

Привет! Меня зовут Василий, я — инженер по диагностике серверного оборудования в Selectel. Занимаюсь выявлением неисправных комплектующих, их заменой и первичной настройкой оборудования перед использованием клиентами.Мой коллега Дима Хамченко ранее уже рассказывал, как мы сделали бота для проверки дисков. Разработка ежедневно помогает нашим инженерам в диагностике. Так как политика компании в том, что мы предоставляем только инфраструктуру, а за сервером следит клиент, я решил разобрать топ популярных проблем — и показать, как с ними бороться. На базе реальных примеров, с которыми люди обращаются в нашу техподдержку через тикет-систему.
Предисловие
Люди обычно пишут в техническую поддержку после того, как ощутили «бессилие» в решении проблемы. До этого пытаются пофиксить неисправность, основываясь на собственных знаниях или интернет-форумах.
Моя задача — рассказать, как можно эффективно выделить, определить и, возможно, решить проблему с вашим удаленным сервером. И написать тикет в техподдержку, который поможет инженерам быстрее разобраться в вашей проблеме и предпринять меры.
Проблема 1. Пропал доступ к серверу
Контекст
Как правило, больше обращений по такому случаю исходит от клиентов, которые используют бюджетные серверы линейки Chipcore. Ведь у них отсутствует IPMI-модуль, через который можно подключиться и проверить статус своей «лошадки», используя виртуальную клавиатуру и монитор.
Из панели управления сервер Chipcore можно только включить, выключить или перезагрузить. Кстати, перезагрузка — то, что стоит сделать в первую очередь, если пропал доступ. Как говорится, семь бед — один Reset.
Если после перезагрузки доступ не появился или вам дорого обходится время простоя, необходимо обратиться в техподдержку через тикет-систему. А внутри заявки — указать UUID сервера и исчерпывающе описать причину обращения. После наши инженеры ответят вам и займуться проверкой апаратной части, которая занимает до 12 часов. В отдельных случаях, когда в сервере установлено много оперативной памяти, время диагностики может быть увеличено, но об этом мы всегда предупредим.
Самостоятельная диагностика
Если вы все же решили провести диагностику самостоятельно, рекомендуем учесть следующие этапы.
1. Загрузитесь через панель управления в отладочный режим. Для сервера на базе Windows — в WinPE, Linux — в Rescue. Либо через Selectel Boot Menu, которая работает со всеми ОС.
Интересный факт. Как правило, наши инженеры для всех диагностик используют режим Rescue.
2. После загрузки в отладочном режиме необходимо последовательно проверить диски и разметку на них, а также настройки сетевой карты. Ниже перечислим команды, которые помогут это сделать.
Вывод разделов дискового пространства:
~ # lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
loop0 7:0 0 555.4M 1 loop /.ro
sda 8:0 1 28.6G 0 disk
├─sda1 8:1 1 703M 0 part /image
├─sda2 8:2 1 5.8M 0 part
└─sda3 8:3 1 300K 0 part
sdb 8:16 1 28.9G 0 disk
├─sdb1 8:17 1 200M 0 part
└─sdb2 8:18 1 28.7G 0 part /mnt/1
sdc 8:32 1 0B 0 disk
sr0 11:0 1 1024M 0 rom
nvme1n1 259:0 0 1.7T 0 disk
nvme4n1 259:1 0 1.8T 0 disk
nvme6n1 259:2 0 1.5T 0 disk
└─md127 9:127 0 0B 0 md
nvme2n1 259:3 0 1.7T 0 disk
nvme7n1 259:4 0 1.5T 0 disk
nvme9n1 259:5 0 1.7T 0 disk
nvme8n1 259:6 0 1.7T 0 disk
nvme5n1 259:7 0 1.8T 0 disk
nvme3n1 259:8 0 1.7T 0 disk
nvme0n1 259:9 0 7T 0 disk
Вывод общих данных о дисках:
~ # smartctl -AiH /dev/x
=== START OF INFORMATION SECTION ===
Model Number: SAMSUNG MZWLO7T6HBLA-00A07
Serial Number: S796NC0W600418
Firmware Version: OPPA2B5Q
PCI Vendor/Subsystem ID: 0x144d
IEEE OUI Identifier: 0x002538
Total NVM Capacity: 7,681,501,126,656 [7.68 TB]
Unallocated NVM Capacity: 0
Controller ID: 129
NVMe Version: 1.4
Number of Namespaces: 128
Namespace 1 Size/Capacity: 7,681,501,126,656 [7.68 TB]
Namespace 1 Utilization: 371,711,803,392 [371 GB]
Namespace 1 Formatted LBA Size: 512
Local Time is: Sat Jan 10 01:03:09 1998 UTC
=== START OF SMART DATA SECTION ===
SMART/Health Information (NVMe Log 0x02)
Critical Warning: 0x00
Temperature: 39 Celsius
Available Spare: 100%
Available Spare Threshold: 10%
Percentage Used: 0%
Data Units Read: 86,953,498 [44.5 TB]
Data Units Written: 95,194,301 [48.7 TB]
Host Read Commands: 4,758,942,709
Host Write Commands: 9,211,817,347
Controller Busy Time: 1,255
Power Cycles: 264
Power On Hours: 359
Unsafe Shutdowns: 70
Media and Data Integrity Errors: 0
Error Information Log Entries: 0
Warning Comp. Temperature Time: 0
Critical Comp. Temperature Time: 0
Temperature Sensor 1: 45 Celsius
Temperature Sensor 2: 42 Celsius
Эти данные можно использовать в качестве приложения при обращении в техподдержку. Главное, что мы спрашиваем, — это серийный номер диска.
Вывод данных об интерфейсах:
~ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: usb0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether f6:4f:9d:49:27:a0 brd ff:ff:ff:ff:ff:ff
3: eth0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 9c:6b:00:4f:bf:d6 brd ff:ff:ff:ff:ff:ff
altname eno1
altname enp5s0
4: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 9c:6b:00:4f:bf:d7 brd ff:ff:ff:ff:ff:ff
altname eno2
altname enp6s0
inet 95.143.189.40/27 brd 95.143.189.63 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::9e6b:ff:fe4f:bfd7/64 scope link
valid_lft forever preferred_lft forever
5: eth2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 9c:6b:00:4f:bf:d8 brd ff:ff:ff:ff:ff:ff
altname eno3
altname enp7s0
6: eth3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 9c:6b:00:4f:bf:d9 brd ff:ff:ff:ff:ff:ff
altname eno4
altname enp8s0
7: eth4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 1c:34:da:0d:5a:40 brd ff:ff:ff:ff:ff:ff
altname enp2s0
8: eth5: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 1c:34:da:0d:5a:41 brd ff:ff:ff:ff:ff:ff
altname enp2s0d1
С помощью данных команд вы можете проверить, правильно ли назначены адресы на интерфейсы. Часто бывает, что клиенты вносят изменения в ОС и сетевые параметры, из-за чего сервер становится недоступным.
Обращение через тикет
Если в ходе диагностики проблемы не обнаружены, есть вероятность, что с вашей ОС какие-то проблемы. Но иногда не получится без помощи инженеров решить какие-то вопросы. Поэтому после рекомендуем создать тикет, полностью прописать все данные, что у вас есть. На основании этого инженеры вам помогут.

Проблема 2. Вышел из строя диск
Контекст
Часто наши клиенты сталкиваются с проблемой выхода из строя дисков. Причин для этого может быть множество. Среди них — брак, поломка памяти, повреждение поверхности диска, превышение количества записей на диск, из-за чего тот перешел в режим чтения, и т. д.
Совет. Со стороны техподдержки мы рекомендуем следить за состоянием дисков, на которых хранятся ваши данные, ведь после начала аренды мы уже не можем знать, что происходит внутри вашей системы.
Есть много инструментов для мониторинга систем хранения данных. Вы можете самостоятельно попробовать настроить критерии уведомления в случае каких-либо неисправностей, чтобы в дальнейшем быть начеку. Это можно сделать через системы вроде Zabbix.
Самостоятельная диагностика
Представим, что прилетело уведомление и вы готовитесь написать в техподдержку о замене дисков для начала необходимо подготовить информацию о состоянии дисков.
Если у вас система на базе Linux, вам поможет инструмент smartmontools. С помощью него вы подготовите данные для замены: SN-номер диска и состояние SMART-показателей, которые инженер сможет проанализировать.
Вывод данных о SN-номере и производителе диска:
~ # smartctl -a /dev/sda
=== START OF INFORMATION SECTION ===
Model Number: Samsung SSD 980 PRO 2TB
Serial Number: S736NU0WC01301R
Firmware Version: 5B2QGXA7
PCI Vendor/Subsystem ID: 0x144d
IEEE OUI Identifier: 0x002538
Total NVM Capacity: 2,000,398,934,016 [2.00 TB]
Unallocated NVM Capacity: 0
Controller ID: 6
NVMe Version: 1.3
Number of Namespaces: 1
Namespace 1 Size/Capacity: 2,000,398,934,016 [2.00 TB]
Namespace 1 Utilization: 4,194,304 [4.19 MB]
Namespace 1 Formatted LBA Size: 512
Namespace 1 IEEE EUI-64: 002538 bc31a00c40
Local Time is: Tue Aug 27 14:44:51 2024 MSK
Firmware Updates (0x16): 3 Slots, no Reset required
Optional Admin Commands (0x0017): Security Format Frmw_DL Self_Test
Optional NVM Commands (0x0057): Comp Wr_Unc DS_Mngmt Sav/Sel_Feat Timestmp
Log Page Attributes (0x0f): S/H_per_NS Cmd_Eff_Lg Ext_Get_Lg Telmtry_Lg
Maximum Data Transfer Size: 128 Pages
Warning Comp. Temp. Threshold: 82 Celsius
Critical Comp. Temp. Threshold: 85 Celsius
Supported Power States
St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat
0 + 8.49W - - 0 0 0 0 0 0
1 + 4.48W - - 1 1 1 1 0 200
2 + 3.18W - - 2 2 2 2 0 1000
3 - 0.0400W - - 3 3 3 3 2000 1200
4 - 0.0050W - - 4 4 4 4 500 9500
Supported LBA Sizes (NSID 0x1)
Id Fmt Data Metadt Rel_Perf
0 + 512 0 0
=== START OF SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
SMART/Health Information (NVMe Log 0x02)
Critical Warning: 0x00
Temperature: 23 Celsius
Available Spare: 100%
Available Spare Threshold: 10%
Percentage Used: 0%
Data Units Read: 38 [19.4 MB]
Data Units Written: 0
Host Read Commands: 6,623
Host Write Commands: 0
Controller Busy Time: 0
Power Cycles: 21
Power On Hours: 26
Unsafe Shutdowns: 13
Media and Data Integrity Errors: 0
Error Information Log Entries: 0
Warning Comp. Temperature Time: 0
Critical Comp. Temperature Time: 0
Temperature Sensor 1: 23 Celsius
Temperature Sensor 2: 20 Celsius
Error Information (NVMe Log 0x01, 16 of 64 entries)
No Errors Logged
Read Self-test Log failed: Invalid Field in Command (0x002)
Если у вас ОС семейства Windows, вы можете воспользоваться программой CristalDiskInfo, которая также сможет отобразить серийный номер и SMART-показатели для тикета.
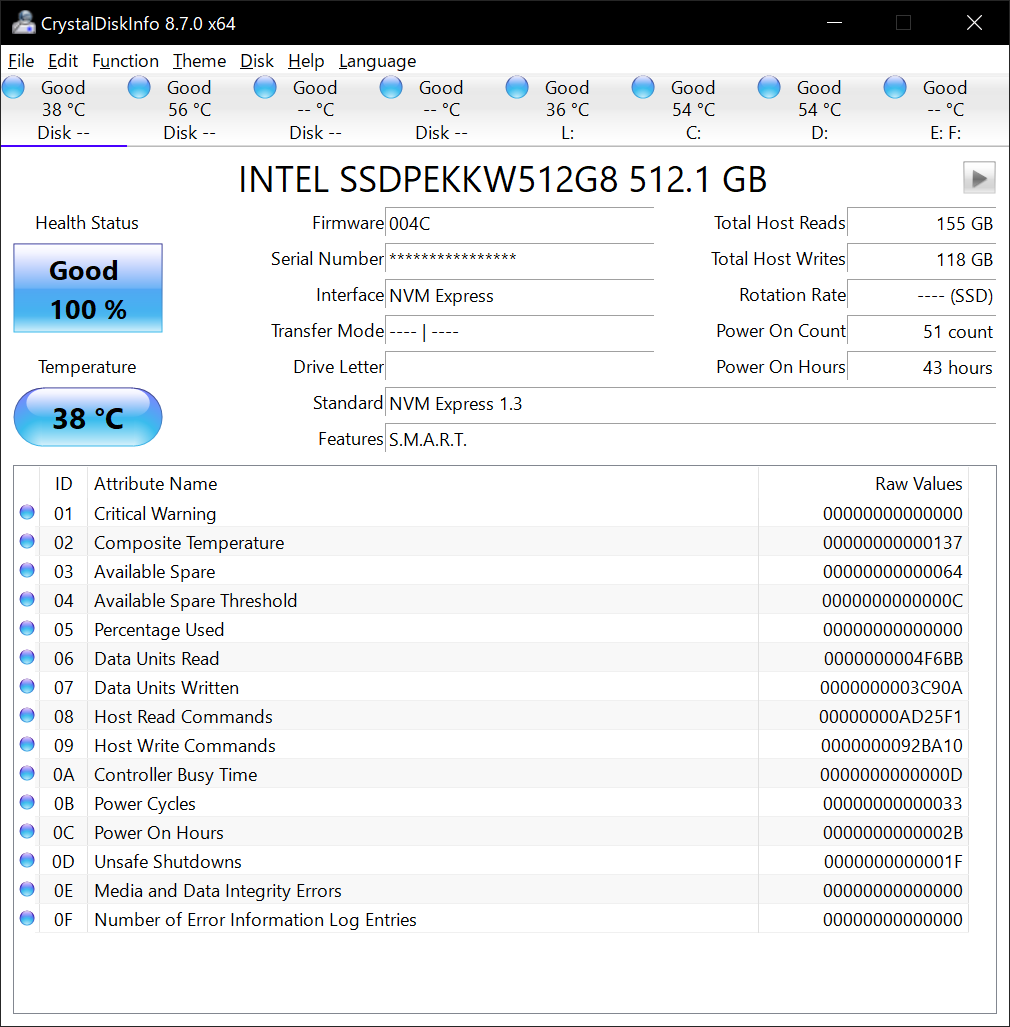
После создания тикета важно по запросу инженеров отправлять дополнительную информацию. При этом нельзя сказать однозначно, какие именно данные нужно собирать, т. к. ключевые показатели у каждого диска могут быть свои. Но если вам важно корректно настроить мониторинг, вы можете создать тикет и мы рассмотрим ваш вопрос.
Важно. Если у вас сформирован RAID-массив на сервере, то придется самостоятельно вывести из него диск перед заменой.
Обращение через тикет

Проблема 3. Вышел из строя блок питания
Контекст
Одна из частых проблем в семействе Chipcore — это выход из строя блоков питания. В данном случае исход почти всегда будет один — тикет в техподдержку для восстановления доступности сервера. Единственное, перед этим необходимо все же попробовать загрузиться в Rescue-режим, чтобы удостовериться, что проблема не в настройках.
Самостоятельная диагностика
Если у вас сервер с BMC-модулем, в логах вы точно обнаружите информацию о вышедшем из строя блоке питания. Также статус датчиков из этого модуля вы можете запросить с помощью команды ipmitool sdr.
~ # ipmitool sdr | grep -i PSU
VOLT_PSU1_VIN | 226 Volts | ok
CUR_PSU1_IOUT | 8.70 Amps | ok
PWR_PSU1_PIN | 120 Watts | ok
PWR_PSU1_POUT | 104 Watts | ok
FAN_PSU1 | 7300 RPM | ok
VOLT_PSU2_VIN | 226 Volts | ok
CUR_PSU2_IOUT | 8.40 Amps | ok
PWR_PSU2_PIN | 120 Watts | ok
PWR_PSU2_POUT | 100 Watts | ok
FAN_PSU2 | 7400 RPM | ok
STS_PSU1 | 0x01 | ok
STS_PSU1_FAN | 0x00 | ok
STS_PSU1_AC_LOST | 0x00 | ok
STS_PSU2 | 0x01 | ok
STS_PSU2_FAN | 0x00 | ok
STS_PSU2_AC_LOST | 0x00 | ok
Проблема 4. Перегревается сервер
Контекст
Температура — один из важных показателей жизнедеятельности сервера. Если не уследить, комплектующие могут деградировать и работать нестабильно, вплоть до полного выхода из строя.
Самостоятельная диагностика
Через Windows температуру можно проверить с помощью различных программ. Одна из них — бесплатная CPUID HWMonitor, которая отображает множество показателей.
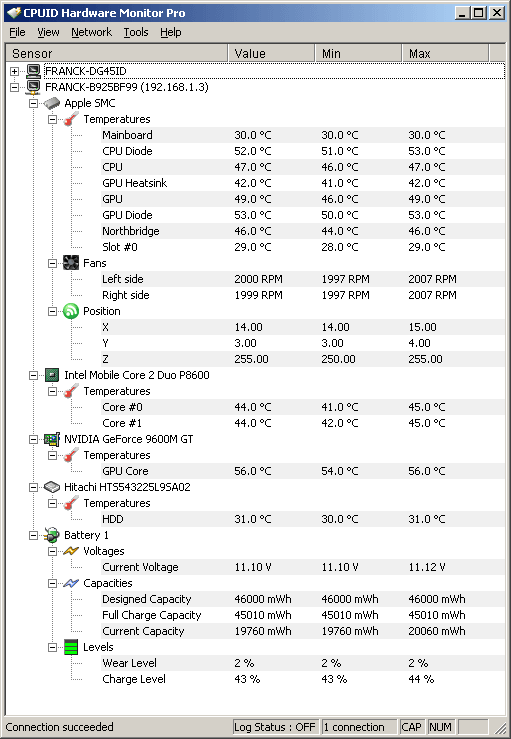
Если вы используете Linux, то можете использовать пакет lm-sensors. Он позволяет отслеживать данные о температуре в реальном времени. После установки с помощью команды sensors вы получите единоразовый вывод данных.
~ # sensors
nvme-pci-0300
Adapter: PCI adapter
Composite: +25.9°C (low = -273.1°C, high = +81.8°C)
(crit = +84.8°C)
Sensor 1: +25.9°C (low = -273.1°C, high = +65261.8°C)
Sensor 2: +38.9°C (low = -273.1°C, high = +65261.8°C)
acpitz-acpi-0
Adapter: ACPI interface
temp1: +27.8°C
coretemp-isa-0000
Adapter: ISA adapter
Package id 0: +63.0°C (high = +80.0°C, crit = +100.0°C)
Core 0: +61.0°C (high = +80.0°C, crit = +100.0°C)
Core 1: +58.0°C (high = +80.0°C, crit = +100.0°C)
Core 2: +61.0°C (high = +80.0°C, crit = +100.0°C)
Core 3: +62.0°C (high = +80.0°C, crit = +100.0°C)
Core 4: +59.0°C (high = +80.0°C, crit = +100.0°C)
Core 5: +63.0°C (high = +80.0°C, crit = +100.0°C)
Core 6: +58.0°C (high = +80.0°C, crit = +100.0°C)
Core 7: +59.0°C (high = +80.0°C, crit = +100.0°C)
Если команду sensors совместить с утилитой watch, вы сможете отслеживать показатели в реальном времени. Для этого необходимо ввести watch sensors.
По нашей практике, если температура процессора превышает 93-95 °C , стоит задуматься о диагностике системы охлаждения данного сервера. За исключением редких случаев, когда такие показатели считаются нормальными для установленного чипа.
Обращение через тикет

Заключение
Цель данной статьи — показать, что скорость помощи инженеров зависит в том числе от исходных данных, которые вы можете предоставить. Ведь кроме вас с первичной диагностикой никто не поможет.
Не забывайте про мониторинг, заведите себе правило хотя бы раз в месяц проверять самочувствие сервера — тогда надежность вашего проекта выйдет на другой уровень.




