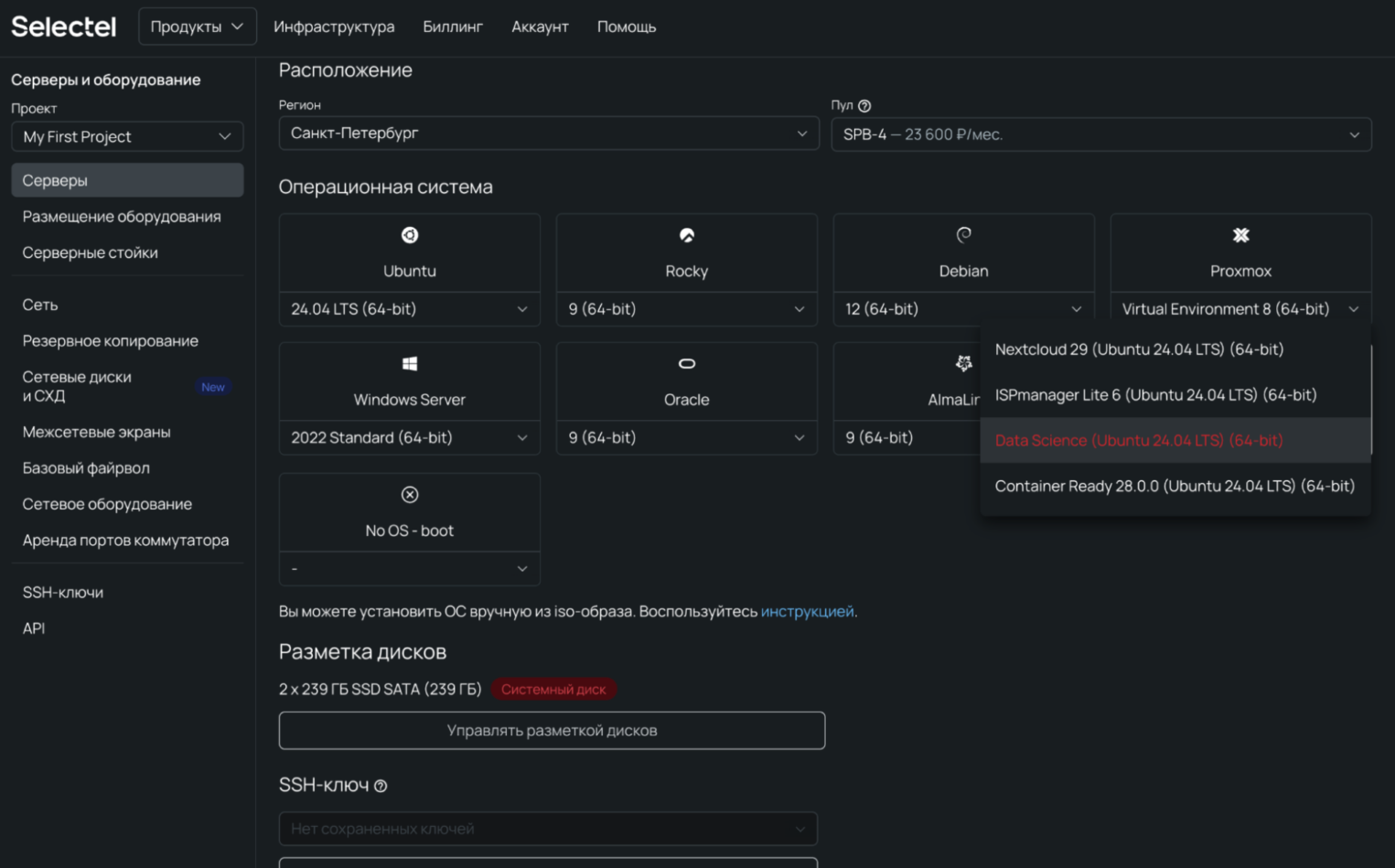
3. Откройте страницу сервера и перейдите ко вкладке Операционная система. В поле Дистрибутив выберите Pre-installed Apps → Data Science (Ubuntu 24.04 LTS).
3. Опционально: для безопасного подключения к серверу по зашифрованному протоколу SSH выберите ранее загруженный и размещенный SSH-ключ или добавьте новый. Подробнее — в инструкции.
4. Выберите тарифный план и нажмите Оплатить сейчас. Далее вы получите сервер с готовностью от нескольких минут до часа.
5. После установки ОС будет сгенерирован пароль для подключения к серверу, который также используется для авторизации в JupyterLab. Пароль можно скопировать в панели управления — для этого перейдите в раздел Операционная система.
Пароль доступен для просмотра 24 часа с момента начала установки ОС или изменения конфигурации. Если забыли пароль от сервера, вы можете сбросить и восстановить его.
Подключение к JupyterLab
Теперь по IP-адресу сервера можно открыть в браузере JupyterLab. Для авторизации достаточно ввести пароль от сервера.
После авторизации открывается стандартный интерфейс инструмента. Вы можете создавать свои нотбуки и писать код. Но где хранить данные?
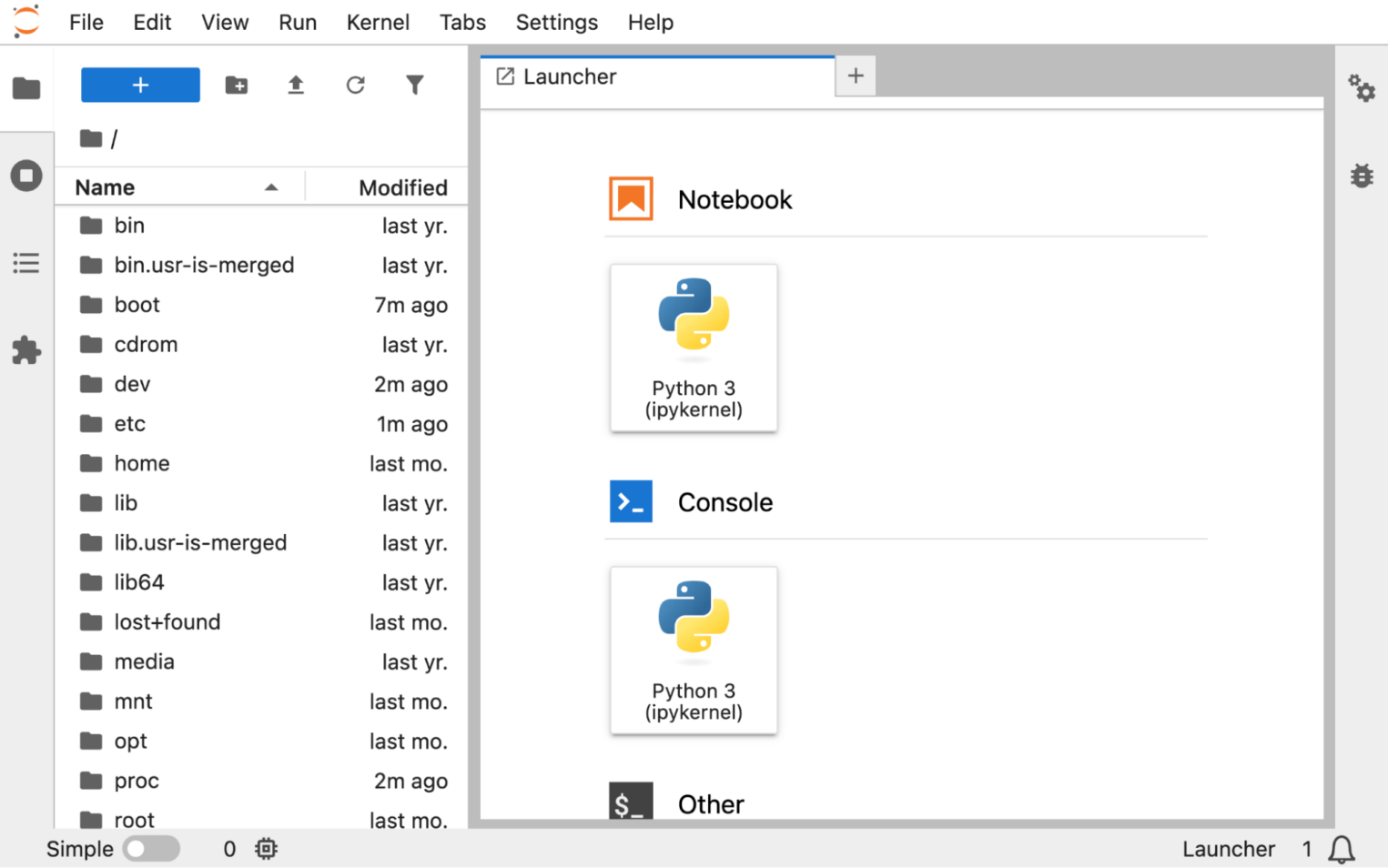
Создание кластера S3
1. Перейдите в панель управления и откройте раздел S3.
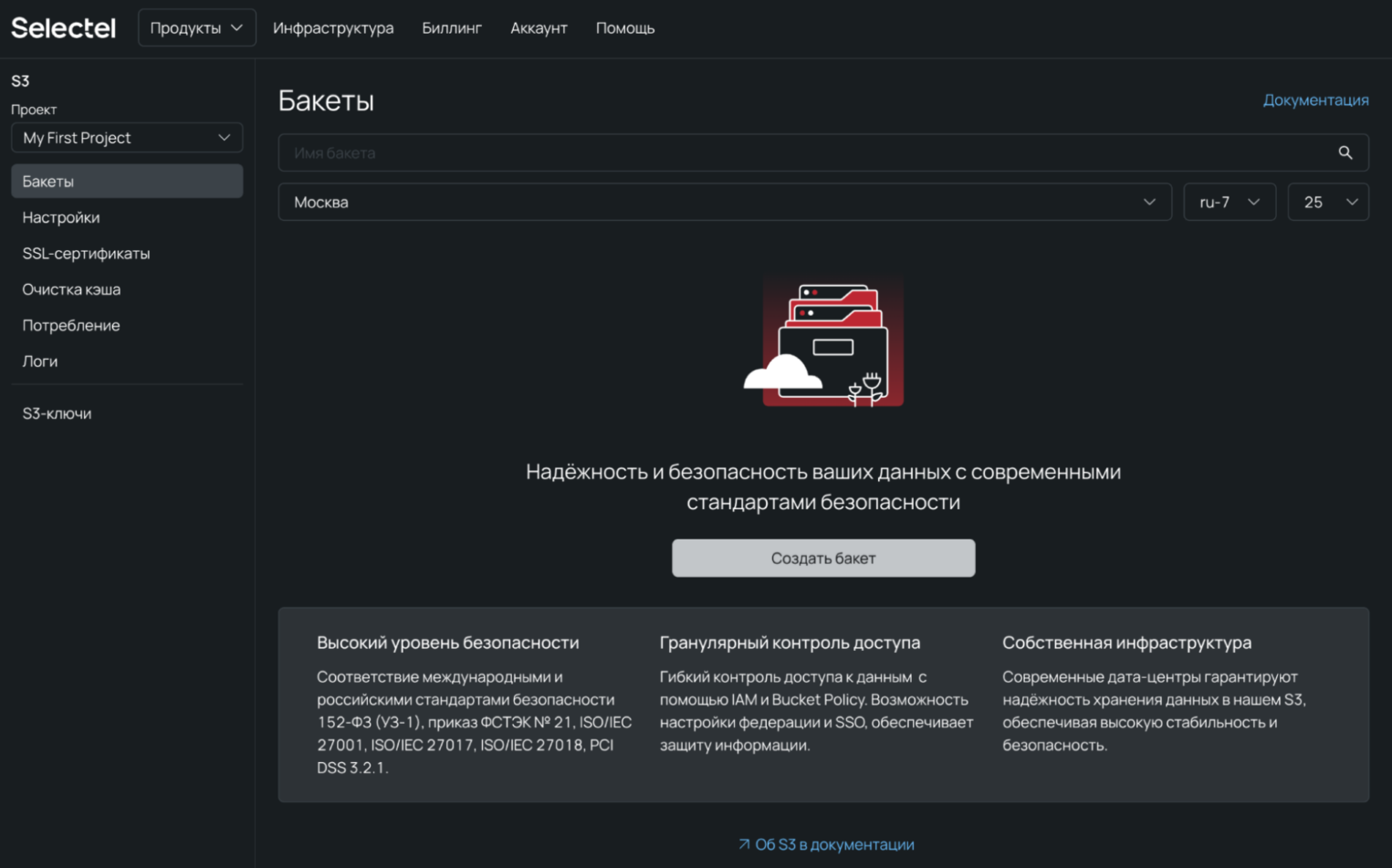
2. Нажмите на кнопку Создать бакет.
3. На открывшейся странице задайте имя и укажите регион и пул, в которых будет размещен бакет. Оптимальный вариант — тот же пул, в котором вы создавали сервер.
- Для примера создадим публичный бакет. Такой контейнер доступен без авторизации. Если же вам нужно ограничить прямой доступ до файлов — подойдет приватный.
- Класс — стандартное хранение. Оптимальный выбор для работы с часто используемыми данными. Холодное хранение применяется для бэкапов, архивов и прочих важных данных с редким обращением.
4. Нажмите на кнопку Создать контейнер.
Создание сервисного пользователя и S3-ключа
Чтобы взаимодействовать с S3 по API, следует создать сервисного пользователя и S3-ключ.
1. Нажмите на свой аккаунт в правом верхнем углу экрана и откройте вкладку Пользователи → Сервисные пользователи.
2. Нажмите на Добавить сервисного пользователя. Имя пользователя можно оставить по умолчанию, а пароль сгенерировать.
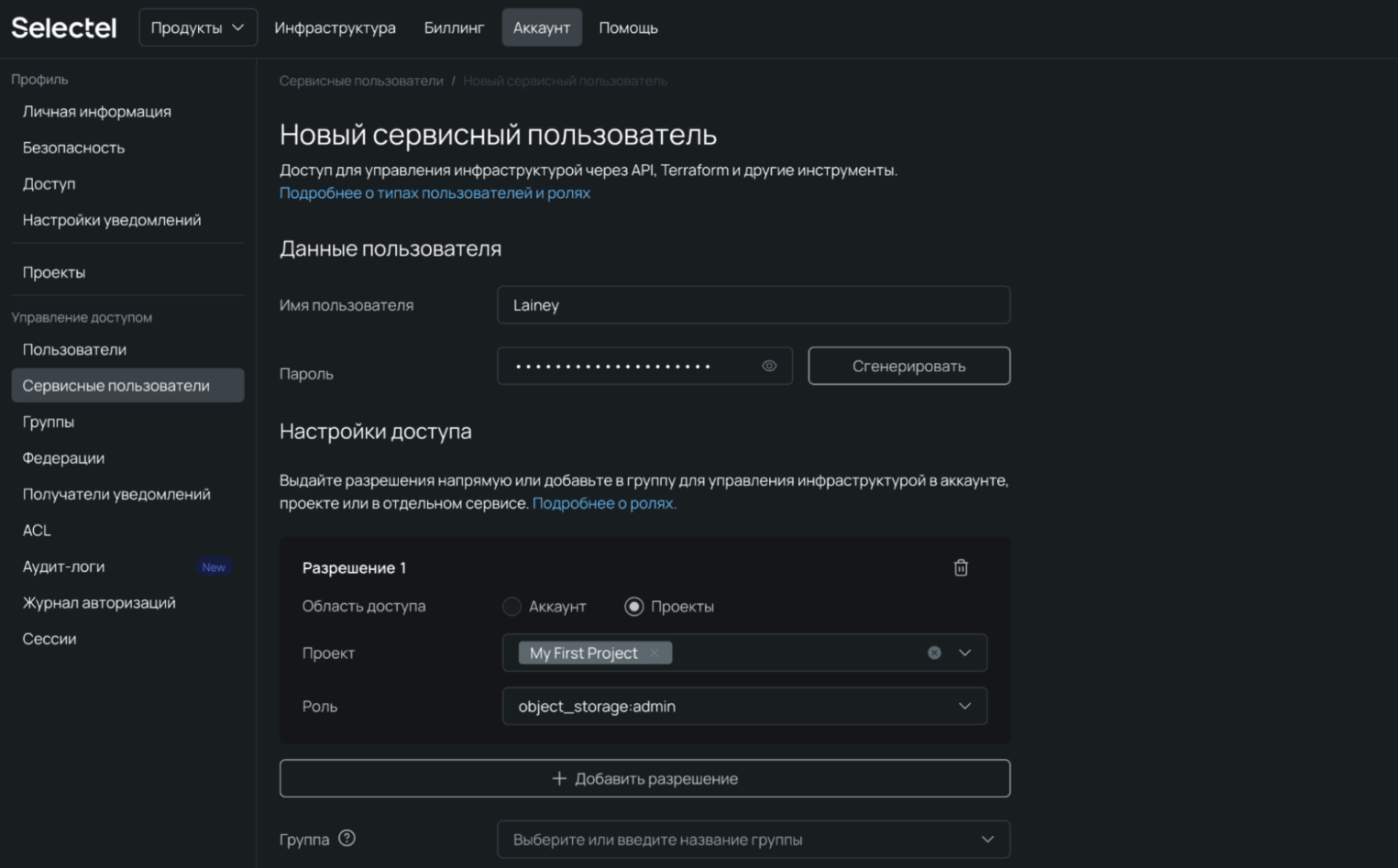
3. В поле Роль выберите object_storage:admin.
4. После выбора нужного проекта нажмите Добавить пользователя.
Создание S3-ключа
1. Перейдите во вкладку S3 → S3-ключи.
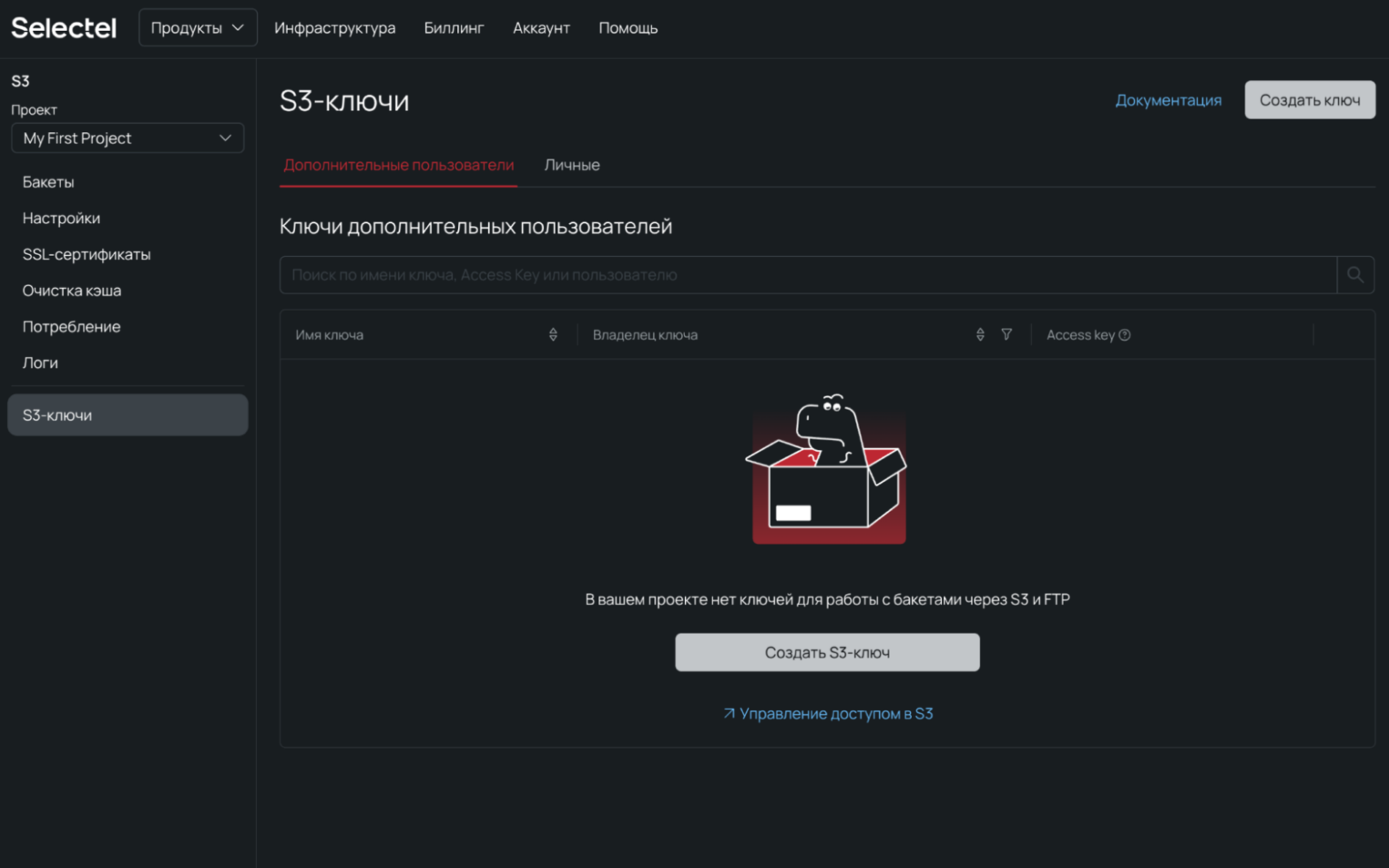
2. Нажмите на кнопку Создать S3-ключ.
3. В открывшемся окне выберите сервисного пользователя, за которым будет закреплен ключ.
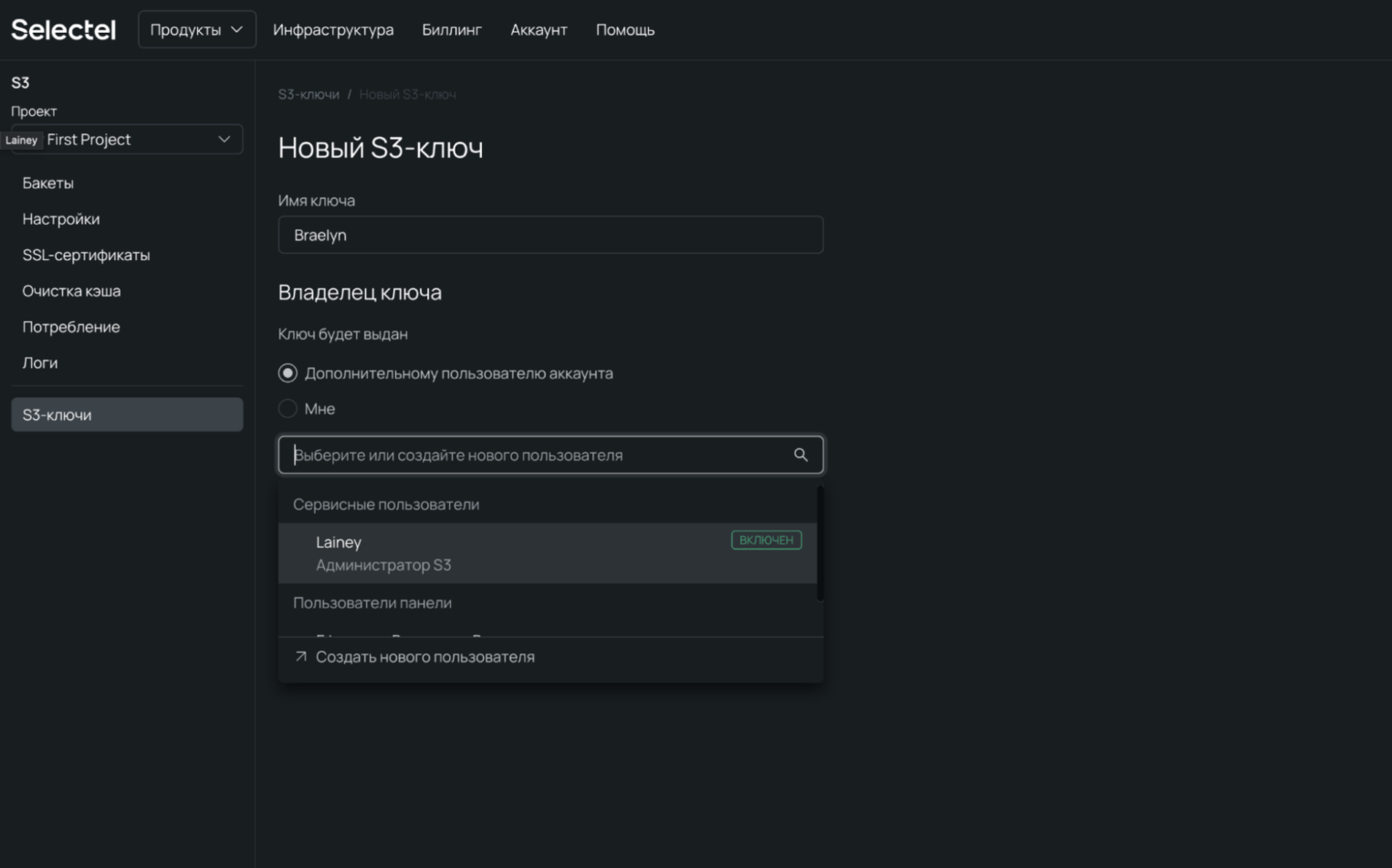
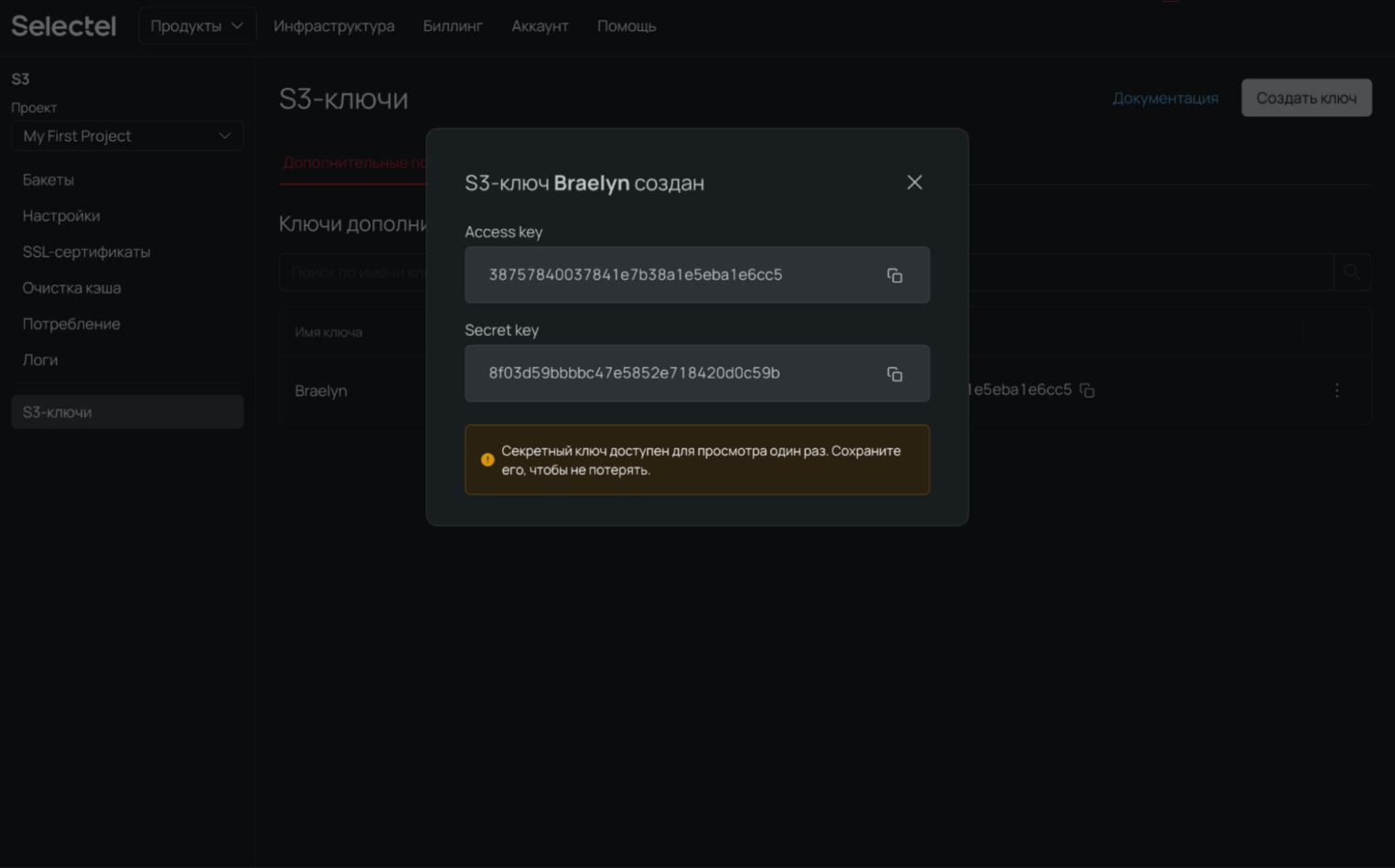
4. Нажмите Создать ключ.
5. Далее скопируйте и сохраните секретный ключ. Он доступен для просмотра один раз — лучше его не терять.
Теперь, когда мы создали и настроили S3 и выделенный сервер, можно перейти к практике и организовать подключение между ними.
Подключение S3 к JupyterLab
Прелесть S3 в том, что с ним можно работать через API. Не нужно отдельно настраивать соединение через локальную сеть, как если бы мы использовали файловое хранилище.
Поэтому процесс подключения к S3 ничем не отличается от стандартного — достаточно воспользоваться S3 API. Если вы работаете с Python, то можно использовать SDK boto3.
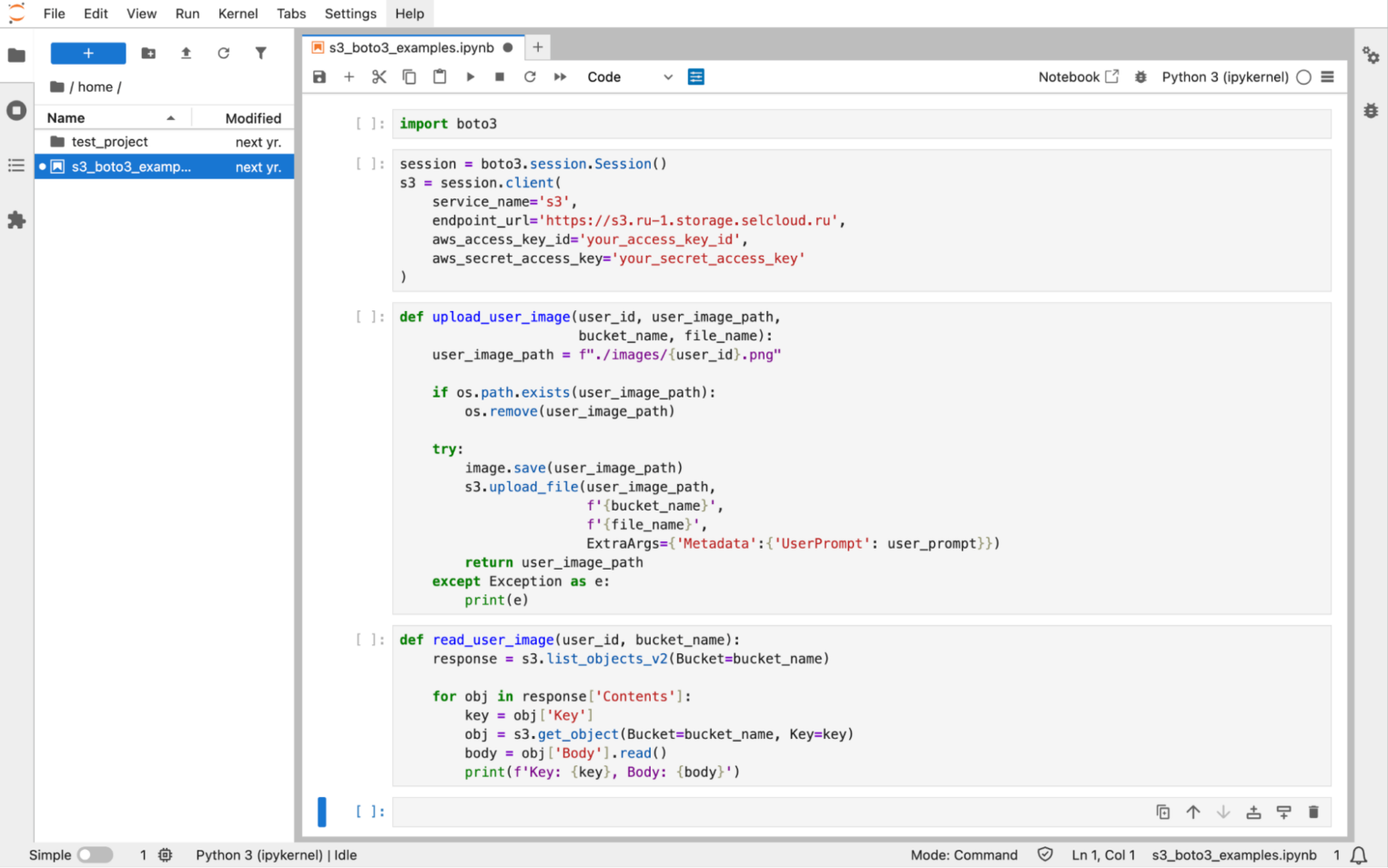
1. Импортируйте boto3.
import boto3
2. Создайте сессию boto3 с указанием URL сервиса S3 для Selectel — https://s3.storage.selcloud.ru. Данные your_access_key_id и your_secret_access_key были получены ранее.
session = boto3.session.Session()
s3 = session.client(
service_name='s3',
endpoint_url='https://s3.ru-1.storage.selcloud.ru',
aws_access_key_id='your_access_key_id',
aws_secret_access_key='your_secret_access_key'
)
Отлично! Теперь вы можете загружать файлы в бакет и читать их.
Пример записи файла в бакет:
def upload_user_image(user_id, user_image_path,
bucket_name, file_name):
user_image_path = f"./images/{user_id}.png"
if os.path.exists(user_image_path):
os.remove(user_image_path)
try:
image.save(user_image_path)
s3.upload_file(user_image_path,
f'{bucket_name}',
f'{file_name}',
ExtraArgs={'Metadata':{'UserPrompt': user_prompt}})
return user_image_path
except Exception as e:
print(e)
Пример чтения файла из бакета:
def read_user_image(user_id, bucket_name):
response = s3.list_objects_v2(Bucket=bucket_name)
for obj in response['Contents']:
key = obj['Key']
obj = s3.get_object(Bucket=bucket_name, Key=key)
body = obj['Body'].read()
print(f'Key: {key}, Body: {body}')
Что особенно важно для данных, которые используются в ML, это метаданные. Представьте: у вас есть сервис для генерации картинок, но вы хотите сохранять не только результаты, но и исходные промты. В таком случае метаданные в S3 станут отличным решением, которое избавляет от дополнительной базы данных с хэш-картой типа изображение-промт.
Пример чтения метаданных из S3:
metadata = s3.head_object(Bucket='your_bucket_name', Key=’your_file_name’)
print(metadata)
Вывод:

Пример: генерация изображений с сохранением в S3
Наконец, мы можем объединить и вычислительные ресурсы, и программное обеспечение, и S3-хранилище в одном кейсе. Самое первое, что приходит в голову, — это генератор изображений по пользовательским промтам.
Это все можно реализовать на базе библиотеки моделей Diffusers. Сервер принимает запрос, генерирует изображение на мощностях GPU и сохраняет результат с метаданными в S3-хранилище.
! pip install diffusers transformers scipy
! pip install accelerate
from diffusers import StableDiffusionPipeline
import torch
import boto3
import os
from datetime import datetime
# Инициализация модели Stable Diffusion
model_id = "dreamlike-art/dreamlike-diffusion-1.0"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
# Инициализация S3-клиента
session = boto3.session.Session()
s3 = session.client(
service_name='s3',
endpoint_url='https://s3.ru-7.storage.selcloud.ru', # Можно скопировать из панели управления S3, вкладка Подключение
aws_access_key_id='8f03d59bbbbc47e5852e718420d0c59b',
aws_secret_access_key='38757840037841e7b38a1e5eba1e6cc5'
)
def generate_and_upload_image(user_id, user_prompt, bucket_name):
"""
Генерирует изображение и загружает в S3
Args:
user_id: ID пользователя
user_prompt: промпт для генерации
bucket_name: имя бакета S3
Returns:
str: путь к загруженному файлу или None в случае ошибки
"""
# Генерация изображения
try:
images = pipe(
prompt=user_prompt,
height=512,
width=1024,
num_inference_steps=100,
guidance_scale=0.5,
num_images_per_prompt=1
).images
except Exception as e:
print(f"Ошибка генерации изображения: {e}")
return None
image = images[0]
# Создаем папку для изображений если не существует
os.makedirs("./images", exist_ok=True)
# Формируем путь к файлу
user_image_path = f"./images/{user_id}.png"
file_name = f"generated/{user_id}_{datetime.now().strftime('%Y%m%d_%H%M%S')}.png"
# Удаляем старый файл если существует
if os.path.exists(user_image_path):
os.remove(user_image_path)
# Сохраняем и загружаем изображение
try:
# Сохраняем изображение локально
image.save(user_image_path)
# Загружаем в S3
s3.upload_file(
user_image_path,
bucket_name,
file_name,
ExtraArgs={
'Metadata': {
'UserID': str(user_id),
'UserPrompt': user_prompt,
'GenerationTime': datetime.now().isoformat(),
'Model': model_id
}
}
)
print(f"Изображение успешно загружено: {file_name}")
return user_image_path
except Exception as e:
print(f"Ошибка при сохранении/загрузке изображения: {e}")
return None
generate_and_upload_image(user_id='Trex123', user_prompt='(((forrest gump))) flying on the , light blue atmosphere, hdr, cinematic', bucket_name='newtest')
Шаблон генератора есть на GitHub — вы можете адаптировать его для своих задач.
На что стоит обратить внимание:
- model_id — переменная-ссылка на модель в Hugging Face, которую хотите использовать. Галерею каждой модели можно посмотреть на Civitai и в официальной библиотеке.
- pipe.to() — метод, с помощью которого можно выбрать, на каких ядрах запустить инференс модели. Для сравнения: на процессоре инференс занимает примерно в 20 раз больше времени.
- pipe() — это функция, которая отвечает за генерацию изображений. С помощью специальных аргументов ее можно конфигурировать — например, настраивать количество размеры изображений, число итераций в инференсе, сам промт и другое.
Заключение
Мы изучили все основные этапы подготовки и запуска выделенных серверов для ML. Полученное рабочее окружение можно использовать для экспериментов, тестирования готовых сервисов и инференса. Все ресурсы — только ваши.