Сравнение способов резервного копирования

Подготовку нового сервера к работе следует начинать с настройки резервного копирования. Все, казалось бы, об этом знают — но порой даже опытные системные администраторы допускают непростительные ошибки. И дело здесь не только в том, что задачу настройки нового сервера нужно решать очень быстро, но еще и в том, что далеко не всегда бывает ясно, какой способ резервного копирования нужно использовать.

Конечно, идеальный способ, который бы всех устраивал, создать невозможно: везде есть свои плюсы и минусы. Но в то же время вполне реальным представляется подобрать способ, максимально подходящий под специфику конкретно проекта.
При выборе способа резервного копирования нужно прежде всего обратить внимание на следующие критерии:
- Скорость (время) резервного копирования в хранилище;
- Скорость (время) восстановления из резервной копии;
- Сколько копий можно будет держать при ограниченном размере хранилища (сервере хранения бекапов);
- Объем рисков из-за неконсистентности резервных копий, неотлаженности метода выполнения бэкапов, полной или частичной потери бекапов;
- Накладные расходы: уровень нагрузки, создаваемой на сервер при выполнении копирования, уменьшение скорости отклика сервиса и т.п.
- Стоимость аренды всех использующихся сервисов.
В этой статье мы расскажем об основных способах резервного копирования и о наиболее типичных проблемах, с которыми могут столкнуться новички в этой очень важной области системного администрирования.
Схема организации хранения и восстановления из резервных копий
При выборе схемы организации метода резервирования следует обратить внимание на следующие базовые моменты:
- Резервные копии нельзя хранить в одном месте с резервируемыми данными. Если вы храните резервную копию на одном дисковом массиве с вашими данными, то вы потеряете её в случае повреждения основного дискового массива.
- Зеркалирование (RAID1) нельзя сравнивать с резервным копированием. Рейд защищает вас только от аппаратной проблемы с одним из дисков (а рано или поздно такая проблема будет, т.к. дисковая подсистема почти всегда является узким местом на сервере). К тому же при использовании аппаратных рейдов есть риск поломки контроллера, т.е. необходимо хранить его запасную модель.
- Если вы храните резервные копии в рамках одной стойки в ДЦ или просто в рамках одного ДЦ, то в такой ситуации тоже имеются определенные риски (об этом можно прочитать, например, здесь.
- Если вы храните резервные копии в разных ДЦ, то резко возрастают затраты на сеть и скорость восстановления из удаленной копии.
Часто причиной восстановления данных служит повреждение файловой системы или дисков. Т.е. бекапы нужно хранить где-то на отдельном сервере-хранилище. В этом случае проблемой может стать «ширина» канала передачи данных. Если у вас выделенный сервер, то резервное копирование очень желательно выполнять по отдельному сетевому интерфейсу, а не на том же, что выполняет обмен данных с клиентами. Иначе запросы вашего клиента могут не «поместиться» в ограниченный канал связи. Или из-за трафика клиентов бекапы не будут сделаны в срок.
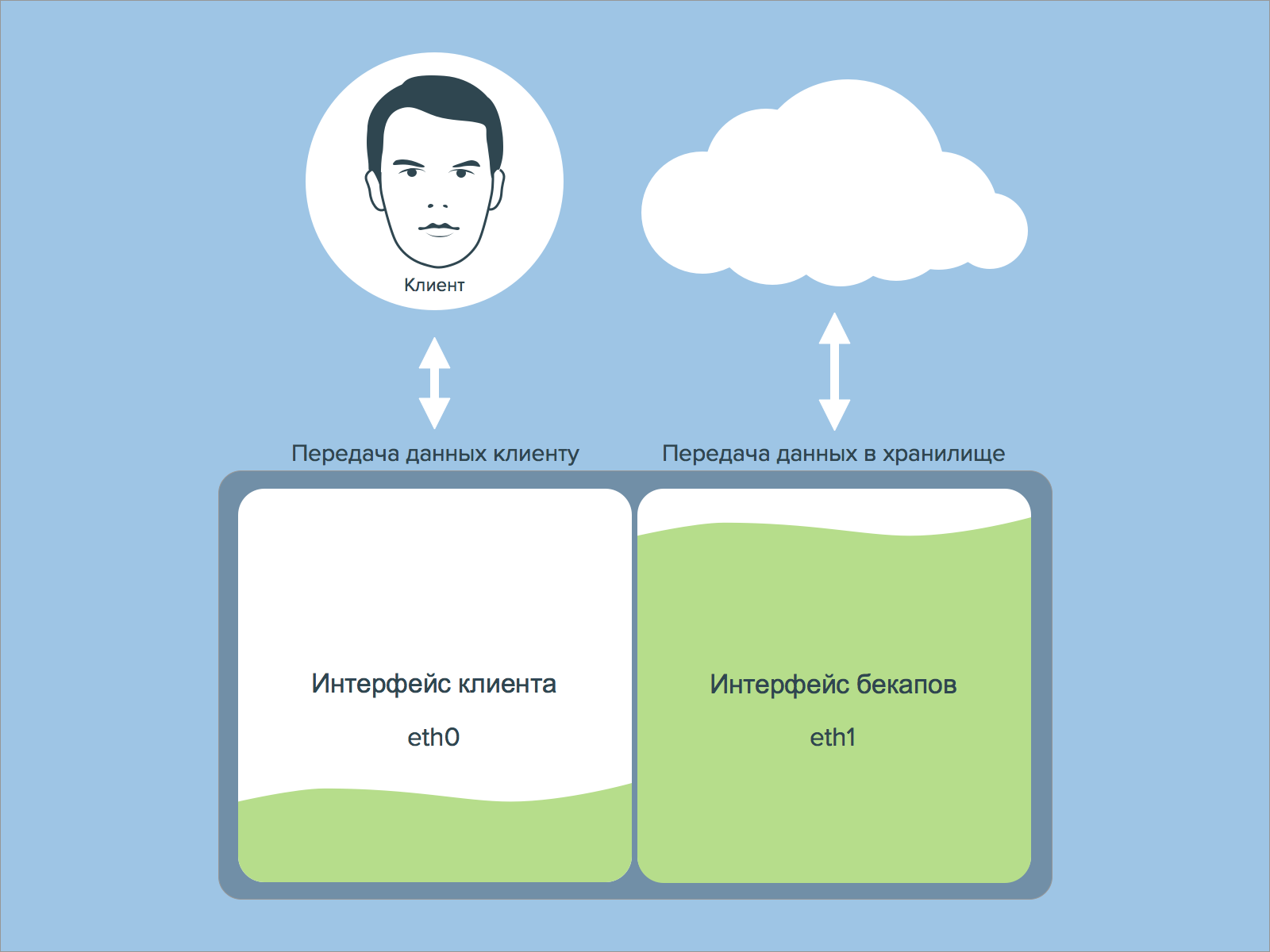
Далее нужно подумать о схеме и времени восстановления данных с точки зрения хранения бекапов. Может быть вас вполне устраивает, что бекап выполняется за 6 часов ночью на хранилище с ограниченной скоростью доступа, однако восстановление длиной в 6 часов вас вряд ли устроит. Значит доступ к резервным копиям должен быть удобным и данные должны копироваться достаточно быстро. Так, например, восстановление 1Тб данных с полосой в 1Гб/с займет почти 3 часа, и это если вы не «упретесь» в производительность дисковой подсистемы в хранилище и сервере. И не забудьте прибавить к этому время обнаружения проблемы, время на решение об откате, время проверки целостности восстановленных данных и объем последующего недовольства клиентов/коллег.
Инкрементальное резервное копирование
При инкрементальном резервном копировании копируются только файлы, которые были изменены со времени предыдущего бэкапа. Последующее инкрементальное резервное копирование добавляет только файлы, которые были изменены с момента предыдущего. В среднем инкрементальное резервное копирование занимает меньше времени, так как копируется меньшее количество файлов. Однако процесс восстановления данных занимает больше времени, так как должны быть восстановлены данные последнего полного резервного копирования, плюс данные всех последующих инкрементальных резервных копирований. При этом в отличие от дифференциального копирования, изменившиеся или новые файлы не замещают старые, а добавляются на носитель независимо.
Инкрементальное копирование чаще всего производится с помощью утилиты rsync. С его помощью можно сэкономить место в хранилище, если количество изменений за день не очень велико. Если измененные файлы имеют большой размер, то они будут скопированы полностью без замены предыдущих версий.
Процесс резервного копирования с помощью rsync можно разделить на следующие шаги:
- Составляется список файлов на резервируемом сервере и в хранилище, по каждому файлу считываются метаданные (права, время изменения и т.д) или контрольная сумма (при использовании ключа —checksum).
- Если метаданные файлов разнятся, то файл бьется на блоки и по каждому блоку считается контрольная сумма. Отличающиеся блоки закачиваются в хранилище.
- Если во время подсчета контрольных сумм или передачи файла в него было внесено изменение, его резервирование повторяется с начала.
- По умолчанию rsync передает данные через SSH, а значит каждый блок данных дополнительно шифруется. Rsync можно также запустить как демон и передавать данные без шифрования по его протоколу.
С более подробной информацией о работе rsync можно ознакомиться на официальном сайте.
Для каждого файла rsync выполняет очень большое количество операций. Если файлов на сервере много или если процессор сильно загружен, то скорость резервного копирования будет существенно снижена.
Из опыта можем сказать, что проблемы на SATA-дисках (RAID1) начинаются примерно после 200G данных на сервере. На самом деле всё, конечное же, зависит от количества inode. И в каждом случае эта величина может смещаться как в одну так и в другую сторону.
После определенной черты время выполнения резервного копирования будет очень долгим или попросту не будет отрабатывать за сутки.
Для того, чтобы не сравнивать все файлы, есть lsyncd. Этот демон собирает информацию об изменившихся файлах, т.е. мы уже заранее будем иметь готовый их список для rsync. Следует, однако, учесть, что он дает дополнительную нагрузку на дисковую подсистему.
Дифференциальное резервное копирование
При дифференциальном резервном копировании каждый файл, который был изменен с момента последнего полного резервного копирования, копируется всякий раз заново. Дифференциальное копирование ускоряет процесс восстановления. Все, что вам необходимо — это последняя полная и последняя дифференциальная резервная копия. Популярность дифференциального резервного копирования растет, так как все копии файлов делаются в определенные моменты времени, что, например, очень важно при заражении вирусами.
Дифференциальное резервное копирование осуществляется, например, при помощи такой утилиты, как rdiff-backup. При работе с этой утилитой возникают те же проблемы, что и при инкрементальном резервном копировании.
В целом, если при поиске разницы в данных осуществляется полный перебор файлов, проблемы такого рода резервирования аналогичны проблемам с rsync.
Хотим отдельно отметить, что если в вашей схеме резервного копирования каждый файл копируется отдельно, то стоит удалять/исключать ненужные вам файлы. Например, это могут быть кеши CMS. В таких кешах обычно очень много маленьких файлов, потеря которых не скажется на корректной работе сервера.
Полное резервное копирование
Полное копирование обычно затрагивает всю вашу систему и все файлы. Еженедельное, ежемесячное и ежеквартальное резервное копирование подразумевает создание полной копии всех данных. Обычно оно выполняется по пятницам или в течение выходных, когда копирование большого объёма данных не влияет на работу организации. Последующие резервные копирования, выполняемые с понедельника по четверг до следующего полного копирования, могут быть дифференциальными или инкрементальными, главным образом для того, чтобы сохранить время и место на носителе. Полное резервное копирование следует проводить по крайней мере еженедельно.
В большинстве публикаций по соответствующей тематике рекомендуется полное резервное копирование выполнять один или два раза в неделю, а в остальное время время — использовать инкрементальное и дифференциальное. В таких советах есть свой резон. В большинстве случаев полного резервного копирования раз в неделю вполне достаточно. Выполнять его повторно имеет смысл в том случае, если у вас нет возможности на стороне хранилища актуализировать полный бекап и для обеспечения гарантии корректности резервной копии (это может понадобиться, например, в случаях, если вы по тем или иным причинам не доверяете имеющимся у вас скриптам или софту для резервного копирования.
На самом деле полное резервное копирование можно поделить на 2 части:
- Полное резервное копирование на уровне файловой системы;
- Полное резервное копирование на уровне устройств.
Рассмотрим их характерные особенности на примере:
root@komarov:~# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/komarov_system-root 3.4G 808M 2.4G 25% /
/dev/mapper/komarov_system-home 931G 439G 493G 48% /home
udev 383M 4.0K 383M 1% /dev
tmpfs 107M 104K 107M 1% /run
tmpfs 531M 0 531M 0% /tmp
none 5.0M 0 5.0M 0% /run/lock
none 531M 0 531M 0% /run/shm
/dev/xvda1 138M 22M 109M 17% /bootРезервировать мы будем только /home. Все остальное можно быстро восстановить вручную. Можно также развернуть сервер системой управления конфигурациями и подключить к нему наш /home.
Полное резервное копирование на уровне файловой системы
Типичный представитель: dump.
Утилита создает «дамп» файловой системы. Можно создавать не только полную, но и инкрементальную резервную копию. dump работает с таблицей inode и «понимает» структуру файлов (так, разреженные файлы сжимаются).
Создавать дамп работающей файловой системы «глупо и опасно», потому что ФС может изменяться во время создания дампа. Его надо создавать со снапшота (чуть позже мы обсудим особенности работы со снапшотами более подробно), отмонтированной или замороженной ФС.
Такая схема так же зависит от количества файлов, и время её выполнения будет расти с ростом количества данных на диске. В то же время у dump скорость работы выше, чем у rsync.
В случае, если требуется возобновить не резервную копию целиком, а, например, только пару случайно испорченных файлов), извлечение таких файлов утилитой restore может занять слишком много времени
Полное резервное копирование на уровне устройств
- mdraid и DRBD
Фактически настраивается RAID1 с диском/рейдом на сервере и сетевым диском, и время от времени (по частоте выполнения бекапов) дополнительный диск синхронизируется с основным диском/рейдом на сервере.Самый большой плюс — скорость. Длительность выполнения синхронизации зависит только от количества внесенных за последний день изменений.
Такая система резервного копирования используется довольно часто, но мало кто отдает себе отчет в том, что полученные с ее помощью резервные копии могут быть недееспособными, и вот почему. Когда синхронизация дисков завершена, диск с резервной копией отключается. Если у нас, например, запущена СУБД, которая пишет данные на локальный диск порциями, храня промежуточные данные в кэше, нет никакой гарантии того, что они вообще попадут на бэкапный диск. В лучшем случае мы потеряем часть изменяемых данных. Поэтому такие бэкапы вряд ли стоит считать надежными. - LVM + dd
Снапшоты — замечательный инстумент для создания консистентных бекапов. Перед созданием снапшота необходимо сбросить кеш ФС и вашего ПО на дисковую подсистему.
Например, с одним MySQL это будет выглядеть так:
$ sudo mysql -e 'FLUSH TABLES WITH READ LOCK;'
$ sudo mysql -e 'FLUSH LOGS;'
$ sudo sync
$ sudo lvcreate -s -p r -l100%free -n %s_backup /dev/vg/%s
$ sudo mysql -e 'UNLOCK TABLES;'* Коллеги рассказывают истории как у кого-то «read lock» иногда приводил к дедлокам, но на моей памяти такого не было ни разу.
Далее можно копировать снапшот в хранилище. Главное — следить за тем, чтобы во время копирования снапшот не самоуничтожился и не забывать, что при создании снапшота скорость записи упадет в разы.
Бекапы СУБД можно создать отдельно (например, используя бинарные логи), устранив тем самым простой на время сброса кеша. А можно создавать дампы в хранилище, запустив там инстанс СУБД. Резервное копирование разных СУБД — это тема для отдельных публикаций.
Копировать снапшот можно с использованием докачки (например, rsync с патчем для копирования блочных устройств https://bugzilla.redhat.com/show_bug.cgi?id=494313), можно по блокам и без шифрования (netcat, ftp). Можно передавать блоки в сжатом виде и монтировать их в хранилище при помощи AVFS, и примонтировать на сервере раздел с бекапами по SMB.
Сжатие устраняет проблемы скорости передачи, забития канала и места в хранилище. Но, однако если вы не используете AVFS в хранилище, то на восстановление только части данных у вас уйдет много времени. Если будете использовать AVFS, то столкнетесь с её «сыростью».
Альтернатива сжатию блоками — squashfs: можно подмонтировать, к примеру, по Samba раздел к серверу и выполнить mksquashfs, но эта утилита так же работает с файлами, т.е. зависит от их количества.
К тому же при создании squashfs тратится достаточно много ОЗУ, что может легко привести к вызову oom-killer.
Безопасность
Необходимо обезопасить себя от ситуации когда хранилище или ваш сервер будут взломаны. Если взломан сервер, то лучше чтобы не было прав на удаление/изменение файлов в хранилище у пользователя, который записывает туда данные.
Если взломано хранилище, то права бекапного пользователя на сервере так же желательно ограничить по максимуму.
Если канал резервного копирования может быть прослушан, то нужны средства шифрования.
Заключение
У каждой системы резервного копирования свои минусы и свои плюсы. В этой статье мы постарались осветить часть нюансов при выборе системы резервного копирования. Надеемся, что они помогут нашим читателям.
В итоге, при выборе системы резервного копирования под ваш проект, нужно провести тесты выбранного типа резервного копирования и обратить внимание на:
- время резервного копирования в текущей стадии проекта;
- время резервного копирования в случае, если данных будет в разы больше;
- нагрузку на канал;
- нагрузку на дисковую подсистему на сервере и в хранилище;
- время восстановление всех данных;
- время восстановления пары файлов;
- необходимость в консистентности данных, особенно БД;
- расход памяти и наличие вызовов oom-killer;
В качестве решений по резервному копированию, можно использовать наше облачное хранилище.



